Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Diese Anleitung hilft Ihnen, die Funktionen zur Sichtbarkeit bei Advanced Container Networking Services zu navigieren, um reale Netzwerk-Anwendungsfälle zu adressieren. Ob Problembehandlung bei DNS-Lösungsproblemen, Optimieren des Eingangs- und Übergabedatenverkehrs oder Sicherstellung der Einhaltung von Netzwerkrichtlinien. In diesem Handbuch wird veranschaulicht, wie Sie Advanced Container Networking Service-Observability-Dashboards, Flussprotokolle und Visualisierungstools wie Hubble UI und CLI nutzen, um Probleme effektiv zu diagnostizieren und zu beheben.
Übersicht über Advanced Container Networking Services-Dashboards
Wir haben Beispieldashboards für Advanced Container Networking Services erstellt, mit denen Sie Netzwerkdatenverkehr, DNS-Anforderungen und Paketverluste in Ihren Kubernetes-Clustern visualisieren und analysieren können. Diese Dashboards sollen Einblicke in die Netzwerkleistung bieten, potenzielle Probleme identifizieren und bei der Problembehandlung unterstützen. Informationen zum Einrichten dieser Dashboards finden Sie unter "Einrichten der Containernetzwerkbeobachtbarkeit für Azure Kubernetes Service (AKS) – Von Azure verwaltete Prometheus und Grafana.
Die Suite von Dashboards umfasst:
- Cluster: Zeigt Metriken auf Knotenebene für Ihre Cluster an.
- DNS (Cluster):Zeigt DNS-Metriken für einen Cluster oder eine Auswahl von Knoten an.
- DNS (Workload): Zeigt DNS-Metriken für die angegebene Workload an (z. B. Pods eines DaemonSets oder einer Bereitstellung wie CoreDNS).
- Verluste (Workload): zeigt Verluste zu/von der angegebenen Workload an (z. B. Pods einer Bereitstellung oder eines DaemonSet).
- Pod Flows (Namespace): Zeigt L4/L7-Paketflüsse an/aus dem angegebenen Namespace (d. h. Pods im Namespace).
- Podflows (Workload):zeigt L4/L7-Paketflows zu/von der angegebenen Workload an (z. B. Pods einer Bereitstellung oder eines DaemonSet).
- L7 Flows (Namespace):Zeigt HTTP-, Kafka- und gRPC-Paketflüsse in/aus dem angegebenen Namespace (d. h. Pods im Namespace) an, wenn eine Layer 7-basierte Richtlinie angewendet wird. Dies ist nur für Cluster mit Cilium-Datenebene verfügbar.
- L7 Flows (Workload):Zeigt HTTP-, Kafka- und gRPC-Flüsse an/von der angegebenen Workload (z. B. Pods einer Bereitstellung oder eines DaemonSets) an, wenn eine Layer 7-basierte Richtlinie angewendet wird. Dies ist nur für Cluster mit Cilium-Datenebene verfügbar.
Anwendungsfall 1: Interpretieren von DNS-Problemen (Domain Name Server) für die Ursachenanalyse (Root Cause Analysis, RCA)
DNS-Probleme auf Pod-Ebene können zu fehlgeschlagenen Dienstermittlungen, langsamen Anwendungsantworten oder Kommunikationsfehlern zwischen Pods führen. Diese Probleme treten häufig aus falsch konfigurierten DNS-Richtlinien, eingeschränkter Abfragekapazität oder Latenz bei der Auflösung externer Domänen auf. Wenn beispielsweise der CoreDNS-Dienst überlastet ist oder ein Upstream-DNS-Server nicht mehr reagiert, kann dies zu Fehlern in abhängigen Pods führen. Das Beheben dieser Probleme erfordert nicht nur die Identifizierung, sondern tiefe Einblicke in das DNS-Verhalten innerhalb des Clusters.
Angenommen, Sie haben eine Webanwendung in einem AKS-Cluster eingerichtet, und jetzt ist die Webanwendung nicht erreichbar. Sie erhalten DNS-Fehler, z.B.
DNS_PROBE_FINISHED_NXDOMAINoderSERVFAIL, während der DNS-Server die Adresse der Webanwendung auflöst.
Schritt 1: Untersuchen von DNS-Metriken in Grafana-Dashboards
Wir haben bereits zwei DNS-Dashboards erstellt, um DNS-Metriken, Anforderungen und Antworten zu untersuchen: DNS (Cluster), die DNS-Metriken für einen Cluster oder eine Auswahl von Knoten sowie DNS (Workload) anzeigt, die DNS-Metriken für eine bestimmte Workload (z. B. Pods eines DaemonSets oder einer Bereitstellung wie CoreDNS) anzeigt.
Überprüfen Sie das DNS-Clusterdashboard , um eine Momentaufnahme aller DNS-Aktivitäten abzurufen. Dieses Dashboard bietet eine allgemeine Übersicht über DNS-Anforderungen und -Antworten, z. B. welche Arten von Abfragen keine Antworten haben, die häufigste Abfrage und die häufigste Antwort. Außerdem werden die wichtigsten DNS-Fehler und die Knoten hervorgehoben, die die meisten dieser Fehler generieren.
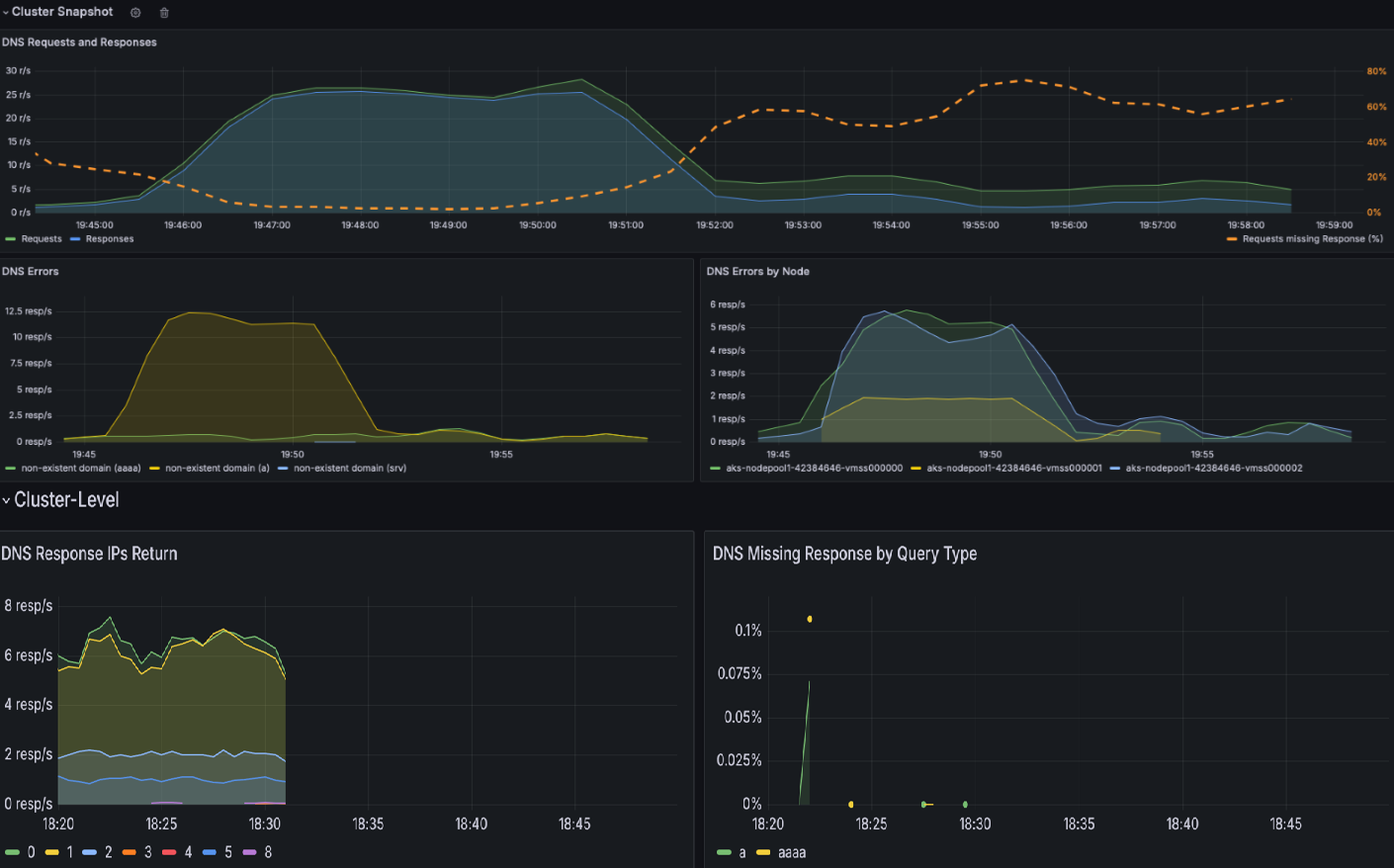
Scrollen Sie nach unten, um Pods mit den meisten DNS-Anforderungen und Fehlern in allen Namespaces zu ermitteln.
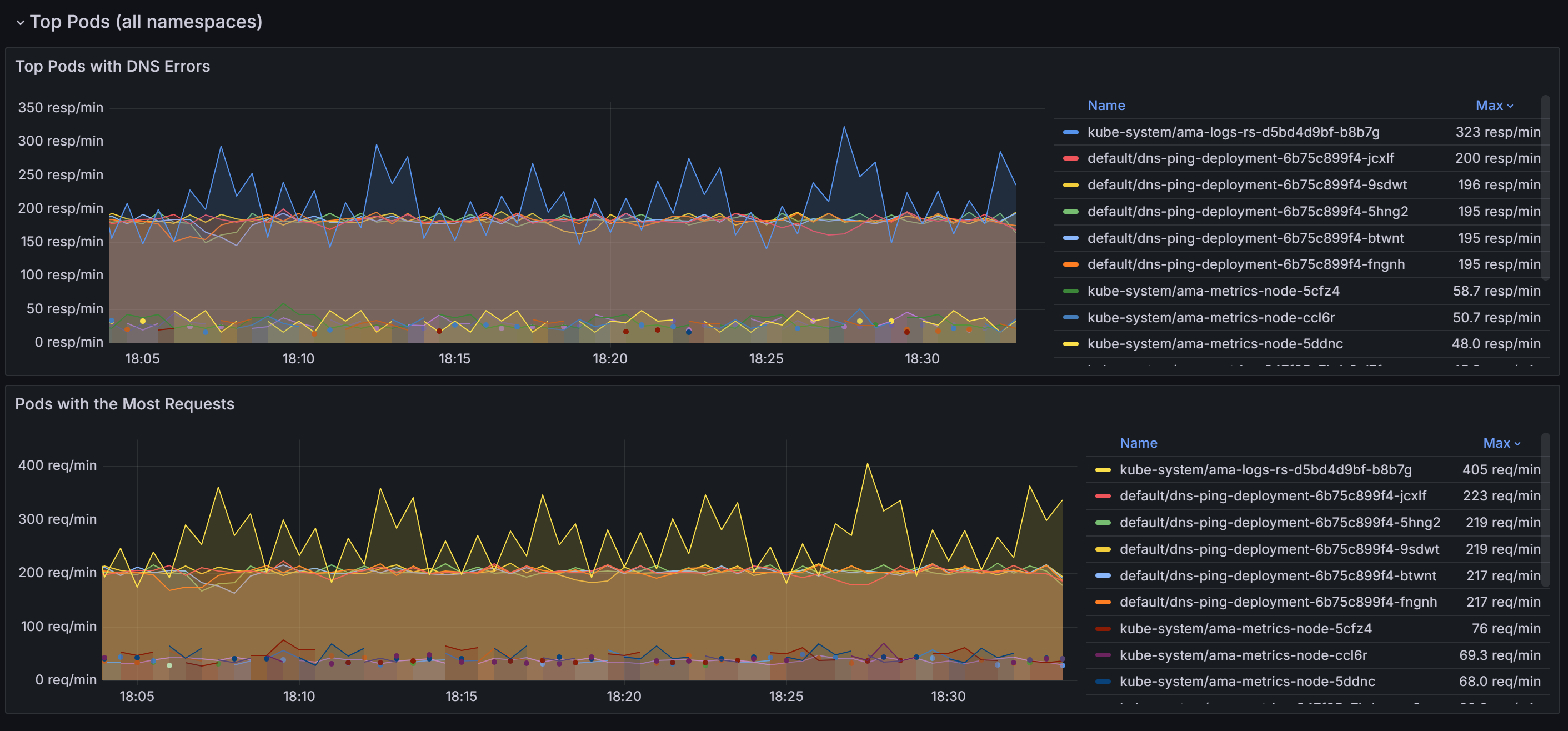
Nachdem Sie die Pods identifiziert haben, die die meisten DNS-Probleme verursachen, können Sie sich weiter in das DNS-Workload-Dashboard einsteigen, um eine genauere Ansicht zu erhalten. Durch das Korrelieren von Daten über verschiedene Bereiche im Dashboard können Sie die Ursachen der Probleme systematisch eingrenzen.
In den Abschnitten DNS-Anforderungen und DNS-Antworten können Sie Trends identifizieren, z. B. einen plötzlichen Rückgang der Antwortraten oder eine Zunahme fehlender Antworten. Eine hohe Anzahl an fehlenden Antworten auf Anfragen % weist auf potenzielle Probleme mit dem Upstream-DNS-Server oder eine Überlastung der Anfragen hin. Im folgenden Screenshot des Beispieldashboards können Sie sehen, dass gegen etwa 15:22 plötzlich eine Zunahme der Anforderungen und Antworten eintritt.

Überprüfen Sie DNS-Fehler nach Typ und suchen Sie nach Spitzen in bestimmten Fehlertypen (z. B.
NXDOMAINfür nicht vorhandene Domänen). In diesem Beispiel gibt es eine erhebliche Zunahme der Fehler bei verweigerter Abfrage, was eine Inkonsistenz in den DNS-Konfigurationen oder nicht unterstützten Abfragen vorschlägt.
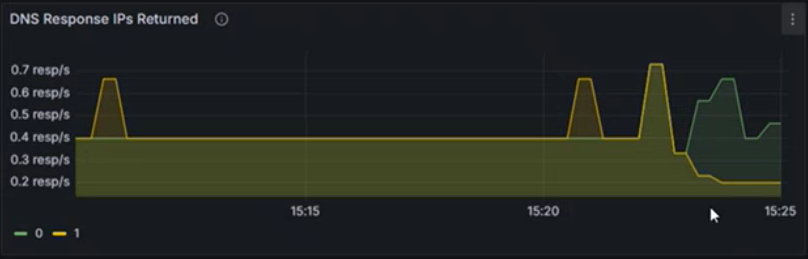
Verwenden Sie Abschnitte wie DNS-Antwort-IPs, die zurückgegeben werden , um sicherzustellen, dass erwartete Antworten verarbeitet werden. In diesem Diagramm wird die Rate erfolgreicher DNS-Abfragen angezeigt, die pro Sekunde verarbeitet wurden. Diese Informationen sind hilfreich, um zu verstehen, wie häufig DNS-Abfragen für die angegebene Workload erfolgreich aufgelöst werden.
- Eine erhöhte Rate kann auf einen Anstieg des Datenverkehrs oder einen potenziellen DNS-Angriff (z. B. Distributed Denial of Service (DDoS)) hinweisen.
- Eine verringerte Rate kann darauf hinweisen, dass es Probleme beim Erreichen des externen DNS-Servers gibt, ein CoreDNS-Konfigurationsproblem vorliegt oder eine von CoreDNS aus nicht erreichbare Workload existiert.
Das Untersuchen der am häufigsten verwendeten DNS-Abfragen kann dabei helfen, Muster im Netzwerkdatenverkehr zu identifizieren. Diese Informationen sind hilfreich, um die Workloadverteilung zu verstehen und ungewöhnliche oder unerwartete Abfrageverhalten zu erkennen, die möglicherweise Aufmerksamkeit erfordern.

Die DNS-Antworttabelle hilft Ihnen bei der Analyse der Ursachen für DNS-Probleme, indem Abfragetypen, Antworten und Fehlercodes wie SERVFAIL (Serverfehler) hervorgehoben werden. Es identifiziert problematische Abfragen, Fehlermuster oder Fehlkonfigurationen. Indem Sie Trends in Rückgabecodes und Antwortraten beobachten, können Sie bestimmte Knoten, Workloads oder Abfragen anheften, die DNS-Störungen oder Anomalien verursachen.
Im folgenden Beispiel können Sie sehen, dass für AAAA (IPV6)-Einträge kein Fehler auftritt, aber es gibt einen Serverfehler mit einem A-Eintrag (IPV4). Manchmal ist der DNS-Server möglicherweise so konfiguriert, dass IPv6 über IPv4 priorisiert wird. Dies kann zu Situationen führen, in denen IPv6-Adressen korrekt zurückgegeben werden, aber IPv4-Adressen auf Probleme stoßen.

Wenn bestätigt wird, dass ein DNS-Problem vorliegt, identifiziert das folgende Diagramm die zehn wichtigsten Endpunkte, die DNS-Fehler in einer bestimmten Workload oder einem bestimmten Namespace verursachen. Sie können dies verwenden, um die Problembehandlung bestimmter Endpunkte zu priorisieren, Fehlkonfigurationen zu erkennen oder Netzwerkprobleme zu untersuchen.









Schritt 2: Debugging der DNS-Auflösung eines Pods mit Hubble-Flowprotokollen
Sie können das Hubble CLI-Tool nutzen, um Abläufe in Echtzeit zu prüfen. Vom letzten Schritt des vorherigen Abschnitts ausgehend hätten Sie eine Liste der Pods, die die meisten DNS-Fehler verursachen. Anschließend können Sie den
hubble observeBefehl verwenden, um DNS-Flüsse auf jedem Pod anzuzeigen. Dieser Befehl filtert DNS-bezogenen Datenverkehr für den angegebenen Pod mit Details wie DNS-Abfragen, Antworten und Latenz.hubble observe --dns --pod <pod-name>In der folgenden Beispielausgabe können Sie sehen, dass die Abfrage abgelehnt wird:
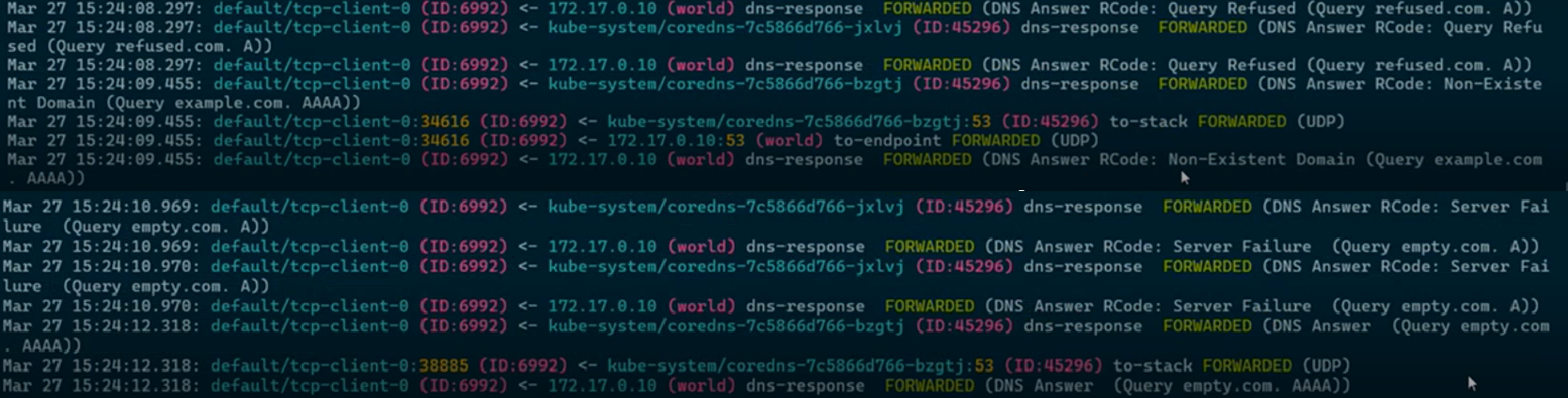
Hubble-Protokolle bieten detaillierte Einblicke in DNS-Abfragen und deren Antworten, die ihnen helfen können, DNS-bezogene Probleme zu diagnostizieren und zu beheben. Jeder Protokolleintrag enthält Informationen wie den Abfragetyp (z. B. A oder AAAA), den abgefragten Domänennamen, den DNS-Antwortcode (z. B. "Abfrage verweigert", "Nicht vorhandene Domäne" oder "Serverfehler") sowie die Quelle und das Ziel der DNS-Anforderung.
Identifizieren Sie den Abfragestatus: Überprüfen Sie das Feld "DNS Answer RCode " auf Antworten wie "Abgelehnte Abfrage " oder "*Serverfehler", was Probleme mit dem DNS-Server oder der Konfiguration angibt.
Überprüfen Sie die abgefragte Domäne: Stellen Sie sicher, dass der aufgeführte Domänenname (z. B. example.com) korrekt ist und vorhanden ist. Vergewissern Sie sich bei Nicht vorhandenen Domänenfehlern , dass die Domäne gültig und aufgelöst werden kann.
Nachverfolgen des Weiterleitungsverhaltens: Überprüfen Sie die Weiterleitungsdetails, um zu verstehen, ob die Abfrage erfolgreich an den DNS-Server oder Endpunkt weitergeleitet wurde. Unterbrechungen in diesem Prozess können auf Netzwerk- oder Konfigurationsprobleme hinweisen.
Analysieren Sie Zeitstempel: Verwenden Sie Zeitstempel, um bestimmte DNS-Probleme mit anderen Ereignissen in Ihrem System zu korrelieren, um eine umfassende Diagnose zu erhalten.
Kreuzüberprüfungs-IDs: Stimmen Sie die ID-Felder für Anforderungen und Antworten ab, um die Kontinuität sicherzustellen und anomalien bei der Abfrageverarbeitung zu überprüfen.

Schritt 3: Visualisieren von Abhängigkeiten mithilfe von Hubble-Dienstdiagrammen
Das Hubble UI-Dienstdiagramm ergänzt CLI-Einblicke durch die Visualisierung von DNS-bezogenen Datenverkehr und Abhängigkeiten. Das Filtern des Dienstdiagramms für DNS-Datenverkehr auf den betroffenen Knoten zeigt Folgendes an:
- Welche Pods oder Dienste hohe Mengen von DNS-Abfragen senden.
- Der Datenverkehr zu CoreDNS oder externen DNS-Diensten.
- Verworfene Paketflows, häufig rot markiert.

Mit den kombinierten Funktionen der Grafana-Dashboards, Hubble CLI und Hubble UI können Sie DNS-Probleme identifizieren und die Ursachenanalyse effektiv durchführen.
Anwendungsfall 2: Identifizieren von Paketverlusten auf Cluster- und Podebene aufgrund falsch konfigurierter Netzwerkrichtlinien oder Netzwerkkonnektivitätsprobleme
Konnektivitäts- und Netzwerkrichtlinienerzwingungsprobleme ergeben sich häufig aus falsch konfigurierten Kubernetes-Netzwerkrichtlinien, inkompatiblen CNI-Plug-Ins (Container Network Interface), überlappenden IP-Bereichen oder Beeinträchtigung der Netzwerkkonnektivität. Solche Probleme können die Anwendungsfunktionalität stören, was zu Dienstausfällen und beeinträchtigten Benutzeroberflächen führt.
Wenn ein Paketabbruch auftritt, erfassen eBPF-Programme das Ereignis und generieren Metadaten zu dem Paket, einschließlich der Abbruchursache und des betreffenden Ortes. Diese Daten werden von einem Benutzerraumprogramm verarbeitet, das die Informationen analysiert und in Prometheus-Metriken konvertiert. Diese Metriken bieten wichtige Einblicke in die Ursachen von Paketabbrüchen, sodass Administratoren Probleme wie Netzwerkrichtlinienfehler effektiv identifizieren und beheben können.
Zusätzlich zu Richtlinienerzwingungsproblemen können Netzwerkkonnektivitätsprobleme aufgrund von Faktoren wie TCP-Fehlern oder Erneutes Übertragen zu Paketverlusten führen. Administratoren können diese Probleme debuggen, indem sie TCP-Retransmissionstabellen und Fehlerprotokolle analysieren, die dazu beitragen, beeinträchtigte Netzwerkverbindungen oder Engpässe zu identifizieren. Durch die Nutzung dieser detaillierten Metriken und Debuggingtools können Teams einen reibungslosen Netzwerkbetrieb sicherstellen, Ausfallzeiten reduzieren und eine optimale Anwendungsleistung gewährleisten.
Angenommen, Sie verfügen über eine mikroservicesbasierte Anwendung, bei der der Frontend-Pod aufgrund einer übermäßig restriktiven Netzwerkrichtlinie, die eingehenden Datenverkehr blockiert, nicht mit einem Back-End-Pod kommunizieren kann.
Schritt 1: Untersuchen von Löschungsmetriken auf Grafana-Dashboards
Falls es zu Paketverlusten kommt, beginnen Sie Ihre Untersuchung mit dem Dashboard Podflows (Namespace). Dieses Dashboard verfügt über Panels, die dabei helfen, Namespaces mit den höchsten Verlusten zu identifizieren und anschließend die Pods innerhalb dieser Namespaces, die die höchsten Verluste verzeichnen. Sehen Sie sich beispielsweise das Wärmebild der ausgehenden Verluste für Topquellpods oder für Topzielpods an, um zu ermitteln, welche Pods am stärksten betroffen sind. Hellere Farben deuten auf höhere Verlustraten hin. Ziehen Sie Vergleiche über die Zeit hinweg, um Muster oder Spitzen in bestimmten Pods zu erkennen.
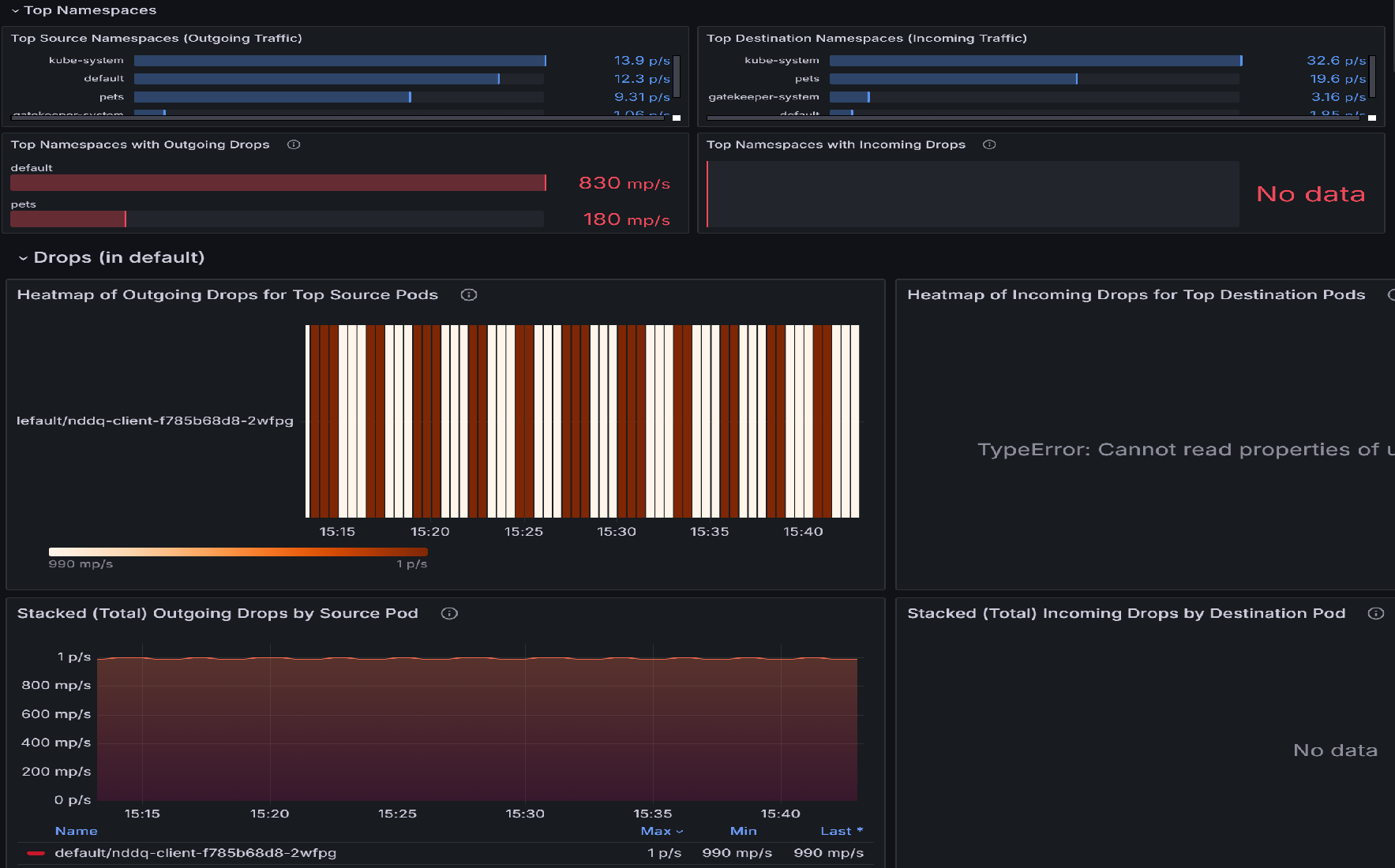
Sobald die Toppods mit den höchsten Verlusten identifiziert wurden, wechseln Sie zum Dashboard Verluste (Workload). Sie können dieses Dashboard verwenden, um Netzwerkverbindungsprobleme zu diagnostizieren, indem Sie Muster in ausgehenden Datenverkehrsabbrüchen aus bestimmten Pods identifizieren. Die Visualisierungen heben hervor, welche Pods die meisten Verluste verzeichnen, die Rate dieser Verluste und die Gründe dafür, z. B. Richtlinienablehnungen. Durch die Korrelierung von Spitzen bei Verlustraten mit bestimmten Pods oder Zeitrahmen können Sie Fehlkonfigurationen, überlastete Dienste oder Richtlinienerzwingungsprobleme eingrenzen, die möglicherweise die Konnektivität stören.
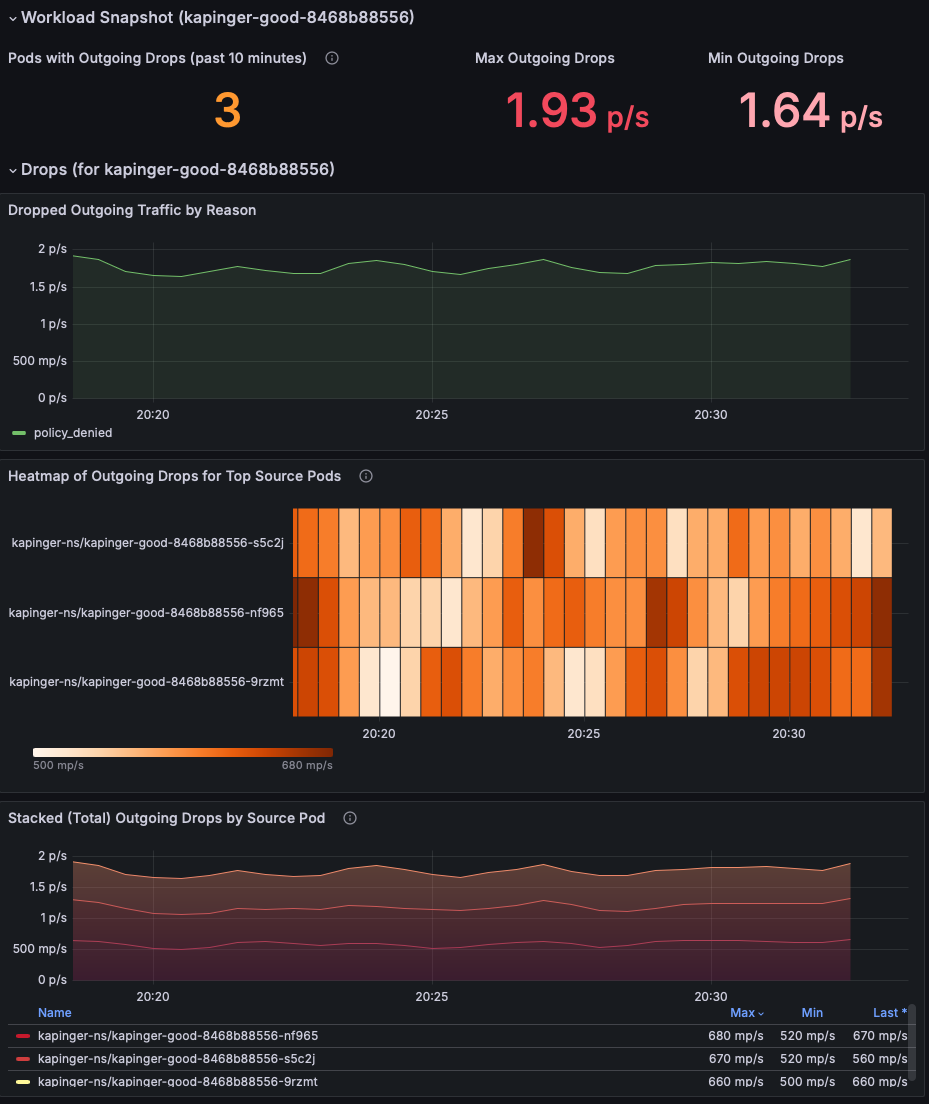
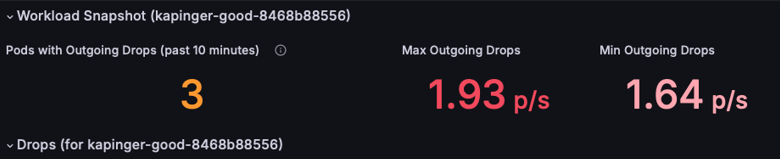
Überprüfen Sie den Abschnitt Workload-Momentaufnahme, um Pods mit ausgehenden Paketverlusten zu identifizieren. Konzentrieren Sie sich auf die Metriken "Max Outgoing Drops " und "Min Outgoing Drops ", um den Schweregrad des Problems zu verstehen (dieses Beispiel zeigt 1,93 Pakete/Sek.). Priorisieren Sie die Untersuchung von Pods mit konsequent hohen Paketverlustquoten.
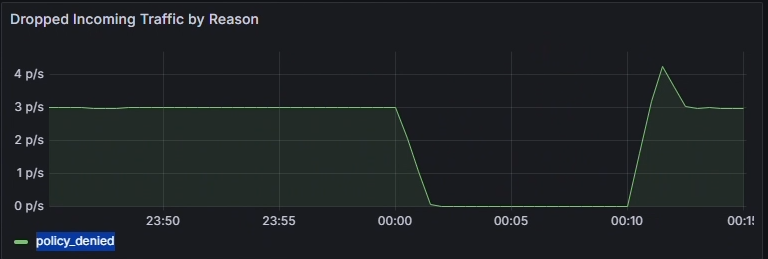
Verwenden Sie das Diagramm Verworfener eingehender/ausgehender Datenverkehr nach Grund, um die Ursache der Abbrüche zu identifizieren. In diesem Beispiel wird die Richtlinie verweigert, was darauf hinweist, dass falsch konfigurierte Netzwerkrichtlinien den ausgehenden Datenverkehr blockieren. Überprüfen Sie, ob ein bestimmtes Zeitintervall einen Spitzenwert bei den Verlusten anzeigt, um den Beginn des Problems einzugrenzen.
Verwenden Sie das Wärmebild der eingehenden Verluste für Topquell-/-zielpods, um festzustellen, welche Pods am stärksten betroffen sind. Hellere Farben deuten auf höhere Abnahmeraten hin. Ziehen Sie Vergleiche über die Zeit hinweg, um Muster oder Spitzen in bestimmten Pods zu erkennen.
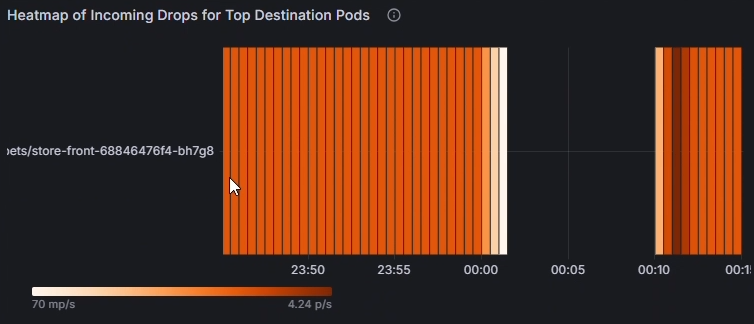
Verwenden Sie das Diagramm Gestapelte ausgehende/eingehende Verluste (Summe) nach Quellpod, um Verlustraten für betroffene Pods zu vergleichen. Identifizieren Sie, ob bestimmte Pods konsistent höhere Verluste aufweisen (z. B. kapinger-bad-6659b89fd8-zjb9k bei 26,8 p/s). Hier bezieht sich p/s auf die Anzahl von verworfenen Paketen pro Sekunde. Vergleichen Sie diese Pods mit ihren Workloads, Labels und Netzwerkrichtlinien, um potenzielle Fehlkonfigurationen zu diagnostizieren.






Schritt 2: Untersuchen mit Hubble CLI
Mithilfe der Hubble CLI können Sie Paketverluste identifizieren, die durch falsch konfigurierte Netzwerkrichtlinien mit detaillierten Echtzeitdaten verursacht werden. Hubble CLI bietet präzise Einblicke in Echtzeit in verworfene Pakete. Indem Sie den Datenverkehr beobachten, sich auf durch Richtlinien verweigerte Verluste konzentrieren und Muster analysieren, können Sie die falsch konfigurierten Netzwerkrichtlinien identifizieren und die Korrekturen überprüfen.

Schritt 3: Beobachten der Hubble-Benutzeroberfläche
Ein weiteres nützliches Tool ist die Hubble-Benutzeroberfläche, die eine visuelle Darstellung von Datenverkehrsflüssen innerhalb eines Namespace bietet. Beispielsweise zeigt die Benutzeroberfläche im Agnhost-Namespace Interaktionen zwischen Pods innerhalb desselben Namespaces, Pods in anderen Namespaces und sogar Paketen an, die von außerhalb des Clusters stammen. Darüber hinaus hebt die Schnittstelle verworfene Pakete hervor und stellt detaillierte Informationen bereit, z. B. die Namen der Quell- und Ziel-Pods sowie pod- und Namespacebezeichnungen. Diese Daten können dazu beitragen, die im Cluster angewendeten Netzwerkrichtlinien zu überprüfen, sodass Administratoren alle falsch konfigurierten oder problematischen Richtlinien schnell identifizieren und beheben können.

Anwendungsfall 3: Identifizieren von Datenverkehrsungleichgewichten innerhalb von Workloads und Namespaces
Datenverkehrsungleichgewichte treten auf, wenn bestimmte Pods oder Dienste innerhalb einer Workload oder eines Namespaces im Vergleich zu anderen einen unverhältnismäßig hohen Netzwerkdatenverkehr verarbeiten. Dies kann zu Ressourcenkonflikten, beeinträchtigter Leistung für überlastete Pods und einer unzureichenden Nutzung anderer führen. Solche Ungleichgewichte entstehen häufig aufgrund falsch konfigurierter Dienste, ungleichmäßiger Datenverkehrsverteilung durch Lastenausgleichsgeber oder unvorhergesehene Nutzungsmuster. Ohne Beobachtbarkeit ist es schwierig festzustellen, welche Pods oder Namespaces überlastet oder wenig genutzt sind. Advanced Container Networking Services kann helfen, indem sie Echtzeitdatenverkehrsmuster auf Pod-Ebene überwacht und Metriken zur Bandbreitennutzung, zu Anforderungsraten und zur Latenz bereitstellt, wodurch das Identifizieren von Ungleichgewichten erleichtert wird.
Angenommen, Sie haben eine Online-Einzelhandelsplattform, die auf einem AKS-Cluster ausgeführt wird. Die Plattform besteht aus mehreren Microservices, einschließlich eines Produktsuchdiensts, eines Benutzerauthentifizierungsdiensts und eines Auftragsverarbeitungsdiensts, der alle im selben Namespace bereitgestellt wird. Während eines saisonalen Verkaufs erlebt der Produktsuchdienst einen Anstieg des Datenverkehrs, während die anderen Dienste im Leerlauf bleiben. Der Lastenausgleich leitet versehentlich mehr Anforderungen an eine Teilmenge von Pods innerhalb der Produktsuchebereitstellung weiter, was zu Überlastung und erhöhter Latenz für Suchabfragen führt. In der Zwischenzeit sind andere Pods in derselben Bereitstellung nicht ausgelastet.
Schritt 1. Untersuchen von Poddatenverkehr mit dem Grafana-Dashboard
Sehen Sie sich das Pod Flows (Workload)-Dashboard an. Die Workload-Momentaufnahme zeigt verschiedene Statistiken wie ausgehenden und eingehenden Datenverkehr sowie ausgehende und eingehende Verluste an.

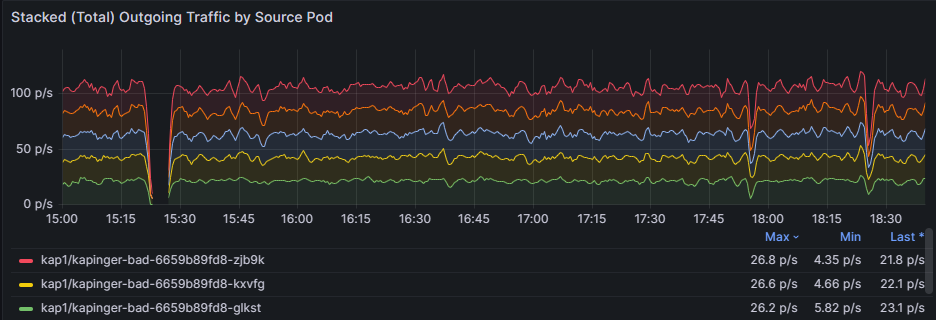
Untersuchen Sie die Schwankungen des Verkehrs für jeden Tracetyp. Erhebliche Abweichungen in den blauen und grünen Linien deuten auf Änderungen im Verkehrsvolumen für Anwendungen und Dienste hin, die zu einer Überlastung beitragen könnten. Durch die Identifizierung von Zeiträumen mit hohem Datenverkehr können Sie Stauzeiten ermitteln und weitere Untersuchungen durchführen. Vergleichen Sie außerdem die Muster des ausgehenden und eingehenden Datenverkehrs. Wenn ein erhebliches Ungleichgewicht zwischen ausgehendem und eingehendem Datenverkehr besteht, kann es auf Netzwerküberlastungen oder Engpässe hinweisen.

Die Diagramme stellen Datenverkehrsflussmetriken auf pod-Ebene innerhalb eines Kubernetes-Clusters dar. Die Heatmap des ausgehenden Datenverkehrs für Top-Quell-Pods zeigt den ausgehenden Datenverkehr von den obersten 10 Quell-Pods an, während die Heatmap des eingehenden Datenverkehrs für Top-Ziel-Pods den eingehenden Datenverkehr an die obersten 10 Ziel-Pods anzeigt. Die Farbintensität zeigt das Verkehrsaufkommen an, wobei dunklere Schattierungen ein höheres Verkehrsaufkommen darstellen. Konsistente Muster heben Pods hervor, die einen signifikanten Datenverkehr generieren oder empfangen, z. B. standard/tcp-client-0, die als zentraler Knoten fungieren können.
Dieses Wärmebild zeigt, dass höherer Datenverkehr empfangen wird und aus dem einzelnen Pod ausgeht. Wenn derselbe Pod (z. B. default/tcp-client-0) in beiden Heatmaps mit hoher Datenverkehrsintensität angezeigt wird, könnte dies darauf hindeuten, dass er sowohl ein hohes Datenverkehrsvolumen sendet als auch empfängt und möglicherweise als zentraler Knoten in der Workload fungiert. Variationen der Netzwerkauslastung zwischen den Pods deuten möglicherweise auf eine ungleiche Datenverkehrsverteilung hin, wobei einige Pods unverhältnismäßig mehr Datenverkehr verarbeiten als andere.

Die Überwachung des TCP-Reset-Verkehrs ist entscheidend für das Verständnis des Netzwerkverhaltens, die Fehlerbehebung, die Gewährleistung der Sicherheit und die Optimierung der Anwendungsleistung. Es bietet wertvolle Einblicke in die Verwaltung und Beendigung von Verbindungen, sodass Netzwerk- und Systemadministratoren eine gesunde, effiziente und sichere Umgebung erhalten. Diese Metriken zeigen, wie viele Pods aktiv an dem Senden oder Empfangen von TCP RST-Paketen beteiligt sind, wodurch instabile Verbindungen oder falsch konfigurierte Pods signalisiert werden können, was zu Einer Netzwerküberlastung führt. Hohe Rücksetzungsraten deuten darauf hin, dass Pods möglicherweise durch Verbindungsversuche überlastet werden oder Ressourcenengpässe erleben.

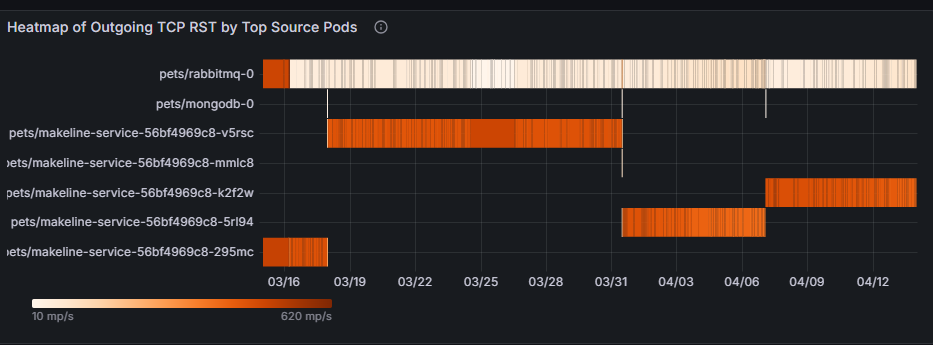
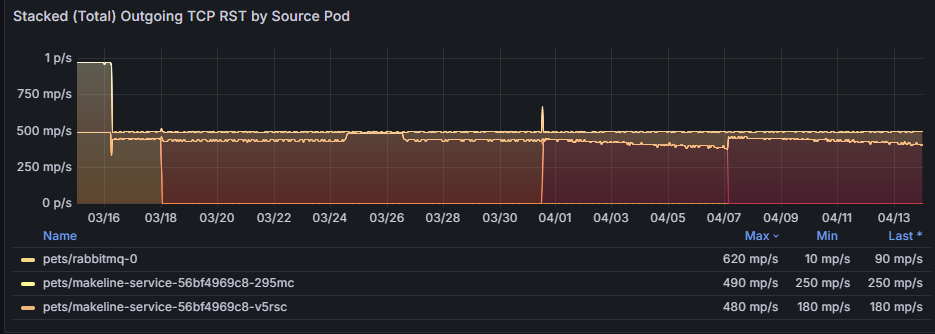
Das Wärmebild der ausgehenden TCP RST-Pakete nach Topquellpods zeigt, welche Quellpods die meisten TCP RST-Pakete generieren und wann es Aktivitätsspitzen gibt. Wenn pets/rabbitmq-0 in dem Beispiel einer Heatmap während Spitzenzeiten konsistent hohe ausgehende Resets zeigt, könnte dies darauf hindeuten, dass die Anwendung oder ihre zugrunde liegenden Ressourcen (CPU, Arbeitsspeicher) überlastet sind. Die Lösung könnte sein, die Konfiguration der Pods zu optimieren, Ressourcen zu skalieren oder Datenverkehr gleichmäßig über Replikate hinweg zu verteilen.
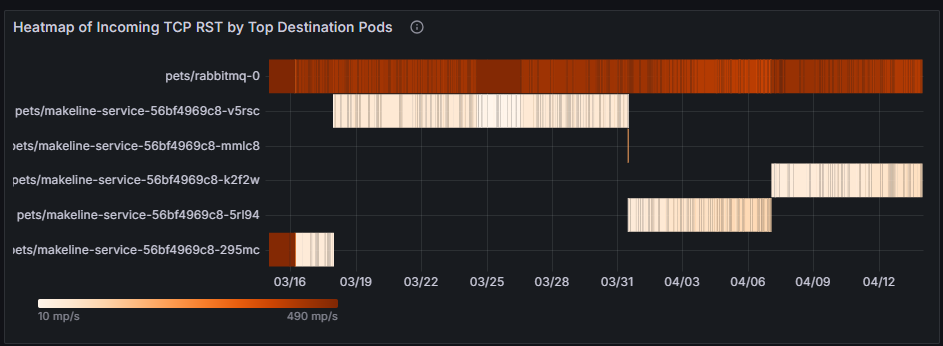
Die Heatmap der eingehenden TCP RST-Pakete bei den Top-Ziel-Pods identifiziert Ziel-Pods, die die meisten TCP RST-Pakete empfangen und auf potenzielle Engpässe oder Verbindungsprobleme bei diesen Pods hinweisen. Wenn Haustiere/Mongodb-0 häufig RST-Pakete empfangen, kann es sich um einen Indikator für überlastete Datenbankverbindungen oder fehlerhafte Netzwerkkonfigurationen handeln. Die Lösung könnte sein, die Datenbankkapazität zu erhöhen, Ratelimitierung zu implementieren oder upstream-Workloads zu untersuchen, die zu übermäßigen Verbindungen führen.
Das Diagramm Gestapelte ausgehende TCP RST-Pakete (Summe) nach Quellpod bietet eine aggregierte Ansicht ausgehender Zurücksetzungen im Lauf der Zeit, wobei Trends oder Anomalien hervorgehoben werden.
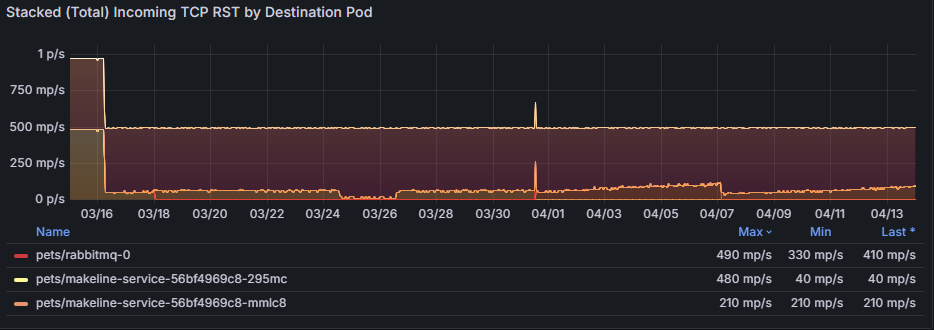
Das Diagramm Gestapelte eingehende TCP RST-Pakete (Summe) nach Zielpod aggregiert eingehende Rücksetzungen und zeigt, wie sich Netzwerküberlastungen auf Zielpods auswirken. Beispielsweise könnte eine anhaltende Zunahme der Resets für pets/rabbitmq-0 darauf hindeuten, dass dieser Dienst den eingehenden Verkehr nicht effektiv bewältigen kann, was zu Timeouts führt.








Anwendungsfall 4: Echtzeitüberwachung der Netzwerkintegrität und Leistung des Clusters
Die Darstellung der Netzwerkintegritätsmetriken eines Clusters auf hoher Ebene ist unerlässlich, um die Gesamtstabilität und Leistung des Systems sicherzustellen. Allgemeine Metriken bieten einen schnellen und umfassenden Überblick über die Netzwerkleistung des Clusters, sodass Administratoren potenzielle Engpässe, Fehler oder Ineffizienzen problemlos erkennen können, ohne detaillierte Details einzutauchen. Diese Metriken, z. B. Latenz, Durchsatz, Paketverlust und Fehlerraten, bieten eine Momentaufnahme der Integrität des Clusters, wodurch proaktive Überwachung und schnelle Problembehandlung ermöglicht werden.
Wir verfügen über ein Beispieldashboard, das die allgemeine Integrität des Clusters darstellt: Kubernetes / Networking / Clusters. Lassen Sie uns tiefer in das Gesamtdashboard eintauchen.
Identifizieren Von Netzwerkengpässen: Indem Sie die weitergeleiteten Bytes und weitergeleiteten Pakete analysieren, können Sie ermitteln, ob plötzliche Tropfen oder Spitzen vorhanden sind, die potenzielle Engpässe oder Überlastungen im Netzwerk angeben.

Erkennen von Paketverlusten: Die Abschnitte " Verworfene Pakete " und " Gelöschte Bytes " helfen bei der Identifizierung, ob ein erheblicher Paketverlust innerhalb bestimmter Cluster auftritt, was auf Probleme wie fehlerhafte Hardware oder falsch konfigurierte Netzwerkeinstellungen hinweisen kann.

Überwachen von Datenverkehrsmustern: Sie können Datenverkehrsmuster im Laufe der Zeit überwachen, um normales und ungewöhnliches Verhalten zu verstehen, was bei proaktiver Problembehandlung hilft. Durch den Vergleich von Max- und Min.-Eingangsbytes und Paketen können Sie Leistungstrends analysieren und ermitteln, ob bestimmte Tageszeiten oder bestimmte Workloads leistungseinbußen verursachen.

Diagnose von Verlustgründen: Die Abschnitte Verworfene Bytes nach Grund und Verworfene Pakete nach Grund helfen dabei, die spezifischen Gründe für Paketverluste zu verstehen, z. B. Richtlinienablehnungen oder unbekannte Protokolle.

Knotenspezifische Analyse: Die Graphen für von Knoten verworfene Bytes und von Knoten verworfene Pakete bieten Einblicke, welche Knoten die meisten Paketverluste erleben. Dadurch können problematische Knoten identifiziert und Korrekturmaßnahmen ergriffen werden, um die Netzwerkleistung zu verbessern.

Verteilung von TCP-Verbindungen: Im folgenden Diagramm wird die Verteilung von TCP-Verbindungen über verschiedene Zustände hinweg bezeichnet. Wenn das Diagramm beispielsweise eine ungewöhnlich hohe Anzahl von Verbindungen im
SYN_SENTZustand anzeigt, kann es darauf hindeuten, dass die Clusterknoten Probleme beim Herstellen von Verbindungen aufgrund der Netzwerklatenz oder falsch konfiguriert haben. Andererseits könnte eine beträchtliche Anzahl von Verbindungen imTIME_WAITZustand darauf hindeuten, dass Verbindungen nicht ordnungsgemäß freigegeben werden, was möglicherweise zu Ressourcenerschöpfung führt.






Anwendungsfall 5: Diagnostizieren von Netzwerkproblemen auf Anwendungsebene
L7 Traffic Observability befasst sich mit kritischen Netzwerkproblemen auf Anwendungsebene, indem umfassende Einblicke in HTTP-, gRPC- und Kafka-Datenverkehr bereitgestellt werden. Diese Erkenntnisse helfen dabei, Probleme wie hohe Fehlerraten (z. B. 4xx clientseitige oder 5xx serverseitige Fehler), unerwartete Datenverkehrsverluste, Latenzspitzen, ungleiche Datenverkehrsverteilung über Pods hinweg und falsch konfigurierte Netzwerkrichtlinien zu erkennen. Diese Probleme treten häufig in komplexen Mikroservicearchitekturen auf, bei denen Abhängigkeiten zwischen Diensten kompliziert sind und die Ressourcenzuordnung dynamisch ist. Beispielsweise können plötzliche Zunahmen von verworfenen Kafka-Nachrichten oder verzögerten GRPC-Anrufen Engpässe bei der Nachrichtenverarbeitung oder Netzwerküberlastung signalisieren.
Angenommen, Sie haben eine E-Commerce-Plattform in einem Kubernetes-Cluster bereitgestellt, in dem der Frontend-Dienst auf mehreren Back-End-Microservices basiert, einschließlich eines Zahlungsgateways (gRPC), eines Produktkatalogs (HTTP) und eines Auftragsverarbeitungsdiensts, der über Kafka kommuniziert. Kürzlich haben Benutzer erhöhte Auscheckfehler und langsame Seitenladezeiten gemeldet. Lassen Sie uns genauer betrachten, wie wir die Ursachenanalyse dieses Problems mithilfe unserer vorkonfigurierten Dashboards für den L7-Datenverkehr durchführen können: Kubernetes/Networking/L7 (Namespaces) und Kubernetes/Networking/L7 (Workload).
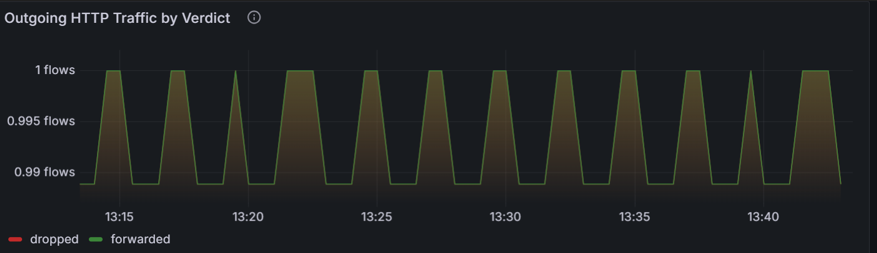
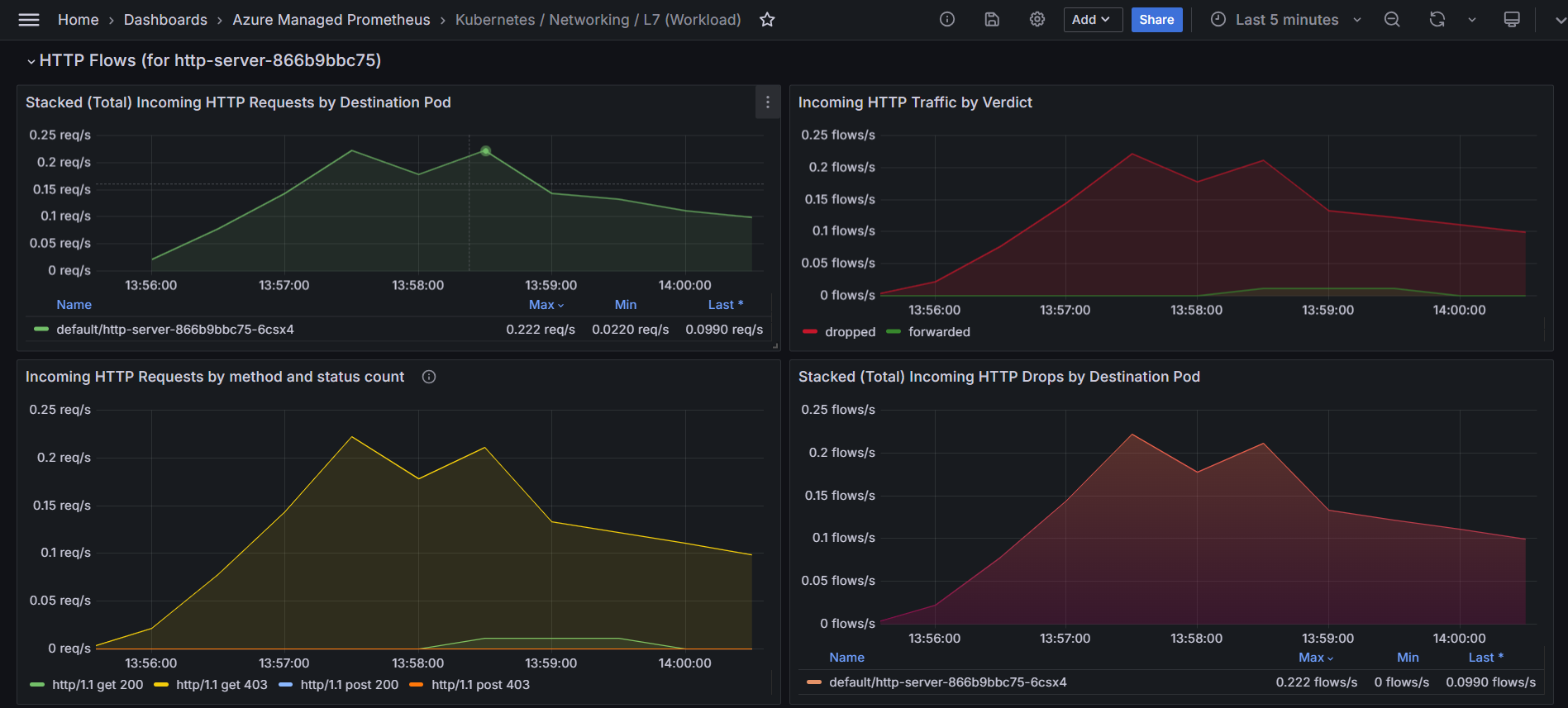
Identifizieren Sie Muster von abgelegten und weitergeleiteten HTTP-Anforderungen. Im folgenden Diagramm wird der ausgehende HTTP-Datenverkehr nach der Beurteilung segmentiert, wobei hervorgehoben wird, ob Anfragen "weitergeleitet" oder "verworfen" werden. Für die E-Commerce-Plattform kann das Diagramm potenzielle Engpässe oder Probleme im Bezahlvorgang aufdecken. Wenn es eine spürbare Zunahme der verworfenen HTTP-Flüsse gibt, kann es auf Probleme wie falsch konfigurierte Netzwerkrichtlinien, Ressourceneinschränkungen oder Konnektivitätsprobleme zwischen dem Frontend- und Back-End-Dienst hinweisen. Durch die Korrelation dieses Diagramms mit bestimmten Zeitrahmen von Benutzerbeschwerden können Administratoren ermitteln, ob diese Rückgänge mit Checkout-Fehlern übereinstimmen.
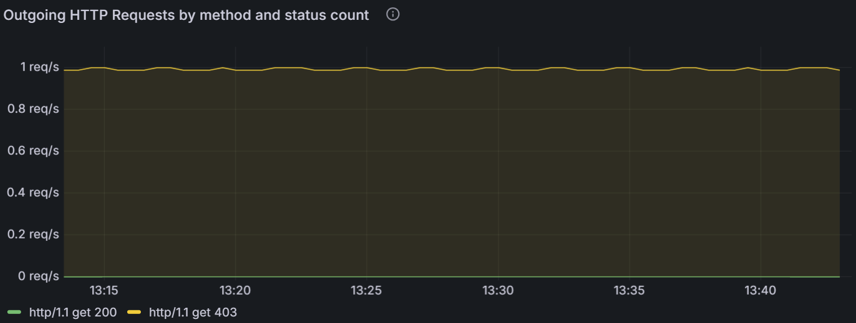
Das folgende Liniendiagramm zeigt die Rate ausgehender HTTP-Anforderungen im Laufe der Zeit, kategorisiert nach ihren Statuscodes (z. B. 200, 403). Sie können dieses Diagramm verwenden, um Spitzen in Fehlerraten (z. B. 403 Verbotene Fehler) zu identifizieren, die auf Probleme mit der Authentifizierung oder Zugriffssteuerung hinweisen können. Indem Sie diese Spitzen mit bestimmten Zeitintervallen korrelieren, können Sie die zugrunde liegenden Probleme untersuchen und beheben, z. B. falsch konfigurierte Sicherheitsrichtlinien oder serverseitige Probleme.
Diese folgende Tabelle gibt an, welche Pods ausgehende HTTP-Anforderungen aufweisen, die zu 4xx Fehlern geführt haben. Sie können diese Heatmap verwenden, um problematische Pods schnell zu identifizieren und die Ursachen für die Fehler zu untersuchen. Indem Sie diese Probleme auf Pod-Ebene angehen, können Sie die Gesamtleistung und Zuverlässigkeit ihres L7-Netzwerkverkehrs verbessern.
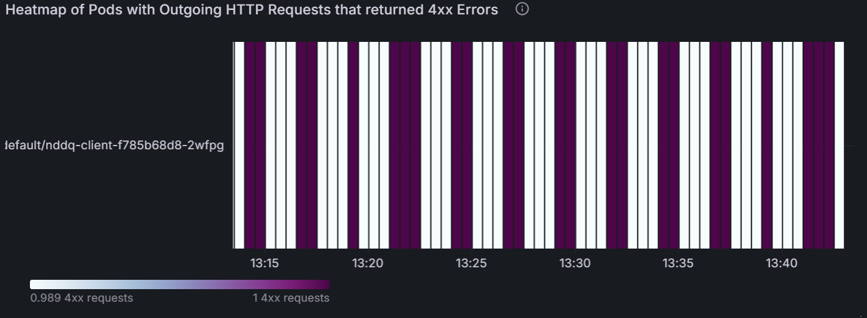
Verwenden Sie die folgenden Diagramme, um zu überprüfen, welche Pods den meisten Datenverkehr erhalten. Dadurch können überlastete Pods identifiziert werden.
- Ausgehende HTTP-Anforderungen für Top 10-Quell pods in der Standardeinstellung zeigt eine stabile Anzahl ausgehender HTTP-Anforderungen im Laufe der Zeit für die obersten zehn Quell pods an. Die Linie bleibt fast flach und zeigt einen konsistenten Verkehr ohne wesentliche Spitzen oder Einbrüche.
- Das Wärmebild der verworfenen ausgehenden HTTP-Anfragen für die 10 Topquellpods als Standard verwendet eine Farbkodierung, um die Anzahl der verworfenen Anforderungen darzustellen. Dunklere Farben deuten auf eine höhere Anzahl verworfener Anforderungen hin, während hellere Farben weniger oder keine verworfenen Anforderungen angeben. Die abwechselnden dunklen und hellen Bänder deuten auf periodische Muster in Anforderungsrückgängen hin.
Diese Diagramme bieten Ihnen wertvolle Einblicke in den Netzwerkdatenverkehr und die Leistung. Das erste Diagramm hilft Ihnen, die Konsistenz und das Volumen des ausgehenden HTTP-Datenverkehrs zu verstehen, was für die Überwachung und Aufrechterhaltung der optimalen Netzwerkleistung von entscheidender Bedeutung ist. Im zweiten Diagramm können Sie Muster oder Zeiträume identifizieren, wenn Probleme mit verworfenen Anforderungen auftreten, was für die Problembehandlung von Netzwerkproblemen oder die Optimierung der Leistung von entscheidender Bedeutung sein kann.





Faktoren, auf die man sich während der Root Cause-Analyse für Layer-7-Datenverkehr konzentrieren sollte
Verkehrsmuster und -volumen: Um Anstiege, Rückgänge oder Ungleichgewichte in der Verkehrsverteilung zu identifizieren, analysieren Sie Verkehrstrends. Überlastete Knoten oder Dienste können zu Engpässen oder verworfenen Anforderungen führen.
Fehlerraten: Verfolgen Sie die Trends bei 4xx-Fehlern (ungültige Anforderungen) und 5xx-Fehlern (Backend-Fehler). Persistente Fehler deuten auf Clientfehler oder serverseitige Ressourceneinschränkungen hin.
Verworfene Anforderungen: Untersuchen Sie Verluste auf bestimmten Pods oder Knoten. Verluste signalisieren häufig Konnektivitätsprobleme oder richtlinienbezogene Verweigerungen.
Richtlinienerzwingung und -konfiguration: Bewerten von Netzwerkrichtlinien, Dienstermittlungsmechanismen und Lastenausgleichseinstellungen für Fehlkonfigurationen.
Wärmebilder und Flowmetriken: Verwenden Sie Visualisierungen wie Wärmebilder, um stark fehlerhafte Pods oder Datenverkehrsanomalien schnell zu identifizieren.

Nächste Schritte
Weitere Informationen zu Advanced Container Networking Services für Azure Kubernetes Service (AKS) finden Sie unter Was ist Advanced Container Networking Services für Azure Kubernetes Service (AKS)?
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.

Azure Kubernetes Service