Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
In diesem Artikel markierte Elemente (Vorschau) befinden sich derzeit in der öffentlichen oder privaten Vorschau. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Im Bereich der KI-Anwendungsentwicklung hat sich das A/B-Experiment als kritische Praxis entwickelt. Es ermöglicht eine kontinuierliche Bewertung von KI-Anwendungen, das Ausgleichen von Geschäftsauswirkungen, Risiken und Kosten. Während Offline- und Onlinebewertungen einige Erkenntnisse liefern, müssen sie mit A/B-Experimenten ergänzt werden, um sicherzustellen, dass die richtigen Metriken zur Messung des Erfolgs verwendet werden. Bei einem A/B-Experiment werden zwei Versionen eines Features, einer Eingabeaufforderung oder eines Modells mithilfe von Featurekennzeichnungen oder dynamischer Konfiguration verglichen, um zu ermitteln, welche Leistung verbessert wird. Diese Methode ist aus mehreren Gründen unerlässlich:
- Die Verbesserung der Modellleistung – Mit A/B-Experimenten können Entwickler verschiedene Versionen von KI-Modellen, Algorithmen oder Features systematisch testen, um die effektivste Version zu identifizieren. Mit kontrollierten Experimenten können Sie die Auswirkungen von Änderungen auf wichtige Leistungsmetriken messen, z. B. Genauigkeit, Benutzerbindung und Reaktionszeit. Dieser iterative Prozess ermöglicht es Ihnen, das beste Modell zu identifizieren, hilft bei der Feinabstimmung und stellt sicher, dass Ihre Modelle die bestmöglichen Ergebnisse liefern.
- Reduzierung von Bias und Verbesserung der Fairness - KI-Modelle können versehentlich Verzerrungen einführen, was zu unfairen Ergebnissen führt. Das A/B-Experiment hilft dabei, diese Verzerrungen zu identifizieren und zu mindern, indem die Leistung verschiedener Modellversionen in verschiedenen Benutzergruppen verglichen wird. Dadurch wird sichergestellt, dass die KI-Anwendungen fair und gerecht sind und für alle Benutzer eine konsistente Leistung bieten.
- Beschleunigung der Innovation – A/B-Experiment fördert eine Innovationskultur, indem kontinuierliches Experimentieren und Lernen gefördert wird. Sie können schnell neue Ideen und Features überprüfen und so die Zeit und Ressourcen reduzieren, die für unproduktive Ansätze aufgewendet werden. Dies beschleunigt den Entwicklungszyklus und ermöglicht Es Teams, innovative KI-Lösungen schneller auf den Markt zu bringen.
- Optimierung der Benutzererfahrung – Die Benutzererfahrung ist in KI-Anwendungen von größter Bedeutung. Mit A/B-Experimenten können Sie mit verschiedenen Benutzeroberflächendesigns, Interaktionsmustern und Personalisierungsstrategien experimentieren. Durch die Analyse von Benutzerfeedback und -verhalten können Sie die Benutzererfahrung optimieren und KI-Anwendungen intuitiver und ansprechender gestalten.
- Data-Driven Entscheidungsfindung – A/B Experimentation bietet ein robustes Framework für datengesteuerte Entscheidungsfindung. Anstatt sich auf Intuition oder Annahmen zu verlassen, können Sie Ihre Entscheidungen auf empirische Beweise stützen. Dies führt zu fundierteren und effektiveren Strategien zur Verbesserung von KI-Anwendungen.
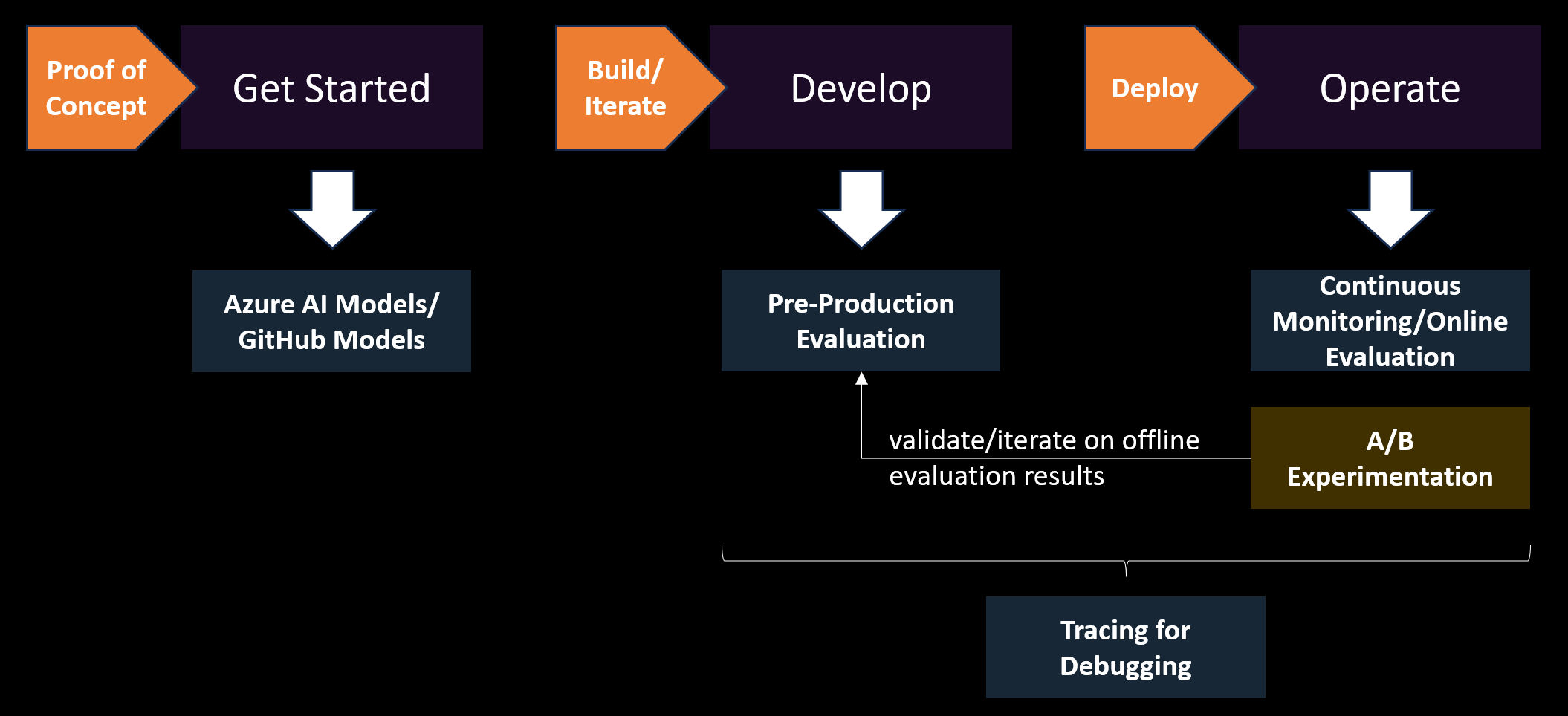
Wie passt das A/B-Experiment in den LEBENSZYKLUS der KI-Anwendung?
A/B-Experimentierung und Offline-Auswertung sind beide wesentliche Komponenten bei der Entwicklung von KI-Anwendungen, die jeweils einzigartige Zwecke dienen, die einander ergänzen.
Bei der Offlinebewertung werden KI-Modelle mithilfe von Testdatensätzen getestet, um ihre Leistung in verschiedenen Metriken wie Fluency und Kohärenz zu messen. Nachdem Sie ein Modell im Azure AI-Modellkatalog oder gitHub Model Marketplace ausgewählt haben, ist die Offline-Vorproduktionsbewertung für die anfängliche Modellüberprüfung während der Integrationstests von entscheidender Bedeutung, sodass Sie potenzielle Probleme erkennen und Verbesserungen vornehmen können, bevor Sie das Modell oder die Anwendung in der Produktion bereitstellen.
Die Offlineauswertung hat jedoch ihre Einschränkungen. Die komplexen Interaktionen, die in realen Szenarien auftreten, können nicht vollständig erfasst werden. Hier kommt A/B-Experiment ins Spiel. Durch die Bereitstellung verschiedener Versionen des KI-Modells oder der UX-Features für Livebenutzer bietet A/B-Experimente Einblicke in die Funktionsweise des Modells und der Anwendung unter realen Bedingungen. Dies hilft Ihnen, das Benutzerverhalten zu verstehen, unvorhergesehene Probleme zu erkennen und die Auswirkungen von Änderungen auf Modellauswertungsmetriken, operative Metriken (z. B. Latenz) und Geschäftsmetriken (z. B. Kontoanmeldungen, Konvertierungen usw.) zu messen.
Wie im Diagramm gezeigt, während die Offlineauswertung für die anfängliche Modellvalidierung und -verfeinerung unerlässlich ist, stellt A/B-Experimente die realen Tests bereit, die erforderlich sind, um sicherzustellen, dass die KI-Anwendung effektiv und fair in der Praxis ausgeführt wird. Gemeinsam bilden sie einen umfassenden Ansatz zur Entwicklung robuster, sicherer und benutzerfreundlicher KI-Anwendungen.
Skalieren von KI-Anwendungen mit Azure AI-Auswertungen und Online-A/B-Experimenten mit CI/CD-Workflows
Wir vereinfachen den Auswertungs- und A/B-Experimentierprozess mit GitHub-Aktionen erheblich, die nahtlos in vorhandene CI/CD-Workflows in GitHub integriert werden können. In Ihren CI-Workflows können Sie jetzt unsere Azure AI Evaluation GitHub Action verwenden, um manuelle oder automatisierte Auswertungen auszuführen, nachdem Änderungen mithilfe des Azure AI Evaluation SDK zur Berechnung von Metriken wie Kohärenz und Fluency übernommen wurden.
Mithilfe der GitHub-Aktion (Vorschau) für Onlineexperimente können Sie A/B-Experimente in Ihre CD-Workflows (Continuous Deployment) integrieren. Sie können dieses Feature verwenden, um A/B-Experimente automatisch mit integrierten KI-Modellmetriken und benutzerdefinierten Metriken als Teil Ihrer CD-Workflows nach erfolgreicher Bereitstellung zu erstellen und zu analysieren. Darüber hinaus können Sie das GitHub Copilot für das Azure-Plugin verwenden, um Experimente durchzuführen, Metriken zu erstellen und die Entscheidungsfindung zu unterstützen.
Von Bedeutung
Onlineexperimente sind über eine Vorschau für eingeschränkten Zugriff verfügbar. Fordern Sie Zugriff auf weitere Informationen an.
Azure AI-Partner
Sie können auch Ihren eigenen A/B-Experimentieranbieter verwenden, um Experimente für Ihre KI-Anwendungen auszuführen. Es gibt mehrere Lösungen, aus denen Sie in Azure Marketplace wählen können:
Statsig
Statsig ist eine Experimentierplattform für Produkt-, Engineering- und Data Science-Teams, die die Von Ihnen erstellten Features mit den von Ihnen wichtigen Geschäftsmetriken verbinden. Statsig unterstützt automatische A/B-Tests und Experimente für Web- und mobile Anwendungen und bietet Teams einen umfassenden Überblick darüber, welche Features die Auswirkungen fördern (und die nicht). Um das Experimentieren mit Azure AI zu vereinfachen, hat Statsig SDKs veröffentlicht, die auf dem Azure AI SDK und der Azure AI Inference-API basieren, die es Statsig-Kunden erleichtert, Experimente auszuführen.
Andere A/B-Experimentanbietende
Split.io
mit Split.io können Sie Featurekennzeichnungen einrichten und sicher in der Produktion bereitstellen und steuern, wer welche Features und wann sieht. Sie können auch jede Kennzeichnung mit Kontextdaten verbinden, sodass Sie wissen, ob Ihre Features Dinge besser oder schlechter machen und ohne Zögern handeln. Mit den Microsoft-Integrationen von Split unterstützen wir Entwicklungsteams beim Verwalten von Featurekennzeichnungen, überwachen die Releaseleistung, das Experiment und die Oberflächendaten, um laufende, datengesteuerte Entscheidungen zu treffen.
LaunchDarkly
LaunchDarkly ist eine Featureverwaltungs- und Experimentierplattform, die mit Softwareentwicklern entwickelt wurde. Es ermöglicht Ihnen, Funktionskennzeichen in großem Umfang zu verwalten, A/B-Tests und Experimente auszuführen und Software schrittweise mit Vertrauen zu liefern.