Lösungsmöglichkeiten
Dieser Artikel ist ein Lösungsvorschlag. Wenn Sie möchten, dass wir diesen Artikel um weitere Informationen ergänzen, z. B. potenzielle Anwendungsfälle, alternative Dienste, Überlegungen zur Implementierung oder Preisempfehlungen, lassen Sie es uns über Feedback auf GitHub wissen.
Dieser Artikel ist ein Implementierungsleitfaden und ein Beispielszenario, das eine Beispielbereitstellung der Lösung enthält, die unter Implementieren der benutzerdefinierten Spracherkennung beschrieben wird:
Aufbau
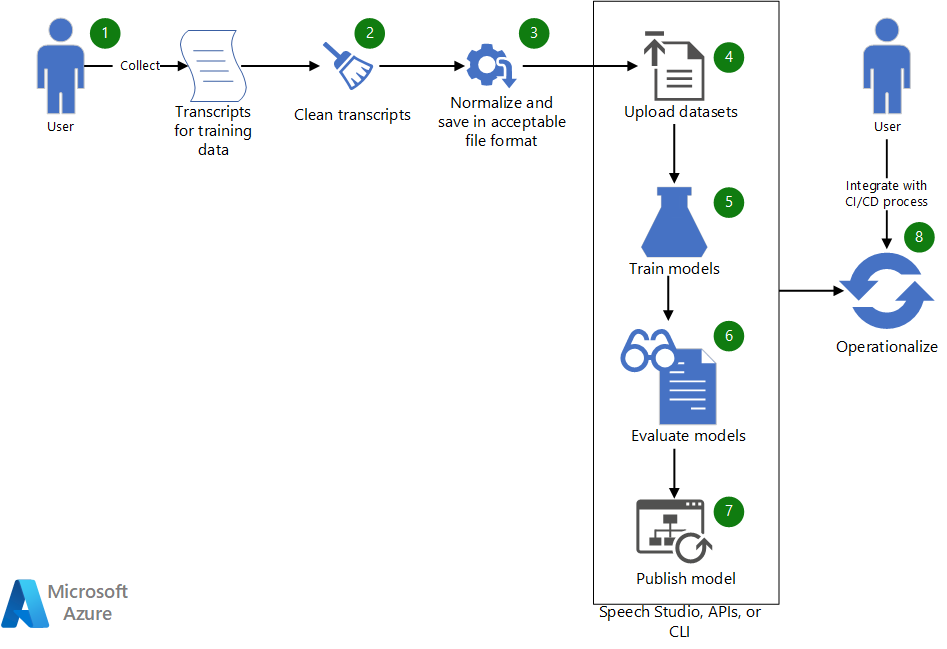
Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
- Sammeln Sie vorhandene Transkripte, um ein benutzerdefiniertes Sprachmodell zu trainieren.
- Wenn die Transkripte im WebVTT- oder SRT-Format vorliegen, bereinigen Sie die Dateien, sodass sie nur die Textteile der Transkripte enthalten.
- Normalisieren Sie den Text, indem Sie alle Satzzeichen entfernen, wiederholte Wörter trennen und alle großen numerischen Werte buchstabieren. Sie können mehrere bereinigte Transkripte zu einem kombinieren, um einen Dataset zu erstellen. Erstellen Sie auf ähnliche Weise ein Dataset zum Testen.
- Nachdem die Datasets bereit sind, laden Sie sie mithilfe von Speech Studio hoch. Wenn sich das Dataset in einem Blob-Speicher befindet, können Sie alternativ die Azure Spracherkennungs-API (Speech-to-Language, STT) und die Speech-CLI verwenden. In der API und der CLI können Sie den URI des Datasets an eine Eingabe übergeben, um ein Dataset für Modelltraining und -tests zu erstellen.
- Verwenden Sie in Speech Studio oder über die API oder CLI das neue Dataset, um ein benutzerdefiniertes Sprachmodell zu trainieren.
- Werten Sie das neu trainierte Modell anhand des Testdatasets aus.
- Wenn die Leistung des benutzerdefinierten Modells Ihren Qualitätserwartungen entspricht, veröffentlichen Sie es zur Verwendung in der Sprachtranskription. Verwenden Sie andernfalls Speech Studio, um die Wortfehlerrate (WER) und bestimmte Fehlerdetails zu überprüfen und zu ermitteln, welche zusätzlichen Daten für das Training erforderlich sind.
- Verwenden Sie die APIs und die CLI, um den Modellerstellungs-, Auswertungs- und Bereitstellungsprozess zu operationalisieren.
Komponenten
- Azure Machine Learning ist ein Dienst für den End-to-End-Lebenszyklus für maschinelles Lernen auf Unternehmensniveau.
- Azure KI Services besteht aus einer Reihe von APIs, SDKs und Diensten, die Ihnen dabei helfen können, Ihre Anwendungen intelligenter, ansprechender und auffindbarer zu machen.
- Speech Studio besteht aus einer Reihe von benutzeroberflächenbasierten Tools zum Erstellen und Integrieren von Features aus dem Azure KI Speech-Dienst in Ihre Anwendungen. Hierbei ist es eine Alternative für Trainingsdatasets. Es wird auch zur Überprüfung von Trainingsergebnissen verwendet.
- Die Spracherkennungs-REST-API ist eine API, mit der Sie Ihre eigenen Daten hochladen, ein benutzerdefiniertes Modell testen und trainieren, die Genauigkeit zwischen Modellen vergleichen und ein Modell an einem benutzerdefinierten Endpunkt bereitstellen können. Sie können sie auch verwenden, um die Erstellung, Auswertung und Bereitstellung Ihres Modells zu operationalisieren.
- Die Speech-CLI ist ein Befehlszeilentool, mit dem der Speech-Dienst verwendet werden kann, ohne dass Code geschrieben werden muss. Sie bietet eine weitere Alternative zum Erstellen und Trainieren von Datasets und zur Operationalisierung Ihrer Prozesse.
Szenariodetails
Dieser Artikel basiert auf dem folgenden fiktiven Szenario:
Contoso, Ltd., ist ein Broadcast-Medienunternehmen, das Übertragungen und Kommentare zu Olympischen Veranstaltungen sendet und kommentiert. Als Teil der Übertragungsvereinbarung stellt Contoso eine Ereignistranskription für Barrierefreiheit und Data Mining bereit.
Contoso möchte den Azure Speech-Dienst verwenden, um Live-Untertitelung und Audiotranskription für Olympische Veranstaltungen bereitzustellen. Contoso beschäftigt weibliche und männliche Kommentatoren aus aller Welt, die mit unterschiedlichen Akzenten sprechen. Darüber hinaus verfügt jeder einzelne Sport über eine spezifische Terminologie, die die Transkription erschweren kann. In diesem Artikel wird der Anwendungsentwicklungsprozess für dieses Szenario beschrieben: Bereitstellen von Untertiteln für eine Anwendung, die eine genaue Ereignistranskription bereitstellen muss.
Contoso verfügt bereits über die folgenden erforderlichen Komponenten:
- Von Menschen generierte Transkripte für frühere Olympische Veranstaltungen. Die Transkripte stellen Kommentare aus verschiedenen Sportarten und diversen Kommentatoren dar.
- Eine Azure Cognitive Service-Ressource. Sie können eine im Azure-Portal erstellen.
Entwickeln einer benutzerdefinierten sprachbasierten Anwendung
Eine sprachbasierte Anwendung verwendet das Azure Speech SDK zum Herstellen einer Verbindung mit dem Azure Speech-Dienst zum Generieren einer textbasierten Audiotranskription. Der Sprachdienst unterstützt verschiedene Sprachen und zwei Sprachmodi: Konversation und Diktat. Um eine benutzerdefinierte sprachbasierte Anwendung zu entwickeln, müssen Sie im Allgemeinen die folgenden Schritte ausführen:
- Verwenden Sie Speech Studio, Azure Speech SDK, Speech-CLI oder die REST-API, um Transkripte für gesprochene Sätze und Äußerungen zu generieren.
- Vergleichen Sie das generierte Transkript mit dem von Menschen erstellten Transkript.
- Wenn bestimmte domänenspezifische Wörter falsch transkribiert werden, sollten Sie ein benutzerdefiniertes Sprachmodell für diese bestimmte Domäne erstellen.
- Sehen Sie sich verschiedene Optionen zum Erstellen benutzerdefinierter Modelle an. Entscheiden Sie, ob ein oder mehrere benutzerdefinierte Modelle besser funktionieren.
- Sammeln Sie Trainings- und Testdaten.
- Stellen Sie sicher, dass die Daten ein akzeptables Format aufweisen.
- Trainieren, testen und bewerten Sie das Modell und stellen Sie es bereit.
- Verwenden Sie das benutzerdefinierte Modell für die Transkription.
- Operationalisieren Sie den Modellerstellungs-, Auswertungs- und Bereitstellungsprozess.
Schauen wir uns diese Schritte genauer an:
1. Verwenden Sie Speech Studio, Azure Speech SDK, Speech-CLI oder die REST-API, um Transkripte für gesprochene Sätze und Äußerungen zu generieren
Azure Speech bietet SDKs, eine CLI-Schnittstelle und eine REST-API zum Generieren von Transkripten aus Audiodateien oder direkt aus Mikrofoneingaben. Wenn sich der Inhalt in einer Audiodatei befindet, muss er in einem unterstützten Format vorliegen. In diesem Szenario verfügt Contoso über frühere Ereignisaufzeichnungen (Audio und Video) in AVI-Dateien. Contoso kann Tools wie FFmpeg verwenden, um Audio aus den Videodateien zu extrahieren und in einem Format zu speichern, das vom Azure Speech SDK unterstützt wird, z. B. WAV.
Im folgenden Code wird der Standard-PCM-Audiocodec pcm_s16le verwendet, um Audio in einem einzelnen Kanal (Mono) mit einer Abtastrate von 8 Kilohertz (kHz) zu extrahieren.
ffmpeg.exe -i INPUT_FILE.avi -acodec pcm_s16le -ac 1 -ar 8000 OUTPUT_FILE.wav
2. Vergleichen Sie das generierte Transkript mit dem von Menschen erstellten Transkript
Um den Vergleich durchzuführen, nimmt Contoso Audiokommentare von mehreren Sportarten auf und verwendet Speech Studio, um das von Menschen erstellte Transkript mit den vom Azure Speech-Dienst transkribierten Ergebnissen zu vergleichen. Die von Contoso von Menschen erstellten Transkripte liegen in einem WebVTT-Format vor. Um diese Transkripte zu verwenden, bereinigt Contoso sie und generiert eine einfache TXT-Datei mit normalisiertem Text ohne die Zeitstempelinformationen.
Informationen zur Verwendung von Speech Studio zum Erstellen und Auswerten eines Datasets finden Sie unter Training und Testdatasets.
Speech Studio bietet einen parallelen Vergleich des vom Menschen generierten Transkripts und der Transkripte, die aus den für den Vergleich ausgewählten Modellen erstellt wurden. Die Testergebnisse enthalten eine WER für die Modelle, wie hier gezeigt:
| Modell | Fehlerrate | Einfügevorgang | Substitution | Löschen |
|---|---|---|---|---|
| Modell 1: 20211030 | 14,69 % | 6 (2,84 %) | 22 (10,43 %) | 3 (1,42 %) |
| Modell 2: Olympics_Skiing_v6 | 6,16 % | 3 (1,42 %) | 8 (3,79 %) | 2 (0,95 %) |
Weitere Informationen zu WER finden Sie unter Auswerten der Wortfehlerrate.
Basierend auf diesen Ergebnissen ist das benutzerdefinierte Modell (Olympics_Skiing_v6) für den Dataset besser als das Basismodell (20211030).
Beachten Sie die Werte für Einfügen und Löschen, die angeben, dass die Audiodatei relativ sauber ist und geringe Hintergrundgeräusche aufweist.
3. Wenn bestimmte domänenspezifische Wörter falsch transkribiert werden, sollten Sie ein benutzerdefiniertes Sprachmodell für diese bestimmte Domäne erstellen
Basierend auf den Ergebnissen in der vorherigen Tabelle werden für das Basismodell Modell 1: 20211030 etwa 10 Prozent der Wörter ersetzt. Verwenden Sie in Speech Studio die Funktion zum detaillierten Vergleich, um fehlende domänenspezifische Wörter zu identifizieren. Die folgende Tabelle zeigt einen Abschnitt des Vergleichs.
| Vom Menschen generiertes Transkript | Modell 1 | Modell 2 |
|---|---|---|
| Olympiasieger zurück zurück bergab seit neunzehn achtundneunzig die große Katja Seizinger aus Deutschland was vierundneunzig und achtundneunzig | Olympiasieger zurück zurück bergab seit neunzehn achtundneunzig die große eine Dimensionierung erfassen sind aus Deutschland was vierundneunzig und achtundneunzig | Olympiasieger zurück zurück bergab seit neunzehn achtundneunzig die große Katja Seizinger aus Deutschland was vierundneunzig und achtundneunzig |
| sie hat die Olympiasiegerin Goggia entthront | sie hat die Olympiasiegerin Georgia entthront | sie hat die Olympiasiegerin Goggia entthront |
Modell 1 erkennt domänenspezifische Wörter wie die Namen der Athletinnen „Katja Seizinger“ und „Goggia“ nicht. Wenn das benutzerdefinierte Modell jedoch mit Daten trainiert wird, die die Namen der Athletinnen und andere domänenspezifische Wörter und Ausdrücke enthalten, ist es in der Lage, sie zu lernen und zu erkennen.
4. Sehen Sie sich verschiedene Optionen zum Erstellen benutzerdefinierter Modelle an. Entscheiden Sie, ob ein oder mehrere benutzerdefinierte Modelle besser funktionieren.
Durch das Experimentieren mit verschiedenen Möglichkeiten zum Erstellen benutzerdefinierter Modelle stellte Contoso fest, dass sie eine bessere Genauigkeit erreichen konnten, indem sie die Anpassung von Sprache und Aussprachemodellen verwendeten. (Siehe den ersten Artikel in diesem Leitfaden.) Contoso stellte auch geringfügige Verbesserungen fest, wenn sie akustische Daten (Originalaudio) zum Erstellen des benutzerdefinierten Modells enthielten. Die Vorteile waren jedoch nicht signifikant genug, um die Wartung und das Training für ein benutzerdefiniertes Akustikmodell lohnenswert zu machen.
Contoso hat festgestellt, dass das Erstellen separater benutzerdefinierter Sprachmodelle für jede Sportart (ein Modell für alpines Skifahren, ein Modell für Rennrodeln, ein Modell für Snowboarden usw.) bessere Erkennungsergebnisse liefert. Sie stellten auch fest, dass die Erstellung separater akustischer Modelle basierend auf der Sportart zur Erweiterung der Sprachmodelle nicht erforderlich war.
5. Sammeln Sie Trainings- und Testdaten
Der Artikel Training und Testdatasets enthält Details zum Sammeln der Daten, die für das Training eines benutzerdefinierten Modells erforderlich sind. Contoso sammelte Transkripte für verschiedene Olympische Sportarten von verschiedenen Kommentatoren und verwendete Sprachmodellanpassung, um ein Modell pro Sporttyp zu erstellen. Sie verwendeten jedoch eine Aussprachedatei für alle benutzerdefinierten Modelle (eine für jede Sportart). Da die Test- und Trainingsdaten getrennt gehalten werden, verwendete Contoso nach dem Erstellen eines benutzerdefinierten Modells Ereignisaudiodaten, deren Transkripte nicht im Trainingsdataset für die Modellauswertung enthalten waren.
6. Stellen Sie sicher, dass die Daten ein akzeptables Format aufweisen
Wie unter Training und Testdatasets beschrieben, müssen Datasets, die zum Erstellen eines benutzerdefinierten Modells oder zum Testen des Modells verwendet werden, in einem bestimmten Format vorliegen. Die Daten von Contoso sind in WebVTT-Dateien enthalten. Sie erstellten einige einfache Tools, um Textdateien zu erstellen, die normalisierten Text für die Anpassung des Sprachmodells enthalten.
7. Trainieren, testen und bewerten Sie das Modell und stellen Sie es bereit
Neue Ereignisaufzeichnungen werden verwendet, um das trainierte Modell weiter zu testen und auszuwerten. Es kann einige Iterationen von Tests und Auswertungen erfordern, um ein Modell zu optimieren. Wenn das Modell Transkripte generiert, die akzeptable Fehlerraten aufweisen, wird es bereitgestellt (veröffentlicht), um vom SDK genutzt zu werden.
8. Verwenden Sie das benutzerdefinierte Modell für die Transkription
Nachdem das benutzerdefinierte Modell bereitgestellt wurde, können Sie den folgenden C#-Code verwenden, um das Modell im SDK für die Transkription zu verwenden:
String endpoint = "Endpoint ID from Speech Studio";
string locale = "en-US";
SpeechConfig config = SpeechConfig.FromSubscription(subscriptionKey: speechKey, region: region);
SourceLanguageConfig sourceLanguageConfig = SourceLanguageConfig.FromLanguage(locale, endPoint);
recognizer = new SpeechRecognizer(config, sourceLanguageConfig, audioInput);
Hinweise zum Code:
endpointist die Endpunkt-ID des benutzerdefinierten Modells, das in Schritt 7 bereitgestellt wird.subscriptionKeyundregionsind der Azure KI Services-Abonnementschlüssel und die Region. Sie können diese Werte aus dem Azure-Portal abrufen, indem Sie zur Ressourcengruppe wechseln, in der die Azure KI Services-Ressource erstellt wurde, und sich ihre Schlüssel ansehen.
9. Operationalisieren Sie den Modellerstellungs-, Auswertungs- und Bereitstellungsprozess
Nachdem das benutzerdefinierte Modell veröffentlicht wurde, muss es regelmäßig ausgewertet und aktualisiert werden, wenn ein neues Vokabular hinzugefügt wird. Ihr Unternehmen kann sich weiterentwickeln und Sie benötigen möglicherweise mehr benutzerdefinierte Modelle, um die Abdeckung für mehr Domänen zu erhöhen. Das Azure Speech-Team veröffentlicht auch neue Basismodelle, die mit mehr Daten trainiert werden, sobald sie verfügbar werden. Automatisierung kann Ihnen helfen, mit diesen Änderungen Schritt zu halten. Der nächste Abschnitt dieses Artikels enthält weitere Details zur Automatisierung der vorherigen Schritte.
Bereitstellen dieses Szenarios
Informationen zur Verwendung von Skripts zum Optimieren und Automatisieren des gesamten Prozesses der Erstellung von Datasets für das Training und Testen, das Erstellen und Auswerten von Modellen sowie die Veröffentlichung neuer Modelle bei Bedarf finden Sie unter Benutzerdefinierte Spracherkennung auf GitHub.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Pratyush Mishra | Principal Engineering Manager
Andere Mitwirkende:
- Mick Alberts | Technical Writer
- Rania Bayoumy | Senior Technical Program Manager
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Was ist Custom Speech?
- Was ist Sprachsynthese?
- Trainieren eines Custom Speech-Modells
- Implementieren von benutzerdefinierter Spracherkennung
- Benutzerdefinierte Spracherkennung von Azure auf GitHub