Verwaltung der Geschäftskontinuität in Azure
Azure unterhält eines der ausgereiftesten und angesehensten Programme zur Verwaltung der Geschäftskontinuität der Branche. Das Ziel der Geschäftskontinuität in Azure besteht darin, die Wiederherstellbarkeit und Resilienz für alle unabhängig wiederherstellbaren Dienste zu erstellen und zu verbessern, unabhängig davon, ob es sich um einen Dienst mit Kundenkontakt (Teil eines Azure-Angebots) oder einen internen unterstützenden Plattformdienst handelt.
Zum Verständnis der Geschäftskontinuität ist es wichtig zu wissen, dass sich viele Angebote aus mehreren Diensten zusammensetzen. Bei Azure wird jeder Dienst mithilfe von Tools statisch identifiziert und er ist die Maßeinheit, die für Datenschutz, Sicherheit, Bestand, Risk Business Continuity Management und andere Funktionen verwendet wird. Um die Möglichkeiten eines Diensts richtig zu messen, werden die drei Elemente „Personen“, „Prozesse“ und „Technologie“ für jeden Dienst einbezogen, unabhängig von der Art des Diensts.
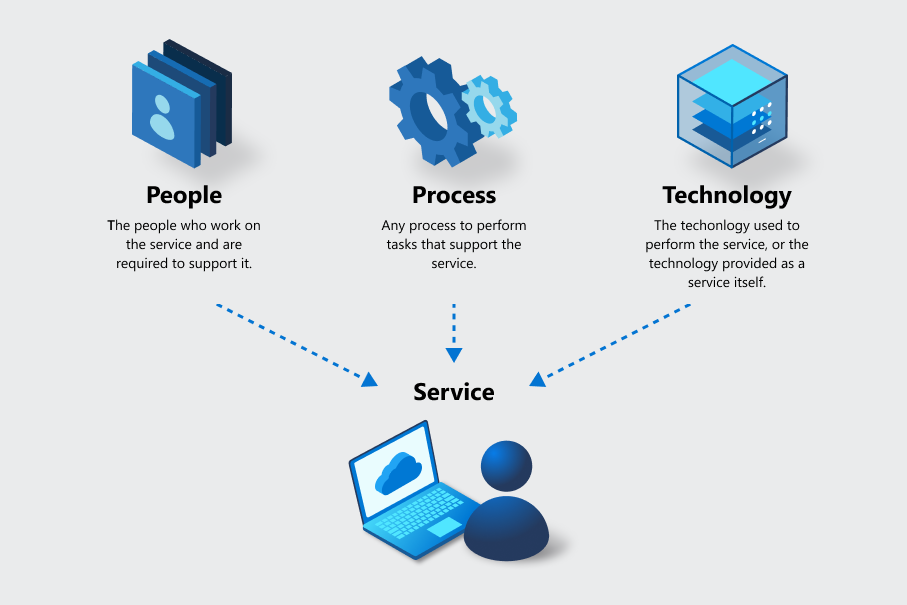
Beispiel:
- Wenn ein Geschäftsprozess auf Personen basiert, z. B. ein Helpdesk oder ein Team, ist die Erbringung des Diensts ihre Aufgabe. Die Personen verwenden Prozesse und Technologien, um den Dienst auszuführen.
- Wenn Technologie als Dienst verwendet wird, z. B. bei Azure Virtual Machines, besteht die Erbringung des Diensts aus der Technologie sowie den Personen und Prozessen, die ihren Betrieb unterstützen.
Modell der gemeinsamen Zuständigkeit
Viele der Angebote von Azure erfordern das Einrichten der Notfallwiederherstellung in mehreren Regionen und sind nicht die Verantwortung von Microsoft. Nicht alle Azure-Dienste replizieren automatisch Daten oder greifen automatisch auf eine ausgefallene Region zurück, um eine regionsübergreifende Replikation in eine andere aktivierte Region durchzuführen. In diesen Fällen sind Sie für die Konfiguration der Wiederherstellung und Replikation verantwortlich.
Microsoft stellt sicher, dass die Baselineinfrastruktur und die Plattformdienste verfügbar sind. In einigen Szenarien erfordert die Nutzung jedoch, dass Sie Ihre Bereitstellungen und den Speicher in einer Kapazität mit mehreren Regionen duplizieren, wenn Sie sich dafür entscheiden. Diese Beispiele veranschaulichen das Modell der gemeinsamen Verantwortung. Es ist ein grundlegender Pfeiler in Ihrer Strategie für Business Continuity & Disaster Recovery (Geschäftskontinuität und Notfallwiederherstellung).
Aufteilung der Verantwortung
In jedem lokalen Rechenzentrum sind Sie für den gesamten Stapel zuständig. Bei einem Wechsel von Ressourcen in die Cloud wird dagegen ein Teil der Zuständigkeit auf Microsoft übertragen. Das folgende Diagramm zeigt die Bereiche und die Aufteilung der Verantwortung zwischen Ihnen und Microsoft je nach Art der Bereitstellung.
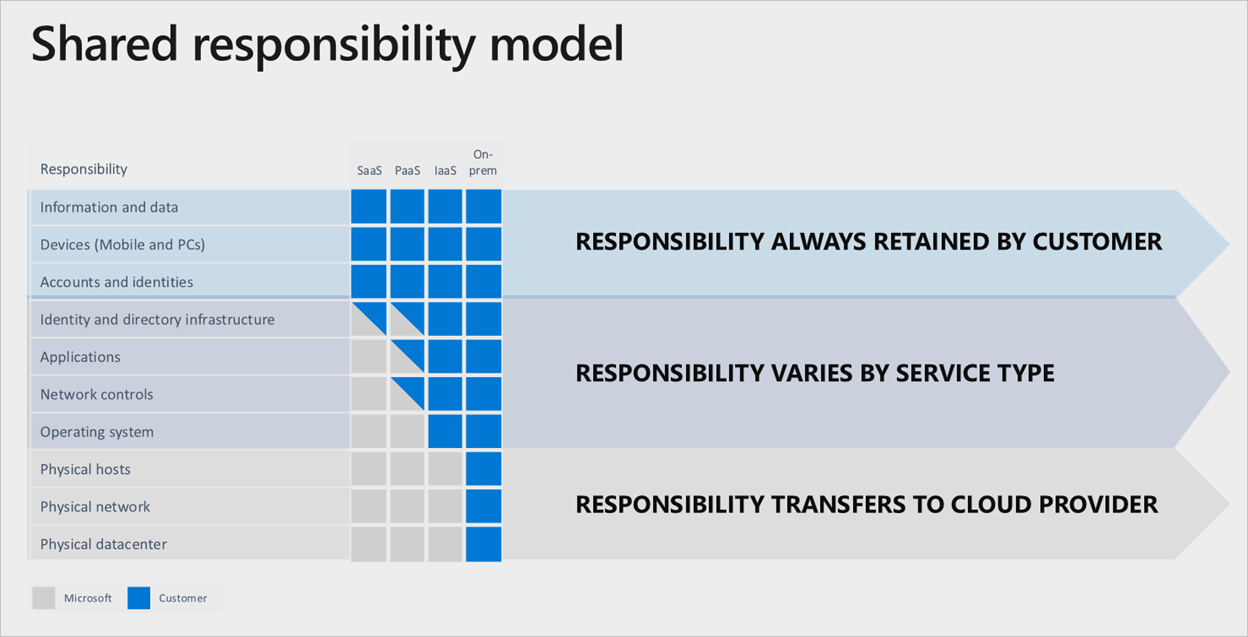
Ein gutes Beispiel für das Modell der gemeinsamen Verantwortung ist die Bereitstellung virtueller Computer. Wenn Sie die regionsübergreifende Replikation für Ausfall von Regionen einrichten möchten, müssen Sie einen doppelten Satz virtueller Computer in einer alternativen aktivierten Region bereitstellen. Azure repliziert diese Dienste im Falle eines Fehlers nicht automatisch. Es liegt in Ihrer Verantwortung, erforderliche Ressourcen bereitzustellen. Sie müssen über einen Prozess verfügen, um primäre Regionen manuell zu ändern, oder Sie müssen einen Datenverkehrs-Manager verwenden, um Fehler zu erkennen und automatisch zu überschlagen.
Für alle Dienste zur kundenfähigen Notfallwiederherstellung gibt es für Sie als Anleitung eine öffentlich zugängliche Dokumentation. Ein Beispiel für eine öffentlich zugängliche Dokumentation zur kundenfähigen Notfallwiederherstellung finden Sie unter Azure Data Lake Analytics.
Weitere Informationen zum Modell der gemeinsamen Verantwortung finden Sie unter Microsoft Trust Center.
Compliance bei Geschäftskontinuität: Verantwortung auf Dienstebene
Jeder Dienst muss im Azure Business Continuity Manager-Tool entsprechende Business Continuity Disaster Recovery-Einträge (BCDR) vornehmen. Die Besitzer von Diensten können das Tool verwenden, um innerhalb eines Verbundmodells zu arbeiten und Anforderungen zu vervollständigen und einzubeziehen, die Folgendes umfassen:
Diensteigenschaften: Definiert den Dienst und die Art und Weise, wie Notfallwiederherstellung und Resilienz erreicht werden. Zudem wird der Verantwortliche für die Notfallwiederherstellung (für Technologie) identifiziert. Weitere Informationen zum Wiederherstellungsbesitz finden Sie in der Diskussion über das Modell der gemeinsamen Verantwortung im vorherigen Abschnitt und im Diagramm.
Analyse der geschäftlichen Auswirkungen: Diese Analyse hilft dem Besitzer des Diensts bei der Definition von RTO (Recovery Time Objective) und RPO (Recovery Point Objective) auf der Grundlage der Kritikalität des Diensts anhand einer Tabelle der Auswirkungen. Betriebliche, rechtliche, regulatorische, markenbezogene und finanzielle Auswirkungen werden als Zielvorgaben für die Wiederherstellung verwendet.
Hinweis
Microsoft veröffentlicht RTO oder RPO nicht für Dienste, da diese Daten nur für interne Maßnahmen bestimmt sind. Alle kundenorientierten Zusagen und Maßnahmen sind SLA-basiert, da sie eine größere Bandbreite abdecken als RTO oder RPO, die nur bei katastrophalen Verlusten anwendbar sind.
Abhängigkeiten: Jeder Dienst ordnet die Abhängigkeiten (andere Dienste) zu, die für den Betrieb erforderlich sind, unabhängig davon, wie kritisch sie sind. Außerdem erfolgt die Zuordnung zur Runtime oder er ist nur für die Wiederherstellung erforderlich oder beides. Wenn es Speicherabhängigkeiten gibt, werden weitere Daten zugeordnet, die den Umfang der Speicherung definieren und ob beispielsweise Momentaufnahmen zu einem bestimmten Zeitpunkt erforderlich sind.
Mitarbeiter: Wie in der Definition eines Diensts erwähnt, ist es wichtig, den Standort und die Anzahl der Mitarbeiter zu kennen, die den Dienst unterstützen können, um sicherzustellen, dass kein Single Point of Failure vorhanden ist, und dass entscheidende Mitarbeiter verteilt sind, um Ausfälle durch das Zusammenwirken an einem einzelnen Standort zu vermeiden.
Externe Lieferanten: Microsoft führt eine umfassende Liste externer Lieferanten, und die als kritisch eingestuften Lieferanten werden auf ihre Fähigkeiten hin überprüft. Wenn ein Dienst eine Abhängigkeit feststellt, werden die Fähigkeiten des Lieferanten mit den Anforderungen des Diensts verglichen, um sicherzustellen, dass ein Ausfall eines Drittanbieters die Azure-Dienste nicht beeinträchtigt.
Wiederherstellungsbewertung: Diese Bewertung ist für das Azure Business Continuity Management-Programm eindeutig. Diese Bewertung misst mehrere wichtige Elemente, um einen Resilienzscore zu erstellen:
- Bereitschaft zum Failover: Obwohl es einen Prozess geben kann, ist er möglicherweise nicht die erste Wahl für kurzfristige Ausfälle.
- Automatisierung des Failovers
- Automatisierung der Entscheidung für einen Failover.
Die zuverlässigste und kürzeste Zeit für einen Failover bietet ein Dienst, der automatisiert ist und keine menschliche Entscheidung erfordert. Ein automatisierter Dienst verwendet die Heartbeat-Überwachung oder synthetische Transaktionen, um festzustellen, dass ein Dienst ausgefallen ist, und um sofortige Abhilfemaßnahmen einzuleiten.
Wiederherstellungsplan und -test: Azure erfordert, dass jeder Dienst über einen detaillierten Wiederherstellungsplan verfügt und dass dieser Plan so getestet wird, als ob der Dienst aufgrund eines schwerwiegenden Ausfalls ausgefallen wäre. Die Wiederherstellungspläne müssen schriftlich festgehalten werden, damit jemand mit ähnlicher Qualifikation und Zugriff die Aufgaben abschließen kann. Ein schriftlicher Plan verhindert, dass man sich auf die Verfügbarkeit von Fachexperten verlassen muss.
Die Tests werden auf verschiedene Weise durchgeführt, einschließlich Selbsttests in einer Produktions- oder produktionsnahen Umgebung und im Rahmen von Übungen mit ausgefallenen Azure-Gesamtregionen in Canary-Regionsgruppen. Diese aktivierten Regionen sind identisch mit Produktionsregionen, können jedoch deaktiviert werden, ohne dass sich dies auf Ihre Dienste auswirkt. Die Tests gelten als integriert, da alle Dienste gleichzeitig betroffen sind.
Kundenaktivierung: Wenn Sie für die Einrichtung der Notfallwiederherstellung verantwortlich sind, ist Azure erforderlich, um anleitungen für öffentlich zugängliche Dokumentationen zu erhalten. Für alle diese Dienste werden Links zur Dokumentation und zu Einzelheiten über das Verfahren bereitgestellt.
Überprüfen Ihrer Compliance bei Geschäftskontinuität
Wenn ein Dienst seinen Eintrag für die Verwaltung der Geschäftskontinuität fertig gestellt hat, müssen Sie ihn zur Genehmigung vorlegen. Sie wird einer in der Verwaltung der Geschäftskontinuität erfahrenen Fachkraft zugewiesen, die den gesamten Eintrag auf Vollständigkeit und Qualität überprüft. Wenn der Eintrag alle Anforderungen erfüllt, wird er genehmigt. Ist dies nicht der Fall, wird er mit der Anforderung einer Überarbeitung abgelehnt. Dieses Verfahren stellt sicher, dass beide Parteien sich einig sind, dass die Anforderungen an die Geschäftskontinuität erfüllt wurden, und dass die Arbeit nur vom Besitzer des Diensts bescheinigt wird. Die internen Überwachungs- und Complianceteams von Azure führen außerdem regelmäßig Stichprobenentnahmen durch, um sicherzustellen, dass die bestmöglichen Daten übermittelt werden.
Testen von Diensten
Microsoft und Azure führen umfangreiche Tests sowohl für die Notfallwiederherstellung als auch für die Bereitschaft in Verfügbarkeitszonen durch. Die Dienste werden in einer Produktions- oder Vorproduktionsumgebung selbst getestet, um die unabhängige Wiederherstellbarkeit von Diensten zu demonstrieren, die nicht von größeren Plattformfailovern abhängig sind.
Um sicherzustellen, dass Dienste in einem echten Region-Down-Szenario ähnlich wiederherstellen können, werden Tests vom Typ "Pull-the-Plug" in Canary-Umgebungen durchgeführt, die vollständig bereitgestellte Regionen sind, die der Produktion entsprechen. So werden beispielsweise die Cluster, Racks und Stromversorgungseinheiten buchstäblich abgeschaltet, um einen Totalausfall der Region zu simulieren.
Während dieser Tests verwendet Azure denselben Produktionsprozess für Erkennung, Benachrichtigung, Reaktion und Wiederherstellung. Niemand erwartet eine Übung, und die Techniker, die für die Wiederherstellung herangezogen werden, sind die normalen Ressourcen der Bereitschaftsrotation. Durch diese Zeitplanung wird die Abhängigkeit von Fachexperten vermieden, die während eines tatsächlichen Ereignisses möglicherweise nicht verfügbar sind.
In diesen Tests sind Dienste enthalten, bei denen Sie für die Einrichtung der Notfallwiederherstellung nach der öffentlich zugänglichen Dokumentation von Microsoft verantwortlich sind. Serviceteams erstellen kundenähnliche Instanzen, um zu zeigen, dass die Notfallwiederherstellung durch den Kunden wie erwartet funktioniert und dass die bereitgestellten Anweisungen korrekt sind.
Weitere Informationen zu Zertifizierungen finden Sie im Microsoft Trust Center und im Abschnitt zur Compliance.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für