Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure AI Foundry enthält ein Inhaltsfiltersystem, das zusammen mit Kernmodellen und Bildgenerierungsmodellen funktioniert.
Von Bedeutung
Das Inhaltsfiltersystem wird nicht auf Aufforderungen und Fertigstellungen angewendet, die vom Flüstermodell in Azure OpenAI in Azure AI Foundry Models verarbeitet werden. Erfahren Sie mehr über das Whisper-Modell in Azure OpenAI.
Funktionsweise
Das Inhaltsfiltersystem wird von Azure AI Content Safety unterstützt, und es funktioniert, indem sowohl die Modellaufforderungseingabe als auch die Abschlussausgabe über eine Reihe von Klassifizierungsmodellen ausgeführt werden, die darauf ausgelegt sind, die Ausgabe schädlicher Inhalte zu erkennen und zu verhindern. Variationen in API-Konfigurationen und Anwendungsentwurf können sich auf Vervollständigungen und somit auf das Filterverhalten auswirken.
Mit Azure OpenAI-Modellbereitstellungen können Sie den Standardinhaltsfilter verwenden oder Ihren eigenen Inhaltsfilter erstellen (weiter unten beschrieben). Modelle, die über serverlose API-Bereitstellungen verfügbar sind, haben standardmäßig die Inhaltsfilterung aktiviert. Weitere Informationen zum Standardinhaltsfilter, der für serverlose API-Bereitstellungen aktiviert ist, finden Sie unter Inhaltssicherheit für Modelle, die direkt von Azure verkauft werden .
Sprachunterstützung
Die Inhaltsfiltermodelle wurden für die folgenden Sprachen trainiert und getestet: Englisch, Deutsch, Japanisch, Spanisch, Französisch, Italienisch, Portugiesisch und Chinesisch. Der Dienst kann jedoch in vielen anderen Sprachen funktionieren, die Qualität kann jedoch variieren. In allen Fällen sollten Sie eigene Tests durchführen, um sicherzustellen, dass es für Ihre Anwendung funktioniert.
Inhaltsrisikofilter (Eingabe- und Ausgabefilter)
Die folgenden speziellen Filter funktionieren sowohl für die Eingabe als auch für die Ausgabe von generativen KI-Modellen:
Kategorien
| Kategorie | BESCHREIBUNG |
|---|---|
| Hass | Die Kategorie „Hass“ beschreibt sprachliche Angriffe oder Verwendungen, die abwertende oder diskriminierende Ausdrücke in Bezug auf eine Person oder eine Identitätsgruppe auf der Grundlage bestimmter differenzierender Merkmale dieser Gruppen enthalten, einschließlich, aber nicht beschränkt auf Rasse, ethnische Zugehörigkeit, Nationalität, Geschlechtsidentität und -ausdruck, sexuelle Orientierung, Religion, Einwanderungsstatus, Fähigkeitsstatus, persönliches Aussehen und Körpergröße. |
| Sexuell | Die Kategorie „Sexuell“ beschreibt Sprache, die sich auf anatomische Organe und Genitalien, romantische Beziehungen, erotisch oder zärtlich dargestellte Akte, körperliche sexuelle Akte – einschließlich solcher Akte, die als Übergriff oder erzwungener sexueller Gewaltakt gegen den eigenen Willen dargestellt werden –, Prostitution, Pornografie und Missbrauch bezieht. |
| Gewalt | Die Kategorie „Gewalt“ beschreibt die Sprache im Zusammenhang mit körperlichen Handlungen, die dazu dienen, jemanden oder etwas zu verletzen, zu beschädigen oder zu töten bzw. die Waffen usw. beschreibt. |
| Selbstverletzung | Die Kategorie „Selbstverletzung“ beschreibt Sprache, die sich auf körperliche Handlungen bezieht und darauf abzielt, den eigenen Körper absichtlich zu verletzen, zu verwunden oder zu schädigen oder sich selbst zu töten. |
Schweregrade
| Kategorie | BESCHREIBUNG |
|---|---|
| Sicher | Der Inhalt kann sich auf die Kategorien Gewalt, Selbstbeschädigung, Sexualität oder Hass beziehen, aber es werden Begriffe in allgemeinen, journalistischen, wissenschaftlichen, medizinischen und ähnlichen professionellen Kontexten verwendet, die für die meisten Zielgruppen angemessen sind. |
| Niedrig | Inhalte, die voreingenommene, urteilende oder dogmatische Ansichten zum Ausdruck bringen, umfassen anstößige Verwendung von Sprache, Stereotypisierung, Anwendungsfälle, die eine fiktive Welt erkunden (z. B. Spiele, Literatur) und Darstellungen mit geringer Intensität. |
| Mittelstufe | Inhalte, die sich einer beleidigenden, beleidigenden, verhöhnenden, einschüchternden oder erniedrigenden Sprache gegenüber bestimmten Identitätsgruppen bedienen, einschließlich Darstellungen der Suche nach und der Ausführung von schädlichen Anweisungen, Phantasien, Verherrlichung, Förderung von Schaden in mittlerer Intensität. |
| High | Inhalte, die explizite und schwerwiegende schädliche Anweisungen, Handlungen, Schäden oder Missbrauch zeigen; dazu gehören die Befürwortung, Verherrlichung oder Förderung von schwerwiegenden schädlichen Handlungen, extremen oder illegalen Formen der Schädigung, Radikalisierung oder nicht-einvernehmlicher Machtaustausch oder Missbrauch. |
Andere Eingabefilter
Sie können auch spezielle Filter für Szenarien mit generativer KI aktivieren:
- Jailbreak-Angriffe: Jailbreak-Angriffe sind Benutzer-Prompts, die darauf abzielen, ein Verhalten des generativen KI-Modells zu provozieren, für dessen Vermeidung es trainiert wurde, oder gegen die in der Systemnachricht festgelegten Regeln zu verstoßen.
- Indirekte Angriffe: Indirekte Angriffe, die auch als indirekte Promptangriffe oder domänenübergreifende Prompteinschleusungsangriffe bezeichnet werden, sind ein potenzielles Sicherheitsrisiko, bei dem Dritte böswillige Anweisungen innerhalb von Dokumenten platzieren, auf die das generative KI-System zugreifen und die es verarbeiten kann.
Andere Ausgabefilter
Sie können auch die folgenden speziellen Ausgabefilter aktivieren:
- Geschütztes Material für Text: Geschützter Materialtext beschreibt bekannte Textinhalte (z. B. Liedtexte, Artikel, Rezepte und ausgewählte Webinhalte), die von großen Sprachmodellen ausgegeben werden können.
- Geschütztes Material für Code: Geschützter Materialcode beschreibt Quellcode, der Quellcode aus öffentlichen Repositorys entspricht, der von großen Sprachmodellen ohne ordnungsgemäße Nennung von Quellrepositorys ausgegeben werden kann.
- Quellenübereinstimmung: Die Quellenübereinstimmungserkennungs-API erkennt, ob die Textantworten großer Sprachmodelle (LLMs) von den durch Benutzer bereitgestellten Quellmaterialien gestützt werden.
Erstellen eines Inhaltsfilters in Azure AI Foundry
Für jede Modellbereitstellung in Azure KI Foundry können Sie direkt den Standardinhaltsfilter verwenden, aber Sie sollten vielleicht mehr Kontrolle haben. So können Sie z. B. einen Filter strenger oder lascher gestalten oder erweiterte Funktionen wie Prompt Shields und die Erkennung von geschütztem Material aktivieren.
Von Bedeutung
Das GPT-image-1-Modell unterstützt keine Inhaltsfilterkonfiguration: Nur der Standardinhaltsfilter wird verwendet.
Tipp
Eine Anleitung zu Inhaltsfiltern in Ihrem Azure KI Foundry-Projekt finden Sie unter Azure KI Foundry-Inhaltsfilterung.
Führen Sie folgende Schritte aus, um einen Inhaltsfilter zu erstellen:
Tipp
Da Sie den linken Bereich im Azure AI Foundry-Portal anpassen können, werden möglicherweise unterschiedliche Elemente angezeigt als in diesen Schritten. Wenn Sie nicht sehen, wonach Sie suchen, wählen Sie ... Mehr am unteren Rand des linken Bereichs.
Wechseln Sie zu Azure AI Foundry und navigieren Sie zu Ihrem Projekt. Wählen Sie dann im linken Menü die Seite "Guardrails + controls " aus, und wählen Sie die Registerkarte "Inhaltsfilter" aus.
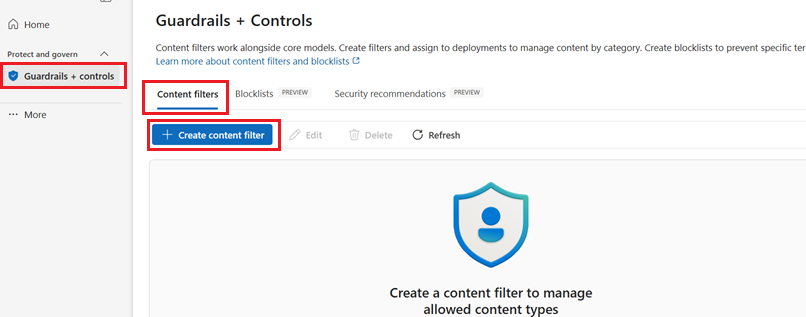
Wählen Sie + Inhaltsfilter erstellen.
Geben Sie auf der Seite Grundlegende Informationen einen Namen für die Inhaltsfilterkonfiguration ein. Wählen Sie eine Verbindung aus, die dem Inhaltsfilter zugeordnet werden soll. Wählen Sie dann Weiter aus.
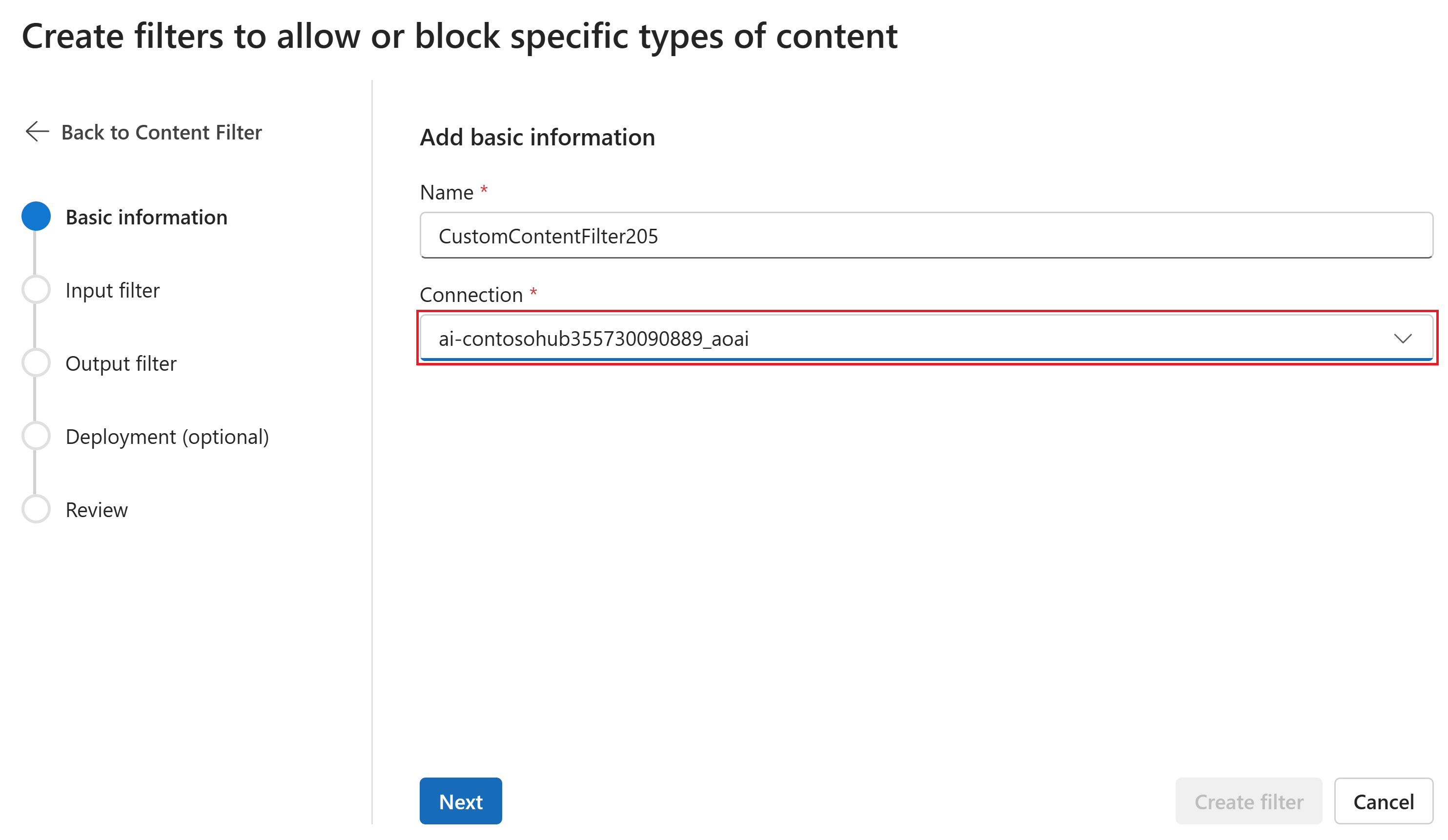
Nun können Sie die Eingabefilter (für Benutzer-Prompts) und Ausgabefilter (für die Modellvervollständigung) konfigurieren.
Auf der Seite Eingabefilter können Sie den Filter für den Eingabe-Prompt festlegen. Für die ersten vier Inhaltskategorien gibt es drei Schweregrade, die konfigurierbar sind: niedrig, mittel und hoch. Sie können die Schieberegler verwenden, um den Schweregradschwellenwert festzulegen, wenn Sie feststellen, dass Ihre Anwendung oder Ihr Verwendungsszenario eine andere Filterung als die Standardwerte erfordert. Mit einigen Filtern, z. B. Prompt Shields und geschützte Materialerkennung, können Sie bestimmen, ob das Modell Inhalte kommentieren und/oder blockieren soll. Wenn Sie "Nur annotieren" auswählen, wird das respektive Modell ausgeführt und Anmerkungen über die API-Antwort zurückgegeben, aber die Inhalte werden nicht gefiltert. Zusätzlich zum Kommentieren können Sie auch Inhalte blockieren.
Wenn Ihr Anwendungsfall für geänderte Inhaltsfilter genehmigt wurde, erhalten Sie die vollständige Kontrolle über die Inhaltsfilterkonfigurationen und können die Filterung teilweise oder vollständig deaktivieren. Sie können auch das Kommentieren nur für Kategorien mit schädlichen Inhalten aktivieren (Gewalt, Hass, sexuelle Inhalte und Selbstverletzung).
Inhalte werden nach Kategorie kommentiert und entsprechend dem von Ihnen festgelegten Schwellenwert blockiert. Passen Sie den Schieberegler der Kategorien für Gewalt, Hass, Sexualität und Selbstverletzung an, um Inhalte mit hohem, mittlerem oder geringem Schweregrad zu blockieren.
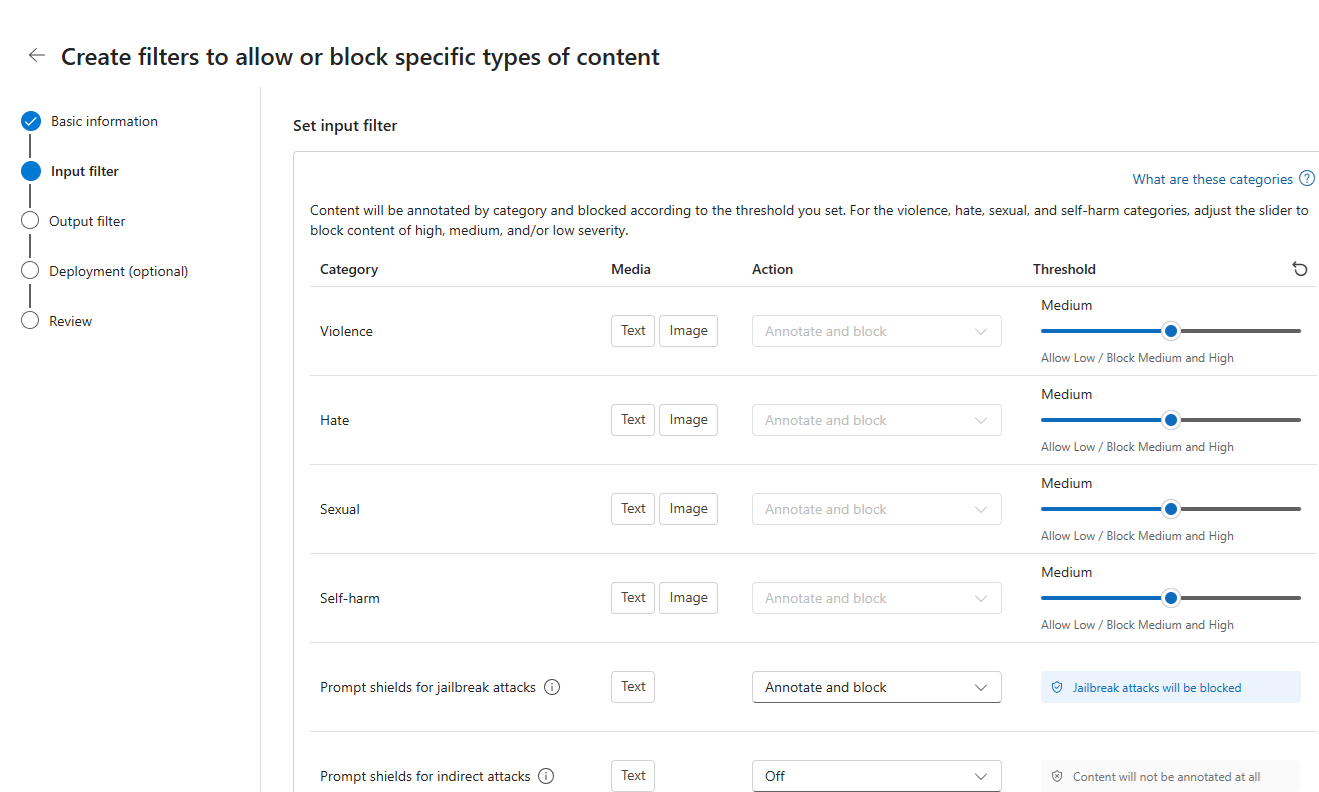
Auf der Seite Ausgabefilter können Sie den Ausgabefilter konfigurieren, der auf alle Ausgabeinhalte angewendet wird, die von Ihrem Modell generiert werden. Konfigurieren Sie die einzelnen Filter wie zuvor. Diese Seite bietet auch die Option „Streamingmodus“, mit der Sie Inhalte nahezu in Echtzeit filtern können, während sie vom Modell generiert werden, wodurch die Wartezeit reduziert wird. Wählen Sie anschließend Weiter.
Inhalte werden nach den einzelnen Kategorien kommentiert und entsprechend dem Schwellenwert blockiert. Passen Sie bei der Kategorie für gewalttätige Inhalte, Hassinhalte, sexuelle Inhalte und Inhalte mit Bezug auf Selbstverletzung den Schwellenwert an, um schädliche Inhalte mit gleichem oder höherem Schweregrad zu blockieren.
Optional können Sie auf der Seite Bereitstellung den Inhaltsfilter einer Bereitstellung zuordnen. Wenn eine ausgewählte Bereitstellung bereits über einen Filter verfügt, müssen Sie bestätigen, dass Sie ihn ersetzen möchten. Sie können den Inhaltsfilter auch später einer Bereitstellung zuordnen. Wählen Sie "Erstellen" aus.
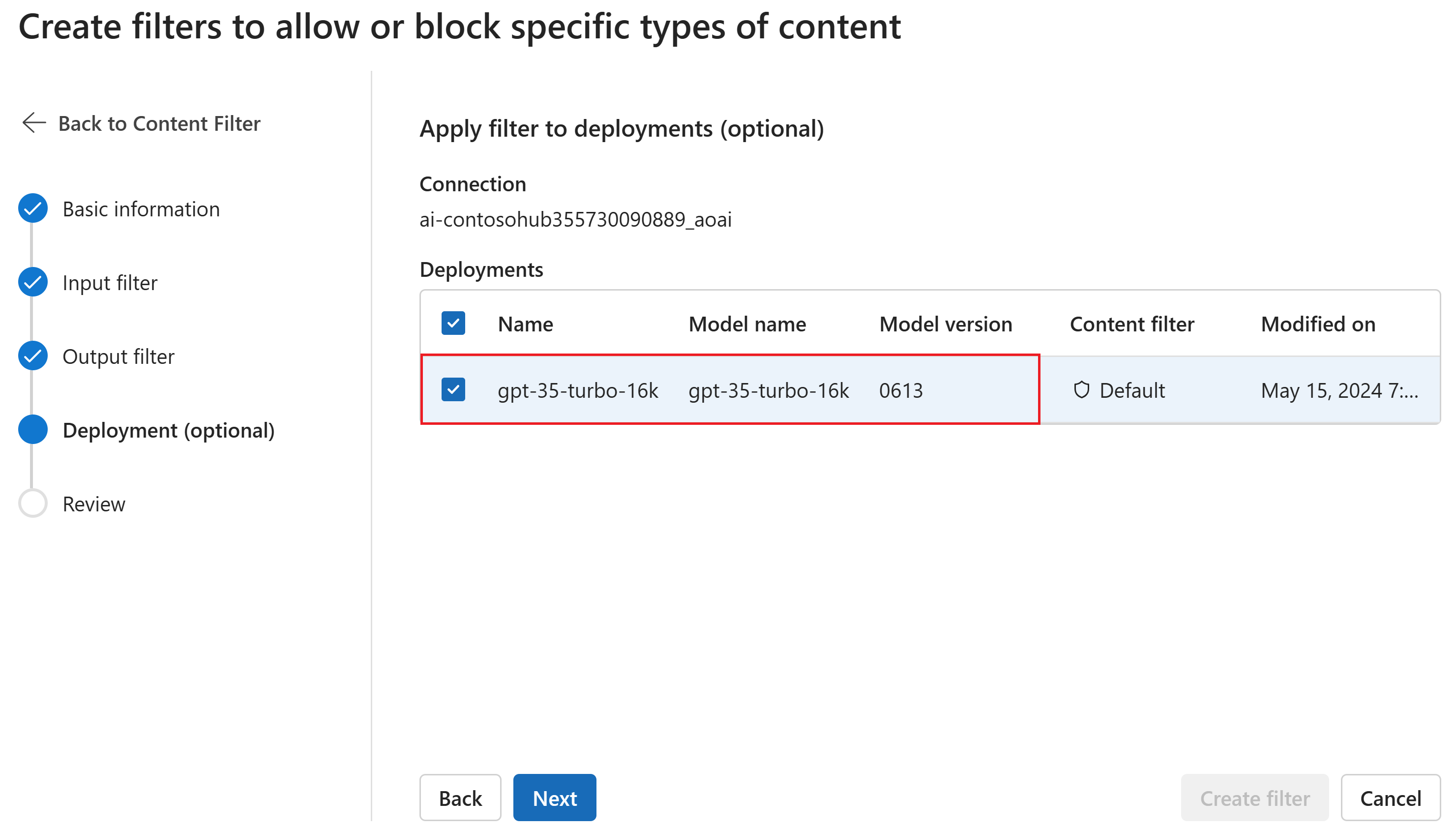
Inhaltsfilterkonfigurationen werden auf Hubebene im Azure AI Foundry-Portal erstellt. Erfahren Sie mehr über die Konfigurierbarkeit in der Azure OpenAI in der Dokumentation zu Azure AI Foundry Models.
Überprüfen Sie auf der Registerkarte Überprüfen Ihre Einstellungen, und wählen Sie dann Filter erstellen.



Verwendung einer Sperrliste als Filter
Sie können eine Sperrliste entweder als Eingabe- oder Ausgabefilter oder als beides anwenden. Aktivieren Sie die Option Sperrliste auf der Seite Eingabefilter und/oder auf der Seite Ausgabefilter. Wählen Sie eine oder mehrere Sperrlisten aus dem Dropdown-Menü aus oder verwenden Sie die integrierte Sperrliste für Obszönitäten. Sie können mehrere Sperrlisten im selben Filter kombinieren.
Anwendung eines Inhaltsfilters
Der Prozess der Filtererstellung bietet Ihnen die Möglichkeit, den Filter auf die gewünschten Bereitstellungen anzuwenden. Sie können Inhaltsfilter auch jederzeit ändern oder aus Ihren Bereitstellungen entfernen.
Führen Sie die folgenden Schritte aus, um einen Inhaltsfilter auf eine Bereitstellung anzuwenden:
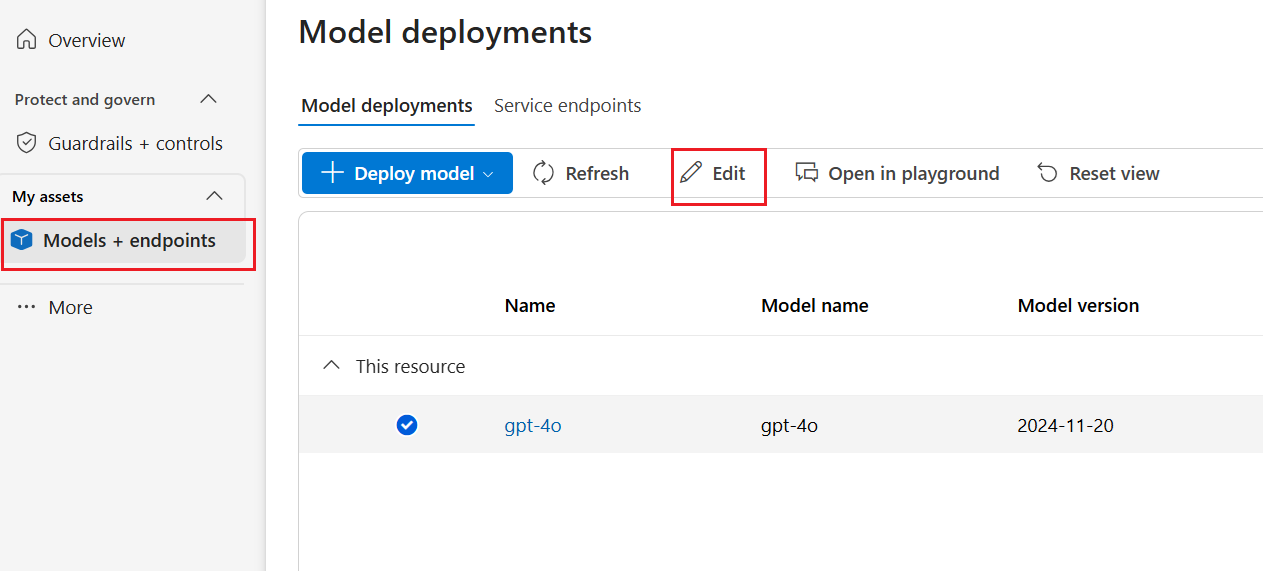
Wechseln Sie zu Azure AI Foundry und wählen Sie ein Projekt aus.
Wählen Sie Modelle + Endpunkte im linken Bereich und dann eine Ihrer Bereitstellungen aus, und wählen Sie dann Bearbeiten.
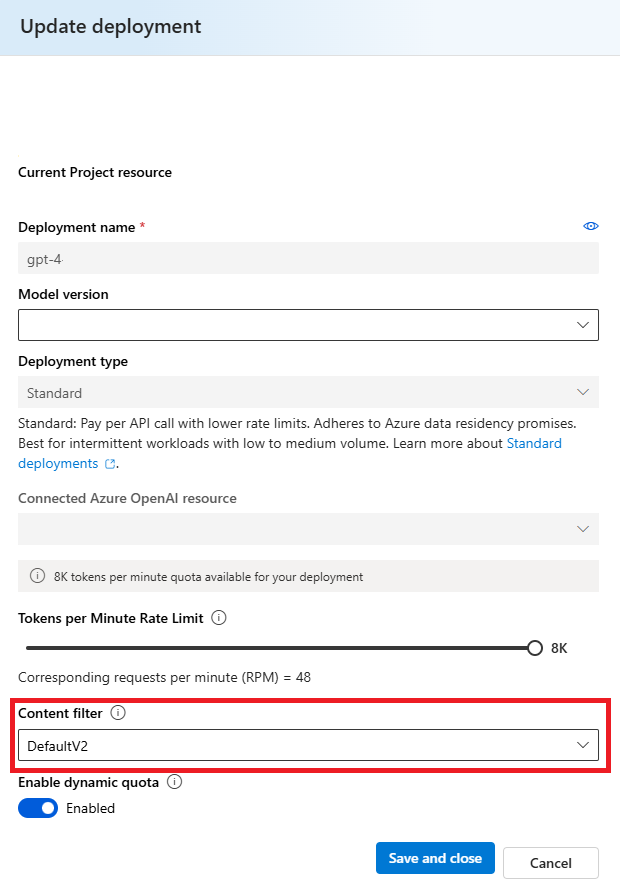
Wählen Sie im Fenster Bereitstellung aktualisieren den Inhaltsfilter aus, den Sie auf die Bereitstellung anwenden möchten. Wählen Sie dann Speichern und schließen.
Sie können bei Bedarf eine Inhaltsfilterkonfiguration auch bearbeiten und löschen. Bevor Sie eine Inhaltsfilterkonfiguration löschen, müssen Sie die Zuweisung für jede Bereitstellung auf der Registerkarte Bereitstellungen aufheben und ersetzen.


Jetzt können Sie zum Playground wechseln, um zu testen, ob der Inhaltsfilter wie erwartet funktioniert.
Tipp
Sie können inhaltsfilter auch mithilfe der REST-APIs erstellen und aktualisieren. Weitere Informationen finden Sie in der API-Referenz. Inhaltsfilter können auf der Ressourcenebene konfiguriert werden. Sobald eine neue Konfiguration erstellt wurde, kann sie einer oder mehreren Bereitstellungen zugeordnet werden. Weitere Informationen zur Modellbereitstellung finden Sie im Ressourcenbereitstellungshandbuch.
Konfigurierbarkeit (Vorschau)
Azure OpenAI in Azure AI Foundry Models enthält Standardsicherheitseinstellungen, die auf alle Modelle angewendet werden (ausgenommen Audio-API-Modelle wie Flüster). Diese Konfigurationen bieten Ihnen standardmäßig eine verantwortungsvolle Umgebung, die Inhaltsfiltermodelle, Blockierlisten, Prompttransformation, Inhaltsanmeldeinformationen und mehr enthält. Hier erfahren Sie mehr.
Alle Kunden können auch Inhaltsfilter konfigurieren und benutzerdefinierte Inhaltsrichtlinien erstellen, die auf ihre Anwendungsfallanforderungen zugeschnitten sind. Das Feature für die Konfigurierbarkeit ermöglicht Kunden, die Einstellungen separat für Prompts und Vervollständigungen anzupassen, um Inhalte für jede Inhaltskategorie mit unterschiedlichen Schweregraden zu filtern, wie in der folgenden Tabelle beschrieben. Inhalte, die im Schweregrad 'sicher' erkannt werden, sind im Annotationsergebnis gekennzeichnet, unterliegen jedoch nicht der Filterung und können nicht konfiguriert werden.
| Nach Schweregrad gefiltert | Konfigurierbar für Aufforderungen | Konfigurierbar für Vervollständigungen | Beschreibungen |
|---|---|---|---|
| Niedrig, mittel, hoch | Ja | Ja | Strengste Filterkonfiguration. Mit den Schweregraden „Niedrig“, „Mittel“ und „Hoch“ erkannte Inhalte werden gefiltert. |
| Mittel, Hoch | Ja | Ja | Mit dem Schweregrad „Niedrig“ erkannte Inhalte werden nicht gefiltert, Inhalte mit mittlerem und hohem Schweregrad werden gefiltert. |
| Hoch | Ja | Ja | Mit den Schweregraden „Niedrig“ und „Mittel“ erkannte Inhalte werden nicht gefiltert. Nur Inhalte mit hohem Schweregrad werden gefiltert. |
| Keine Filter | Wenn genehmigt1 | Wenn genehmigt1 | Unabhängig vom erkannten Schweregrad wird kein Inhalt gefiltert. Genehmigung erforderlich1. |
| Nur kommentieren | Wenn genehmigt1 | Wenn genehmigt1 | Deaktiviert die Filterfunktion, sodass Inhalte nicht blockiert, aber Anmerkungen über die API-Antwort zurückgegeben werden. Genehmigung erforderlich1. |
1 Bei Azure OpenAI-Modelle haben nur die Kunden uneingeschränkte Kontrolle über die Inhaltsfilterung und können Inhaltsfilter deaktivieren, die für die angepasste Inhaltsfilterung zugelassen wurden. Beantragen Sie geänderte Inhaltsfilter über dieses Formular: Azure OpenAI Limited Access Review: Modified Content Filters. Für Azure Government-Kunden wenden Sie sich über dieses Formular für geänderte Inhaltsfilter an: Azure Government – Anfordern der geänderten Inhaltsfilterung für Azure OpenAI.
Konfigurierbare Inhaltsfilter für Eingaben (Prompts) und Ausgaben (Vervollständigungen) stehen für alle Azure OpenAI-Modelle zur Verfügung.
Inhaltsfilterkonfigurationen werden in einer Ressource im Azure KI Foundry-Portal erstellt und können Bereitstellungen zugeordnet werden. Weitere Informationen zum Konfigurieren von Inhaltsfiltern finden Sie hier.
Kunden sind dafür verantwortlich, sicherzustellen, dass Anwendungen, die Azure OpenAI integrieren, den Verhaltenskodex einhalten.
Verwandte Inhalte
- Erfahren Sie mehr über die zugrunde liegenden Modelle, auf denen Azure OpenAI basiert.
- Die Azure KI Foundry-Inhaltsfilterung wird von Azure KI Inhaltssicherheit unterstützt.
- Erfahren Sie mehr über das Verstehen und Minimieren von Risiken im Zusammenhang mit Ihrer Anwendung: Übersicht über Methoden für verantwortungsvolle KI für Azure OpenAI-Modelle.
- Über Azure AI Evaluation erfahren Sie mehr über die Auswertung Ihrer Modelle mit generativer KI und KI-Systeme.