Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die direkte Präferenzoptimierung (DPO) ist eine Ausrichtungsmethode für große Sprachmodelle, die zur Anpassung der Modellgewichte auf der Grundlage menschlicher Präferenzen verwendet wird. Es unterscheidet sich vom vertiefenden Lernen aus menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF) dadurch, dass es keine Anpassung eines Belohnungsmodells erfordert und einfachere binäre Datenpräferenzen für das Training verwendet. Es ist rechnerisch leichter und schneller als RLHF, während es bei der Ausrichtung genauso effektiv ist.
Warum ist DPO nützlich?
DPO ist besonders nützlich in Szenarien, in denen es keine eindeutige richtige Antwort gibt und subjektive Elemente wie Tonfall, Stil oder bestimmte inhaltliche Vorlieben wichtig sind. Dieser Ansatz ermöglicht es dem Modell auch, sowohl von positiven Beispielen (was als richtig oder ideal angesehen wird) als auch von negativen Beispielen (was weniger erwünscht oder falsch ist) zu lernen.
Man geht davon aus, dass DPO eine Technik ist, die es den Kunden erleichtern wird, qualitativ hochwertige Trainingsdatensätze zu erzeugen. Während viele Kunden Schwierigkeiten haben, ausreichend große Datensätze für die überwachte Feinabstimmung zu generieren, verfügen sie oft bereits über Präferenzdaten, die auf der Grundlage von Benutzerprotokollen, A/B-Tests oder kleineren manuellen Annotationen gesammelt wurden.
Dataset-Format für die direkte Präferenzoptimierung
Dateien für die direkte Präferenzoptimierung haben ein anderes Format als Daten für die überwachte Feinabstimmung. Kunden geben eine „Unterhaltung“ ein, die die Systemnachricht und die anfängliche Benutzernachricht enthält, und dann „Vervollständigungen“ mit gepaarten Präferenzdaten. Benutzer können nur zwei Vervollständigungen angeben.
Die Felder der obersten Ebene sind: input, preferred_output, und non_preferred_output
- Jedes Element im Ordner preferred_output/non_preferred_output muss mindestens eine Assistentenmeldung enthalten
- Jedes Element im Ordner preferred_output/non_preferred_output kann nur Rollen in (assistant, tool) haben.
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
Training-Datasets müssen im Format jsonl vorliegen.
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Modellunterstützung für die direkte Präferenzoptimierung
gpt-4o-2024-08-06,gpt-4.1-2025-04-14,gpt-4.1-mini-2025-04-14unterstützt die direkte Präferenzoptimierung in den jeweiligen Feinabstimmungsregionen. Die neueste Verfügbarkeit der Region wird auf der Seite „Modelle“ aktualisiert
Benutzende können die Feinabstimmung der Präferenzen sowohl mit Basismodellen als auch mit Modellen verwenden, die bereits mit der überwachten Feinabstimmung optimiert wurden, solange es sich um ein unterstütztes Modell/eine unterstützte Version handelt.
Wie verwende ich die Feinabstimmung der direkten Präferenzoptimierung?
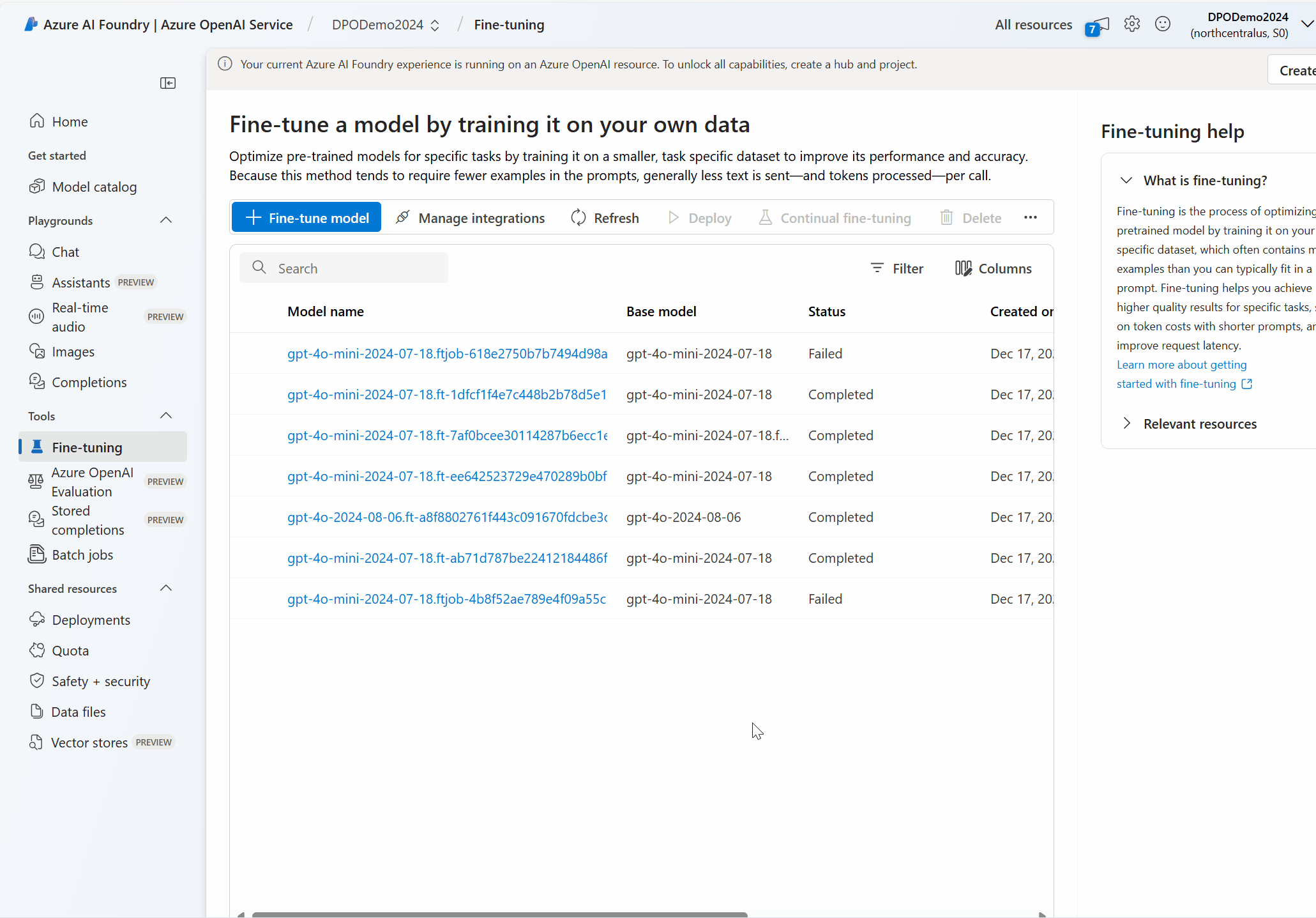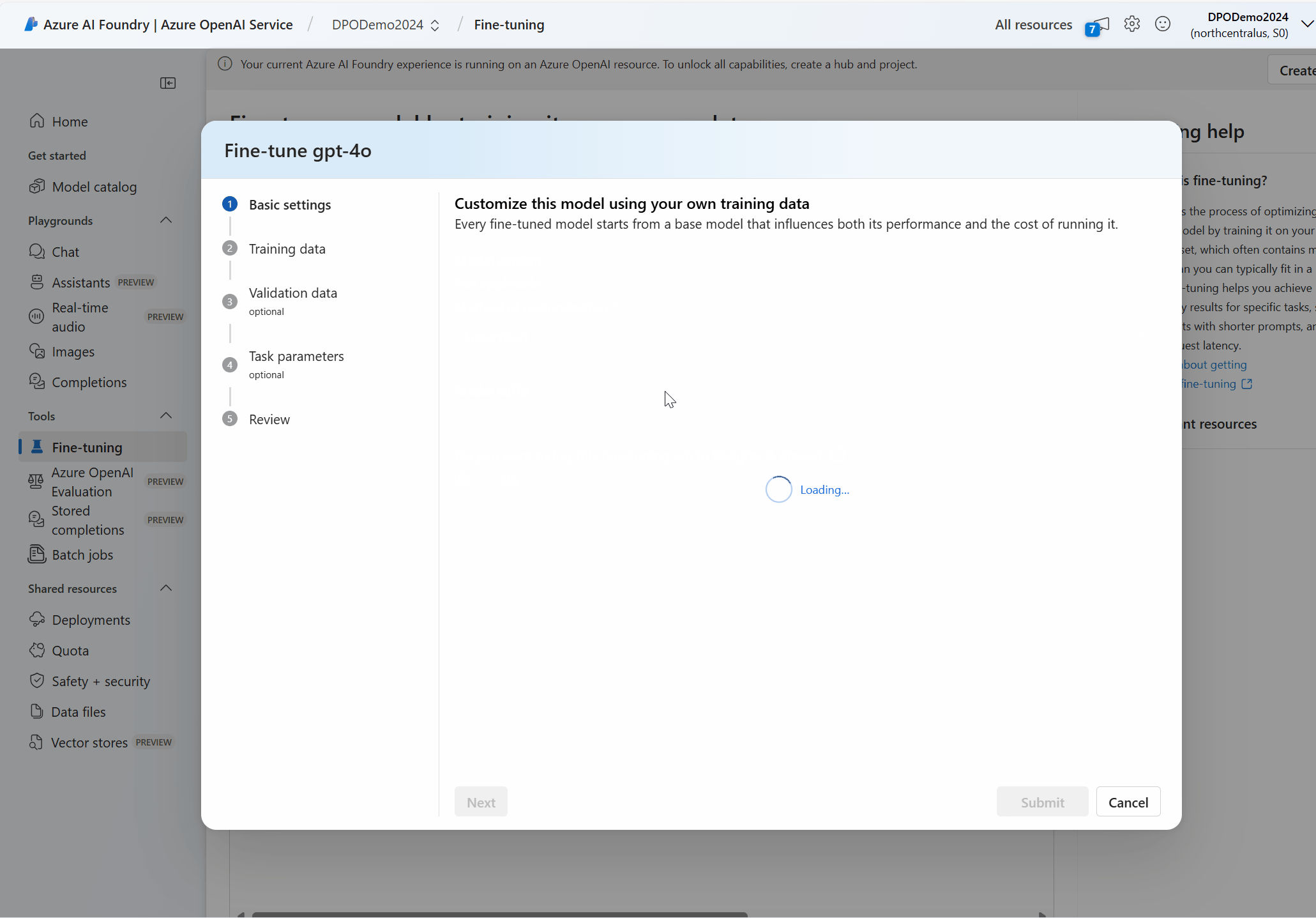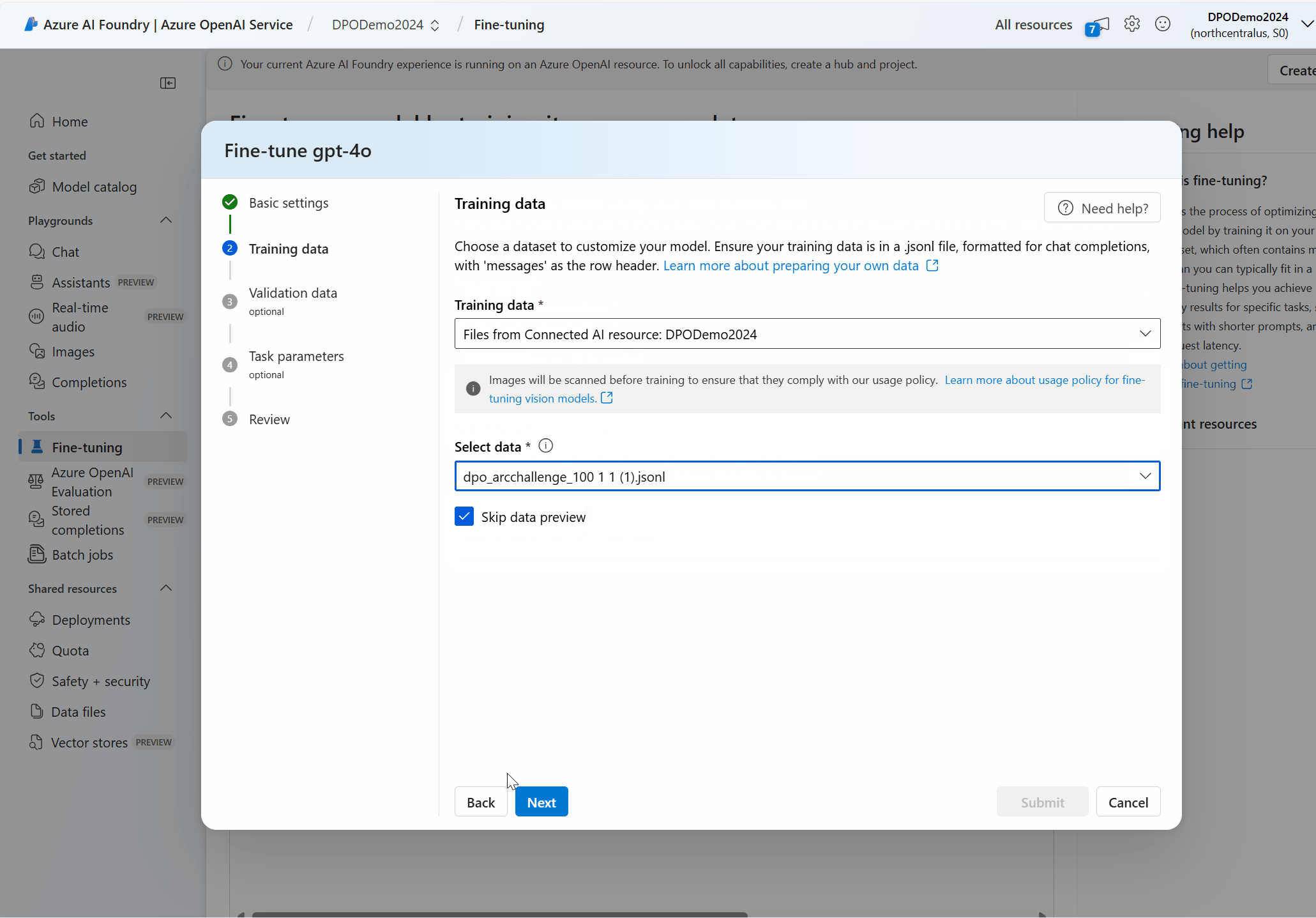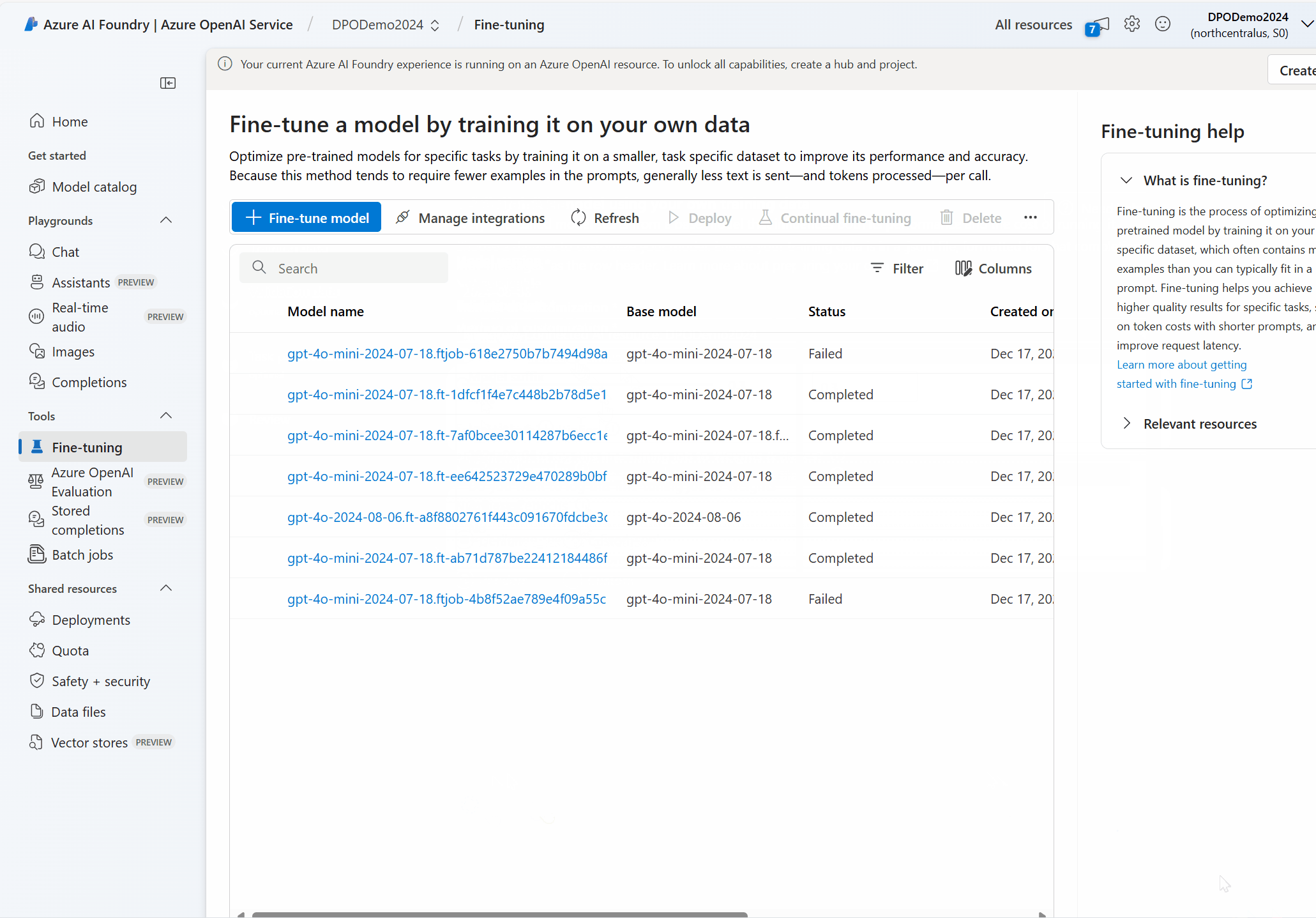
- Bereiten Sie
jsonlDatasets im Präferenz-Format vor. - Wählen Sie das Modell und dann die Methode der Anpassung Direkte Präferenzoptimierung.
- Datasets hochladen – Training und Validierung Zeigen Sie bei Bedarf eine Vorschau an.
- Wählen Sie die Hyperparameter aus. Für erste Experimente werden die Standardwerte empfohlen.
- Überprüfen Sie die Auswahl und erstellen Sie einen Feinabstimmungsauftrag.
Nächste Schritte
- Erkunden Sie die Feinabstimmungsfunktionen im Azure OpenAI-Feinabstimmungstutorial.
- Überprüfen der Feinabstimmung des regionalen Verfügbarkeitsmodells
- Weitere Informationen zu Azure OpenAI-Kontingenten