Tutorial: Verwenden von Azure Functions und Python zum Verarbeiten gespeicherter Dokumente
Dokument Intelligenz kann als Teil einer automatisierten, mit Azure Functions erstellten Datenverarbeitungspipeline verwendet werden. In diesem Leitfaden erfahren Sie, wie Sie Azure Functions verwenden, um Dokumente zu verarbeiten, die in einen Azure Blob Storage-Container hochgeladen werden. Im Rahmen dieses Workflows werden mithilfe des Layoutmodells für Dokument Intelligenz Tabellendaten aus gespeicherten Dokumenten extrahiert und in einer CSV-Datei in Azure gespeichert. Die Daten können dann mithilfe von Microsoft Power BI angezeigt werden (wird hier nicht behandelt).
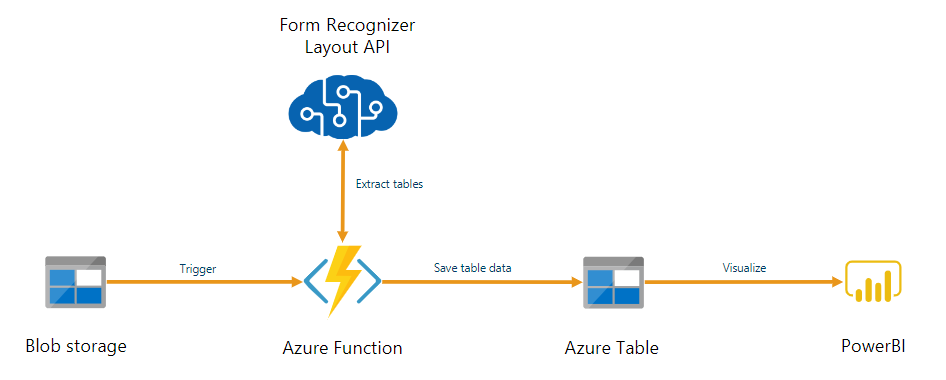
In diesem Tutorial lernen Sie Folgendes:
- Erstellen eines Azure-Speicherkontos.
- Erstellen eines Azure Functions-Projekts
- Extrahieren von Layoutdaten aus hochgeladenen Formularen.
- Hochladen extrahierter Layoutdaten in Azure Storage.
Voraussetzungen
Azure-Abonnement - Erstellen eines kostenlosen Abonnements
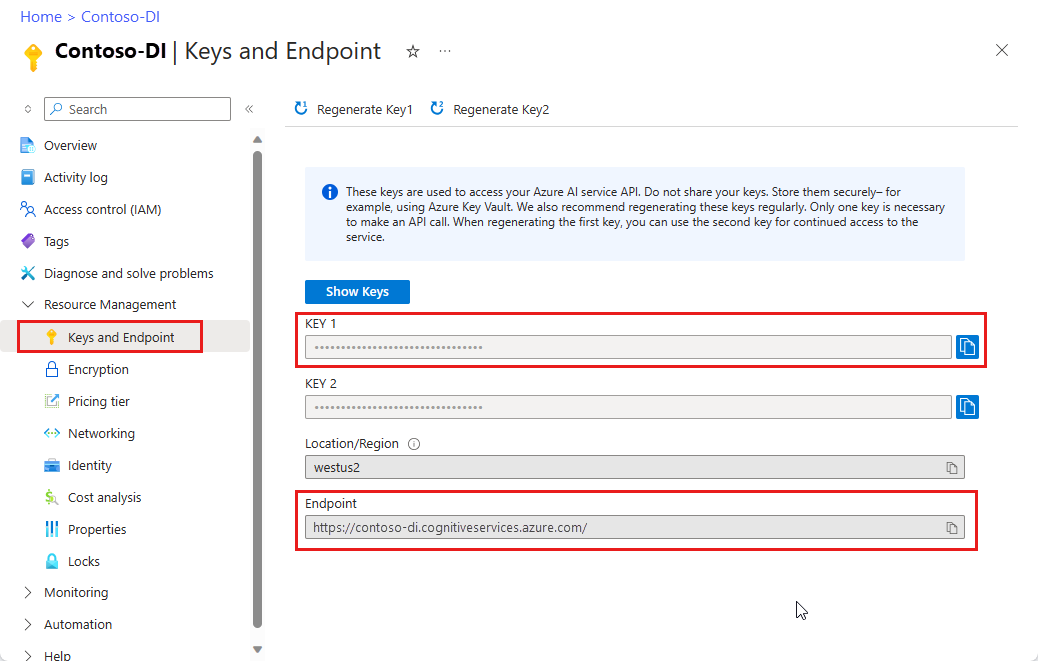
Eine Dokument Intelligenz-Ressource. Sobald Sie über Ihr Azure-Abonnement verfügen, sollten Sie im Azure-Portal eine Dokument Intelligenz-Ressource erstellen, um Ihren Schlüssel und Endpunkt zu erhalten. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst zu testen, und später für die Produktion auf einen kostenpflichtigen Tarif upgraden.Wählen Sie nach der Bereitstellung der Ressource Zu Ressource wechseln aus. Sie benötigen den Schlüssel und Endpunkt der von Ihnen erstellten Ressource, um Ihre Anwendung mit der Dokument Intelligenz-API zu verbinden. Der Schlüssel und der Endpunkt werden weiter unten im Tutorial in den Code eingefügt:
Python 3.6.x, 3.7.x, 3.8.x oder 3.9.x (Python 3.10.x wird für dieses Projekt nicht unterstützt).
Die neueste Version von Visual Studio Code (VS Code) mit den folgenden Installierten Erweiterungen:
Azure Functions-Erweiterung. Nach der Installation sollte das Azure-Logo im linken Navigationsbereich angezeigt werden.
Azure Functions Core Tools Version 3.x (Version 4.x wird für dieses Projekt nicht unterstützt).
Python-Erweiterung für Visual Studio Code. Weitere Informationen finden Sie unter Erste Schritte mit Python in VS Code.
Ein lokales PDF-Dokument für die Analyse. Sie können unser PDF-Beispieldokument für dieses Projekt verwenden.
Erstellen eines Azure-Speicherkontos
Erstellen Sie ein allgemeines Azure Storage-v2 -Konto im Azure-Portal. Wenn Sie nicht wissen, wie Sie ein Azure-Speicherkonto mit einem Speichercontainer erstellen, befolgen Sie diese Schnellstarts:
- Informationen zu Azure-Speicherkonten Wenn Sie Ihr Speicherkonto erstellen, wählen Sie Standardleistung im Feld Instanzendetails>Leistung aus.
- Erstellen Sie einen Container. Legen Sie bei der Erstellung Ihres Containers das Feld Öffentliche Zugriffsebene im Fenster Neuer Container auf Container fest (anonymer Lesezugriff für Container und Dateien).
Wählen Sie im linken Bereich die Registerkarte Ressourcenfreigabe (CORS) aus, und entfernen Sie die ggf. vorhandene CORS-Richtlinie.
Erstellen Sie nach der Bereitstellung Ihres Speicherkontos zwei leere Blob Storage-Container namens input und output.
Erstellen eines Azure Functions-Projekts
Erstellen Sie einen neuen Ordner namens functions-app für die Projektdateien, und wählen Sie dann Auswählen aus.
Öffnen Sie Visual Studio Code, und öffnen Sie die Befehlspalette. Suchen Sie nach Python:Select Interpreter, und wählen Sie diese Option aus. → Wählen Sie einen installierten Python-Interpreter aus, der Version 3.6.x, 3.7.x, 3.8.x oder 3.9.x aufweist. Diese Auswahl fügt Ihrem Projekt den Pfad des von Ihnen ausgewählten Python-Interpreters hinzu.
Wählen Sie das Azure-Logo im linken Navigationsbereich aus.
Ihre vorhandenen Azure-Ressourcen werden in der Ressourcenansicht angezeigt.
Wählen Sie das Azure-Abonnement aus, das Sie für dieses Projekt verwenden. Die Azure Functions-App sollte darunter angezeigt werden.
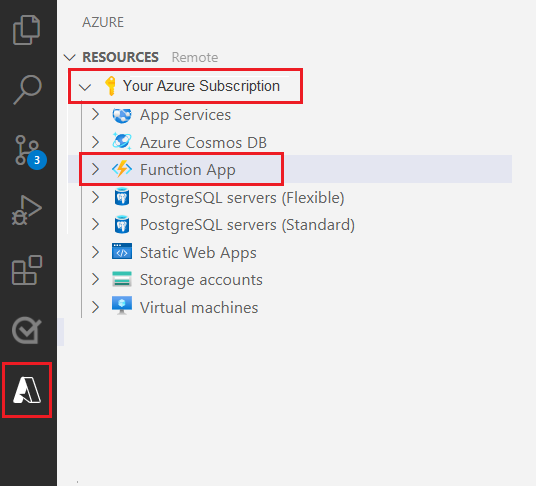
Wählen Sie den Abschnitt „Arbeitsbereich (lokal)“ unter Ihren aufgeführten Ressourcen aus. Wählen Sie das Plussymbol aus, und wählen Sie dann die Schaltfläche Funktion erstellen aus.

Wenn Sie dazu aufgefordert werden, wählen Sie Neues Projekt erstellen aus, und navigieren Sie zum Verzeichnis function-app. Klicken Sie auf Auswählen.
Sie werden aufgefordert, verschiedene Einstellungen zu konfigurieren:
Sprache auswählen → Wählen Sie „Python“ aus.
Python-Interpreter auswählen, um eine virtuelle Umgebung zu erstellen → Wählen Sie den Interpreter aus, den Sie zuvor als Standard festgelegt haben.
Vorlage auswählen → Wählen Sie Azure Blob Storage-Trigger aus, und geben Sie dem Trigger einen Namen, oder akzeptieren Sie den Standardnamen. Drücken Sie zur Bestätigung die EINGABETASTE.
Einstellung auswählen → Wählen Sie ➕ Neue lokale App-Einstellung erstellen im Dropdownmenü aus.
Abonnement auswählen → Wählen Sie Ihr Azure-Abonnement mit dem von Ihnen erstellten Speicherkonto aus. → Wählen Sie Ihr Speicherkonto aus. → Wählen Sie dann den Namen des Speichereingabecontainers (in diesem Fall
input/{name}) aus. Drücken Sie zur Bestätigung die EINGABETASTE.Auswählen, wie Sie Ihr Projekt öffnen möchten → Wählen Sie im Dropdownmenü Projekt im aktuellen Fenster öffnen aus.
Nach Abschluss dieser Schritte fügt VS Code ein neues Azure Functions-Projekt mit einem Python-Skript namens __init__.py hinzu. Dieses Skript wird ausgelöst, wenn eine Datei in den Speichercontainer input hochgeladen wird:
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Testen der Funktion
Drücken Sie F5, um die grundlegende Funktion auszuführen. Daraufhin werden Sie von VS Code aufgefordert, ein zu verwendendes Speicherkonto auszuwählen.
Wählen Sie das von Ihnen erstellte Speicherkonto aus, und setzen Sie den Vorgang fort.
Öffnen Sie den Azure Storage-Explorer, und laden Sie ein PDF-Beispieldokument in den Container input hoch. Überprüfen Sie dann das VS Code-Terminal. Das Skript sollte protokollieren, dass es durch den PDF-Upload ausgelöst wurde.
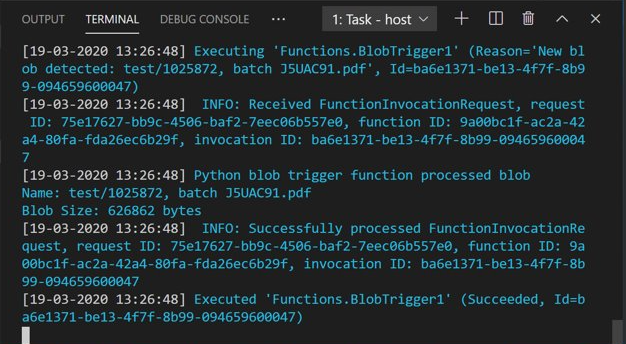
Beenden Sie das Skript, bevor Sie fortfahren.
Hinzufügen von Dokumentverarbeitungscode
Fügen Sie dem Python-Skript nun Ihren eigenen Code hinzu, um den Dokument Intelligenz-Dienst aufzurufen und die hochgeladenen Dokumente mithilfe des Layoutmodells für die Dokument Intelligenz zu analysieren.
Navigieren Sie in VS Code zur Datei requirements.txt der Funktion. Diese Datei definiert die Abhängigkeiten für Ihr Skript. Fügen Sie der Datei die folgenden Python-Pakete hinzu:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyÖffnen Sie dann das Skript __init__.py. Fügen Sie die folgenden
import-Anweisungen ein:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdDie generierte Funktion
mainmuss nicht geändert werden. Ihr benutzerdefinierter Code wird in diese Funktion eingefügt.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")Durch den folgenden Codeblock wird die Dokument Intelligenz-API zum Analysieren des Layouts für das hochgeladene Dokument aufgerufen. Geben Sie Ihre Endpunkt- und Schlüsselwerte an.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Wichtig
Denken Sie daran, den Schlüssel aus Ihrem Code zu entfernen, wenn Sie fertig sind, und ihn niemals zu veröffentlichen. Verwenden Sie für die Produktion eine sichere Art der Speicherung und des Zugriffs auf Ihre Anmeldeinformationen wie Azure Key Vault. Weitere Informationen finden Sie unter Azure KI Services-Sicherheit.
Fügen Sie als Nächstes Code hinzu, um den Dienst abzufragen und die zurückgegebenen Daten abzurufen.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonFügen Sie den folgenden Code hinzu, um eine Verbindung mit dem Azure Storage-Container output herzustellen. Geben Sie Ihre eigenen Werte für Speicherkontoname und -schlüssel ein. Den Schlüssel können Sie im Azure-Portal auf der Registerkarte Zugriffsschlüssel Ihrer Speicherressource abrufen.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")Mit dem folgenden Code wird die zurückgegebene Antwort von Dokument Intelligenz analysiert sowie eine CSV-Datei erstellt und in den Container output hochgeladen.
Wichtig
Dieser Code muss wahrscheinlich bearbeitet werden, um der Struktur Ihrer eigenen Dokumente zu entsprechen.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Durch den letzten Codeblock werden schließlich die extrahierten Tabellen- und Textdaten in Ihr Blob Storage-Element hochgeladen.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Ausführen der Funktion
Drücken Sie F5, um die Funktion erneut auszuführen.
Laden Sie über den Azure Storage-Explorer ein PDF-Beispielformular in den Speichercontainer input hoch. Durch diese Aktion sollte die Ausführung des Skripts ausgelöst werden, und die resultierende CSV-Datei sollte als Tabelle im Container output angezeigt werden.
Sie können diesen Container mit Power BI verbinden, um umfangreiche Visualisierungen der darin enthaltenen Daten zu erstellen.
Nächste Schritte
In diesem Tutorial haben Sie gelernt, wie Sie eine in Python geschriebene Azure-Funktion verwenden, um hochgeladene PDF-Dokumente automatisch zu verarbeiten und ihren Inhalt in einem datenfreundlicheren Format auszugeben. Als Nächstes erfahren Sie, wie Sie die Daten mithilfe von Power BI anzeigen.
- Was ist Dokument Intelligenz?
- Weitere Informationen zum Layoutmodell
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für