Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Alle API Management-Ebenen
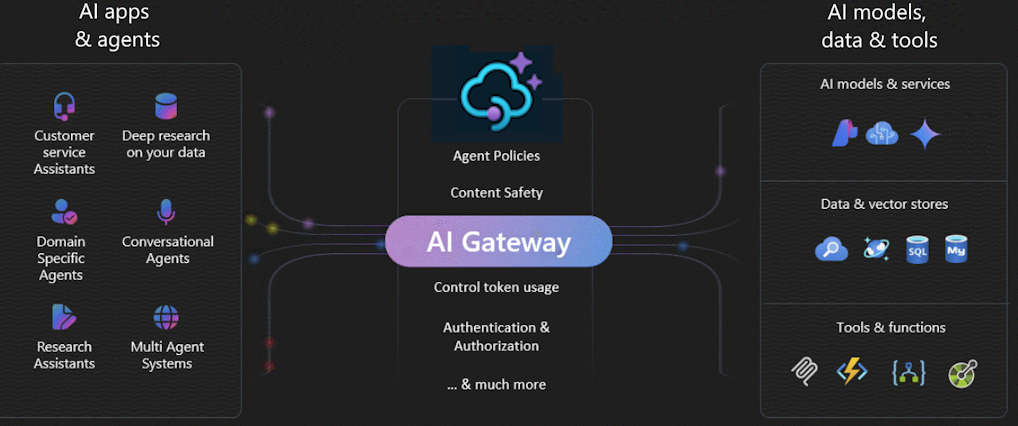
Das AI-Gateway in Azure API Management ist eine Reihe von Funktionen, mit denen Sie Ihre KI-Back-Ends effektiv verwalten können. Verwenden Sie diese Funktionen zum Sichern, Skalieren, Überwachen und Steuern von KI-Modellen, Agents und Tools, die Ihre intelligenten Apps und Workloads unterstützen.
Verwenden Sie das KI-Gateway, um eine vielzahl von KI-Endpunkten zu verwalten, darunter:
- Microsoft Foundry und Azure OpenAI in Microsoft Foundry Models Bereitstellungen
- Azure AI Model Inference API-Bereitstellungen
- Remote-MCP-Server und A2A-Agent-APIs
- OpenAI-kompatible Modelle und Endpunkte, die von nicht Microsoft Anbietern gehostet werden
- Selbst gehostete Modelle und Endpunkte
Hinweis
Das KI-Gateway, einschließlich MCP-Serverfunktionen, erweitert das vorhandene API-Gateway der API-Verwaltung; es ist kein separates Angebot. Verwandte Governance- und Entwicklerfeatures befinden sich im Azure API Center.
Hinweis
Neu! Das KI-Gateway kann jetzt direkt in Microsoft Foundry integriert werden, sodass Sie KI-Modelle, Agents und Tools in Ihrer Foundry-Umgebung steuern können. Weitere Informationen finden Sie im Abschnitt AI-Gateway im Abschnitt Microsoft Foundry.
Warum ein KI-Gateway verwenden?
Die KI-Einführung in Organisationen umfasst mehrere Phasen:
- Definieren von Anforderungen und Auswerten von KI-Modellen
- Erstellen von KI-Apps und Agents, die Zugriff auf KI-Modelle und -Dienste benötigen
- Operationalisieren und Bereitstellen von KI-Apps und Back-Ends in der Produktion
Da die KI-Einführung reift, insbesondere in größeren Unternehmen, hilft das KI-Gateway bei der Bewältigung wichtiger Herausforderungen. Es hilft Ihnen:
- Authentifizieren und Autorisieren des Zugriffs auf KI-Dienste
- Lastverteilung über mehrere KI-Endpunkte
- Überwachen und Protokollieren von KI-Interaktionen
- Verwalten von Tokennutzung und Kontingenten für mehrere Anwendungen
- Aktivieren von Self-Service für Entwicklerteams
Verkehrsvermittlung und -steuerung
Mithilfe des KI-Gateways können Sie:
- Schnelles Importieren und Konfigurieren von openAI-kompatiblen oder Passthrough-LLM-Endpunkten als APIs
- Verwalten von Modellen, die in Microsoft Foundry oder Anbietern wie Amazon Bedrock bereitgestellt werden
- Verwalten von Chatabschlussen, Antworten und Echtzeit-APIs
- Stellen Sie Ihre vorhandenen REST-APIs als MCP-Server bereit und unterstützen Sie die Weiterleitung an MCP-Server.
- Importieren und Verwalten von A2A-Agent-APIs (Vorschau)
Um z. B. ein modell zu integrieren, das in Microsoft Foundry oder einem anderen Anbieter bereitgestellt wird, stellt API-Verwaltung optimierte Assistenten bereit, um das Schema zu importieren und die Authentifizierung für den KI-Endpunkt mithilfe einer verwalteten Identität einzurichten, wodurch die Notwendigkeit für die manuelle Konfiguration entfernt wird. Innerhalb derselben benutzerfreundlichen Umgebung können Sie Richtlinien für API-Skalierbarkeit, Sicherheit und Observability vorkonfigurieren.

Weitere Informationen:
- Importieren einer Microsoft Foundry-API
- Importieren einer Sprachmodell-API
- Verfügbarmachen einer REST-API als MCP-Server
- Verfügbarmachen und Steuern eines vorhandenen MCP-Servers
- Importieren einer A2A-Agent-API
Skalierbarkeit und Leistung
Eine der wichtigsten Ressourcen für generative KI-Dienste sind Token. Microsoft Foundry und andere Anbieter weisen Kontingente für Ihre Modellbereitstellungen als Token pro Minute (TPM) zu. Sie verteilen diese Token für Ihre Modellkunden, z. B. verschiedene Anwendungen, Entwicklerteams oder Abteilungen innerhalb des Unternehmens.
Wenn Sie über eine einzelne App verfügen, die eine Verbindung mit einem AI-Dienst-Back-End herstellt, können Sie die Tokennutzung mit einem TPM-Grenzwert verwalten, den Sie direkt in der Modellbereitstellung festlegen. Wenn Ihr Anwendungsportfolio jedoch wächst, haben Sie möglicherweise mehrere Apps, die einzelne oder mehrere AI-Dienstendpunkte aufrufen. Diese Endpunkte können pay-as-you-go- oder Provisioned Throughput Units (PTU)-Instanzen sein. Sie müssen sicherstellen, dass eine App nicht das gesamte TPM-Kontingent verwendet und andere Apps daran hindern, auf die benötigten Back-Ends zuzugreifen.
Tokenratenbegrenzung und Kontingente
Konfigurieren Sie eine Tokengrenzrichtlinie für Ihre LLM-APIs zum Verwalten und Erzwingen von Grenzwerten pro API-Consumer basierend auf der Verwendung von KI-Diensttoken. Mithilfe dieser Richtlinie können Sie ein TPM-Limit oder ein Tokenkontingent über einen bestimmten Zeitraum festlegen, z. B. stündlich, täglich, wöchentlich, monatlich oder jährlich.
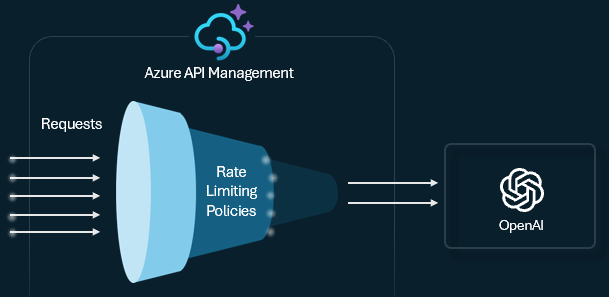
Mit dieser Richtlinie können tokenbasierte Grenzwerte flexibel für einen beliebigen Zählerschlüssel zugewiesen werden. Hierzu zählen z. B. Abonnementschlüssel, Ursprungs-IP-Adresse oder ein beliebiger Schlüssel, der über einen Richtlinienausdruck definiert ist. Die Richtlinie ermöglicht außerdem die Vorberechnung von Eingabeaufforderungstoken auf der Azure API Management-Seite, wodurch unnötige Anforderungen an das AI-Dienst-Back-End minimiert werden, wenn die Aufforderung bereits den Grenzwert überschreitet.
Das folgende einfache Beispiel veranschaulicht, wie ein TPM-Grenzwert von 500 pro Abonnementschlüssel festgelegt wird:
<llm-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</llm-token-limit>
Weitere Informationen:
Semantische Zwischenspeicherung
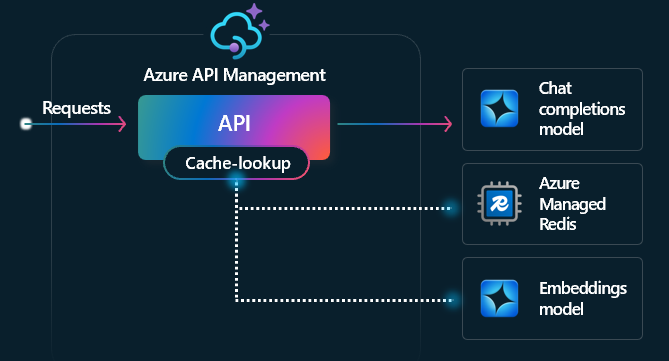
Die semantische Zwischenspeicherung ist eine Technik, die die Leistung von LLM-APIs verbessert, indem die Ergebnisse (Fertigstellungen) früherer Eingabeaufforderungen zwischengespeichert und wiederverwendet werden, indem die Vektornähe der Eingabeaufforderung mit vorherigen Anforderungen verglichen wird. Diese Technik reduziert die Anzahl der Aufrufe an das AI-Dienst-Back-End, verbessert die Reaktionszeiten für Endbenutzer und kann dazu beitragen, Kosten zu senken.
Aktivieren Sie in der API-Verwaltung die semantische Zwischenspeicherung mithilfe von Azure Managed Redis oder einem anderen externen Cache, der mit RediSearch kompatibel ist und in Azure API Management integriert ist. Mithilfe der Embeddings-API speichern die llm-semantic-cache-store- und llm-semantic-cache-lookup-Richtlinien semantisch ähnliche Ergebnisse der Eingabeaufforderungen im Cache und rufen sie von dort ab. Dieser Ansatz gewährleistet die Wiederverwendung von Vervollständigungen, was die Tokennutzung reduziert und die Reaktionsleistung verbessert.
Weitere Informationen:
- Setup eines externen Caches in Azure API Management
- Aktivieren der semantischen Zwischenspeicherung für KI-APIs in Azure API Management
Native Skalierungsfeatures in der API-Verwaltung
Die API-Verwaltung bietet außerdem integrierte Skalierungsfeatures, mit denen das Gateway hohe Anforderungen an Ihre AI-APIs verarbeiten kann. Diese Features umfassen die automatische oder manuelle Hinzufügung von Gatewayskalierungseinheiten und das Hinzufügen regionaler Gateways für Multiregion-Bereitstellungen. Bestimmte Funktionen sind von der API-Verwaltungsdienstebene abhängig.
Weitere Informationen:
- Aktualisieren und Skalieren einer API-Verwaltungsinstanz
- Bereitstellen einer API-Verwaltungsinstanz in mehreren Regionen
Hinweis
Während die API-Verwaltung die Gatewaykapazität skalieren kann, müssen Sie auch den Datenverkehr an Ihre KI-Back-Ends skalieren und verteilen, um eine erhöhte Last zu berücksichtigen (siehe Abschnitt " Resilienz "). Um beispielsweise die geografische Verteilung Ihres Systems in einer multiregionsübergreifenden Konfiguration zu nutzen, stellen Sie BACK-End-KI-Dienste in denselben Regionen wie Ihre API-Verwaltungsgateways bereit.
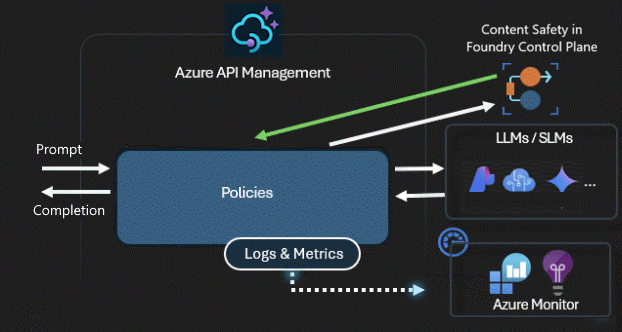
Sicherheit und Schutz
Ein KI-Gateway sichert und steuert den Zugriff auf Ihre KI-APIs. Mithilfe des KI-Gateways können Sie:
- Verwenden Sie verwaltete Identitäten, um sich bei KI-Diensten in Azure zu authentifizieren, daher benötigen Sie keine API-Schlüssel für die Authentifizierung.
- Konfigurieren der OAuth-Autorisierung für KI-Apps und Agents für den Zugriff auf APIs oder MCP-Server mithilfe des Anmeldeinformations-Managers der API-Verwaltung
- Richtlinien anwenden, um LLM-Eingabeaufforderungen mithilfe von Azure KI Inhaltssicherheit automatisch zu moderieren.
Weitere Informationen:
- Authentifizieren und Autorisieren des Zugriffs auf LLM-APIs
- Informationen zu API-Anmeldeinformationen und Anmeldeinformationsverwaltung
- Erzwingen von Inhaltssicherheitsprüfungen für LLM-Anforderungen
- Schützen des Zugriffs auf MCP-Server
Resiliency
Eine Herausforderung beim Erstellen intelligenter Anwendungen besteht darin, sicherzustellen, dass die Anwendungen ausfallsicher gegenüber Back-End-Fehlern sind und hohe Lasten bewältigen können. Indem Sie Ihre LLM-Endpunkte mit backends in Azure API Management konfigurieren, können Sie die Last über sie hinweg ausgleichen. Sie können auch Schaltkreistrennregeln definieren, um die Weiterleitung von Anforderungen an AI-Dienst-Back-Ends zu beenden, wenn sie nicht reaktionsfähig sind.
Lastverteiler
Der Lastenausgleich des Back-Ends unterstützt Round-Robin-, gewichteten, prioritätsbasierten und sitzungsbasierten Lastenausgleich. Sie können eine Lastenverteilungsstrategie definieren, die Ihren spezifischen Anforderungen entspricht. Definieren Sie beispielsweise Prioritäten innerhalb der Lastenausgleichskonfiguration, um eine optimale Nutzung bestimmter Microsoft Foundry-Endpunkte sicherzustellen, insbesondere diejenigen, die als PTU-Instanzen erworben wurden.
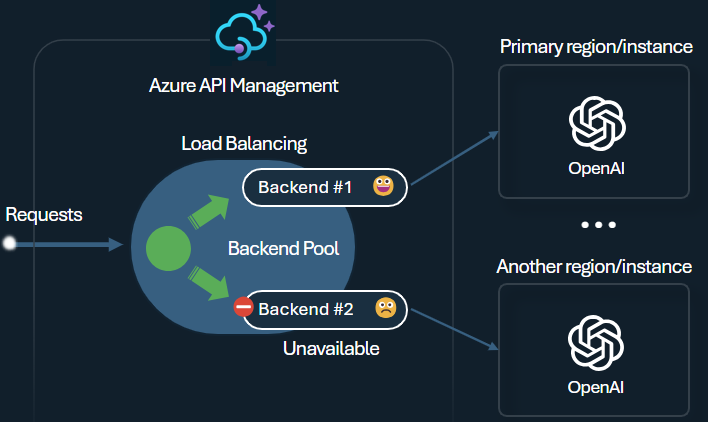
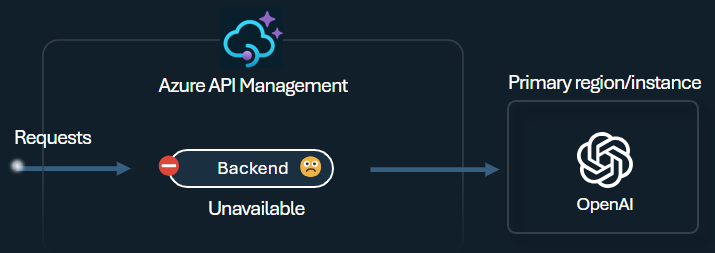
Sicherungsautomat
Der Trennschalter des Back-Ends bietet eine dynamische Tripdauer. Dabei werden Werte aus dem vom Back-End bereitgestellten Retry-After-Header angewendet. Dieses Feature stellt eine präzise und zeitnahe Wiederherstellung der Back-Ends sicher, wobei die Nutzung Ihrer Prioritäts-Back-Ends maximiert wird.
Weitere Informationen:
Observability und Governance
DIE API-Verwaltung bietet umfassende Überwachungs- und Analysefunktionen zum Nachverfolgen von Tokennutzungsmustern, zur Optimierung der Kosten, zur Sicherstellung der Einhaltung Ihrer KI-Governancerichtlinien und zur Behebung von Problemen mit Ihren AI-APIs. Verwenden Sie diese Funktionen, um:
- Protokollieren von Eingabeaufforderungen und Ergebnissen im Azure Monitor.
- Verfolgen Sie Tokenmetriken pro Consumer in Application Insights.
- Zeigen Sie das integrierte Überwachungsdashboard an.
- Konfigurieren sie Richtlinien mit benutzerdefinierten Ausdrücken.
- Verwalten von Tokenkontingenten für alle Anwendungen.
Sie können beispielsweise Tokenmetriken mithilfe der llm-emit-token-metricRichtlinie ausgeben und benutzerdefinierte Dimensionen hinzufügen, die Sie zum Filtern der Metrik in Azure Monitor verwenden können. Im folgenden Beispiel werden Tokenmetriken mit Dimensionen für Client-IP-Adresse, API-ID und Benutzer-ID (aus einem benutzerdefinierten Header) ausgegeben:
<llm-emit-token-metric namespace="llm-metrics">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</llm-emit-token-metric>
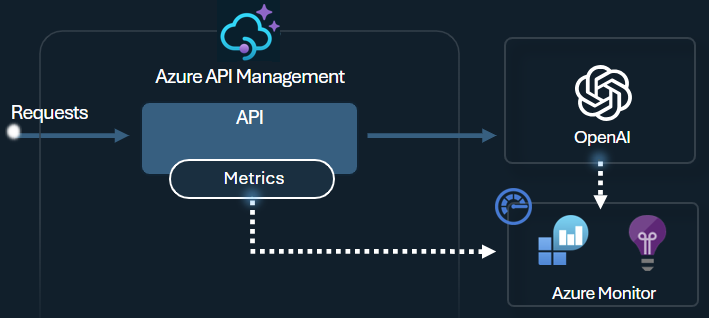
Aktivieren Sie außerdem die Protokollierung für LLM-APIs in Azure API Management, um die Tokennutzung, Aufforderungen und Abschlüsse zum Zweck der Abrechnung und Überwachung nachzuverfolgen. Nachdem Sie die Protokollierung aktiviert haben, können Sie die Protokolle in Application Insights analysieren und ein integriertes Dashboard in der API-Verwaltung verwenden, um Tokennutzungsmuster für Ihre AI-APIs anzuzeigen.

Weitere Informationen:
- Protokollieren von Tokennutzung, Aufforderungen und Vervollständigungen
- Erzeugung von Metriken des Tokenverbrauchs
Entwicklerumgebung
Verwenden Sie das AI-Gateway und Azure API Center, um die Entwicklung und Bereitstellung Ihrer KI-APIs und MCP-Server zu optimieren. Zusätzlich zu den benutzerfreundlichen Import- und Richtlinienkonfigurationsfunktionen für allgemeine KI-Szenarien in der API-Verwaltung können Sie folgende Vorteile nutzen:
- Einfache Registrierung von APIs und MCP-Servern in einem Organisationskatalog im Azure API Center
- Self-Service-API und MCP-Serverzugriff über Entwicklerportale im API Management and API Center
- API-Verwaltungsrichtlinien-Toolkit zur Anpassung
- API Center Copilot Studio Connector zum Erweitern der Funktionen von KI-Agents

Weitere Informationen:
- Registrieren und Ermitteln von MCP-Servern im API Center
- Synchronisieren von APIs und MCP-Servern zwischen API-Verwaltung und API Center
- API-Verwaltungsentwicklerportal
- API Center-Portal
- Azure API Management Policy Toolkit
- API Center Copilot Studio Connector
KI-Gateway in Microsoft Foundry (Vorschau)
Sie können jetzt KI-Gateway direkt in Microsoft Foundry integrieren, sodass Sie KI-Datenverkehr aus Ihrer Foundry-Umgebung steuern können. Wenn Sie eine KI-Gatewayinstanz mit Ihrer Foundry-Ressource erstellen oder zuordnen, können Sie Ihre Foundry-Ressourcen über das Gateway steuern, sichern und überwachen.
Models: Konfigurieren Sie Tokenkontingente und Ratelimits direkt in der Foundry-Schnittstelle für alle Modellbereitstellungen, einschließlich Azure OpenAI und anderer Anbieter.
Agents: Registrieren Sie Agents, die überall ausgeführt werden – Azure, andere Clouds oder lokal – in der Gießereisteuerungsebene für zentralisiertes Inventar und Governance. Zeigen Sie Telemetrie in Foundry oder Application Insights an, und wenden Sie Richtlinien wie Drosselung oder Inhaltssicherheit an.
Tools: Registrieren Sie MCP-Tools, die in einer beliebigen Umgebung gehostet werden, um die automatische Governance und Ermittlung zu aktivieren. Tools erscheinen im Inventar der Gießerei, bereit zur Verwendung durch Agenten.
Für erweiterte Szenarien wie benutzerdefinierte Richtlinien, Unternehmensnetzwerke oder Verbundgateways greifen Sie auf die vollständige Azure API Management Erfahrung zu, während die Kontinuität mit den von Foundry verwalteten Ressourcen beibehalten wird.
Weitere Informationen:
- AI-Gateway in Microsoft Foundry aktivieren
- Registrieren von benutzerdefinierten Agenten in Foundry
- Steuern von Tools mit KI-Gateway
- Verbinden eines KI-Gateways mit dem Foundry Agent Service
Früher Zugriff auf KI-Gateway-Funktionen
Als API-Verwaltungskunde können Sie über den KI-Gateway-Veröffentlichungskanal frühzeitig zugriff auf neue Features und Funktionen erhalten. Mit diesem Zugriff können Sie die neuesten KI-Gatewayinnovationen ausprobieren, bevor sie allgemein verfügbar sind, und Feedback geben, um das Produkt zu gestalten.
Weitere Informationen:
Labore und Codebeispiele
- AI-Gateway-Funktionen-Labore
- KI-Gateway-Workshop
- Azure OpenAI mit API-Verwaltung (Node.js)
- Python Beispielcode
- Einheitliches KI-Gateway-Designmuster
Architektur und Design
- KI-Gatewayreferenzarchitektur mithilfe der API-Verwaltung
- KI-Hub-Gateway-Landezonen-Beschleuniger
- Designing und Implementierung einer Gatewaylösung mit Azure OpenAI-Ressourcen
- Verwenden Sie ein Gateway vor mehreren Azure OpenAI-Bereitstellungen
Verwandte Inhalte
Blog: AI-Gateway in Azure API Management ist jetzt in Microsoft Foundry - Blog: Einführung von KI-Funktionen in Azure API Management
- Blog: Integrieren Azure Inhaltssicherheit mit API-Verwaltung
- Schulung: Verwalten ihrer generativen KI-APIs
- Intelligenter Lastenausgleich für OpenAI-Endpunkte