Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Cosmos DB
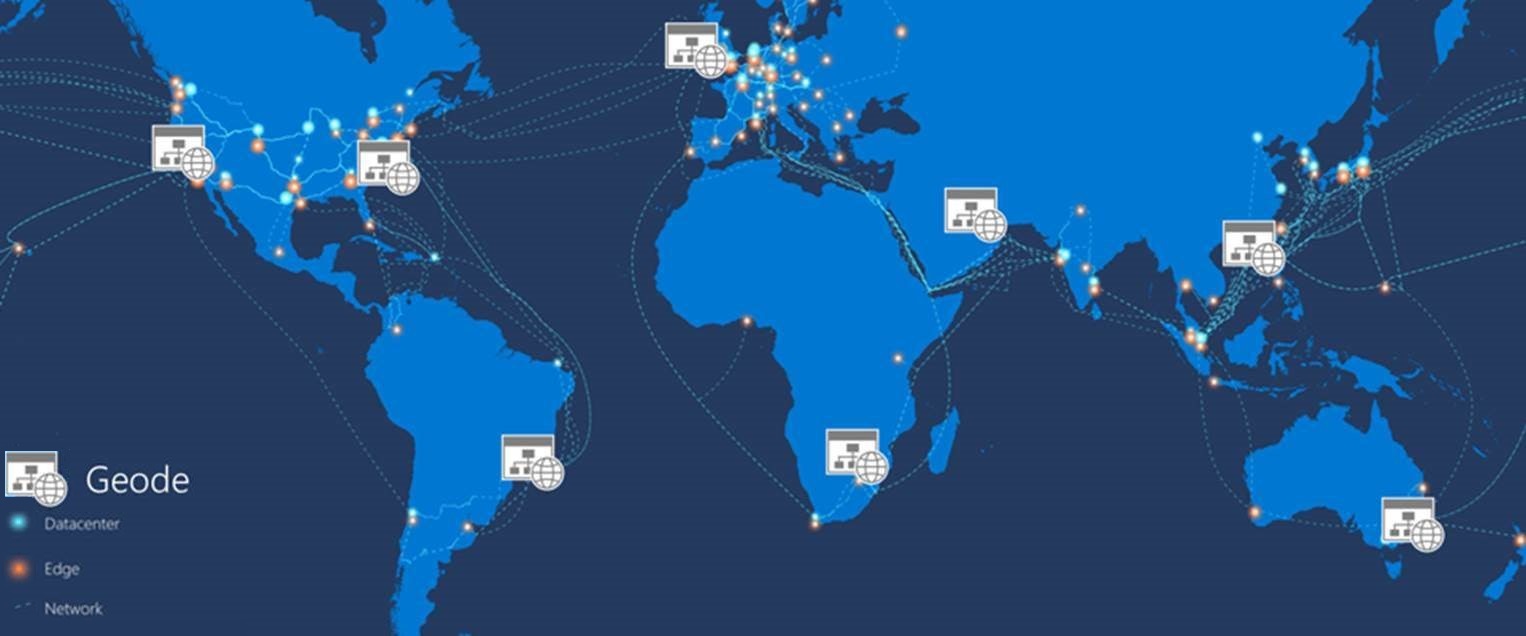
Stellen Sie eine Sammlung von Back-End-Diensten in einer Reihe von geographischennodes bereit, von denen jede Anforderung von jedem Client in jeder Region bedient werden kann. Dieser Active-Active-Ansatz verteilt die Anfragenverarbeitung auf der ganzen Welt, um die Latenz zu verringern und die Verfügbarkeit zu erhöhen.
Kontext und Problem
Für viele größere Dienste müssen besondere Anforderungen in Bezug auf die geografische Verfügbarkeit und die Skalierbarkeit erfüllt werden. Bei klassischen Entwürfen werden Daten häufig für die Computeumgebung bereitgestellt, indem sie auf einem Remotecomputer mit SQL Server gespeichert werden, der als Computeebene für diese Daten dient. Bei einer Zunahme der Daten wird dann entsprechend hochskaliert.
Der klassische Ansatz kann die folgenden Probleme verursachen:
- Probleme aufgrund von Netzwerklatenz für Benutzer, die von weit entfernten Standorten eine Verbindung mit dem Hostingendpunkt herstellen
- Verkehrsmanagement bei Bedarfserhöhungen, die die Dienste in einer einzigen Region überwältigen können
- Aus Kostensicht zu hohe Komplexität bei der Bereitstellung von Exemplaren der App-Infrastruktur in mehreren Regionen für einen rund um die Uhr verfügbaren Dienst
Die moderne Cloudinfrastruktur wurde weiterentwickelt, um einen geografischen Lastenausgleich für Front-End-Dienste zu ermöglichen, während für Back-End-Dienste die geografische Replikation erfolgen kann. Wenn Daten näher beim Benutzer angeordnet werden können, fördert dies die Verfügbarkeit und Leistung. Wenn Daten geografisch auf eine weit verstreute Benutzerbasis verteilt sind, sollten die geografisch verteilten Datenspeicher ebenfalls mit den Computeressourcen zusammengefasst werden, von denen die Daten verarbeitet werden. Beim Geode-Muster wird die Rechenleistung zu den Daten gebracht.
Lösung
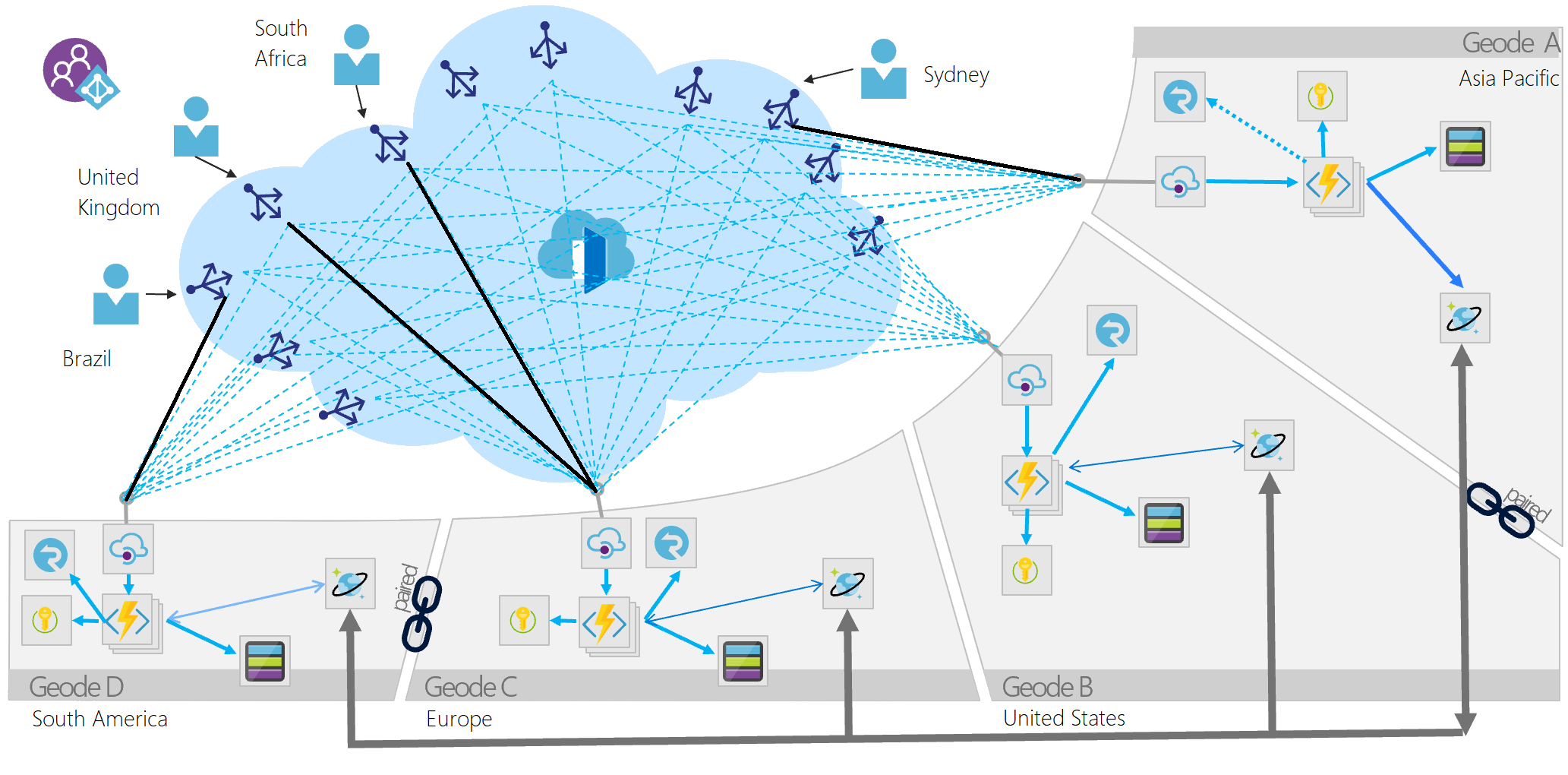
Stellen Sie den Dienst in mehreren Satellitenbereitstellungen auf der ganzen Welt bereit, von denen jeder als Geode bezeichnet wird. Beim Geode-Muster werden die wichtigsten Features von Azure genutzt, um Datenverkehr über den kürzesten Pfad zu einer nahegelegenen Geode weiterzuleiten, was die Latenz und Leistung verbessert. Jede Geode befindet sich hinter einem globalen Load Balancer und nutzt einen geo-replizierten Lese-/Schreibdienst wie Azure Cosmos DB, um die Datenebene zu hosten, wodurch die Konsistenz der Daten zwischen den Geoden sichergestellt wird. Mit den Datenreplikationsdiensten wird sichergestellt, dass Datenspeicher für alle geografischen Knoten identisch sind, damit alle Anforderungen von allen geografischen Knoten aus bereitgestellt werden können.
Der Hauptunterschied zwischen einem Bereitstellungsstempel und einer Geode besteht darin, dass Geoden niemals isoliert existieren. Eine Produktionsplattform sollte immer mehr als eine Geode umfassen.
Geoden verfügen über die folgenden Merkmale:
- Sie umfassen unterschiedliche Arten von Ressourcen, die häufig in einer Vorlage definiert sind.
- Sie haben keine Abhängigkeiten außerhalb des Geode-Fußabdrucks und sind eigenständig. Jeder Geode arbeitet unabhängig von anderen, und wenn einer ausfällt, arbeiten die anderen weiter.
- Sie sind über ein Edgenetzwerk und eine Replikationsebene lose miteinander gekoppelt. Sie können beispielsweise Azure Traffic Manager oder Azure Front Door zum Voranstellen der Geodes verwenden, während Azure Cosmos DB als Replikationsebene im Hintergrund fungiert. Geoden sind nicht mit Clustern identisch, da sie einen Replikations-Backplan teilen, sodass die Plattform quorumprobleme übernimmt.
Das Geode-Muster wird in Big Data-Architekturen genutzt, die Standardhardware verwenden, um gleichzeitig auf demselben Rechner befindliche Daten zu verarbeiten, und MapReduce wird verwendet, um die Ergebnisse über mehrere Computer hinweg zusammenzufassen. Eine andere Art der Nutzung ist die Anordnung von Computeressourcen in der Nähe des Edgebereichs, um diese näher am intelligenten Edgebereich des Netzwerks zu platzieren und so die Antwortzeit zu reduzieren.
Dienstleistungen können dieses Muster über Dutzende oder Hunderte von Geoden verwenden. Darüber hinaus erhöht sich die Resilienz der gesamten Lösung mit jedem hinzugefügten geografischen Knoten, weil die Aufgaben von jedem anderen geografischen Knoten übernommen werden können, falls bei einem regionalen Ausfall einer oder mehrere geografische Knoten in den Offlinezustand versetzt werden.
Es ist auch möglich, lokale Verfügbarkeitstechniken, wie Verfügbarkeitszonen oder Regionenpaare, mit dem Geode-Muster zu erweitern, um globale Verfügbarkeit zu erreichen. Diese Vorgehensweise erhöht zwar die Komplexität, aber sie ist hilfreich, wenn Ihre Architektur auf einer Speicher-Engine basiert, z. B. Blob-Speicher, der nur in eine gepaarte Region replizieren kann. Sie können Geodes in einer zonalen (einzelnen Zone), mehrzonigen oder regionalen Bereitstellungsumgebung bereitstellen, unter Berücksichtigung regulatorischer oder standortbezogener Latenzeinschränkungen.
Probleme und Überlegungen
Verwenden Sie die folgenden Verfahren und Technologien, um dieses Muster zu implementieren:
- Moderne DevOps-Methoden und -Tools, um identische geografische Knoten für eine große Zahl von Regionen oder Instanzen zu erstellen und in kurzer Zeit bereitzustellen.
- Automatische Skalierung zum Aufskalieren von Compute- und Datenbankdurchsatz-Instanzen innerhalb eines geografischen Knotens. Jede Geode skaliert individuell innerhalb der Beschränkungen der gemeinsamen Rückwand.
- Ein Front-End-Dienst wie Azure Front Door, der dynamische Inhaltsbeschleunigung, Routing über einen optimalen Anwesenheitspunkt und Split TCP durchführt.
- Es wird ein Replikationsdatenspeicher wie Azure Cosmos DB genutzt, um die Datenkonsistenz zu steuern.
- Nach Möglichkeit werden serverlose Technologien eingesetzt, um die Kosten für Always On-Bereitstellungen zu reduzieren. Dies gilt vor allem, wenn die Auslastung häufig neu weltweit verteilt wird. Bei dieser Strategie können viele Geoden mit geringem zusätzlichem Investitionsaufwand eingesetzt werden. Mit serverlosen und verbrauchsbasierten Abrechnungstechnologien werden überflüssige Kapazitäten und Kosten reduziert, die aufgrund von doppelten geografisch verteilten Bereitstellungen entstehen.
- Die API-Verwaltung ist nicht erforderlich, um das Entwurfsmuster zu implementieren, kann jedoch zu jeder Geode hinzugefügt werden, die als Schnittstelle für die Azure Function App der Region dient, um eine robustere API-Ebene bereitzustellen und dadurch die Implementierung zusätzlicher Funktionen wie Ratenbegrenzung zu ermöglichen.
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Geben Sie an, ob Daten lokal in jeder Region verarbeitet oder Aggregationen nur innerhalb eines geografischen Knotens mit anschließender weltweiter Replikation des Ergebnisses verteilt werden sollen. Der Änderungsfeedprozessor von Azure Cosmos DB ermöglicht diese präzise Steuerung über das Lease-Container-Konzept und das entsprechende LeaseCollectionPrefix-Element in der Azure Functions-Bindung. Jeder Ansatz ist mit anderen Vor- und Nachteilen verbunden.
- Geoden können zusammenarbeiten, indem der Azure Cosmos DB-Änderungsfeed und eine Plattform für die Echtzeitkommunikation wie SignalR verwendet werden. Geodes können mit Remotebenutzern über andere Geodes in einem Meshmuster kommunizieren, ohne zu wissen oder sich darum zu kümmern, wo sich der Remotebenutzer befindet.
- Bei diesem Entwurfsmuster werden alle Komponenten implizit entkoppelt. Dies führt zu einer äußerst stark verteilten und entkoppelten Architektur. Überlegen Sie sich, wie Sie unterschiedliche Komponenten der gleichen Anforderung nachverfolgen können, da diese unter Umständen asynchron in verschiedenen Instanzen ausgeführt werden. Eine geeignete Überwachungsstrategie ist entscheidend. Sowohl Azure Front Door als auch Azure Cosmos DB können problemlos in Log Analytics integriert werden, und Azure Functions sollte parallel zu Application Insights bereitgestellt werden, um ein stabiles Überwachungssystem für jede Komponente in der Architektur bereitzustellen.
- Bei verteilten Bereitstellungen gibt es eine größere Anzahl von Geheimnissen und Eingangspunkten, die angemessene Sicherheitsmaßnahmen erfordern. Key Vault bietet eine sichere Ebene für die Geheimnisverwaltung, und jede Ebene innerhalb der API-Architektur muss ordnungsgemäß geschützt werden, sodass der Front-End-Dienst (beispielsweise Azure Front Door) der einzige Zugangspunkt für die API ist. Der Datenverkehr von Azure Cosmos DB zu Azure Function Apps und von den Function Apps zu Azure Front Door sollte mithilfe von Microsoft Entra ID oder durch Methoden wie die IP- Einschränkung eingeschränkt werden.
- Die Leistung hängt stark von der Anzahl bereitgestellter geografischer Knoten sowie von den spezifischen App Service-Plänen ab, die auf die API-Technologie der jeweiligen geografischen Knoten angewendet werden. Die Bereitstellung zusätzlicher Geoknoten oder der Wechsel zu Premium-Tarifen führt zu höheren Kosten für den zusätzlichen Arbeitsspeicher und die Rechenressourcen, jedoch nicht auf Basis einzelner Transaktionen. Betrachten Sie die Durchführung eines Lasttests der API-Architektur nach der Bereitstellung und vergleichen Sie die Erhöhung der Anzahl der Geodes mit der Erhöhung der Preisstufe, damit das kostengünstigste Modell für Ihre Bedürfnisse genutzt wird.
- Bestimmen Sie die Verfügbarkeitsanforderungen für Ihre Daten. Azure Cosmos DB verfügt über optionale Flags, um Verfügbarkeitszonen, Schreibvorgänge in mehreren Regionen und Ähnliches zu aktivieren. Diese erhöhen zwar die Verfügbarkeit für die Azure Cosmos DB-Instanz sowie die Resilienz der Datenschicht, sind aber auch mit zusätzlichen Kosten verbunden.
- Azure bietet verschiedene Lastenausgleichsgeräte, die unterschiedliche Funktionen für die Verteilung des Datenverkehrs bereitstellen. Verwenden Sie die Entscheidungsstruktur, um die richtige Option für das Front-End Ihrer API zu finden.
Wann Sie dieses Muster verwenden sollten
Verwenden Sie dieses Muster in folgenden Fällen:
- Implementierung einer umfassenden Plattform, deren Benutzer weit verstreut sind
- Für alle Dienste mit hohen Anforderungen an die Verfügbarkeit und Resilienz, da auf dem Muster mit geografischen Knoten basierende Dienste den gleichzeitigen Ausfall mehrerer Dienstregionen überstehen können
Dieses Muster ist unter Umständen nicht geeignet.
- Architekturen mit Einschränkungen, die verhindern, dass alle Geode-Knoten gleichwertig für die Datenspeicherung genutzt werden können. Es kann z. B. Anforderungen an die Datenresidenz geben, eine Anwendung, die den temporären Zustand für eine bestimmte Sitzung beibehalten muss, oder eine starke Ausrichtung von Anfragen auf eine einzelne Region. In diesem Fall sollten Sie die Nutzung von Bereitstellungsstempeln in Verbindung mit einer globalen Routingebene erwägen, die über den Speicherort der Daten eines Benutzers informiert ist. Dies kann beispielsweise die Komponente für Datenverkehrsrouting sein, die unter Muster mit Bereitstellungsstempeln beschrieben ist.
- Situationen, in denen keine geografische Verteilung erforderlich ist. Erwägen Sie stattdessen die Verwendung von Verfügbarkeitszonen und Regionspaaren für das Clustering.
- Situationen, in denen eine Legacy-Plattform nachgerüstet werden muss. Dieses Muster ist nur für die cloudnative Entwicklung geeignet, und die Nachrüstung kann sich schwierig gestalten.
- Einfache Architekturen und Anforderungen, bei denen die Georedundanz und geografische Verteilung nicht erforderlich oder vorteilhaft sind.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Geode-Muster im Design seiner Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Azure Well-Architected Framework-Säulen behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Dieses Muster verwendet Datenreplikation, um den Idealfall zu unterstützen, dass jeder Client eine Verbindung zu jeder geografischen Instanz herstellen kann, und kann so dazu beitragen, dass Ihre Workload einem oder mehreren regionalen Ausfällen standhält. - RE:05 Hochverfügbares Design für mehrere Regionen - RE:05 Regionen und Verfügbarkeitszonen |
| Die Leistungseffizienz unterstützt Ihre Workload dabei, Anforderungen effizient durch die Optimierung von Skalierung, Daten und Code zu erfüllen. | Mit diesem Muster können Sie Ihre Anwendung aus einer Region bereitstellen, die Ihrer verteilten Benutzerbasis am nächsten liegt. Dadurch wird die Latenz reduziert, da der Datenverkehr über weite Strecken entfällt und die Infrastruktur nur von Benutzern gemeinsam genutzt wird, die derzeit denselben Geoknoten verwenden. - PE:03 Dienste auswählen |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiele
- Mit Windows Active Directory wird eine frühe Variante dieses Musters implementiert. Die Multiprimärreplikation bedeutet, dass alle Updates und Anforderungen theoretisch von allen wartbaren Knoten bereitgestellt werden können, während FSMO-Rollen (Flexible Single Master Operation) bedeuten, dass nicht alle Geoknoten gleich sind.