Dokumentverarbeitungsmodelle
Wichtig
- Public Preview-Releases von Dokument Intelligenz bieten frühzeitigen Zugriff auf Features, die sich in der aktiven Entwicklung befinden. Features, Ansätze und Prozesse können sich aufgrund von Benutzerfeedback vor der allgemeinen Verfügbarkeit (General Availability, GA) ändern.
- Die Public Preview von Dokument Intelligenz-Clientbibliotheken verwendet standardmäßig Version 2024-07-31-preview der REST-API.
- Die Public Preview 2024-07-31-preview ist derzeit lediglich in den folgenden Azure-Regionen verfügbar. Beachten Sie, dass das benutzerdefinierte generative Modell (Dokumentfeldextraktion) in KI Studio nur in der Region „USA, Norden-Mitte“ verfügbar ist:
- USA, Osten
- USA, Westen 2
- Europa, Westen
- USA Nord Mitte
Dieser Inhalt gilt für: ![]() Version 4.0 (Vorschau) | Vorherige Versionen:
Version 4.0 (Vorschau) | Vorherige Versionen: ![]() Version 3.1 (GA)
Version 3.1 (GA) ![]() Version 3.0 (GA)
Version 3.0 (GA) ![]() Version 2.1 (GA)
Version 2.1 (GA)
Dieser Inhalt gilt für: ![]() Version 3.1 (GA) | Aktuelle Version:
Version 3.1 (GA) | Aktuelle Version: ![]() Version 4.0 (Vorschau) | Vorherige Versionen:
Version 4.0 (Vorschau) | Vorherige Versionen: ![]() Version 3.0
Version 3.0 ![]() Version 2.1
Version 2.1
Dieser Inhalt gilt für: ![]() Version 3.0 (GA) | Aktuelle Versionen:
Version 3.0 (GA) | Aktuelle Versionen: ![]() Version 4.0 (Vorschau)
Version 4.0 (Vorschau) ![]() Version 3.1 | Vorherige Version:
Version 3.1 | Vorherige Version: ![]() Version 2.1
Version 2.1
Dieser Inhalt gilt für: ![]() Version 2.1 | Neueste Version:
Version 2.1 | Neueste Version: ![]() Version 4.0 (Vorschau)
Version 4.0 (Vorschau)
Azure KI Dokument Intelligenz unterstützt eine Vielzahl von Modellen, mit denen Sie Ihren Apps und Flows intelligente Dokumentverarbeitung hinzufügen können. Sie können ein vordefiniertes domänenspezifisches Modell oder ein benutzerdefiniertes Modell trainieren, das auf Ihre spezifischen Geschäftsanforderungen und Anwendungsfälle zugeschnitten ist. Dokument Intelligenz kann mit der REST-API oder Python-, C#-, Java- und JavaScript-Clientbibliotheken verwendet werden.
Hinweis
- Dokumentverarbeitungsprojekte, die Finanzdaten, geschützte Gesundheitsdaten, persönliche oder hochsensible Daten umfassen, erfordern besondere Umsicht.
- Stellen Sie sicher, dass alle nationalen, regionalen und branchenspezifischen Anforderungen erfüllt werden.
Übersicht über das Modell
In der folgenden Tabelle sind die verfügbaren Modelle für jede aktuelle Vorschau- und stabile API aufgeführt:
| Modelltyp | Modell | • 2024-02-29-preview • 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Dokumentanalysemodelle | Lesen | ✔️ | ✔️ | ✔️ | – |
| Dokumentanalysemodelle | Layout | ✔️ | ✔️ | ✔️ | ✔️ |
| Dokumentanalysemodelle | Allgemeines Dokument | in das Layout verschoben** | ✔️ | ✔️ | – |
| Vordefinierte Modelle | Bankscheck | ✔️ | – | n/v | – |
| Vordefinierte Modelle | Kontoauszug | ✔️ | – | n/v | – |
| Vordefinierte Modelle | Lohnabrechnung | ✔️ | – | n/v | – |
| Vordefinierte Modelle | Vertrag | ✔️ | ✔️ | – | – |
| Vordefinierte Modelle | Krankenversicherungskarte | ✔️ | ✔️ | ✔️ | – |
| Vordefinierte Modelle | ID-Dokument | ✔️ | ✔️ | ✔️ | ✔️ |
| Vordefinierte Modelle | Rechnung | ✔️ | ✔️ | ✔️ | ✔️ |
| Vordefinierte Modelle | Rechnung | ✔️ | ✔️ | ✔️ | ✔️ |
| Vordefinierte Modelle | US Unified Tax* | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US 1040 Tax* | ✔️ | ✔️ | – | – |
| Vordefinierte Modelle | US 1098 Tax* | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US 1099 Tax* | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US W2 Tax | ✔️ | ✔️ | ✔️ | – |
| Vordefinierte Modelle | US-Hypothek 1003 URLA | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US Mortgage 1004 URAR | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US Mortgage 1005 | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US Mortgage 1008 Zusammenfassung | ✔️ | – | n/v | – |
| Vordefinierte Modelle | US-Hypothekenabschluss-Offenlegung | ✔️ | – | n/v | – |
| Vordefinierte Modelle | Heiratsurkunde | ✔️ | – | n/v | – |
| Vordefinierte Modelle | Kreditkarte | ✔️ | – | n/v | – |
| Vordefinierte Modelle | Visitenkarte | deprecated | ✔️ | ✔️ | ✔️ |
| Benutzerdefiniertes Klassifizierungsmodell | Benutzerdefinierter Klassifizierer | ✔️ | ✔️ | – | Nicht zutreffend |
| Benutzerdefiniertes generatives Modell | Benutzerdefiniertes generatives Modell | ✔️ | – | n/v | Nicht zutreffend |
| Benutzerdefiniertes Extraktionsmodell | Benutzerdefiniertes neuronales Modell | ✔️ | ✔️ | ✔️ | Nicht zutreffend |
| Customextraction-Modell | Benutzerdefinierte Vorlage | ✔️ | ✔️ | ✔️ | ✔️ |
| Benutzerdefiniertes Extraktionsmodell | Benutzerdefiniert zusammengesetzt | ✔️ | ✔️ | ✔️ | ✔️ |
| Alle Modelle | Add-On-Funktionen | ✔️ | ✔️ | – | Nicht zutreffend |
* – Enthält Untermodelle. Informationen zu unterstützten Variationen und Untertypen finden Sie in den modellspezifischen Informationen.
Latency
Latenz ist die Zeit, die ein API-Server benötigt, um eine eingehende Anforderung zu behandeln und zu verarbeiten und die ausgehende Antwort an den Client zu senden. Die Dauer einer Dokumentanalyse hängt von der Größe (z. B. Anzahl von Seiten) und vom Inhalt der einzelnen Seiten ab. Dokument Intelligenz ist ein mehrinstanzenfähiger Dienst, bei dem die Latenz für ähnliche Dokumente vergleichbar, aber nicht immer identisch ist. Gelegentliche Variabilität bei Latenz und Leistung ist in jedem auf Microservices basierenden, zustandslosen, asynchronen Dienst, der Bilder und große Dokumente im großen Stil verarbeitet, inhärent. Obwohl wir die Hardware-, Kapazitäts- und Skalierungsfunktionen kontinuierlich hochskalieren, können zur Laufzeit weiterhin Latenzprobleme auftreten.
| Add-On-Funktion | Add-On/Free | • 2024-02-29-preview &bullet [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-v4.0%20(2024-07-31-preview)&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Extraktion von Schrifteigenschaften | Add-On | ✔️ | ✔️ | – | – |
| Formelextraktion | Add-On | ✔️ | ✔️ | – | – |
| Hochauflösende Extraktion | Add-On | ✔️ | ✔️ | – | – |
| Barcodeextraktion | Kostenlos | ✔️ | ✔️ | – | – |
| Sprachenerkennung | Kostenlos | ✔️ | ✔️ | – | – |
| Schlüssel-Wert-Paare | Kostenlos | ✔️ | – | n/v | – |
| Abfragefelder | Add-On* | ✔️ | – | n/v | Nicht zutreffend |
| Durchsuchbare PDF | Add-On* | ✔️ | – | n/v | Nicht zutreffend |
Funktionen der Modellanalyse
| Modell-ID | Inhaltsextraktion | Abfragefelder | Absätze | Absatzrollen | Auswahlmarkierungen | Tabellen | Schlüssel-Wert-Paare | Sprachen | Barcodes | Dokumentanalyse | Formeln* | Schriftstil* | Hohe Auflösung* | Durchsuchbare PDF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | O | O | O | O | O | ✓ | |||||||
| prebuilt-layout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |||
| prebuilt-document | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| prebuilt-businessCard | ✓ | ✓ | ✓ | |||||||||||
| prebuilt-contract | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| Vordefinierte Rechnung | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| prebuilt-receipt | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-bankStatement | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1004 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1005 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099(Varianten) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1040(variations) | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ – Aktiviert
O – Optional
* – Durch Premium-Features entstehen zusätzliche Kosten
Add-On*: Abfragefelder werden anders berechnet als die anderen Add-On-Features. Weitere Informationen finden Sie unter Preise.
Begrenzungsrahmen- und Polygonkoordinaten
Ein umgebendes Feld (polygon in Version 3.0 und höher) ist ein abstraktes Rechteck, das Textelemente in einem Dokument umschließt und als Referenzpunkt für die Objekterkennung verwendet wird.
Der Begrenzungsrahmen gibt die Position mithilfe einer x- und y-Koordinatenebene an, die als Array von vier numerischen Paaren dargestellt wird. Jedes Paar stellt eine Ecke des Felds in der folgenden Reihenfolge dar: oben links, oben rechts, unten rechts, unten links.
Bildkoordinaten werden in Pixel angegeben. Bei einer PDF-Datei werden die Koordinaten in Zoll angegeben.
Für alle Modelle mit Ausnahme des Visitenkartenmodells unterstützt Dokument Intelligenz jetzt Add-On-Funktionen, um eine komplexere Analyse zu ermöglichen. Diese optionalen Funktionen können je nach Szenario der Dokumentextraktion aktiviert und deaktiviert werden. Für das Release 2023-07-31 (allgemeine Verfügbarkeit) und die spätere API-Version stehen sieben Add-On-Funktionen zur Verfügung:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax modelssearchablePDF(2024-07-31-preview)Only available for Read Model
Sprachunterstützung
Die auf Deep Learning basierenden universellen Modelle von Dokument Intelligenz unterstützen eine Vielzahl von Sprachen und können mehrsprachige Texte aus Ihren Bildern und Dokumenten extrahieren, darunter auch Textzeilen mit gemischten Sprachen. Die Sprachunterstützung variiert je nach Funktionalität des Dokument Intelligenz-Diensts. Eine umfassende Liste finden Sie in den folgenden Artikeln:
- Sprachunterstützung: Dokumentanalysemodelle
- Sprachunterstützung: vorgefertigte Modelle
- Sprachunterstützung: benutzerdefinierte Modelle
Regionale Verfügbarkeit
Dokument Intelligenz ist in vielen der mehr als 60 globalen Azure-Infrastrukturregionen allgemein verfügbar.
Weitere Informationen finden Sie auf unserer Seite Azure-Geografien zur Auswahl der Region, die für Sie und Ihre Kunden am besten geeignet ist.
Modelldetails
In diesem Abschnitt wird die Ausgabe beschrieben, die Sie von jedem Modell erwarten können. Sie können die Ausgabe der meisten Modelle mit Add-On-Features erweitern.
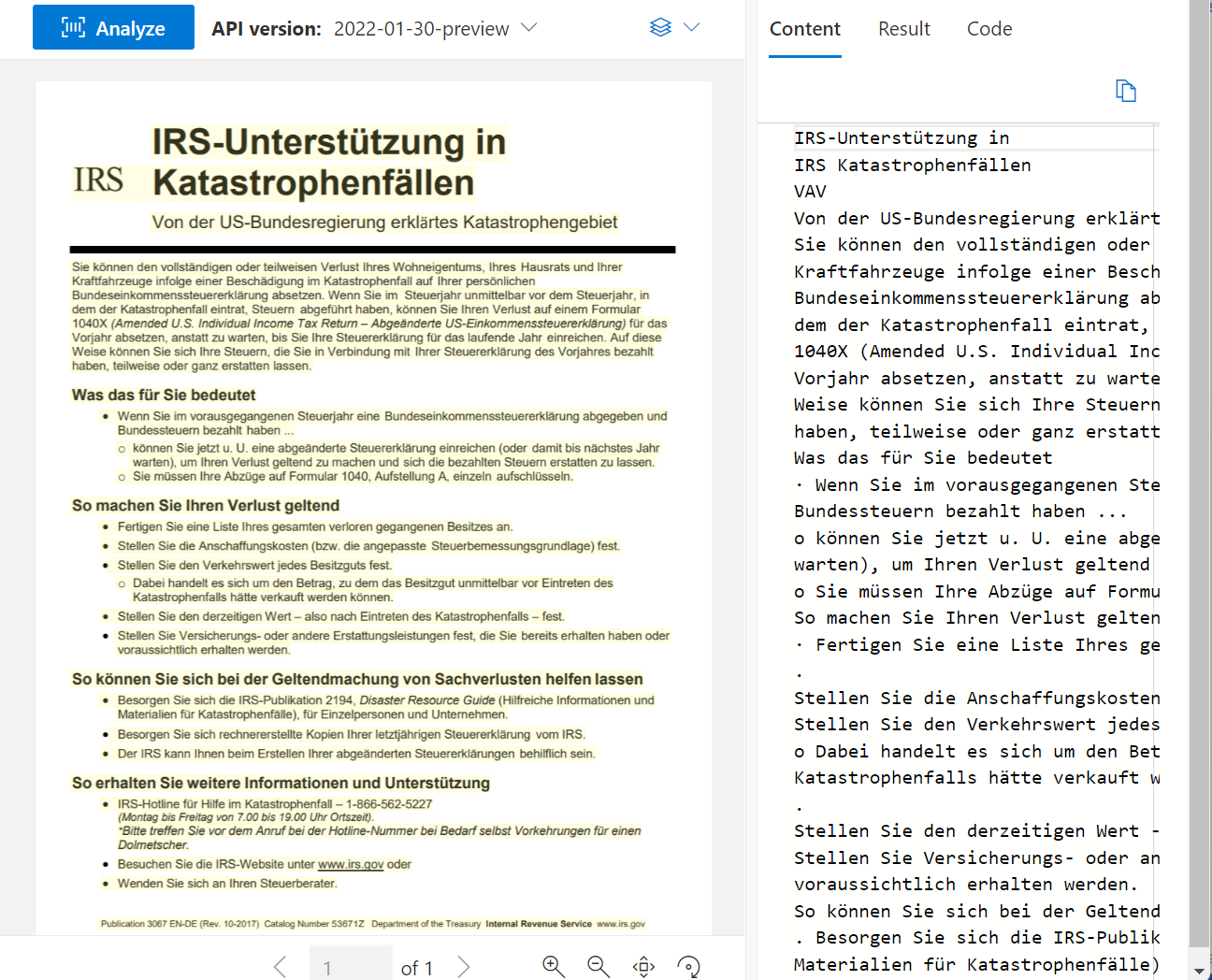
Read OCR

Die Lese-API analysiert und extrahiert Zeilen, Wörter, deren Positionen, erkannte Sprachen und Handschrift, falls erkannt.
Beispieldokument verarbeitet mit Dokument Intelligenz Studio:
Layoutanalyse

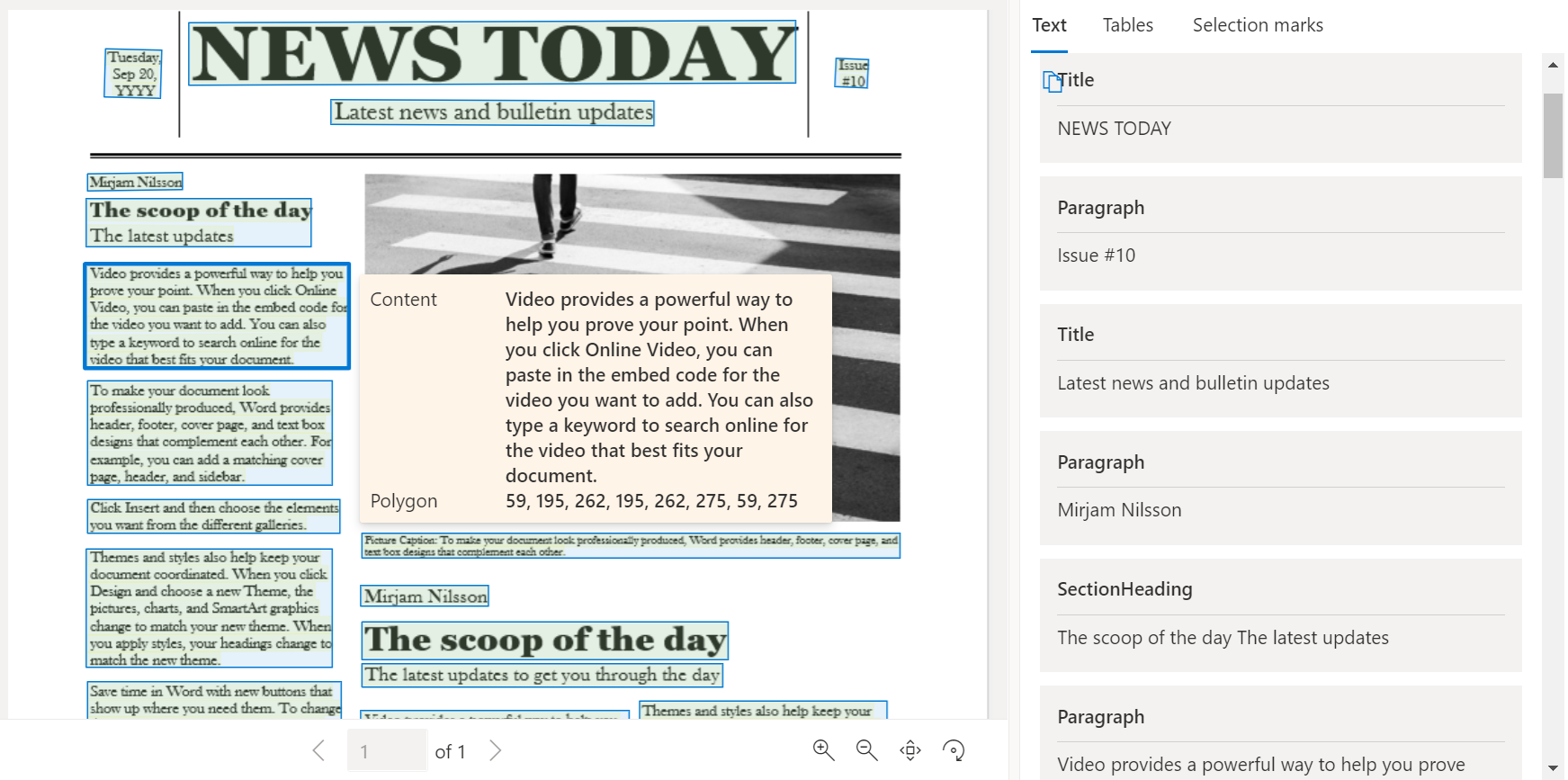
Das Layoutanalysemodell analysiert und extrahiert Text, Tabellen, Auswahlmarkierungen und andere Strukturelemente wie Titel, Abschnittsüberschriften, Seitenkopfzeilen, Seitenfußzeilen und mehr.
Beispieldokument verarbeitet mit Dokument Intelligenz Studio:
Krankenversicherungskarte
![]()
Das Krankenversicherungskartenmodell kombiniert leistungsstarke Funktionen zur optischen Zeichenerkennung (Optical Character Recognition, OCR) mit Deep Learning-Modellen, um wichtige Informationen aus US-Krankenversicherungskarten zu analysieren und zu extrahieren.
Beispiel für eine mit Dokument Intelligenz Studio verarbeitete US-Krankenversicherungskarte:

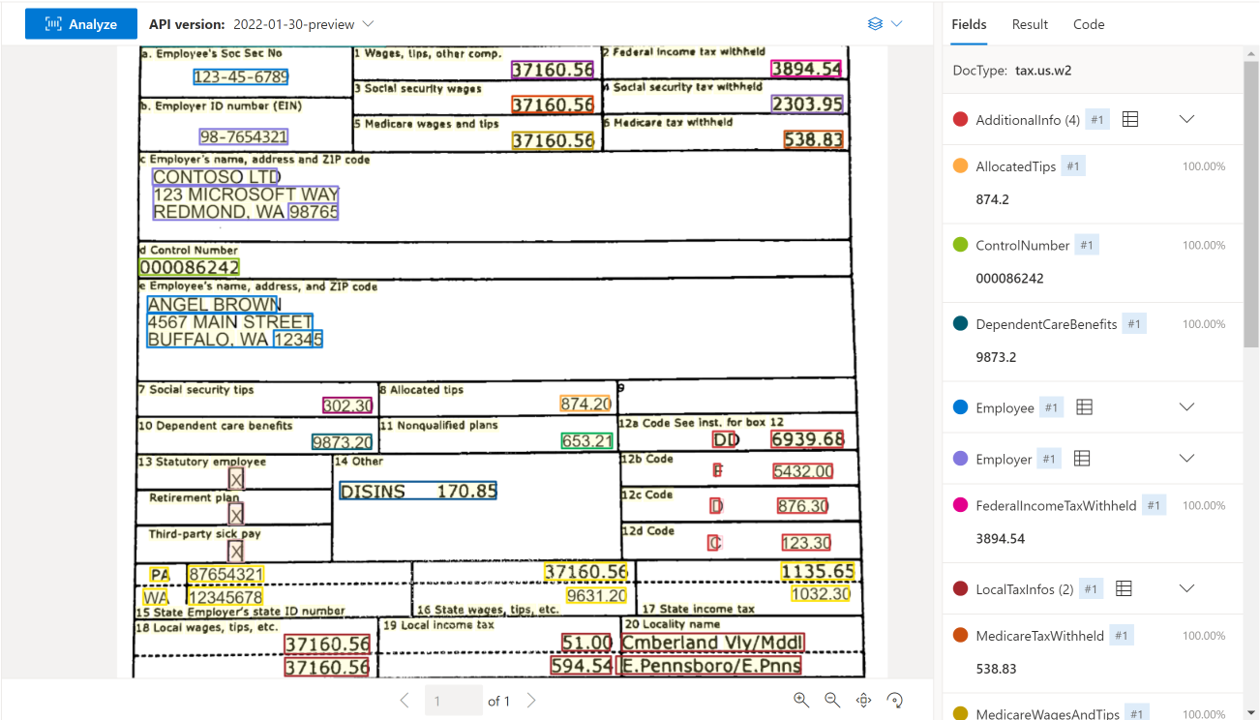
US-Steuerdokumente
Die US-Steuerdokumentmodelle analysieren und extrahieren Schlüsselfelder und Positionen aus einer ausgewählten Gruppe von Steuerdokumenten. Die API unterstützt die Analyse von englischsprachigen US-Steuerdokumenten verschiedener Formate und Qualität, einschließlich per Smartphone erfasster Bilder, gescannter Dokumente und digitaler PDFs. Die folgenden Modelle werden derzeit unterstützt:
| Modell | Beschreibung | ModelID |
|---|---|---|
| US-Steuer W-2 | Extrahieren Sie Details zur steuerpflichtigen Ausgleichszahlung. | prebuilt-tax.us.w2 |
| US Tax 1040 | Extrahieren von Details zu Hypothekenzinsen. | prebuilt-tax.us.1040(variations) |
| US-Steuer 1098 | Extrahieren von Details zu Hypothekenzinsen. | prebuilt-tax.us.1098(variations) |
| US Tax 1099 | Extrahieren von Einnahmen aus anderen Quellen als dem Arbeitgeber. | prebuilt-tax.us.1099 (Varianten) |
W-2-Beispieldokument verarbeitet mit Dokument Intelligenz Studio:
US-Hypothekendokumente

Die Modelle für US-Hypothekendokumente analysieren und extrahieren Schlüsselfelder, einschließlich Darlehens-, Kredit- und Immobilieninformationen aus einer ausgewählten Gruppe von Hypothekendokumenten. Die API unterstützt die Analyse von englischsprachigen US-Hypothekendokumenten verschiedener Formate und Qualität, einschließlich per Smartphone erfasster Bilder, gescannter Dokumente und digitaler PDFs. Die folgenden Modelle werden derzeit unterstützt:
| Modell | Beschreibung | ModelID |
|---|---|---|
| 1003 Microsoft-Software-Lizenzbedingungen (EULA) | Extrahieren von Informationen zu Darlehen, Darlehensnehmer, Immobilien. | prebuilt-mortgage.us.1003 |
| Zusammenfassungsdokument 1008 | Extrahieren von Informationen zu Darlehensnehmer, Verkäufer, Immobilie, Hypotheken und Absicherung. | prebuilt-mortgage.us.1008 |
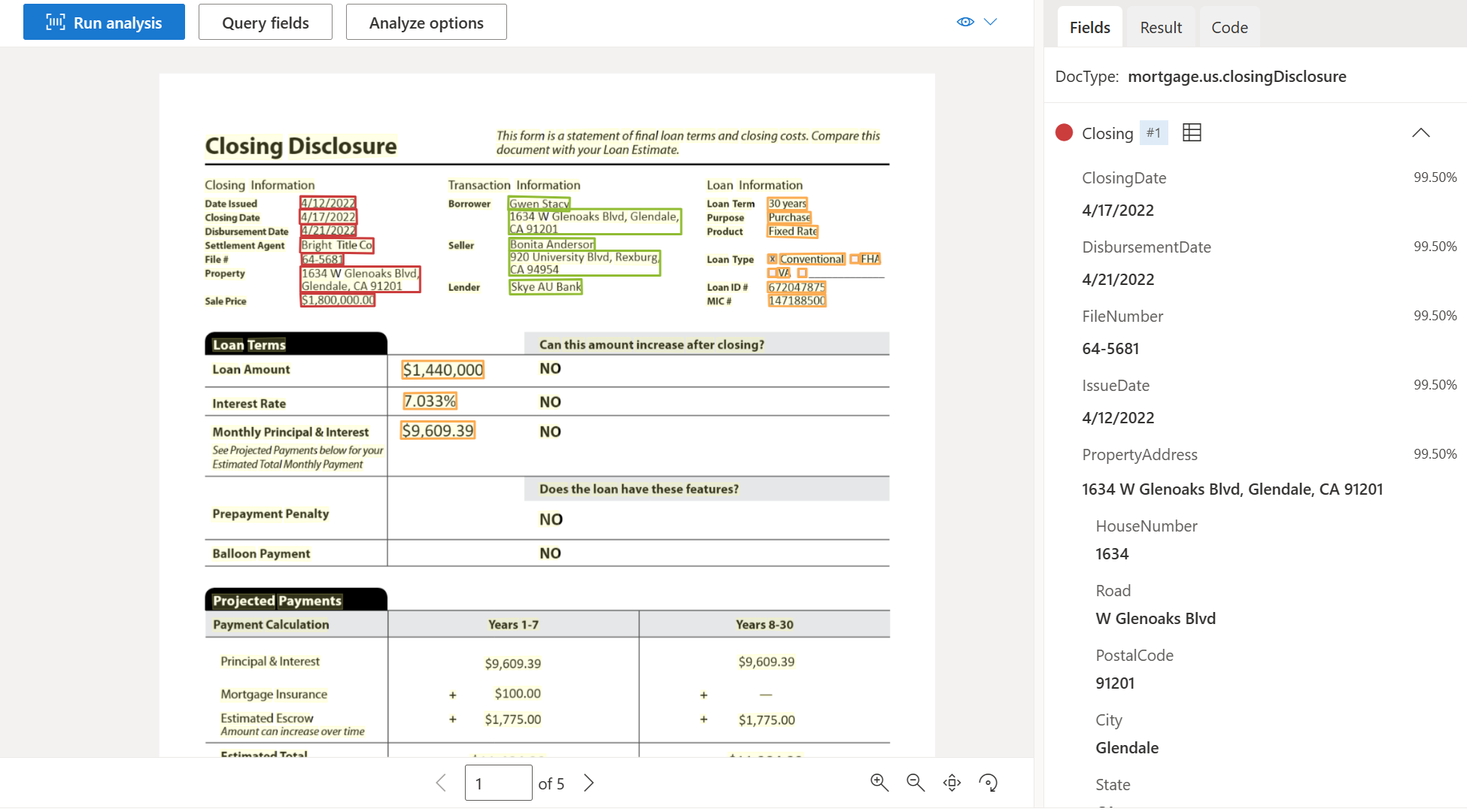
| Offenlegung des Abschlusses | Extrahieren von Informationen zu Abschluss, Transaktionskosten und Kreditdetails. | prebuilt-mortgage.us.closingDisclosure |
| Heiratsurkunde | Extrahieren von Eheinformationen für gemeinschaftliche Kreditantragsteller. | prebuilt-marriageCertificate |
| US-Steuer W-2 | Extrahieren von Details zur steuerpflichtigen Vergütung für die Einkommensprüfung. | prebuilt-tax.us.w2 |
Beispieldokument für die Abschlussoffenlegung, verarbeitet mit Document Intelligence Studio:
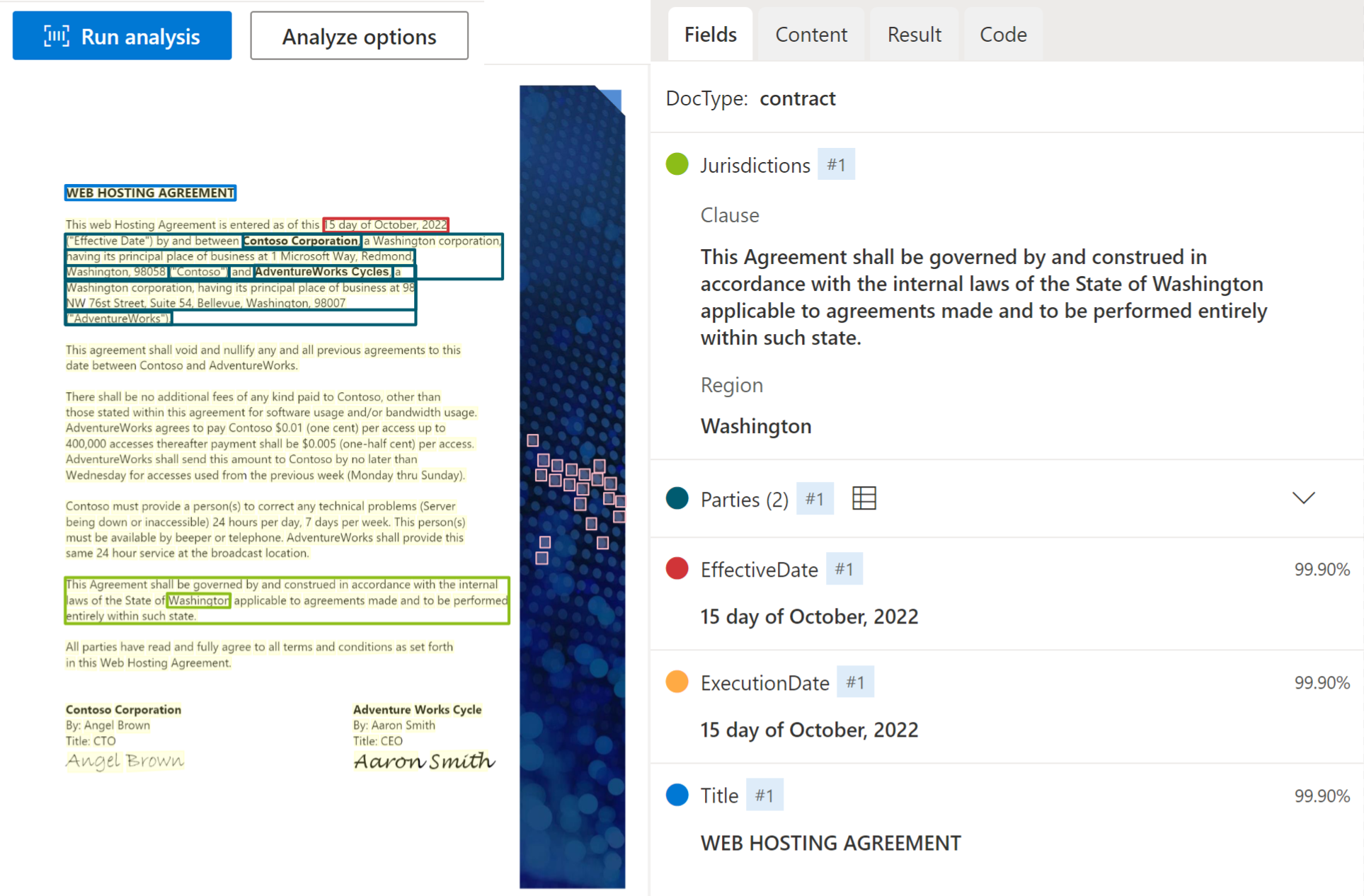
Vertrag
![]()
Das Vertragsmodell analysiert und extrahiert Schlüsselfelder und Zeilenelemente aus Vertragsvereinbarungen, einschließlich Parteien, Gerichtsbarkeiten, Vertrags-IDs und Titeln. Das Modell unterstützt derzeit englischsprachige Vertragsdokumente.
Beispielvertrag verarbeitet mit Dokument Intelligenz Studio:
Rechnung

Das Rechnungsmodell automatisiert die Verarbeitung von Rechnungen, um Kundennamen, Abrechnungsadresse, Fälligkeitsdatum und fälliger Betrag, Rechnungspositionen und andere Schlüsseldaten zu extrahieren. Derzeit unterstützt das Modell englische, spanische, deutsche, französische, italienische, portugiesische und niederländische Rechnungen.
Beispielrechnung verarbeitet mit Dokument Intelligenz Studio:

Rechnung
Verwenden Sie das Belegmodell, um Verkaufsquittungen auf Händlernamen, Datumsangaben, Artikelpositionen, Mengen und Summen aus gedruckten und handschriftlichen Belegen zu scannen. Die Version v3.0 unterstützt auch die Verarbeitung einseitiger Hotelbelege.
Beispielbeleg verarbeitet mit Dokument Intelligenz Studio:

Identitätsdokument (ID)

Mit dem Identitätsdokumentmodell (ID) können Sie US-Führerscheine (alle 50 Bundesstaaten und District of Columbia) und Seiten mit biografischen Angaben aus internationalen Reisepässen (ohne Visa und andere Reisedokumente) verarbeiten, um wichtige Felder zu extrahieren.
US-Beispielfahrerlaubnis verarbeitet mit Dokument Intelligenz Studio:

Heiratsurkunde
![]()
Verwenden Sie das Modell für Heiratsurkunden, um US-Ehezertifikate zu verarbeiten und Schlüsselfelder zu extrahieren, u. a. Personen, Datum und Ort.
Beispiel für US-Heiratsurkunde, verarbeitet mit Document Intelligence Studio:

Kreditkarte
![]()
Verwenden Sie das Kreditkartenmodell, um Kredit- und Debitkarten zum Extrahieren von Schlüsselfeldern zu verarbeiten.
Beispielkreditkarte, verarbeitet mit Document Intelligence Studio:

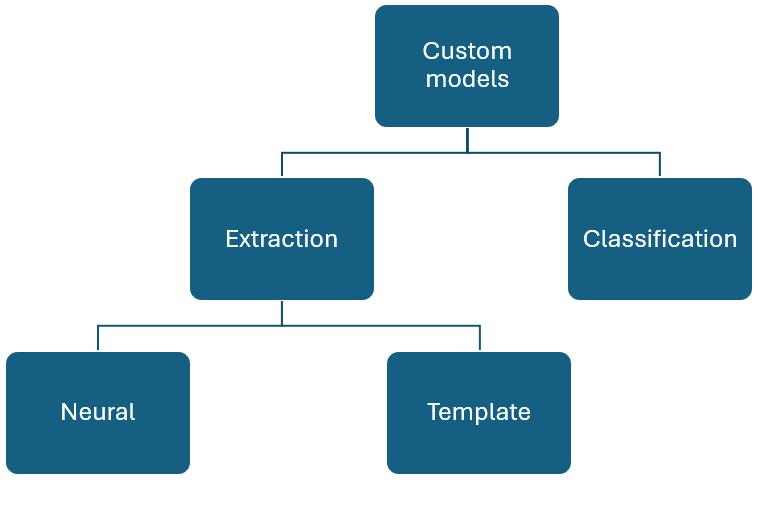
Benutzerdefinierte Modelle

Benutzerdefinierte Modelle können allgemein in zwei Typen unterteilt werden. Benutzerdefinierte Klassifizierungsmodelle, die die Klassifizierung eines „Dokumenttyps“ unterstützen, und benutzerdefinierte Extraktionsmodelle, die ein definiertes Schema aus einem bestimmten Dokumenttyp extrahieren können.
Benutzerdefinierte Dokumentmodelle analysieren und extrahieren Daten aus Formularen und Dokumenten, die für Ihr Unternehmen spezifisch sind. Sie erkennen Formularfelder innerhalb Ihrer unterschiedlichen Inhalte und extrahieren Schlüssel-Wert-Paare sowie Tabellendaten. Für den Anfang benötigen Sie lediglich ein Beispiel des Formulartyps.
Version v3.0 und höher der benutzerdefinierten Modelle unterstützt die Signaturerkennung in benutzerdefinierten Vorlagen (Formularen) sowie seitenübergreifende Tabellen in Vorlagenmodellen und neuronalen Modellen. Die Signaturerkennung sucht nach einer vorhandenen Signatur, nicht nach der Identität der Person, die das Dokument signiert. Wenn das Modell unsigniert für die Signaturerkennung zurückgibt, hat das Modell keine Signatur im definierten Feld gefunden.
Benutzerdefinierte Beispielvorlage verarbeitet mit Dokument Intelligenz Studio:
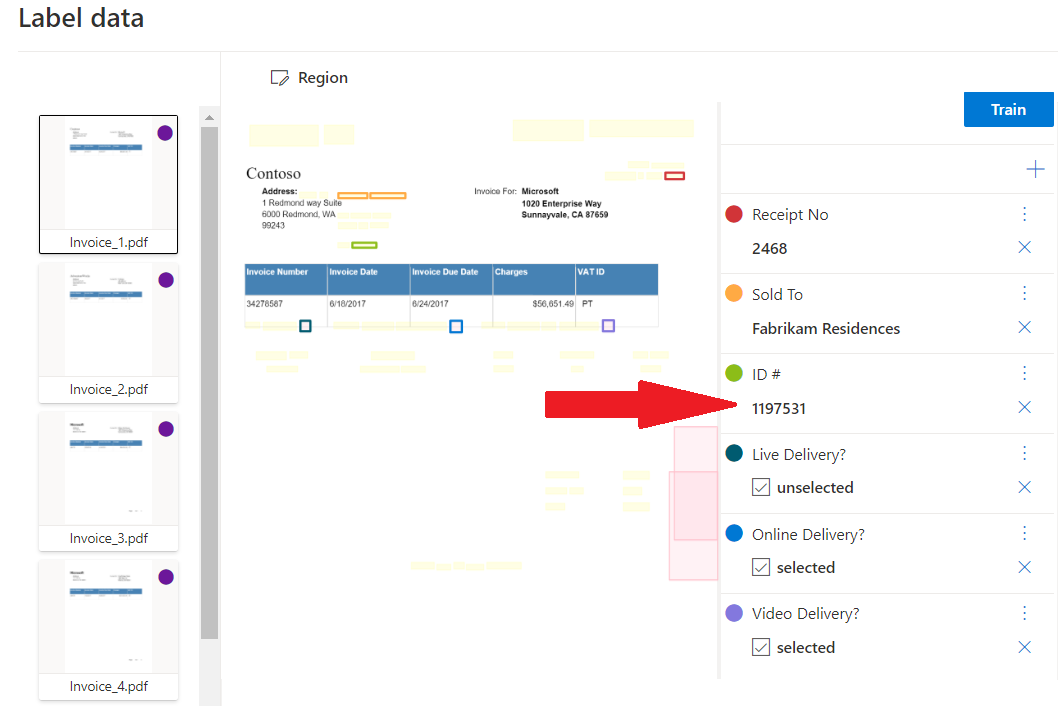
Benutzerdefinierte Extraktion

Es gibt zwei Arten von Extraktionsmodellen: Benutzerdefiniertes Vorlagenmodell oder Benutzerdefiniertes neuronales Modell. Um ein benutzerdefiniertes Extraktionsmodell zu erstellen, beschriften Sie ein Dataset von Dokumenten mit den Werten, die Sie extrahieren möchten, und trainieren das Modell für das beschriftete Dataset. Zunächst benötigen Sie lediglich fünf Beispiele desselben Formular- oder Dokumenttyps.
Benutzerdefinierter Beispielauszug verarbeitet mit Dokument Intelligenz Studio:

Benutzerdefinierter Klassifizierer

Das benutzerdefinierte Klassifizierungsmodell ermöglicht Ihnen, den Dokumenttyp zu identifizieren, bevor Sie das Extraktionsmodell aufrufen. Das Klassifizierungsmodell ist ab der 2023-07-31 (GA) API verfügbar. Zum Trainieren eines benutzerdefinierten Klassifizierungsmodells sind mindestens zwei verschiedene Klassen und mindestens fünf Beispiele pro Klasse erforderlich.
Zusammengesetzte Modelle
Ein zusammengestelltes Modell wird erstellt, indem eine Sammlung benutzerdefinierter Modelle verwendet und zu einem einzigen Modell zusammengesetzt wird, das auf Ihren Formulartypen basiert. In einem zusammengesetzten Modell werden verschiedene benutzerdefinierten Modelle kombiniert und dann mit einer einzigen Modell-ID aufgerufen. Sie können einem einzelnen zusammengestellten Modell bis zu 200 trainierte benutzerdefinierte Modelle zuweisen.
Dialogfeld eines zusammengesetzten Modells in Dokument Intelligenz Studio:
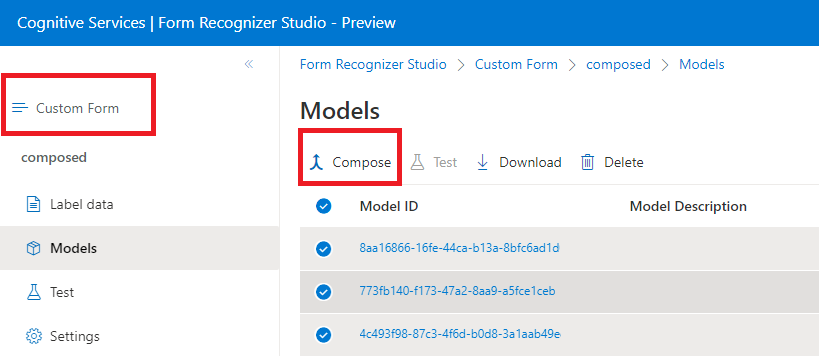
Eingabeanforderungen
Unterstützte Dateiformate:
Modell PDF Abbildung: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-07-31-preview und höher beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Hinweis
Das Tool für die Beschriftung von Beispielen unterstützt nicht das BMP-Dateiformat. Dies ist eine Einschränkung des Tools, nicht des Dokument Intelligenz-Diensts.
Versions-Migration
Informationen zur Verwendung von Dokument Intelligenz 3.0 in Ihren Anwendungen finden Sie im Migrationsleitfaden für Dokument Intelligenz 3.1.
| Modell | Beschreibung |
|---|---|
| Dokumentanalyse | |
| Layout | Extrahiert Text- und Layoutinformationen aus Dokumenten. |
| Vordefiniert | |
| Rechnung | Extrahieren Sie Schlüsselinformationen aus englischen und spanischen Rechnungen. |
| Rechnung | Extrahieren Sie Schlüsselinformationen aus englischen Quittungen. |
| Ausweisdokument | Extrahieren von Schlüsselinformationen aus US-Führerscheinen und internationalen Pässen. |
| Visitenkarte | Extrahieren von Schlüsselinformationen aus englischen Visitenkarten. |
| Benutzerdefiniert | |
| Benutzerdefiniert | Extrahieren Sie Daten aus Formularen und Dokumenten, die für Ihr Unternehmen spezifisch sind. Benutzerdefinierte Modelle werden speziell für Ihre individuellen Daten und Anwendungsfälle trainiert. |
| Zusammengestellt | Erstellt eine Sammlung benutzerdefinierter Modelle und weist sie einem einzelnen Modell zu, das aus Ihren Formulartypen erstellt wurde. |
Layout
Die Layout-API analysiert und extrahiert Text, Tabellen und Kopfzeilen, Auswahlmarkierungen und Strukturinformationen aus Dokumenten.
Mithilfe des Beispielbezeichnungstools bearbeitetes Beispieldokument:
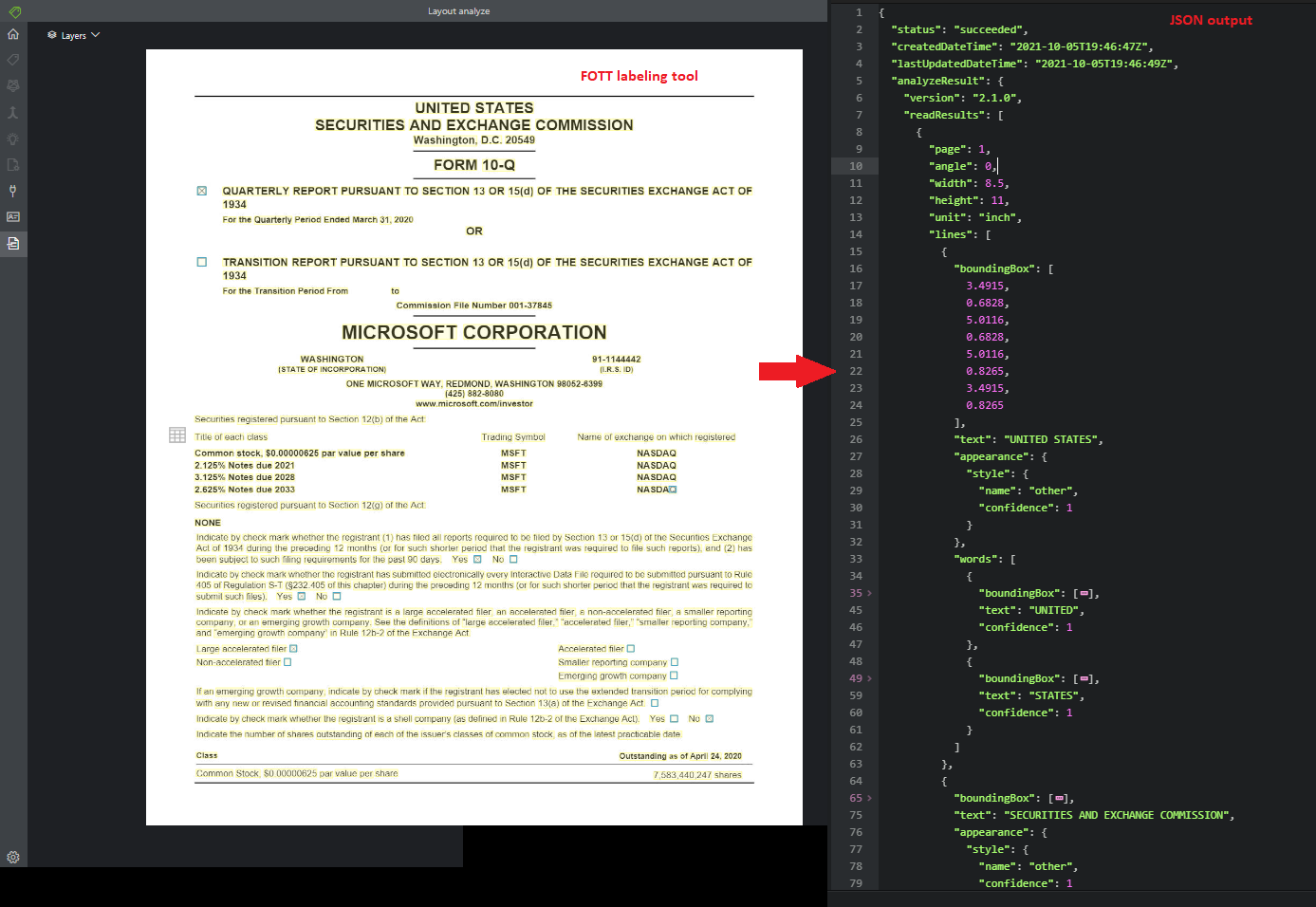
Rechnung
Das Rechnungsmodell analysiert und extrahiert Schlüsselinformationen aus Verkaufsrechnungen. Die API analysiert Rechnungen in verschiedenen Formaten und extrahiert Schlüsselinformationen wie Kundenname, Rechnungsadresse, Fälligkeitsdatum und fälliger Betrag.
Mithilfe des Beispielbezeichnungstools bearbeitete Beispielrechnung:

Rechnung
- Das Belegmodell analysiert und extrahiert Schlüsselinformationen aus gedruckten und handschriftlichen Verkaufsbelegen (Quittungen).
Mit dem Beispielbezeichnungstool bearbeiteter Beispielbeleg:
ID-Dokument
Das ID-Dokumentmodell analysiert und extrahiert wichtige Informationen aus den folgenden Dokumenten:
US-Führerscheine (alle 50 Bundesstaaten und District of Columbia (D. C.))
Seiten mit persönlichen Daten aus internationalen Reisepässen (mit Ausnahme von Visa und anderen Reisedokumenten). Die API analysiert Identitätsdokumente und extrahiert
Beispiel eines mit dem Beispielbezeichnungstool bearbeiteten US-Führerscheins:
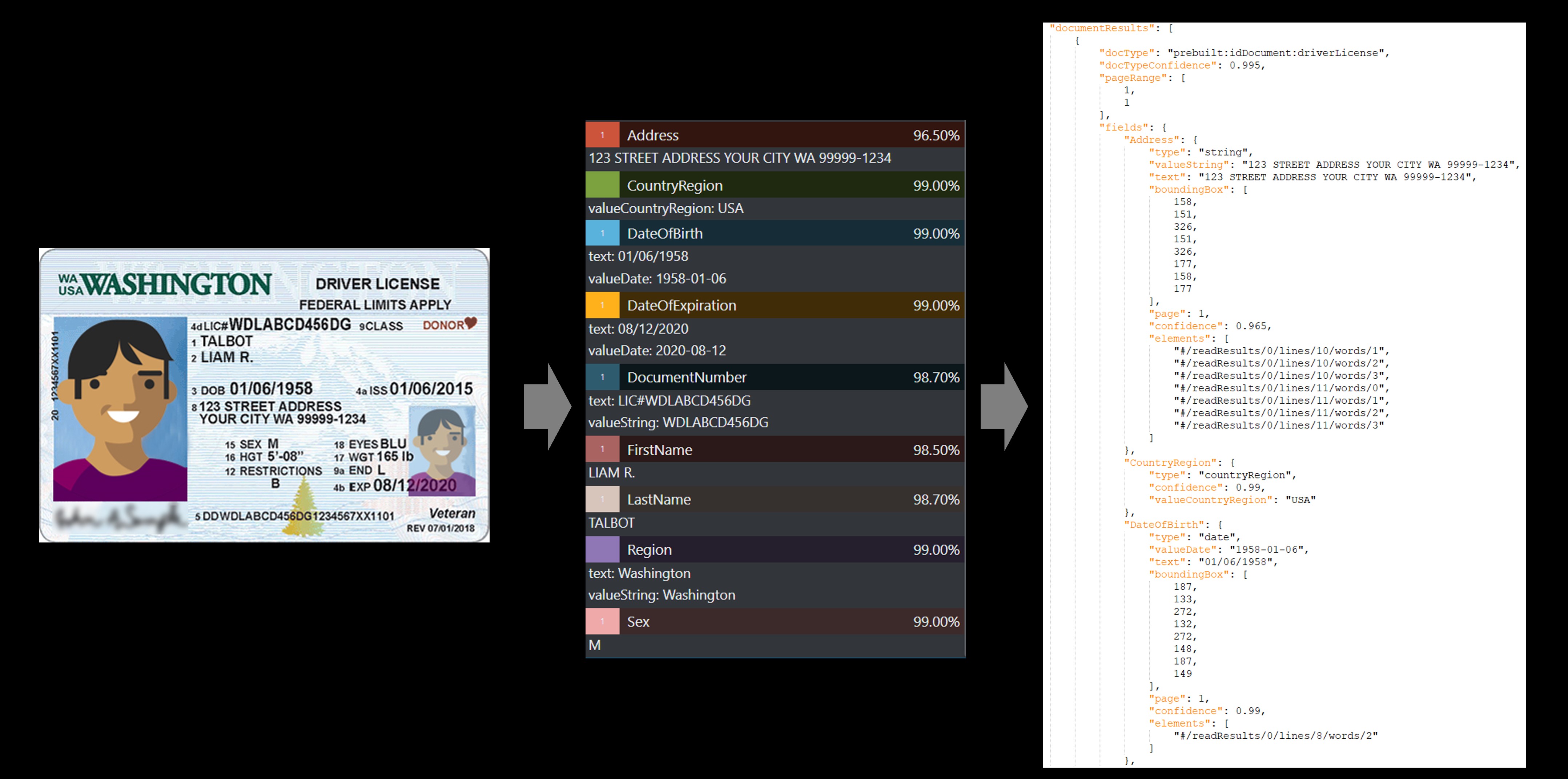
Visitenkarte
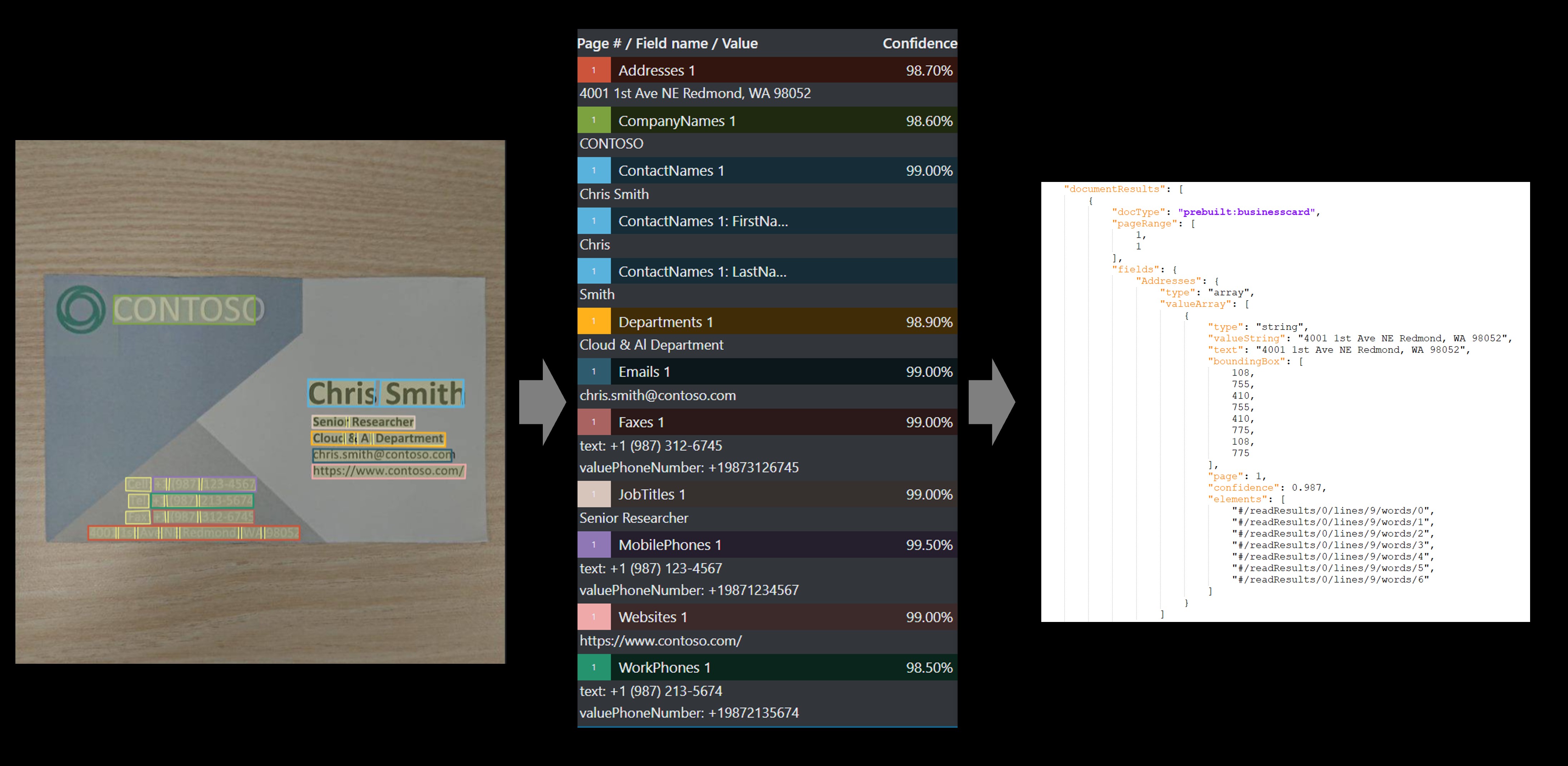
Das Visitenkartenmodell analysiert und extrahiert Schlüsselinformationen aus Visitenkartenbildern.
Beispiel einer mit dem Beispielbezeichnungstool bearbeiteten Visitenkarte:
Benutzerdefiniert
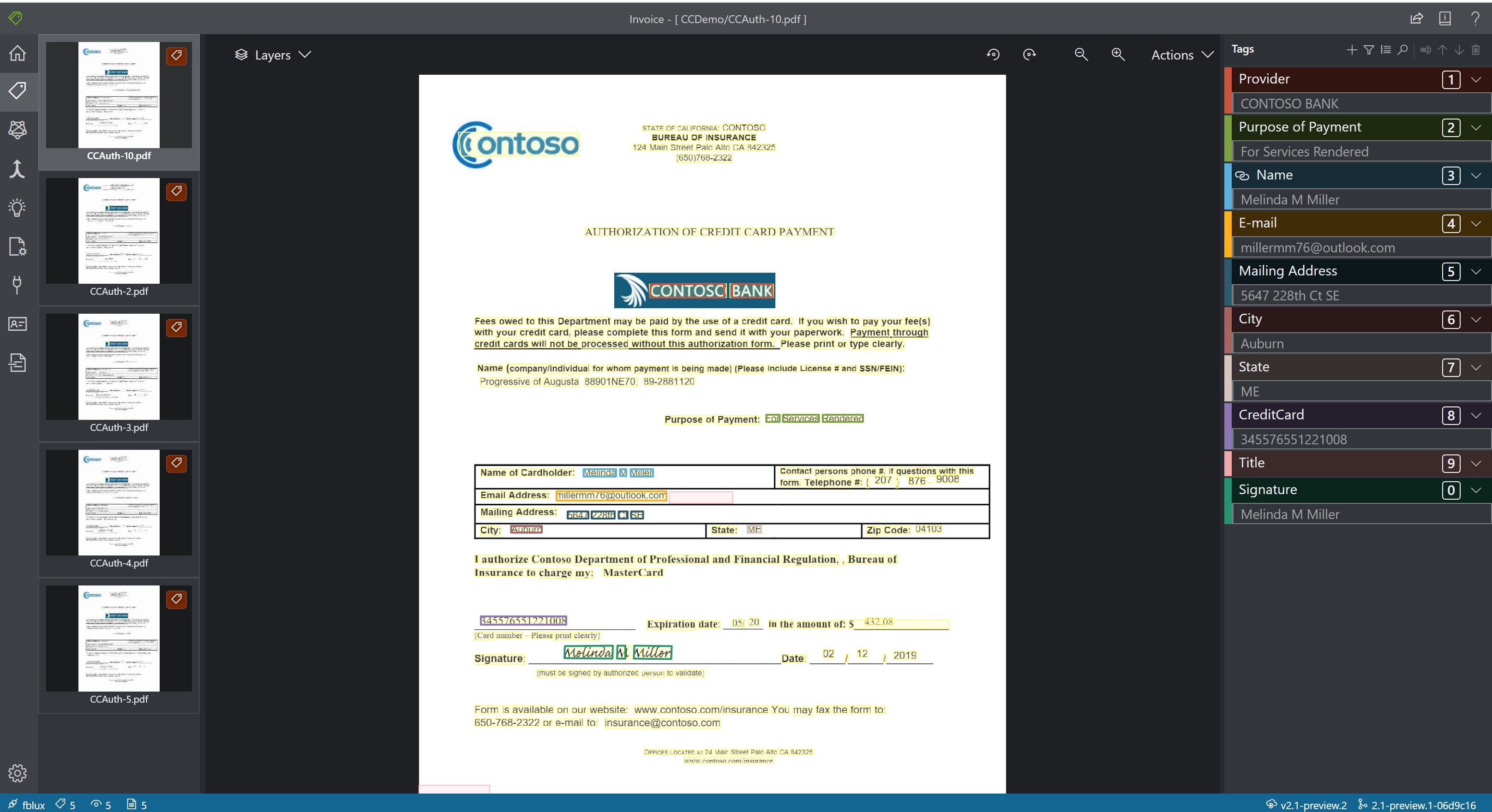
- Benutzerdefinierte Modelle analysieren und extrahieren Daten aus Formularen und Dokumenten, die für Ihr Unternehmen spezifisch sind. Bei der API handelt es sich um ein Machine Learning-Programm, das darauf trainiert ist, Formularfelder innerhalb Ihrer unterschiedlichen Inhalte zu erkennen und Schlüssel-Wert-Paare sowie Tabellendaten zu extrahieren. Für den Einstieg benötigen Sie nur fünf Beispiele desselben Formulartyps, und Ihr benutzerdefiniertes Modell kann mit oder ohne bezeichnete Datasets trainiert werden.
Beispiel eines mit dem Beispielbezeichnungstool bearbeiteten benutzerdefinierten Modells:
Zusammengestelltes benutzerdefiniertes Modell
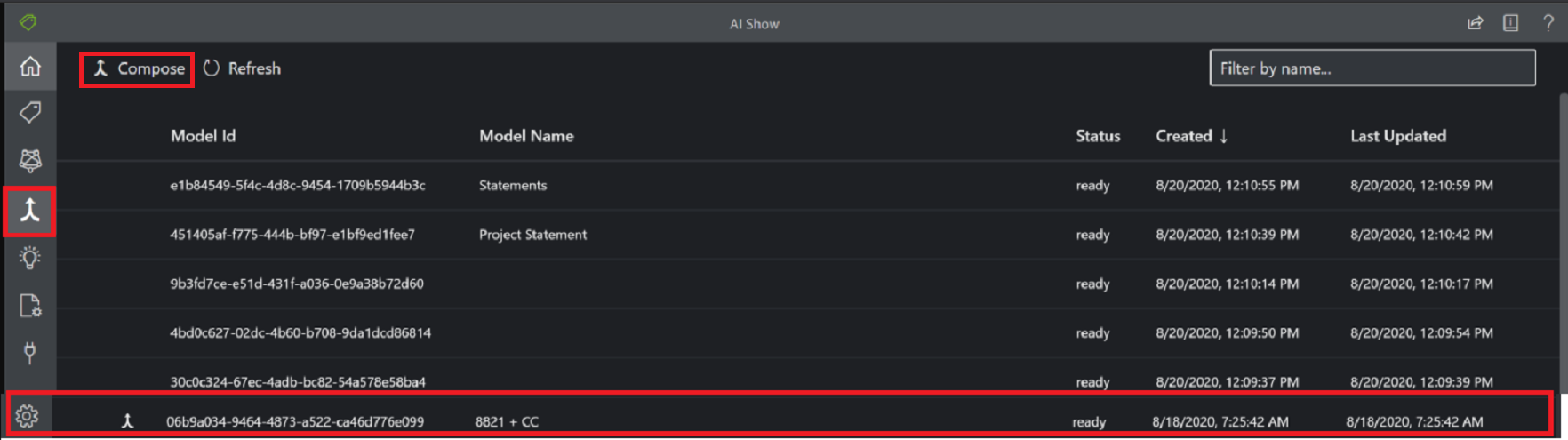
Ein zusammengestelltes Modell wird erstellt, indem eine Sammlung benutzerdefinierter Modelle verwendet und zu einem einzigen Modell zusammengesetzt wird, das auf Ihren Formulartypen basiert. In einem zusammengesetzten Modell werden verschiedene benutzerdefinierten Modelle kombiniert und dann mit einer einzigen Modell-ID aufgerufen. Sie können einem einzelnen zusammengestellten Modell bis zu 100 trainierte benutzerdefinierte Modelle zuweisen.
Dialogfenster eines mit dem Beispielbezeichnungstool zusammengesetzten Modells:
Extrahieren von Modelldaten
| Modell | Textextraktion | Sprachenerkennung | Auswahlmarkierungen | Tabellen | Absätze | Absatzrollen | Schlüssel-Werte-Paare | Fields |
|---|---|---|---|---|---|---|---|---|
| Layout | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Rechnung | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Rechnung | ✓ | ✓ | ✓ | |||||
| Ausweisdokument | ✓ | ✓ | ✓ | |||||
| Visitenkarte | ✓ | ✓ | ✓ | |||||
| Benutzerdefiniertes Formular | ✓ | ✓ | ✓ | ✓ | ✓ |
Eingabeanforderungen
Unterstützte Dateiformate:
Modell PDF Abbildung: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-07-31-preview und höher beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Hinweis
Das Tool für die Beschriftung von Beispielen unterstützt nicht das BMP-Dateiformat. Dies ist eine Einschränkung des Tools, nicht des Dokument Intelligenz-Diensts.
Versions-Migration
Weitere Informationen zur Verwendung von Dokument Intelligenz 3.0 in Ihren Anwendungen finden Sie im Migrationsleitfaden für Dokument Intelligenz 3.1.
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe des Dokument Intelligenz-Stichproben-Bezeichnungstools zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.