Zwischenspeichern ist eine gängige Methode zur Verbesserung der Leistung und Skalierbarkeit eines Systems. Die Zwischenspeicherung erfolgt durch vorübergehendes Kopieren häufig verwendeter Daten in einen schnellen Speicher, der sich in der Nähe der Anwendung befindet. Wenn sich dieser schnelle Datenspeicher näher an der Anwendung befindet als die ursprüngliche Datenquelle, kann Zwischenspeichern die Antwortzeiten für Clientanwendungen erheblich verbessern und die Daten schneller bereitstellen.
Zwischenspeichern ist am effektivsten, wenn eine Instanz des Clients wiederholt die gleichen Daten liest – insbesondere dann, wenn alle folgenden Kriterien für den ursprünglichen Datenspeicher gelten:
- Er bleibt relativ statisch.
- Er ist langsam verglichen mit der Geschwindigkeit des Caches.
- Er unterliegt in hohem Maße Konflikten.
- Er ist weit weg, wenn die Netzwerklatenz den Zugriff verlangsamt.
Caching in verteilten Anwendungen
Verteilte Anwendungen stellen für das Zwischenspeichern von Daten meist eine oder beide der folgenden Strategien bereit:
- Sie verwenden einen privaten Cache, in dem Daten lokal auf dem Computer gespeichert werden, auf dem eine Instanz der Anwendung oder des Diensts ausgeführt wird.
- Sie verwenden einen freigegebenen Cache, der als gemeinsame Datenquelle für mehrere Prozesse und Computer dient.
In beiden Fällen kann Zwischenspeichern vom Client und Server ausgeführt werden. Clientseitiges Zwischenspeichern erfolgt durch den Prozess, der die Benutzeroberfläche für ein System, z. B. einen Webbrowser oder eine Desktopanwendung, bereitstellt. Serverseitiges Zwischenspeichern erfolgt durch den Prozess, der Unternehmensdienste bereitstellt, die remote ausgeführt werden.
Privates Caching
Die einfachste Art des Caches ist ein In-Memory-Speicher. Er wird im Adressbereich eines einzelnen Prozesses gespeichert, und der in diesem Prozess ausgeführte Code greift direkt auf ihn zu. Auf diese Art von Cache können Sie schnell zugreifen. Sie kann auch ein wirksames Mittel zum Speichern bescheidener Mengen statischer Daten bieten. Die Größe eines Caches wird in der Regel durch die Arbeitsspeichermenge eingeschränkt, die auf dem Computer verfügbar ist, auf dem der Prozess gehostet wird.
Wenn im Cache mehr Informationen gespeichert werden müssen, als physisch im Arbeitsspeicher möglich, können Sie zwischengespeicherte Daten auf das lokale Dateisystem schreiben. Der Zugriff auf diese Daten ist langsamer als der Zugriff auf die Daten im Arbeitsspeicher, jedoch schneller und zuverlässiger als der Datenabruf aus einem Netzwerk.
Wenn dieses Modell bei Ihnen von mehreren Instanzen einer Anwendung gleichzeitig verwendet wird, verwendet jede dieser Anwendungsinstanzen einen eigenen unabhängigen Cache mit jeweils eigenen Daten.
Stellen Sie sich einen Cache als Momentaufnahme der Originaldaten zu einem bestimmten Zeitpunkt in der Vergangenheit vor. Wenn diese Daten nicht statisch sind, bewahren die verschiedenen Anwendungsinstanzen vermutlich jeweils verschiedene Versionen dieser Daten in ihren Caches auf. Daher kann die gleiche Abfrage in jeder dieser Instanzen unterschiedliche Ergebnisse zurückgeben (siehe Abbildung 1).
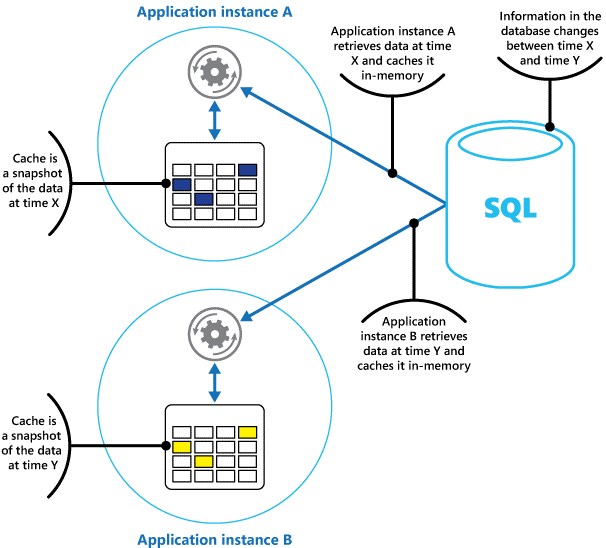
Abbildung 1: Verwenden eines In-Memory-Caches in verschiedenen Instanzen einer Anwendung
Shared Caching
Wenn Sie einen gemeinsam genutzten bzw. freigegebenen Cache verwenden, kann dies verhindern, dass die Daten in den einzelnen Caches voneinander abweichen, wie es beim In-Memory-Zwischenspeichern der Fall sein kann. Shared Caching stellt sicher, dass verschiedene Anwendungsinstanzen die gleiche Ansicht der zwischengespeicherten Daten haben. Hierzu wird der Cache an einem separaten Speicherort platziert, der in der Regel als Teil eines gesonderten Diensts gehostet wird, wie in Abbildung 2 dargestellt.
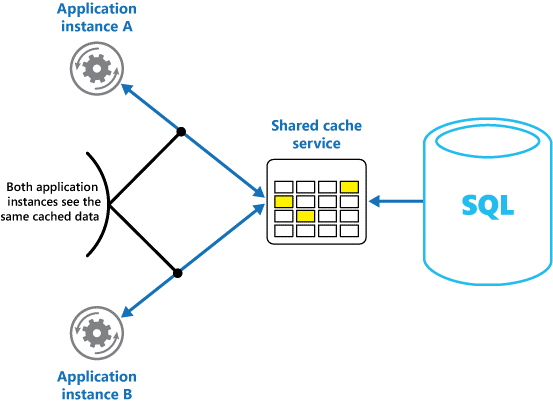
Abbildung 2: Verwenden eines freigegebenen Caches
Ein wichtiger Vorteil des Shared Cachings ist seine Skalierbarkeit. Viele Dienste, die freigegebenen Cache bereitstellen, werden durch einen Servercluster implementiert und verwenden Software, um die Daten innerhalb des Clusters transparent zu verteilen. Eine Instanz der Anwendung sendet einfach eine Anforderung an den Cachedienst. Die zu Grunde liegende Infrastruktur bestimmt den Speicherort für die zwischengespeicherten Daten im Cluster. Durch weitere Server lässt sich der Cache problemlos skalieren.
Die beiden größten Nachteile des Ansatzes mit Shared Caching sind:
- Der Zugriff auf den Cache ist langsamer, da er nicht mehr für jede Anwendungsinstanz lokal gespeichert wird.
- Die Anforderung, einen separaten Cachedienst zu implementieren, könnte die Lösung verkomplizieren.
Überlegungen zur Verwendung von Caching
Die folgenden Abschnitte gehen näher auf die einzelnen Überlegungen zum Entwurf und der Verwendung eines Cache ein.
Entscheiden, wann Daten zwischengespeichert werden sollen
Caching kann die Leistung, Skalierbarkeit und Verfügbarkeit erheblich verbessern. Je mehr Daten Sie besitzen, und je größer die Anzahl der Benutzer ist, die auf diese Daten zugreifen müssen, desto größer sind die Vorteile des Zwischenspeicherns. Zwischenspeichern verringert Wartezeiten und Konflikte, die mit der Handhabung großer Datenmengen, an die verschiedene Anforderungen gleichzeitig gestellt werden, im ursprünglichen Datenspeicher verbunden sind.
Eine Datenbank kann z. B. eine begrenzte Anzahl gleichzeitiger Verbindungen unterstützen. Werden die Daten in diesem Fall aber nicht aus der zu Grunde liegenden Datenbank, sondern aus einem freigegebenen Cache abgerufen, so kann die Clientanwendung selbst dann noch auf diese Daten zugreifen, wenn die Anzahl der verfügbaren Verbindungen erschöpft ist. Außerdem können die Clientanwendungen, sollte die Datenbank – aus welchem Grund auch immer – nicht mehr zur Verfügung stehen, nach wie vor auf die im Cache gespeicherten Daten zugreifen.
Zwischenspeichern empfiehlt sich besonders für Daten, die häufig eingelesen werden, aber nur selten geändert (bei denen z. B. der Anteil der Lesezugriffe gegenüber dem Anteil der Schreibzugriffe überwiegt). Allerdings sollten Sie den Cache nicht als autoritativen Speicher wichtiger Informationen verwenden. Stellen Sie stattdessen sicher, dass alle Änderungen, die Ihre Anwendung nicht verlieren darf, immer in einem persistenten Datenspeicher gespeichert werden. Sollte der Cache also einmal nicht verfügbar sein, kann Ihre Anwendung über den Datenspeicher weiterhin verwendet werden, ohne dass wichtige Informationen verloren gehen.
Bestimmen, wie Daten effektiv zwischengespeichert werden
Der Schlüssel für die effektive Verwendung eines Cache liegt darin, möglichst geeignete Daten für eine Zwischenspeicherung zu finden und diese zum richtigen Zeitpunkt zwischenzuspeichern. Die Daten können dem Cache bei Bedarf beim ersten Abruf durch eine Anwendung hinzugefügt werden. Die Anwendung muss die Daten nur einmal aus dem Datenspeicher abrufen, und der nachfolgende Zugriff kann über den Cache erfolgen.
Alternativ kann ein Cache im Voraus teilweise oder vollständig mit Daten gefüllt werden, in der Regel beim Start der Anwendung (diese Vorgehensweise wird als Seeding bezeichnet). Allerdings könnte Seeding bei einem großen Cache nicht ratsam sein, da diese Strategie beim Anwendungsstart eine plötzliche, hohe Last für den ursprünglichen Datenspeicher bedeutet.
Oft hilft eine Analyse der Verwendungsmuster bei der Entscheidung, ob eine vollständige oder teilweise Vorabfüllung des Caches sinnvoll ist, und welche Daten zwischengespeichert werden sollen. Beispielsweise können Sie den Cache per Seeding anfänglich mit den statischen Benutzerprofildaten derjenigen Benutzer füllen, die die Anwendung regelmäßig (z. B. täglich) verwenden, aber nicht für Benutzer, die die Anwendung nur einmal pro Woche verwenden.
Caching funktioniert in der Regel gut mit Daten, die sich nicht oder nur selten ändern. Beispiele hierfür sind Referenzinformationen wie Produkt- und Preisinformationen einer E-Commerce-Anwendung oder freigegebene statische Ressourcen, deren Erstellung sehr aufwändig ist. Einige oder alle dieser Daten können beim Anwendungsstart in den Cache geladen werden, um die Ressourcenbelastung zu minimieren und die Leistung zu steigern. Möglicherweise möchten Sie auch einen Hintergrundprozess einrichten, der die Referenzdaten im Cache regelmäßig aktualisiert, um sicherzustellen, dass es auf dem neuesten Stand ist. Oder der Hintergrundprozess kann den Cache aktualisieren, wenn sich die Referenzdaten ändern.
Für dynamische Daten ist Zwischenspeichern weniger geeignet, auch wenn es hier Ausnahmen gibt (siehe „Zwischenspeichern hochgradig dynamischer Daten“ weiter unten in diesem Artikel). Wenn sich die Originaldaten häufig ändern, sind die Daten im Cache entweder schnell überholt, oder der Aufwand der Synchronisierung des Caches mit dem Originaldatenspeicher steht in keinem Verhältnis zum Nutzen des Caches.
Ein Cache muss nicht alle Daten einer Entität vollständig enthalten. Stellt ein Datenelement beispielsweise ein Objekt mit mehreren Werten dar, zum Beispiel einen Bankkunden mit Name, Adresse und Kontostand, können einige dieser Elemente statisch bleiben, z. B. der Name und die Adresse. Andere Elemente, z. B. der Kontostand, können dynamischer sein. In einer solchen Situation kann es sinnvoll sein, den statischen Anteil der Daten zwischenzuspeichern und bei Bedarf nur die übrigen Informationen abzurufen (bzw. zu berechnen).
Sie sollten durch Leistungs- und Nutzungsanalysen ermitteln, ob ein Vorabfüllen des Caches, ein Laden der Daten bei Bedarf oder eine Kombination aus beidem sinnvoll ist. Bei der Entscheidung sollten sowohl die Flüchtigkeit als auch das Nutzungsmuster der Daten eine Rolle spielen. Nutzungs- und Leistungsanalysen für den Cache sind bei stark frequentierten und ausgelasteten Anwendungen wichtig, die hochgradig skalierbar sein müssen. Gerade in hochgradig skalierbaren Szenarien können Sie den Cache per Seeding vorab füllen, um die Belastung des Datenspeichers zu Spitzenzeiten zu verringern.
Durch Zwischenspeichern lassen sich auch wiederholte Berechnungen während der Laufzeit einer Anwendung vermeiden. Wenn durch eine Operation Daten umgewandelt oder komplizierte Berechnungen durchgeführt werden, können die Ergebnisse der Operation im Cache gespeichert werden. Falls die gleiche Berechnung später erneut erforderlich ist, kann die Anwendung das Ergebnis einfach aus dem Cache abrufen.
Eine Anwendung kann Daten ändern, die in einem Cache gespeichert sind. Sie sollten den Cache jedoch als flüchtigen Datenspeicher betrachten, der jederzeit entfernt werden könnte. Wichtige Daten sollten Sie daher nicht nur im Cache, sondern auch im ursprünglichen Datenspeicher speichern. Das bedeutet: Sollte die Verfügbarkeit des Caches einmal nicht gegeben sein, vermindern Sie auf diese Weise das Risiko eines Datenverlusts.
Zwischenspeichern hochgradig dynamischer Daten
Wenn Sie Informationen, die sich sehr schnell ändern, in einem persistenten Datenspeicher ablegen, kann dies das System enorm belasten. Denken Sie hier zum Beispiel an ein Gerät, das kontinuierlich einen Status oder ein anderes Messergebnis meldet. Wenn diese Daten in einer Anwendung nicht zwischengespeichert werden, weil die zwischengespeicherten Informationen nahezu sofort schon wieder veraltet sind, gilt diese Überlegung ebenso aber auch für das Speichern und Abrufen der Informationen im Datenspeicher. Die Daten haben sich zwischen dem Speichern und Abrufen eventuell bereits schon wieder geändert.
In einer Situation wie dieser sollten Sie überlegen, welche Vorteile das Speichern der dynamischen Informationen im Cache gegenüber dem Speichern im persistenten Datenspeicher hat. Wenn die Daten nicht so wichtig sind und nicht überprüft werden müssen, spielt der gelegentliche Verlust einer Änderung sicherlich keine Rolle.
Verwalten des Datenablaufs in einem Cache
In den meisten Fällen handelt es sich bei den Daten in einem Cache um eine Kopie der Daten im ursprünglichen Datenspeicher. Die Daten im ursprünglichen Datenspeicher können sich jedoch nach dem Zwischenspeichern ändern, wodurch die Daten im Cache veralten. Viele Cachesysteme bieten daher die Möglichkeit, für die Daten im Cache ein Ablaufdatum festzulegen, wodurch sich der Zeitraum reduziert, in dem Daten veraltet vorliegen.
Beim Ablauf zwischengespeicherter Daten werden die Daten aus dem Cache entfernt, und die Anwendung muss die Daten bei Bedarf wieder aus dem ursprünglichen Datenspeicher abrufen (die neu abgerufenen Informationen können dann wieder im Cache gespeichert werden). Zu diesem Zweck können Sie bei der Konfiguration des Cache eine Standardrichtlinie für den Kennwortablauf festlegen. Bei vielen Cachediensten können Sie auch das Ablaufdatum für einzelne Objekte festlegen, wenn Sie sie programmgesteuert im Cache speichern. Einige Caches ermöglichen Ihnen, das Ablaufdatum als absoluten Wert anzugeben, oder als gleitenden Wert, der bewirkt, dass das Element aus dem Cache entfernt wird, wenn nicht innerhalb der angegebenen Zeit darauf zugegriffen wird. Durch diese Einstellung wird jede Cache-weite Ablaufrichtlinie überschrieben, allerdings nur für die angegebenen Elemente.
Hinweis
Das Ablaufdatum für den Cache insgesamt sowie für einzelne Elemente muss sorgfältig bedacht werden. Wenn es zu kurz ist, veralten die Elemente zu schnell und werden entfernt, wodurch sich die Vorteile des Cache aufheben. Wenn es zu lang ist, kann es passieren, dass die im Cache vorliegenden Daten nicht mehr aktuell sind.
Wenn die Zeitspanne bis zum Ablauf der Daten sehr lange ist, kann der Cache auch überlaufen. In diesem Fall müssen bei jeder erneuten Anfrage zum Hinzufügen von Daten ältere Elemente meist zwangsweise aus dem Cache entfernt werden. In der Regel entfernen Cachedienste die Daten auf Basis der am längsten zurückliegenden Verwendung (Least Recently Used, LRU), aber meist können Sie diese Richtlinie überschreiben und dadurch verhindern, dass Elemente entfernt werden. Wenn Sie jedoch diesen Ansatz verfolgen, riskieren Sie eine Überschreitung des Arbeitsspeichers, der im Cache verfügbar ist. Eine Anwendung, die versucht, ein Element zum Cache hinzufügen, wird mit einer Ausnahme fehlschlagen.
Einige Cacheimplementierungen könnten auch zusätzliche Entfernungsrichtlinien bieten. Es gibt mehrere Typen von Entfernungsrichtlinien. Dazu gehören:
- Eine kürzlich verwendete Richtlinie (in der Annahme, dass die Daten nicht erneut benötigt werden).
- Eine Richtlinie für First In, First Out (älteste Daten werden zuerst entfernt).
- Eine explizite Entfernungsrichtlinie auf Basis eines ausgelösten Ereignisses (z. B. Änderung der Daten).
Ungültige Daten in einem clientseitigen Cache
Daten, die in einem clientseitigen Cache gespeichert sind, gelten im Allgemeinen als außerhalb des Einflussbereichs des Diensts liegend, der dem Client die Daten bereitstellt. Ein Dienst kann nicht direkt erzwingen, dass ein Client einem clientseitigen Cache Daten hinzufügt oder daraus entfernt.
Dies bedeutet, dass ein Client, der einen schlecht konfigurierten Cache verwendet, weiterhin veralteten Informationen verwenden kann. Wenn z. B. die Richtlinien für den Ablauf des Caches nicht ordnungsgemäß implementiert sind, könnte ein Client veraltete Informationen verwenden, die lokal zwischengespeichert sind, wenn die Informationen in der ursprünglichen Datenquelle geändert wurden.
Wenn Sie eine Webanwendung entwickeln, die Daten über eine HTTP-Verbindung bereitstellt, können Sie einen Webclient (z. B. einen Browser oder Webproxy) implizit zwingen, die neuesten Informationen abzurufen. Sie können dies tun, wenn eine Ressource durch eine Änderung der URI aktualisiert wird. Webclients verwenden die URI einer Ressource in der Regel als Schlüssel für den clientseitigen Cache, sodass die Änderung der URI bewirkt, dass der Webclient zuvor zwischengespeicherte Versionen einer Ressource ignoriert und stattdessen die neue Version abruft.
Verwalten der Parallelität in einem Cache
Caches sind häufig für mehrere Instanzen einer Anwendung freigegeben. Dabei kann jede Anwendungsinstanz die Daten im Cache lesen und ändern. Die Parallelitätsprobleme eines jeden freigegebenen Datenspeichers gelten daher auch für einen freigegebenen Cache. In Situationen, in denen Anwendungen die im Cache gespeicherten Daten ändern müssen, müssen Sie sicherstellen, dass die von einer Anwendungsinstanz vorgenommenen Änderungen die Änderungen einer anderen Instanz nicht überschreiben.
Je nach Art der Daten und der Wahrscheinlichkeit von Konflikten sollten Sie eine der beiden folgenden Parallelitätsstrategien verfolgen:
- Optimistisch (vollständig): Die Anwendung prüft unmittelbar vor der Aktualisierung, ob sich die Daten im Cache seit deren Abruf geändert haben. Haben sich die Daten nicht geändert, kann die Aktualisierung vorgenommen werden. Andernfalls muss die Anwendung entscheiden, ob die sie die Aktualisierung vornimmt. (Die Geschäftslogik, die dieser Entscheidung zu Grunde liegt, ist die anwendungsspezifische.) Diese Strategie eignet sich für Situationen, in denen nur selten Änderungen vorgenommen werden bzw. in denen kaum mit Konflikten zu rechnen ist.
- Pessimistisch (eingeschränkt): Beim Abrufen von Daten sperrt die Anwendung die Daten im Cache, um zu verhindern, dass diese durch eine andere Anwendungsinstanz geändert werden. So werden Konflikte umgangen, allerdings werden andere Anwendungsinstanzen, die die gleichen Daten verarbeiten müssen, dabei unter Umständen blockiert. Die pessimistische Parallelität kann die Skalierbarkeit der Lösung beeinträchtigen und sollte nur für kurzlebige Prozesse verwendet werden. Diese Strategie ist eher geeignet für Situationen, in denen Konflikte wahrscheinlich sind, insbesondere dann, wenn eine Anwendung mehrere Elemente im Cache aktualisiert und sicherstellen muss, dass diese Änderungen konsistent angewendet werden.
Implementieren von Hochverfügbarkeit und Skalierbarkeit mit Verbesserung der Leistung
Verwenden Sie einen Cache nicht als primäres Datenrepository. Dies sollte der ursprüngliche Datenspeicher bleiben, aus dem der Cache gefüllt wird. Der ursprüngliche Datenspeicher ist für die Persistenz der Daten verantwortlich.
Achten Sie darauf, Ihre Lösungen nicht abhängig von der Verfügbarkeit eines gemeinsam genutzten Cachediensts zu machen. Eine Anwendung sollte funktionsfähig bleiben, wenn der Dienst, der den freigegebenen Cache bereitstellt, nicht verfügbar ist. Die Anwendung sollte beim Warten auf die Fortsetzung des Cachediensts auf keinen Fall nicht mehr reagieren, und es sollte auch kein Fehler auftreten.
Die Anwendung muss also in der Lage sein, die Verfügbarkeit des Cachediensts zu erkennen, und bei Bedarf auf den ursprünglichen Datenspeicher zurückgreifen können, wenn der Cache nicht verfügbar ist. Diesem Szenario kommt besonders das Circuit-Breaker-Muster entgegen. Der Dienst, der den Cache bereitstellt, kann wiederhergestellt werden, und sobald er verfügbar ist, kann der Cache wieder nach einer Strategie wie dem cachefremden Muster aus dem ursprünglichen Datenspeicher gefüllt werden.
Allerdings wird möglicherweise die Skalierbarkeit des Systems beeinträchtigt, wenn die Anwendung auf den ursprünglichen Datenspeicher zurückgreift, falls der Cache vorübergehend nicht verfügbar ist. Während der Wiederherstellung des Datenspeichers könnte der ursprüngliche Datenspeicher mit Datenanforderungen überschwemmt werden, sodass Zeitüberschreitungen und fehlgeschlagene Verbindungen die Folge wären.
Erwägen Sie, zusätzlich zum freigegebenen Cache, auf den alle Anwendungsinstanzen zugreifen, einen lokalen privaten Cache in jeder Anwendungsinstanz zu implementieren. Beim Abrufen eines Elements kann die Anwendung zunächst in ihrem lokalen Cache, dann im freigegebenen Cache und schließlich im ursprünglichen Datenspeicher nachsehen. Der lokale Cache kann mit den Daten des freigegebenen Caches bzw., sollte dieser nicht verfügbar sein, mit den Daten aus der ursprünglichen Datenbank gefüllt werden.
Bei dieser Strategie ist eine sorgfältige Konfiguration erforderlich, um zu verhindern, dass der lokale Cache gegenüber dem freigegebenen Cache zu sehr veraltet. Der lokale Cache fungiert jedoch als Puffer, wenn der freigegebene Cache nicht erreichbar ist. Eine solche Struktur sehen Sie in Abbildung 3.
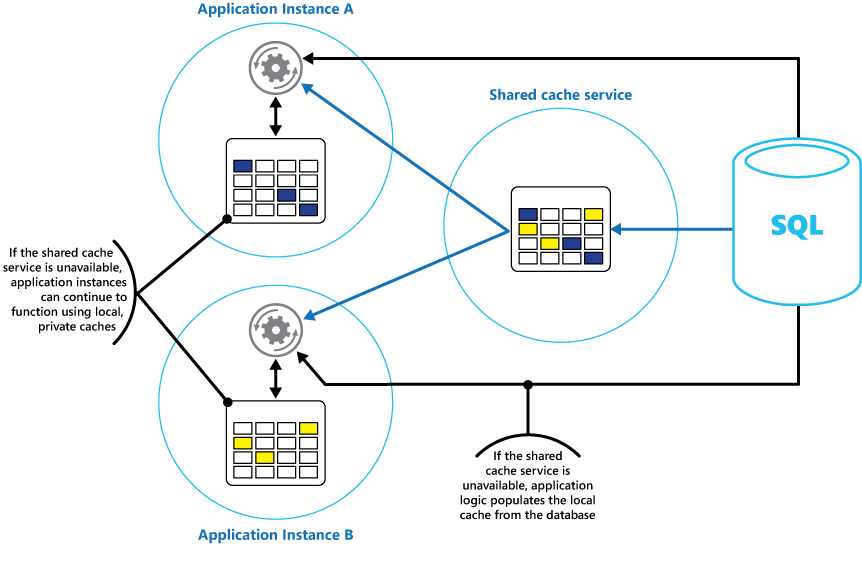
Abbildung 3: Verwenden eines lokalen privaten Caches mit einem freigegebenen Cache
Zur Unterstützung großer Caches, die relativ langlebige Daten enthalten, bieten einige Cachedienste eine Option für hohe Verfügbarkeit, die für den Fall, dass der Cache nicht verfügbar ist, automatisches Failover implementiert. Diese Strategie schließt in der Regel die Replikation der auf einem primären Cacheserver zwischengespeicherten Daten auf einem sekundären Cacheserver ein, sodass bei einem Ausfall des primären Cacheservers bzw. einem Verlust der Konnektivität sofort zum sekundären Server gewechselt werden kann.
Zur Verkürzung der Latenzzeit, die das Schreiben an mehrere Ziele mit sich bringt, kann die Replikation der Daten auf den sekundären Server auch asynchron zum Zwischenspeichern der Daten auf dem primären Server erfolgen. Diese Strategie birgt zwar das Risiko, dass einige der zwischengespeicherten Informationen bei einem Fehler während dieses Prozesses verloren gehen, der Verlustanteil sollte jedoch gegenüber der Gesamtgröße des Caches vernachlässigbar sein.
Zur Verhinderung von Überlastung und Verbesserung der Skalierbarkeit kann es bei einem sehr großen freigegebenen Cache von Vorteil sein, die zwischengespeicherten Daten in Partitionen auf mehrere Knoten aufzuteilen. Viele freigegebene Caches unterstützen die Möglichkeit des dynamischen Hinzufügens (und Entfernens) von Knoten und die Neuverteilung der Daten auf diese Partitionen. Diese Strategie könnte z. B. das Clustering einbeziehen, wobei die Sammlung der Knoten den Clientanwendungen als nahtloser, einzelner Cache dargestellt wird. Intern werden die Daten jedoch nach einer vordefinierten Verteilungsstrategie, die die Last gleichmäßig verteilt, auf die Knoten verteilt. Weitere Informationen zur möglichen Partitionierungsstrategien finden Sie im Leitfaden zur Datenpartitionierung.
Clustering kann die Verfügbarkeit des Cache auch erhöhen. Wenn ein Knoten ausfällt, ist der Rest des Caches weiterhin verfügbar. Clustering wird häufig in Verbindung mit Replikation und Failover verwendet. Jeder Knoten kann repliziert werden, und das Replikat kann schnell online geschaltet werden, wenn der Knoten ausfällt.
Vermutlich beinhalten viele Lese- und Schreibvorgänge nur einzelne Werte oder Elemente. Mitunter wird es aber auch erforderlich sein, große Datenmengen schnell zu speichern oder abzurufen. Beispielsweise könnte das Seeding eines Caches mit sich bringen, Hunderte oder Tausende von Elementen in den Cache zu schreiben. Eine Anwendung muss möglicherweise eine große Anzahl verwandter Elemente als Teil einer Anforderung aus dem Cache abrufen.
Viele große Caches bieten für diese Zwecke die Möglichkeit eines Batchvorgangs. So kann eine Clientanwendung eine große Menge an Elementen in eine einzige Anforderung packen und so den durch unzählige kleine Anforderungen verursachten Mehraufwand verringern.
Caching und letztendliche Konsistenz
Das cachefremde Muster ist davon abhängig, dass die Anwendungsinstanz, die den Cache füllt, Zugriff auf die aktuellste und konsistenteste Version der Daten hat. In einem System, das letztendlich Konsistenz bereitstellt (z. B. ein replizierter Datenspeicher), ist dies unter Umständen nicht der Fall.
Es kann durchaus passieren, dass eine Anwendungsinstanz ein Datenelement ändert und damit die Version dieses Elements im Cache schon wieder ungültig macht. Eine andere Instanz der Anwendung versucht nun möglicherweise, dieses Element aus dem Cache einzulesen. Dabei kommt es zu einem Cachefehler, sodass die Instanz die Daten aus dem Datenspeicher einliest und dem Cache hinzufügt. Wurde der Datenspeicher allerdings nicht vollständig mit den anderen Replikaten synchronisiert, kann es passieren, dass die Anwendungsinstanz einen alten Wert einliest und diesen veralteten Wert im Cache speichert.
Weitere Informationen zur Aufrechterhaltung der Datenkonsistenz finden Sie unter Data consistency primer (Grundlagen der Datenkonsistenz).
Schützen der Daten im Cache
Unabhängig vom verwendeten Cachedienst sollten Sie überlegen, wie Sie die Daten im Cache vor nicht autorisiertem Zugriff schützen. Dabei müssen zwei Aspekte vorrangig bedacht werden:
- Der Schutz der Daten im Cache.
- Der Schutz der Daten während der Übertragung zwischen dem Cache und der Anwendung, die den Cache verwendet.
Zum Schutz von Daten im Cache kann der Cachedienst einen Authentifizierungsmechanismus implementieren, der erfordert, dass die Anwendungen Folgendes angeben:
- Welche Identitäten auf die Daten im Cache zugreifen können.
- Welche Vorgänge (Lese- und Schreibzugriff) diese Identitäten ausführen dürfen.
Zur Reduzierung des damit einhergehenden Mehraufwands beim Lesen und Schreiben der Daten kann eine Identität, nachdem sie Lese- oder Schreibzugriff auf den Cache erhalten hat, auf alle Daten im Cache zugreifen.
Wenn Sie den Zugriff auf Teilmengen der Daten im Cache einschränken müssen, nutzen Sie eine der folgenden Methoden:
- Teilen Sie den Cache in Partitionen auf (mithilfe mehrerer Cacheserver), und gewähren Sie den Identitäten nur Zugriff auf die Partitionen, die sie verwenden dürfen.
- Verschlüsseln Sie die Daten jeder Teilmenge mit verschiedenen Schlüsseln, und stellen Sie die Verschlüsselungsschlüssel nur den Identitäten bereit, die Zugriff auf die jeweilige Teilmenge haben dürfen. Bei der Verschlüsselungsmethode kann eine Clientanwendung nach wie vor auf alle Daten im Cache zugreifen, jedoch nur die Daten entschlüsseln, für die sie den Schlüssel hat.
Sie müssen die Daten auch während der Übertragung in den und aus dem Cache schützen. Hierbei sind Sie von den Sicherheitsfeatures der Netzwerkinfrastruktur abhängig, über die sich die Clientanwendungen mit dem Cache verbinden. Wenn der Cache über einen lokalen Server innerhalb der gleichen Organisation bereitgestellt wird, der auch die Clientanwendungen hostet, sind dank der Isolation des Netzwerks wahrscheinlich keine weiteren Schritte erforderlich. Wenn der Cache hingegen remote bereitgestellt wird und eine TCP- oder HTTP-Verbindung über ein öffentliches Netzwerk (z. B. das Internet) erfordert, erwägen Sie die Implementierung von SSL.
Überlegungen zur Implementierung von Caching in Azure
Azure Cache for Redis ist eine Implementierung des quelloffenen Redis-Cache, der als Dienst in einem Azure-Rechenzentrum ausgeführt wird. Er bietet einen Cachedienst, auf den jede Azure-Anwendung zugreifen kann, und zwar unabhängig davon, ob die Anwendung als Clouddienst, als Website oder auf einem virtuellen Azure-Computer implementiert ist. Caches können von Clientanwendungen, die über den entsprechenden Zugriffsschlüssel verfügen, gemeinsam verwendet werden.
Azure Cache for Redis ist eine Hochleistungs-Cachinglösung, die Verfügbarkeit, Skalierbarkeit und Sicherheit bietet. Die Lösung wird in der Regel als Dienst auf einem dedizierten Computer oder verteilt auf mehrere dedizierte Computer ausgeführt. Es wird versucht, so viele Informationen wie möglich im Arbeitsspeicher zu speichern, um schnellen Zugriff sicherzustellen. Diese Architektur ist für geringe Latenzzeiten und hohen Durchsatz konzipiert, indem langsame E/A-Vorgänge möglichst vermieden werden.
Azure Cache for Redis ist mit zahlreichen APIs kompatibel, die von Clientanwendungen verwendet werden. Wenn Sie bereits über Anwendungen verfügen, die Azure Cache for Redis lokal verwenden, stellt Azure Cache for Redis einen schnellen Migrationspfad für die Umstellung auf die Zwischenspeicherung in der Cloud bereit.
Features von Redis
Redis ist mehr als ein einfacher Cacheserver. Die Lösung bietet eine verteilte In-Memory-Datenbank mit einem umfassenden Befehlssatz, der zahlreiche gängige Szenarien unterstützt. Diese werden weiter unten in diesem Dokument im Abschnitt „Verwenden des Redis-Zwischenspeicherns“ beschrieben. In diesem Abschnitt werden einige der wichtigsten Features von Redis vorgestellt.
Redis als arbeitsspeicherinterne Datenbank
Redis unterstützt sowohl Lese- als auch Schreibvorgänge. In Redis können Schreibvorgänge bei Systemausfällen geschützt werden, indem sie regelmäßig in einer lokalen Momentaufnahmen- oder einer Append-only-Protokolldatei gespeichert werden. Diese Situation tritt bei vielen anderen Caches (die als vorübergehende Datenspeicher betrachtet werden sollten) gar nicht ein.
Alle Schreibvorgänge erfolgen asynchron und hindern keine Clients am Lesen und Schreiben von Daten. Beim Start von Redis liest es die Daten aus der Snapshot- oder Protokolldatei ein und erstellt daraus den arbeitsspeicherinternen Cache. Weitere Informationen finden Sie auf der Redis-Website unter Redis persistence (Redis-Persistenz).
Hinweis
Im Falle eines schwerwiegenden Fehlers garantiert Redis nicht, dass alle Schreibvorgänge gespeichert werden, im schlimmsten Fall verlieren Sie aber nur die aktualisierten Daten weniger Sekunden. Denken Sie jedoch daran, dass ein Cache keineswegs als autoritative Datenquelle eingesetzt werden sollte und es den Anwendungen, die den Cache verwenden, obliegt, sicherzustellen, dass wichtige Daten erfolgreich in einem persistenten Datenspeicher abgelegt werden. Weitere Informationen finden Sie unter Cachefremdes Muster.
Von Redis unterstützte Datentypen
Redis ist ein Schlüssel-/Wertspeicher, dessen Werte einfache Typen oder komplexe Datenstrukturen wie Hashes, Listen und Sätze sein können. Redis unterstützt für diese Datentypen einen Satz atomarer Operationen. Schlüssel können permanent oder zeitlich begrenzt sein. In letzterem Fall werden die Schlüssel mit ihren Werten zum entsprechenden Zeitpunkt automatisch aus dem Cache entfernt. Weitere Informationen zu den Schlüsseln und Werten in Redis finden Sie auf der Redis-Website auf der Seite An Introduction to Redis data types and abstractions (Eine Einführung zu Redis-Datentypen und Abstraktionen).
Replikation und Clustering mit Redis
Redis unterstützt die Replikation zwischen Primär- und Sekundärgeräten, um Verfügbarkeit und Durchsatz sicherzustellen. Schreibvorgänge auf einen Redis-Primärknoten werden auf einem oder mehreren untergeordneten Knoten repliziert. Lesevorgänge können vom Primärknoten oder einem beliebigen der untergeordneten Elemente bereitgestellt werden.
Wenn Sie eine Netzwerkpartition haben, können untergeordnete Knoten weiterhin Daten bereitstellen und sich später transparent mit dem Primärknoten synchronisieren, sobald die Verbindung wiederhergestellt ist. Weitere Informationen finden Sie auf der Seite Replication (in englischer Sprache) auf der Redis-Website.
Darüber hinaus bietet Redis Clustering-Features, mit denen Sie Daten auf Servern transparent in Shards partitionieren können, um so die Last zu verteilen. Dieses Feature verbessert die Skalierbarkeit, da neue Redis-Server hinzugefügt und die Daten neu partitioniert werden können, während der Cache anwächst.
Darüber hinaus kann jeder Server im Cluster mithilfe der Replikation zwischen Primär- und Sekundärgeräten repliziert werden. Dies gewährleistet die Verfügbarkeit der Daten auf jedem Knoten im Cluster. Weitere Informationen zu Clustering und Sharding finden Sie auf der Redis-Website auf der Seite Redis cluster tutorial (Redis-Clustertutorial).
Arbeitsspeichernutzung in Redis
Die Größe eines Redis-Caches ist durch die auf dem Hostcomputer verfügbaren Ressourcen begrenzt. Bei der Konfiguration eines Redis-Servers können Sie seine maximale Arbeitsspeichergröße angeben. Sie können einen Schlüssel in einem Redis-Cache auch mit einer Ablaufzeit konfigurieren, nach deren Verstreichen der Schlüssel automatisch aus dem Cache entfernt wird. Dieses Feature kann einen Überlauf des In-Memory-Cache durch veraltete Daten weitgehend verhindern.
Während sich der Arbeitsspeicher füllt, kann Redis automatisch – unter Berücksichtigung einer Reihe von Richtlinien – Schlüssel und deren Werte daraus entfernen. Die Standardrichtlinie ist LRU (Least Recently Used, d. h. am längsten zurückliegende Verwendung), aber Sie können auch andere Richtlinien auswählen, zum Beispiel die Entfernung von Schlüsseln nach dem Zufallsprinzip oder gar keine Entfernung von Schlüsseln (in diesem Fall schlägt jeder Versuch fehl, einem bereits vollen Cache weitere Elemente hinzuzufügen). Weitere Informationen finden Sie auf der Seite Using Redis as an LRU Cache (Verwenden von Redis als LRU-Cache).
Transaktionen und Batches in Redis
Redis ermöglicht einer Clientanwendung die Übermittlung einer Reihe von Vorgängen, die Daten im Cache als atomare Transaktion lesen und schreiben. Alle Befehle einer solchen Transaktion werden garantiert sequenziell ausgeführt und kein Befehl eines anderen parallel ausgeführten Clients wird in diese Sequenz eingefügt.
Es handelt sich hier jedoch nicht um echte Transaktionen im Sinne einer relationalen Datenbanktransaktion. Die Verarbeitung von Transaktionen besteht aus zwei Phasen – in der ersten werden die Befehle in die Warteschlange gestellt, in der zweiten werden die Befehle ausgeführt. Während der Einreihungsphase werden die Befehle der Transaktion vom Client an die Warteschlange übertragen. Falls während dieses Vorgangs ein Fehler auftritt (z. B. ein Syntaxfehler oder eine falsche Anzahl von Parametern), verweigert Redis die Verarbeitung der gesamten Transaktion und verwirft sie.
Während der Ausführungsphase führt Redis die in die Warteschlange eingereihten Befehle in der richtigen Reihenfolge aus. Wenn ein Befehl während dieser Phase fehlschlägt, fährt Redis schlicht mit dem nächsten Befehl in der Warteschlange fort. Ein Rollback der bereits ausgeführten Befehle findet nicht statt. Diese vereinfachte Transaktionsform trägt zur Aufrechterhaltung der Leistung bei und verhindert Leistungsprobleme durch Überlastung.
Redis implementiert keine Form der optimistischen Sperre zur Aufrechterhaltung der Konsistenz. Detaillierte Informationen zu Transaktionen und Sperren in Redis finden Sie auf der Seite Transactions (in englischer Sprache) auf der Redis-Website.
Darüber hinaus unterstützt Redis auch die nicht-transaktionale Batchverarbeitung von Anforderungen. Das Redis-Protokoll, mit dem Clients Befehle an einen Redis-Server senden, ermöglicht dem Client auch die Übertragung mehrerer Vorgänge innerhalb einer Anforderung. Dadurch reduziert sich die Paketfragmentierung im Netzwerk. Die einzelnen Befehle werden bei der Verarbeitung des Batch ausgeführt. Ein falsch formulierter Befehl wird bei dieser Art der Verarbeitung zwar abgelehnt (was bei einer Transaktion nicht vorkommt), die restlichen Befehle werden aber ausgeführt. Außerdem gibt es keine Garantie dafür, in welcher Reihenfolge die Befehle des Batchs verarbeitet werden.
Sicherheit in Redis
Bei Redis geht es ausschließlich um den schnellen Datenzugriff. Es stützt sich dabei auf die Ausführung in einer vertrauenswürdigen Umgebung und verlässt sich darauf, dass nur vertrauenswürdige Clients darauf zugreifen. Redis unterstützt ein begrenztes Sicherheitsmodell auf Grundlage der Kennwortauthentifizierung. (Es ist möglich, die Authentifizierung vollständig zu entfernen, obwohl wir dies nicht empfehlen.)
Alle authentifizierten Clients verwenden das gleiche globale Kennwort und haben Zugriff auf die gleichen Ressourcen. Wenn Sie bei der Anmeldung mehr Sicherheit benötigen, müssen Sie vor dem Redis-Server einen eigenen Sicherheitslayer implementieren, den alle Clientanforderungen passieren müssen. Redis sollte mit nicht vertrauenswürdigen bzw. nicht authentifizierten Clients nicht in direkten Kontakt kommen.
Sie können den Zugriff auf Befehle einschränken, indem Sie sie deaktivieren oder umbenennen (und die neuen Namen nur privilegierten Clients bereitstellen).
Redis unterstützt keine Form der Datenverschlüsselung direkt, d. h., eine Verschlüsselung muss immer auf Clientseite erfolgen. Darüber hinaus bietet Redis keinerlei Transportsicherheit. Zum Schutz von Daten bei der Übertragung über das Netzwerk sollten Sie einen SSL-Proxy implementieren.
Weitere Informationen finden Sie auf der Redis-Website auf der Seite Redis Security (Sicherheit in Redis).
Hinweis
Azure Cache for Redis bietet eine eigene Sicherheitsebene, über die Clients eine Verbindung herstellen. Die zu Grunde liegenden Redis-Server stehen dem öffentlichen Netzwerk nicht zur Verfügung.
Azure Redis Cache
Azure Cache for Redis bietet Zugriff auf Redis-Server, die in einem Azure-Rechenzentrum gehostet werden. Die Lösung fungiert als Fassade, die für Zugriffssteuerung und Sicherheit zuständig ist. Einen Cache können Sie mithilfe des Azure-Portals bereitstellen.
Das Portal bietet eine Anzahl vordefinierter Konfigurationen. Diese Konfiguration reichen von einem Cache mit 53 GB, der als dedizierter Dienst ausgeführt wird, SSL-Kommunikation unterstützt (zur Gewährleistung des Datenschutzes) und eine Replikation zwischen Primär- und Sekundärgeräten mit einer SLA von 99,9 % bereitstellt, bis zu einem Cache mit lediglich 250 MB ohne Replikation (ohne Verfügbarkeitsgarantien), der auf gemeinsam genutzter Hardware ausgeführt wird.
Auch die Entfernungsrichtlinie für den Cache können Sie über das Azure-Portal konfigurieren, ebenso, wie Sie dort durch Hinzufügen von Benutzern zu den bereitgestellten Rollen den Zugriff auf den Cache steuern können. Zu diesen Rollen, die die Vorgänge definieren, die Mitglieder ausführen können, gehören Owner, Contributor und Reader. So haben Mitglieder der Rolle „Owner“ (Eigentümer) vollständige Kontrolle über den Cache und seinen Inhalt (einschließlich dessen Sicherheit), Mitglieder der Rolle „Contributor“ (Mitwirkender) können Informationen im Cache lesen und schreiben und Mitglieder der Rolle „Reader“ (Leser) können die Daten aus dem Cache nur abrufen.
Die meisten Verwaltungsaufgaben werden über das Azure-Portal ausgeführt . Darum sind viele Verwaltungsbefehle aus der Standardversion von Redis, wie die Möglichkeit der programmgesteuerten Änderung der Konfiguration, das Herunterfahren des Redis-Servers, die Konfiguration weiterer Slaves oder das zwangsweise Speichern von Daten auf der Festplatte nicht verfügbar.
Das Azure-Portal bietet eine praktische grafische Übersicht, mit der sich die Leistung des Caches gut überwachen lässt. Beispielsweise können Sie die Anzahl der aktiven Verbindungen, die Anzahl der ausgeführten Anforderungen, die Menge der Lese- und Schreibzugriffe und die Anzahl der Cachetreffer gegenüber den fehlgeschlagenen Zugriffen auf den Cache anzeigen. Diesen Informationen können Sie die Effektivität des Caches entnehmen und daraufhin gegebenenfalls die Konfiguration oder die Entfernungsrichtlinie ändern.
Sie können auch Warnungen erstellen, über die Administratoren E-Mail-Benachrichtigungen erhalten, wenn eine oder mehrere wichtige Metriken außerhalb des erwarteten Bereichs fallen. Sie könnten z. B. festlegen, dass ein Administrator benachrichtigt wird, wenn die Anzahl der fehlgeschlagenen Zugriffe auf den Cache innerhalb der letzten Stunde einen angegebenen Wert überschritten hat, da es in diesem Fall nahe liegt, dass der Cache zu klein ist oder die zwischengespeicherten Daten zu früh entfernt werden.
Sie können auch die CPU-, Arbeitsspeicher- und Netzwerkauslastung des Caches überwachen.
Weitere Informationen und Beispiele zum Erstellen und Konfigurieren einer Azure Cache for Redis-Instanz finden Sie auf der Seite Lap around Azure Redis Cache (Einblicke in Azure Cache for Redis) im Azure-Blog.
Caching von Sitzungsstatus und HTML-Ausgabe
Wenn Sie ASP.NET-Webanwendungen erstellen, deren Berechtigungen durch Azure-Webrollen gesteuert werden, können Sie die Statusinformationen von Sitzungen und HTML-Ausgaben in einer Azure Cache for Redis-Instanz speichern. Der Sitzungsstatusanbieter für Azure Cache for Redis ermöglicht die Freigabe der Informationen zwischen verschiedenen Instanzen einer ASP.NET-Webanwendung und ist somit sehr nützlich in Webfarmumgebungen, in denen keine Client-/Serveraffinität besteht und ein Caching der Sitzungsdaten im Arbeitsspeicher inadäquat ist.
Die Verwendung des Sitzungszustandsanbieters mit Azure Cache for Redis bietet verschiedene Vorteile:
- Freigeben des Sitzungsstatus für eine große Anzahl von Instanzen von ASP.NET-Webanwendungen.
- Bereitstellen verbesserter Skalierbarkeit.
- Ein kontrollierter gleichzeitiger Zugriff auf die gleichen Sitzungsstatusdaten für mehrere Reader und einen einzigen Writer wird unterstützt.
- Zur Einsparung von Arbeitsspeicher und Verbesserung der Netzwerkleistung wird Komprimierung verwendet.
Weitere Informationen finden Sie unter ASP.NET-Sitzungszustandsanbieter für Azure Cache for Redis.
Hinweis
Für ASP.NET-Anwendungen, die außerhalb der Azure-Umgebung ausgeführt werden, sollte der Sitzungszustandsanbieter für Azure Cache for Redis nicht verwendet werden. Die Latenzzeiten für den Zugriff auf den Cache außerhalb von Azure können die Leistungsvorteile des Caching zunichte machen.
Auf ähnliche Weise ermöglicht Ihnen der Ausgabecacheanbieter für Azure Cache for Redis das Speichern der von einer ASP.NET-Webanwendung generierten HTTP-Antworten. Die Verwendung von Azure Cache for Redis mit dem Ausgabecacheanbieter kann die Reaktionszeiten von Anwendungen verbessern, die komplexe HTML-Ausgaben rendern. Anwendungsinstanzen, die ähnliche Antworten generieren, können die freigegebenen Ausgabefragmente im Cache nutzen, anstatt die HTML-Ausgabe völlig neu generieren zu müssen. Weitere Informationen finden Sie unter ASP.NET-Ausgabecacheanbieter für Azure Cache for Redis.
Erstellen eines benutzerdefinierten Redis-Cache
Azure Cache for Redis fungiert als Fassade für die zugrunde liegenden Redis-Server. Wenn Sie eine erweiterte Konfiguration benötigen, die nicht vom Azure Redis-Cache bereitgestellt wird (z. B. einen Cache mit mehr als 53 GB), können Sie mit virtuellen Azure-Computern eigene Redis-Server erstellen und bereitstellen.
Das hierzu erforderliche Verfahren ist unter Umständen recht komplex, da Sie eventuell mehrere virtuelle Computer als Primärknoten und untergeordnete Knoten erstellen müssen, wenn Sie auch Replikation implementieren möchten. Außerdem benötigen Sie mehrere primäre und untergeordnete Server, wenn Sie einen Cluster erstellen möchten. Für die Mindestversion einer Clustertopologie mit Replikation, die ein hohes Maß an Verfügbarkeit und Skalierbarkeit bietet, sind mindestens sechs virtuelle Computer erforderlich, die in drei Paare mit jeweils einem primären und einem untergeordneten Server organisiert sind (ein Cluster muss mindestens drei Primärknoten enthalten).
Der jeweilige primäre und untergeordnete Server eines Paars sollten sich nahe beieinander befinden, um die Wartezeit zu minimieren. Die einzelnen Paare können aber in separaten Azure-Rechenzentren in verschiedenen Regionen bereitgestellt werden, wenn sich die zwischengespeicherten Daten möglichst nahe der Anwendungen befinden sollen, die sie am wahrscheinlichsten nutzen. Ein Beispiel für die Erstellung und Konfiguration eines Redis-Knotens, der als Azure-VM ausgeführt wird, finden Sie unter Running Redis on a CentOS Linux VM in Azure (Ausführen von Redis auf einer CentOS Linux-VM in Azure).
Hinweis
Wenn Sie auf diese Weise Ihren eigenen Redis-Cache implementieren, sind Sie selbst für die Überwachung, die Verwaltung und den Schutz des Diensts verantwortlich.
Partitionierung eines Redis-Cache
Einen Cache zu partitionieren bedeutet, ihn auf mehrere Computer aufzuteilen. Diese Struktur hat gegenüber einem einzigen Cacheserver verschiedene Vorteile:
- Der Cache kann weit über die Kapazität eines einzelnen Servers hinausgehen.
- Die Daten werden zugunsten einer höheren Verfügbarkeit auf mehrere Server verteilt. Wenn ein Server ausfällt oder nicht zugänglich ist, stehen nur dessen Daten nicht mehr zur Verfügung. Auf die Daten der verbleibenden Server kann weiterhin zugegriffen werden. Für einen Cache ist dies nicht wichtig, da die zwischengespeicherten Daten nur eine vorübergehende Kopie der in einer Datenbank gespeicherten Daten sind. Zwischengespeicherte Daten auf einem Server, der nicht mehr verfügbar ist, können stattdessen auf einem anderen Server zwischengespeichert werden.
- Die Last wird auf die Server verteilt, wodurch sich Leistung und Skalierbarkeit verbessern.
- Das lokalere Speichern der Daten in der Nähe der Benutzer (Geolocating), die darauf zugreifen, verringert die Latenz.
Für einen Cache ist die häufigste Form der Partitionierung das Sharding. Bei dieser Strategie ist jede Partition (bzw. jeder Shard) ein separater Redis-Cache. Die Daten werden mittels der Sharding-Logik, die verschiedene Strategien einsetzen kann, auf bestimmte Partitionen verteilt. Nähere Informationen zur Implementierung von Sharding finden Sie unter Sharding Pattern (Sharding-Muster).
Für die Implementierung der Partitionierung in einem Redis-Cache können Sie eine der folgenden beiden Strategien anwenden:
- Serverseitige Abfrageweiterleitung: Bei diesem Verfahren sendet eine Clientanwendung eine Anforderung an einen der Redis-Server im Cache (in der Regel an den geografisch nächstliegenden Server). Jeder Redis-Server speichert Metadaten, die die Partition auf diesem Server beschreiben. Zudem enthält er aber auch Informationen zu den Partitionen auf den anderen Servern. Der Redis-Server überprüft die Clientanforderung. Wenn die Anforderung lokal aufgelöst werden kann, führt der Redis-Server den angeforderten Vorgang aus. Andernfalls leitet er die Anforderung an den geeigneten Server weiter. Dieses Modell wird durch das Clustering-Feature von Redis implementiert und auf der Seite Redis Cluster Tutorial (Redis-Cluster-Tutorial) auf der Redis-Website ausführlich beschrieben. Redis-Clustering ist für Clientanwendungen transparent und dem Cluster können zusätzliche Redis-Server hinzugefügt (und die Daten neu partitioniert) werden, ohne die Clients neu zu konfigurieren.
- Clientseitige Partitionierung: In diesem Modell enthält die Client-Anwendung Logik (möglicherweise in Form einer Bibliothek), die Anforderungen an einen geeigneten Redis-Server weiterleitet. Diese Strategie kann mit Azure Cache for Redis angewandt werden. Erstellen Sie mehrere Azure Cache for Redis-Instanzen (eine für jede Datenpartition), und implementieren Sie die clientbasierte Logik, die die Anforderungen an den richtigen Cache weiterleitet. Wenn sich das Partitionierungsschema ändert (z. B. weil weitere Azure Cache for Redis-Instanzen hinzugefügt werden), müssen die Clientanwendungen unter Umständen neu konfiguriert werden.
- Proxy-unterstützte Partitionierung: Bei diesem Schema senden Clientanwendungen Anforderungen an einen zwischengeschalteten Proxydienst, der weiß, wie die Daten partitioniert sind, und die Anforderung an einen geeigneten Redis-Server weiterleitet. Auch diese Strategie kann mit Azure Cache for Redis angewandt werden. Der Proxydienst kann z. B. als Azure-Clouddienst implementiert werden. Diese Strategie setzt eine zusätzliche Ebene der Komplexität für die Implementierung des Diensts voraus, weshalb die Ausführung der Anforderungen im Vergleich zur clientseitigen Partitionierung länger dauern kann.
Die Seite Partitionierung: das Teilen von Daten zwischen mehreren Redis-Instanzen auf die Redis-Website enthält weitere Informationen zur Implementierung der Partitionierung mit Redis.
Implementieren von Clientanwendungen für den Redis-Cache
Redis unterstützt in den verschiedensten Programmiersprachen geschriebene Clientanwendungen. Wenn Sie neue Anwendungen mit .NET Framework erstellen, empfehlen wir jedoch die Verwendung der Clientbibliothek „StackExchange.Redis“. Diese Bibliothek bietet ein .NET Framework-Objektmodell, das die Details des Verbindungsaufbaus mit einem Redis-Server sowie des Sendens von Befehlen und Empfangens von Antworten abstrahiert. Sie ist als NuGet-Paket in Visual Studio verfügbar. Mit der gleichen Bibliothek können Sie eine Verbindung mit einer Azure Cache for Redis-Instanz oder einem benutzerdefinierten Redis-Cache auf einem virtuellen Computer herstellen.
Zum Herstellen der Verbindung mit einem Redis-Server verwenden Sie die statische Methode Connect der ConnectionMultiplexer-Klasse. Die mit dieser Methode erstellte Verbindung kann für die gesamte Lebensdauer der Clientanwendung verwendet werden – auch von mehreren Threads gleichzeitig. Sie sollten nicht bei jedem Redis-Vorgang die Verbindung trennen und wiederherstellen, da dies die Leistung beeinträchtigen kann.
Sie können die Verbindungsparameter, z. B. die Adresse des Redis-Hosts und das benötigte Kennwort, in der Methode angeben. Bei Verwendung von Azure Cache for Redis ist das Kennwort der primäre oder sekundäre Schlüssel, der über das Azure-Portal für Azure Cache for Redis generiert wird.
Nach dem Aufbau der Verbindung mit dem Redis-Server können Sie ein Handle für die Redis-Datenbank abrufen, die als Cache dient. Die hierfür benötigte GetDatabase -Methode wird von der Redis-Verbindung bereitgestellt. Danach können Sie mit den Methoden StringGet und StringSet Elemente aus dem Cache abrufen und Daten im Cache speichern. Diese Methoden erwarten als Parameter einen Schlüssel und geben entweder das Element aus dem Cache zurück, dessen Wert mit dem Schlüssel übereinstimmt (StringGet), oder fügen das Element mit diesem Schlüssel dem Cache hinzu (StringSet).
Je nach Standort des Redis-Servers können bei vielen Vorgängen zwischen der Übertragung der Anforderung an den Server und der Rückgabe der Antwort an den Client auch Latenzzeiten entstehen. Durch asynchrone Versionen zahlreicher ihrer Methoden sorgt die StackExchange-Bibliothek jedoch dafür, dass die Clientanwendungen reaktionsfähig bleiben. Diese Methoden unterstützen das aufgabenbasierte asynchrone Muster von .NET Framework.
Der folgende Codeausschnitt zeigt eine Methode namens RetrieveItem. Er veranschaulicht ein Beispiel für die Implementierung des cachefremden Musters mit Redis und der StackExchange-Bibliothek. Die Methode akzeptiert einen Zeichenfolgeschlüsselwert und versucht durch Aufrufen der StringGetAsync-Methode (der asynchronen Version von StringGet), das entsprechende Element aus dem Redis-Cache abzurufen.
Wird das Element nicht gefunden, so wird es mit der GetItemFromDataSourceAsync-Methode (einer lokalen Methode, die nicht Teil der StackExchange-Bibliothek ist) aus der zugrunde liegenden Datenquelle abgerufen. Dann wird es mit der StringSetAsync -Methode dem Cache hinzugefügt, sodass es beim nächsten Mal schneller abgerufen werden kann.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Die Methoden StringGet und StringSet sind nicht auf das Abrufen oder Speichern von Zeichenfolgenwerten beschränkt. Sie akzeptieren jedes Element, das als Bytearray serialisiert wird. Wenn Sie ein .NET-Objekt speichern müssen, können Sie es als Bytedatenstrom serialisieren und mit der StringSet -Methode in den Cache schreiben.
Auf ähnliche Weise können Sie ein Objekt mit der StringGet -Methode aus dem Cache lesen und in ein .NET-Objekt deserialisieren. Der folgende Code zeigt verschiedene Erweiterungsmethoden für die IDatabase-Schnittstelle (die GetDatabase-Methode einer Redis-Verbindung gibt ein IDatabase-Objekt zurück) sowie Beispielcode, in dem diese Methoden zum Lesen und Schreiben eines BlogPost-Objekts in den Cache verwendet werden:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Der folgende Codeausschnitt veranschaulicht eine Methode namens RetrieveBlogPost, die diese Erweiterungsmethoden nach dem Cache-Aside-Muster zum Lesen und Schreiben eines serialisierbaren BlogPost-Objekts im Cache verwendet:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Wenn eine Clientanwendung mehrere asynchrone Anforderungen sendet, unterstützt Redis auch Befehls-Pipelining. Redis kann Anforderungen nach dem Multiplexer-Verfahren über die gleiche Verbindung verarbeiten, statt Befehle in strenger Reihenfolge zu empfangen und auszuführen.
Auch dadurch werden Latenzzeiten durch eine effizientere Nutzung des Netzwerks verringert. Der folgende Codeausschnitt zeigt ein Beispiel, das die Daten zweier Kunden gleichzeitig abruft. Der Code sendet zwei Anforderungen und führt dann weitere Verarbeitungsschritte aus (die hier nicht dargestellt werden), bevor er auf die Ergebnisse wartet. Die Wait-Methode des Cacheobjekts ist vergleichbar mit der Task.Wait-Methode von .NET Framework:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Weitere Informationen zum Schreiben von Clientanwendungen, die Azure Cache for Redis verwenden können, finden Sie in der Dokumentation zu Azure Cache for Redis. Weitere Informationen finden Sie auch unter StackExchange.Redis.
Die Seite Pipelines and Multiplexers (Pipelines und Multiplexer) auf der gleichen Website bietet darüber hinaus Informationen zu asynchronen Vorgängen und Pipelining mit Redis und der StackExchange-Bibliothek.
Verwenden des Redis-Zwischenspeicherns
Die einfachste Verwendung von Redis für das Zwischenspeichern beinhaltet das Speichern von Schlüssel-/Wertpaaren, wobei der Wert eine nicht interpretierte Zeichenfolge von beliebiger Länge ist, die beliebige binäre Daten enthalten kann. (Im Prinzip handelt es sich hier um ein Bytearray, das als Zeichenfolge behandelt werden kann.) Dieses Szenario wurde im Abschnitt „Implementieren von Clientanwendungen für den Redis-Cache“ weiter oben in diesem Artikel dargestellt.
Beachten Sie, dass Schlüssel auch nicht interpretierte Daten enthalten, damit Sie beliebige binäre Informationen als Schlüssel verwenden können. Je länger der Schlüssel jedoch ist, desto mehr Speicherplatz beansprucht er, und desto länger dauern Suchvorgänge. Aus Gründen der Leistung und Verwaltbarkeit sollten Sie Ihren Keyspace sorgfältig planen und aussagekräftige (aber nicht allzu lange) Schlüssel verwenden.
Verwenden Sie zum Beispiel strukturierte Schlüssel wie „customer:100“ zur Darstellung des Schlüssels für den Kunden mit der ID 100, anstatt einfach nur „100“. Mit einem solchen Schema können Sie problemlos zwischen Werten unterscheiden, die unterschiedliche Datentypen speichern. Nach diesem Schema würden Sie zum Beispiel zur Darstellung des Schlüssels für den Auftrag mit der ID 100 den Schlüssel „orders:100“ verwenden.
Abgesehen von eindimensionalen Binärzeichenfolgen kann ein Wert eines Schlüssel-/Wertpaars in Redis auch strukturiertere Informationen wie Listen, Sätze (sortierte und unsortierte) und Hashes enthalten. Redis bietet einen umfassenden Befehlssatz, mit dem diese Datentypen verarbeitet werden können, wobei viele dieser Befehle über eine Clientbibliothek, z. B. StackExchange, auch .NET Framework-Anwendungen zur Verfügung stehen. Eine detailliertere Übersicht über diese Datentypen und die Befehle zu deren Verarbeitung finden Sie auf der Seite An introduction to Redis data types and abstractions (Eine Einführung zu Redis-Datentypen und -Abstraktionen) auf der Redis-Website.
In diesem Abschnitt werden einige gängige Anwendungsbeispiele für diese Datentypen und Befehle vorgestellt.
Ausführen von atomaren und Batchvorgängen
Redis unterstützt eine Reihe von atomaren Get- und Set-Vorgängen für Zeichenfolgewerte. Durch diese Vorgänge lässt sich die Konkurrenzsituation, die zwischen separaten GET- und SET-Befehlen auftreten kann, entschärfen. Die verfügbaren Vorgänge umfassen:
INCR,INCRBY,DECRundDECRBY, die atomare Inkrement- und Dekrementvorgänge an ganzzahligen numerischen Datenwerten ausführen. Die StackExchange-Bibliothek bietet zur Ausführung dieser Vorgänge und zur Rückgabe der Ergebniswerte aus dem Cache erweiterte Versionen derIDatabase.StringIncrementAsync- undIDatabase.StringDecrementAsync-Methoden. Folgender Codeausschnitt veranschaulicht die Verwendung dieser Methoden:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, die den Wert eines Schlüssels abruft und ihn in einen neuen Wert ändert. Die StackExchange-Bibliothek stellt diesen Vorgang über die MethodeIDatabase.StringGetSetAsyncbereit. Nachfolgender Codeausschnitt zeigt ein Beispiel für diese Methode. Dieser Code gibt den aktuellen Wert zurück, der mit dem Schlüssel „data:counter“ aus dem vorhergehenden Beispiel verknüpft ist. Dann setzt er den Wert für diesen Schlüssel auf null zurück – alles als Teil des gleichen Vorgangs:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETundMSET, die einen Satz von Zeichenfolgewerten in einem Vorgang zurückgeben oder ändern können. Diese Funktionalität wird, wie das folgende Beispiel zeigt, auch von den erweiterten MethodenIDatabase.StringGetAsyncundIDatabase.StringSetAsyncunterstützt:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Sie können auch mehrere Vorgänge zu einer einzigen Redis-Transaktion zusammenfassen, wie weiter vorn in diesem Artikel im Abschnitt „Transaktionen und Batches in Redis“ beschrieben. Die StackExchange-Bibliothek bietet über die ITransaction-Schnittstelle Unterstützung für Transaktionen.
Sie erstellen ein ITransaction-Objekt mithilfe der IDatabase.CreateTransaction-Methode. Sie rufen Befehle für die Transaktion mithilfe der Methoden auf, die vom ITransaction -Objekt bereitgestellt werden.
Die ITransaction-Schnittstelle bietet Zugriff auf einen Satz von Methoden, die denen ähneln, auf die über die IDatabase-Schnittstelle zugegriffen wird; allerdings sind diese Methoden asynchron. Dies bedeutet, dass sie nur ausgeführt werden, wenn die ITransaction.Execute-Methode aufgerufen wird. Der von der ITransaction.Execute -Methode zurückgegebene Wert gibt an, ob die Transaktion erfolgreich erstellt wurde (true) oder fehlgeschlagen ist (false).
Der folgende Codeausschnitt zeigt ein Beispiel, das zwei Leistungsindikatoren innerhalb derselben Transaktion inkrementiert bzw. dekrementiert:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Denken Sie daran, dass es sich bei Redis-Transaktionen nicht um Transaktionen im Sinne von relationalen Datenbanktransaktionen handelt. Die Execute -Methode reiht lediglich alle Befehle der Transaktion zur Ausführung in eine Warteschlange ein, und wenn einer der Befehle fehlerhaft ist, wird die Transaktion gestoppt. Nach der erfolgreichen Einreihung aller Befehle in die Warteschlange werden die einzelnen Befehle asynchron ausgeführt.
Auch wenn ein Befehl fehlschlägt, wird die Verarbeitung der anderen fortgesetzt. Falls Sie die erfolgreiche Ausführung eines Befehls überprüfen müssen, können Sie das Befehlsergebnis mit der Eigenschaft Result der entsprechenden Aufgabe abrufen, wie das vorangegangene Beispiel zeigt. Das Lesen der Eigenschaft Result blockiert den aufrufenden Thread so lange, bis die Aufgabe abgeschlossen ist.
Weitere Informationen finden Sie unter Transactions in Redis (Transaktionen in Redis).
Zum Ausführen von Batchvorgängen können Sie die IBatch -Schnittstelle der StackExchange-Bibliothek verwenden. Diese Schnittstelle bietet Zugriff auf einen Satz von Methoden, die denen ähneln, auf die über die IDatabase -Schnittstelle zugegriffen wird; allerdings sind diese Methoden asynchron.
Sie erstellen ein IBatch-Objekt mit der IDatabase.CreateBatch-Methode und führen den Batch dann mit der IBatch.Execute-Methode aus, wie das folgende Beispiel zeigt. Dieser Code legt lediglich einen Zeichenfolgewert fest, inkrementiert bzw. dekrementiert die Leistungsindikatoren aus dem vorherigen Beispiel und zeigt das Ergebnis an:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Machen Sie sich einen wichtigen Unterschied zur Transaktion klar: Wenn ein Befehl in einem Batch fehlschlägt, weil er fehlerhaft formuliert wurde, werden die verbleibenden Befehle möglicherweise dennoch ausgeführt. Die IBatch.Execute-Methode gibt keinen Hinweis auf Erfolg oder Fehler zurück.
Ausführen von Fire-and-Forget-Cache-Vorgängen (Auslösen und Vergessen)
Zur Unterstützung von Fire-and-Forget-Vorgängen verwendet Redis Befehlsflags. In dieser Situation initiiert der Client einfach einen Vorgang, hat aber kein Interesse am Ergebnis und wartet den Abschluss der Befehlsausführung nicht ab. Das folgende Beispiel zeigt, wie der Befehl INCR als Fire-and-Forget-Vorgang ausgeführt wird:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Festlegen des automatischen Ablaufens von Schlüsseln
Wenn Sie ein Element in einem Redis-Cache speichern, können Sie ein Zeitlimit angeben, nach dem das Element automatisch aus dem Cache entfernt wird. Sie können auch mit dem TTL -Befehl abfragen, wie viel Zeit noch bis zum Ablauf eines Schlüssels verbleibt. Dieser Befehl steht StackExchange-Anwendungen mit der IDatabase.KeyTimeToLive -Methode zur Verfügung.
Der folgende Codeausschnitt zeigt, wie für einen Schlüssel eine Ablaufzeit von 20 Sekunden festgelegt und seine verbleibende Lebensdauer abgefragt wird:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Mit dem Befehl EXPIRE, der in der StackExchange-Bibliothek als KeyExpireAsync -Methode zur Verfügung steht, können Sie als Ablaufzeit auch einen genauen Zeitpunkt (Datum und Uhrzeit) festlegen:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Tipp
Mit dem Befehl DEL, der in der StackExchange-Bibliothek als IDatabase.KeyDeleteAsync-Methode verfügbar ist, können Sie ein Element auch manuell aus dem Cache entfernen.
Verwenden von Tags zum übergreifenden Korrelieren der Elemente im Cache
Ein Redis-Satz ist eine Sammlung mehrerer Elemente, die einen gemeinsamen Schlüssel verwenden. Einen solchen Satz können Sie mit dem Befehl SADD erstellen. Die Elemente eines Satzes können Sie mit dem Befehl SMEMBERS abrufen. Die StackExchange-Bibliothek implementiert den Befehl SADD mit der IDatabase.SetAddAsync-Methode und der SMEMBERS-Befehl mit der IDatabase.SetMembersAsync-Methode.
Mit den Befehlen SDIFF (set difference = Unterschiedsmenge), SINTER (set intersection = Schnittmenge) und SUNION (set union = Vereinigungsmenge) können bestehende Sätze auch zu neuen Sätzen zusammengefasst werden. Die StackExchange-Bibliothek vereinheitlicht diese Vorgänge in der IDatabase.SetCombineAsync -Methode. Der erste Parameter für diese Methode gibt den auszuführenden Set-Vorgang an.
Die folgenden Codeausschnitte veranschaulichen, wie praktisch Sätze zum schnellen Speichern und Abrufen ähnlicher Elemente sind. Dieser Code nutzt den BlogPost -Typ, der im Abschnitt „Implementieren von Clientanwendungen für den Redis-Cache“ weiter oben in diesem Artikel beschrieben wurde.
Ein BlogPost -Objekt enthält vier Felder – eine ID, einen Titel, eine Bewertung für die Rangfolge und eine Sammlung von Tags. Der erste der folgenden Codeausschnitte zeigt Beispieldaten zum Füllen einer C#-Liste mit BlogPost -Objekten:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Sie können die Tags der einzelnen BlogPost-Objekte als Satz in einem Redis-Cache speichern und jeden Satz der BlogPost-ID zuordnen. Auf diese Weise findet eine Anwendung die Tags eines bestimmten Blogbeitrags sehr schnell. Wenn Sie die Suchrichtung umkehren und alle Blogbeiträge mit einem bestimmten Tag finden möchten, können Sie einen weiteren Satz mit Blogbeiträgen erstellen, deren Schlüssel die Tag-ID referenziert:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Mithilfe dieser Strukturen lassen sich viele allgemeine Abfragen sehr effizient ausführen. Sie können zum Beispiel wie folgt alle von Blogbeitrag 1 verwendeten Tags suchen und anzeigen:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Mit dem Befehl SINTER (set intersection) können Sie wie folgt alle Tags suchen, die sowohl Blogbeitrag 1 als auch Blogbeitrag 2 zugeordnet sind:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Oder Sie können alle Blogbeiträge suchen, die ein bestimmtes Tag enthalten:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Suchen der zuletzt verwendeten Elemente
Eine vielen Anwendungen gemeinsame Aufgabe ist das Suchen der zuletzt verwendeten Elemente. So sollen auf einer Blogsite beispielsweise Informationen über die zuletzt gelesenen Blogbeiträge angezeigt werden.
Diese Funktionalität kann durch eine Redis-Liste implementiert werden. Eine Redis-Liste enthält mehrere Elemente, die den gleichen Schlüssel verwenden. Die Liste fungiert als Warteschlange mit doppeltem Ende. Mit den Befehlen LPUSH (Links-Push) und RPUSH (Rechts-Push) können Sie Elemente mittels Push an beiden Enden der Liste einreihen. Mit den Befehlen LPOP (Links-Pop) und RPOP (Rechts-Pop) können Sie Elemente mittels Pop von beiden Enden der Liste abrufen. Mit den Befehlen LRANGE (linker Bereich) und RRANGE (rechter Bereich) können Sie auch einen Elementebereich von beiden Enden der Liste zurückgeben.
Die nachfolgenden Codeausschnitte zeigen, wie diese Vorgänge mit den von der StackExchange-Bibliothek bereitgestellten Befehlen ausgeführt werden. Dieser Code verwendet den BlogPost -Typ aus den vorherigen Beispielen. Während ein Benutzer einen Blogbeitrag liest, schiebt die IDatabase.ListLeftPushAsync-Methode den Titel des Blogbeitrags in eine Liste, die mit dem Schlüssel „blog:recent_posts“ im Redis-Cache verknüpft ist.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Auch die Titel aller nachfolgend gelesenen Blogbeiträge werden in diese Liste verschoben. Die Liste wird durch die Reihenfolge geordnet, in der die Titel hinzugefügt wurden. Die zuletzt gelesenen Blogbeiträge befinden sich am linken Ende der Liste. (Wenn der gleiche Blogbeitrag mehrmals gelesen wird, ist er mehrfach in der Liste eingetragen.)
Mit der IDatabase.ListRange -Methode können Sie die Titel der zuletzt gelesenen Beiträge anzeigen. Diese Methode akzeptiert als Parameter den Schlüssel mit der Liste, einen Startpunkt und einen Endpunkt. Der folgende Code ruft die Titel der 10 Blogbeiträge ab, die sich in der Liste am weitesten links befinden (Elemente 0 bis 9):
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Beachten Sie, dass die ListRangeAsync-Methode keine Elemente aus der Liste entfernt. Zu diesem Zweck können Sie die IDatabase.ListLeftPopAsync- und IDatabase.ListRightPopAsync-Methode verwenden.
Um zu verhindern, dass die Liste ins Unermessliche anwächst, können Sie die Liste mit ListTrimAsync in regelmäßigen Abständen kürzen. Der folgende Codeausschnitt zeigt Ihnen, wie Sie alle Elemente bis auf die fünf am weitesten links befindlichen aus der Liste entfernen:
await cache.ListTrimAsync(redisKey, 0, 5);
Implementieren einer Rangliste
Standardmäßig werden die Elemente eines Satzes nicht in einer bestimmten Reihenfolge aufbewahrt. Mit dem Befehl ZADD, der in der StackExchange-Bibliothek als IDatabase.SortedSetAdd -Methode zur Verfügung steht, können Sie einen Satz jedoch sortieren. Die Elemente werden nach einem numerischen Wert, dem Score (Bewertung), der dem Befehl als Parameter übergeben wird, sortiert.
Der folgende Codeausschnitt fügt einer sortierten Liste den Titel eines Blogbeitrags hinzu. In diesem Beispiel hat jeder Blogbeitrag auch ein Scorefeld mit der Rangfolge des Blogbeitrags.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Mit der IDatabase.SortedSetRangeByRankWithScores-Methode können Sie die Titel und Scores der Blogbeiträge in aufsteigender Scorereihenfolge abrufen:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Hinweis
Darüber hinaus stellt die StackExchange-Bibliothek die IDatabase.SortedSetRangeByRankAsync-Methode bereit, die die Daten in der Bewertungsreihenfolge, jedoch ohne Angabe der Bewertungen zurückgibt.
Mit zusätzlichen Parametern, die Sie der IDatabase.SortedSetRangeByRankWithScoresAsync-Methode übergeben, können Sie die Elemente auch in absteigender Scorereihenfolge abrufen, oder die Anzahl der abgerufenen Elemente begrenzen. Das nächste Beispiel zeigt die Titel und Scores der Blogbeiträge mit den zehn höchsten Scores:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
Im nächsten Beispiel wird die IDatabase.SortedSetRangeByScoreWithScoresAsync-Methode verwendet. Damit können Sie die zurückgegebenen Elemente auf diejenigen eines bestimmten Scorebereichs beschränken:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Nachrichten über Kanäle
Abgesehen von seiner Funktion als Datencache bietet ein Redis-Server über einen hochleistungsfähigen Publish/Subscribe-Mechanismus auch Messaging-Funktionalität. Clientanwendungen können einen Kanal abonnieren (subskribieren), und andere Anwendungen oder Dienste können Nachrichten für diesen Kanal veröffentlichen (publizieren). Die subskribierenden Anwendungen erhalten die veröffentlichten Nachrichten und können diese verarbeiten.
Redis bietet den SUBSCRIBE-Befehl für Clientanwendungen, um Kanäle zu abonnieren. Dieser Befehl erwartet als Parameter den Namen eines oder mehrerer Kanäle, über die die Anwendung Nachrichten akzeptiert. Die StackExchange-Bibliothek bietet darüber hinaus die ISubscription-Schnittstelle, über die eine .NET Framework-Anwendung Kanäle abonnieren und Nachrichten über Kanäle veröffentlichen kann.
Sie erstellen ein ISubscription-Objekt mithilfe der GetSubscriber-Methode der Verbindung mit dem Redis-Server. Und Sie empfangen Nachrichten über einen Kanal mithilfe der SubscribeAsync -Methode dieses Objekts. Das folgende Codebeispiel zeigt, wie ein Kanal mit dem Namen „messages:blogPosts“ abonniert wird:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Der erste Parameter der Subscribe -Methode ist der Name des Kanals. Dieser Name entspricht den gleichen Konventionen, denen Schlüssel im Cache entsprechen. Der Name kann beliebige Binärdaten enthalten, aber wir empfehlen, dass Sie relativ kurze, aussagekräftige Zeichenfolgen verwenden, um eine gute Leistung und Verwaltbarkeit zu gewährleisten.
Beachten Sie außerdem, dass der von Kanälen verwendete Namespace sich von dem Namespace unterscheidet, der von Schlüsseln verwendet wird. Sie können also Kanäle und Schlüssel identischen Namens haben, obwohl dies die Verwaltung Ihres Anwendungscodes erschweren könnte.
Der zweite Parameter ist ein Aktionsdelegat. Dieser Delegat wird bei jeder im Kanal neu veröffentlichten Nachricht asynchron ausgeführt. Im nächsten Beispiel wird lediglich eine Nachricht auf der Konsole angezeigt (die Nachricht enthält den Titel eines Blogbeitrags).
Für die Veröffentlichung über einen Kanal kann eine Anwendung den Redis-Befehl PUBLISH verwenden. Außerdem stellt die StackExchange-Bibliothek zu diesem Zweck die IServer.PublishAsync -Methode bereit. Der nächste Codeausschnitt zeigt, wie eine Nachricht über den Kanal „messages:blogPosts“ veröffentlicht wird:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Über den Publish/Subscribe-Mechanismus sollten Sie verschiedene Dinge wissen:
- Mehrere Abonnenten können den gleichen Kanal abonnieren. Sie alle erhalten dann die in diesem Kanal veröffentlichten Nachrichten.
- Abonnenten empfangen nur Nachrichten, die nach dem Abschluss ihres Abonnements veröffentlicht wurden. Die Kanäle sind nicht gepuffert. Sobald also eine Nachricht veröffentlicht wurde, pusht die Redis-Infrastruktur die Nachricht an jeden Abonnenten und entfernt sie anschließend.
- Abonnenten erhalten Nachrichten standardmäßig in der Reihenfolge, in der sie gesendet werden. Innerhalb eines sehr aktiven Systems mit sehr vielen Nachrichten und vielen Abonnenten und Publishern würde die garantierte Zustellung der Nachrichten in der sequenziell richtigen Reihenfolge die Leistung des Systems beeinträchtigen. Wenn die Nachrichten unabhängig voneinander sind und die Reihenfolge ihrer Zustellung unerheblich ist, können Sie die Parallelverarbeitung durch das Redis-System aktivieren, was die Reaktionsfähigkeit verbessern kann. Dazu setzen Sie die Einstellung PreserveAsyncOrder der vom Abonnenten verwendeten Verbindung auf dem StackExchange-Client auf „false“:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Aspekte der Serialisierung
Berücksichtigen Sie beim Wählen eines Serialisierungsformats die Kompromisse zwischen Leistung, Interoperabilität, Versionsverwaltung, Kompatibilität mit vorhandenen Systemen, Datenkomprimierung und Arbeitsspeicherauslastung. Bedenken Sie beim Bewerten der Leistung, dass Benchmarks stark kontextabhängig sind. Sie spiegeln ggf. nicht Ihre tatsächliche Arbeitsauslastung wider, und neuere Bibliotheken oder Versionen werden unter Umständen nicht berücksichtigt. Es gibt kein „schnellstes“ Serialisierungsmodul für alle Szenarien.
Einige zu berücksichtigende Optionen sind:
Protokollpuffer (auch kurz als „protobuf“ bezeichnet) sind ein von Google entwickeltes Serialisierungsformat, mit dem strukturierte Daten effizient serialisiert werden können. Hierbei werden Definitionsdateien mit starker Typisierung verwendet, um Nachrichtenstrukturen zu definieren. Anschließend werden die Definitionsdateien in sprachspezifischen Code zum Serialisieren und Deserialisieren von Nachrichten kompiliert. Protokollpuffer können für vorhandene RPC-Mechanismen verwendet werden, oder es kann ein RPC-Dienst generiert werden.
Für Apache Thrift wird ein ähnlicher Ansatz mit stark typisierten Definitionsdateien und einem Kompilierungsschritt genutzt, um den Serialisierungscode und RPC-Dienste zu generieren.
Apache Avro stellt eine ähnliche Funktionalität für Protokollpuffer und Thrift bereit, allerdings ohne einen Kompilierungsschritt. Stattdessen enthalten serialisierte Daten immer ein Schema, mit dem die Struktur beschrieben wird.
JSON ist ein offener Standard, bei dem für Menschen lesbare Textfelder verwendet werden. Er bietet eine umfassende plattformübergreifende Unterstützung. JSON verwendet keine Nachrichtenschemas. Da es sich um ein textbasiertes Format handelt, ist seine Effizienz bei der Übertragung nicht sehr hoch. In einigen Fällen geben Sie zwischengespeicherte Elemente aber ggf. direkt per HTTP an einen Client zurück. In diesem Fall können mit der JSON-Speicherung die Kosten für die Deserialisierung aus einem anderen Format und die anschließende Serialisierung in JSON gespart werden.
Binäres JSON (BSON) ist ein binäres Serialisierungsformat, das eine ähnliche Struktur wie JSON verwendet. BSON wurde so entworfen, dass es einfach und leicht zu scannen ist und schnell serialisiert und deserialisiert werden kann (verglichen mit JSON). Die Nutzlasten sind von der Größe her mit JSON vergleichbar. Je nach den Daten kann eine BSON-Nutzlast kleiner oder größer als eine JSON-Nutzlast sein. BSON verfügt über einige zusätzliche Datentypen, die in JSON nicht verfügbar sind, insbesondere „BinData“ (für Bytearrays) und „Date“.
MessagePack ist ein binäres Serialisierungsformat mit einem kompakten Design für die Übertragung. Es werden keine Nachrichtenschemas oder Überprüfungen des Nachrichtentyps verwendet.
Bond ist ein plattformübergreifendes Framework zur Verwendung von schematisierten Daten. Die sprachübergreifende Serialisierung und Deserialisierung wird unterstützt. Relevante Unterschiede zu anderen hier aufgeführten Systemen sind die Unterstützung von Vererbung, Typaliase und generics.
gRPC ist ein Open Source-RPC-System, das von Google entwickelt wurde. Standardmäßig werden Protokollpuffer als Definitionssprache und zugrunde liegendes Format für den Nachrichtenaustausch genutzt.
Nächste Schritte
- Dokumentation zu Azure Cache for Redis
- Häufig gestellte Fragen zu Azure Cache for Redis
- Aufgabenbasiertes asynchrones Muster
- Redis-Dokumentation
- StackExchange.Redis
- Datenpartitionierungsleitfaden
Zugehörige Ressourcen
Eventuell sind auch folgende Muster für Ihr Szenario interessant, wenn Sie Caching in Ihren Anwendungen implementieren:
Cachefremdes Muster: Dieses Muster beschreibt, wie Daten bei Bedarf aus einem Datenspeicher in einen Cache geladen werden. Dieses Muster trägt auch dazu bei, die Konsistenz zwischen den im Cache gespeicherten Daten und den Daten im ursprünglichen Datenspeicher zu bewahren.
Sharding-Muster : Dieses Muster beschreibt die Implementierung einer horizontalen Partitionierung, die beim Speichern und Abrufen großer Datenvolumen zur Verbesserung der Skalierbarkeit beiträgt.