Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Bevor Sie Ihr Modell trainieren, müssen Sie Ihre Dokumente mit den Kategorien versehen, in die Sie sie kategorisieren möchten. Datenbeschriftung ist ein wichtiger Schritt im Entwicklungslebenszyklus. In diesem Schritt können Sie die Klassen erstellen, in die Sie Ihre Daten kategorisieren möchten, und Ihre Dokumente mit diesen Klassen beschriften. Diese Daten werden im nächsten Schritt beim Trainieren Ihres Modells verwendet, damit Ihr Modell aus den beschrifteten Daten lernen kann. Wenn Sie Ihre Daten bereits bezeichnet haben, können Sie sie direkt in Ihr Projekt importieren , aber Sie müssen sicherstellen, dass Ihre Daten dem akzeptierten Datenformat folgen.
Für die Erstellung eines benutzerdefinierten Textklassifizierungsmodells sind beschriftete Daten erforderlich. Falls Ihre Daten noch nicht beschriftet sind, können Sie sie in Language Studio beschriften. Anhand von beschrifteten Daten kann das Modell bestimmen, wie Text interpretiert werden soll. Auch werden sie zum Trainieren und zur Auswertung verwendet.
Voraussetzungen
Um Daten beschriften zu können, benötigen Sie Folgendes:
- Ein erfolgreich erstelltes Projekt mit einem konfigurierten Azure Blob Speicherkonto,
- Dokumente, die die hochgeladenen Textdaten in Ihrem Speicherkonto enthalten.
Weitere Informationen finden Sie unter Lebenszyklus der Projektentwicklung.
Richtlinien für die Datenbeschriftung
Nach dem Vorbereiten Ihrer Daten, Entwerfen Ihres Schemas und Erstellen Ihres Projekts müssen Sie Ihre Daten beschriften. Das Beschriften der Daten ist wichtig, um Ihrem Modell mitzuteilen, welche Dokumente den von Ihnen benötigten Klassen zugeordnet werden. Wenn Sie Ihre Daten in Language Studio beschriften (oder beschriftete Daten importieren), werden diese Bezeichnungen in der JSON-Datei in Ihrem Speichercontainer gespeichert, den Sie mit diesem Projekt verbunden haben.
Beachten Sie beim Beschriften Ihrer Daten Folgendes:
Im Allgemeinen führen mehr beschriftete Daten zu besseren Ergebnissen (vorausgesetzt, die Daten sind ordnungsgemäß beschriftet).
Es gibt keine feste Anzahl von Etiketten, die garantieren können, dass Ihr Modell am besten funktioniert. Die Leistung des Modells hängt von möglicher Mehrdeutigkeit in Ihrem Schema sowie von der Qualität Ihrer beschrifteten Daten ab. Dennoch empfehlen wir 50 beschriftete Dokumente pro Klasse.
Beschriften Ihrer Daten
Beschriften Sie Ihre Daten wie folgt:
Wechseln Sie in Language Studio zu Ihrer Projektseite.
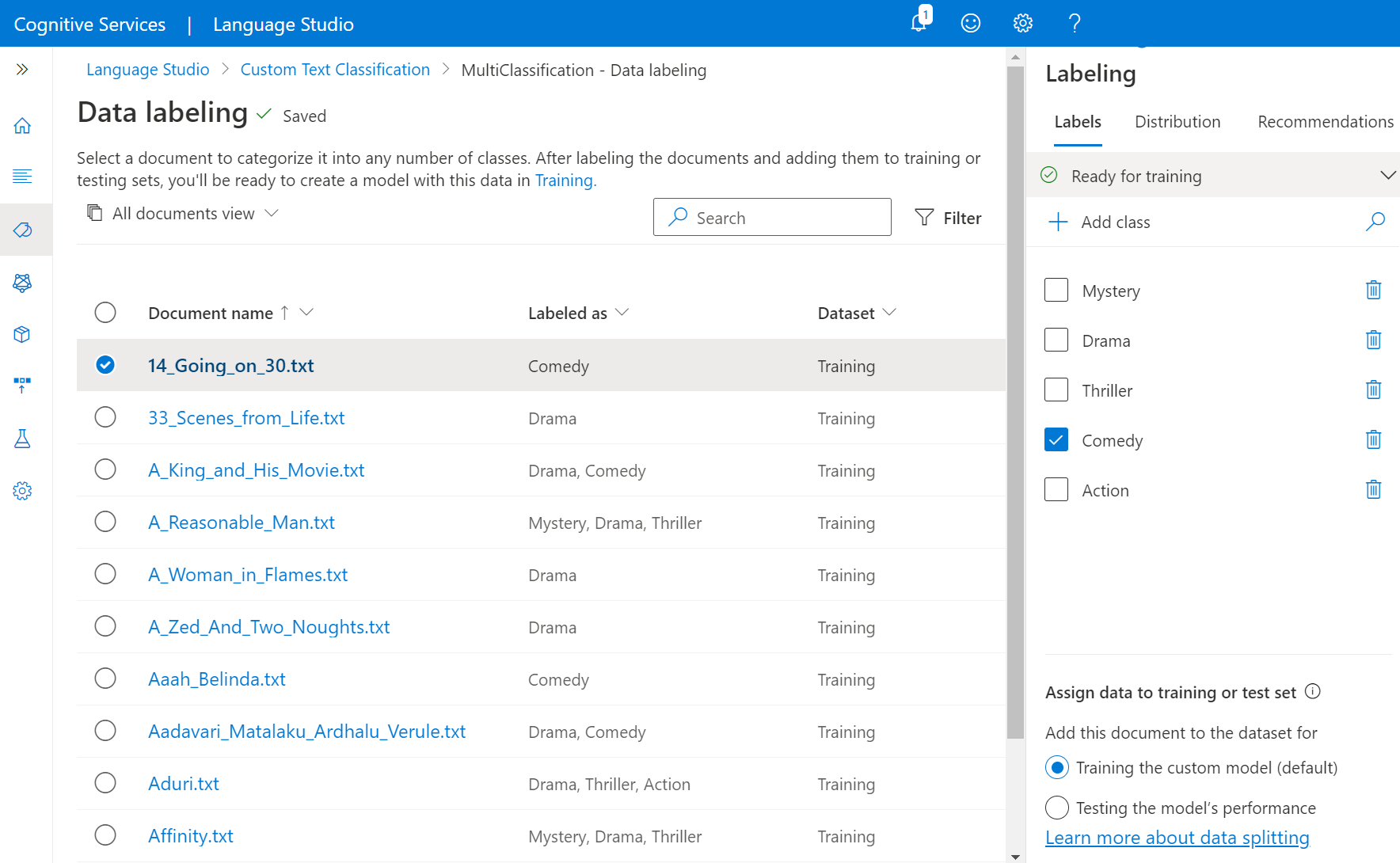
Wählen Sie im Menü auf der linken Seite die Option Datenbeschriftung aus. Es steht eine Liste mit allen Dokumenten in Ihrem Speichercontainer zur Verfügung. Siehe Abbildung unten.
Tipp
Mithilfe der Filter im oberen Menü können Sie unbeschriftete Dateien anzeigen, um mit deren Beschriftung zu beginnen. Die Filter können auch verwendet werden, um Dokumente anzuzeigen, die mit einer bestimmten Klasse beschriftet sind.
Wechseln Sie auf der linken Seite des oberen Menüs zu einer Einzeldateiansicht, oder wählen Sie eine bestimmte Datei aus, um mit der Beschriftung zu beginnen. Auf der linken Seite finden Sie eine Liste aller
.txt-Dateien, die in Ihren Projekten verfügbar sind. Mithilfe der Schaltflächen Zurück und Weiter am unteren Seitenrand können Sie durch Ihre Dokumente navigieren.Hinweis
Wenn Sie für Ihr Projekt mehrere Sprachen aktiviert haben, können Sie im oberen Menü über die Dropdownliste Sprache die Sprache des jeweiligen Dokuments auswählen.
Verwenden Sie im Bereich auf der rechten Seite die Option Klasse hinzufügen, um Ihrem Projekt Klassen hinzuzufügen, mit denen Sie Ihre Daten beschriften können.
Beginnen Sie mit der Beschriftung Ihrer Dateien.
Klassifizierung mehrerer Bezeichnungen: Ihre Datei kann mit mehreren Klassen beschriftet werden. Sie können dies tun, indem Sie alle anwendbaren Kontrollkästchen neben den Klassen aktivieren, mit der Sie dieses Dokument bezeichnen möchten.
Sie können auch das Feature „Automatisches Bezeichnen“ verwenden, um eine vollständige Bezeichnung zu gewährleisten.
Im Bereich auf der rechten Seite finden Sie unter dem Pivotelement Bezeichnungen alle Klassen in Ihrem Projekt sowie die jeweilige Anzahl beschrifteter Instanzen.
Im unteren Abschnitt des rechten Seitenbereichs können Sie die aktuell angezeigte Datei zum Schulungssatz oder Testsatz hinzufügen. Standardmäßig werden alle Dokumente Ihrem Trainingssatz hinzugefügt. Weitere Informationen zu Trainings- und Testsätzen sowie zu ihrer Verwendung beim Trainieren und Auswerten von Modellen finden Sie hier.
Tipp
Wenn Sie planen, die automatische Datenteilung zu verwenden, verwenden Sie die Standardoption zum Zuweisen aller Dokumente in Ihren Schulungssatz.
Unter dem Pivotelement Verteilung können Sie die Verteilung in den Schulungs- und Testsätzen anzeigen. Es gibt zwei Ansichtsoptionen:
- Alle Instanzen: Hier wird die Anzahl aller bezeichneten Instanzen einer bestimmten Klasse angezeigt.
- Dokumente mit mindestens einer Bezeichnung: Hier wird jedes Dokument gezählt, wenn es mindestens eine bezeichnete Instanz dieser Klasse enthält.
Während Sie etikettieren, werden Ihre Änderungen regelmäßig synchronisiert. Wenn sie noch nicht gespeichert wurden, finden Sie am oberen Rand der Seite eine Warnung. Wenn Sie manuell speichern möchten, wählen Sie unten auf der Seite die Schaltfläche Beschriftungen speichern aus.


Entfernen von Bezeichnungen
Wenn Sie eine Bezeichnung entfernen möchten, können Sie die Schaltfläche neben der Klasse deaktivieren.
Löschen von Klassen
Um einen Kurs zu löschen, wählen Sie das Symbol neben dem Kurs aus, den Sie entfernen möchten. Wenn Sie eine Klasse löschen, werden alle zugehörigen beschrifteten Instanzen aus Ihrem Dataset entfernt.
Nächste Schritte
Nachdem Sie Ihre Daten beschriftet haben, können Sie mit dem Trainieren eines Modells beginnen, das auf der Grundlage Ihrer Daten lernt.