Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Lernprogramm erstellen Sie eine Node.js RAG-Anwendung (Retrieval Augmented Generation) mit Express.js, Azure OpenAI und Azure AI Search und stellen sie in Azure App Service bereit. Diese Anwendung veranschaulicht, wie Sie eine Chatschnittstelle implementieren, die Informationen aus Ihren eigenen Dokumenten abruft und Azure AI-Dienste nutzt, um genaue, kontextbezogene Antworten mit korrekten Zitaten bereitzustellen. Die Lösung verwendet verwaltete Identitäten für die kennwortlose Authentifizierung zwischen Diensten.
In diesem Tutorial lernen Sie Folgendes:
- Stellen Sie eine Express.js Anwendung bereit, die RAG-Muster mit Azure AI-Diensten verwendet.
- Konfigurieren Sie Azure OpenAI und Azure AI Search für die Hybridsuche.
- Hochladen und Indizieren von Dokumenten für die Verwendung in Ihrer KI-basierten Anwendung.
- Verwenden Sie verwaltete Identitäten für die sichere Dienst-zu-Dienst-Kommunikation.
- Testen Sie Ihre RAG-Implementierung lokal mit Produktionsdiensten.
Architekturübersicht
Bevor Sie mit der Bereitstellung beginnen, ist es hilfreich, die Architektur der Anwendung zu verstehen, die Sie erstellen. Das folgende Diagramm stammt aus dem benutzerdefinierten RAG-Muster für Azure AI Search:
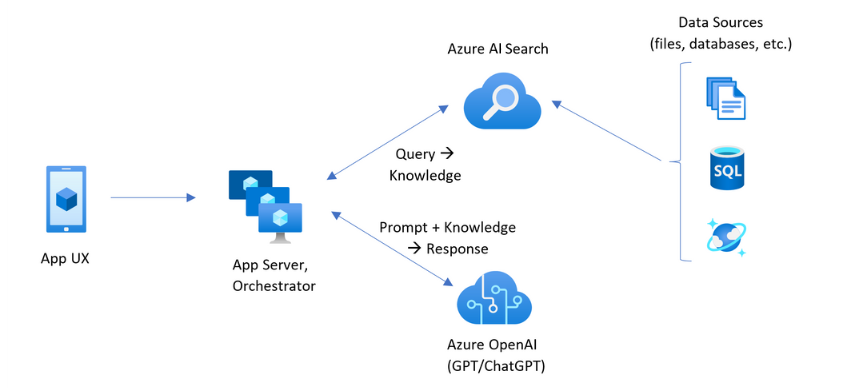
In diesem Lernprogramm übernimmt die Blazer-Anwendung in App Service sowohl die App-UX als auch den App-Server. Es macht jedoch keine separate Wissensabfrage für Azure AI Search. Stattdessen wird Azure OpenAI aufgefordert, die Wissensabfrage auszuführen, die Azure AI Search als Datenquelle angibt. Diese Architektur bietet mehrere wichtige Vorteile:
- Integrierte Vektorisierung: Die integrierten Vektorisierungsfunktionen von Azure AI Search machen es einfach und schnell, alle Ihre Dokumente für die Suche aufzunehmen, ohne dass mehr Code zum Generieren von Einbettungen erforderlich ist.
- Vereinfachter API-Zugriff: Durch Die Verwendung des Azure OpenAI On Your Data-Musters mit Azure AI Search als Datenquelle für Azure OpenAI-Fertigstellungen ist es nicht erforderlich, komplexe Vektorsuch- oder Einbettungsgenerierungen zu implementieren. Es ist nur ein API-Aufruf, und Azure OpenAI verarbeitet alles, einschließlich Prompt Engineering und Abfrageoptimierung.
- Erweiterte Suchfunktionen: Die integrierte Vektorisierung bietet alles, was für die erweiterte Hybridsuche mit semantischer Reranking erforderlich ist, was die Stärken des Schlüsselwortabgleichs, der Vektorähnlichkeit und der KI-basierten Rangfolge kombiniert.
- Vollständige Zitatunterstützung: Antworten enthalten automatisch Zitate an Quelldokumente, wodurch Informationen überprüft und nachverfolgt werden können.
Voraussetzungen
- Ein Azure-Konto mit einem aktiven Abonnement – Kostenlos ein Konto erstellen.
- GitHub-Konto zur Verwendung von GitHub Codespaces – Erfahren Sie mehr über GitHub Codespaces.
1. Öffnen des Beispiels mit Codespaces
Die einfachste Möglichkeit für die ersten Schritte ist die Verwendung von GitHub Codespaces, die eine vollständige Entwicklungsumgebung mit allen erforderlichen Tools vorinstalliert bietet.
Navigieren Sie zum GitHub-Repository unter https://github.com/Azure-Samples/app-service-rag-openai-ai-search-nodejs.
Wählen Sie die Schaltfläche "Code " aus, wählen Sie die Registerkarte " Codespaces " aus, und klicken Sie auf "Codespace erstellen" im Hauptbereich.
Warten Sie einige Augenblicke, bis Der Codespace initialisiert wird. Wenn Sie bereit sind, wird eine vollständig konfigurierte VS Code-Umgebung in Ihrem Browser angezeigt.
2. Bereitstellen der Beispielarchitektur
Melden Sie sich im Terminal mit Azure Developer CLI bei Azure an:
azd auth loginFolgen Sie den Anweisungen, um den Authentifizierungsprozess abzuschließen.
Bereitstellen der Azure-Ressourcen mit der AZD-Vorlage:
azd provisionWenn Sie dazu aufgefordert werden, geben Sie die folgenden Antworten:
Frage Antwort Geben Sie einen neuen Umgebungsnamen ein: Geben Sie einen eindeutigen Namen ein. Wählen Sie ein Azure-Abonnement aus, das Sie verwenden möchten: Wählen Sie das Abonnement aus. Wählen Sie eine zu verwendende Ressourcengruppe aus: Wählen Sie Eine neue Ressourcengruppe erstellen aus. Wählen Sie einen Speicherort aus, in dem die Ressourcengruppe erstellt werden soll: Wählen Sie eine beliebige Region aus. Die Ressourcen werden tatsächlich in Ost-USA 2 erstellt. Geben Sie einen Namen für die neue Ressourcengruppe ein: Drücken Sie Enter. Warten Sie, bis die Bereitstellung abgeschlossen ist. Dieser Vorgang wird Folgendes ausführen:
- Erstellen Sie alle erforderlichen Azure-Ressourcen.
- Stellen Sie die Blazor-Anwendung in Azure App Service bereit.
- Konfigurieren Sie die sichere Dienst-zu-Dienst-Authentifizierung mithilfe von verwalteten Identitäten.
- Richten Sie die erforderlichen Rollenzuweisungen für den sicheren Zugriff zwischen Diensten ein.
Hinweis
Weitere Informationen dazu, wie verwaltete Identitäten funktionieren, finden Sie unter Was sind verwaltete Identitäten für Azure-Ressourcen? und wie verwaltete Identitäten mit App Service verwendet werden.
Nach erfolgreicher Bereitstellung wird eine URL für Ihre bereitgestellte Anwendung angezeigt. Notieren Sie sich diese URL, greifen Sie aber noch nicht darauf zu, da Sie den Suchindex noch einrichten müssen.
3. Hochladen von Dokumenten und Erstellen eines Suchindexes
Nachdem die Infrastruktur bereitgestellt wurde, müssen Sie Dokumente hochladen und einen Suchindex erstellen, den die Anwendung verwendet:
Navigieren Sie im Azure-Portal zu dem Speicherkonto, das von der Bereitstellung erstellt wurde. Der Name beginnt mit dem Zuvor angegebenen Umgebungsnamen.
Wählen Sie "Container" im linken Navigationsmenü aus, und öffnen Sie den Dokumentcontainer .
Laden Sie Beispieldokumente hoch, indem Sie auf "Hochladen" klicken. Sie können die Beispieldokumente aus dem
sample-docsOrdner im Repository oder eigene PDF-, Word- oder Textdateien verwenden.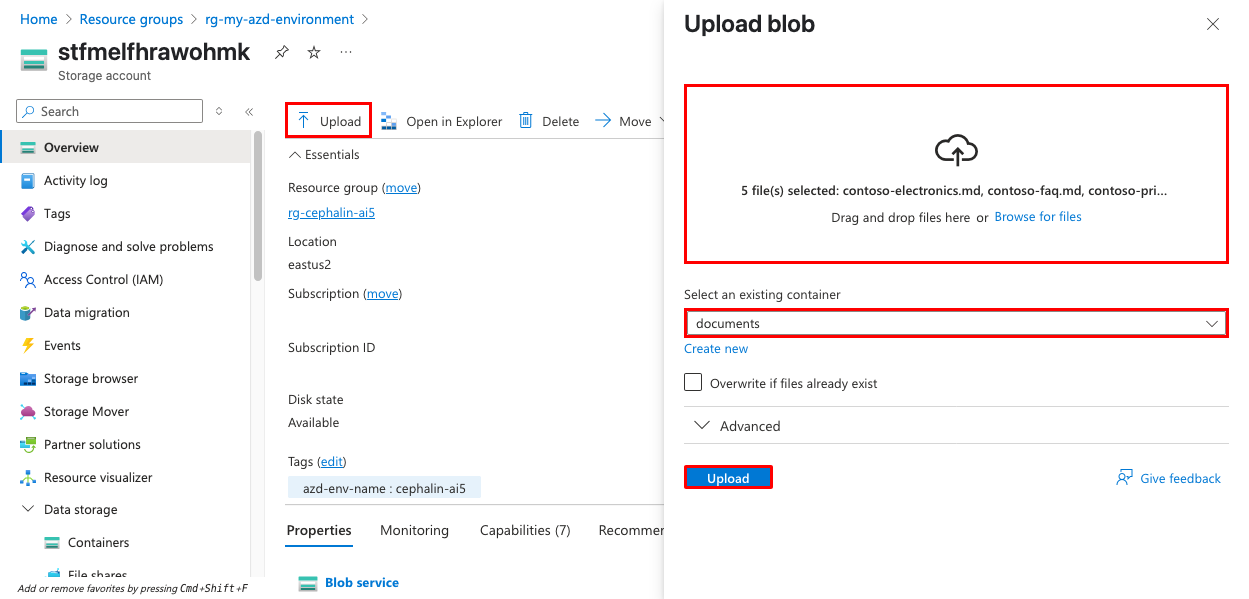
Navigieren Sie im Azure-Portal zu Ihrem Azure AI Search-Dienst.
Wählen Sie "Importieren" und "Vektorisieren von Daten " aus, um den Prozess zum Erstellen eines Suchindexes zu starten.
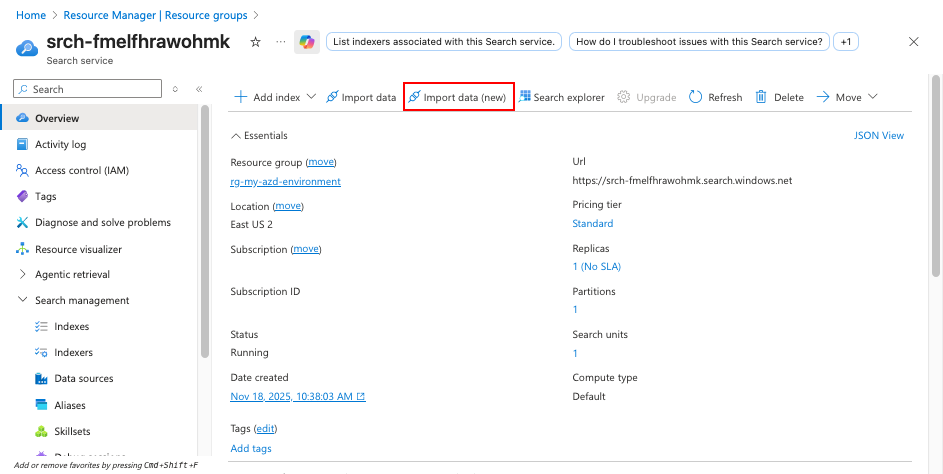
Führen Sie im Schritt "Herstellen einer Verbindung mit Ihren Daten" folgendes aus:
- Wählen Sie Azure Blob Storage als Datenquelle aus.
- Wählen Sie RAG aus.
- Wählen Sie Ihr Speicherkonto und den Dokumentcontainer aus.
- Stellen Sie sicher, dass "Authentifizieren mit verwalteter Identität" ausgewählt ist.
- Wählen Sie Weiteraus.
In der Phase Text vektorisieren:
- Wählen Sie Ihren Azure OpenAI-Dienst aus.
- Wählen Sie text-embedding-ada-002 als Einbettungsmodell aus. Die AZD-Vorlage hat dieses Modell bereits für Sie bereitgestellt.
- Wählen Sie die vom System zugewiesene Identität für die Authentifizierung aus.
- Aktivieren Sie das Bestätigungskontrollkästchen auf zusätzliche Kosten.
- Wählen Sie Weiteraus.
Tipp
Erfahren Sie mehr über die Vektorsuche in Azure AI Search und Texteinbettungen in Azure OpenAI.
Im Schritt „Vektorisieren und Anreichern Ihrer Bilder“ gehen Sie wie unten beschrieben vor:
- Behalten Sie die Standardeinstellungen bei.
- Wählen Sie Weiteraus.
Führen Sie im Schritt "Erweiterte Einstellungen " folgendes aus:
- Stellen Sie sicher , dass "Semantik-Rangfolge aktivieren" ausgewählt ist.
- (Optional) Wählen Sie einen Indizierungszeitplan aus. Dies ist nützlich, wenn Sie Ihren Index regelmäßig mit den neuesten Dateiänderungen aktualisieren möchten.
- Wählen Sie Weiteraus.
Führen Sie im Schritt "Überprüfen und Erstellen" folgendes aus:
- Kopieren Sie den Objektnamen-Präfix-Wert. Es ist Ihr Suchindexname.
- Wählen Sie "Erstellen" aus, um den Indizierungsprozess zu starten.
Warten Sie, bis der Indizierungsprozess abgeschlossen ist. Dies kann je nach Größe und Anzahl Ihrer Dokumente einige Minuten dauern.
Um den Datenimport zu testen, wählen Sie Suche starten und probieren Sie eine Suchabfrage wie "Erzählen Sie mir von Ihrem Unternehmen."
Legen Sie in Ihrem Codespace-Terminal den Suchindexnamen als AZD-Umgebungsvariable fest:
azd env set SEARCH_INDEX_NAME <your-search-index-name>Ersetzen Sie
<your-search-index-name>durch den zuvor kopierten Indexnamen. AZD verwendet diese Variable in nachfolgenden Bereitstellungen, um die App-Einstellungen im App Service festzulegen.
4. Testen der Anwendung und Bereitstellen
Wenn Sie die Anwendung vor oder nach der Bereitstellung lokal testen möchten, können Sie sie direkt aus Ihrem Codespace ausführen:
Rufen Sie in Ihrem Codespace-Terminal die AZD-Umgebungswerte ab:
azd env get-valuesÖffnen Sie .env. Aktualisieren Sie mithilfe der Terminalausgabe die folgenden Werte in den jeweiligen Platzhaltern
<input-manually-for-local-testing>:AZURE_OPENAI_ENDPOINTAZURE_SEARCH_SERVICE_URLAZURE_SEARCH_INDEX_NAME
Melden Sie sich mit der Azure CLI bei Azure an:
az loginDadurch kann die Azure Identity-Clientbibliothek im Beispielcode ein Authentifizierungstoken für den angemeldeten Benutzer empfangen.
Führen Sie die Anwendung lokal aus:
npm run devWenn Sie sehen, dass Ihre Anwendung auf Port 8080 ausgeführt wird, wählen Sie "Im Browser öffnen" aus.
Versuchen Sie, einige Fragen in der Chatoberfläche zu stellen. Wenn Sie eine Antwort erhalten, wird ihre Anwendung erfolgreich mit der Azure OpenAI-Ressource verbunden.
Beenden Sie den Entwicklungsserver mit STRG+C.
Wenden Sie die neue
SEARCH_INDEX_NAMEKonfiguration in Azure an, und stellen Sie den Beispielanwendungscode bereit:azd up
5. Testen der bereitgestellten RAG-Anwendung
Nachdem die Anwendung vollständig bereitgestellt und konfiguriert wurde, können Sie nun die RAG-Funktionalität testen:
Öffnen Sie die anwendungs-URL, die am Ende der Bereitstellung bereitgestellt wird.
Sie sehen eine Chatoberfläche, in der Sie Fragen zum Inhalt Ihrer hochgeladenen Dokumente eingeben können.
Versuchen Sie, Fragen zu stellen, die für den Inhalt Ihrer Dokumente spezifisch sind. Wenn Sie beispielsweise die Dokumente im Ordner "Sample-Docs " hochgeladen haben, können Sie diese Fragen ausprobieren:
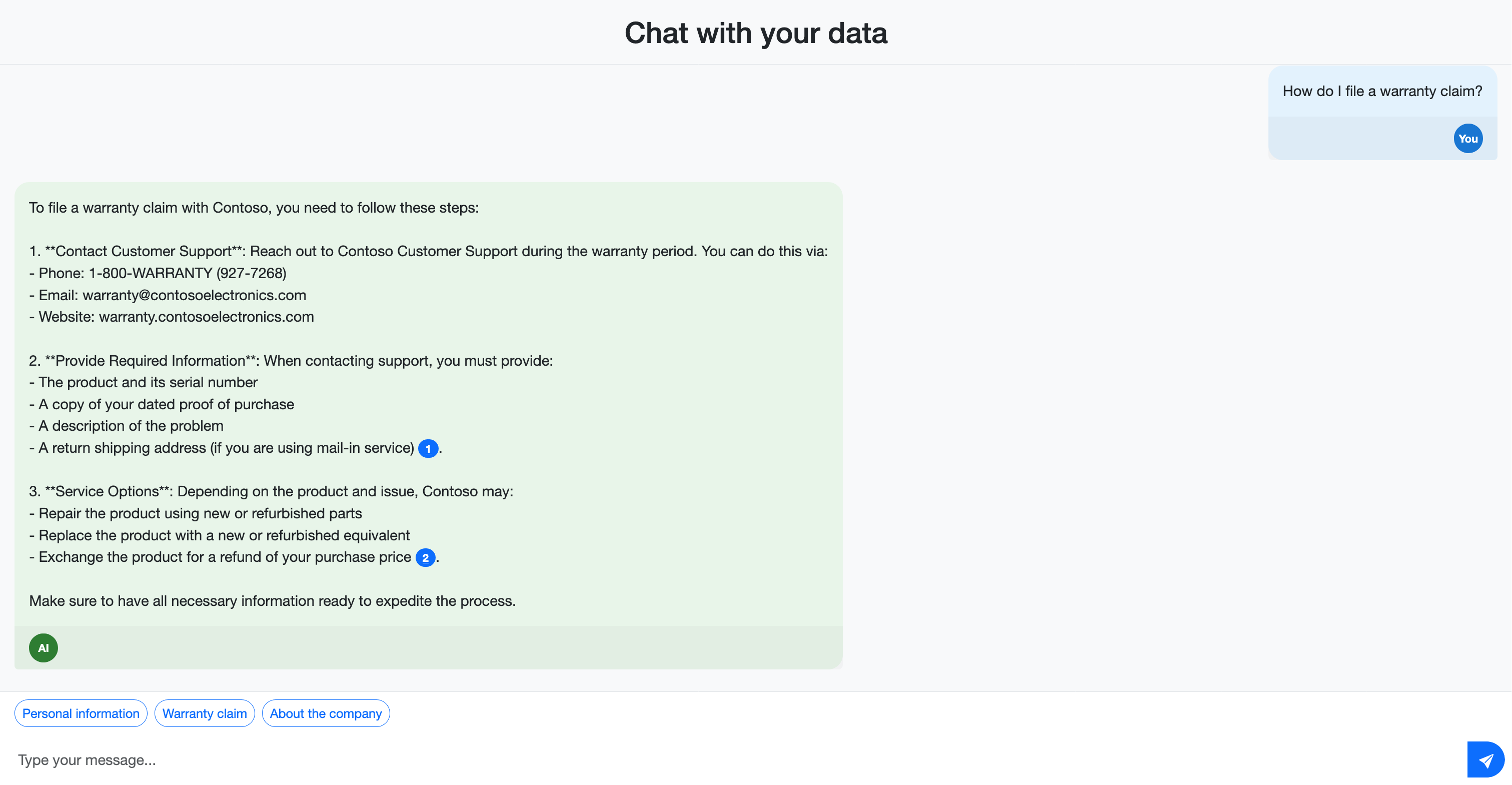
- Wie verwendet Contoso meine personenbezogenen Daten?
- Wie stellen Sie einen Garantieanspruch ein?
Beachten Sie, wie die Antworten Zitate enthalten, die auf die Quelldokumente verweisen. Diese Zitate helfen Benutzern, die Genauigkeit der Informationen zu überprüfen und weitere Details im Quellmaterial zu finden.
Testen Sie die Hybridsuchfunktionen, indem Sie Fragen stellen, die von verschiedenen Suchansätzen profitieren können:
- Fragen mit spezifischer Terminologie (gut für die Stichwortsuche).
- Fragen zu Konzepten, die mit unterschiedlichen Begriffen beschrieben werden können (gut für die Vektorsuche).
- Komplexe Fragen, die den Kontext verstehen müssen (gut für semantische Rangfolge).
Bereinigen von Ressourcen
Wenn Sie mit der Anwendung fertig sind, können Sie alle Ressourcen löschen, um weitere Kosten zu vermeiden:
azd down --purge
Mit diesem Befehl werden alle Ressourcen gelöscht, die Ihrer Anwendung zugeordnet sind.
Häufig gestellte Fragen
- Wie ruft der Beispielcode Zitate aus Azure OpenAI-Chatabschluss ab?
- Was ist der Vorteil der Verwendung von verwalteten Identitäten in dieser Lösung?
- Wie wird die vom System zugewiesene verwaltete Identität in dieser Architektur und Beispielanwendung verwendet?
- Wie wird die Hybridsuche mit semantischer Rangfolger in der Beispielanwendung implementiert?
- Warum werden alle Ressourcen in Ost-USA 2 erstellt?
- Kann ich meine eigenen OpenAI-Modelle anstelle der von Azure bereitgestellten Modelle verwenden?
- Wie kann ich die Qualität der Antworten verbessern?
Wie ruft der Beispielcode Zitationsangaben aus Azure OpenAI-Chatabschlüssen ab?
Im Beispiel werden Zitate mithilfe eines data_source "With" type: "azure_search" für den Chatclient abgerufen. Wenn ein Chatabschluss angefordert wird, enthält die Antwort ein citations Objekt innerhalb des Nachrichtenkontexts. Der Code extrahiert diese Zitate wie folgt:
const message = choice.message;
const content = message.content;
const citations = message.context?.citations || [];
In der Chatantwort verwendet der Inhalt die Notation [doc#], um auf das entsprechende Zitat in der Liste zu verweisen und es den Benutzern zu ermöglichen, die Informationen zu den ursprünglichen Quelldokumenten zurückzuverfolgen. Weitere Informationen finden Sie unter:
Was ist der Vorteil der Verwendung von verwalteten Identitäten in dieser Lösung?
Verwaltete Identitäten vermeiden die Notwendigkeit, Anmeldeinformationen in Ihrem Code oder Ihrer Konfiguration zu speichern. Mithilfe von verwalteten Identitäten kann die Anwendung sicher auf Azure-Dienste wie Azure OpenAI und Azure AI Search zugreifen, ohne geheime Schlüssel zu verwalten. Dieser Ansatz folgt den Zero Trust-Sicherheitsprinzipien und reduziert das Risiko einer Gefährdung von Anmeldeinformationen.
Wie wird die vom System zugewiesene verwaltete Identität in dieser Architektur und Beispielanwendung verwendet?
Die AZD-Bereitstellung erstellt vom System zugewiesene verwaltete Identitäten für Azure App Service, Azure OpenAI und Azure AI Search. Außerdem werden die jeweiligen Rollenzuweisungen für alle zugewiesen (siehe die Datei main.bicep). Informationen zu den erforderlichen Rollenzuweisungen finden Sie unter Netzwerk- und Zugriffskonfiguration für Azure OpenAI On Your Data.
Im Beispiel Express.js Anwendung verwenden die Azure-SDKs diese verwaltete Identität für die sichere Authentifizierung, sodass Sie anmeldeinformationen oder geheime Schlüssel nicht überall speichern müssen. Beispielsweise wird AzureOpenAI mit DefaultAzureCredential initialisiert, was automatisch die verwaltete Identität verwendet, wenn es in Azure ausgeführt wird.
const scope = "https://cognitiveservices.azure.com/.default";
const azureADTokenProvider = getBearerTokenProvider(new DefaultAzureCredential(), scope);
// Initialize Azure OpenAI client with managed identity
this.openAIClient = new AzureOpenAI({
azureADTokenProvider,
apiVersion: "2024-02-01", // Update this to a known working API version
endpoint: this.config.openai.endpoint
});
Ebenso wird beim Konfigurieren der Datenquelle für Azure AI Search die verwaltete Identität für die Authentifizierung angegeben:
const searchDataSource = {
type: 'azure_search',
parameters: {
// ...
authentication: {
type: 'system_assigned_managed_identity'
},
// ...
}
};
Diese Einrichtung ermöglicht eine sichere, kennwortlose Kommunikation zwischen Ihrer Express.js-App und Azure-Diensten, die bewährte Methoden für Zero Trust-Sicherheit folgen. Erfahren Sie mehr über DefaultAzureCredential und die Azure Identity-Clientbibliothek für JavaScript.
Wie wird die Hybridsuche mit semantischer Rangfolger in der Beispielanwendung implementiert?
Die Beispielanwendung konfiguriert die Hybridsuche mit semantischer Rangfolge mithilfe des Azure OpenAI SDK. Im Back-End wird die Datenquelle wie folgt eingerichtet:
const searchDataSource = {
type: 'azure_search',
parameters: {
// ...
query_type: 'vector_semantic_hybrid',
semantic_configuration: `${this.config.search.index.name}-semantic-configuration`,
embedding_dependency: {
type: 'deployment_name',
deployment_name: this.config.openai.embedding.deployment
}
}
};
Mit dieser Konfiguration kann die Anwendung die Vektorsuche (semantische Ähnlichkeit), den Schlüsselwortabgleich und die semantische Rangfolge in einer einzelnen Abfrage kombinieren. Der semantische Rangfolger sortiert die Ergebnisse neu, um die relevantesten und kontextbezogenen Antworten zurückzugeben, die dann von Azure OpenAI zum Generieren von Antworten verwendet werden.
Der Name der semantischen Konfiguration wird automatisch durch den integrierten Vektorisierungsprozess definiert. Er verwendet den Suchindexnamen als Präfix und fügt als Suffix an -semantic-configuration . Dadurch wird sichergestellt, dass die semantische Konfiguration eindeutig dem entsprechenden Index zugeordnet ist und einer konsistenten Benennungskonvention folgt.
Warum werden alle Ressourcen in der Region "East US 2" erstellt?
Im Beispiel werden die Modelle gpt-4o-mini und text-embedding-ada-002 verwendet, die beide mit dem Standardbereitstellungstyp in Ost-US 2 verfügbar sind. Diese Modelle werden auch ausgewählt, da sie nicht in Kürze außer Dienst gestellt werden und Stabilität für die Testbereitstellung bieten. Modellverfügbarkeit und Bereitstellungstypen können je nach Region variieren, sodass USA, Osten 2 ausgewählt ist, um sicherzustellen, dass das Beispiel sofort funktioniert. Wenn Sie eine andere Region oder ein anderes Modell verwenden möchten, stellen Sie sicher, dass Sie Modelle auswählen, die für denselben Bereitstellungstyp in derselben Region verfügbar sind. Überprüfen Sie bei der Auswahl Ihrer eigenen Modelle sowohl ihre Verfügbarkeit als auch ihre Einstellungsdaten, um Unterbrechungen zu vermeiden.
- Modellverfügbarkeit: Azure OpenAI-Dienstmodelle
- Deaktivierungsdaten für Modell: Eingestellte Unterstützung und Deaktivierung des Azure OpenAI Service-Modells.
Kann ich meine eigenen OpenAI-Modelle anstelle der von Azure bereitgestellten Modelle verwenden?
Diese Lösung wurde entwickelt, um mit Azure OpenAI Service zu arbeiten. Während Sie den Code so ändern können, dass andere OpenAI-Modelle verwendet werden, verlieren Sie die integrierten Sicherheitsfeatures, die verwaltete Identitätsunterstützung und die nahtlose Integration in Azure AI Search, die diese Lösung bereitstellt.
Wie kann ich die Qualität der Antworten verbessern?
Sie können die Antwortqualität verbessern, indem Sie:
- Hochladen höherer Qualität, relevanterer Dokumente.
- Anpassen von Segmentierungsstrategien in der Azure AI Search-Indizierungspipeline. Sie können jedoch keine Blöcke mit der integrierten Vektorisierung anpassen, die in diesem Lernprogramm gezeigt wird.
- Experimentieren mit verschiedenen Eingabeaufforderungsvorlagen im Anwendungscode.
- Optimieren Sie die Suche mit anderen Eigenschaften in der
type: "azure_searchDatenquelle. - Verwenden sie speziellere Azure OpenAI-Modelle für Ihre spezifische Domäne.