In den letzten Jahren wurden Versicherer und Unternehmen, die versicherungsähnliche Produkte anbieten, mit verschiedenen neuen Regelungen konfrontiert. Diese neuen Vorschriften machen eine umfangreichere Finanzmodellierung für die Versicherungswirtschaft erforderlich. Mit Solvency II ist ein neues Regelwerk der Europäischen Union in Kraft getreten. Dieses Gesetz verlangt von der Versicherungswirtschaft den Nachweis, dass der Versicherer anhand von entsprechenden Analysen seine Zahlungsfähigkeit am Jahresende sichergestellt hat. Versicherer, die variable jährliche Zahlungen bereitstellen, müssen die Richtlinie Actuarial Guideline XLIII beachten und umfangreiche Analysen des Cashflows bei Forderungen und Verbindlichkeiten erstellen. Alle Arten von Versicherern, darunter auch solche, die versicherungsähnliche Produkte vertreiben, müssen bis zum Jahr 2021 den internationalen Rechnungslegungsstandard International Financial Reporting Standard 17 (IFRS 17) implementieren. (IFRS steht für International Financing Reporting Standards). Je nachdem, in welchen Rechtsräumen die Versicherer tätig sind, gelten andere Vorschriften. Aufgrund dieser Standards und Bestimmungen müssen Aktuare und Versicherungsmathematiker beim Modellieren von Forderungen und Verbindlichkeiten rechenintensive Techniken nutzen. Für einen Großteil der Analyse werden anstelle von einzeln eingegebenen Elementen wie Forderungen und Verbindlichkeiten stochastisch erzeugte Szenariodaten verwendet. Über die Anforderungen der Regulierungsbehörden hinaus sind Versicherungsmathematiker auch in beträchtlichem Umfang für die Finanzmodellierung und -berechnung zuständig. Sie erstellen die Eingabetabellen für die Modelle, welche die gesetzlich vorgeschriebenen Berichte generieren. Interne Computer-Grids können die Berechnungsanforderungen nicht erfüllen. Daher wechseln Versicherungsmathematiker immer mehr in die Cloud.
Versicherungsmathematiker wechseln in die Cloud, um mehr Zeit zum Überprüfen, Evaluieren und Validieren von Ergebnissen zu haben. Wenn die Regulierungsbehörden Versicherungsunternehmen prüfen, müssen die Versicherungsmathematiker in der Lage sein, ihre Ergebnisse zu erläutern. Durch den Wechsel in die Cloud erhalten sie Zugriff auf Computerressourcen, mit denen sie dank der Leistungsfähigkeit der Parallelisierung 20.000 Analysestunden in 24 bis 120 Iststunden ausführen können. Um diesen Bedarf nach Skalierung zu unterstützen, stellen viele Unternehmen, die versicherungsmathematische Software erstellen, Lösungen bereit, die ein Ausführen der Berechnungen in Azure ermöglichen. Einige dieser Lösungen basieren auf Technologien, die lokale und in Azure ausgeführt werden, wie beispielsweise die HPC-Lösung HPC Pack von PowerShell. Andere Lösungen sind Azure-nativ und nutzen Azure Batch, Virtual Machine Scale Sets oder eine benutzerdefinierte Skalierungslösung.
In diesem Artikel wird betrachtet, wie versicherungsmathematische Entwickler Azure zusammen mit Modellierungspaketen für die Risikoanalyse verwenden können. Erläutert werden auch einige der Azure-Technologien, welche die Modellierungspakete für das skalierte Ausführen in Azure nutzen. Sie können die gleiche Technologie für eine weitergehende Analyse Ihrer Daten verwenden. Betrachtet werden folgende Elemente:
- Ausführen größerer Modelle in kürzerer Zeit in Azure
- Berichterstellung aus den Ergebnissen
- Verwalten der Datenaufbewahrung
Unabhängig davon, für welche Versicherung (Lebensversicherung, Sachversicherung, Unfallversicherung, Krankenversicherung oder eine andere Art von Versicherung) Sie arbeiten: Sie müssen Finanz- und Risikomodelle für Ihre Forderungen und Verbindlichkeiten erstellen. Anschließend können Sie Ihre Investitionen und Prämien anpassen, damit Sie als Versicherer solvent bleiben. Durch den internationalen Rechnungslegungsstandard IFRS 17 kommen Änderungen an den von den Versicherungsmathematikern erstellten Modellen hinzu, z. B. die Berechnung der sog. vertraglichen Servicemarge (Contractual Service Margin – kurz CSM), wodurch sich für die Versicherer die Verwaltung ihres Gewinns im Zeitverlauf ändert.
Ausführen größerer Modelle in kürzerer Zeit in Azure
Sie glauben an das Versprechen der Cloud: Sie kann Ihre Finanz- und Risikomodelle schneller und einfacher ausführen. Bei vielen Versicherern lässt die Überschlagsrechnung das Problem erkennen: Sie brauchen Jahre oder sogar Jahrzehnte an Ablaufzeit, um diese Berechnungen von Anfang bis Ende auszuführen. Zur Lösung des Laufzeitproblems ist Technologie erforderlich. Folgende Strategien kommen zum Einsatz:
- Vorbereitung der Daten: Manche Daten ändern sich nur langsam. Sobald eine Police oder ein Dienstvertrag in Kraft getreten ist, bewegen sich die Forderungen im vorhersagbaren Rahmen. Sie können die für die Ausführung des Modells benötigten Daten bei deren Eingang vorbereiten, wodurch Sie nicht viel Zeit für die Datenbereinigung und -vorbereitung einplanen müssen. Sie können auch mit Clustern arbeiten, um durch gewichtete Darstellungen einen Ersatz für einzelne Daten zu erstellen. Weniger Datensätze führen in der Regel zu einer kürzeren Rechenzeit.
- Parallelisierung: Wenn Sie die gleiche Analyse für zwei oder mehr Elemente durchführen müssen, kann die Analyse möglicherweise gleichzeitig erfolgen.
In der Folge werden diese Elemente einzeln betrachtet.
Datenaufbereitung
Daten gehen aus verschiedenen unterschiedlichen Quellen ein. Sie haben semistrukturierte Daten aus Policen in Ihren Geschäftsbüchern. Sie haben außerdem Informationen zu versicherten Personen und Unternehmen sowie den Elementen, die in verschiedenen Antragsformularen enthalten sind. Economic Scenario Generators (ESGs) produzieren Daten in einer Vielzahl von Formaten, die möglicherweise in eine Form übertragen werden müssen, die Ihr Modell verwenden kann. Aktuelle Daten zu Forderungswerten müssen ebenfalls normalisiert werden. Börsendaten, Cashflowdaten aus Mieteinnahmen, Zahlungsinformationen zu Hypotheken und andere Forderungsdaten müssen bei der Übertragung von der Quelle in das Modell alle in gewisser Weise vorbereitet werden. Schließlich sollten Sie alle Annahmen aktualisieren, die auf bisherigen Erfahrungswerten beruhen. Um die spätere Ausführung des Modells zu beschleunigen, bereiten Sie die Daten vor. Zur Laufzeit nehmen Sie alle nötigen Aktualisierungen vor, um die Änderungen seit der letzten geplanten Aktualisierung zu berücksichtigen.
Wie bereiten Sie die Daten vor? Wir betrachten zuerst den allgemeinen Teil und wenden uns dann der Arbeit mit den verschiedenen Erscheinungsformen der Daten zu. Zunächst benötigen Sie einen Mechanismus, um alle Änderungen seit der letzten Synchronisierung abzurufen. Dieser Mechanismus sollte einen Wert beinhalten, der sortierbar ist. Bei kürzlichen Änderungen sollte dieser Wert größer als bei allen vorherigen Änderungen sein. Ein Feld mit einer fortlaufenden ID oder ein Zeitstempel sind die beiden Mechanismen, die am häufigsten verwendet werden. Wenn ein Datensatz einen fortlaufenden ID-Schlüssel aufweist, der Rest des Datensatzes jedoch aktualisierbare Felder enthält, müssen Sie so etwas wie einen Zeitstempel des Typs „Zuletzt geändert“ verwenden, um die Änderungen zu finden. Nachdem die Datensätze verarbeitet wurden, zeichnen Sie den sortierbaren Wert des zuletzt aktualisierten Elements auf. Dieser Wert (wahrscheinlich ein Zeitstempel in einem Feld namens Zuletzt geändert) wird zu Ihrem Wasserzeichen, das für nachfolgende Abfragen im Datenspeicher verwendet wird. Datenänderungen können auf unterschiedliche Weise verarbeitet werden. Die beiden folgenden Mechanismen, die sehr wenig Ressourcen verbrauchen, werden häufig verwendet:
- Wenn Sie hunderte oder tausende Änderungen verarbeiten müssen, laden Sie die Daten in den Blobspeicher. Verwenden Sie in Azure Data Factory einen Ereignisauslöser, um das Changeset zu verarbeiten.
- Wenn Sie nur kleinere Changesets verarbeiten müssen oder Ihre Daten bei jeder Änderung aktualisieren möchten, fügen Sie jede Änderung in eine Warteschlangennachricht ein, die von Service Bus oder Speicherwarteschlangen gehostet wird. In diesem Artikel werden die Vor- und Nachteile dieser beiden Warteschlangentechnologien sehr gut erläutert. Sobald sich eine Nachricht in einer Warteschlange befindet, können Sie in Azure Functions oder Azure Data Factory einen Auslöser verwenden, um die Nachricht zu verarbeiten.
Ein typisches Szenario wird in folgender Abbildung veranschaulicht. Zunächst sammelt ein geplanter Auftrag einige DataSets und platziert die Datei in den Speicher. Der geplante Auftrag kann ein lokal ausgeführter CRON-Auftrag, eine Aufgabe der Aufgabenplanung, eine Logik-App oder irgendetwas sein, das auf Basis eines Zeitgebers ausgeführt wird. Nach dem Hochladen der Datei kann eine Azure Function- oder Data Factory-Instanz zum Verarbeiten der Daten ausgelöst werden. Wenn die Datei in kurzer Zeit verarbeitet werden kann, verwenden Sie eine Funktion. Wenn die Verarbeitung komplex ist und KI oder eine andere komplexe Skriptprogrammierung erfordert, ist HDInsight, Azure Databricks oder eine benutzerdefinierte Anwendung wahrscheinlich besser geeignet. Danach wird die Datei in eine verwendbare Form aufgelöst, entweder als neue Datei oder als Datensatz in einer Datenbank.
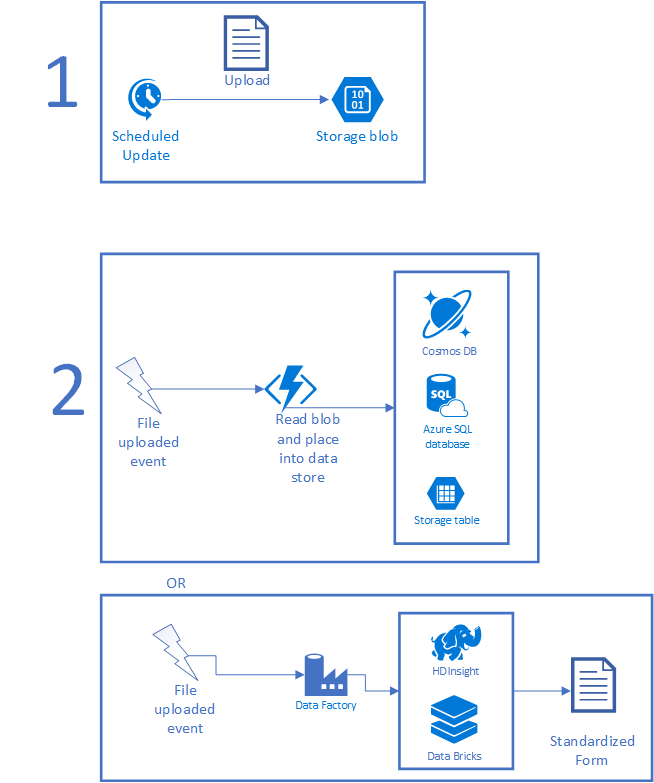
Wenn sich die Daten in Azure befinden, müssen sie so eingerichtet werden, dass sie für die Modellierungsanwendung verwendbar sind. Sie können Code für benutzerdefinierte Umwandlungen schreiben, die Elemente mit HDInsight oder Azure Databricks verarbeiten, um größere Elemente zu erfassen, oder die Daten in die richtigen Datasets kopieren. Auch Big Data-Tools können für Schritte wie die Umwandlung unstrukturierter in strukturierte Daten oder beim Ausführen von künstlicher Intelligenz (KI) und Machine Learning (ML) für die empfangenen Daten hilfreich sein. Sie können zudem virtuelle Computer hosten, Daten direkt in Datenquellen von lokalen Computern hochladen, Azure Functions direkt aufrufen usw.
Später müssen die Daten von Ihren Modellen genutzt werden. Wie Sie vorgehen, hängt weitgehend davon ab, wie die Berechnungen auf die Daten zugreifen müssen. Einige Modellierungssysteme setzen voraus, dass alle Datendateien auf dem Knoten vorhanden sind, der die Berechnung ausführt. Andere nutzen Datenbanken wie Azure SQL-Datenbank, MySQL oder PostgreSQL. Sie können mit einer kostengünstigen Version eines der genannten Systeme beginnen und die Leistung dann während eines Modellierungslaufs hochskalieren. So wenden Sie nur die für die tägliche Arbeit notwendigen Kosten auf. Zusätzliche Geschwindigkeit realisieren Sie nur dann, wenn Tausende von Kernen Daten anfordern. In der Regel sind diese Daten während eines Modellierungslaufs schreibgeschützt. Wenn Ihre Berechnungen über mehrere Regionen hinweg erfolgen, sollten Sie Azure Cosmos DB oder die Georeplikation in Azure SQL-Datenbank in Betracht ziehen. Beide bieten Mechanismen, um Daten automatisch über Regionen mit geringer Latenz hinweg zu replizieren. Ihre Wahl hängt von den Tools ab, die Ihre Entwickler kennen, von der Modellierung Ihrer Daten und von der Anzahl der Regionen, die für den Modellierungslauf verwendet werden.
Nehmen Sie sich etwas Zeit, um darüber nachzudenken, wo Ihre Daten gespeichert werden sollen. Bringen Sie in Erfahrung, welche Daten wie oft gleichzeitig angefordert werden. Überlegen Sie, wie Sie die Informationen verteilen:
- Erhält jeder Berechnungsknoten eine eigene Kopie?
- Wird die Kopie über einen Standort mit hoher Bandbreite freigegeben?
Wenn Sie mit Azure SQL die Daten zentral aufbewahren, werden Sie für die Datenbank die meiste Zeit wahrscheinlich einen preisgünstigeren Tarif verwenden. Wenn die Daten nur bei einem Modellierungslauf verwendet und nicht sehr häufig aktualisiert werden, gehen Azure-Kunden sogar so weit und deaktivieren ihre Datenbankinstanzen zwischen den Modellierungsläufen, nachdem sie die Daten gesichert haben. Die möglichen Einsparungen sind beträchtlich. Kunden können auch Pools für elastische Azure SQL-Datenbanken nutzen. Diese sind für die Kontrolle der Datenbankkosten ausgelegt, besonders wenn Sie nicht wissen, welche Datenbanken zu unterschiedlichen Zeiten stark ausgelastet sind. Pools für elastische Datenbanken ermöglichen einer Sammlung von Datenbanken die Nutzung der erforderlichen Leistung und werden wieder zentral herunterskaliert, wenn sich der Bedarf an eine andere Stelle im System verschiebt.
Während eines Modellierungslaufs müssen Sie möglicherweise die Datensynchronisierung deaktivieren, damit die im Verlauf des Prozesses stattfindenden Berechnungen die gleichen Daten verwenden. Wenn Sie Warteschlangen verwenden, deaktivieren Sie die Nachrichtenprozessoren, gestatten Sie jedoch den Warteschlangen den Empfang von Daten.
Sie können auch die Zeit vor der Ausführung nutzen, um ökonomische Szenarien zu generieren sowie versicherungsmathematische Annahmen und allgemeine sonstige statistische Daten zu aktualisieren. Werfen Sie nun einen Blick auf Economic Scenario Generators (ESGs). Die Society of Actuaries (Aktuarvereinigung) stellt den Academy Interest Rate Generator (AIRG) bereit, ein ESG, das die US-amerikanische Finanzbehörde abbildet. AIRG ist für die Verwendung bei Elementen wie VM-20-Berechnungen (Valuation Manual 20) vorgeschrieben. Andere ESGs können den Aktienmarkt, Hypotheken, Warenpreise usw. modellieren.
Da die Daten in Ihrer Umgebung vorverarbeitet werden, können Sie auch andere Teile früher ausführen. Beispiel: Sie müssen ein Szenario modellieren, für das Datensätze zur Darstellung größerer Bevölkerungsgruppen verwendet werden. Dazu werden in der Regel Datensätze in Clustern zusammengefasst (Clustering). Wenn das DataSet sporadisch (z. B. einmal täglich) aktualisiert wird, kann der Datensatz auf den Teil reduziert werden, der im Rahmen des Erfassungsprozesses im Modell verwendet wird.
Sehen Sie sich ein praktisches Beispiel an. Bei IFRS-17 müssen Sie Ihre Verträge so gruppieren, dass der maximale Abstand zwischen den Startterminen für zwei beliebige Verträge weniger als ein Jahr beträgt. Angenommen, Sie machen es sich einfach und verwenden das Vertragsjahr als Gruppierungsmechanismus. Diese Segmentierung kann erfolgen, während die Daten in Azure geladen werden. Dazu wird die Datei gelesen, und die Datensätze werden in die entsprechende Jahresgruppe verschoben.
Durch die Konzentration auf die Datenvorbereitung verkürzt sich die Zeit, die zum Ausführen der Modellkomponenten erforderlich ist. Durch das frühzeitige Einbinden der Daten können Sie Iststunden für die Ausführung Ihrer Modelle sparen.
Parallelisierung
Mit der richtigen Parallelisierung der Schritte kann die Istzeit für die Ausführung erheblich verkürzt werden. Diese Beschleunigung wird zum einen durch die Optimierung der implementierten Teile erreicht. Zum anderen wissen Sie, wie Sie Ihr Modell in einer Art und Weise ausdrücken, die es erlaubt, zwei oder mehr Aktivitäten gleichzeitig auszuführen. Der Trick dabei ist, die Balance zwischen der Größe der Arbeitsanforderung und der Produktivität eines einzelnen Knotens zu finden. Wenn die Aufgabe mehr Zeit für Setup und Bereinigung als für die Auswertung benötigt, haben Sie zu klein gedacht. Ist die Aufgabe zu groß, verkürzt sich die Ausführungszeit nicht. Die Aktivität muss klein genug sein, um über mehrere Knoten verteilt zu werden, und sich positiv auf die Ablaufzeit für die Ausführung auswirken.
Um Ihr System optimal auszulasten, müssen Sie den Workflow für Ihr Modell genau verstehen und wissen, wie sich die Berechnungen und die Möglichkeit des Aufskalierens gegenseitig beeinflussen. Ihre Software verfügt möglicherweise über ein Konzept für Aufträge, Aufgaben oder Ähnliches. Nutzen Sie dieses Wissen, um etwas zu entwerfen, das Arbeit aufteilen kann. Wenn Ihr Modell einige benutzerdefinierte Schritte enthält, entwerfen Sie diese Schritte so, dass Eingaben zum Aufteilen in kleinere Verarbeitungsgruppen möglich sind. Dieser Entwurf wird häufig wird als Scatter-Gather-Muster bezeichnet.
- Scatter: Eingaben entlang natürlicher Linien aufteilen und das Ausführen separater Aufgaben erlauben.
- Gather: Ausgaben nach Abschluss der Aufgaben sammeln.
Beim Aufteilen von Elementen müssen Sie außerdem wissen, wo der Prozess synchronisieren muss, bevor Sie fortfahren. Es gibt einige häufig verwendete Stellen, an denen Elemente aufgeteilt werden. Bei ineinander verschachtelten stochastischen Ausführungen haben Sie möglicherweise tausend äußere Loops mit einem Satz von Wendepunkten, die innere Loops von einhundert Szenarios ausführen. Jeder äußere Loop kann gleichzeitig ausgeführt werden. An einem Wendepunkt erfolgt ein Halt, die inneren Loops werden dann gleichzeitig ausgeführt, und die Informationen werden wieder zurückgeführt, um die Daten für den äußeren Loop anzupassen und den Vorgang fortzusetzen. Die folgende Abbildung veranschaulicht den Workflow. Ausreichende Compute-Kapazität vorausgesetzt, können Sie die 100.000 inneren Loops auf 100.000 Kernen ausführen, wodurch sich die Verarbeitungszeit auf folgende Zeiten reduziert:

Die Verteilung bringt eine leichte Erhöhung mit sich, je nachdem, wie der Vorgang erfolgt. Er kann so einfach wie das Erstellen eines kleinen Auftrags mit den richtigen Parametern oder so komplex wie das Kopieren von 100.000 Dateien an die richtigen Stellen sein. Sogar die Verarbeitung der Ergebnisse kann noch beschleunigt werden, wenn Sie die Ergebnisaggregation mithilfe von Apache Spark für Azure HDInsight, Azure Databricks oder einer eigenen Bereitstellung verteilen. Beispiel: Bei der Berechnung von Durchschnittswerten geht es nur darum, sich die Anzahl der bisherigen Elemente und die Summe zu merken. Andere Berechnungen funktionieren möglicherweise besser auf einem einzelnen Computer mit tausenden von Kernen. Dafür können Sie GPU-fähige Computer in Azure verwenden.
Die meisten Aktuarteams beginnen diesen Weg durch das Verlagern ihrer Modelle in Azure. Anschließend sammeln sie Zeitdaten zu den verschiedenen Schritten im Prozess. Danach sortieren Sie absteigend die Istzeit für jeden Schritt (von der längsten bis zur kürzesten Ablaufzeit). Nicht betrachtet wird die Gesamtausführungszeit, da manche Vorgänge tausende von Kernstunden, aber nur 20 Minuten Ablaufzeit benötigen. Entwickler für versicherungsmathematische Lösungen suchen für jeden der Auftragsschritte mit der längsten Ausführungszeit nach Möglichkeiten, die Ablaufzeit zu reduzieren und trotzdem die richtigen Ergebnisse zu erzielen. Dieser Vorgang wird regelmäßig wiederholt. Einige Aktuarteams legen eine Ausführungszeit als Ziel fest, z. B. sollte eine Hedginganalyse über Nacht in unter 8 Stunden ausgeführt werden. Sobald die Zeit auf über 8,25 Stunden ansteigt, konzentriert sich ein Teil des Aktuarteams auf die Verbesserung der Zeit für das Element, das in der Analyse die längste Ausführungszeit aufweist. Wurde die Zeit unter 7,5 Stunden gedrückt, konzentrieren sie sich wieder auf die Entwicklung. Die heuristische Methode des Zurückgehens und Optimierens wird von Versicherungsmathematikern unterschiedlich verwendet.
Für die gesamte Ausführung stehen verschiedene Optionen zur Auswahl. Versicherungsmathematische Software arbeitet überwiegend mit Computer-Grids. Für lokale Grids und Grids in Azure werden entweder HPC Pack, ein Partner-Paket oder benutzerdefinierte Software verwendet. Für Azure optimierte Grids verwenden Virtual Machine Scale Sets, Batch oder eine benutzerdefinierte Anwendung. Wenn Sie sich für Scale Sets oder Batch entscheiden, stellen Sie sicher, dass virtuelle Computer (VMs) mit niedriger Priorität unterstützt werden (VM Scale Sets mit niedriger Priorität – Dokumentation, Batch mit niedriger Priorität – Dokumentation). Ein virtueller Computer (VM) mit niedriger Priorität ist ein virtueller Computer, der auf Hardware ausgeführt wird, die Sie für einen Bruchteil des normalen Preises mieten können. Der niedrigere Preis beruht darauf, dass VMs mit niedriger Priorität vorzeitig entfernt werden können, wenn es die Kapazität erfordert. Wenn Sie in Ihrem Zeitbudget ein wenig Flexibilität haben, stellen virtuelle Computer mit niedriger Priorität eine hervorragende Möglichkeit dar, den Preis für einen Modellierungslauf zu reduzieren.
Wenn Sie die Ausführung und Bereitstellung über mehrere Computer hinweg (möglicherweise auch mit Computern in unterschiedlichen Regionen) koordinieren müssen, können Sie CycleCloud nutzen. Durch CycleCloud entstehen keine zusätzlichen Kosten. Es dient bei Bedarf zum Orchestrieren der Datenverschiebung. Dies schließt Zuordnung, Überwachung und Herunterfahren der Computer ein. CycleCloud unterstützt auch Computer mit niedriger Priorität und sorgt so für eine Kostenbegrenzung. Sie können sogar die Mischung der benötigten Computer beschreiben. Beispiel: Sie benötigen eine Klasse von Computern, die Ausführung kann jedoch gut auf jeder Version mit mindestens zwei Kernen erfolgen. Cycle kann die Kerne übergreifend über diese Computertypen zuordnen.
Berichterstellung aus den Ergebnissen
Nachdem Sie die versicherungsmathematischen Pakete ausgeführt und Ergebnisse erzeugt haben, stehen Ihnen verschiedene, für die Regulierungsbehörden ausgelegte Berichte zur Verfügung. Außerdem haben Sie einen Berg neuer Daten, die Sie vielleicht analysieren möchten, um Erkenntnisse zu generieren, die nicht von Regulierungsbehörden oder Prüfern gefordert werden. Vielleicht möchten das Profil Ihrer besten Kunden besser verstehen. Mithilfe Ihrer Erkenntnisse können Sie der Marketingabteilung sagen, wie ein kostengünstiger, d. h. rentabler Kunde aussieht, damit die Marketingabteilung und der Vertrieb solche Kunden schneller aufspüren können. Ebenso können Sie die Daten nutzen, um zu ermitteln, welche Gruppen am meisten von der Versicherung profitieren. Sie können z. B. ermitteln, dass Personen, die zur jährlichen Routineuntersuchung gehen, sich schon vorher über das Frühstadium von Gesundheitsrisiken informiert haben. Dies spart der Versicherungsgesellschaft Zeit und Geld. Sie können diese Daten zum Steuern des Verhaltens in Ihrem Kundenstamm verwenden.
Zu diesem Zweck sollten Sie Zugriff auf viele Data Science-Tools sowie auf einige Elemente für die Visualisierung haben. Je nach Umfang der gewünschten Untersuchung können Sie mit einem virtuellen Data Science-Computer beginnen, der über den Azure Marketplace bereitgestellt werden kann. Für diese virtuellen Computer gibt es eine Windows- und Linux-Version. Einmal installiert stehen Microsoft R Open, Microsoft Machine Learning Server, Anaconda, Jupyter und andere Tools für die Arbeit bereit. Geben Sie ein wenig R- oder Python-Code ein, um die Daten zu visualisieren und Ihre Erkenntnisse mit Kollegen zu teilen.
Wenn Sie weitere Analysen durchführen müssen, können Sie über HDInsight oder Databricks Apache Data Science-Tools wie Spark, Hadoop und andere nutzen. Sie sollten diese Tools eher dann verwenden, wenn die Analyse regelmäßig ausgeführt werden muss und Sie den Workflow automatisieren möchten. Sie sind auch nützlich für die Live-Analyse großer DataSets.
Wenn Sie etwas Interessantes gefunden haben, müssen Sie die Ergebnisse präsentieren. Viele Aktuare und Versicherungsmathematiker beginnen mit den Beispielergebnissen und übernehmen diese in Excel, um Diagramme, Graphen und andere Visualisierungen zu erstellen. Wenn Sie nach etwas suchen, das auch eine ansprechende Benutzeroberfläche für den Drilldown in die Daten hat, werfen Sie einen Blick auf Power BI. Power BI kann ansprechende Visualisierungen erstellen und die Quelldaten anzeigen. Durch das Hinzufügen von sortierten Lesezeichen mit Anmerkungen können Sie dem Leser die Daten erläutern.
Datenaufbewahrung
Ein Großteil der Daten, die Sie in das System einbringen, müssen für zukünftige Prüfungen aufbewahrt werden. Die Vorschriften für die Datenaufbewahrung liegen in der Regel im Bereich von 7 bis 10 Jahren, können aber variieren. Zur Mindestaufbewahrung zählt Folgendes:
- Eine Momentaufnahme der ursprünglichen Eingaben in das Modell. Dazu gehören Forderungen, Verbindlichkeiten, Annahmen, ESGs und andere Eingaben.
- Eine Momentaufnahme der endgültigen Ausgaben. Dazu gehören alle Daten, die zum Erstellen der Berichte für die Regulierungsbehörden verwendet wurden.
- Andere wichtige Zwischenergebnisse. Ein Prüfer wird Sie fragen, warum Ihr Modell ein Ergebnis produziert hat. Sie müssen den Nachweis führen, warum das Modell eine bestimmte Auswahl vorgenommen oder bestimmte Zahlen ermittelt hat. Viele Versicherer entscheiden sich dafür, die für die Generierung der endgültigen Ausgaben verwendeten Binärdaten der ursprünglichen Eingaben aufzubewahren. Bei Rückfragen führen sie dann das Modell erneut aus, um eine aktuelle Kopie der Zwischenergebnisse zu erhalten. Wenn die Ausgaben übereinstimmen, sollten die Zwischendateien auch die benötigten Erläuterungen enthalten.
Während der Ausführung des Modells verwenden Aktuare und Versicherungsmathematiker Datenübermittlungsmechanismen, die die Anforderungslast der Ausführung verarbeiten können. Wenn die Ausführung abgeschlossen ist und die Daten nicht mehr benötigt werden, bewahren sie einige der Daten auf. Ein Versicherer sollte mindestens die Eingaben und die Laufzeitkonfiguration für mögliche Reproduktionsanforderungen aufbewahren. Die Datenbanken werden durch Sicherungen in Azure Blob Storage aufbewahrt, und die Server werden heruntergefahren. Daten im Hochgeschwindigkeitsspeicher werden ebenfalls in den kostengünstigeren Azure Blob Storage verschoben. Sobald sich die Daten im Blobspeicher befinden, können Sie die Datenebene für jedes Blob auswählen: „Heiß“, „Kalt“ oder „Archiv“. „Heiß“ eignet sich gut für Dateien, auf die häufig zugegriffen wird. „Kalt“ ist optimiert für seltenen Datenzugriff. „Archiv“ ist optimal für die Aufbewahrung prüffähiger Dateien geeignet, doch gehen die Preiseinsparungen zu Lasten der Latenz: Die Latenz für Daten auf der Ebene „Archiv“ wird in Stunden gemessen. Lesen Sie Azure Blob Storage: Speicherebenen „Heiß“, „Kalt“ und „Archiv“, um die verschiedenen Speicherebenen besser zu verstehen. Sie können Daten von der Erstellung bis zur Löschung mit einer Lebenszyklusverwaltung verwalten. URIs für Blobs bleiben statisch, der Speicherplatz für das Blob wird jedoch mit der Zeit kostengünstiger. Dieses Feature erspart vielen Benutzern von Azure Storage eine Menge Geld und Sorgen. Informationen zu den Vor-und Nachteilen finden Sie unter Verwalten des Azure Blob Storage-Lebenszyklus. Die Tatsache, dass Sie Dateien automatisch löschen können, ist sehr praktisch: Es bedeutet, dass Sie nicht versehentlich eine Prüfung durch den Verweis auf eine Datei ausdehnen, die sich außerhalb des Bereichs befindet, da die Datei selbst automatisch entfernt werden kann.
Überlegungen
Wenn das versicherungsmathematische System, das Sie ausführen, eine lokale Grid-Implementierung enthält, wird diese Grid-Implementierung wahrscheinlich auch in Azure ausgeführt. Einige Anbieter haben spezielle Azure-Implementierungen, die mit Hyperscale ausgeführt werden. Im Rahmen der Umstellung auf Azure sollten Sie Ihre internen Tools ebenfalls migrieren. Allerorts haben Aktuare und Versicherungsmathematiker festgestellt, dass ihre Data Science-Fähigkeiten gut auf dem Laptop oder mit einer großen Umgebung funktionieren. Suchen Sie nach Dingen, die Ihr Team bereits tut: Vielleicht haben Sie ein Tool, das Deep Learning verwendet, aber mehrere Stunden oder Tage auf einer GPU ausgeführt werden muss. Versuchen Sie, die gleiche Workload auf einem Computer mit vier High-End-GPUs auszuführen, und sehen Sie sich die Laufzeiten an. Die Chancen stehen gut, dass sich Dinge, die Sie bereits haben, erheblich beschleunigen lassen.
Bei Verbesserungen sollten Sie dafür sorgen, auch eine Form der Datensynchronisierung zu etablieren, um die Modellierungsdaten einzuspeisen. Die Modellausführung kann erst gestartet werden, wenn die Daten bereit sind. Dies kann einigen Mehraufwand bedeuten, sodass Sie nur geänderte Daten senden. Der tatsächliche Ansatz hängt von der Datengröße ab. Die Aktualisierung einer MB ist kein große Sache, aber die Reduzierung der Anzahl von Gigabyte-Uploads beschleunigt die Dinge um ein Vielfaches.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Scott Seely | Software Architect
Nächste Schritte
- R-Entwickler: Ausführen einer parallelen R-Simulation mit Azure Batch
- ETL mit Databricks: Extrahieren, Transformieren und Laden von Daten mithilfe von Azure Databricks
- ETL mit HDInsight: Extrahieren, Transformieren und Laden von Daten mithilfe von Apache Hive in Azure HDInsight
- Data Science VM: Anleitung für Linux
- Data Science VM: Anleitung für Windows