Retrieval-Augmented Generation (RAG) mit Azure KI Dokument Intelligenz
Dieser Inhalt gilt für:![]() Version 4.0 (Vorschau)
Version 4.0 (Vorschau)
Einführung
Retrieval-Augmented Generation (RAG) ist ein Entwurfsmuster, das ein vortrainiertes großes Sprachmodell (Large Language Model, LLM) wie ChatGPT mit einem externen Datenabrufsystem kombiniert, um erweiterte Antworten zu generieren, die neue Daten außerhalb der ursprünglichen Trainingsdaten enthalten. Durch das Hinzufügen eines Informationsempfangssystems zu Ihren Anwendungen können Sie mit Ihren Dokumenten chatten, Inhalte generieren und die Leistungsfähigkeit von Azure OpenAI-Modellen für Ihre Daten nutzen. Außerdem haben Sie mehr Kontrolle über die vom LLM verwendeten Daten, da es eine Antwort formuliert.
Das Layoutmodell von Dokument Intelligenz ist eine auf erweitertem maschinellem Lernen basierende Dokumentlayoutanalyse-API. Das Layoutmodell bietet eine umfassende Lösung für erweiterte Extraktion von Inhalten und Analyse der Dokumentenstruktur. Mit dem Layoutmodell können Sie Text- und Strukturelemente einfach extrahieren, um große Textmengen in kleinere, aussagekräftige Abschnitte zu unterteilen, die auf dem semantischen Inhalt und nicht auf willkürlichen Unterteilungen basieren. Die extrahierten Informationen können bequem im Markdown-Format ausgegeben werden, sodass Sie Ihre Strategie für die Bildung semantischer Blöcke auf der Grundlage der bereitgestellten Bausteine definieren können.
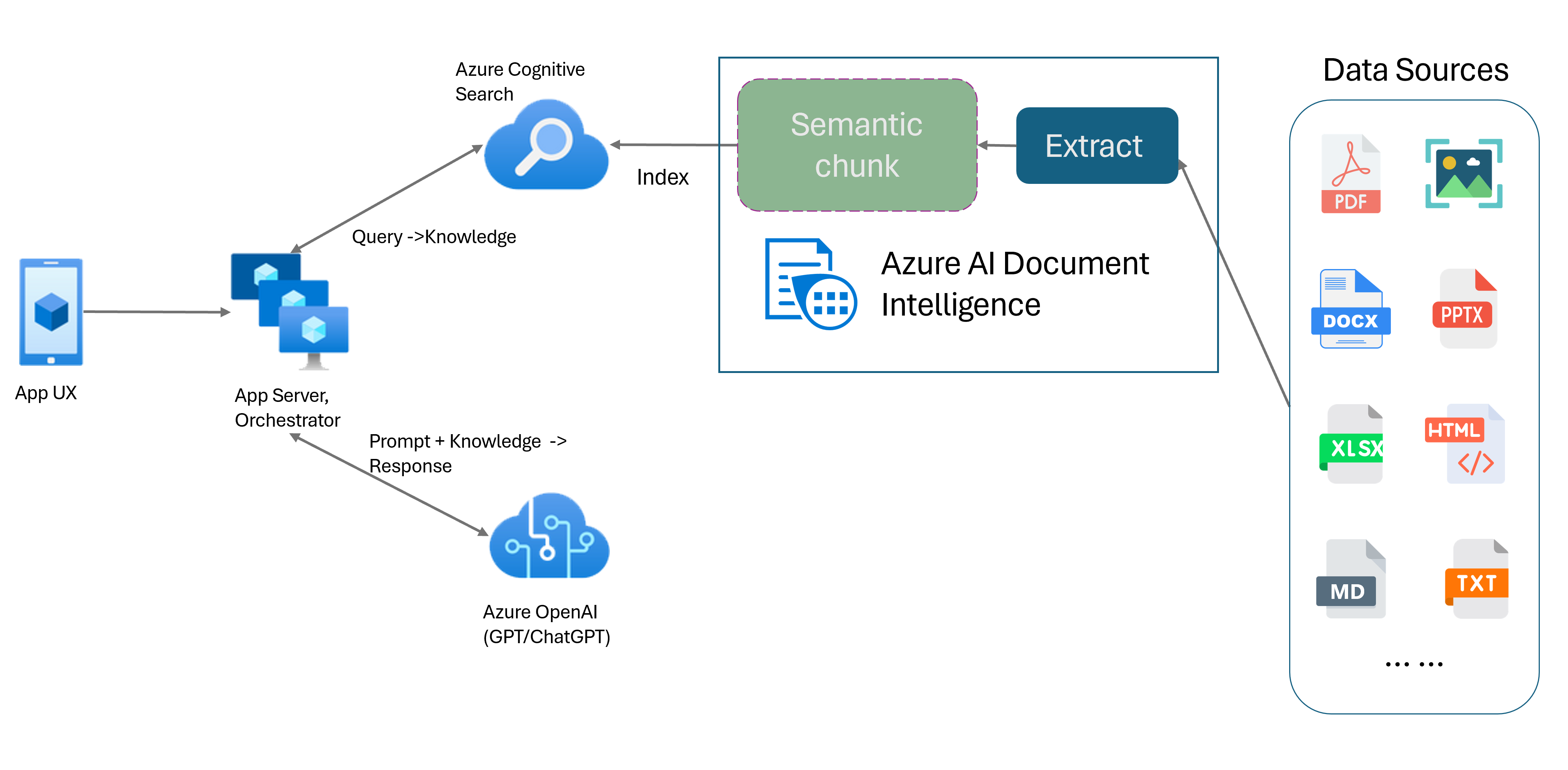
Bildung semantischer Blöcke
Lange Sätze sind für NLP-Anwendungen (Natural Language Processing, linguistische Datenverarbeitung) schwierig. Insbesondere, wenn sie aus mehreren Nebensätzen, komplexen Substantiv- oder Verbphrasen, Relativsätzen und Klammerausdrücken bestehen. Genau wie die menschlichen Betrachter muss auch ein NLP-System erfolgreich den Überblick über alle dargestellten Abhängigkeiten behalten. Das Ziel der Bildung semantischer Blöcke besteht darin, semantisch kohärente Fragmente einer Satzdarstellung zu finden. Diese Fragmente können dann unabhängig voneinander verarbeitet und als semantische Darstellungen ohne Verlust von Informationen, Interpretationen oder semantischer Relevanz neu kombiniert werden. Die inhärente Bedeutung des Texts wird als Leitfaden für den Blockbildungsprozess verwendet.
Strategien für die Segmentierung von Textdaten spielen eine wichtige Rolle bei der Optimierung der RAG-Reaktion und -Leistung. Feste Größe und Semantik sind zwei unterschiedliche Segmentierungsmethoden:
Bildung von Blöcken fester Größe. Die meisten der heutigen in RAG verwendeten Segmentierungsstrategien basieren auf Textsegmenten fester Größe, die als Blöcke bezeichnet werden. Die Bildung von Blöcken fester Größe ist bei Texten, die keine starke semantische Struktur ausweisen, z. B. Protokolle und Daten, schnell, einfach und effektiv. Sie wird jedoch nicht für Texte empfohlen, die ein semantisches Verständnis und einen präzisen Kontext erfordert. Die Verwendung von Fenstern mit fester Größe kann dazu führen, dass Wörter, Sätze oder Absätze abgetrennt werden, wodurch das Verständnis erschwert und der Informationsfluss gestört werden.
Bildung semantischer Blöcke. Bei dieser Methode wird der Text auf der Grundlage des semantischen Verständnisses in Blöcke unterteilt. Die Abgrenzungen der Unterteilungen sind auf das Satzthema ausgerichtet und verbrauchen erhebliche rechnerische, algorithmisch komplexe Ressourcen. Dies hat jedoch den entscheidenden Vorteil, dass die semantische Konsistenz innerhalb jedes Blocks erhalten bleibt. Diese Methode ist nützlich für Textzusammenfassungen, Stimmungsanalyse und Dokumentklassifizierung.
Bildung semantischer Blöcke mit dem Layoutmodell von Dokument Intelligenz
Markdown ist eine strukturierte und formatierte Markupsprache und eine beliebte Eingabe für die Bildung semantischer Blöcke in RAG (Retrieval-Augmented Generation). Sie können den Markdown-Inhalt aus dem Layoutmodell verwenden, um Dokumente basierend auf Absatzgrenzen aufzuteilen, bestimmte Blöcke für Tabellen zu erstellen und Ihre Segmentierungsstrategie zu optimieren, um die Qualität der generierten Antworten zu verbessern.
Vorteile der Verwendung des Layoutmodells
Vereinfachte Verarbeitung. Sie können verschiedene Dokumenttypen wie digitale und gescannte PDF-Dateien, Bilder, Office-Dateien (DOCX, XLSX, PPTX) und HTML mit nur einem einzigen API-Aufruf analysieren.
Skalierbarkeit und KI-Qualität. Das Layoutmodell ist bei der optischen Zeichenerkennung (OCR), der Tabellenextraktion und der Dokumentstrukturanalyse äußerst skalierbar. Es unterstützt 309 gedruckte und 12 handschriftliche Sprachen und gewährleistet so hochwertige Ergebnisse auf der Grundlage von KI-Funktionen.
Kompatibilität des großen Sprachmodells (LLM). Die als Markdown formatierte Ausgabe des Layoutmodells ist LLM-freundlich und erleichtert die nahtlose Integration in Ihre Workflows. Sie können eine beliebige Tabelle in einem Dokument in ein Markdown-Format umwandeln und so einen großen Aufwand beim Parsen der Dokumente für ein besseres LLM-Verständnis vermeiden.
Textbildverarbeitung mit Dokument Intelligenz Studio und Ausgabe als Markdown unter Verwendung des Layoutmodells

Tabellenbildverarbeitung mit Document Intelligence Studio unter Verwendung des Layoutmodells
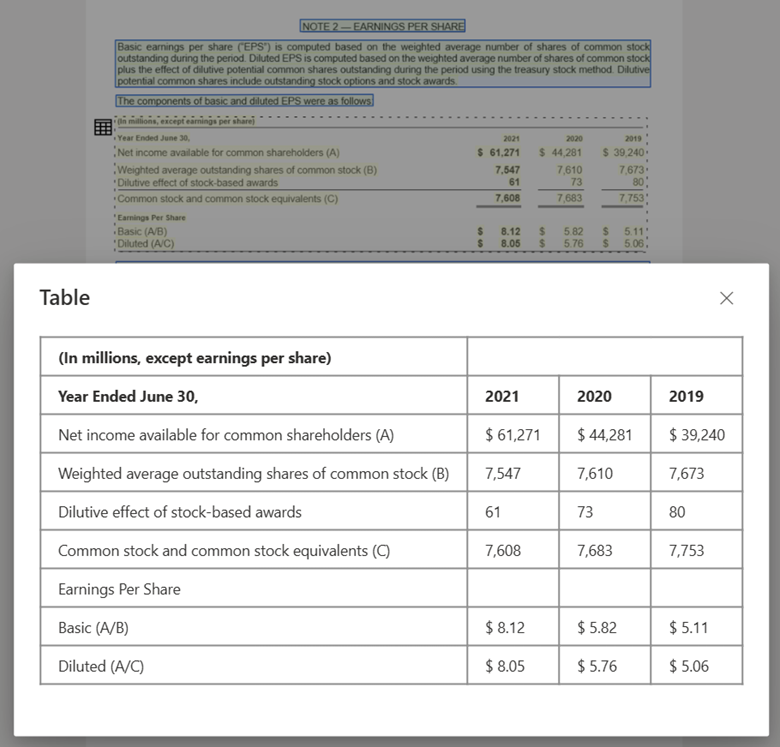
Erste Schritte
Das Dokument Intelligenz-Layoutmodell 2024-02-29-preview und 2023-10-31-preview unterstützt die folgenden Entwicklungsoptionen:
Bereit für den Einstieg?
Dokument Intelligenz Studio
Für die ersten Schritte können Sie den Schnellstart zu Dokument Intelligenz Studio verwenden. Anschließend können Sie Document Intelligence-Features mithilfe des bereitgestellten Beispielcodes in Ihre eigene Anwendung integrieren.
Beginnen Sie mit dem Layoutmodell. Sie müssen die folgenden Analyseoptionen auswählen, um RAG im Studio zu verwenden:
**Required**- Analysebereich ausführen → Aktuelles Dokument
- Seitenbereich → Alle Seiten
- Ausgabeformatvorlage → Markdown
**Optional**- Sie können auch relevante optionale Erkennungsparameter auswählen.
Wählen Sie Speichern.
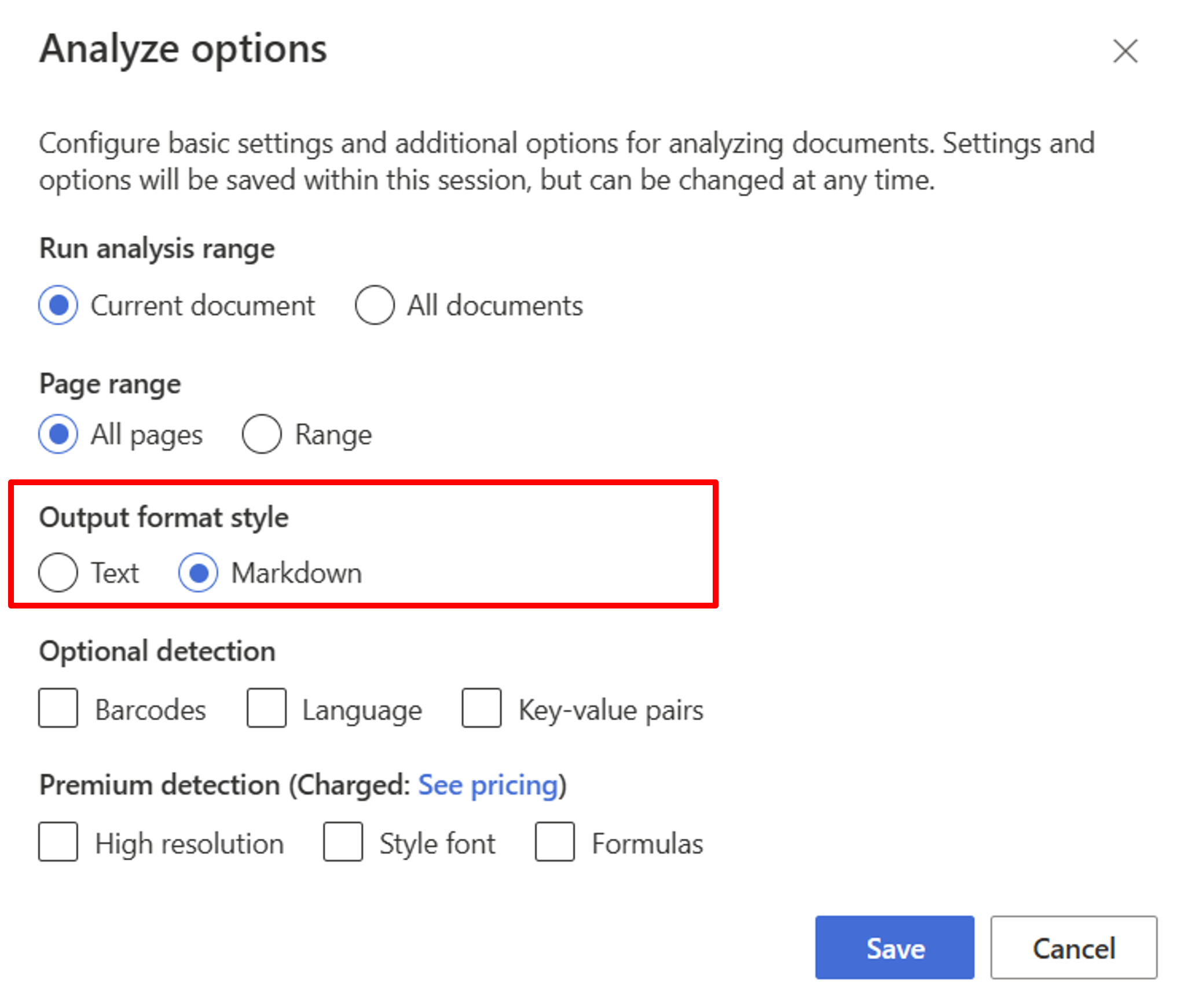
Wählen Sie die Schaltfläche Analyse ausführen aus, um die Ausgabe anzuzeigen.

SDK oder REST-API
Folgen Sie der Anleitung Document Intelligence-Schnellstart für das SDK für Ihre bevorzugte Programmiersprache oder die REST-API. Verwenden Sie das Layoutmodell, um Inhalt und Struktur aus Ihren Dokumenten zu extrahieren.
Sie können auch GitHub-Repositorys auf Codebeispiele und Tipps zum Analysieren eines Dokuments im Markdown-Ausgabeformat überprüfen.
Erstellen eines Dokumentchats mit semantischer Blockbildung
Azure OpenAI für Ihre Daten ermöglicht es Ihnen, unterstützte Chats in Ihren Dokumenten auszuführen. Azure OpenAI für Ihre Daten wendet das Dokument Intelligenz-Layoutmodell an, um Dokumentdaten zu extrahieren und zu analysieren, indem lange Texte basierend auf Tabellen und Absätzen unterteilt werden. Sie können Ihre Segmentierungsstrategie auch mithilfe Azure OpenAI-Beispielskripts anpassen, die Sie in unserem GitHub-Repository finden.
Azure KI Document Intelligence ist jetzt als ein Dokumentladeprogramm in LangChain integriert. Sie können den Dienst verwenden, um Daten einfach zu laden und im Markdown-Format auszugeben. Weitere Informationen finden Sie in unserem Beispielcode, der eine einfache Demo für das RAG-Muster mit Azure KI Dokument Intelligenz als Dokumentladeprogramm und Azure Cognitive Search zum Abrufen in LangChain enthält.
Der Chat mit Ihrem Codebeispiel für Data Solution Accelerator veranschaulicht ein End-to-End-Baseline-RAG-Musterbeispiel. Darin werden Azure KI-Suche zum Abrufen und Azure KI Document Intelligence zum Laden von Dokumenten und Bilden semantischer Blöcke verwendet.
Anwendungsfall
Wenn Sie nach einem bestimmten Abschnitt in einem Dokument suchen, können Sie mithilfe der Bildung semantischer Blöcke das Dokument in kleinere Abschnitte unterteilen, die auf den Abschnittsüberschriften basieren und Ihnen helfen, den gesuchten Abschnitt schnell und einfach zu finden:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Nächste Schritte
Weitere Informationen zu Azure KI Dokument Intelligenz.
Hier erfahren Sie, wie Sie Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.