Was ist Azure Kubernetes Service (AKS) Network Observability?
Kubernetes ist ein leistungsstarkes Tool zum Verwalten von Containeranwendungen. Da containerisierte Umgebungen immer komplexer werden, kann es schwierig sein, Netzwerkprobleme in einem Kubernetes-Cluster zu identifizieren und zu beheben.
Network Observability ist ein wichtiger Bestandteil der Aufrechterhaltung eines fehlerfreien und leistungsfähigen Kubernetes-Clusters. Durch das Sammeln und Analysieren von Daten zum Netzwerkdatenverkehr können Sie Einblicke in den Betrieb Ihres Clusters gewinnen und potenzielle Probleme identifizieren, bevor sie zu Ausfällen oder Leistungseinbußen führen.
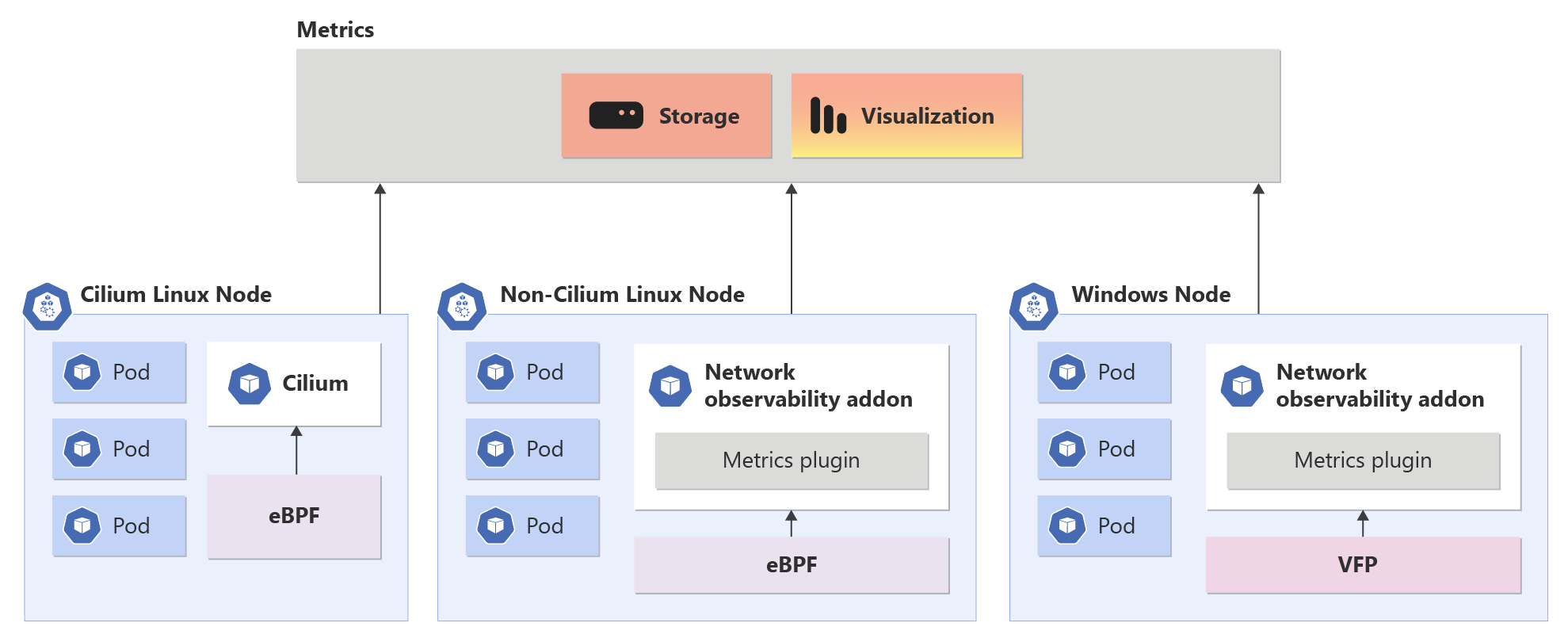
Übersicht über das Network Observability-Add-On in AKS
Das Networking Observability-Add-On funktioniert nahtlos auf Nicht-Cilium- und Cilium-Datenebenen. Kunden erhalten Funktionen für DevOps und SecOps auf Unternehmensniveau. Diese Lösung bietet eine zentrale Möglichkeit, Netzwerkprobleme in Ihrem Cluster für Clusternetzwerkadministratoren, Clustersicherheitsadministratoren und DevOps-Techniker zu überwachen.
Wenn das Network Observability-Add-On aktiviert ist, ermöglicht es die Sammlung und Konvertierung nützlicher Metriken in das Prometheus-Format, das dann in Grafana visualisiert werden kann. Azure bietet verwaltete Dienste für Prometheus und Grafana an.
Von Azure verwaltetes Prometheus und Grafana: Ein von Azure bereitgestellter verwalteter Dienst, der sich um die Infrastruktur und Wartung von Prometheus und Grafana kümmert, damit Sie sich auf die Konfiguration und Visualisierung Ihrer Metriken konzentrieren können.
Multi CNI-Unterstützung: Das Add-on Network Observability unterstützt sowohl Azure CNI als auch Kubenet Netzwerk-Plugins.
Metriken
Das Add-On "Network Observability" unterstützt derzeit nur Metriken auf Knotenebene. Cilium- und Non-Cilium-Datenpläne weisen unterschiedliche Metriken auf, doch das Grafana-Dashboard funktioniert nahtlos für beide.
Alle Metriken weisen die folgenden Bezeichnungen auf:
clusterinstance(Knotenname)
Bei Nicht-Cilium-Datenplanen stellt das Add-On "Network Observability" Metriken sowohl auf Linux- als auch auf Windows-Plattformen bereit. Die folgende Tabelle gibt einen Überblick über die verschiedenen generierten Metriken.
| Metrikname | Beschreibung | Zusätzliche Bezeichnungen | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | Gesamtzahl der weitergeleiteten Pakete | direction |
✅ | ✅ |
| networkobservability_forward_bytes | Gesamtanzahl weitergeleiteter Byte | direction |
✅ | ✅ |
| networkobservability_drop_count | Gesamtzahl der gelöschten Pakete | direction, reason |
✅ | ✅ |
| networkobservability_drop_bytes | Gesamtanzahl der gelöschten Byte | direction, reason |
✅ | ✅ |
| networkobservability_tcp_state | Anzahl der derzeit aktiven TCP-Sockets nach TCP-Status. | state |
✅ | ✅ |
| networkobservability_tcp_connection_remote | Anzahl der derzeit aktiven TCP-Sockets nach Remote-IP/Port. | address (IP), port |
✅ | ❌ |
| networkobservability_tcp_connection_stats | TCP-Verbindungsstatistiken. (z. B. Delayed ACKs, TCPKeepAlive, TCPSackFailures) | statistic |
✅ | ✅ |
| networkobservability_tcp_flag_counters | Anzahl der TCP-Pakete nach Flag. | flag |
❌ | ✅ |
| networkobservability_ip_connection_stats | TCP-Verbindungsstatistiken. | statistic |
✅ | ❌ |
| networkobservability_udp_connection_stats | UDP-Verbindungsstatistiken. | statistic |
✅ | ❌ |
| networkobservability_udp_active_sockets | Anzahl der derzeit aktiven UDP-Sockets | ✅ | ❌ | |
| networkobservability_interface_stats | Schnittstellenstatistiken. | InterfaceName, statistic |
✅ | ✅ |
Begrenzungen
- Metriken auf Podebene werden nicht unterstützt.
Skalieren
Bei Verwendung von Azure verwalteten Prometheus und Grafana gelten bestimmte Skalierungseinschränkungen. Weitere Informationen finden Sie unter Scrape Prometheus-Metriken im großen Stil in Azure Monitor.
Nächste Schritte
Weitere Informationen zu Azure Kubernetes Service (AKS) finden Sie unter Was ist Azure Kubernetes Service (AKS)?.
Informationen zum Erstellen eines AKS-Clusters mit Network Observability und von Azure verwaltetem Prometheus und Grafana finden Sie unter Einrichten von Network Observability für Azure Kubernetes Service (AKS) – von Azure verwaltetes Prometheus und Grafana.

Azure Kubernetes Service