Dieser Artikel enthält eine Lösung und Anleitung für die Entwicklung von Offlinedatenvorgängen und Datenverwaltung (DataOps) für ein automatisiertes Fahrsystem. Die DataOps-Lösung basiert auf dem Framework, das im Entwurfsleitfaden für autonome Fahrzeugvorgänge (AVOps) beschrieben ist. DataOps ist einer der Bausteine von AVOps. Weitere Bausteine sind Machine Learning-Vorgänge (MLOps), Validierungsvorgänge (ValOps), DevOps und zentralisierte AVOps-Funktionen.
Apache®, Apache Spark und Apache Parquet sind entweder eingetragene Marken oder Marken der Apache Software Foundation in den USA und/oder anderen Ländern. Die Verwendung dieser Marken impliziert keine Zustimmung durch die Apache Software Foundation.
Aufbau

Laden Sie eine Visio-Datei herunter, die dieses Architekturdiagramm enthält.
Datenfluss
Die Messdaten stammen aus den Datenströmen eines Fahrzeugs. Zu den Quellen gehören Kameras, Fahrzeugtelemetrie sowie Radar-, Ultraschall- und Lidar-Sensoren. Datenprotokollierungen im Fahrzeug speichern die Messdaten auf Protokollierungsspeichergeräten. Die Protokollierungsspeicherdaten werden in deinen Ziel-Data Lake hochgeladen. Ein Dienst wie Azure Data Box oder Azure Stack Edge oder eine dedizierte Verbindung wie Azure ExpressRoute erfasst die Daten in Azure. Messdaten in den folgenden Formaten landen in Azure Data Lake Storage: Measurement Data Format Version 4 (MDF4), Technical Data Management Systems (TDMS) und rosbag. Die hochgeladenen Daten gelangen in ein dediziertes Speicherkonto namens Landing, das für den Empfang und die Validierung der Daten bestimmt ist.
Eine Azure Data Factory Pipeline wird in einem geplanten Intervall ausgelöst, um die Daten im Landespeicherkonto zu verarbeiten. Die Pipeline führt die folgenden Schritte aus:
- Führt eine Datenqualitätsprüfung aus, z. B. eine Prüfsumme. In diesem Schritt werden Daten mit niedriger Qualität entfernt, sodass nur qualitativ hochwertige Daten an die nächste Phase übergeben werden. Azure App Service wird verwendet, um den Code für die Qualitätsprüfung auszuführen. Daten, die als unvollständig gelten, werden für die zukünftige Verarbeitung archiviert.
- Ruft für die Herkunftsnachverfolgung mithilfe von App Service eine Metadaten-API auf. In diesem Schritt werden Metadaten, die in Azure Cosmos DB gespeichert sind, aktualisiert, um einen neuen Datenstrom zu erstellen. Für jede Messung gibt es einen Rohdatenstrom.
- Kopiert die Daten in ein Speicherkonto namens Raw in Data Lake Storage.
- Ruft die Metadaten-API auf, um den Datenstrom als abgeschlossen zu markieren, damit andere Komponenten und Dienste den Datenstrom nutzen können.
- Archiviert die Messungen und entfernt sie aus dem Landespeicherkonto.
Data Factory und Azure Batch verarbeiten die Daten in der Rohzone, um Informationen zu extrahieren, die Downstreamsysteme nutzen können:
- Batch liest die Daten aus Themen in der Rohdatei und gibt die Daten in ausgewählte Themen in den entsprechenden Ordnern aus.
- Da die Dateien in der Rohzone jeweils mehr als 2 GB groß sein können, werden Parallelverarbeitungsfunktionen für jede Datei ausgeführt. Diese Funktionen extrahieren Bildverarbeitungs-, Lidar-, Radar- und GPS-Daten. Sie führen auch Metadatenverarbeitung durch. Data Factory und Batch bieten eine Möglichkeit, Parallelität auf skalierbare Weise auszuführen.
- Die Daten werden heruntergerechnet, um die Datenmenge zu reduzieren, die beschriftet und kommentiert werden muss.
Wenn Daten aus der Fahrzeugprotokollierung nicht über die verschiedenen Sensoren hinweg synchronisiert werden, wird eine Data Factory-Pipeline ausgelöst, die die Daten synchronisiert, um ein gültiges Dataset zu erstellen. Der Synchronisierungsalgorithmus wird in Batch ausgeführt.
Eine Data Factory-Pipeline wird ausgeführt, um die Daten anzureichern. Beispiele für Verbesserungen sind Telemetriedaten, Fahrzeugprotokolldaten und andere Daten, z. B. Wetter-, Karten- oder Objektdaten. Angereicherte Daten helfen dabei, Datenanalysten Erkenntnisse zu liefern, die sie beispielsweise bei der Algorithmusentwicklung verwenden können. Die generierten Daten werden in Apache Parquet-Dateien gespeichert, die mit den synchronisierten Daten kompatibel sind. Metadaten zu den angereicherten Daten werden in einem Metadatenspeicher in Azure Cosmos DB gespeichert.
Drittanbieterpartner führen manuelle oder automatische Bezeichnungen durch. Die Daten werden über Azure Data Share für Drittanbieterpartner freigegeben und in Microsoft Purview integriert. Data Share verwendet ein dediziertes Speicherkonto namens Labeled in Data Lake Storage, um die bezeichneten Daten an die Organisation zurückzugeben.
Eine Data Factory-Pipeline führt die Szenenerkennung durch. Szenenmetadaten werden im Metadatenspeicher gespeichert. Szenendaten werden als Objekte in Parquet- oder Delta-Dateien gespeichert.
Neben Metadaten für die Anreicherungsdaten und erkannten Szenen speichert der Metadatenspeicher in Azure Cosmos DB Metadaten für die Messungen, z. B. Laufwerksdaten. Dieser Speicher enthält auch Metadaten für die Herkunft der Daten, während er die Prozesse für Extraktion, Downsampling, Synchronisierung, Anreicherung und Szenenerkennung durchläuft. Die Metadaten-API wird verwendet, um auf die Messungen, die Herkunft und die Szenendaten zuzugreifen und nachzuschlagen, wo die Daten gespeichert sind. Daher dient die Metadaten-API als Speicherebenenmanager. Sie verteilt Daten auf Speicherkonten. Außerdem bietet sie Entwicklern eine Möglichkeit, eine metadatenbasierte Suche zum Abrufen von Datenspeicherorten zu verwenden. Aus diesem Grund ist der Metadatenspeicher eine zentralisierte Komponente, die Nachverfolgbarkeit und Herkunft im gesamten Datenfluss der Lösung bietet.
Azure Databricks und Azure Synapse Analytics werden verwendet, um eine Verbindung mit der Metadaten-API herzustellen und auf Data Lake Storage zuzugreifen und die Daten zu recherchieren.
Komponenten
- Mit Data Box-Geräten können Sie Terabyte von Daten auf schnelle, kostengünstige und zuverlässige Weise in und aus Azure senden. In dieser Lösung wird Data Box verwendet, um gesammelte Fahrzeugdaten über einen regionalen Netzbetreiber an Azure zu übertragen.
- Azure Stack Edge-Geräte stellen Azure-Funktionen an Edgestandorten bereit. Beispiele für Azure-Funktionen sind Compute, Speicher, Netzwerk und hardwarebeschleunigtes maschinelles Lernen.
- ExpressRoute erweitert lokale Netzwerke über eine private Verbindung in die Microsoft-Cloud.
- Azure Data Lake speichert eine große Datenmenge in deren nativem Rohformat. In diesem Fall speichert Azure Data Lake Storage Daten basierend auf Phasen, z. B. roh oder extrahiert.
- Data Factory ist eine vollständig verwaltete, serverlose Lösung zum Erstellen und Planen von ETL-Workflows (Extrahieren, Transformieren, Laden) und ELT-Workflows (Extrahieren, Laden, Transformieren). Hier führt Azure Data Factory ETL über Batch-Compute aus und erstellt datengesteuerte Workflows zum Orchestrieren der Datenverschiebung und Transformieren von Daten.
- Batch führt umfangreiche auf Parallelverarbeitung ausgelegte HPC-Batchaufträge (High Performance Computing) effizient in Azure aus. Diese Lösung verwendet Batch, um umfangreiche Anwendungen für Aufgaben wie Datenwrangling, Filtern und Vorbereiten von Daten und Extrahieren von Metadaten auszuführen.
- Azure Cosmos DB ist eine global verteilte Datenbank mit Unterstützung mehrerer Modelle. Hier speichert sie Metadatenergebnisse, z. B. gespeicherte Messungen.
- Data Share teilt Daten mit Partnerorganisationen mithilfe erweiterter Sicherheit. Mit der direkten Freigabe können Datenanbieter Daten direkt an ihrem Speicherort freigeben, ohne die Daten zu kopieren oder Schattenkopien zu erstellen. In dieser Lösung teilt Data Share Daten mit Beschriftungsunternehmen.
- Azure Databricks bietet eine Reihe von Tools zum Verwalten von Datenlösungen auf Unternehmensniveau im großen Stil. Dies ist für langwierige Vorgänge mit großen Mengen von Fahrzeugdaten erforderlich. Technische Fachkräfte für Daten verwenden Azure Databricks als Analyseworkbench.
- Azure Synapse Analytics dient dazu, schneller Erkenntnisse aus Data Warehouses und Big Data-Systemen zu gewinnen.
- Azure Cognitive Search stellt Datenkatalogsuchdienste bereit.
- App Service stellt einen serverlosen Web-App-Dienst bereit. In diesem Fall hostet App Service die Metadaten-API.
- Microsoft Purview stellt Datengovernance in Organisationen bereit.
- Azure Container Registry ist ein Dienst, der eine verwaltete Registrierung von Containerimages erstellt. Diese Lösung verwendet Container Registry zum Speichern von Containern für die Verarbeitung von Themen.
- Application Insights ist eine Erweiterung von Azure Monitor und stellt Funktionen zur Verwaltung der Anwendungsleistung bereit. In diesem Szenario hilft Ihnen Application Insights dabei, die Beobachtbarkeit für die Messextraktion zu verbessern: Sie können Application Insights verwenden, um benutzerdefinierte Ereignisse, benutzerdefinierte Metriken und andere Informationen zu protokollieren, während die Lösung jede Messung für die Extraktion verarbeitet. Sie können auch Abfragen in Log Analytics erstellen, um detaillierte Informationen zu jeder Messung zu erhalten.
Szenariodetails
Das Entwerfen eines robusten DataOps-Frameworks für autonome Fahrzeuge ist von entscheidender Bedeutung für die Verwendung Ihrer Daten, das Nachverfolgen ihrer Herkunft und die Bereitstellung dieser Daten in Ihrer Organisation. Ohne einen gut konzipierten DataOps-Prozess können die riesigen Datenmengen, die autonome Fahrzeuge generieren, schnell überwältigend und schwer zu verwalten sein.
Wenn Sie eine effektive DataOps-Strategie implementieren, tragen Sie dazu bei, dass Ihre Daten ordnungsgemäß gespeichert werden, leicht zugänglich sind und eine klare Herkunft aufweisen. Außerdem vereinfachen Sie die Verwaltung und Analyse der Daten, was zu fundierteren Entscheidungen und einer verbesserten Fahrzeugleistung führt.
Ein effizienter DataOps-Prozess bietet eine Möglichkeit zum einfachen Verteilen von Daten in Ihrer Organisation. Verschiedene Teams können dann auf die Informationen zugreifen, die sie benötigen, um ihre Vorgänge zu optimieren. DataOps erleichtert die Zusammenarbeit und das Teilen von Erkenntnissen, wodurch die Gesamteffektivität Ihrer Organisation verbessert wird.
Typische Herausforderungen für Datenvorgänge im Kontext autonomer Fahrzeuge sind:
- Verwaltung des täglichen Terabyte- oder Petabytevolumens an Messdaten aus Forschungs- und Entwicklungsfahrzeugen.
- Datenfreigabe und Zusammenarbeit zwischen mehreren Teams und Partnern, z. B. für Bezeichnungen, Anmerkungen und Qualitätsprüfungen.
- Rückverfolgbarkeit und Herkunft für einen sicherheitskritischen Wahrnehmungsstapel, der Versionsverwaltung und die Herkunft von Messdaten erfasst.
- Metadaten und Datenermittlung, um semantische Segmentierung, Bildklassifizierung und Objekterkennungsmodelle zu verbessern.
Diese AVOps DataOps-Lösung bietet Anleitungen zum Angehen dieser Herausforderungen.
Mögliche Anwendungsfälle
Diese Lösung kommt Automobil-Erstausrüstungsherstellern (OEMs), Tier-1-Anbietern und unabhängigen Softwareanbietern (Independent Software Vendors, ISVs) zugute, die Lösungen für automatisiertes Fahren entwickeln.
Verbunddatenvorgänge
In einer Organisation, die AVOps implementiert, tragen mehrere Teams aufgrund der Komplexität, die für AVOps erforderlich ist, zu DataOps bei. Beispielsweise kann ein Team für die Datensammlung und Datenerfassung zuständig sein. Ein anderes Team ist möglicherweise für das Qualitätsmanagement von Lidar-Daten verantwortlich. Aus diesem Grund sind die folgenden Prinzipien einer Datengitterarchitektur für DataOps wichtig:
- Domänenorientierte Dezentralisierung von Datenbesitz und -architektur. Ein dediziertes Team ist für eine Datendomäne verantwortlich, die Datenprodukte für diese Domäne bereitstellt, z. B. beschriftete Datasets.
- Daten als Produkt. Jede Datendomäne verfügt über verschiedene Zonen in Speichercontainern, die in Data Lake implementiert sind. Es gibt Zonen für die interne Nutzung. Es gibt auch eine Zone, die veröffentlichte Datenprodukte für andere Datendomänen oder externe Nutzung enthält, um Datenduplizierung zu vermeiden.
- Self-Service-Daten als Plattform, um autonome, domänenorientierte Datenteams zu ermöglichen.
- Verbundgovernance zum Ermöglichen der Interoperabilität und des Zugriffs zwischen AVOps-Datendomänen, die einen zentralisierten Metadatenspeicher und einen Datenkatalog erfordern. Beispielsweise benötigt eine Bezeichnungsdatendomäne möglicherweise Zugriff auf eine Datensammlungsdomäne.
Weitere Informationen zu Data Mesh-Implementierungen finden Sie unter Analyse auf Cloudebene.
Beispielstruktur für AVOps-Datendomänen
Die folgende Tabelle enthält einige Ideen zum Strukturieren von AVOps-Datendomänen:
| Datendomäne | Veröffentlichte Datenprodukte | Lösungsschritt |
|---|---|---|
| Datensammlung | Hochgeladene und überprüfte Messdateien | Ziel- und Rohdaten |
| Extrahierte Bilder | Ausgewählte und extrahierte Bilder oder Frames, Lidar- und Radardaten | Extrahiert |
| Extrahiertes Radar oder Lidar | Ausgewählte und extrahierte Lidar- und Radardaten | Extrahiert |
| Extrahierte Telemetriedaten | Ausgewählte und extrahierte Fahrzeugtelemetriedaten | Extrahiert |
| Bezeichnet | Bezeichnete Datasets | Bezeichnet |
| Neuberechnung | Generierte KPIs (Key Performance Indicators) auf Basis wiederholter Simulationsläufe | Neuberechnung |
Jede AVOps-Datendomäne wird basierend auf einer Blaupausenstruktur eingerichtet. Diese Struktur umfasst Data Factory, Data Lake Storage, Datenbanken, Batch- und Apache Spark-Runtimes über Azure Databricks oder Azure Synapse Analytics.
Metadaten und Datenermittlung
Jede Datendomäne ist dezentralisiert und verwaltet die entsprechenden AVOps-Datenprodukte individuell. Für die zentrale Datenermittlung und um zu wissen, wo sich Datenprodukte befinden, sind zwei Komponenten erforderlich:
- Ein Metadatenspeicher, der Metadaten zu verarbeiteten Messdateien und Datenströmen wie Videosequenzen speichert. Mit dieser Komponente können die Daten mit Anmerkungen, die indiziert werden müssen, z. B. zum Durchsuchen der Metadaten von nicht beschrifteten Dateien, auffindbar und nachverfolgbar gemacht werden. Sie können beispielsweise alle Frames für bestimmte Fahrzeugidentifikationsnummern (VINs) oder Frames mit Fußgängern oder anderen anreicherungsbasierten Objekten zurückgeben.
- Ein Datenkatalog, der die Herkunft, die Abhängigkeiten zwischen AVOps-Datendomänen und die an der AVOps-Datenschleife beteiligten Datenspeicher zeigt. Ein Beispiel für einen Datenkatalog ist Microsoft Purview.
Sie können Azure Data Explorer oder Azure Cognitive Search verwenden, um einen Metadatenspeicher zu erweitern, der auf Azure Cosmos DB basiert. Ihre Auswahl hängt vom endgültigen Szenario ab, das Sie für die Datenermittlung benötigen. Verwenden Sie Azure Cognitive Search für semantische Suchfunktionen.
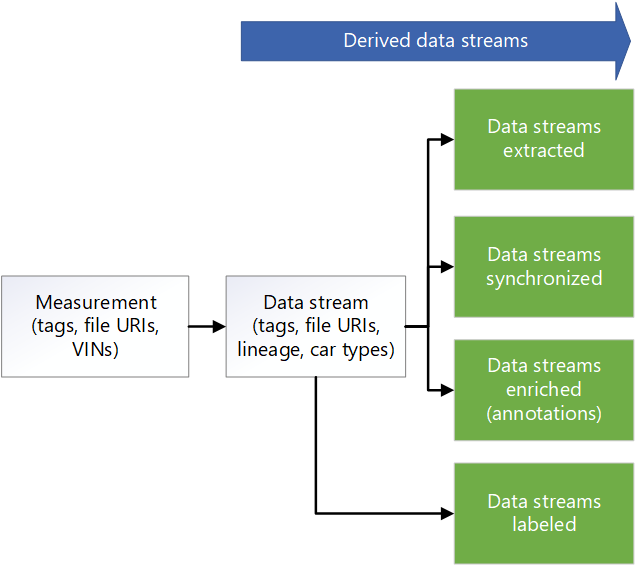
Das folgende Metadatenmodelldiagramm zeigt ein typisches einheitliches Metadatenmodell, das in mehreren AVOps-Datenschleifenpfeilern verwendet wird:
Datenfreigabe
Die Datenfreigabe ist ein häufiges Szenario in einer AVOps-Datenschleife. Zu den Anwendungen zählen die gemeinsame Nutzung von Daten zwischen Datendomänen und die externe Freigabe, z. B. zur Integration von Bezeichnungspartnern. Microsoft Purview bietet die folgenden Funktionen für eine effiziente Datenfreigabe in einer Datenschleife:
Zu den empfohlenen Formaten für den Datenaustausch mit Bezeichnungen gehören COCO-Datasets (Common Objects in Context,gemeinsame Objekte im Kontext und Association for Standardization of Automation and Measuring Systems (ASAM) OpenLABEL-Datasets.
In dieser Lösung werden die beschrifteten Datasets in MLOps-Prozessen verwendet, um spezialisierte Algorithmen wie Wahrnehmungs- und Sensorfusionsmodelle zu erstellen. Die Algorithmen können Szenen und Objekte in einer Umgebung erkennen, z. B. fahrspurwechselnde Autos, blockierte Straßen, Fußgängerverkehr, Ampeln und Verkehrszeichen.
Datenpipeline
In dieser DataOps-Lösung wird die Verschiebung von Daten zwischen verschiedenen Phasen in der Datenpipeline automatisiert. Durch diesen Ansatz bietet der Prozess Vorteile für Effizienz, Skalierbarkeit, Konsistenz, Reproduzierbarkeit, Anpassungsfähigkeit und Fehlerbehandlung. Er verbessert den gesamten Entwicklungsprozess, beschleunigt den Fortschritt und unterstützt den sicheren und effektiven Einsatz von Technologien für das autonome Fahren.
In den folgenden Abschnitten wird beschrieben, wie Sie Datenverschiebungen zwischen den Phasen implementieren und wie Sie Ihre Speicherkonten strukturieren sollten.
Hierarchische Ordnerstruktur
Eine gut organisierte Ordnerstruktur ist eine wichtige Komponente einer Datenpipeline bei der Entwicklung des autonomen Fahrens. Eine solche Struktur ermöglicht eine systematische und leicht navigierbare Anordnung von Datendateien, die effiziente Datenverwaltung und einen effizienten Datenabruf ermöglicht.
In dieser Lösung haben die Daten im Ordner raw die folgende hierarchische Struktur:
region/raw/<measurement-ID>/<data-stream-ID>/JJJJ/MM/TT
Die Daten im extrahierten Zonenspeicherkonto verwenden eine ähnliche hierarchische Struktur:
region/extracted/<measurement-ID>/<data-stream-ID>/JJJJ/MM/TT
Wenn Sie ähnliche hierarchische Strukturen verwenden, können Sie die hierarchische Namespacefunktion von Data Lake Storage nutzen. Hierarchische Strukturen helfen dabei, skalierbaren und kostengünstigen Objektspeicher zu erstellen. Diese Strukturen verbessern auch die Effizienz der Objektsuche und des Objektabrufs. Die Partitionierung nach Jahr und VIN erleichtert die Suche nach relevanten Bildern aus bestimmten Fahrzeugen. Im Data Lake wird ein Speichercontainer für jeden Sensor erstellt, z. B. eine Kamera, ein GPS-Gerät oder ein Lidar- oder Radarsensor.
Zielspeicherkonto zum Rohspeicherkonto
Eine Data Factory-Pipeline wird basierend auf einem Zeitplan ausgelöst. Nachdem die Pipeline ausgelöst wurde, werden die Daten aus dem Zielspeicherkonto in das Rohspeicherkonto kopiert.

Die Pipeline ruft alle Messordner ab und durchläuft diese. Bei jeder Messung führt die Lösung die folgenden Aktivitäten aus:
Eine Funktion überprüft die Messung. Die Funktion ruft die Manifestdatei aus dem Messmanifest ab. Anschließend überprüft die Funktion, ob alle MDF4-, TDMS- und rosbag-Messdateien für die aktuelle Messung im Messordner vorhanden sind. Wenn die Überprüfung erfolgreich ist, fährt die Funktion mit der nächsten Aktivität fort. Wenn die Überprüfung fehlschlägt, überspringt die Funktion die aktuelle Messung und wechselt zum nächsten Messordner.
Es wird ein Web-API-Aufruf für eine API ausgeführt, die eine Messung erstellt, und die JSON-Nutzlast aus der JSON-Datei des Messmanifests wird an die API übergeben. Wenn der Aufruf erfolgreich ist, wird die Antwort analysiert, um die Mess-ID abzurufen. Wenn der Aufruf fehlschlägt, wird die Messung zur Fehlerbehandlung in die Aktivität bei Fehler verschoben.
Hinweis
Diese DataOps-Lösung basiert auf der Annahme, dass Sie die Anzahl der Anforderungen an den App-Dienst begrenzen. Wenn Ihre Lösung möglicherweise eine unbestimmte Anzahl von Anforderungen vorgibt, sollten Sie ein Ratenbegrenzungsmuster in Betracht ziehen.
Ein Web-API-Aufruf erfolgt an eine API, die einen Datenstrom erstellt, indem die erforderliche JSON-Nutzlast erstellt wird. Wenn der Aufruf erfolgreich ist, wird die Antwort analysiert, um die Datenstrom-ID und den Speicherort des Datenstroms abzurufen. Wenn der Aufruf fehlschlägt, wird die Messung in die Aktivität bei Fehler verschoben.
Ein Web-API-Aufruf wird ausgeführt, um den Status des Datenstroms auf
Start Copyzu aktualisieren. Wenn der Aufruf erfolgreich ist, kopiert die Kopieraktivität Messdateien an den Speicherort des Datenstroms. Wenn der Aufruf fehlschlägt, wird die Messung in die Aktivität bei Fehler verschoben.Eine Data Factory-Pipeline ruft Batch auf, um die Messdateien aus dem Landespeicherkonto in das Rohspeicherkonto zu kopieren. Ein Kopiermodul einer Orchestrator-App erstellt einen Auftrag mit den folgenden Aufgaben für jede Messung:
- Kopieren der Messdateien in das Rohspeicherkonto.
- Kopieren der Messdateien in ein Archivspeicherkonto.
- Entfernen der Messdateien aus dem Landespeicherkonto.
Hinweis
In diesen Aufgaben verwendet Batch einen Orchestratorpool und das AzCopy-Tool, um Daten zu kopieren und zu entfernen. AzCopy verwendet SAS-Token, um Kopier- oder Entfernungsaufgaben auszuführen. SAS-Token werden in einem Schlüsseltresor gespeichert und mit den Begriffen
landingsaskey,archivesaskeyundrawsaskeyreferenziert.Ein Web-API-Aufruf wird ausgeführt, um den Status des Datenstroms auf
Copy Completezu aktualisieren. Wenn der Aufruf erfolgreich ist, wird die Sequenz mit der nächsten Aktivität fortgesetzt. Wenn der Aufruf fehlschlägt, wird die Messung in die Aktivität bei Fehler verschoben.Die Messdateien werden aus dem Landespeicherkonto in ein Zielarchiv verschoben. Diese Aktivität kann eine bestimmte Messung erneut ausführen, indem sie über eine Hydrat-Kopierpipeline zurück in das Landespeicherkonto verschoben wird. Die Lebenszyklusverwaltung ist für diese Zone aktiviert, sodass Messungen in dieser Zone automatisch gelöscht oder archiviert werden.
Tritt bei einer Messung ein Fehler auf, wird die Messung in eine Fehlerzone verschoben. Von dort aus kann sie in das Landespeicherkonto verschoben werden, um erneut ausgeführt zu werden. Alternativ kann die Lebenszyklusverwaltung die Messung automatisch löschen oder archivieren.
Beachten Sie folgende Punkte:
- Diese Pipelines werden basierend auf einem Zeitplan ausgelöst. Dieser Ansatz trägt dazu bei, die Nachverfolgbarkeit von Pipelineausführungen zu verbessern und unnötige Ausführungen zu vermeiden.
- Jede Pipeline wird mit dem Parallelitätswert 1 konfiguriert, um sicherzustellen, dass alle vorherigen Ausführungen abgeschlossen werden, bevor die nächste geplante Ausführung beginnt.
- Jede Pipeline ist so konfiguriert, dass Messungen parallel kopiert werden. Wenn z. B. eine geplante Ausführung 10 Messungen zum Kopieren aufnimmt, können die Pipelineschritte gleichzeitig für alle zehn Messungen ausgeführt werden.
- Jede Pipeline ist so konfiguriert, dass eine Warnung in Monitor generiert wird, wenn die Pipeline länger dauert als die erwartete Zeit bis zum Abschluss.
- Die Aktivität bei Fehler wird in späteren Beobachtbarkeitsabschnitten implementiert.
- Die Lebenszyklusverwaltung löscht automatisch Teilmessungen, z. B. Messungen mit fehlenden rosbag-Dateien.
Batchentwurf
Die gesamte Extraktionslogik ist in verschiedenen Containerimages mit einem Container für jeden Extraktionsprozess verpackt. Batch führt die Containerworkloads parallel aus, wenn Informationen aus Messdateien extrahiert werden.

Batch verwendet einen Orchestratorpool und einen Ausführungspool für die Verarbeitung von Workloads:
- Ein Orchestratorpool verfügt über Linux-Knoten ohne Containerruntime-Unterstützung. Der Pool führt Python-Code aus, der die Batch-API verwendet, um Aufträge und Aufgaben für den Ausführungspool zu erstellen. Dieser Pool überwacht auch diese Aufgaben. Data Factory ruft den Orchestratorpool auf, der die Containerworkloads orchestriert, die Daten extrahieren.
- Ein Ausführungspool verfügt über Linux-Knoten mit Containerruntimes, um ausgeführte Containerworkloads zu unterstützen. Für diesen Pool werden Aufträge und Aufgaben über den Orchestratorpool geplant. Alle Containerimages, die für die Verarbeitung im Ausführungspool erforderlich sind, werden mithilfe von JFrog in eine Containerregistrierung gepusht. Der Ausführungspool ist so konfiguriert, dass er eine Verbindung mit dieser Registrierung herstellt und die erforderlichen Images pullt.
Speicherkonten, aus denen Daten gelesen und geschrieben werden, werden über NFS 3.0 auf den Batchknoten und den Containern bereitgestellt, die auf den Knoten ausgeführt werden. Dieser Ansatz hilft Batchknoten und Containern, Daten schnell zu verarbeiten, ohne die Datendateien lokal auf die Batchknoten herunterladen zu müssen.
Hinweis
Die Batch- und Speicherkonten müssen sich zum Einbinden im selben virtuellen Netzwerk befinden.
Aufrufen von Batch aus Data Factory
In der Extraktionspipeline übergibt der Trigger den Pfad der Metadatendatei und den Rohdatenstrompfad in die Pipelineparameter. Data Factory verwendet eine Lookup-Aktivität, um den JSON-Code aus der Manifestdatei zu analysieren. Die Datenstrom-ID für Rohdaten kann aus dem Rohdatenstreampfad extrahiert werden, indem die Pipelinevariable analysiert wird.
Data Factory ruft eine API auf, um einen Datenstrom zu erstellen. Die API gibt den Pfad für den extrahierten Datenstrom zurück. Der extrahierte Pfad wird dem aktuellen Objekt hinzugefügt, und Data Factory ruft Batch über eine benutzerdefinierte Aktivität auf, indem das aktuelle Objekt übergeben wird, nachdem der extrahierte Datenstrompfad angefügt wurde:
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
Schrittweiser Extraktionsprozess

Data Factory plant einen Auftrag mit einer Aufgabe für den Orchestratorpool, um eine Messung für die Extraktion zu verarbeiten. Data Factory übergibt die folgenden Informationen an den Orchestratorpool:
- Die Mess-ID
- Der Speicherort der zu extrahierenden Messdateien vom Typ MDF4, TDMS oder rosbag
- Der Zielpfad des Speicherorts des extrahierten Inhalts
- Die ID des extrahierten Datenstroms
Der Orchestratorpool ruft eine API auf, um den Datenstrom zu aktualisieren, und legt seinen Status auf fest
Processing.Der Orchestratorpool erstellt einen Auftrag für jede Messdatei, die Teil der Messung ist. Jeder Auftrag enthält die folgenden Aufgaben:
Aufgabe Zweck Hinweis Validierung Überprüft, ob Daten aus der Messdatei extrahiert werden können. Alle anderen Aufgaben hängen von dieser Aufgabe ab. Verarbeiten von Metadaten Leitet Metadaten aus der Messdatei ab und erweitert die Metadaten der Datei mithilfe einer API, um die Metadaten der Datei zu aktualisieren. Verarbeiten von StructuredTopicsExtrahiert strukturierte Daten aus einer bestimmten Messdatei. Die Liste der Themen, aus der strukturierte Daten extrahiert werden sollen, wird als Konfigurationsobjekt übergeben. Verarbeiten von CameraTopicsExtrahiert Bilddaten aus einer bestimmten Messdatei. Die Liste der Themen, aus der Images extrahiert werden sollen, wird als Konfigurationsobjekt übergeben. Verarbeiten von LidarTopicsExtrahiert Lidardaten aus einer bestimmten Messdatei. Die Liste der Themen, aus der Lidardaten extrahiert werden sollen, wird als Konfigurationsobjekt übergeben. Verarbeiten von CANTopicsExtrahiert CAN-Daten (Controller Area Network) aus einer bestimmten Messdatei. Die Liste der Themen, aus der Daten extrahiert werden sollen, wird als Konfigurationsobjekt übergeben. Der Orchestratorpool überwacht den Fortschritt jeder Aufgabe. Nachdem alle Aufträge für alle Messdateien abgeschlossen sind, ruft der Pool eine API auf, um den Datenstrom zu aktualisieren, und legt seinen Status auf
Completedfest.Der Orchestrator wird ordnungsgemäß beendet.
Hinweis
Jede Aufgabe ist ein separates Containerimage, das über Logik verfügt, die für ihren Zweck entsprechend definiert ist. Aufgaben akzeptieren Konfigurationsobjekte als Eingabe. Die Eingabe gibt beispielsweise an, wo die Ausgabe geschrieben werden soll und welche Messdatei verarbeitet werden soll. Ein Array von Thementypen, z. B.
sensor_msgs/Image, ist ein weiteres Beispiel für die Eingabe. Da alle anderen Aufgaben von der Validierungsaufgabe abhängen, wird dafür eine abhängige Aufgabe erstellt. Alle anderen Aufgaben können unabhängig voneinander verarbeitet und parallel ausgeführt werden.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Zuverlässigkeit
Zuverlässigkeit stellt sicher, dass Ihre Anwendung Ihre Verpflichtungen gegenüber den Kunden erfüllen kann. Weitere Informationen finden Sie in der Überblick über die Säule „Zuverlässigkeit“.
- Erwägen Sie in Ihrer Lösung die Verwendung von Azure-Verfügbarkeitszonen, bei denen es sich um eindeutige physische Standorte innerhalb derselben Azure-Region handelt.
- Planen Sie für Notfallwiederherstellung und Kontofailover.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Es ist wichtig, die Aufteilung der Zuständigkeiten zwischen einem Automobilhersteller und Microsoft zu verstehen. In einem Fahrzeug ist der Hersteller der Besitzer des gesamten Stapels, aber wenn die Daten in die Cloud wandern, gehen einige Verantwortlichkeiten auf Microsoft über. Azure Platform as a Service-Layer (PaaS) bieten integrierte Sicherheit auf dem physischen Stapel, einschließlich des Betriebssystems. Sie können den vorhandenen Infrastruktursicherheitskomponenten die folgenden Funktionen hinzufügen:
- Identitäts- und Zugriffsverwaltung mit Microsoft Entra-Identitäten und Richtlinien für den bedingten Microsoft Entra-Zugriff.
- Infrastrukturgovernance, die Azure Policy verwendet.
- Datengovernance, die Microsoft Purview verwendet.
- Verschlüsselung ruhender Daten, die native Azure-Speicher- und Datenbankdienste verwenden. Weitere Informationen finden Sie unter Überlegungen zum Schutz von Daten.
- Der Schutz von kryptografischen Schlüsseln und Geheimnissen. Verwenden Sie zu diesem Zweck Azure Key Vault.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Ein Hauptanliegen für OEMs und Tier 1-Lieferanten, die DataOps für automatisierte Fahrzeuge betreiben, sind die Betriebskosten. Diese Lösung verwendet die folgenden Praktiken, um die Kosten zu optimieren:
- Nutzen verschiedener Optionen, die Azure zum Hosten von Anwendungscode bietet. Diese Lösung verwendet App Service und Batch. Eine Anleitung zum Auswählen des richtigen Diensts für Ihre Bereitstellung finden Sie unter Auswählen eines Azure-Computediensts.
- Verwenden der direkten Azure Storage-Datenfreigabe.
- Kostenoptimierung durch Lebenszyklusverwaltung.
- Kosteneinsparungen bei App Service durch die Verwendung reservierter Instanzen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Ryan Matsumura | Senior Program Manager
- Jochen Schroeer | Lead Architect (Service Line Mobility)
- Brij Singh | Principal Software Engineer
- Ginette Vellera | Senior Software Engineering Lead
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Was ist Azure Batch?
- Was ist Azure Data Factory?
- Einführung in Azure Data Lake Storage Gen2
- Willkommen bei Azure Cosmos DB
- App Service: Übersicht
- Was ist Azure Data Share?
- Was ist Azure Data Box?
- Dokumentation zu Azure Stack Edge
- Was ist Azure ExpressRoute?
- Was ist Azure Machine Learning?
- Was ist Azure Databricks?
- Was ist Azure Synapse Analytics?
- Azure Monitor – Übersicht
- ROS-Protokolldateien (rosbags)
- Umfangreiche Datenbetriebsplattform für autonome Fahrzeuge