Erste Schritte mit dem Dokument Intelligenz-Tool für die Beschriftung von Beispielen
Dieser Inhalt gilt für:![]() v2.1.
v2.1.
Tipp
- Testen Sie das Dokument Intelligenz v3.0-Studio, um eine verbesserte Erfahrung und eine höhere Modellqualität zu erhalten.
- v3.0 Studio unterstützt jedes Modell, das mit in v2.1 gekennzeichneten Daten trainiert wurde.
- Ausführliche Informationen zum Migrieren von v2.1 zu v3.0 finden Sie im API-Migrationshandbuch.
- Sehen Sie sich unsere SDK-Schnellstarts zur REST-API oder zu C#, Java, JavaScript oder Python an, um mit der Version v3.0 zu beginnen.
Das Azure KI Dokument Intelligenz-Tool für die Beschriftung von Beispielen ist ein Open-Source-Tool, mit dem Sie die neuesten Features der Dokument Intelligenz- und OCR (optische Zeichenerkennung)-Dienste testen können:
Analysieren von Dokumenten mit der Layout-API. Testen Sie die Layout-API, um Text, Tabellen, Auswahlmarkierungen und Struktur aus Dokumenten zu extrahieren.
Analysieren von Dokumenten mit einem vordefinierten Modell. Beginnen Sie mit einem vordefinierten Modell, um Daten aus Rechnungen, Belegen, Identitätsdokumenten oder Visitenkarten zu extrahieren.
Trainieren und Analysieren eines benutzerdefinierten Formulars. Verwenden Sie ein benutzerdefiniertes Modell, um Daten aus Dokumenten zu extrahieren, die spezifisch für verschiedene Geschäftsdaten und Anwendungsfälle sind.
Voraussetzungen
Für den Einstieg benötigen Sie Folgendes:
Azure-Abonnement – Sie können ein kostenloses Abonnement erstellen.
Eine Azure KI Services- oder Dokument Intelligenz-Ressource. Sobald Sie über Ihr Azure-Abonnement verfügen, erstellen Sie im Azure-Portal eine Dokument Intelligenz-Ressource für einen einzelnen Dienst oder für mehrere Dienste, um Ihren Schlüssel und Endpunkt zu erhalten. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst zu testen, und später für die Produktion auf einen kostenpflichtigen Tarif upgraden.Tipp
Erstellen Sie eine Azure KI Services-Ressource, wenn Sie planen, auf mehrere Azure KI Services unter einem einzelnen Endpunkt/Schlüssel zuzugreifen. Erstellen Sie nur für den Zugriff auf Dokument Intelligenz eine Dokument Intelligenz-Ressource. Beachten Sie, dass Sie eine Einzeldienstressource benötigen, wenn Sie die Microsoft Entra-Authentifizierung verwenden möchten.
Erstellen einer Dokument Intelligenz-Ressource
Wechseln Sie zum Azure-Portal und erstellen Sie eine neue Dokument Intelligenz-Ressource . Geben Sie im Bereich Erstellen die folgenden Informationen an:
| Projektdetails | BESCHREIBUNG |
|---|---|
| Abonnement | Wählen Sie das Azure-Abonnement aus, dem Zugriff gewährt wurde. |
| Ressourcengruppe | Die Azure-Ressourcengruppe mit Ihrer Ressource. Sie können eine neue Gruppe erstellen oder sie einer bereits bestehenden Gruppe hinzufügen. |
| Region | Der Speicherort Ihrer Azure KI-Services-Ressource. Verschiedene Speicherorte können Wartezeiten verursachen, haben aber keinen Einfluss auf die Laufzeitverfügbarkeit Ihrer Ressource. |
| Name | Einen aussagekräftigen Namen für Ihre Ressource. Es wird empfohlen, einen aussagekräftigen Namen auszuwählen, z. B. MyNameFormRecognizer. |
| Preisstufe | Die Kosten für Ihre Ressource hängen vom ausgewählten Tarif und Ihrer Nutzung ab. Weitere Informationen finden Sie unter API-Preise. |
| Bewerten + erstellen | Wählen Sie die Schaltfläche Überprüfen + Erstellen aus, um Ihre Ressource auf dem Azure-Portal bereitzustellen. |
Abrufen des Schlüssels und des Endpunkts
Nach Abschluss der Bereitstellung Ihrer Dokument Intelligenz-Ressource suchen Sie diese im Portal in der Liste Alle Ressourcen und wählen sie aus. Schlüssel und Endpunkt befinden sich auf der entsprechenden Seite der Ressource unter Ressourcenverwaltung. Speichern Sie diese beiden Elemente an einem temporären Speicherort, bevor Sie fortfahren.

Analysieren mithilfe eines vordefinierten Modells
Dokument Intelligenz bietet verschiedene vordefinierte Modelle zur Auswahl. Jedes Modell verfügt über einen eigenen Satz unterstützter Felder. Welches Modell für den Analyze-Vorgang verwendet wird, hängt vom Typ des zu analysierenden Dokuments ab. Hier finden Sie die vordefinierten Modelle, die vom Dokument Intelligenz-Dienst derzeit unterstützt werden:
- Rechnung: Extrahieren von Text, Auswahlmarkierungen, Tabellen, Schlüssel-Wert-Paaren und wichtigen Informationen aus Rechnungen
- Beleg: Extrahieren von Text und wichtigen Informationen aus Belegen
- Ausweisdokument: Extrahieren von Text und wichtigen Informationen aus Führerscheinen und Reisepässen
- Visitenkarte: Extrahieren von Text und wichtigen Informationen aus Visitenkarten
Navigieren Sie zum Dokument Intelligenz-Beispieltool.
Wählen Sie auf der Startseite des Beispieltools die Kachel Use prebuilt model to get data (Vordefiniertes Modell zum Abrufen von Daten verwenden) aus.
Wählen Sie im Dropdownfenster den zu analysierenden Formulartyp aus.
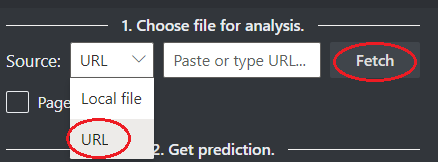
Wählen Sie aus den folgenden Optionen eine URL zu der Datei aus, die Sie analysieren möchten:
Wählen Sie im Feld Quelle die URL aus dem Dropdownmenü aus, fügen Sie die ausgewählte URL ein, und wählen Sie die Schaltfläche Abrufen aus.
Fügen Sie im Feld Dokument Intelligenz-Dienstendpunkt den Endpunkt ein, den Sie mit Ihrem Dokument Intelligenz-Abonnement erhalten haben.
Fügen Sie im Feld Schlüssel den Schlüssel ein, den Sie von Ihrer Dokument Intelligenz-Ressource erhalten haben.
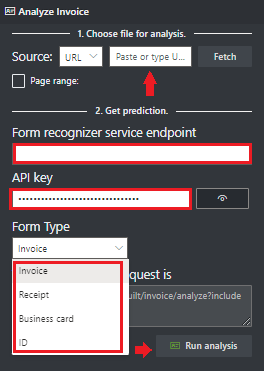
Wählen Sie Run Analysis (Analyse ausführen) aus. Das Dokument Intelligenz-Tool für die Beschriftung von Beispielen ruft die „Analyze Prebuilt“-API auf und analysiert das Dokument.
Zeigen Sie die Ergebnisse an. Sehen Sie sich die extrahierten Schlüssel-Wert-Paare, die Positionen, den extrahierten markierten Text und die erkannten Tabellen an.
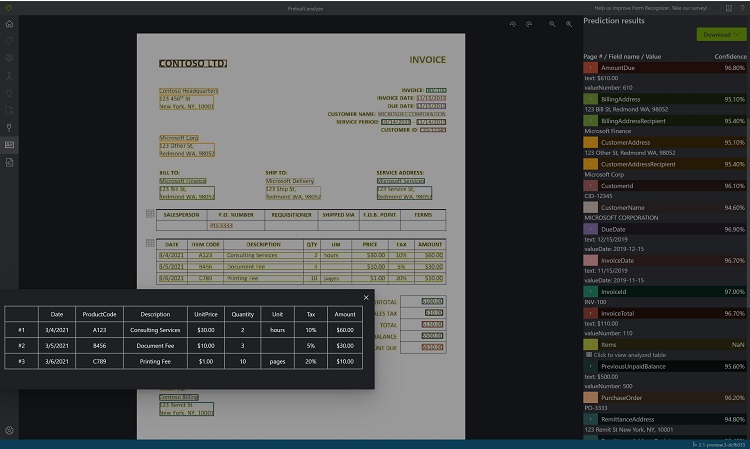
Laden Sie die JSON-Ausgabedatei herunter, um die ausführlichen Ergebnisse anzuzeigen.
- Der Knoten „readResults“ enthält jede Textzeile mit der Platzierung des zugehörigen Begrenzungsrahmens auf der Seite.
- Der Knoten „selectionMarks“ zeigt jede Auswahlmarkierung (Kontrollkästchen, Optionsfeld) und ihren Status (
selectedoderunselected) an. - Der Abschnitt „pageResults“ enthält die extrahierten Tabellen. Für jede Tabelle werden der Text-, Zeilen- und Spaltenindex, die Zeilen- und Spaltenaufteilung, der Begrenzungsrahmen und mehr extrahiert.
- Das Feld „documentResults“ enthält Informationen zu Schlüssel-Wert-Paaren und Positionen für die relevantesten Teile des Dokuments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Analysieren des Layouts
Die Layout-API der Dokument Intelligenz von Azure extrahiert Text, Tabellen, Auswahlmarkierungen und Strukturinformationen aus Dokumenten (PDF, TIFF) und Bildern (JPG, PNG, BMP).
Navigieren Sie zum Dokument Intelligenz-Beispieltool.
Wählen Sie auf der Startseite des Beispieltools die Option Use Layout to get text, tables and selection marks (Layout zum Abrufen von Text, Tabellen und Auswahlmarkierungen verwenden) aus.
Fügen Sie im Feld Dokument Intelligenz-Dienstendpunkt den Endpunkt ein, den Sie mit Ihrem Dokument Intelligenz-Abonnement erhalten haben.
Fügen Sie im Feld Schlüssel den Schlüssel ein, den Sie von Ihrer Dokument Intelligenz-Ressource erhalten haben.
Wählen Sie im Feld Quelle die URL aus dem Dropdownmenü aus, fügen Sie die folgende URL
https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/layout-page-001.jpgein, und wählen Sie die Schaltfläche Abrufen aus.Wählen Sie Run Layout (Layout ausführen) aus. Das Dokument Intelligenz-Tool für die Beschriftung von Beispielen ruft
Analyze Layout APIauf und analysiert das Dokument.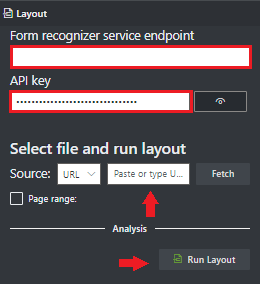
Anzeigen der Ergebnisse: Sehen Sie sich den hervorgehobenen extrahierten Text, die erkannten Auswahlmarkierungen und die erkannten Tabellen an.
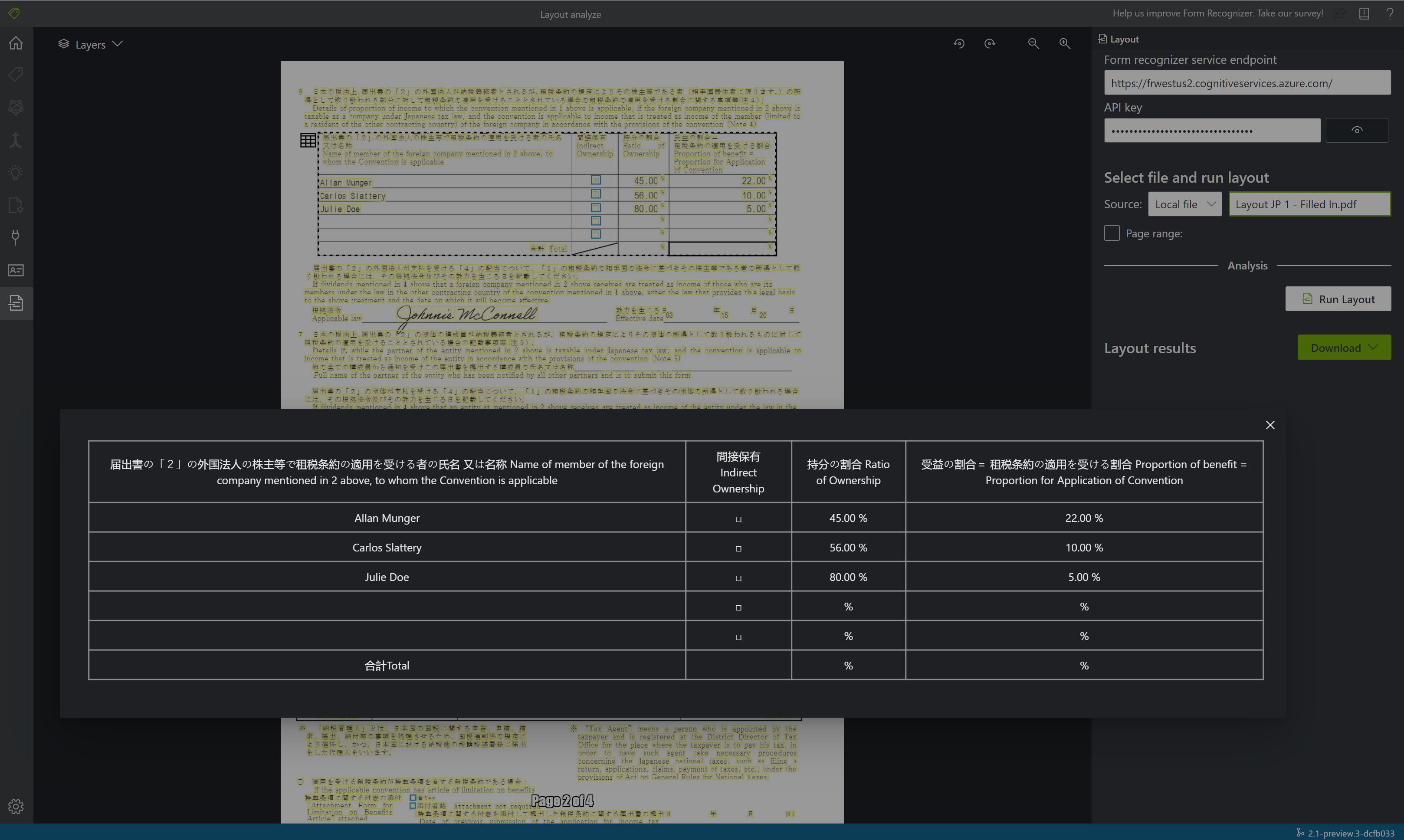
Laden Sie die JSON-Ausgabedatei herunter, um die ausführlichen Layoutergebnisse anzuzeigen.
- Der Knoten
readResultsenthält jede Textzeile mit der Platzierung des zugehörigen Begrenzungsrahmens auf der Seite. - Der Knoten
selectionMarkszeigt jede Auswahlmarkierung (Kontrollkästchen, Optionsfeld) und ihren Status –selectedoderunselected– an. - Der Abschnitt
pageResultsenthält die extrahierten Tabellen. Für jede Tabelle werden der Text-, Zeilen- und Spaltenindex, die Zeilen- und Spaltenaufteilung, der Begrenzungsrahmen und mehr extrahiert.
- Der Knoten
Trainieren eines benutzerdefinierten Formularmodells
Trainieren Sie ein benutzerdefiniertes Modell, um Daten aus Formularen und Dokumenten zu analysieren und zu extrahieren, die für Ihr Unternehmen spezifisch sind. Bei der API handelt es sich um ein maschinelles Lernprogramm, das darauf trainiert ist, Formularfelder innerhalb Ihrer unterschiedlichen Inhalte zu erkennen und Schlüssel-Wert-Paare sowie Tabellendaten zu extrahieren. Am Anfang benötigen Sie mindestens fünf Stichproben desselben Formulartyps, und Ihr benutzerdefiniertes Modell kann mit oder ohne beschriftete Datasets trainiert werden.
Voraussetzungen für das Trainieren eines benutzerdefinierten Formularmodells
Ein Azure Storage-Blobcontainer, der eine Reihe von Trainingsdaten enthält. Stellen Sie sicher, dass alle Trainingsdokumente im selben Format vorliegen. Wenn Ihre Formulare unterschiedliche Formate aufweisen, sortieren Sie sie in Unterordner für jeweils ein Format. Für dieses Projekt können Sie unser Beispieldataset verwenden.
Wenn Sie nicht wissen, wie Sie ein Azure Storage-Konto mit einem Container erstellen, folgen Sie den Anweisungen im Azure Storage-Schnellstart für das Azure-Portal.
Konfigurieren von CORS
Für Ihr Azure-Speicherkonto muss CORS (Cross Origin Resource Sharing) konfiguriert sein, damit es über das Dokument Intelligenz-Studio zugänglich ist. Zum Konfigurieren von CORS im Azure-Portal benötigen Sie Zugriff auf die Registerkarte „CORS“ Ihres Speicherkontos.
Wählen Sie die Registerkarte „CORS“ für das Speicherkonto aus.
Erstellen Sie zunächst einen neuen CORS-Eintrag im Blob-Dienst.
Setzen Sie die Erlaubten Ursprünge auf
https://fott-2-1.azurewebsites.net.
Tipp
Sie können anstelle der Domäne auch das Platzhalterzeichen „*“ verwenden, um allen Ursprungsdomänen die Ausführung von CORS-Anforderungen zu erlauben.
Wählen Sie für Zulässige Methoden alle verfügbaren acht Optionen aus.
Genehmigen Sie die Angaben für Zulässige Header und Verfügbar gemachte Header, indem Sie in jedes Feld ein Sternchen (*) eingeben.
Legen Sie für Max. Alter 120 Sekunden oder einen anderen gültigen Wert ein.
Wählen Sie oben auf der Seite die Schaltfläche „Speichern“ aus, um die Änderungen zu speichern.
Verwenden des Tools für die Beschriftung von Beispielen
Navigieren Sie zum Dokument Intelligenz-Beispieltool.
Wählen Sie auf der Startseite des Beispieltools die Option Use Custom to train a model with labels and get key value pairs (Benutzerdefinierte Option zum Trainieren eines Modells mit Beschriftungen und Abrufen von Schlüssel-Wert-Paaren verwenden) aus.
Wählen Sie New Project (Neues Projekt) aus.
Erstellen eines neuen Projekts
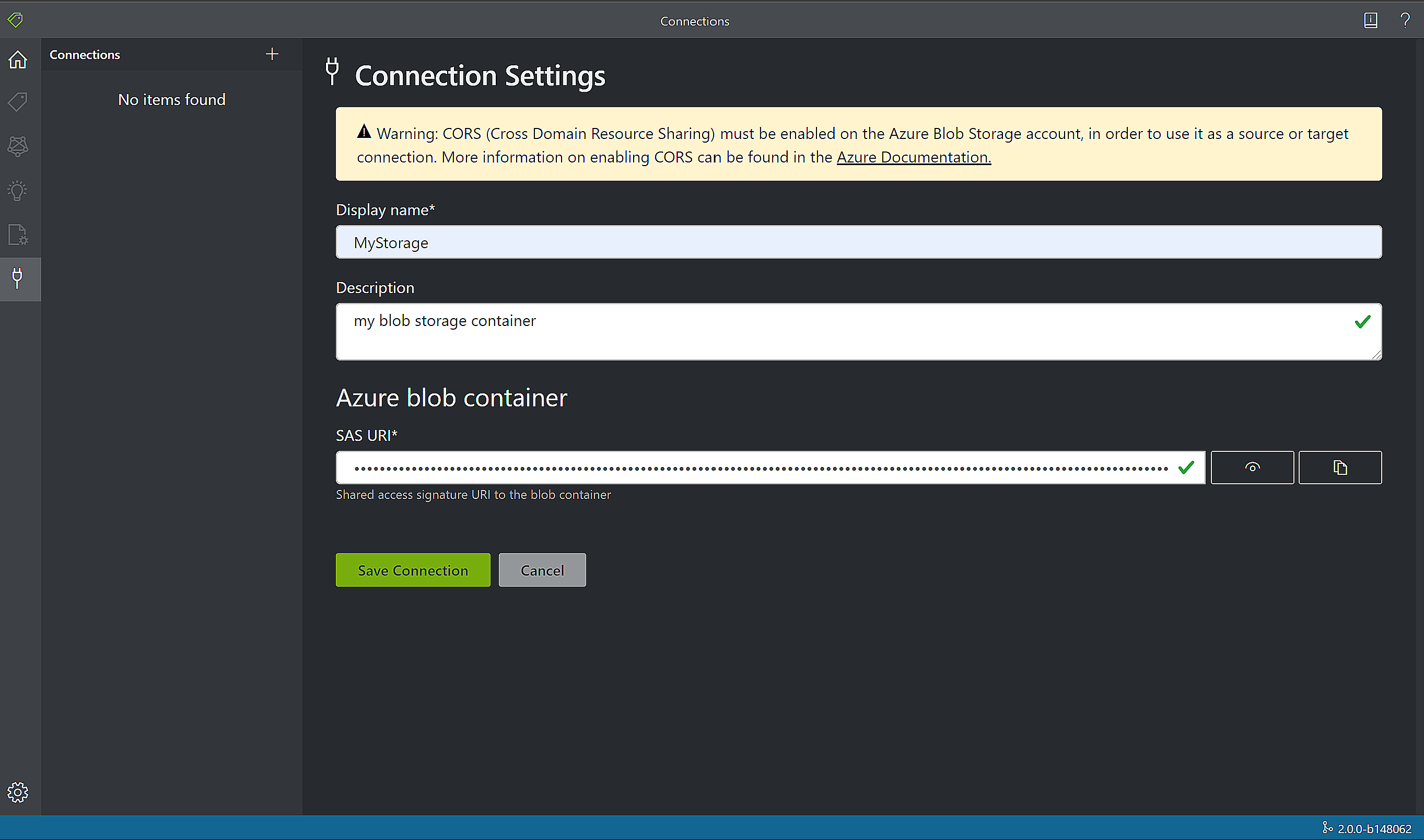
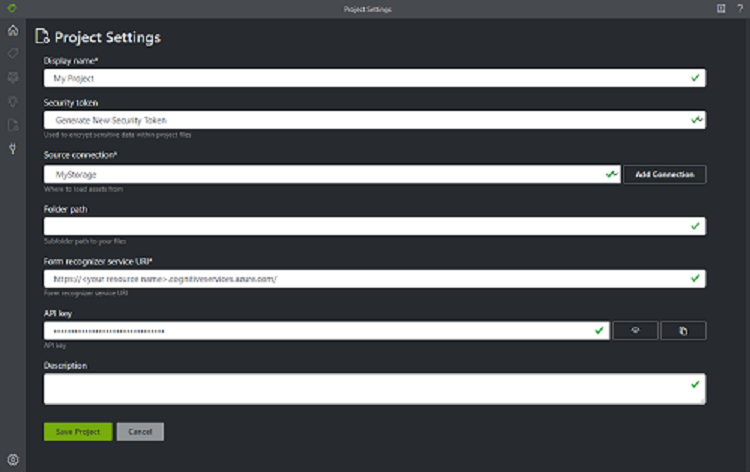
Konfigurieren Sie die Felder Project Settings (Projekteinstellungen) mit den folgenden Werten:
Display Name (Anzeigename). Geben Sie dem Projekt einen Namen.
Security Token (Sicherheitstoken). Jedes Projekt generiert automatisch ein Sicherheitstoken, das zum Ver- und Entschlüsseln von vertraulichen Projekteinstellungen verwendet werden kann. Sie finden die Sicherheitstoken in den Anwendungseinstellungen, indem Sie unten auf der linken Navigationsleiste das Zahnradsymbol auswählen.
Source connection (Quellverbindung). Das Tool für die Beschriftung von Beispielen stellt eine Verbindung mit einer Quelle (Ihre hochgeladenen Originalformulare) und einem Ziel (erstellte Beschriftungen und Ausgabedaten) her. Verbindungen können projektübergreifend eingerichtet und freigegeben werden. Dabei wird ein erweiterbares Anbietermodell verwendet, sodass Sie ganz einfach neue Anbieter von Quellen und Zielen hinzufügen können.
- Erstellen Sie eine neue Verbindung, und wählen Sie die Schaltfläche Add Connection (Verbindung hinzufügen) aus. Geben Sie die folgenden Werte in die Felder ein:
- Display Name (Anzeigename). Vergeben Sie einen Namen für die Verbindung.
- Beschreibung. Fügen Sie eine kurze Beschreibung hinzu.
- SAS URL (SAS-URL). Fügen Sie die Shared Access Signature-URL (SAS) Ihres Azure Blob Storage-Containers ein.
Navigieren Sie zu Ihrer Speicherressource im Azure-Portal, und wählen Sie die Registerkarte Speicher-Explorer aus, um die SAS-URL für Ihre benutzerdefinierten Modelltrainingdaten abzurufen. Wechseln Sie zum Container, klicken Sie mit der rechten Maustaste auf diesen, und wählen Sie Shared Access Signature abrufen aus. Achten Sie darauf, die SAS für den Container abzurufen, nicht für das Speicherkonto. Stellen Sie sicher, dass die Berechtigungen Lesen, Schreiben, Löschen und Auflisten aktiviert sind, und wählen Sie anschließend Erstellen aus. Kopieren Sie den Wert im Abschnitt URL dann an einen temporären Speicherort. Er muss das Format
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>aufweisen.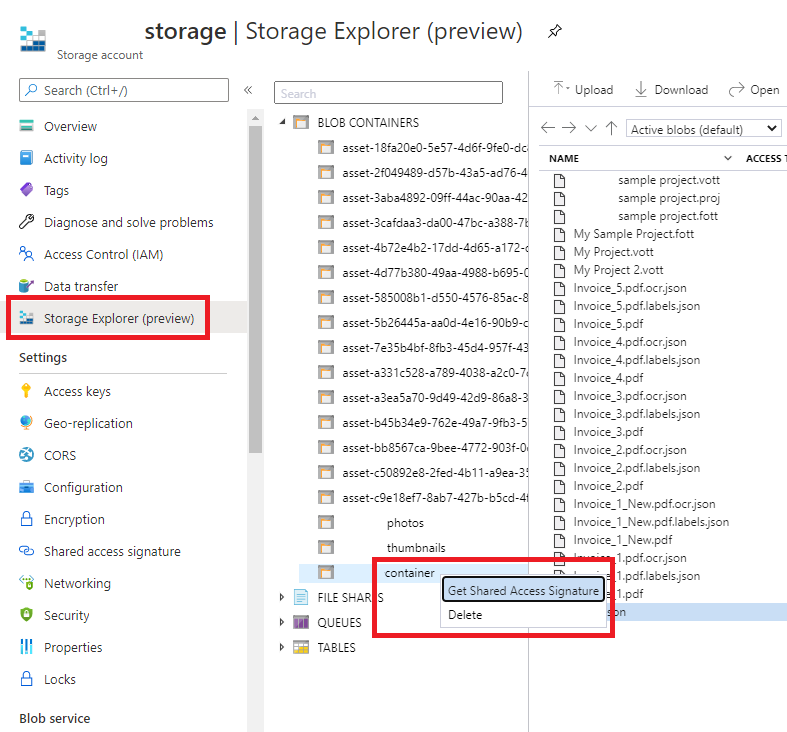
Folder Path (Ordnerpfad) (optional). Wenn sich Ihre Quellformulare in einem Ordner im Blobcontainer befinden, geben Sie den Ordnernamen an.
Dokument Intelligenz-Dienst-URI – Ihre Endpunkt-URL für Dokument Intelligenz.
Schlüssel. Ihr Dokument Intelligenz-Schlüssel.
API-Version. Behalten Sie den Standardwert bei (v2.1).
Beschreibung (optional). Beschreiben Sie Ihr Projekt.
Beschriften Ihrer Formulare
Wenn Sie ein Projekt erstellen oder öffnen, wird das Hauptfenster des Beschriftungs-Editors geöffnet. Der Beschriftungs-Editor besteht aus drei Teilen:
- Ein Vorschaubereich, dessen Größe angepasst werden kann und der eine scrollbare Liste mit Formularen aus der Quellverbindung enthält.
- Der Hauptbereich des Editors, in dem Sie Beschriftungen anwenden können.
- Der Bearbeitungsbereich des Editors, in dem Sie Beschriftungen ändern, sperren, neu anordnen und löschen können.
Identifizieren von Text und Tabellen
Wählen Sie im linken Bereich Layout für nicht besuchte Dokumente ausführen aus, um Text- und Tabellenlayoutinformationen für jedes Dokument abzurufen. Das Beschriftungstool zeichnet einen Begrenzungsrahmen um jedes Textelement.
Das Beschriftungstool zeigt außerdem an, welche Tabellen automatisch extrahiert wurden. Wählen Sie das Tabellen-/Rastersymbol auf der linken Seite des Dokuments aus, um die extrahierte Tabelle anzuzeigen. Da der Tabelleninhalt automatisch extrahiert wird, werden Sie ihn nicht beschriften, sondern verlassen sich auf die automatisierte Extraktion.
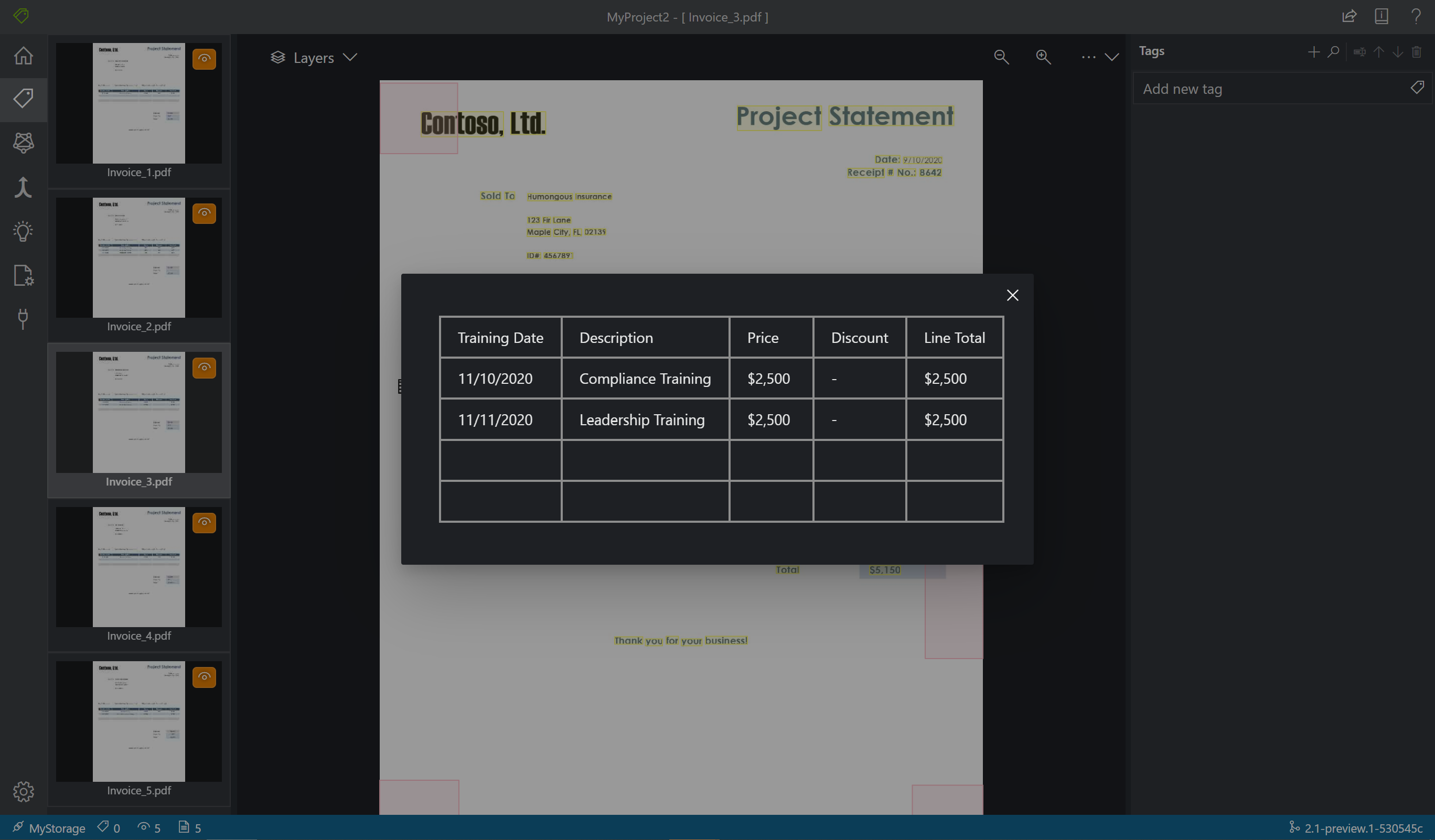
Anwenden von Beschriftungen auf Text
Als Nächstes erstellen Sie Tags (Bezeichnungen) und wenden sie auf die Textelemente an, die das Modell analysieren soll. Beachten Sie, dass das Dataset für die Stichprobenbeschriftung bereits beschriftete Felder enthält. Sie fügen ein weiteres Feld hinzu.
Verwenden Sie den Tag-Editor-Bereich, um ein neues Tag zu erstellen, das identifiziert werden soll:
Wählen Sie + (Pluszeichen) aus, um ein neues Tag zu erstellen.
Geben Sie als Namen des Tags „Total“ ein.
Drücken Sie die EINGABETASTE, um das Tag zu speichern.
Wählen Sie im Hauptbereich des Editors den Gesamtwert in den markierten Textelementen aus.
Wählen Sie das Tag „Total“ aus, das auf den Wert angewendet werden soll, oder drücken Sie die entsprechende Taste auf der Tastatur. Die Zifferntasten sind als Schnellzugriffstasten für die ersten zehn Tags zugewiesen. Sie können die Beschriftungen mithilfe der nach oben und unten weisenden Pfeilsymbole im Bearbeitungsbereich neu anordnen. Führen Sie die folgenden Schritte aus, um alle fünf Formulare im Beispieldataset zu beschriften:
Tipp
Beachten Sie beim Beschriften Ihrer Formulare die folgenden Tipps:
Sie können auf jedes ausgewählte Element nur ein Tag anwenden.
Jedes Tag kann nur einmal pro Seite angewendet werden. Wenn ein Wert in demselben Formular mehrfach erscheint, sollten Sie für jede Instanz andere Tags erstellen. Beispiel: „rechnung 1“, „rechnung 2“ usw.
Tags können nicht seitenübergreifend genutzt werden.
Beschriften Sie Werte so, wie sie im Formular vorkommen. Versuchen Sie nicht, einen Wert mit zwei unterschiedlichen Tags in zwei Teile zu unterteilen. Ein Adressfeld sollte beispielsweise auch dann nur mit einem Tag beschriftet werden, wenn es über mehrere Zeilen verläuft.
Fügen Sie in Ihre beschrifteten Felder keine Schlüssel ein, sondern nur die Werte.
Die Tabellendaten sollten automatisch erkannt werden und sind in der fertigen JSON-Ausgabedatei im Abschnitt „pageResults“ enthalten. Wenn das Modell jedoch nicht alle Tabellendaten erkennt, können Sie auch Beschriftungen hinzufügen und ein Modell speziell für die Erkennung von Tabellen trainieren. Weitere Informationen finden Sie unter Trainieren eines benutzerdefinierten Modells | Beschriften von Formularen.
Verwenden Sie die Schaltflächen rechts neben dem + -Zeichen, um Ihre Tags zu suchen, umzubenennen, neu anzuordnen und zu löschen.
Um ein angewendetes Tag zu entfernen, ohne das Tag selbst zu löschen, wählen Sie das Tagrechteck in der Dokumentansicht aus und drücken die Taste ENTF.
Trainieren eines benutzerdefinierten Modells
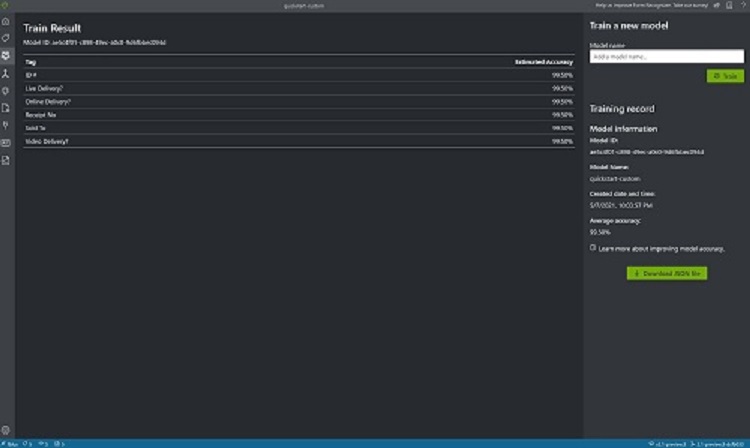
Wählen Sie im linken Bereich das Symbol „Trainieren“ aus, um die Seite „Training“ zu öffnen. Wählen Sie dann die Schaltfläche Trainieren aus, um mit dem Training des Modells zu beginnen. Sobald der Trainingsprozess abgeschlossen ist, sehen Sie folgende Informationen:
Modell-ID: Die ID des Modells, das erstellt und trainiert wurde. Jeder Trainingsaufruf erstellt ein neues Modell mit eigener ID. Kopieren Sie diese Zeichenfolge an einen sicheren Speicherort. Sie werden sie benötigen, wenn Sie Vorhersageaufrufe über die REST-API oder die Clientbibliothek ausführen.
Durchschnittliche Genauigkeit: Die durchschnittliche Genauigkeit des Modells. Sie können die Modellgenauigkeit verbessern, indem Sie weitere Formulare beschriften und erneut ein Training ausführen, um ein neues Modell zu erstellen. Es wird empfohlen, zunächst fünf Formulare zu beschriften sowie die Ergebnisse zu analysieren und zu testen, um dann bei Bedarf weitere Formulare hinzuzufügen.
Die Liste der Beschriftungen und die geschätzte Genauigkeit für jede Beschriftung. Weitere Informationen finden Sie unter Interpretieren und Verbessern von Genauigkeit und Konfidenz.
Analysieren eines benutzerdefinierten Formulars
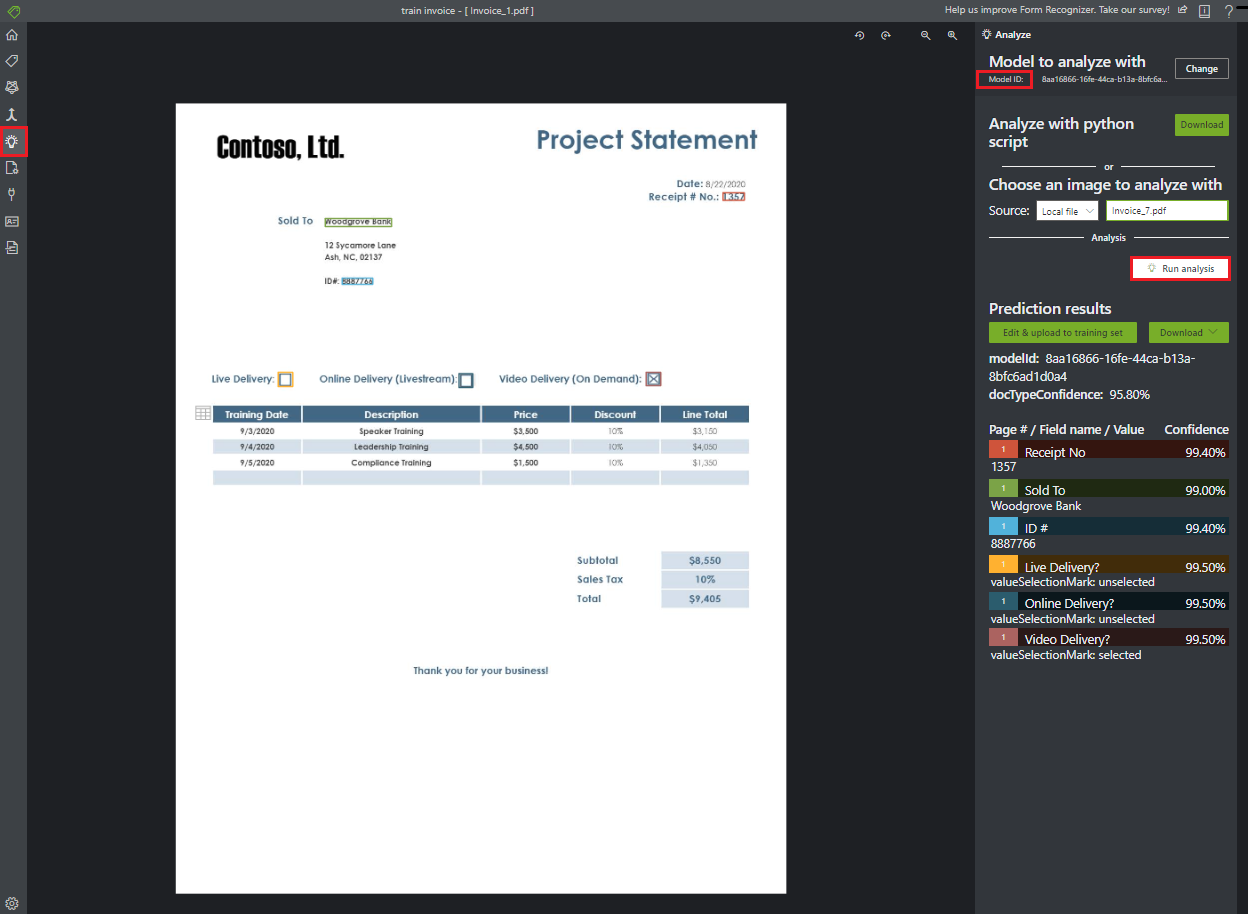
Wählen Sie das Symbol
Analyzeauf der Navigationsleiste aus, und testen Sie Ihr Modell.Wählen Sie Local file (Lokale Datei) aus, und suchen Sie im Beispieldataset, das Sie im Testordner entpackt haben, nach einer Datei.
Wählen Sie dann die Schaltfläche Analyse ausführen aus, um Schlüssel-Wert-Paare, Text- und Tabellenvorhersagen für das Formular abzurufen. Das Tool wendet Tags in Begrenzungsrahmen an und berichtet die Konfidenz jeder Beschriftung.
Das ist alles! Sie haben erfahren, wie Sie das Dokument Intelligenz-Tool für Stichproben für vordefinierte, Layout- und benutzerdefinierte Dokument Intelligenz-Modelle verwenden. Sie haben auch gelernt, wie Sie ein benutzerdefiniertes Formular mit manuell beschrifteten Daten analysieren.