Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Multimodale große Sprachmodelle (Large Language Models, LLMs), die verschiedene Formen von Dateneingaben verarbeiten und interpretieren können, stellen ein leistungsfähiges Tool dar, das die Fähigkeiten von reinen Sprachsystemen auf ein neues Level bringen kann. Bei den verschiedenen Datentypen sind Bilder für viele reale Anwendungen wichtig. Die Einbindung von Bilddaten in KI-Systeme sorgt für ein visuelles Grundverständnis.
In diesem Artikel wird Folgendes behandelt:
- Verwenden von Bilddaten in prompt flow
- Verwenden des integrierten GPT-4V-Tools zum Analysieren von Bildeingaben
- Erstellen eines Chatbots, der Bild- und Texteingaben verarbeiten kann
- Erstellen einer Batchausführung mithilfe von Bilddaten
- Nutzen eines Onlineendpunkts mit Bilddaten
Bildtyp in prompt flow
prompt flow-Eingabe und -Ausgabe unterstützen Bilder als neuen Datentyp.
So verwenden Sie Bilddaten auf der Seite für die prompt flow-Erstellung
Fügen Sie eine Floweingabe hinzu, und wählen Sie den Datentyp Bild aus. Sie können eine Bilddatei hochladen oder ziehen und ablegen, ein Bild aus der Zwischenablage einfügen oder eine Bild-URL oder den relativen Bildpfad im Flowordner angeben.

Zeigen Sie eine Vorschau des Bilds an. Wenn das Bild nicht ordnungsgemäß angezeigt wird, löschen Sie das Bild, und fügen Sie es erneut hinzu.

Möglicherweise möchten Sie das Bild mithilfe des Python-Tools vorverarbeitet, bevor Sie es an die LLM übergeben. Sie können beispielsweise die Größe des Bilds ändern oder es auf eine kleinere Größe zuschneiden.
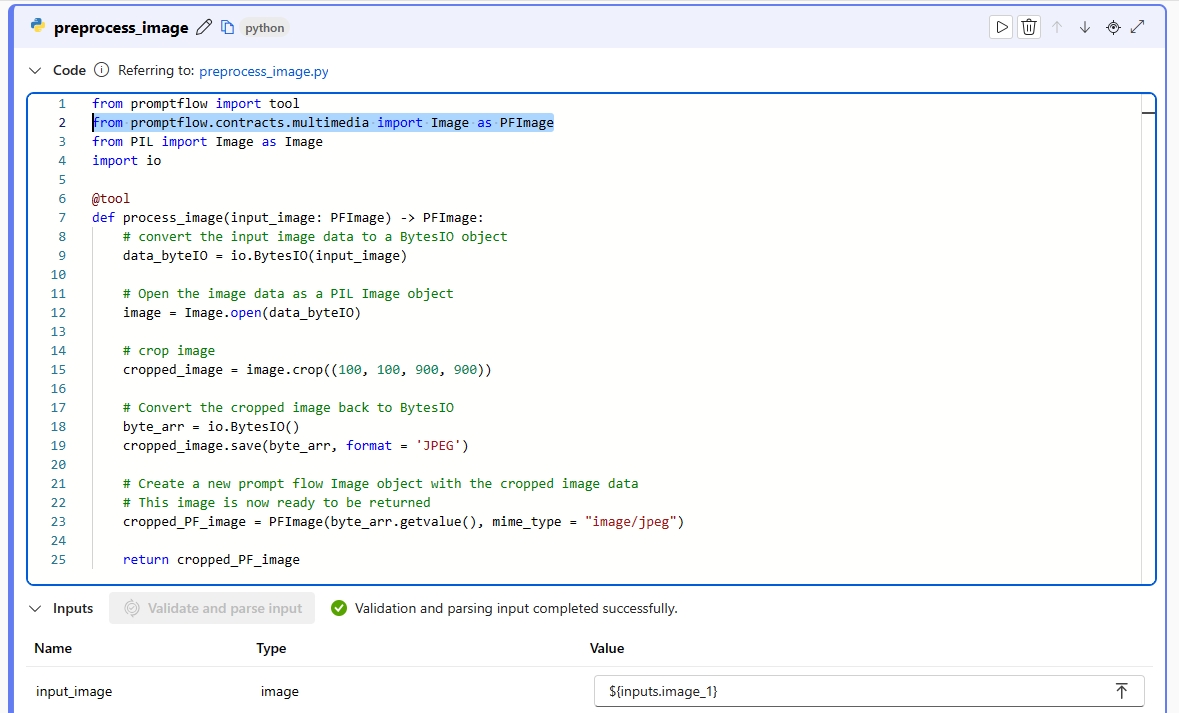
from promptflow import tool from promptflow.contracts.multimedia import Image as PFImage from PIL import Image as Image import io @tool def process_image(input_image: PFImage) -> PFImage: # convert the input image data to a BytesIO object data_byteIO = io.BytesIO(input_image) # Open the image data as a PIL Image object image = Image.open(data_byteIO) # crop image cropped_image = image.crop((100, 100, 900, 900)) # Convert the cropped image back to BytesIO byte_arr = io.BytesIO() cropped_image.save(byte_arr, format = 'JPEG') # Create a new prompt flow Image object with the cropped image data # This image is now ready to be returned cropped_PF_image = PFImage(byte_arr.getvalue(), mime_type = "image/jpeg") return cropped_PF_image ``` > [!IMPORTANT] > To process images using a Python function, you need to use the `Image` class that you import from the `promptflow.contracts.multimedia` package. The `Image` class is used to represent an `Image` type within prompt flow. It is designed to work with image data in byte format, which is convenient when you need to handle or manipulate the image data directly. > > To return the processed image data, you need to use the `Image` class to wrap the image data. Create an `Image` object by providing the image data in bytes and the [MIME type](https://developer.mozilla.org/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types) `mime_type`. The MIME type lets the system understand the format of the image data, or it can be `*` for unknown type.Führen Sie den Python-Knoten aus, und überprüfen Sie die Ausgabe. In diesem Beispiel gibt die Python-Funktion das verarbeitete Bildobjekt zurück. Wählen Sie die Bildausgabe aus, um eine Vorschau des Bilds anzuzeigen.
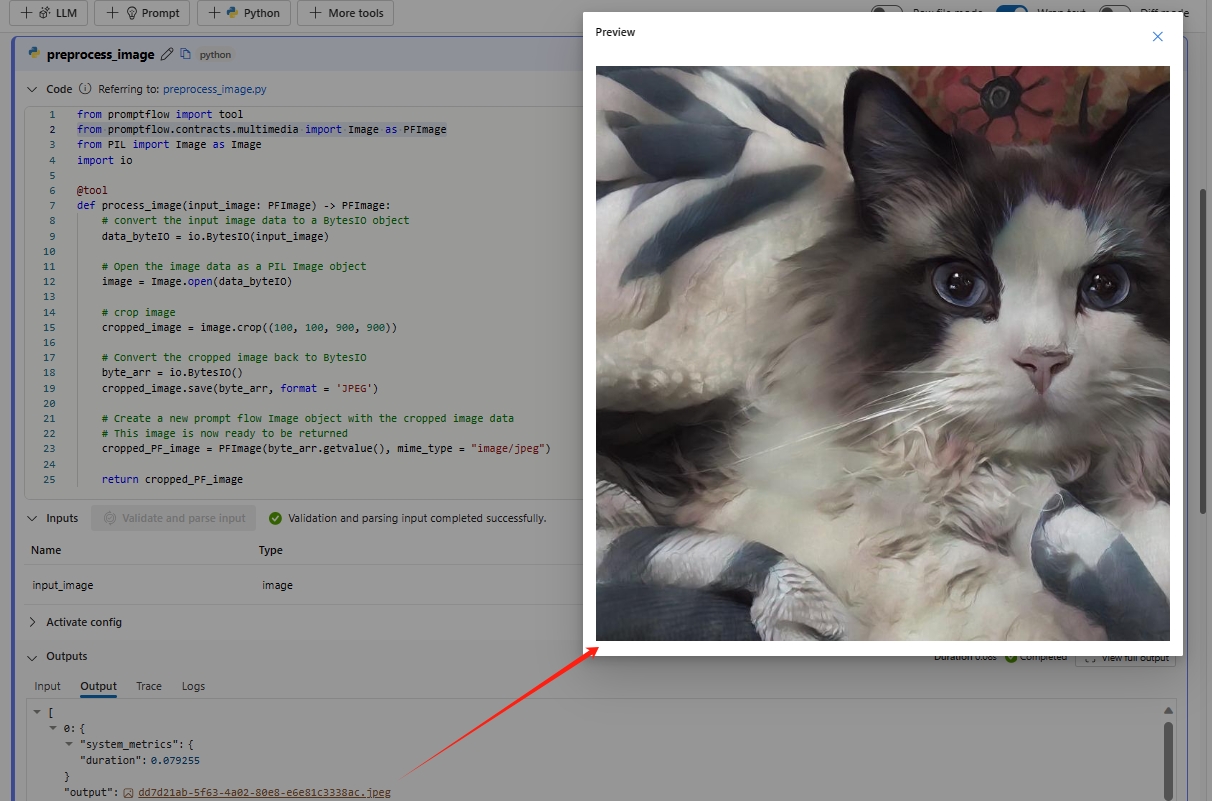
Wenn das Imageobjekt vom Python-Knoten als Flowausgabe festgelegt ist, können Sie auch eine Vorschau des Images auf der Flowausgabeseite anzeigen.




Verwenden des GPT-4V-Tools
Das Tool „Azure OpenAI GPT-4 Turbo with Vision und „OpenAI GPT-4V“ sind integrierte Tools in prompt flow, die das OpenAI GPT-4V-Modell verwenden können, um Fragen basierend auf Eingabebildern zu beantworten. Sie finden das Tool, indem Sie auf der Flowerstellungsseite die Option + Weitere Tools auswählen.
Fügen Sie das Tool „Azure OpenAI GPT-4 Turbo with Vision“ dem Flow hinzu. Stellen Sie sicher, dass Sie über eine Azure OpenAI-Verbindung verfügen und Modelle vom Typ „GPT-4 Vision-preview“ verfügbar sind.

Die Jinja-Vorlage zum Verfassen von Prompts im GPT-4V-Tool folgt einer ähnlichen Struktur wie die Chat-API im LLM-Tool. Um eine Bildeingabe in Ihrem Prompt darzustellen, können Sie die Syntax  verwenden. Bildeingaben können in user-, system- und assistant-Nachrichten übergeben werden.
Nachdem Sie den Prompt verfasst haben, wählen Sie die Schaltfläche Eingabe überprüfen und analysieren aus, um die Eingabeplatzhalter zu analysieren. Die durch  dargestellte Bildeingabe wird als Bildtyp mit dem Eingabenamen INPUT NAME analysiert.
Sie können der Bildeingabe einen Wert auf folgende Weise zuweisen:
- Verweisen aus der Floweingabe des Bildtyps
- Verweisen aus den Bildtypausgaben eines anderen Knotens
- Hochladen, Ziehen und Einfügen eines Bilds oder Angeben einer Bild-URL oder des relativen Bildpfads
Erstellen eines Chatbots zum Verarbeiten von Bildern
In diesem Abschnitt erfahren Sie, wie Sie einen Chatbot erstellen, der Bild- und Texteingaben verarbeiten kann
Angenommen, Sie möchten einen Chatbot erstellen, der Fragen zu Bild und Text zusammen beantworten kann. Sie können dies erreichen, indem Sie die Schritte in diesem Abschnitt befolgen.
Erstellen Sie einen Chatflow.
Wählen Sie in Eingaben den Datentyp als „Liste“aus. Im Chatfeld können Benutzer*innen eine gemischte Abfolge von Texten und Bildern eingeben, und der prompt flow-Dienst wandelt diese in eine Liste um.
Fügen Sie das Tool GPT-4V zum Flow hinzu. Sie können die Prompts aus dem standardmäßigen LLM-Toolchat kopieren und in das GPT 4V-Tool einfügen. Anschließend löschen Sie den standardmäßigen LLM-Toolchat aus dem Flow.
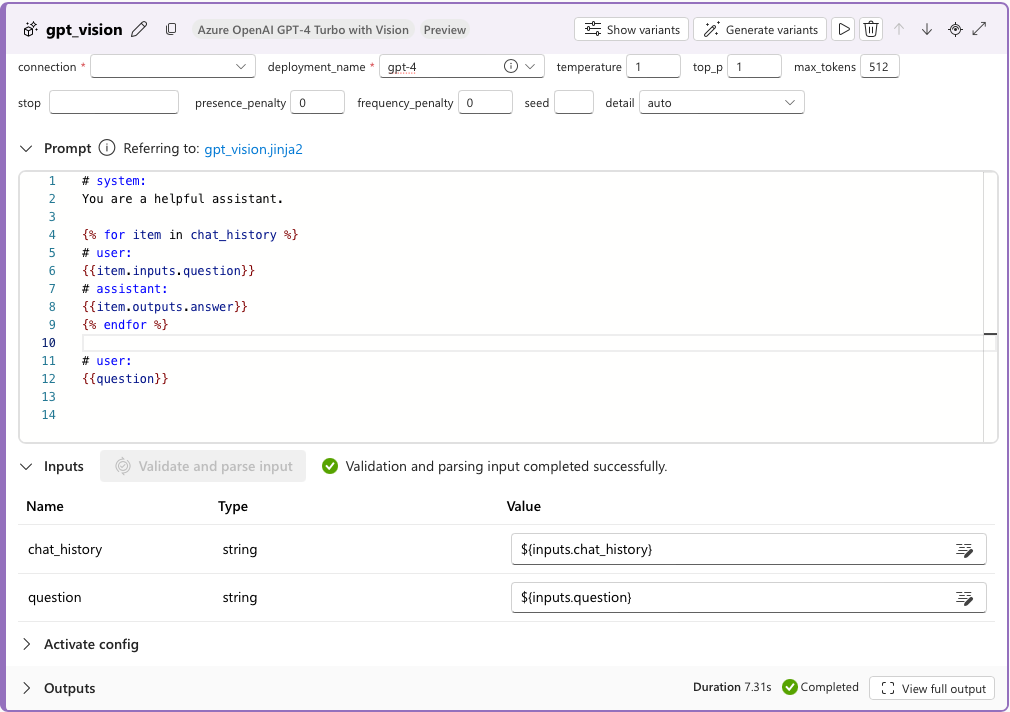
In diesem Beispiel bezieht sich
{{question}}auf die Chateingabe, bei der es sich um eine Liste von Texten und Bildern handelt.Ändern Sie in Ausgaben den Wert der „Antwort“ in den Namen der Ausgabe Ihres Visionstools, z. B.
${gpt_vision.output}.
(Optional) Sie können dem Flow eine beliebige benutzerdefinierte Logik hinzufügen, um die GPT-4V-Ausgabe zu verarbeiten. Sie können beispielsweise das Tool "Guardrails & Controls" hinzufügen, um festzustellen, ob die Antwort unangemessenen Inhalt enthält, und dem Benutzer eine endgültige Antwort zu geben.
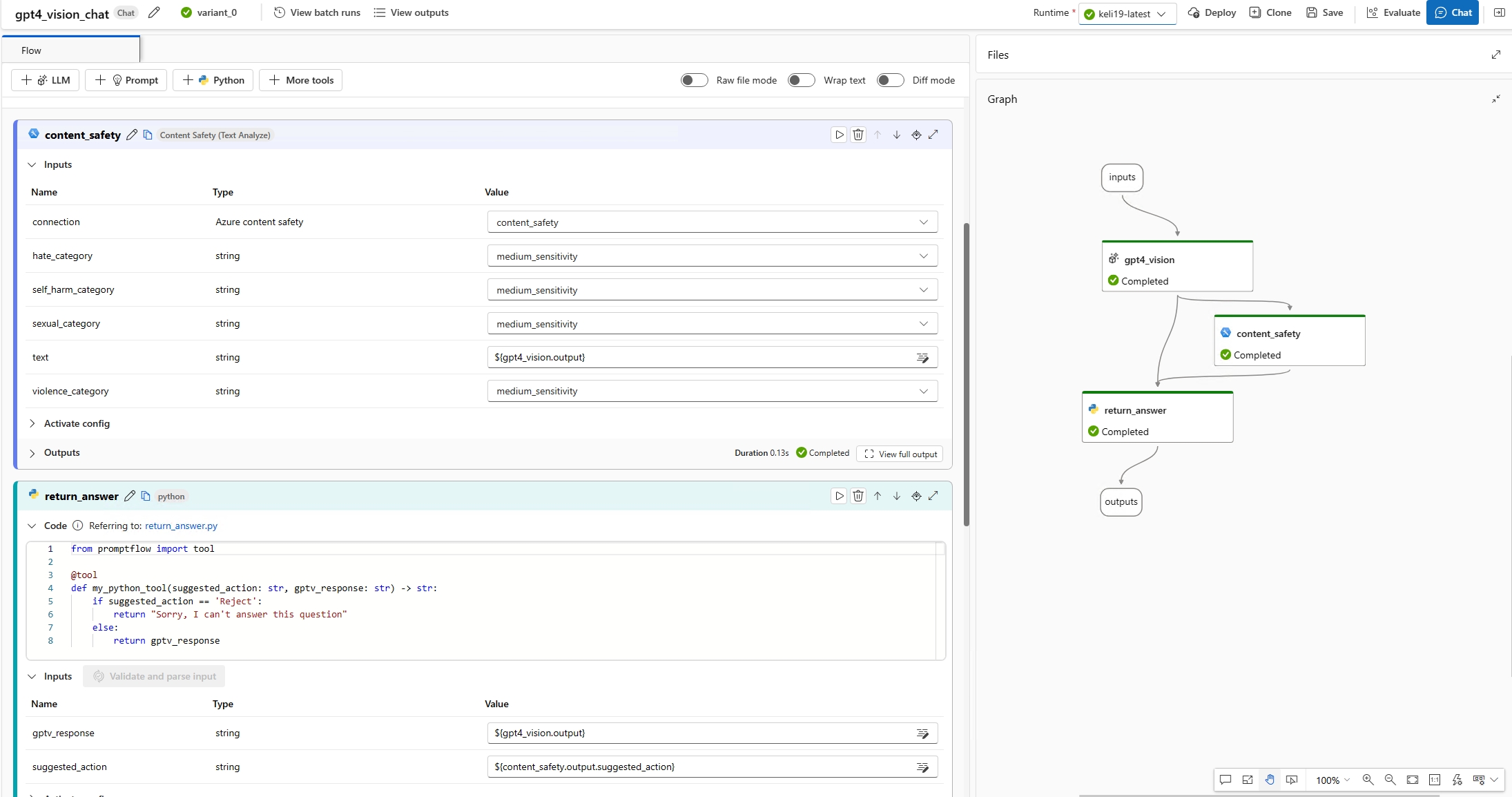
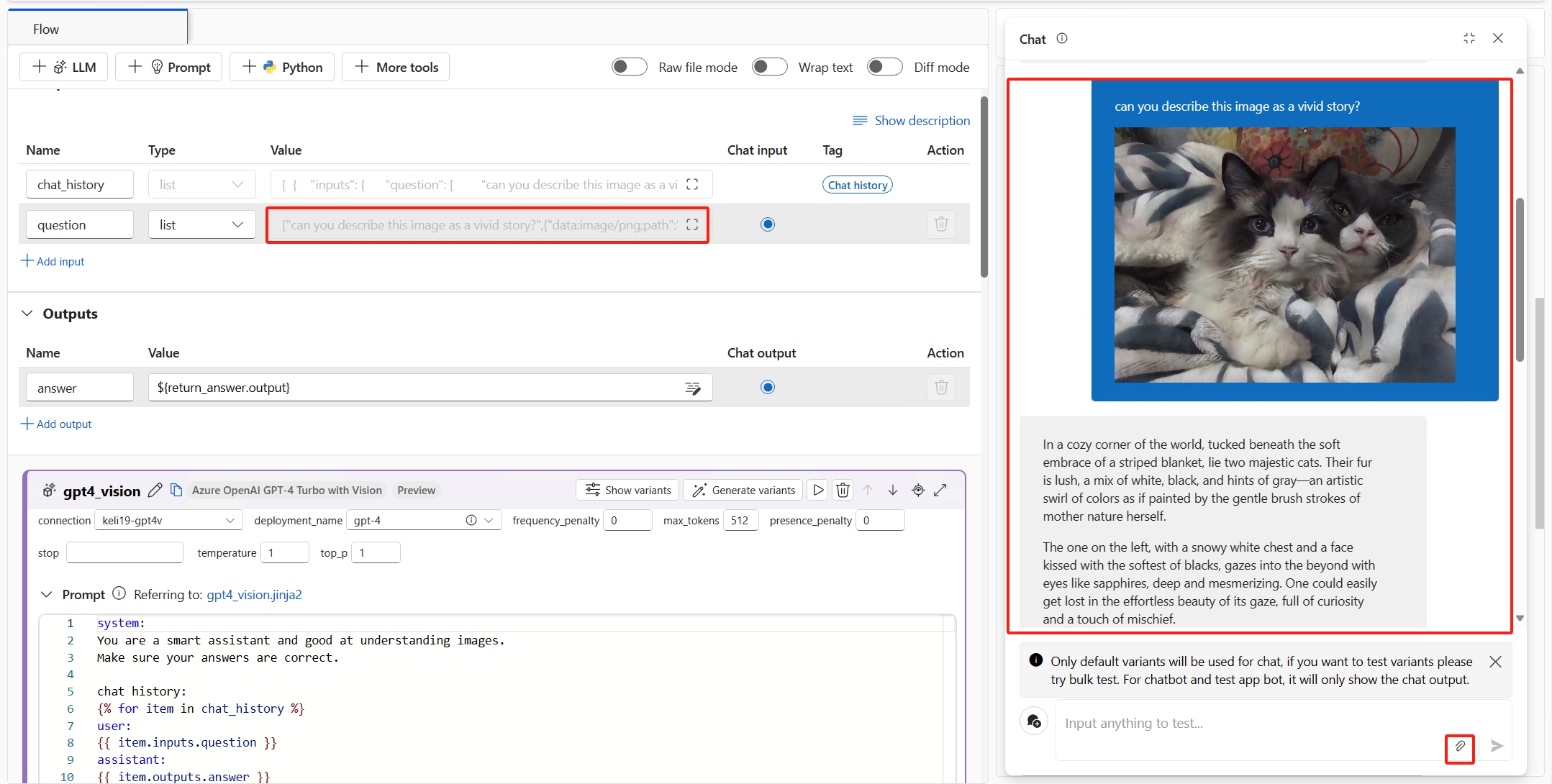
Jetzt können Sie den Chatbot testen. Öffnen Sie das Chatfenster, und geben Sie alle Fragen mit Bildern ein. Der Chatbot beantwortet die Fragen basierend auf Bild- und Texteingaben. Der Chateingabewert wird automatisch mit der Eingabe aus dem Chatfenster abgeglichen. Sie finden die Texte mit Bildern im Chatfeld, das in eine Liste von Texten und Bildern übersetzt wird.





Hinweis
Um es Ihrem Chatbot zu ermöglichen, mit Rich-Text und Bildern zu reagieren, legen Sie die Chatausgabe auf den Typ list fest. Die Liste sollte aus Zeichenfolgen (für Text) und prompt flow-Bildobjekten (für Bilder) in benutzerdefinierter Reihenfolge bestehen.

Erstellen einer Batchausführung mithilfe von Bilddaten
Mit einer Batchausführung können Sie den Flow mit einem umfangreichen Dataset testen. Es gibt drei Methoden zum Darstellen von Bilddaten: über eine Bilddatei, eine öffentliche Bild-URL oder eine Base64-Zeichenfolge.
- Bilddatei: Zum Testen mit Bilddateien in der Batchausführung müssen Sie einen Datenordner vorbereiten. Dieser Ordner muss eine Batchausführungs-Eingabedatei im Format
jsonlenthalten, die sich im Stammverzeichnis befindet, zusammen mit allen Bilddateien, die im selben Ordner oder denselben Unterordnern gespeichert sind.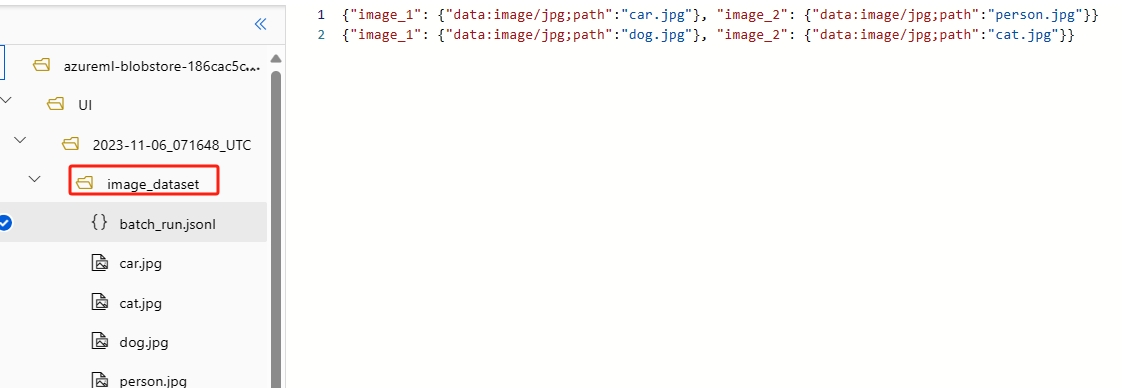 In der Eingabedatei sollten Sie das Format
In der Eingabedatei sollten Sie das Format {"data:<mime type>;path": "<image relative path>"}verwenden, um auf die einzelnen Bilddateien zu verweisen. Beispiel:{"data:image/png;path": "./images/1.png"}. - Öffentliche Bild-URL: Sie können auch mithilfe des folgenden Formats auf die Bild-URL in der Eingabedatei verweisen:
{"data:<mime type>;url": "<image URL>"}. Beispiel:{"data:image/png;url": "https://www.example.com/images/1.png"}. - Base64-Zeichenfolge: Auf eine Base64-Zeichenfolge kann in der Eingabedatei mithilfe des folgenden Formats verwiesen werden:
{"data:<mime type>;base64": "<base64 string>"}. Beispiel:{"data:image/png;base64": "iVBORw0KGgoAAAANSUhEUgAAAGQAAABLAQMAAAC81rD0AAAABGdBTUEAALGPC/xhBQAAACBjSFJNAAB6JgAAgIQAAPoAAACA6AAAdTAAAOpgAAA6mAAAF3CculE8AAAABlBMVEUAAP7////DYP5JAAAAAWJLR0QB/wIt3gAAAAlwSFlzAAALEgAACxIB0t1+/AAAAAd0SU1FB+QIGBcKN7/nP/UAAAASSURBVDjLY2AYBaNgFIwCdAAABBoAAaNglfsAAAAZdEVYdGNvbW1lbnQAQ3JlYXRlZCB3aXRoIEdJTVDnr0DLAAAAJXRFWHRkYXRlOmNyZWF0ZQAyMDIwLTA4LTI0VDIzOjEwOjU1KzAzOjAwkHdeuQAAACV0RVh0ZGF0ZTptb2RpZnkAMjAyMC0wOC0yNFQyMzoxMDo1NSswMzowMOEq5gUAAAAASUVORK5CYII="}.

Zusammenfassend lässt sich sagen, dass prompt flow ein eindeutiges Wörterbuchformat verwendet, um ein Bild darzustellen: {"data:<mime type>;<representation>": "<value>"}. Hier bezieht sich <mime type> auf MIME-Imagetypen des HTML-Standards, und <representation> bezieht sich auf die unterstützten Imagedarstellungen: path, url und base64.
Erstellen einer Batchausführung
Wählen Sie auf der Flowerstellungsseite Auswerten > Benutzerdefinierte Auswertung aus, um eine Batchausführung zu initiieren. Wählen Sie in den Batchausführungseinstellungen ein Dataset aus, das entweder ein Ordner (mit der Eingabedatei und Bilddateien) oder eine Datei (die nur die Eingabedatei enthält) sein kann. Sie können eine Vorschau der Eingabedatei anzeigen und eine Eingabezuordnung durchführen, um die Spalten in der Eingabedatei auf die Floweingaben abzustimmen.

Anzeigen von Batchausführungsergebnissen
Sie können die Ausgaben der Batchausführung auf der Seite mit den Ausführungsdetails überprüfen. Wählen Sie das Bildobjekt in der Ausgabetabelle aus, um auf einfache Weise eine Vorschau des Bilds anzuzeigen.

Wenn die Batchausführungsausgaben Bilder enthalten, können Sie das flow_outputs-Dataset mit der JSON-Ausgabedatei und den Ausgabebildern überprüfen.

Nutzen eines Onlineendpunkts mit Bilddaten
Sie können einen Flow für einen Onlineendpunkt für Rückschlüsse in Echtzeit bereitstellen.
Derzeit unterstützt die Registerkarte Test auf der Detailseite der Bereitstellung keine Bildeingaben oder -ausgaben.
Vorerst können Sie den Endpunkt testen, indem Sie eine Anforderung senden, die Bildeingaben enthält.
Um den Onlineendpunkt mit Bildeingabe zu nutzen, sollten Sie das Bild mithilfe des Formats {"data:<mime type>;<representation>": "<value>"} darstellen. In diesem Fall kann <representation> entweder url oder base64 sein.
Wenn der Flow eine Bildausgabe generiert, wird sie im Format base64 zurückgegeben, z. B. {"data:<mime type>;base64": "<base64 string>"}.