Kontinuierliche Überprüfung mit Azure Auslastungstest und Azure Chaos Studio
Da cloudnative Anwendungen und Dienste immer komplexer werden, kann die Bereitstellung von Änderungen und neuen Versionen für sie eine Herausforderung darstellen. Ausfälle treten häufig durch fehlerhafte Bereitstellungen oder Veröffentlichungen auf. Aber auch nach der Bereitstellung können Fehler auftreten, wenn eine Anwendung mit dem Empfang von echtem Datenverkehr beginnt, insbesondere in komplexen Workloads, die in hoch verteilten mehrinstanzenfähigen Cloudumgebungen ausgeführt werden und von mehreren Entwicklungsteams verwaltet werden. Diese Umgebungen benötigen mehr Resilienzmaßnahmen wie Wiederholungslogik und automatische Skalierung, die normalerweise während des Entwicklungsprozesses schwierig getestet werden können.
Aus diesem Grund ist eine kontinuierliche Überprüfung in einer Umgebung, die der Produktionsumgebung ähnelt, wichtig, damit Sie Probleme oder Fehler so früh wie möglich im Entwicklungszyklus finden und beheben können. Workloadteams sollten frühzeitig im Entwicklungsprozess (nach links) testen und Entwickler*innen die Durchführung von Tests in einer Umgebung erleichtern, die sich in der Nähe der Produktionsumgebung befindet.
Unternehmenskritische Workloads haben hohe Verfügbarkeitsanforderungen, mit Zielen von 3, 4 oder 5 neun (99,9 %, 99,99 % oder 99,99 % bzw. 99,999 %). Es ist entscheidend, strenge automatisierte Tests zu implementieren, um diese Ziele zu erreichen.
Die kontinuierliche Überprüfung hängt von jeder Workload und von architektonischen Merkmalen ab. Dieser Artikel enthält einen Leitfaden zum Vorbereiten und Integrieren von Azure Load Testing und Azure Chaos Studio in einen regelmäßigen Entwicklungszyklus.
1 – Definieren von Tests basierend auf erwarteten Schwellenwerten
Kontinuierliche Tests sind ein komplexer Prozess, der eine ordnungsgemäße Vorbereitung erfordert. Es muss klar sein, was getestet wird und welche Ergebnisse erwartet werden.
In PE:06 – Empfehlungen für Leistungstests und RE:08 – Empfehlungen zum Entwerfen einer Zuverlässigkeitsteststrategie empfiehlt das Azure Well-Architected Framework, dass Sie zunächst wichtige Szenarien, Abhängigkeiten, erwartete Nutzung, Verfügbarkeit, Leistung und Skalierbarkeitsziele identifizieren.
Anschließend sollten Sie eine Reihe messbarer Schwellenwerte definieren, um die erwartete Leistung der wichtigsten Szenarien zu quantifizieren.
Tipp
Beispiele für Schwellenwerte sind die erwartete Anzahl von Benutzeranmeldungen, Anforderungen pro Sekunde für eine bestimmte API und Vorgänge pro Sekunde für einen Hintergrundprozess.
Sie sollten Schwellenwerte verwenden, um ein Integritätsmodell für Ihre Anwendung zu entwickeln, sowohl zum Testen als auch zum Ausführen der Anwendung in der Produktion.
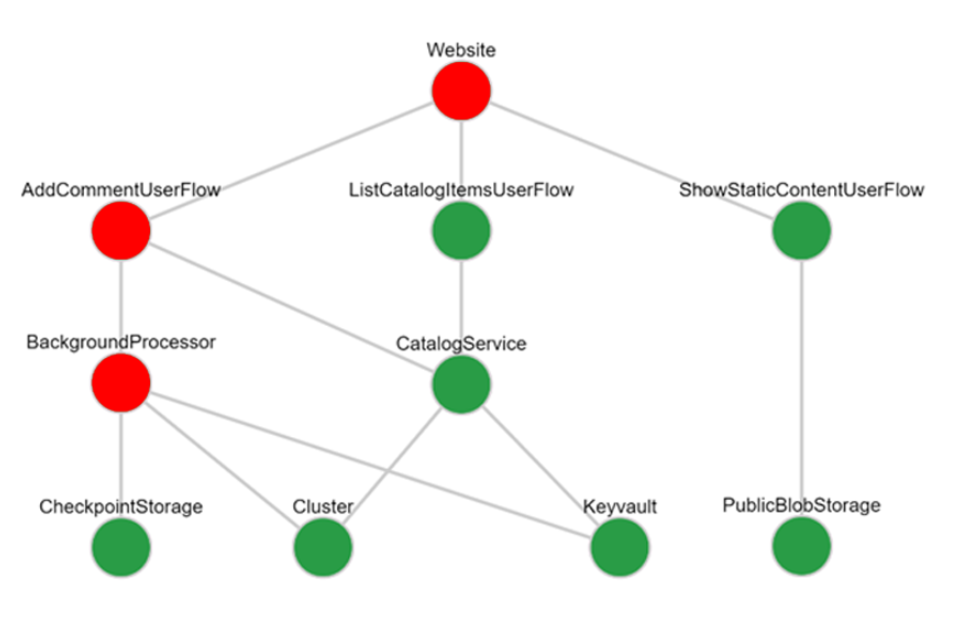
Verwenden Sie als Nächstes die Werte, um einen Auslastungstest zu definieren, der realistischen Datenverkehr zum Testen der grundlegenden Anwendungsleistung, für die Überprüfung der erwarteten Skalierungsvorgänge usw. generiert. Anhaltender künstlicher Benutzerdatenverkehr ist in Vorproduktionsumgebungen erforderlich, da es ohne Verbrauch schwierig ist, Laufzeitprobleme aufzudecken.
Auslastungstests stellen sicher, dass an der Anwendung oder Infrastruktur vorgenommene Änderungen keine Probleme verursachen und das System weiterhin die erwarteten Leistungs- und Testkriterien erfüllt. Ein fehlgeschlagener Testlauf, der die Testkriterien nicht erfüllt, weist darauf hin, dass Sie die Baseline anpassen müssen oder dass ein unerwarteter Fehler aufgetreten ist.
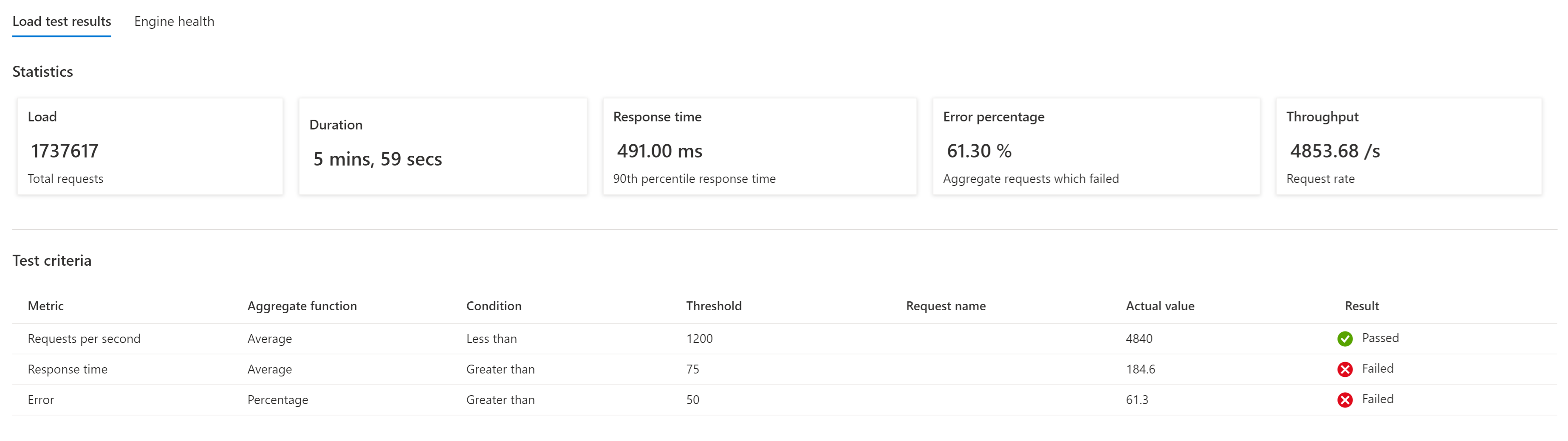
Obwohl automatisierte Tests die tägliche Nutzung darstellen, sollten Sie regelmäßig manuelle Auslastungstests ausführen, um zu überprüfen, wie das System auf unerwartete Lastspitzen reagiert.
Der zweite Teil der kontinuierlichen Validierung ist die Einführung von Fehlern (Chaos Engineering). In diesem Schritt wird die Resilienz eines Systems überprüft, indem seine Reaktionen auf Fehler getestet werden. Außerdem wird überprüft, ob alle Resilienzmaßnahmen wie Wiederholungslogik, automatische Skalierung und andere wie erwartet funktionieren.
2: Implementieren der Validierung mit Load Testing und Chaos Studio
Microsoft Azure bietet diese verwalteten Dienste zum Implementieren von Auslastungstests und Chaos-Engineering:
- Azure Load Testing erzeugt synthetische Benutzerlasten für Anwendungen und Dienste.
- Azure Chaos Studio bietet die Möglichkeit, Chaosexperimente durchzuführen, indem systematisch Fehler in Anwendungskomponenten und die Infrastruktur injiziert werden.
Sie können sowohl Chaos Studio als auch Load Testing über das Azure-Portal bereitstellen und konfigurieren, aber im Kontext der kontinuierlichen Überprüfung ist es wichtiger, dass Sie APIs haben, um Tests programmgesteuert und automatisiert bereitzustellen, zu konfigurieren und auszuführen. Mithilfe dieser beiden Tools können Sie beobachten, wie das System auf Probleme reagiert und seine Fähigkeit zur Selbstheilung als Reaktion auf Infrastruktur- oder Anwendungsfehler erfahren.
Das folgende Video zeigt eine kombinierte Implementierung von Chaos und Load Testing, integriert in Azure DevOps:
Wenn Sie eine unternehmenskritische Workload entwickeln, nutzen Sie die Referenzarchitekturen, detaillierte Anleitungen, Beispielimplementierungen und Codeartefakte, die im Rahmen des Azure Mission-Critical-Projekts und des Azure Well-Architected Framework bereitgestellt werden.
Die Mission-Critical-Implementierung stellt den Azure Load Testing-Dienst via Terraform bereit, der eine Sammlung von PowerShell Core-Wrapperskripts enthält, um über seine API mit dem Dienst zu interagieren. Diese Skripts können direkt in eine Bereitstellungspipeline eingebettet werden.
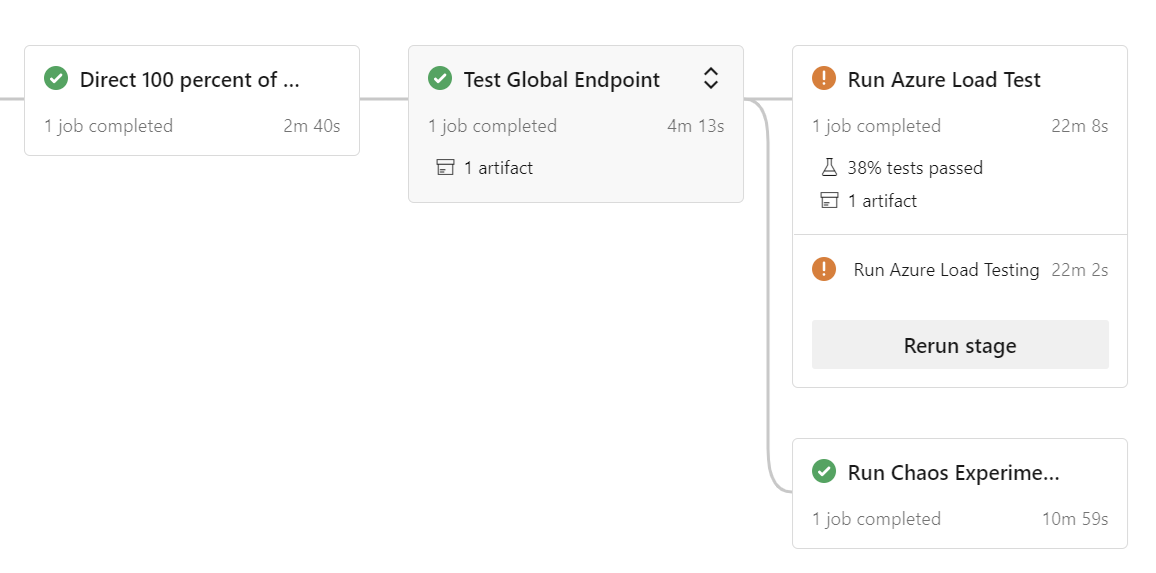
Eine Option in der Referenzimplementierung besteht darin, den Auslastungstest direkt aus der End-to-End-Pipeline (e2e) heraus auszuführen, die verwendet wird, um einzelne (Branch-spezifische) Entwicklungsumgebungen zu starten:

Die Pipeline führt automatisch einen Auslastungstest mit oder ohne Chaosexperimente (je nach Auswahl) parallel aus:
Hinweis
Das Ausführen von Chaosexperimenten während eines Auslastungstests kann zu längeren Wartezeiten, längeren Reaktionszeiten und vorübergehend erhöhten Fehlerraten führen. Sie werden im Vergleich zu einer Ausführung ohne Chaosexperimente höhere Werte feststellen, bis ein horizontaler Skalierungsvorgang oder ein Failover abgeschlossen ist.
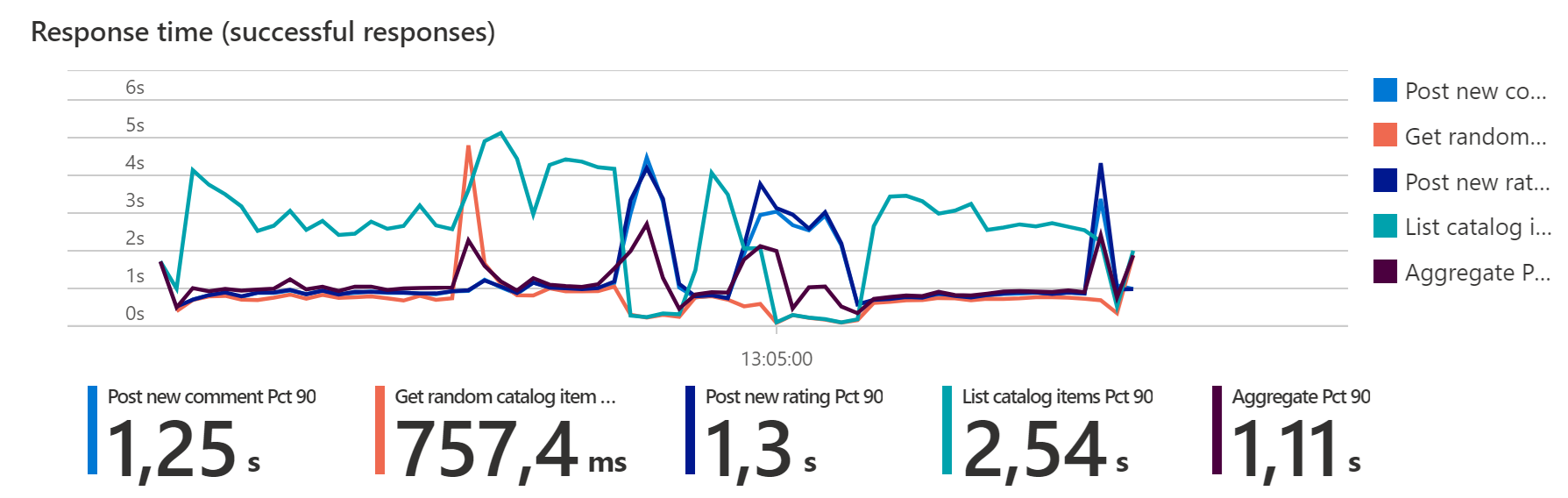
Je nachdem, ob Chaostests aktiviert sind, und abhängig von der Auswahl der Experimente können Baselinedefinitionen variieren, da die Toleranz für Fehler im „Normalzustand“ und im „Chaoszustand“ unterschiedlich sein kann.
3: Anpassen von Schwellenwerten und Einrichten eines Basisplans
Als Letztes passen Sie die Schwellenwerte für regelmäßige Ausführungen an, um zu überprüfen, ob die Anwendung (weiterhin) die erwartete Leistung bereitstellt und keine Fehler erzeugt. Richten Sie eine separate Baseline für Chaostests ein, die erwartete Spitzen bei Fehlerraten und vorübergehend verringerte Leistung toleriert. Diese Aktivität ist kontinuierlich und muss regelmäßig wiederholt werden. Beispielsweise nach der Einführung neuer Features, der Änderung von Dienst-SKUs und anderen Vorgängen.
Der Azure Load Testing-Dienst bietet eine integrierte Funktion namens Testkriterien, mit der bestimmte Kriterien angegeben werden können, die ein Test erfüllen (bestehen) muss. Diese Funktion kann verwendet werden, um verschiedene Baselines zu implementieren.

Die Funktion ist über das Azure-Portal und über die Auslastungstest-API verfügbar, und die Wrapperskripts, die als Teil des unternehmenskritischen Azure-Frameworks entwickelt wurden, bieten eine Möglichkeit, eine JSON-basierte Baselinedefinition zu übergeben.
Es wird dringend empfohlen, diese Tests direkt in Ihre CI/CD-Pipelines zu integrieren und sie während der frühen Phasen der Featureentwicklung auszuführen. Ein Beispiel finden Sie in der Beispielimplementierung in der unternehmenskritischen Azure-Referenzimplementierung.
Zusammengefasst lässt sich sagen, dass Fehler in einem komplexen verteilten System unvermeidlich sind, und dass die Lösung daher entworfen (und getestet) werden muss, um Fehler zu behandeln. Der Leitfaden zur unternehmenskritischen Well-Architected Framework-Workload mit seinen Anleitungen und Referenzimplementierungen kann Ihnen dabei helfen, hochzuverlässige Anwendungen zu entwerfen und zu betreiben, um maximalen Nutzen aus der Microsoft Cloud zu ziehen.
Nächster Schritt
Sehen Sie sich den Bereitstellungs- und Testentwurfsbereich für unternehmenskritische Workloads an.
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für