Dieses Clientprojekt half einem Fortune 500-Lebensmittelunternehmen, seine Nachfragevorhersage zu verbessern. Das Unternehmen liefert Produkte direkt an mehrere Einzelhandelsgeschäfte. Diese Optimierung hat dem Unternehmen dabei geholfen, seinen Vorrat an Lebensmitteln in verschiedenen Geschäften über mehrere US-Regionen hinweg zu verbessern. Damit dies möglich war, hat das Microsoft CSE-Team (Commercial Software Engineering) mit den Datenanalysten des Kundenunternehmens zusammengearbeitet, um individuelle Machine Learning-Modelle für die ausgewählten Regionen für eine Pilotstudie zu entwickeln. Die Modelle berücksichtigen Folgendes:
- Demografie der Käufer
- Historische und prognostizierte Wetterdaten
- Vergangene Lieferungen
- Produktrückgaben
- Sonderveranstaltungen
Das Ziel, den Bestand zu optimieren, stellte eine zentrale Komponente des Projekts dar, und das Kundenunternehmen konnte bereits in frühen praktischen Versuchen einen bedeutenden Anstieg der Verkäufe beobachten. Außerdem hat das Team den mittleren absoluten prozentualen Fehler (Mean Absolute Percentage Error, MAPE) im Vergleich zu einem historischen durchschnittlichen Baselinemodell um 40 % verringert.
Ein wichtiger Bestandteil des Projekts bestand darin, den Data Science-Workflow von der Pilotstudie hin zur Produktionsebene hochzuskalieren. Für diesen Workflow auf Produktionsebene musste das CSE-Team Folgendes umsetzen:
- Entwickeln von Modellen für viele Regionen
- Aktualisieren und überwachen Sie kontinuierlich die Leistung der Modelle.
- Erleichtern Sie die Zusammenarbeit zwischen den Daten- und Ingenieurteams.
Der herkömmliche Data Science-Workflow, wie er heute existiert, ähnelt einer einmaligen Laborumgebung mehr als einem Produktionsworkflow. Eine Umgebung für Datenwissenschaftler muss für sie für Folgendes geeignet sein:
- Aufbereiten der Daten
- Experimentieren mit unterschiedlichen Modellen
- Optimieren von Hyperparametern
- Erstellen eines Zyklus zum Erstellen, Testen, Auswerten und Optimieren
Die meisten Tools, die für diese Aufgaben verwendet werden, verfügen über bestimmte Zwecke und sind für die Automatisierung nicht gut geeignet. Bei einem Machine Learning-Vorgang auf Produktionsebene müssen Lebenszyklusverwaltung der Anwendung und DevOps stärker berücksichtigt werden.
Das CSE-Team half dem Kunden, den Betrieb auf Produktionsniveau zu bringen. Sie haben verschiedene Aspekte der Continuous Integration und Continuous Delivery (CI/CD) implementiert und Probleme wie die Beobachtungsfähigkeit und Integration mit Azure-Funktionen behandelt. Während der Implementierung hat das Team Lücken in vorhandenen MLOps-Anleitungen entdeckt. Diese Lücken mussten geschlossen werden, damit MLOps verständlicher wurde und maßstabgerecht besser skaliert werden konnte.
Wenn Unternehmen die MLOps-Verfahren verstehen, können sie besser sicherstellen, dass vom System produzierte Machine Learning-Modelle Produktionsqualität aufweisen und die Leistung des Unternehmens steigern. Das Unternehmen muss sich nicht mehr die meiste Zeit auf die Details in Bezug auf Infrastruktur und Entwicklungsarbeit konzentrieren, die erforderlich sind, um Machine Learning-Modelle für Vorgänge auf Produktionsebene zu entwickeln und auszuführen. Das Implementieren von MLOps hilft auch den Datenwissenschafts- und Softwareentwicklungs-Communitys, zusammenzuarbeiten, um ein produktionsfähiges System bereitzustellen.
Das CSE-Team hat dieses Projekt verwendet, um die Anforderungen der Machine Learning-Community zu erfüllen, indem Punkte wie das Entwickeln eines MLOps-Reifegradmodells angegangen wurden (was möglicherweise zum Erstellen von „MLOps in a Box“ führen konnte). Diese Bemühungen zielten darauf ab, die MLOps-Einführung zu verbessern, indem sie die typischen Herausforderungen der wichtigsten Akteure im MLOps-Prozess verstehen.
Szenarien: Bereitstellung und Technik
Im Szenario, das sich mit der Bereitstellung befasst, werden die realen Herausforderungen besprochen, die das CSE-Team lösen musste. Das technische Szenario definiert die Anforderungen zum Erstellen eines MLOps-Lebenszyklus, der so zuverlässig ist wie der DevOps-Lebenszyklus.
Bereitstellung
Das Kundenunternehmen liefert in regelmäßigen Abständen Lebensmittel direkt an Einzelhandelsmärkte. Die Anforderungen variieren bei jedem Einzelhandelsgeschäft, sodass die Menge an Lebensmitteln in jeder wöchentlichen Lieferung variieren muss. Das Maximieren von Verkäufen und das Minimieren von Produktrückgaben und entgangenen Verkaufschancen sind die Ziele der Prognosemethoden, die das Kundenunternehmen einsetzt. Dieses Projekt konzentriert sich auf die Verwendung von maschinellem Lernen, um die Prognosen zu verbessern.
Das CSE-Team hat das Projekt in zwei Phasen aufgeteilt. Phase 1 konzentrierte sich auf die Entwicklung von Machine Learning-Modellen, die eine praktisch orientierte Pilotstudie zur Effektivität von Prognosen durch maschinelles Lernen für eine ausgewählte Vertriebsregion unterstützen. Der Erfolg der Phase 1 führte zu Phase 2, in der das Team die anfängliche Pilotstudie aus einer minimalen Gruppe von Modellen, die eine einzelne geografische Region unterstützt haben, auf eine Reihe von nachhaltigen Produktionsmodellen für alle Vertriebsregionen des Kunden skaliert hat. Ein zentraler Aspekt bei der hochskalierten Lösung war die Notwendigkeit, die große Anzahl von geografischen Regionen und die dortigen lokalen Einzelhandelsgeschäfte zu berücksichtigen. Das Team hat die Machine Learning-Modelle auf große und kleine Geschäfte in jeder Region ausgerichtet.
In der Pilotstudie der Phase 1 wurde festgestellt, dass ein Modell, das für die Einzelhandelsgeschäfte einer Region dediziert ist, die lokale Verkaufshistorie, lokale demografische Daten, das Wetter und besondere Ereignisse nutzen kann, um die Nachfrageprognose für die Geschäfte in der Region zu optimieren. Vier Ensemblemodelle für Machine Learning-Prognosen waren für die Niederlassungen in einer Region zuständig. Die Modelle haben Daten in wöchentlichen Batches verarbeitet. Außerdem hat das Team zwei Baselinemodelle entwickelt, die historische Daten für den Vergleich verwenden.
Für die erste Version der skalierten Phase 2-Lösung wählte das CSE-Team 14 geografische Regionen aus, um teilzunehmen, einschließlich kleiner und großer Einzelhandelsmärkte. Dabei wurden mehr als 50 Machine Learning-Vorhersagemodelle eingesetzt. Das Team erwartete ein weiteres Systemwachstum und hat die Machine Learning-Modelle weiter verfeinert. Es wurde schnell klar, dass diese breiter skalierte Machine Learning-Lösung nur dann nachhaltig ist, wenn sie auf den bewährten Methoden von DevOps für die Machine Learning-Umgebung basiert.
| Environment | Marktregion | Format | Modelle | Modellbereich | Modellbeschreibung |
|---|---|---|---|---|---|
| Entwicklungsumgebung | Alle geografischen Märkte/Regionen (z. B. North Texas) | Große Geschäfte (Supermärkte, Kaufhäuser usw.) | Zwei Ensemblemodelle | Produkte mit langer Lagerdauer | Die lange und kurze Lagerdauer verfügt jeweils ein Ensemble aus dem Linearen Regressionsmodell „Least Absolute Shrinkage and Selection Operator“ (LASSO) und einem neuronalen Netz mit kategorialen Einbettungen |
| Produkte mit kurzer Lagerdauer | Die lange und kurze Lagerdauer verfügt jeweils über ein Ensemble aus dem Linearen Regressionsmodell „Least Absolute Shrinkage and Selection Operator“ (LASSO) und einem neuronalen Netz mit kategorischen Einbettungen. | ||||
| Ein Ensemblemodell | – | Historischer Durchschnitt | |||
| Kleine Geschäfte (Apotheken, Lebensmittelläden usw.) | Zwei Ensemblemodelle | Produkte mit langer Lagerdauer | Die lange und kurze Lagerdauer verfügt jeweils über ein Ensemble aus dem Linearen Regressionsmodell „Least Absolute Shrinkage and Selection Operator“ (LASSO) und einem neuronalen Netz mit kategorischen Einbettungen. | ||
| Produkte mit kurzer Lagerdauer | Die lange und kurze Lagerdauer verfügt jeweils über ein Ensemble aus dem Linearen Regressionsmodell „LASSO“ und einem neuronalen Netz mit kategorischen Einbettungen | ||||
| Ein Ensemblemodell | – | Historischer Durchschnitt | |||
| Wie oben für 13 weitere geografische Regionen | |||||
| Wie oben für die Produktionsumgebung |
Der MLOps-Prozess stellt ein Framework für das hochskalierte System bereit, das den vollständigen Lebenszyklus der Machine Learning-Modelle berücksichtigt. Das Framework umfasst Entwicklung, Tests, Bereitstellung, Betrieb und Überwachung. Es erfüllt die Anforderungen eines klassischen CI/CD-Prozesses. Da MLOps im Vergleich zu DevOps weniger ausgereift ist, wurden die vorhandenen Lücken von MLOps deutlich. Die Projektteams haben anschließend daran gearbeitet, einige dieser Lücken zu schließen. Sie wollten ein funktionales Prozessmodell bereitstellen, das die Verwendbarkeit der hochskalierten Machine Learning-Lösung sicherstellen soll.
Der in diesem Projekt entwickelte MLOps-Prozess hat in der Praxis einen wichtigen Schritt nach vorne gemacht, durch den MLOps weiter ausgereift und besser verwendbar wurde. Der neue Prozess kann direkt auf andere Machine Learning-Projekte angewendet werden. Das CSE-Team hat die Erkenntnisse genutzt, um einen Entwurf eines MLOps-Reifemodells zu entwickeln, das von allen Benutzern auf andere Machine Learning-Projekte angewendet werden kann.
Technisches Szenario
MLOps, auch als DevOps für maschinelles Lernen bezeichnet, ist ein Dachbegriff, der Philosophien, Methoden und Technologien umfasst, die sich auf die Implementierung von maschinellen Lernlebenszyklus in einer Produktionsumgebung beziehen. Dies ist noch immer ein relativ neues Konzept. Es gab viele Versuche, zu definieren, was MLOps ist, und viele Menschen haben gefragt, ob MLOps alles unterführen kann, wie Datenwissenschaftler Daten vorbereiten, um die letztendliche Bereitstellung, Überwachung und Auswertung von maschinellen Lernergebnissen zu ermöglichen. DevOps ist schon mehrere Jahre alt und umfasst eine Reihe grundlegender Praktiken, während MLOps noch recht neu ist. Wie es sich entwickelt, entdecken wir die Herausforderungen, zwei Disziplinen zusammenzubringen, die oft mit unterschiedlichen Fähigkeiten und Prioritäten arbeiten: Software/ops Engineering und Data Science.
Das Implementieren von MLOps in realen Produktionsumgebungen bringt besondere Herausforderungen mit sich, die überwunden werden müssen. Teams können die Azure-Funktionen verwenden, die MLOps-Muster unterstützen. Azure kann den Clients außerdem Dienste zur Ressourcenverwaltung und Orchestrierung zur Verfügung stellen, um eine effektive Machine Learning-Lebenszyklusverwaltung zu ermöglichen. Azure-Dienste sind die Grundlage für die MLOps-Lösung, die in diesem Artikel erläutert wird.
Anforderungen von Machine Learning-Modellen
Ein Großteil der Arbeit während der Pilotstudie der Phase 1 umfasste das Erstellen der Machine Learning-Modelle, die das CSE-Team auf die großen und kleinen Einzelhandelsgeschäfte in einer einzelnen Region anwenden würde. Wichtige Anforderungen für das enthaltene Modell umfassten Folgendes:
Verwenden von Azure Machine Learning Service.
Anfängliche experimentelle Modelle, die in Jupyter-Notebooks entwickelt und in Python implementiert wurden
Hinweis
Die Teams würden denselben Machine Learning-Ansatz für große und kleine Geschäften verwenden, die Trainings- und Bewertungsdaten unterscheiden sich aber je nach Größe des Geschäfts.
Erforderliche Vorbereitung von Daten für die Modellnutzung.
Daten, die nicht in Echtzeit, sondern auf Batchbasis verarbeitet werden.
Erneutes Training der Modelle, wenn Code oder Daten geändert werden, oder das Modell wird veraltet.
Anzeigen der Modellleistung in Power BI-Dashboards.
Die Modellleistung bei der Bewertung gilt als signifikant, wenn MAPE <= 45 % im Vergleich zu einem historischen durchschnittlichen Baselinemodell beträgt
MLOps-Anforderungen
Das Team musste mehrere wichtige Anforderungen erfüllen, um die Lösung aus Phase 1 der Pilotfeldstudie zu skalieren, in der nur wenige Modelle für eine einzelne Vertriebsregion entwickelt wurden. Phase 2 implementierte benutzerdefinierte Machine Learning-Modelle für mehrere Regionen. Die Implementierung umfasste:
Wöchentliche Batchverarbeitung für große und kleine Geschäfte in jeder Region, einschließlich des erneuten Trainings der einzelnen Modelle mit neuen Datasets
Fortlaufende Optimierung der Machine Learning-Modelle
Integration des Prozesses Entwicklung/Test/Verpacken/Test/Bereitstellung für CI/CD in einer DevOps-ähnlichen Verarbeitungsumgebung für MLOps
Hinweis
Dies ist eine Umstellung in der Art und Weise, wie Datenanalysten und Data Engineers in der Vergangenheit häufig gearbeitet haben.
Ein eindeutiges Modell, das jede Region für große und kleine Geschäfte basierend auf dem Verlauf, den demografischen Daten und anderen Schlüsselvariablen der Geschäfte repräsentiert. Das Modell musste das gesamte Dataset verarbeiten, um das Risiko eines Verarbeitungsfehlers zu minimieren.
Die Fähigkeit, zunächst 14 Vertriebsregionen zu unterstützen, mit Plänen für eine weitere Skalierung.
Pläne für zusätzliche Modelle für langfristige Prognosen für Regionen und andere Gruppierungen von Geschäften
Lösung für Machine Learning-Modelle
Der Machine Learning-Lebenszyklus bzw. der Data Science-Lebenszyklus kann in etwa durch den folgenden allgemeinen Prozessablauf beschrieben werden:
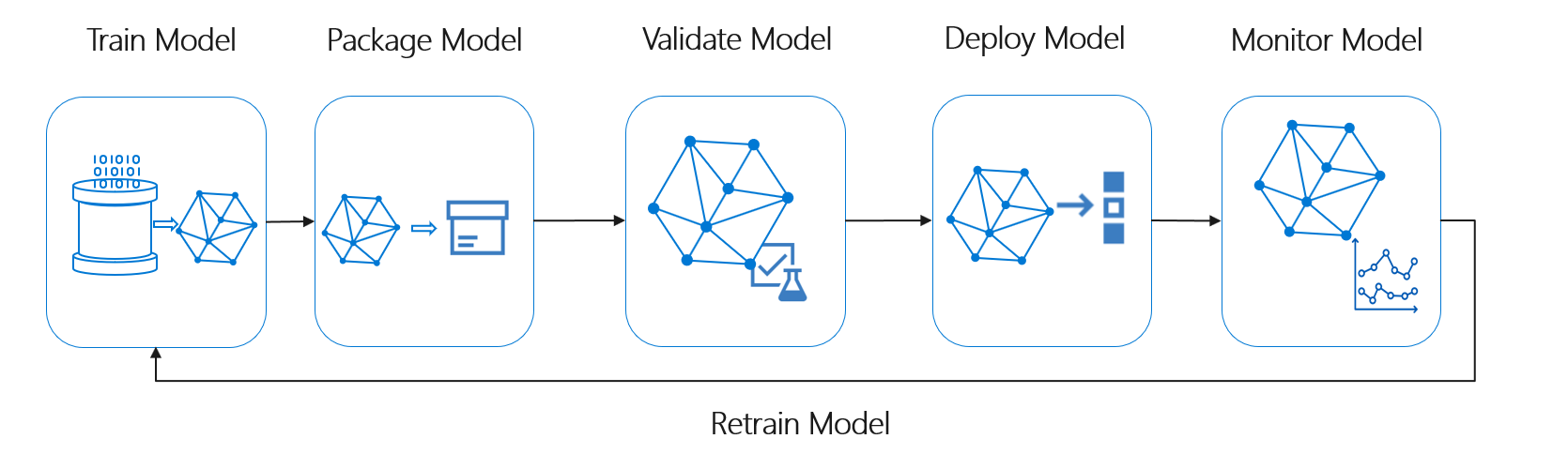
Das Bereitstellen des Modells kann jede betriebliche Verwendung des validierten Machine Learning-Modells darstellen. Im Vergleich zu DevOps ergibt sich bei MLOps eine zusätzliche Herausforderung in Bezug darauf, wie dieser Machine Learning-Lebenszyklus in den typischen CI/CD-Prozess integriert werden kann.
Der Data Science-Lebenszyklus folgt nicht dem typischen Lebenszyklus der Softwareentwicklung. Er umfasst die Verwendung von Azure Machine Learning, um die Modelle zu trainieren und zu scoren, daher mussten diese Schritte in die CI/CD-Automatisierung aufgenommen werden.
Die Batchverarbeitung von Daten die Grundlage der Architektur. Zwei Azure Machine Learning-Pipelines sind für den Prozess von zentraler Bedeutung, eine für das Training und die andere für die Bewertung. Dieses Diagramm zeigt die Data Science-Methodik, die für die anfängliche Phase des Kundenprojekts verwendet wurde:
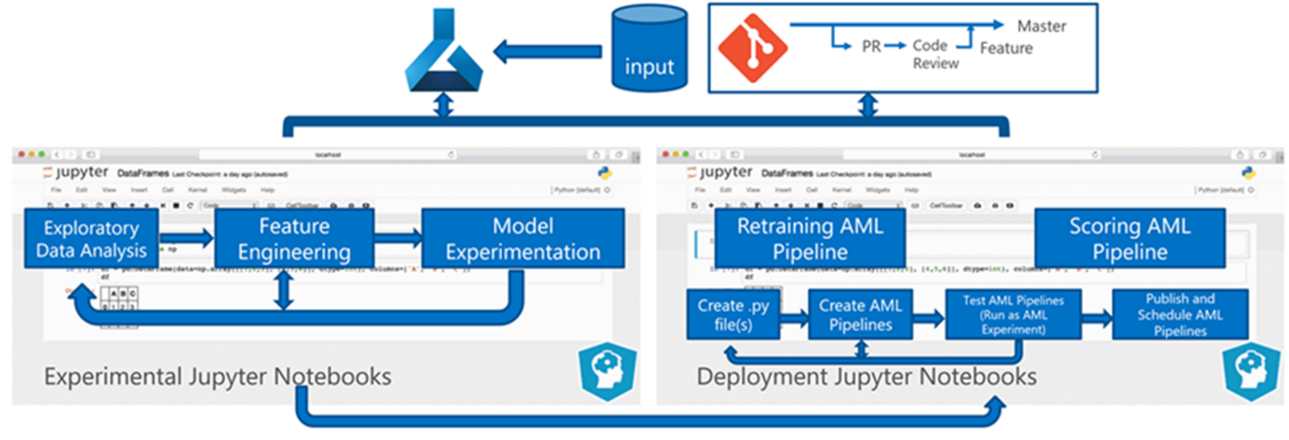
Das Team hat verschiedene Algorithmen getestet. Schließlich hat es ein Ensembledesign aus dem Linearen Regressionsmodell „LASSO“ und einem neuronalen Netz mit kategorischen Einbettungen ausgewählt. Das Team hat das gleiche Modell verwendet, das durch die Menge an Produkten definiert ist, die der Kunde am Standort speichern kann, und zwar sowohl für große als auch für kleine Geschäfte. Das Team unterteilte das Modell weiter in Produkte mit kurzer und langer Lagerdauer.
Datenanalysten trainieren die Machine Learning-Modelle, wenn das Team neuen Code veröffentlicht und neue Daten verfügbar sind. Das Training erfolgt in der Regel im wöchentlichen Rhythmus. Folglich umfasst jede Verarbeitung eine große Datenmenge. Da das Team diese Daten aus vielen Quellen in unterschiedlichen Formaten erfasst, ist eine Aufbereitung erforderlich, um die Daten in ein verwendbares Format zu versetzen, bevor sie von Datenanalysten verarbeitet werden können. Diese Datenaufbereitung erfordert einen erheblichen manuellen Aufwand, und das CSE-Team identifizierte sie als einen primären Kandidaten für die Automatisierung.
Wie bereits erwähnt haben die Datenanalysten experimentelle Azure Machine Learning-Modelle entwickelt und in Phase 1 der Pilotstudie auf eine einzelne Vertriebsregion angewendet, um die Nützlichkeit dieses Prognoseansatzes auszuwerten. Dem CSE-Team zufolge konnte in der Pilotstudie ein signifikanter Anstieg der Verkäufe beobachtet werden. Dieser Erfolg rechtfertigte es, die Lösung in Phase 2 auf das volle Produktionsniveau zu bringen, beginnend mit 14 geografischen Regionen und Tausenden von Geschäften. Das Team kann dann dasselbe Muster verwenden, um zusätzliche Regionen hinzuzufügen.
Das Pilotmodell diente als Grundlage für die hochskalierte Lösung, das CSE-Team wusste jedoch, dass das Modell fortlaufend weitere Optimierungen benötigt, damit seine Leistung gesteigert werden kann.
MLOps-Lösung
Da MLOps-Konzepte reif sind, entdecken Teams häufig Herausforderungen beim Zusammenführen der Datenwissenschaft und DevOps-Fachrichtungen. Der Grund dafür ist, dass die wichtigsten Akteure in den Disziplinen, Softwareingenieuren und Datenwissenschaftlern mit unterschiedlichen Fähigkeiten und Prioritäten arbeiten.
Aber es gibt Ähnlichkeiten, auf denen man aufbauen kann. MLOps ist wie auch DevOps ein Entwicklungsprozess, der von einer Toolkette implementiert wird. Die MLOps-Toolkette umfasst unter anderem Folgendes:
- Versionskontrolle
- Codeanalyse
- Buildautomatisierung
- Continuous Integration
- Testen von Frameworks und Automatisierung
- In CI/CD-Pipelines integrierte Compliancerichtlinien
- Bereitstellungsautomatisierung
- Überwachung
- Notfallwiederherstellung und Hochverfügbarkeit
- Paket- und Containerverwaltung
Wie bereits erwähnt nutzt die Lösung den vorhandenen DevOps-Leitfaden, aber sie wird erweitert, um eine ausgereifte MLOps-Implementierung zu erstellen, die die Anforderungen des Kundenunternehmens und der Data Science-Community erfüllt. MLOps baut auf DevOps-Leitfäden auf, mit den folgenden zusätzlichen Anforderungen:
- Daten-/Modellversionsverwaltung ist nicht das Gleiche wie die Codeversionsverwaltung: Es muss eine Versionsverwaltung von Datasets geben, wenn sich das Schema und die Ursprungsdaten ändern.
- Anforderungen an den digitalen Überwachungspfad: Verfolgen Sie alle Änderungen nach, wenn Sie mit Code und Kundendaten arbeiten.
- Generalisierung: Bei der Wiederverwendung unterscheiden sich Modelle von Code, da Datenanalysten Modelle basierend auf Eingabedaten und -szenarien optimieren müssen. Wenn Sie ein Modell für ein neues Szenario wiederverwenden möchten, müssen Sie es möglicherweise optimieren/übertragen/weitere Informationen dazu erhalten. Sie benötigen die Trainingspipeline.
- Veraltete Modelle: Modelle veralten im Laufe der Zeit, und Sie müssen daher in der Lage sein, sie bei Bedarf neu zu trainieren, um sicherzustellen, dass sie in der Produktion nicht an Relevanz verlieren.
MLOps-Herausforderungen
Unausgereifter MLOps-Standard
Das Standardmuster für MLOps ist noch in der Entwicklung. Eine Lösung wird in der Regel von Grund auf neu erstellt und an die Anforderungen eines bestimmten Kunden oder Benutzers angepasst. Das CSE-Team hat diese Lücke erkannt und versucht, die bewährten Methoden von DevOps in diesem Projekt anzuwenden. Es hat den DevOps-Prozess erweitert, um den zusätzlichen Anforderungen von MLOps gerecht zu werden. Der vom Team entwickelte Prozess ist ein brauchbares Beispiel dafür, wie ein MLOps-Standardmuster aussehen sollte.
Unterschiede bei Fertigkeiten
Softwareentwickler und Datenanalysten haben individuelle Fertigkeiten, die sie im Team einbringen. Diese unterschiedlichen Fertigkeiten erschweren die Suche nach einer Lösung, die allen Anforderungen gerecht wird. Es ist wichtig, einen gut verständlichen Workflow für die Modellbereitstellung zu entwickeln, vom Experimentieren bis hin zur Produktion. Jedes Teammitglied muss wissen, wie es Änderungen in das System integrieren kann, ohne den MLOps-Prozess zu unterbrechen.
Verwalten mehrerer Modelle
Es ist häufig erforderlich, dass mehrere Modelle für schwierige Machine Learning-Szenarien gelöst werden müssen. Eine der Herausforderungen von MLOps besteht darin, diese Modelle zu verwalten. Dazu zählt u. a. Folgendes:
- Es gibt ein kohärentes Versionsverwaltungsschema.
- Kontinuierliche Evaluierung und Überwachung aller Modelle.
Eine nachvollziehbare Herkunft von Code und Daten ist ebenfalls erforderlich, um Modellprobleme zu diagnostizieren und reproduzierbare Modelle zu erstellen. Die Investition in benutzerdefinierte Dashboards kann sinnvoll sein, um die Leistung von bereitgestellten Modellen und den Zeitpunkt erforderlicher Eingriffe zu ermitteln. Das Team hat solche Dashboards für dieses Projekt erstellt.
Erforderliche Datenaufbereitung
Daten, die mit diesen Modellen verwendet werden, stammen aus vielen privaten und öffentlichen Quellen. Da die ursprünglichen Daten nicht organisiert sind, kann das Machine Learning-Modell die Daten im unformatierten Zustand nicht verwenden. Ein Datenanalyst muss die Daten in ein Standardformat aufbereiten, damit das Machine Learning-Modell genutzt werden kann.
Ein großer Teil des Pilottests konzentrierte sich auf die Aufbereitung der Rohdaten, damit das Machine Learning-Modell sie verarbeiten kann. In einem MLOps-System muss das Team diesen Prozess automatisieren und die Ausgaben nachverfolgen.
MLOps-Reifegradmodell
Der Zweck des MLOps-Reifegradmodells besteht darin, die Prinzipien und Praktiken zu verdeutlichen und Lücken in einer MLOps-Implementierung zu identifizieren. Dies ist auch eine Möglichkeit, einem Kunden zu zeigen, wie die MLOps-Funktion inkrementell erweitert werden kann, anstatt ihn gleichzeitig mit allem zu überfordern. Der Kunde sollte es als Leitfaden für Folgendes verwenden:
- Schätzen des Umfangs der Arbeit für das Projekt
- Festlegen von Erfolgskriterien
- Identifizieren der Ergebnisse.
Das MLOps-Reifegradmodell umfasst fünf Ebenen technischer Funktionen:
| Ebene | BESCHREIBUNG |
|---|---|
| 0 | Keine Vorgänge |
| 1 | DevOps, aber kein MLOps |
| 2 | Automatisiertes Training |
| 3 | Automatisierte Modellimplementierung |
| 4 | Automatisierte Vorgänge (vollständiges MLOps) |
Die aktuelle Version des MLOps-Reifegradmodells finden Sie im Artikel MLOps-Reifegradmodell.
MLOps-Prozessdefinition
MLOps umfasst alle Aktivitäten von der Erfassung der Rohdaten bis zur Bereitstellung der Modellausgabe, auch Bewertung genannt:
- Datenaufbereitung
- Modelltraining
- Testen und Auswerten des Modells
- Builddefinition und Pipeline
- Releasepipeline
- Bereitstellung
- Bewertung
Grundlegender Machine Learning-Prozess
Der grundlegende Machine Learning-Prozess ähnelt der herkömmlichen Softwareentwicklung, aber es gibt bedeutende Unterschiede. Dieses Diagramm veranschaulicht die wichtigsten Schritte im Machine Learning-Prozess:
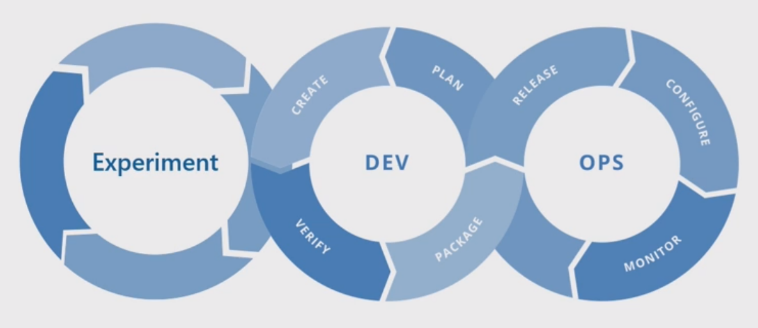
Die Experimentphase ist einzigartig für den Data Science-Lebenszyklus, der widerspiegelt, wie Datenwissenschaftler traditionell ihre Arbeit erledigen. Sie unterscheidet sich von der Art und Weise, wie Codeentwickler ihre Arbeit verrichten. Das folgende Diagramm veranschaulicht den Lebenszyklus im Detail.
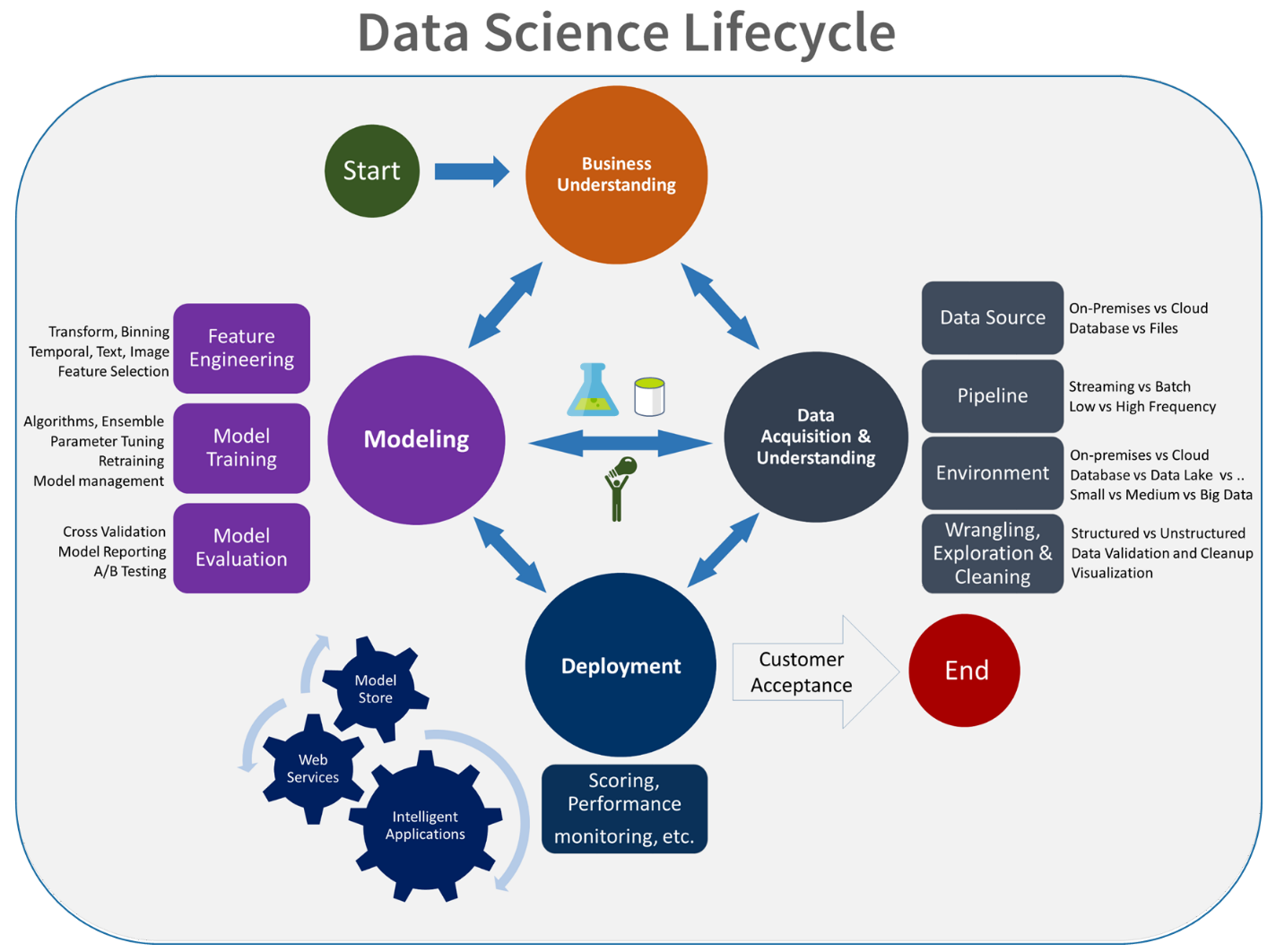
Die Integration dieses Datenentwicklungsprozesses in MLOps stellt eine Herausforderung dar. Hier sehen Sie das Muster, das das Team verwendet hat, um den Prozess in ein Format zu integrieren, das von MLOps unterstützt werden kann:
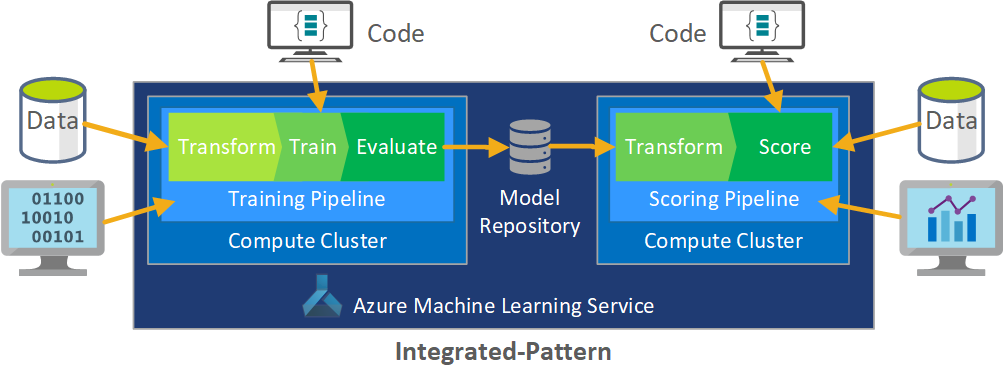
Die Rolle von MLOps besteht darin, einen koordinierten Prozess zu erstellen, mit dem größere CI/CD-Umgebungen, die in Systemen auf Produktionsebene üblich sind, effizient unterstützt werden. Konzeptionell muss das MLOps-Modell alle Prozessanforderungen von Experimenten bis hin zur Bewertung einschließen.
Das CSE-Team hat den MLOps-Prozess optimiert, damit er die spezifischen Anforderungen des Kunden erfüllt. Die wichtigste Anforderung war die Notwendigkeit, eine Batchverarbeitung anstelle einer Echtzeitverarbeitung durchzuführen. Als das Team das hochskalierte System entwickelt hat, wurden einige Mängel erkannt und behoben. Der wichtigste dieser Mängel führte zur Entwicklung einer Brücke zwischen Azure Data Factory und Azure Machine Learning, die das Team in Azure Data Factory als integrierten Connector implementiert hat. Diese Komponenten wurden erstellt, um das erforderliche Auslösen und Überwachen des Status zu vereinfachen, damit die Prozessautomatisierung funktioniert.
Eine weitere grundlegende Änderung bestand darin, dass Datenanalysten in der Lage sein mussten, experimentellen Code aus Jupyter-Notebooks in den MLOps-Bereitstellungsprozess zu exportieren, anstatt Training und Bewertung direkt auszulösen.
Dies ist das endgültige Modell des MLOps-Prozessmodells:
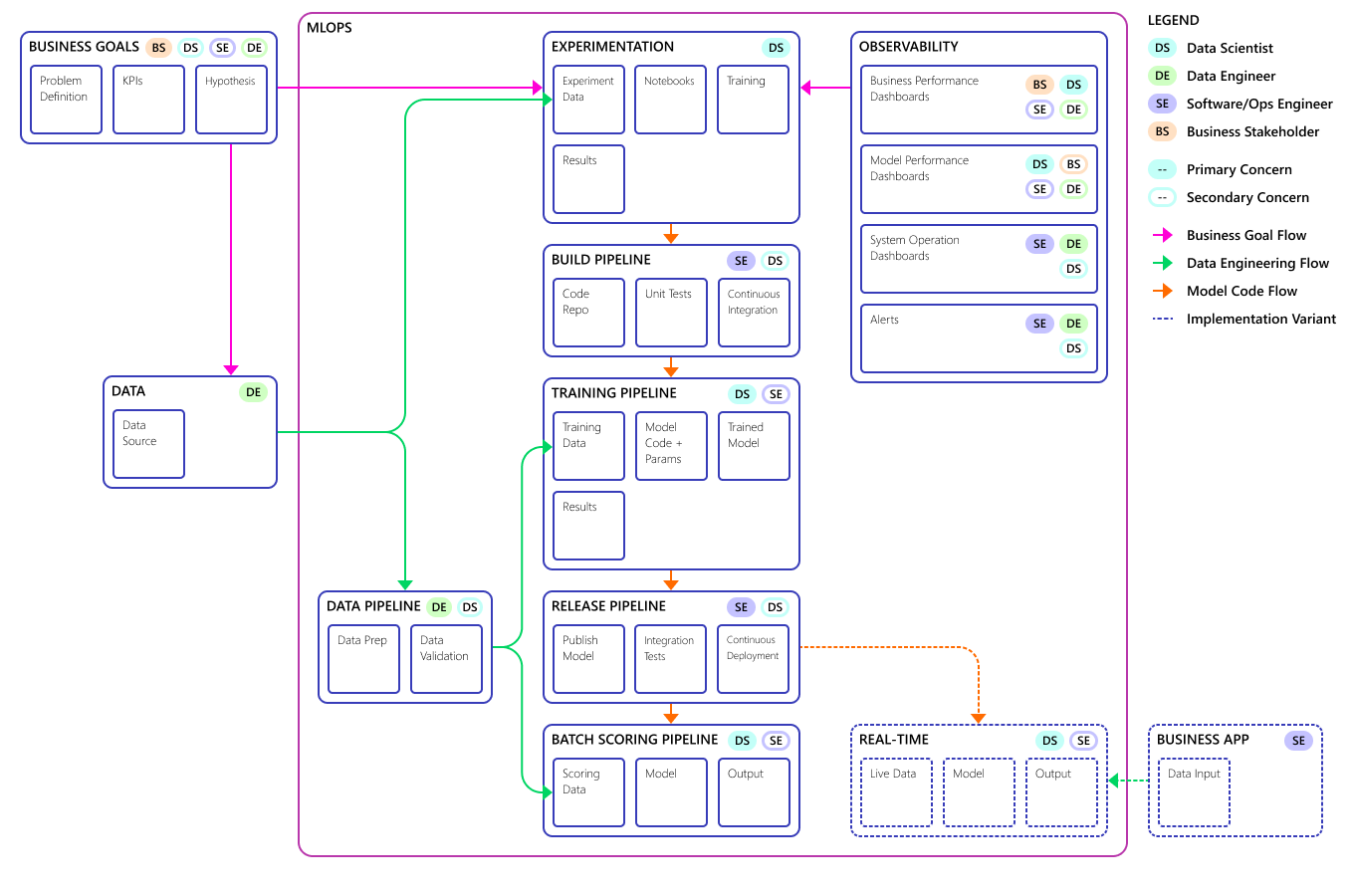
Wichtig
Der letzte Schritt ist die Bewertung. Der Prozess führt das Machine Learning-Modell aus, um Vorhersagen vorzunehmen. So wird die grundlegende Anforderung für geschäftliche Anwendungsfälle für die Nachfrageprognose erfüllt. Das Team bewertet die Qualität der Vorhersagen mithilfe der MAPE, die ein Maß für die Vorhersagegenauigkeit der statistischen Prognosemethoden und eine Verlustfunktion für Regressionsprobleme im maschinellen Lernen ist. In diesem Projekt hat das Team einen MAPE-Wert von <= 45 % als signifikant bewertet.
MLOps-Prozessablauf
Im folgenden Diagramm wird beschrieben, wie Sie CI/CD-Entwicklungs- und-Freigabeworkflows auf den Machine Learning-Lebenszyklus anwenden:
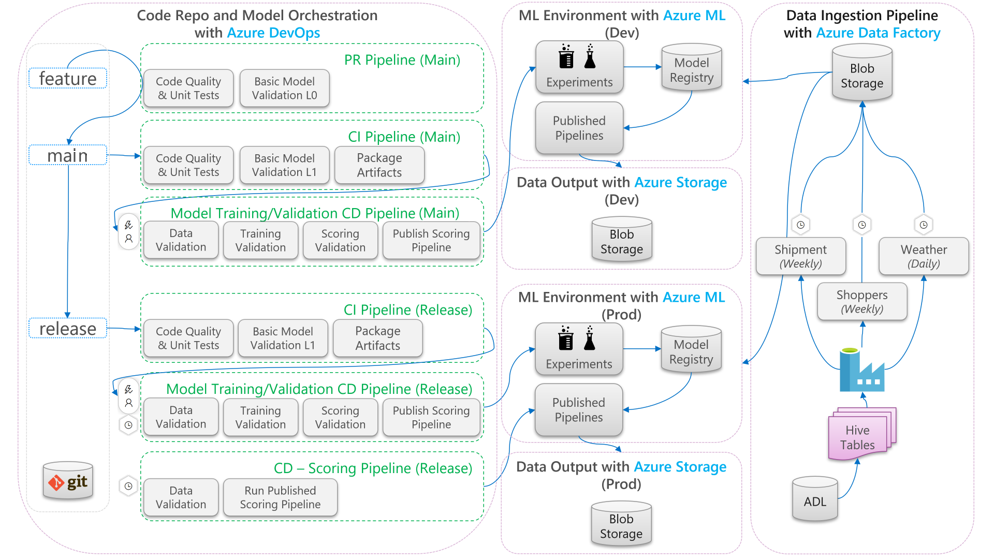
- Wenn ein Pull Request aus einem Featurebranch erstellt wird, führt die Pipeline Codevalidierungstests aus, um die Qualität des Codes über Komponententests und Codequalitätstests zu validieren. Zum Überprüfen des Qualitätsupstreams führt die Pipeline auch grundlegende Modellvalidierungstests aus, um die End-to-End-Trainings- und Bewertungsschritte mit einem Beispielsatz simulierter Daten zu überprüfen.
- Wenn der PR im Mainbranch zusammengeführt wird, führt die CI-Pipeline die gleichen Codevalidierungstests und grundlegenden Modellvalidierungstests mit einer größeren Epoche aus. Die Pipeline verpackt anschließend die Artefakte einschließlich des Codes und der Binärdateien, die in der Machine Learning-Umgebung ausgeführt werden.
- Wenn die Artefakte verfügbar sind, wird eine Modellvalidierungs-CD-Pipeline ausgelöst. Diese führt eine End-to-End-Validierung der Machine Learning-Entwicklungsumgebung aus. Ein Bewertungsmechanismus wird veröffentlicht. Bei einem Batchbewertungsszenario wird eine Bewertungspipeline in der Machine Learning-Umgebung veröffentlicht und ausgelöst, um Ergebnisse zu erzielen. Wenn Sie ein Echtzeitbewertungsszenario verwenden möchten, können Sie eine Web-App veröffentlichen oder einen Container bereitstellen.
- Nachdem ein Meilenstein erstellt und im Releasebranch zusammengeführt wurde, werden die gleiche CI-Pipeline und die Modellvalidierungs-CD-Pipeline ausgelöst. Dieses Mal werden sie für den Code aus dem Releasebranch ausgeführt.
Betrachten Sie den oben gezeigten MLOps-Prozessdatenfluss als Archetypframework für Projekte mit ähnlichen Architekturoptionen.
Codevalidierungstests
Codevalidierungstests für Machine Learning konzentrieren sich auf die Validierung der Qualität der Codebasis. Dabei handelt es sich um das gleiche Konzept wie bei jedem Entwicklungsprojekt, das Codequalitätstests (Linten), Komponententests und die Bestimmung von Code Coverage-Messungen umfasst.
Grundlegende Modellvalidierungstests
Die Modellvalidierung bezieht sich in der Regel auf die Validierung der End-to-End-Prozessschritte, die erforderlich sind, um ein gültiges Machine Learning-Modell zu entwickeln. Es umfasst Schritte wie:
- Datenüberprüfung: stellt sicher, dass die Eingabedaten gültig sind
- Trainingsüberprüfung: stellt sicher, dass das Modell erfolgreich trainiert werden kann
- Bewertungsüberprüfung: stellt sicher, dass das Team das trainierte Modell für die Bewertung mit den Eingabedaten erfolgreich verwenden kann
Die Ausführung all dieser Schritte in der Machine Learning-Umgebung ist kostspielig und zeitaufwändig. Daher führte das Team grundlegende Modellvalidierungstests lokal auf einem Entwicklungscomputer durch. Die oben aufgeführten Schritte wurden ausgeführt und haben Folgendes verwendet:
- Lokales Testdatensatz: Ein, häufig verschleiertes, kleines Dataset, das in das Repository eingecheckt und als Eingabedatenquelle verwendet wird.
- Lokales Flag: ein Flag oder Argument im Code des Modells, das angibt, dass der Code das lokale Ausführen des Datasets vorsieht. Das Flag weist den Code an, alle Aufrufe der Machine Learning-Umgebung zu umgehen.
Das Ziel dieser Validierungstests besteht nicht darin, die Leistung des trainierten Modells zu bewerten. Ziel ist es eher, zu überprüfen, ob der Code für den End-to-End-Prozess eine gute Qualität hat. Es sichert die Qualität des Codes, der upstream gepusht wird, wie z. B. die Einbeziehung von Modellvalidierungstests in den PR- und CI-Build. Dies ermöglicht es Techniker und Datenanalysten, Breakpoints zu Debuggingzwecken in den Code einzufügen.
Modellvalidierungs-CD-Pipeline
Das Ziel der Modellvalidierungspipeline besteht darin, die End-to-End-Modelltrainings- und -bewertungsschritte in der Machine Learning-Umgebung mit reellen Daten zu validieren. Jedes trainierte Modell, das produziert wird, wird der Modellregistrierung hinzugefügt und markiert, um nach Abschluss der Überprüfung eine Promotion zu erwarten. Bei der Batchvorhersage kann die Höherstufung die Veröffentlichung einer Bewertungspipeline umfassen, in der die Pipeline diese Version des Modells verwendet. Für die Echtzeitbewertung kann das Modell markiert werden, um anzugeben, dass es höher gestuft wurde.
Bewertungs-CI/CD-Pipeline
Die Bewertungs-CD-Pipeline gilt für das Batchrückschlussszenario, bei dem derselbe Modellorchestrator als Modellvalidierung die veröffentlichte Bewertungspipeline auslöst.
Entwicklungs- und Produktionsumgebungen im Vergleich
Es empfiehlt sich, die Entwicklungsumgebung (dev) und die Produktionsumgebung (prod) voneinander zu trennen. Durch das Trennen kann das System die Modellvalidierungs-CD-Pipeline und die Bewertungs-CD-Pipeline nach unterschiedlichen Zeitplänen auslösen. Für den beschriebenen MLOps-Ablauf werden Pipelines, die auf den Mainbranch abzielen, in der Entwicklungsumgebung ausgeführt, und die Pipeline für den Releasebranch wird in der Produktionsumgebung ausgeführt.
Codeänderungen und Datenänderungen im Vergleich
In den vorherigen Abschnitten wurde größtenteils besprochen, wie Codeänderungen von der Entwicklung bis zur Freigabe behandelt werden. Bei Datenänderungen sollte jedoch die gleiche Strenge gelten wie bei Codeänderungen, damit die gleiche Validierungsqualität und -konsistenz in der Produktion bereitgestellt werden kann. Bei einem Datenänderungstrigger oder einem Trigger mit Timer kann das System die Modellvalidierungs-CD-Pipeline und die Bewertungs-CD-Pipeline aus dem Modellorchestrator auslösen, um denselben Prozess wie bei Codeänderungen in der Releasebranch-Produktionsumgebung auszuführen.
MLOps-Personas und -Rollen
Eine wichtige Voraussetzung für alle MLOps-Prozesse besteht darin, dass sie die Anforderungen der vielen Benutzer des Prozesses erfüllen. Berücksichtigen Sie diese Benutzer für Designzwecke als einzelne Personas. Für dieses Projekt hat das Team diese Personas wie folgt identifiziert:
- Datenanalyst: erstellt das Machine Learning-Modell und seine Algorithmen
- Techniker
- Datentechniker: verarbeitet die Datenaufbereitung
- Softwareentwickler: verarbeitet die Modellintegration in das Ressourcenpaket und den CI/CD-Workflow
- Vorgänge oder IT: ist für Dateisystemvorgänge zuständig
- Geschäftlicher Projektbeteiligter: befasst sich mit den Prognosen des Machine Learning-Modells und wie gut diese das Unternehmen unterstützen
- Datenendbenutzer: nutzt die Modellausgabe auf eine Weise, die bei Geschäftsentscheidungen hilfreich ist
Das Team musste drei wichtige Punkte beheben, die sich bei den Persona- und Rollenuntersuchungen gezeigt haben:
- Datenanalysten und Data Engineers haben in ihrer Arbeit unterschiedliche Vorgehensweisen und Fähigkeiten. Ein zentraler Punkt im MLOps-Prozessfluss besteht darin, die Zusammenarbeit zwischen Datenanalysten und Datentechniker zu vereinfachen. Dafür müssen sich alle Teammitglieder neue Fertigkeiten aneignen.
- Die wichtigsten Personas müssen vereinheitlicht werden, ohne dass eine ausgeschlossen wird. Eine Möglichkeit hierfür besteht in Folgendem:
- Stellen Sie sicher, dass sie das konzeptionelle Modell für MLOps verstehen.
- Einigen Sie sich auf die Teammitglieder, die zusammenarbeiten werden.
- Legen Sie die Arbeitsrichtlinien fest, um gemeinsame Ziele zu erreichen.
- Wenn der Business-Stakeholder und der Daten-Endbenutzer eine Möglichkeit benötigen, mit der Datenausgabe aus den Modellen zu interagieren, ist eine benutzerfreundliche Benutzeroberfläche die Standardlösung.
Andere Teams stoßen in anderen Machine Learning-Projekten sicher auf ähnliche Punkte, wenn sie eine Hochskalierung für die Produktion durchführen.
MLOps-Lösungsarchitektur
Logische Architektur
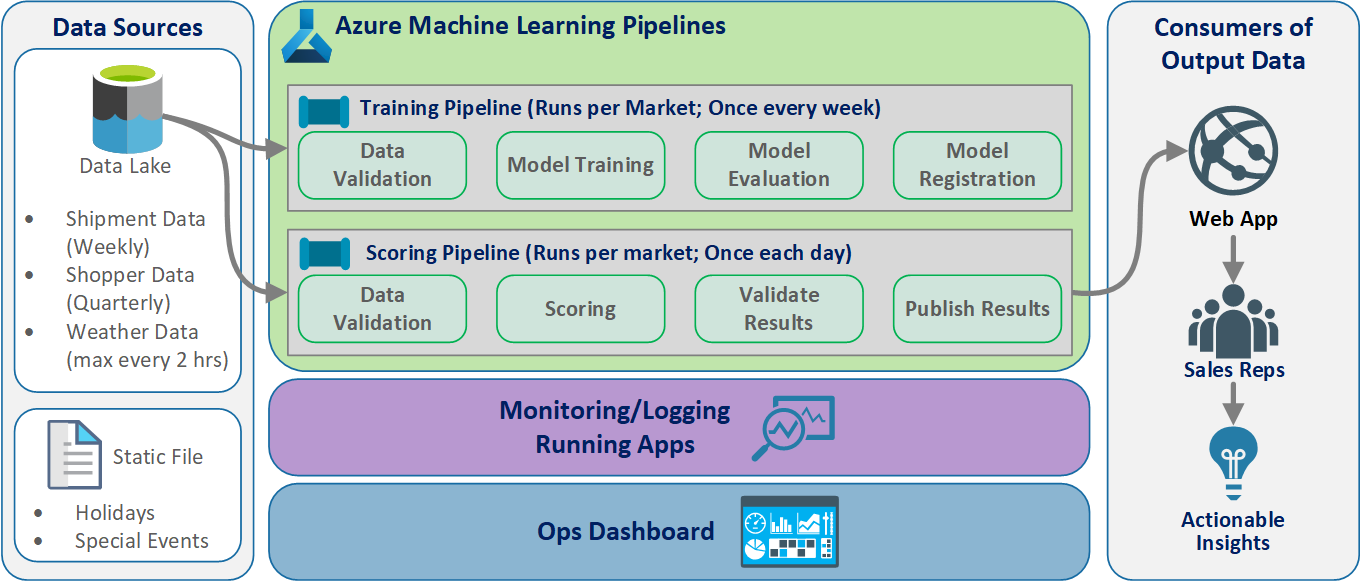
Die Daten stammen aus vielen Quellen in vielen verschiedenen Formaten und werden daher aufbereitet, bevor sie in den Data Lake eingefügt werden. Die Aufbereitung erfolgt mithilfe von Microservices, die als Azure Functions betrieben werden. Die Kunden passen die Microservices an die Datenquellen an und transformieren sie in ein standardisiertes CSV-Format, das von den Trainings- und Bewertungspipelines verwendet werden kann.
Systemarchitektur
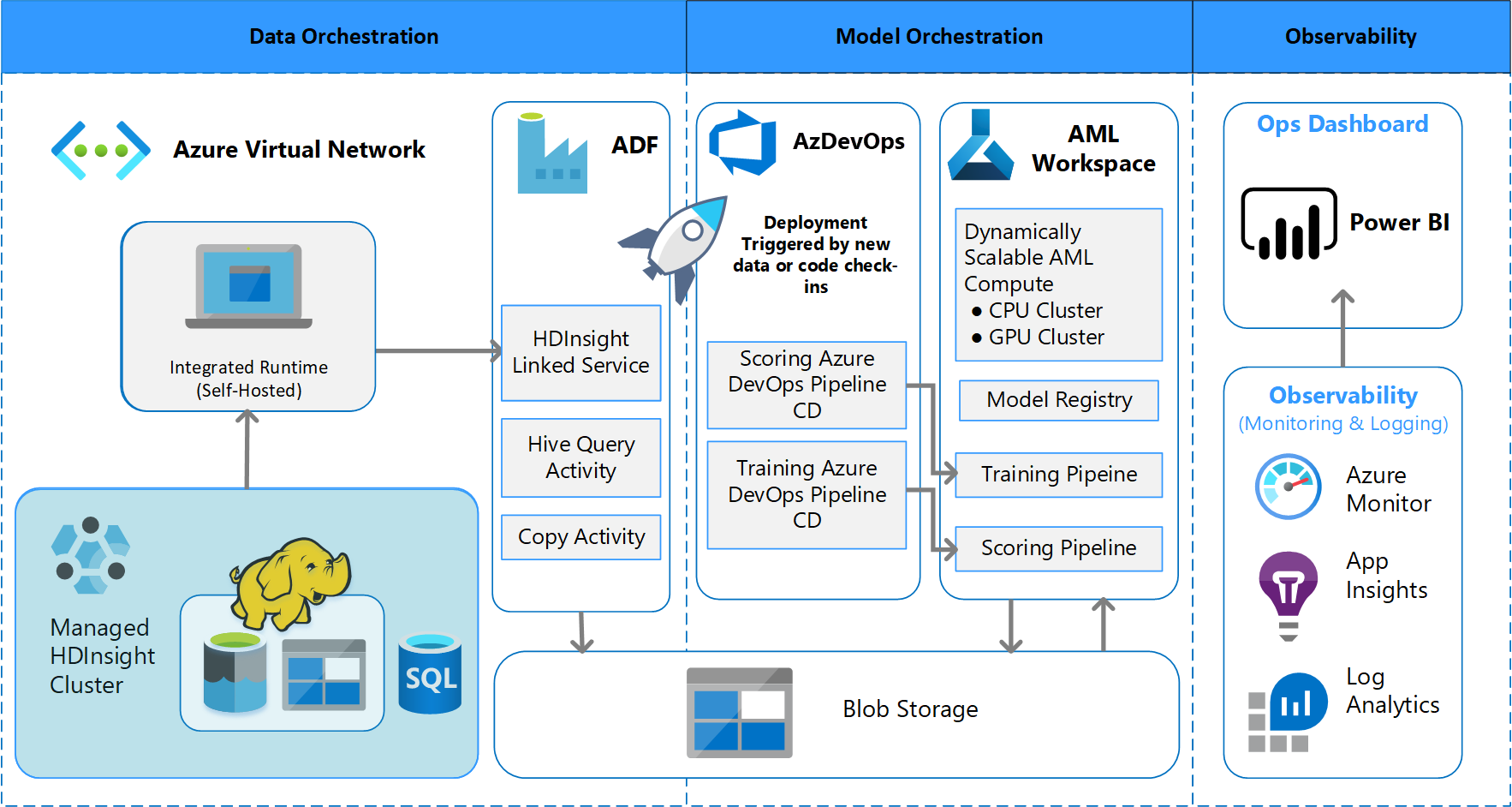
Architektur der Batchverarbeitung
Das Team hat den Architekturentwurf erarbeitet, um ein Schema für die Batchdatenverarbeitung zu unterstützen. Es gibt Alternativen, aber was verwendet wird, muss MLOps-Prozesse unterstützen. Die vollständige Nutzung der verfügbaren Azure-Dienste war eine Entwurfsanforderung. Das folgende Diagramm veranschaulicht diese Architektur:
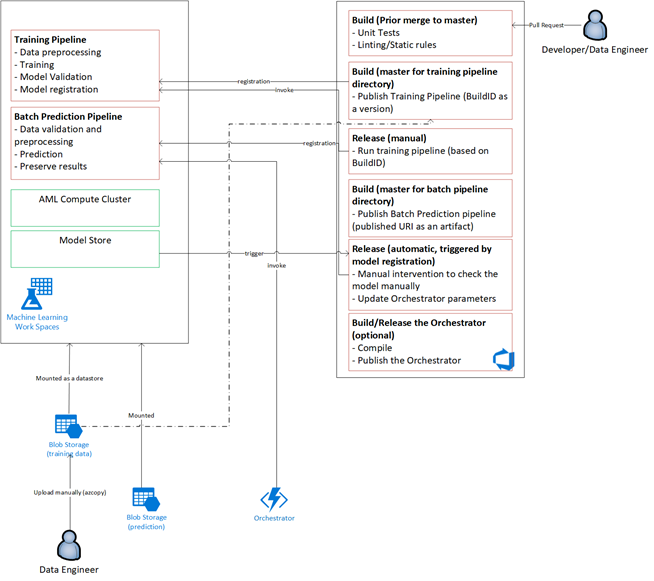
Lösungsübersicht
Azure Data Factory führt Folgendes aus:
- Löst eine Azure-Funktion aus, um die Datenerfassung mit Parametern und einer Azure Machine Learning-Pipelineausführung zu starten.
- Startet eine Durable Function, um den Abschluss der Azure Machine Learning-Pipeline abzufragen.
Benutzerdefinierte Dashboards in Power BI zeigen die Ergebnisse an. Andere Azure-Dashboards, die mit Azure SQL, Azure Monitor und App Insights über das OpenCensus Python-SDK verbunden sind, verfolgen Azure-Ressourcen nach. Diese Dashboards enthalten Informationen über den Zustand des Machine Learning-Systems. Außerdem liefern sie Daten, die der Kunde für Prognosen zu Produktbestellungen verwendet.
Modellorchestrierung
Die Modellorchestrierung führt folgende Schritte aus:
- Wenn ein Pull Request übermittelt wird, löst DevOps eine Codevalidierungspipeline aus.
- Diese Pipeline führt Komponententests, Codequalitätstests und Modellvalidierungstests aus.
- Beim Zusammenführen in den Mainbranch werden dieselben Codevalidierungstests ausgeführt, und DevOps verpackt die Artefakte.
- Die DevOps-Sammlung von Artefakten löst für Azure Machine Learning Folgendes aus:
- Datenüberprüfung
- Trainingsüberprüfung
- Bewertungsüberprüfung
- Nach Abschluss der Prüfung wird die letzte Bewertungspipeline ausgeführt.
- Das Ändern von Daten und das Übermitteln eines neuen PR löst die Validierungspipeline erneut aus, gefolgt von der endgültigen Bewertungspipeline.
Ermöglichen von Experimenten
Wie bereits erwähnt unterstützt der herkömmliche Data Science-Machine Learning-Lebenszyklus den MLOps-Prozess ohne Änderungen nicht. Dabei werden verschiedene Arten von manuellen Tools und Experimente, Validierung, Paketerstellung und Modellübergabe verwendet, die für einen effektiven CI/CD-Prozess nicht problemlos skaliert werden können. MLOps erfordert ein hohes Maß an Prozessautomatisierung. Unabhängig davon, ob ein neues Machine Learning-Modell entwickelt oder ein altes Modell geändert wird, ist es erforderlich, den Lebenszyklus des Machine Learning-Modells zu automatisieren. In Phase 2 verwendete das Team Azure DevOps, um Azure Machine Learning-Pipelines für Trainingsaufgaben zu orchestrieren und erneut zu veröffentlichen. Der zeitintensive Mainbranch führte grundlegende Tests von Modellen durch und pushte stabile Releases über den Releasebranch mit langer Laufzeit.
Die Quellcodeverwaltung wird zu einem wichtigen Teil dieses Prozesses. Git ist das Versionskontrollsystem, das zum Nachverfolgen von Notebook- und Modellcode verwendet wird. Außerdem wird die Prozessautomatisierung unterstützt. Der grundlegende Workflow, der für die Verwendung der Quellcodeverwaltung implementiert wird, wendet folgende Prinzipien an:
- Verwenden Sie die formale Versionsverwaltung für Code und Datasets.
- Verwenden Sie einen Branch für die neue Codeentwicklung, bis der Code vollständig entwickelt und überprüft ist.
- Nachdem der neue Code überprüft wurde, kann er in den Mainbranch zusammengeführt werden.
- Für eine Version wird ein permanent versionierter Branch erstellt, der vom Mainbranch getrennt ist.
- Verwenden Sie die Versions- und Quellcodeverwaltung für die Datasets, die Sie für das Training oder die Verwendung aufbereitet haben, sodass Sie die Integrität der einzelnen Datasets beibehalten können.
- Verwenden Sie die Quellcodeverwaltung, um Ihre Jupyter Notebook-Experimente nachzuverfolgen.
Integration in Datenquellen
Datenanalysten verwenden viele Rohdatenquellen und verarbeitete Datasets, um verschiedene Machine Learning-Modelle zu testen. Die Menge an Daten in einer Produktionsumgebung kann enorm sein. Damit die Datenanalysten verschiedene Modelle testen können, müssen sie Verwaltungstools wie Azure Data Lake verwenden. Die Anforderung einer formalen Identifizierung und Versionskontrolle gilt für alle Rohdaten, vorbereitete Datasets und Machine Learning-Modelle.
Im Projekt bedingten die Datenwissenschaftler die folgenden Daten für die Eingabe in das Modell:
- Historische wöchentliche Versanddaten seit Januar 2017
- Historische und prognostizierte tägliche Wetterdaten für jede Postleitzahl
- Shopper-Daten für jede Speicher-ID
Integration der Quellcodeverwaltung
Damit Datenanalysten bewährte Methoden in der Entwicklung anwenden können, müssen die Tools, die sie benötigen, in Quellcodeverwaltungssysteme wie GitHub integriert werden. Dies ermöglicht die Versionsverwaltung von Machine Learning-Modellen, die Zusammenarbeit zwischen Teammitgliedern und die Notfallwiederherstellung, wenn die Teams einen Datenverlust oder einen Systemausfall erfahren.
Unterstützung von Modellensembles
Der Modellentwurf in diesem Projekt war ein Ensemblemodell. Das heißt, dass Datenanalysten im endgültigen Modellentwurf viele Algorithmen verwendet haben. In diesem Fall haben die Modelle denselben grundlegenden Algorithmusentwurf genutzt. Der einzige Unterschied bestand darin, dass sie unterschiedliche Trainings- und Bewertungsdaten verwendet haben. Die Modelle verwendeten die Kombination aus einem linearen LASSO-Regressionsalgorithmus und eine neuronalen Netz.
Das Team hat außerdem eine Option untersucht, mit der der Prozess so weit fortgeführt werden kann, bis die Ausführung vieler Echtzeitmodelle in der Produktionsumgebung mit einer bestimmten Anforderung unterstützt wird. Diese Option kam in diesem Projekt jedoch nicht zum Einsatz. Diese Option kann die Verwendung von Ensemblemodellen in A/B-Tests und verschachtelten Experimenten ermöglichen.
Endbenutzeroberfläche
Das Team hat Endbenutzeroberflächen für Einblicke, Überwachung und Instrumentierung entwickelt. Wie bereits erwähnt zeigen Dashboards die Machine Learning-Modelldaten visuell an. Diese Dashboards zeigen die folgenden Daten in einem benutzerfreundlichen Format an:
- Pipelineschritte, einschließlich vor der Verarbeitung der Eingabedaten.
- Zum Überwachen der Integrität der Machine Learning-Modellverarbeitung:
- Welche Metriken erfassen Sie aus dem bereitgestellten Modell?
- MAPE: Mean Absolute Percentage Error (Mittlerer absoluter prozentualer Fehler, die zentrale Metrik für die Gesamtleistung. Zielen Sie auf einen MAPE-Wert von <= 0,45 pro Modell ab.)
- RMSE 0: Root Mean Squared Error (mittlere quadratische Gesamtabweichung, RMSE), beim tatsächlichen Zielwert = 0.
- RMSE All: RMSE für das gesamte Dataset.
- Wie beurteilen Sie, ob das Modell in der Produktion erwartungsgemäß funktioniert?
- Gibt es eine Möglichkeit, zu erkennen, ob Produktionsdaten zu stark von den erwarteten Werten abweichen?
- Weist das Modell in der Produktion eine schlechte Leistung auf?
- Haben Sie einen Failoverzustand?
- Welche Metriken erfassen Sie aus dem bereitgestellten Modell?
- Verfolgen Sie die Qualität der verarbeiteten Daten nach.
- Zeigen Sie die Bewertung/Vorhersagen an, die vom Machine Learning-Modell erstellt wurden.
Die Anwendung füllt die Dashboards der Art der Daten und der Datenverarbeitung und Analyse entsprechend auf. Daher muss das Team das exakte Layout der Dashboards für die einzelnen Anwendungsfälle entwerfen. Hier finden Sie zwei Beispieldashboards:
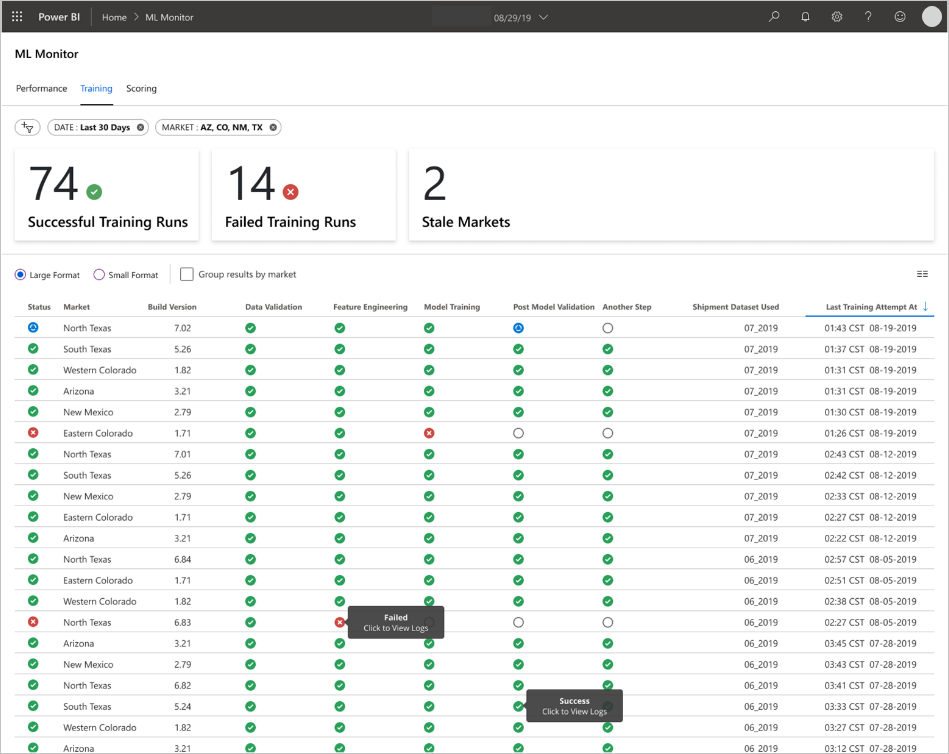
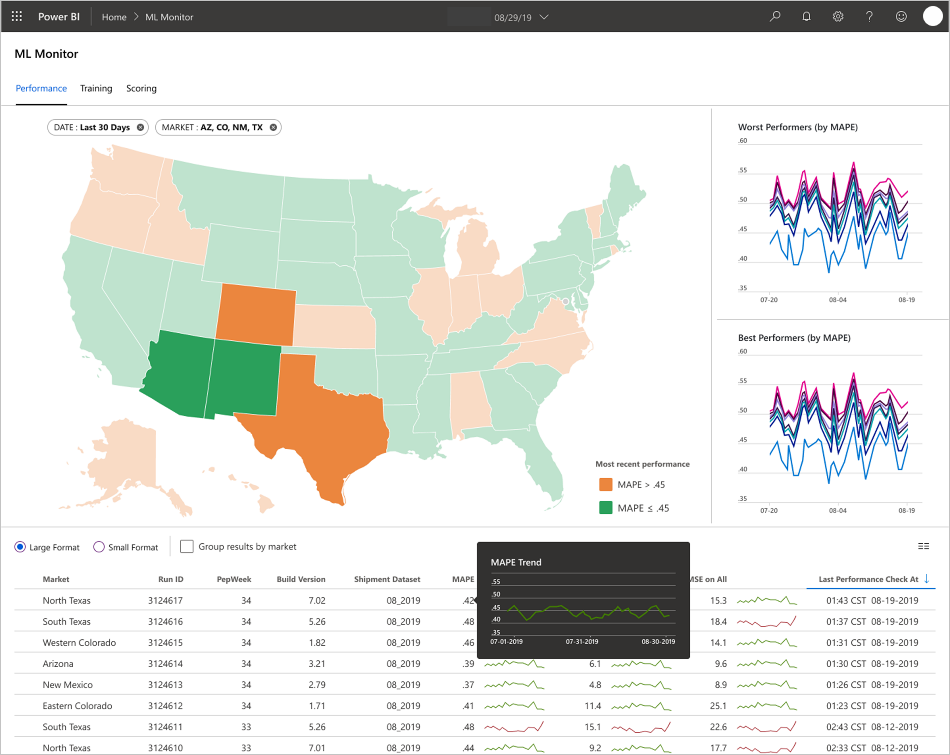
Die Dashboards wurden so konzipiert, dass sie dem Endnutzer der Vorhersagen des Machine Learning-Modells leicht verwertbare Informationen liefern.
Hinweis
Bei veralteten Modellen handelt es sich um Bewertungsausführungen, bei denen Datenanalysten das Modell trainiert haben, das seit der Bewertung mehr als 60 Tage lang verwendet wurde. Die Seite Bewertung des Dashboards zur ML-Überwachung zeigt diese Integritätsmetrik an.
Komponenten
- Azure Machine Learning
- Azure Blob Storage
- Azure Data Lake-Speicher
- Azure Pipelines
- Azure Data Factory
- Azure Functions für Python
- Azure Monitor
- Azure SQL-Datenbank
- Azure-Dashboards
- Power BI
Überlegungen
Im Folgenden finden Sie eine Liste mit Punkten, die Sie bedenken sollten. Sie basieren auf den Erfahrungen, die das CSE-Team während des Projekts gemacht hat.
Überlegungen zur Umgebung
- Datenwissenschaftler entwickeln die meisten ihrer Machine Learning-Modellen mithilfe von Python, oft beginnend mit Jupyter-Notebooks. Es kann eine Herausforderung sein, diese Notebooks als Produktionscode zu implementieren. Jupyter Notebooks sind eher ein experimentelles Tool, während Python-Skripts für die Produktion besser geeignet sind. Teams müssen häufig Zeit aufwenden, um den Modellerstellungscode in Python-Skripts umzugestalten.
- Machen Sie Kunden, die noch nicht mit DevOps und maschinellem Lernen vertraut sind, darauf aufmerksam, dass Experimente und Produktion eine unterschiedliche Strenge erfordern, weshalb es sich empfiehlt, beide Bereiche zu trennen.
- Tools wie der Azure Machine Learning Visual Designer oder AutoML können effektiv sein, um grundlegende Modelle zu erstellen, während der Kunde DevOps-Standardpraktiken für den Rest seiner Lösung anwendet.
- Azure DevOps verfügt über Plug-Ins, die in Azure Machine Learning integriert werden können, um die Pipelineschritte auszulösen. Das MLOpsPython-Repository enthält einige Beispiele für solche Pipelines.
- Maschinelles Lernen erfordert für das Training häufig leistungsstarke GPU-Computer (Graphics Processing Unit). Wenn der Kunde nicht bereits über eine solche Hardware verfügt, ist die Verwendung von Azure Machine Learning Compute-Clustern eine effektive Möglichkeit für die schnelle Bereitstellung kostengünstiger, leistungsfähiger Hardware, die automatisch skaliert wird. Wenn für einen Kunden erweiterte Sicherheits- und/oder Überwachungsanforderungen bestehen, gibt es andere Optionen, wie etwa Standard-VMs, Databricks oder lokales Compute.
- Damit ein Kunde erfolgreich ist, benötigen die Modellerstellungsteams (Datenanalysten) und die Bereitstellungsteams (DevOps-Techniker) einen effizienten Kommunikationskanal. Dies kann mit täglichen Stand-up-Meetings oder mit einem formalen Onlinechatdienst erreicht werden. Beide Ansätze helfen bei der Integration ihrer Entwicklungsanstrengungen in einem MLOps-Framework.
Überlegungen zur Datenvorbereitung
Die einfachste Lösung für die Verwendung von Azure Machine Learning ist das Speichern von Daten in einer unterstützten Datenspeicherlösung. Tools wie Azure Data Factory sind effektiv für das Weiterleiten von Daten zu und von diesen Speicherorten nach einem Zeitplan.
Es ist wichtig, dass Kunden einen Rhythmus für das Erfassen zusätzlicher Daten für das erneute Trainieren einrichten, damit ihre Modelle auf dem aktuellen Stand sind. Wenn sie noch über keine Datenpipeline verfügen, ist das Erstellen einer solchen Pipeline ein wichtiger Bestandteil der gesamten Lösung. Die Verwendung einer Lösung wie z. B. Datasets in Azure Machine Learning kann für die Versionsverwaltung von Daten nützlich sein, um die Nachverfolgbarkeit von Modellen zu erleichtern.
Überlegungen zum Trainieren und Auswerten des Modells
Für Kunden, die gerade erst in das maschinelle Lernen einsteigen, kann eine vollständige MLOps-Pipeline etwas zu viel sein. Bei Bedarf können sie mit Azure Machine Learning die Nachverfolgung von Experimentausführungen und die Verwendung Azure Machine Learning Compute als Trainingsziel vereinfachen. Diese Optionen stellen eine einfachere Einstiegslösung dar, um mit der Integration von Azure-Diensten zu beginnen.
Der Übergang von einem Notebook-Experiment zu wiederholbaren Skripts ist immer noch ein ziemlich schwieriger Übergang für viele Datenanalysten. Je früher sie den Trainingscode in Python-Skripts schreiben können, desto einfacher ist es, dass sie mit der Versionsverwaltung ihres Trainingscodes beginnen und das erneute Trainieren aktivieren.
Dies ist jedoch nicht die einzige Möglichkeit. Databricks unterstützt das Planen von Notebooks als Aufträge. Nach den derzeitigen Erfahrungen unserer Kunden ist dieser Ansatz jedoch aufgrund von Testbeschränkungen nur schwer mit vollständigen DevOps-Praktiken zu kombinieren.
Es ist auch wichtig, zu verstehen, welche Metriken verwendet werden, damit ein Modell als Erfolg gelten kann. Die Genauigkeit ist alleine oft nicht ausreichend, um die Gesamtleistung eines Modells im Vergleich zu einem anderen zu bestimmen.
Computeaspekte
- Kunden sollten die Verwendung von Containern in Erwägung ziehen, um ihre Computeumgebungen zu standardisieren. Fast alle Azure Machine Learning Compute-Ziele unterstützen die Verwendung von Docker. Wenn ein Container die Abhängigkeiten behandelt hat, kann die Reibung erheblich reduziert werden, insbesondere wenn das Team viele Berechnungsziele verwendet.
Überlegungen zur Modellbereitstellung
- Das Azure Machine Learning-SDK bietet eine Option zur direkten Bereitstellung im Azure Kubernetes Service über ein registriertes Modell, das die Grenzen in Bezug darauf festlegt, welche Sicherheit und welche Metriken vorhanden sind. Es gibt möglicherweise eine einfachere Lösung, mit der Kunden ihr Modell testen können, aber es ist am besten, eine stabilere Bereitstellung für AKS für Produktionsworkloads zu entwickeln.
Nächste Schritte
- Weitere Informationen zu MLOps
- MLOps unter Azure
- Azure Monitor-Visualisierungen
- Machine Learning-Lebenszyklus
- Azure DevOps-Erweiterung für maschinelles Lernen
- Azure Machine Learning-CLI
- Auslösen von Anwendungen, Prozessen oder CI/CD-Workflows basierend auf Azure Machine Learning-Ereignissen
- Einrichten von Modelltraining und Bereitstellung mit Azure DevOps