Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Leitfaden wird veranschaulicht, wie Sie die Resilienz eines Valkey-Clusters überprüfen, der auf Azure Kubernetes Service (AKS) mithilfe des Locust-Lastentestframeworks bereitgestellt wird. Es führt sie durch die Erstellung eines Testclients, die Bereitstellung in AKS, das Simulieren von Fehlern und das Analysieren des Clusterverhaltens.
Hinweis
Dieser Artikel enthält Verweise auf den Begriff 'Master' (primär), ein Begriff, den Microsoft nicht mehr verwendet. Wenn der Begriff aus der Valkey-Software entfernt wird, entfernen wir ihn aus diesem Artikel.
Erstellen einer Beispielclientanwendung für Valkey
Die folgenden Schritte zeigen, wie Sie eine Beispielclientanwendung für Valkey erstellen.
Die Beispielclientanwendung verwendet das Locust Load Testing Framework , um eine Workload auf dem von Ihnen konfigurierten und bereitgestellten Valkey-Cluster zu simulieren. Der Python-Code implementiert eine Locust User-Klasse , die eine Verbindung mit dem Valkey-Cluster herstellt und einen Set- und Get-Vorgang ausführt. Sie können diese Klasse erweitern, um komplexere Vorgänge zu implementieren.
Hinweis
Es wird empfohlen, den sichersten Authentifizierungsfluss zu verwenden, der verfügbar ist. Der in diesem Verfahren beschriebene Authentifizierungsfluss erfordert ein sehr hohes Vertrauen in die Anwendung und trägt Risiken, die in anderen Flüssen nicht vorhanden sind. Sie sollten diesen Fluss nur verwenden, wenn andere sicherere Flüsse, z. B. verwaltete Identitäten, nicht lebensfähig sind.
Erstellen Sie die Dockerfile-Datei , und
requirements.txtplatzieren Sie sie in einem neuen Verzeichnis mit den folgenden Befehlen:mkdir valkey-client cd valkey-client cat > Dockerfile <<EOF FROM python:3.10-slim-bullseye COPY requirements.txt . COPY locustfile.py . RUN pip install --upgrade pip && pip install --no-cache-dir -r requirements.txt EOF cat > requirements.txt <<EOF valkey locust EOFErstellen Sie die
locustfile.pyDatei, die den Valkey-Clientanwendungscode enthält:cat > locustfile.py <<EOF import time from locust import between, task, User, events,tag, constant_throughput from valkey import ValkeyCluster from random import randint class ValkeyLocust(User): wait_time = constant_throughput(50) host = "valkey-cluster.valkey.svc.cluster.local" def __init__(self, *args, **kwargs): super(ValkeyLocust, self).__init__(*args, **kwargs) self.client = ValkeyClient(host=self.host) def on_stop(self): self.client.close() @task @tag("set") def set_value(self): self.client.set_value("set_value") @task @tag("get") def get_value(self): self.client.get_value("get_value") class ValkeyClient(object): def __init__(self, host, *args, **kwargs): super().__init__(*args, **kwargs) with open("/etc/valkey-password/valkey-password-file.conf", "r") as f: self.password = f.readlines()[0].split(" ")[1].strip() self.host = host self.vc = ValkeyCluster(host=self.host, port=6379, password=self.password, username="default", cluster_error_retry_attempts=0, socket_timeout=2, keepalive=1 ) def set_value(self, key, command='SET'): start_time = time.perf_counter() try: result = self.vc.set(randint(0, 1000), randint(0, 1000)) if not result: result = '' length = len(str(result)) total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=length, ) except Exception as e: total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=0, exception=e ) result = '' return result def get_value(self, key, command='GET'): start_time = time.perf_counter() try: result = self.vc.get(randint(0, 1000)) if not result: result = '' length = len(str(result)) total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=length, ) except Exception as e: total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=0, exception=e ) result = '' return result EOF
Erstellen und Übertragen des Docker-Images in das ACR
Erstellen Sie das Docker-Image, und laden Sie es mithilfe des
az acr buildBefehls in azure Container Registry (ACR) hoch.az acr build --image valkey-client --registry ${MY_ACR_REGISTRY} .Überprüfen Sie, ob das Bild erfolgreich mithilfe des
az acr repository listBefehls verschoben wurde.az acr repository list --name ${MY_ACR_REGISTRY} --output tableDie Ausgabe sollte das
valkey-clientBild wie im folgenden Beispiel anzeigen:Result ---------------- valkey-client
Stellen Sie den Beispielclient-Pod in AKS bereit
Erstellen Sie ein
Pod, das das im vorherigen Schritt erstellte Valkey-Client-Image verwendet, indem Sie den Befehlkubectl applyverwenden. Die Pod-Spezifikation enthält das Geheimnisspeicher-CSI-Volume mit dem Valkey-Kennwort, das der Client für die Verbindung zum Valkey-Cluster verwendet.kubectl apply -f - <<EOF --- kind: Pod apiVersion: v1 metadata: name: valkey-client namespace: valkey spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: agentpool operator: In values: - nodepool1 containers: - name: valkey-client image: ${MY_ACR_REGISTRY}.azurecr.io/valkey-client command: ["locust", "--processes", "4"] volumeMounts: - name: valkey-password mountPath: "/etc/valkey-password" volumes: - name: valkey-password csi: driver: secrets-store.csi.k8s.io readOnly: true volumeAttributes: secretProviderClass: "valkey-password" EOFPortieren Sie den Port 8089, um auf die Locust-Weboberfläche auf Ihrem lokalen Rechner zuzugreifen, indem Sie den Befehl
kubectl port-forwardverwenden.kubectl port-forward -n valkey valkey-client 8089:8089Greifen Sie auf die Locust-Webschnittstelle bei
http://localhost:8089zu, und starten Sie den Test. Sie können die Anzahl der Benutzer und die Spawnrate anpassen, um einen Workload auf dem Valkey-Cluster zu simulieren. Die folgende Grafik geht von 100 Benutzern und einer Spawnrate von 10 aus: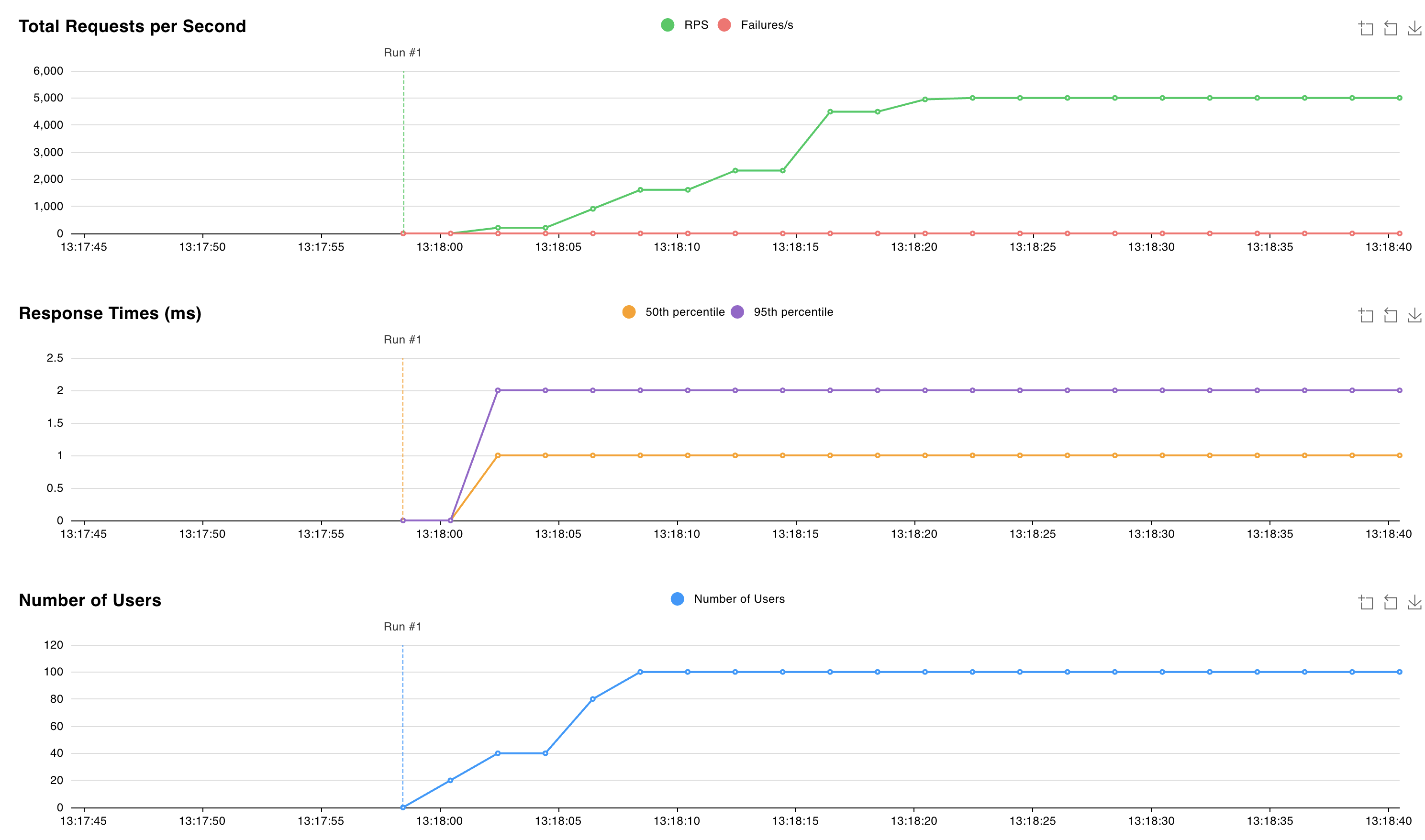
Simulieren von Fehlern und Beobachten des Valkey-Clusterverhaltens
Simulieren Sie einen Ausfall, indem Sie die
StatefulSetmithilfe des Befehlskubectl deletemit dem Flag--cascade=orphanlöschen. Das Ziel besteht darin, einen einzelnen Pod zu löschen, ohne dass derStatefulSetgelöschte Pod sofort neu wiederherstellen muss.kubectl delete statefulset valkey-masters --cascade=orphanLöschen Sie den
valkey-masters-0Pod mithilfe deskubectl delete podBefehls.kubectl delete pod valkey-masters-0Überprüfen Sie die Liste der Pods mithilfe des
kubectl get podsBefehls.kubectl get podsDie Ausgabe sollte angeben, dass der Pod
valkey-masters-0gelöscht wurde. Die anderen Pods sollten sich im StatusRunningbefinden, wie im folgenden Beispiel gezeigt:NAME READY STATUS RESTARTS AGE valkey-client 1/1 Running 0 6m34s valkey-masters-1 1/1 Running 0 16m valkey-masters-2 1/1 Running 0 16m valkey-replicas-0 1/1 Running 0 16m valkey-replicas-1 1/1 Running 0 16m valkey-replicas-2 1/1 Running 0 16mRufen Sie die Protokolle des
valkey-replicas-0-Pods mit dem Befehlkubectl logs valkey-replicas-0ab.kubectl logs valkey-replicas-0In der Ausgabe beobachten wir, dass das vollständige Ereignis etwa 18 Sekunden dauert:
1:S 05 Nov 2024 12:18:53.961 * Connection with primary lost. 1:S 05 Nov 2024 12:18:53.961 * Caching the disconnected primary state. 1:S 05 Nov 2024 12:18:53.961 * Reconnecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:18:53.961 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:18:53.964 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:18:54.910 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:18:54.910 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:18:54.912 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:18:55.920 * Connecting to PRIMARY 10.224.0.250:6379 [..CUT..] 1:S 05 Nov 2024 12:19:10.056 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:10.057 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:10.058 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:19:10.709 * Node c44d4b682b6fb9b37033d3e30574873545266d67 () reported node 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () as not reachable. 1:S 05 Nov 2024 12:19:10.864 * NODE 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () possibly failing. 1:S 05 Nov 2024 12:19:11.066 * 10000 changes in 60 seconds. Saving... 1:S 05 Nov 2024 12:19:11.068 * Background saving started by pid 29 1:S 05 Nov 2024 12:19:11.068 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:11.068 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:11.069 # Error condition on socket for SYNC: Connection refused 29:C 05 Nov 2024 12:19:11.090 * DB saved on disk 29:C 05 Nov 2024 12:19:11.090 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB 1:S 05 Nov 2024 12:19:11.169 * Background saving terminated with success 1:S 05 Nov 2024 12:19:11.884 * FAIL message received from ba36d5167ee6016c01296a4a0127716f8edf8290 () about 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () 1:S 05 Nov 2024 12:19:11.884 # Cluster state changed: fail 1:S 05 Nov 2024 12:19:11.974 * Start of election delayed for 510 milliseconds (rank #0, offset 7225807). 1:S 05 Nov 2024 12:19:11.976 * Node d43f370a417d299b78bd1983792469fe5c39dcdf () reported node 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () as not reachable. 1:S 05 Nov 2024 12:19:12.076 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:12.076 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:12.076 * Currently unable to failover: Waiting the delay before I can start a new failover. 1:S 05 Nov 2024 12:19:12.078 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:19:12.581 * Starting a failover election for epoch 15. 1:S 05 Nov 2024 12:19:12.616 * Currently unable to failover: Waiting for votes, but majority still not reached. 1:S 05 Nov 2024 12:19:12.616 * Needed quorum: 2. Number of votes received so far: 1 1:S 05 Nov 2024 12:19:12.616 * Failover election won: I'm the new primary. 1:S 05 Nov 2024 12:19:12.616 * configEpoch set to 15 after successful failover 1:M 05 Nov 2024 12:19:12.616 * Discarding previously cached primary state. 1:M 05 Nov 2024 12:19:12.616 * Setting secondary replication ID to c0b5b2df8a43b19a4d43d8f8b272a07139e0ca34, valid up to offset: 7225808. New replication ID is 029fcfbae0e3e4a1dccd73066043deba6140c699 1:M 05 Nov 2024 12:19:12.616 * Cluster state changed: okWährend dieses Zeitfensters von 18 Sekunden stellen wir fest, dass Schreibvorgänge in die Shard, die zum gelöschten Pod gehört, fehlschlagen, und der Valkey-Cluster eine neue primäre Instanz auswählt. Die Anforderungslatenz ist während dieses Zeitfensters auf 60 ms gestiegen.
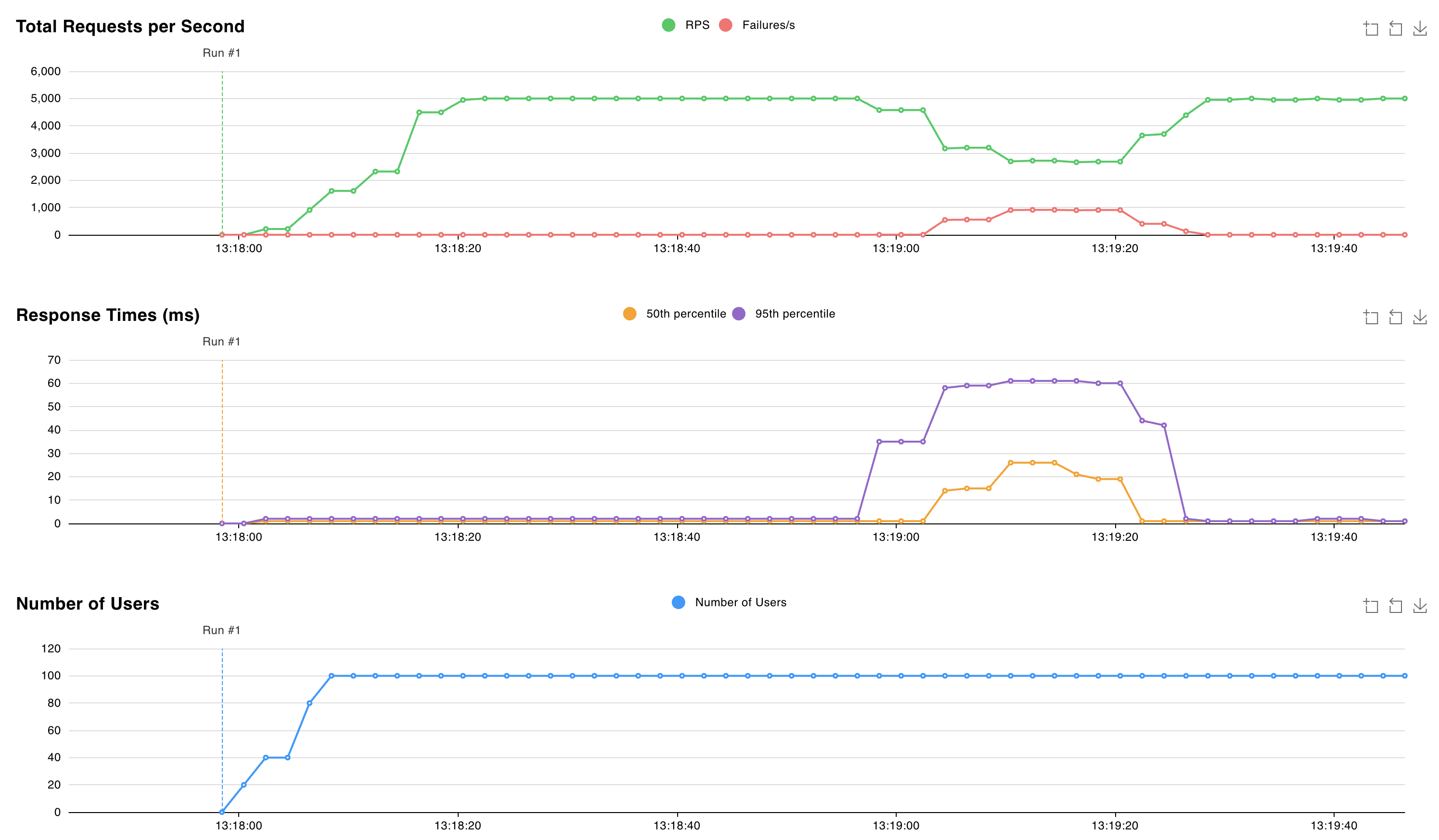
Nachdem die neue Primäre ausgewählt wurde, bedient der Valkey-Cluster weiterhin Anforderungen mit einer Latenz von ca. 2 ms.
Nächster Schritt
Mitwirkende
Microsoft pflegt diesen Artikel. Die folgenden Mitwirkenden haben es ursprünglich geschrieben:
- Nelly Kiboi | Servicetechnikerin
- Saverio Proto | Principal Customer Experience Engineer