Tutorial: Automatisierte Validierungstests
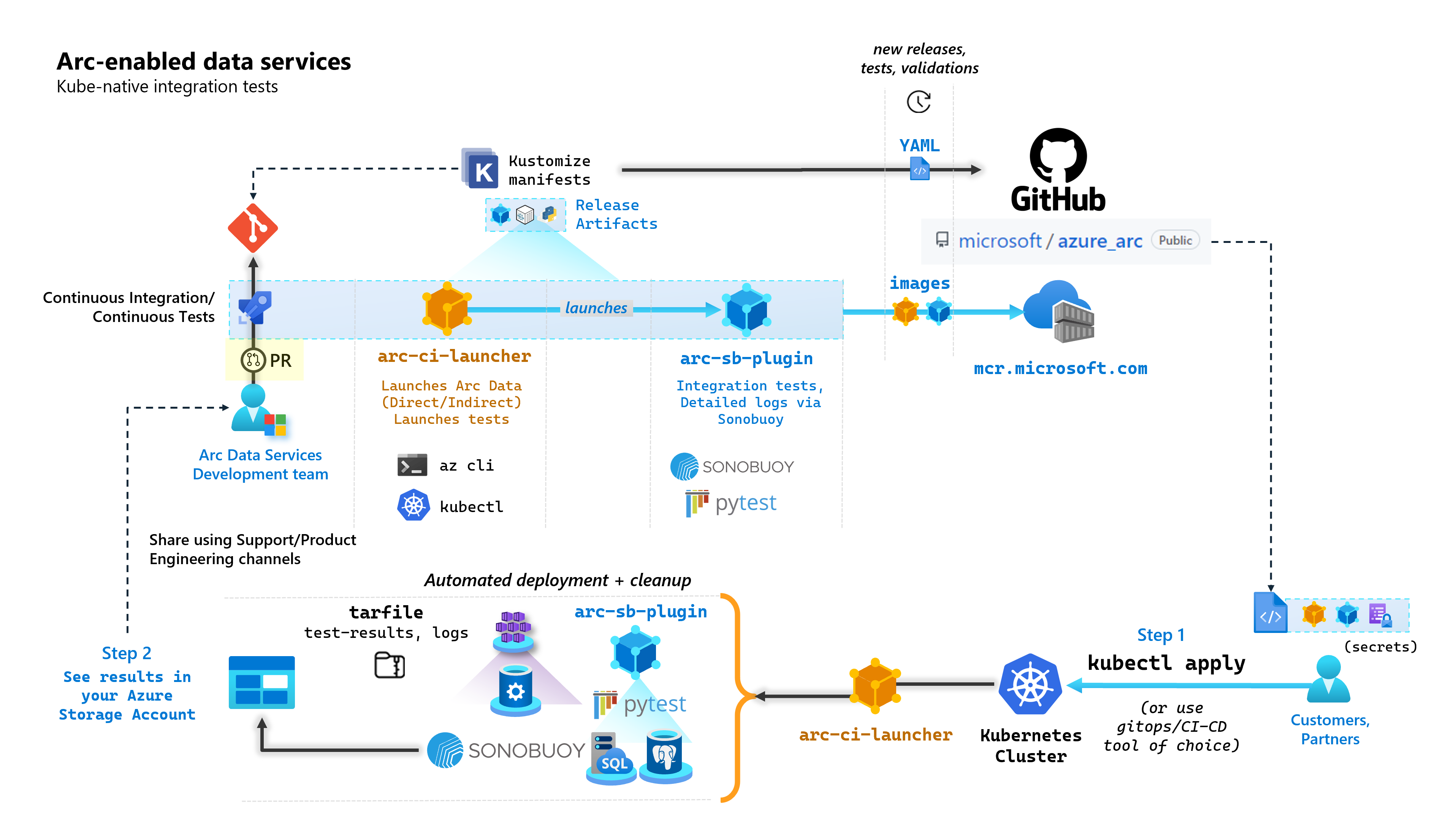
Bei jedem Commit, das Arc-fähige Datendienste aufbaut, führt Microsoft automatisierte CI/CD-Pipelines aus, die End-to-End-Tests durchführen. Diese Tests werden über zwei Container orchestriert, die zusammen mit dem Kernprodukt (Data Controller, SQL verwaltete Instanz aktiviert von Azure Arc & PostgreSQL Server) Standard enthalten sind. Bei diesen Containern handelt es sich um:
arc-ci-launcher: Enthält Bereitstellungsabhängigkeiten (z. B. CLI-Erweiterungen) sowie Produktbereitstellungscode (unter Verwendung der Azure CLI) für den direkten und den indirekten Konnektivitätsmodus. Sobald ein Onboarding von Kubernetes mit dem Datencontroller durchgeführt wurde, nutzt der Container Sonobuoy, um parallele Integrationstests auszulösen.arc-sb-plugin: Ein Sonobuoy-Plug-In mit Pytest-basierten End-to-End-Integrationstests, die von einer einfachen Feuerprobe (Bereitstellungen, Löschungen) bis hin zu komplexen Hochverfügbarkeitsszenarien, Chaostests (Ressourcenlöschungen) usw. reichen.
Diese Testcontainer werden öffentlich zugänglich gemacht, damit Kunden und Partner Arc-fähige Datendienste in ihren eigenen, an beliebigen Standorten betriebenen Kubernetes-Clustern testen und validieren können:
- Kubernetes-Distributionen/-Versionen
- Hostdistributionen/-versionen
- Speicher (
StorageClass/CSI), Netzwerk (z. B.LoadBalancers, DNS) - Weitere Kubernetes- oder infrastrukturspezifische Einrichtung
Kunden, die beabsichtigen, Arc-fähige Datendienste auf einer nicht dokumentierten Distribution auszuführen, müssen diese Validierungstests erfolgreich durchführen, damit die Version als unterstützt betrachtet wird. Darüber hinaus können Partner diesen Ansatz nutzen, um die Konformität ihrer Lösung mit Arc-fähigen Datendiensten zu zertifizieren – siehe Kubernetes-Validierung von Datendiensten mit Azure Arc-Unterstützung.
Die folgende Abbildung skizziert diesen allgemeinen Prozess:
In diesem Tutorial lernen Sie Folgendes:
- Bereitstellen von
arc-ci-launcherunter Verwendung vonkubectl - Überprüfen der Ergebnisse von Validierungstests in Ihrem Azure Blob Storage-Konto
Voraussetzungen
Anmeldeinformationen:
- Die Datei
test.env.tmplenthält die erforderlichen Anmeldeinformationen und ist eine Kombination der vorhandenen Voraussetzungen, die zum Einbinden eines mit Azure Arc verbundenen Clusters und eines direkt verbundenen Datencontrollers erforderlich sind. Die Einrichtung dieser Datei wird im Folgenden anhand von Beispielen erläutert. - Eine kubeconfig-Datei für den getesteten Kubernetes-Cluster mit
cluster-admin-Zugriff (derzeit zum Onboarding des verbundenen Clusters erforderlich)
- Die Datei
Clienttools:
kubectlmuss installiert sein, Mindestversion (Major:1, Minor:21)git-Befehlszeilenschnittstelle (oder UI-basierte Alternativen)
Vorbereitung des Kubernetes-Manifests
Das Startprogramm wird als Bestandteil des Repositorys microsoft/azure_arc als Kustomize-Manifest zur Verfügung gestellt („Kustomize“ ist in kubectl integriert), sodass kein zusätzliches Tool benötigt wird.
- Klonen Sie das Repository lokal:
git clone https://github.com/microsoft/azure_arc.git
- Navigieren Sie zu
azure_arc/arc_data_services/test/launcher, um die folgende Ordnerstruktur anzuzeigen:
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
In diesem Tutorial konzentrieren wir uns auf die Schritte für AKS, aber die obige Overlaystruktur kann auf weitere Kubernetes-Distributionen erweitert werden.
Das einsatzbereite Manifest enthält Folgendes:
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
Es gibt zwei Dateien, die erstellt werden müssen, um das Startprogramm für die Ausführung in einer bestimmten Umgebung zu lokalisieren. Jede dieser Dateien kann durch Kopieren und Ausfüllen der obigen Vorlagendateien (*.tmpl) erstellt werden:
.test.env: Ausfüllen von.test.env.tmplpatch.json: Ausfüllen vonpatch.json.tmpl
Tipp
.test.env ist ein einzelner Satz von Umgebungsvariablen, die das Verhalten des Startprogramms steuern. Durch die sorgfältige Erstellung für eine vorgegebene Umgebung wird die Reproduzierbarkeit des Startprogrammverhaltens sichergestellt.
Konfiguration 1: .test.env
Nachfolgend finden Sie ein ausgefülltes Beispiel Datei .test.env, die auf der Grundlage von .test.env.tmpl erstellt wurde (einschließlich von Inline-Kommentaren).
Wichtig
Die nachstehende export VAR="value"-Syntax ist nicht für die lokale Ausführung zum Abrufen von Umgebungsvariablen von Ihrem Rechner vorgesehen, sondern für das Startprogramm bestimmt. Das Startprogramm bindet diese .test.env-Datei in unveränderter Form über den secretGenerator von Kubernetes als Kubernetes-Geheimnis (secret) ein (Kustomize nimmt eine Datei, codiert den gesamten Inhalt der Datei in Base64 und wandelt ihn in ein Kubernetes-Geheimnis um). Während der Initialisierung führt das Startprogramm den Bash-Befehl source aus, der die Umgebungsvariablen aus der in unverändertem Zustand eingebundenen .test.env-Datei in die Umgebung des Startprogramms importiert.
Anders ausgedrückt: Nachdem Sie .test.env.tmpl kopiert und bearbeitet haben, um .test.env zu erstellen, sollte die generierte Datei ähnlich wie das nachstehende Beispiel aussehen. Der Vorgang zum Ausfüllen der .test.env-Datei ist für alle Betriebssysteme und Terminals identisch.
Tipp
Es gibt eine Handvoll Umgebungsvariablen, die aus Gründen der Nachvollziehbarkeit einer zusätzlichen Erklärung bedürfen. Diese werden mit see detailed explanation below [X] kommentiert.
Tipp
Hinweis: Das folgende .test.env-Beispiel bezieht sich auf den direkten Modus. Einige dieser Variablen, wie z. B. ARC_DATASERVICES_EXTENSION_VERSION_TAG, gelten nicht für den indirekten Modus. Der Einfachheit halber ist es am besten, die .test.env-Datei unter Berücksichtigung der Variablen für den direkten Modus einzurichten. Wenn Sie CONNECTIVITY_MODE=indirect umschalten, ignoriert das Startprogramm die spezifischen Einstellungen für den direkten Modus und verwendet eine Teilmenge aus der Liste.
Anders ausgedrückt: Die Planung für den direkten Modus ermöglicht es uns, die Variablen des indirekten Modus zu erfüllen.
Fertiges Beispiel für .test.env:
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
Wichtig
Wenn Sie die Konfigurationsdatei auf einem Windows-Computer erstellen, müssen Sie die Zeilenumbruchsequenz von CRLF (Windows) in LF (Linux) konvertieren, da arc-ci-launcher als Linux-Container ausgeführt wird. Wenn Sie die Zeile auf CRLF enden lassen, kann dies zu einem Fehler beim Start des arc-ci-launcher-Containers wie dem folgenden führen: /launcher/config/.test.env: $'\r': command not found Führen Sie die Änderung zum Beispiel mit VSCode (unten rechts im Fenster) durch:

Ausführliche Erläuterung für bestimmte Variablen
1. ARC_DATASERVICES_EXTENSION_* – Erweiterungsversion und Train
Obligatorisch: Diese Variable ist für Bereitstellungen im Modus
directerforderlich.
Das Startprogramm kann sowohl GA- als auch Prä-GA-Versionen bereitstellen.
Die Zuordnung der Erweiterungsversion zum Releasetrain (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) wird von hier aus abgerufen:
- GA:
stable- Versionsprotokoll - Prä-GA:
preview- Tests vor dem Release
2. ARC_DATASERVICES_WHL_OVERRIDE – Download-URL für vorherige Azure CLI-Version
Optional: Lassen Sie diese Variable in
.test.envleer, um die vordefinierte Standardeinstellung zu verwenden.
Das Startprogrammimage ist zum Veröffentlichungszeitpunkt der einzelnen Containerimages mit der neuesten arcdata-CLI-Version vorkonfiguriert. Um jedoch mit älteren Versionen zu arbeiten und Upgradetests durchzuführen, kann es notwendig sein, dem Startprogramm einen Downloadlink für die Azure CLI-Blob-URL zur Verfügung zu stellen, um die vorkonfigurierte Version zu überschreiben. Wenn Sie das Startprogramm z. B. anweisen möchten, Version 1.4.3 zu installieren, geben Sie Folgendes ein:
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
Eine Zuordnung zwischen CLI-Version und Blob-URL finden Sie hier.
3. CUSTOM_LOCATION_OID – Benutzerdefinierte Objekt-ID des Locations-Objekts von Ihrem spezifischen Microsoft Entra-Mandanten
Obligatorisch: Diese Variable ist zum Erstellen des benutzerdefinierten Speicherorts für den verbundenen Cluster erforderlich.
Anhand der folgenden Schritte aus Aktivieren benutzerdefinierter Speicherorte im Cluster können Sie die eindeutige Objekt-ID eines benutzerdefinierten Speicherorts für Ihren Azure AD-Mandanten abrufen.
Es gibt zwei Ansätze zum Abrufen des CUSTOM_LOCATION_OID Microsoft Entra-Mandanten.
Über die Azure CLI:
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Navigieren Sie über das Azure-Portal zu Ihrem Microsoft Entra-Blatt, und suchen Sie nach
Custom Locations RP: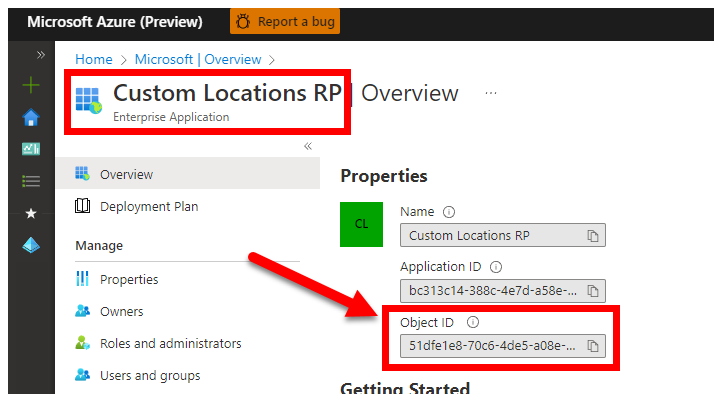
4. SPN_CLIENT_* – Anmeldeinformationen für Dienstprinzipal
Obligatorisch: Diese Variable ist für Bereitstellungen im direkten Modus erforderlich.
Das Startprogramm meldet sich mit diesen Anmeldeinformationen bei Azure an.
Validierungstests sollen für Kubernetes-Cluster und Azure-Abonnements ohne Produktion/Test durchgeführt werden – schwerpunktmäßig auf die funktionale Validierung des Kubernetes/Infrastruktur-Setups. Um die zur Durchführung von Starts erforderlichen manuellen Schritte zu vermeiden, empfiehlt es sich daher, ein SPN_CLIENT_ID/SECRET anzugeben, das über die Rolle Owner auf Ebene der Ressourcengruppe (oder des Abonnements) verfügt. Dadurch werden mehrere Ressourcen in dieser Ressourcengruppe erstellt, und diesen Ressourcen werden Berechtigungen für verschiedene verwaltete Identitäten zugewiesen, die im Rahmen der Bereitstellung erstellt wurden (diese Rollenzuweisungen erfordern wiederum, dass dem Dienstprinzipal die Rolle Owner zugewiesen ist).
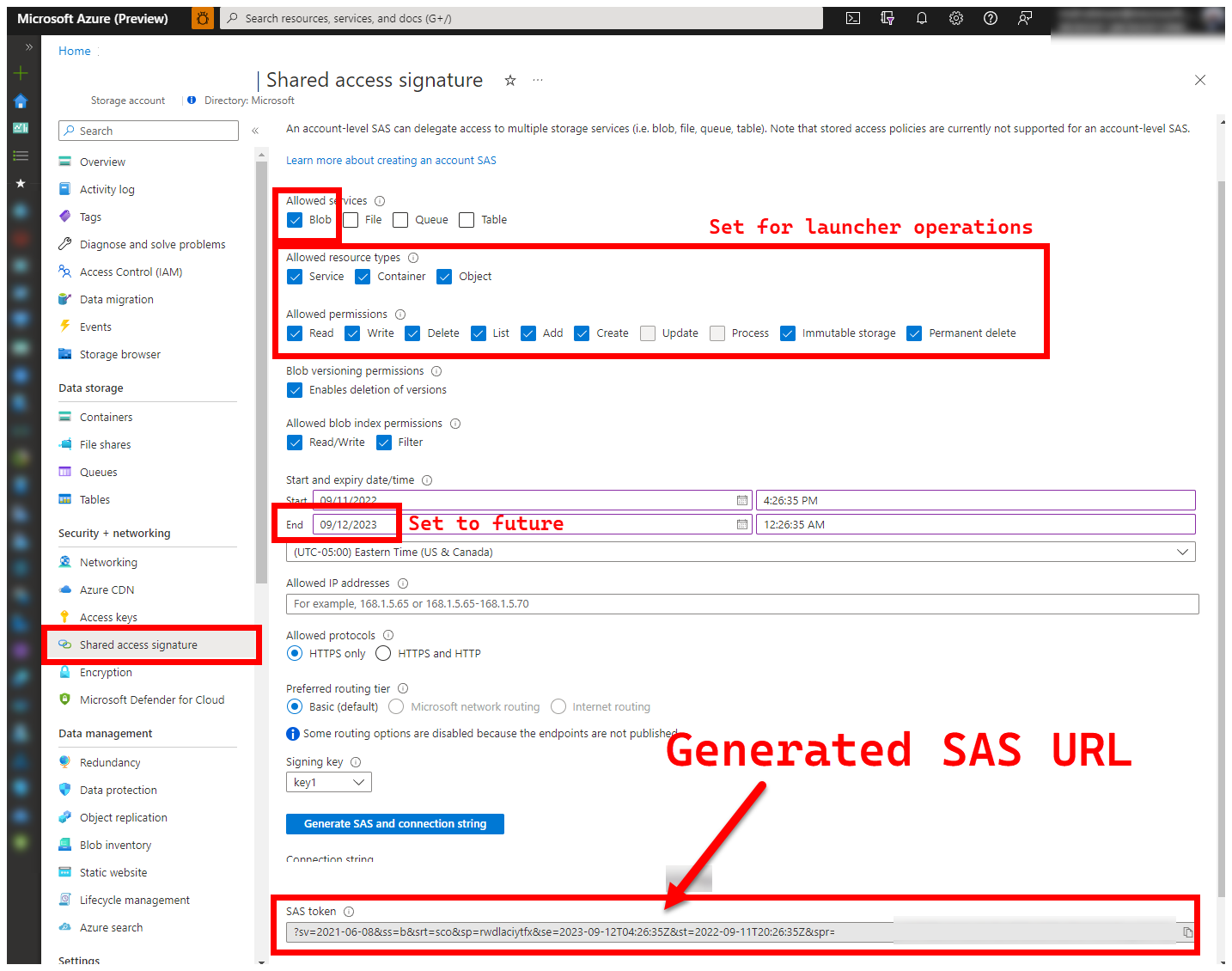
5. LOGS_STORAGE_ACCOUNT_SAS – SAS-URL für Blob Storage-Konto
Empfohlen: Wenn Sie diese Variable leer lassen, erhalten Sie keine Testergebnisse und Protokolle.
Das Startprogramm benötigt einen persistenten Speicherort (Azure Blob Storage), in den die Ergebnisse hochgeladen werden können, da Kubernetes das Kopieren von Dateien aus angehaltenen/abgeschlossenen Pods (noch) nicht erlaubt, siehe hier. Das Startprogramm stellt die Verbindung mit Azure Blob Storage über eine kontospezifische SAS-URL (im Gegensatz zur container- oder blobspezifischen URL) her. Dabei handelt es sich um eine signierte URL mit einer Definition für den zeitlich begrenzten Zugriff – siehe Gewähren von eingeschränktem Zugriff auf Azure Storage-Ressourcen mithilfe von SAS (Shared Access Signature). Dies geschieht, um folgende Aufgaben auszuführen:
- Erstellen eines neuen Speichercontainers im bestehenden Speicherkonto (
LOGS_STORAGE_ACCOUNT), sofern dieser noch nicht vorhanden ist (Name basiert aufLOGS_STORAGE_CONTAINER) - Erstellen eines neuen, eindeutig benannten Blobs (Testprotokoll-TAR-Dateien)
Die folgenden Schritte stammen aus Gewähren von eingeschränktem Zugriff auf Azure Storage-Ressourcen mithilfe von SAS (Shared Access Signature).
Tipp
Die SAS-URLs unterscheiden sich vom Schlüssel des Speicherkontos. Eine SAS-URL ist wie folgt formatiert:
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
Es gibt verschiedene Ansätze zum Generieren einer SAS-URL. In diesem Beispiel wird das Portal gezeigt:
Wenn Sie stattdessen die Azure CLI verwenden möchten, finden Sie weitere Informationen unter az storage account generate-sas.
6. SKIP_* – Steuern des Startprogrammverhaltens durch Überspringen bestimmter Stufen
Optional: Lassen Sie diese Variable in
.test.envleer, um alle Stufen auszuführen (gleichbedeutend mit0oder leer).
Das Startprogramm macht SKIP_*-Variablen verfügbar, um bestimmte Schritte auszuführen und zu überspringen – etwa, um eine Ausführung ausschließlich zur Bereinigung durchzuführen.
Wenngleich das Startprogramm so konzipiert ist, dass sowohl zu Beginn als auch am Ende jeder Ausführung eine Bereinigung stattfindet, bleiben aufgrund von Start- und/oder Testfehlern möglicherweise Ressourcenrückstände zurück. Um das Startprogramm im reinen Bereinigungsmodus auszuführen, legen Sie die folgenden Variablen in .test.env fest:
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
Die obigen Einstellungen weisen das Startprogramm an, alle Ressourcen von Arc und Arc-Datendiensten zu bereinigen und keine Protokolle bereitzustellen/zu testen/zu laden.
Konfiguration 2: patch.json
Nachfolgend finden Sie ein ausgefülltes Beispiel der Datei patch.json, die auf der Grundlage von patch.json.tmpl erstellt wurde (einschließlich von Inline-Kommentaren):
Hinweis:
spec.docker.registry, repository, imageTagsollte mit den Werten in der obigen.test.env-Datei identisch sein.
Fertiges Beispiel für patch.json:
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
Bereitstellung des Startprogramms
Es wird empfohlen, das Startprogramm in einem Nicht-Produktionscluster/Testcluster bereitzustellen, da es destruktive Aktionen für Arc und andere verwendete Kubernetes-Ressourcen durchführt.
imageTag-Spezifikation
Das Startprogramm wird im Kubernetes-Manifest als Job definiert. Dazu muss Kubernetes mitgeteilt werden, wo das Image des Startprogramms zu finden ist. Diese Festlegung erfolgt in base/kustomization.yaml:
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
Tipp
Wir fassen noch einmal zusammen: Es gibt 3 Stellen, an denen wir imageTags angegeben haben. Zum besseren Verständnis folgt eine Erläuterung der verschiedenen Verwendungszwecke für jede dieser Stellen. Wenn Sie eine bestimmte Version testen, stimmen in der Regel alle 3 Werte überein (entsprechend einer bestimmten Version):
| # | Dateiname | Variablenname | Warum? | Verwendet von? |
|---|---|---|---|---|
| 1 | .test.env |
DOCKER_TAG |
Abrufen des Bootstrapperimages im Rahmen der Erweiterungsinstallation | az k8s-extension create im Startprogramm |
| 2 | patch.json |
value.imageTag |
Abrufen des Datencontrollerimages | az arcdata dc create im Startprogramm |
| 3 | kustomization.yaml |
images.newTag |
Abrufen des Startprogrammimages | kubectl apply für das Startprogramm |
kubectl apply
Um sicherzustellen, dass das Manifest ordnungsgemäß eingerichtet wurde, führen Sie eine clientseitige Validierung mit --dry-run=client durch. Diese gibt die Kubernetes-Ressourcen aus, die für das Startprogramm erstellt werden müssen:
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
Führen Sie die folgenden Schritte aus, um das Startprogramm und die Protokollfragmente bereitzustellen:
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
Nun sollte das Startprogramm starten – und Sie sollten Folgendes sehen:
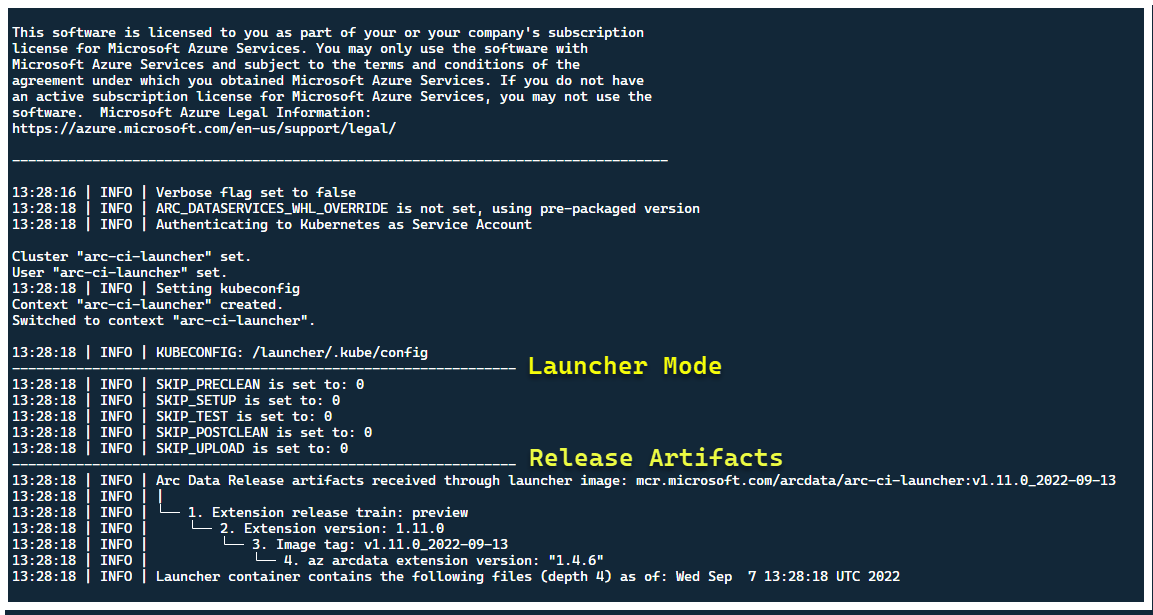
Am besten stellen Sie das Startprogramm in einem Cluster ohne bereits vorhandene Arc-Ressourcen bereit. Das Startprogramm umfasst jedoch eine Preflight-Überprüfung, um bereits vorhandene benutzerdefinierte Ressourcendefinitionen und ARM-Ressourcen von Arc und Arc-Datendiensten zu erkennen, und versucht, diese vor der Bereitstellung der neuen Version bestmöglich zu bereinigen (unter Verwendung der bereitgestellten Anmeldeinformationen für den Dienstprinzipal):
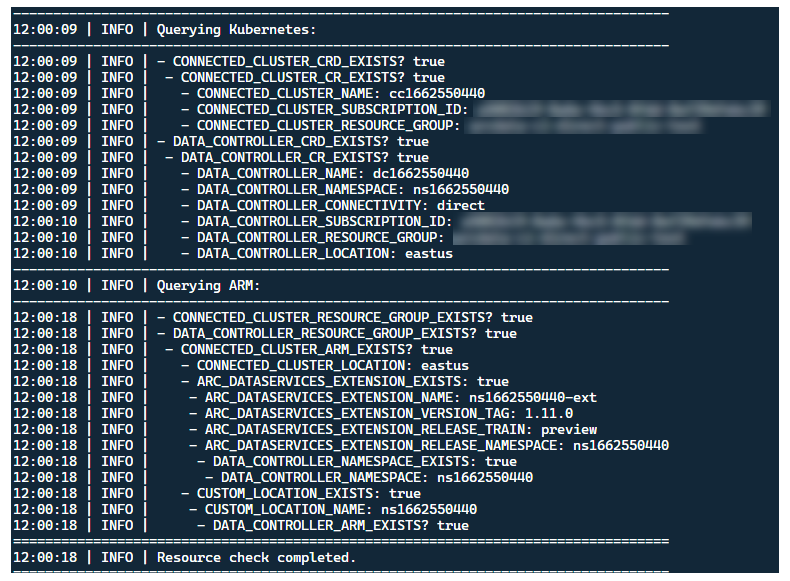
Derselbe Prozess der Metadatenermittlung und -bereinigung wird auch beim Beenden des Startprogramms durchgeführt, um den Cluster weitestgehend in dem Zustand zurückzuversetzen, in dem er sich vor dem Start befand.
Vom Startprogramm ausgeführte Schritte
Allgemein betrachtet führt das Startprogramm die folgende Abfolge von Schritten durch:
Authentifizierung bei der Kubernetes-API mithilfe eines podgebundenen Dienstkontos.
Authentifizierung bei der ARM-API mithilfe eines geheimnisgebundenen Dienstkontos.
Durchführen einer CRD-Metadatenüberprüfung zum Ermitteln vorhandener benutzerdefinierter Ressourcen von Arc und Arc-Datendiensten.
Bereinigen aller vorhandenen benutzerdefinierten Ressourcen in Kubernetes sowie nachfolgend der Ressourcen in Azure. Beendigung, falls die Anmeldedaten in
.test.envnicht mit den im Cluster vorhandenen Ressourcen übereinstimmen.Generieren eines eindeutigen Satzes von Umgebungsvariablen basierend auf dem Zeitstempel für den Arc-Clusternamen, den Datencontroller und den benutzerdefinierten Speicherort/Namespace. Ausgabe der Umgebungsvariablen, wobei vertrauliche Werte unkenntlich gemacht werden (z. B. das Kennwort für den Dienstprinzipal usw.).
a. Für den direkten Modus – Durchführen des Onboarding des Clusters in Azure Arc, anschließend Bereitstellung des Controllers.
b. Für den indirekten Modus: Bereitstellen des Datencontrollers.
Sobald der Datencontroller in den Zustand
Readyübergegangen ist, werden verschiedene Azure CLI-Protokolle (az arcdata dc debug) erstellt und lokal gespeichert, gekennzeichnet alssetup-complete– als Baseline.Verwenden der Umgebungsvariable
TESTS_DIRECT/INDIRECTaus.test.envzum Starten einer Reihe parallelisierter Sonobuoy-Testläufe basierend auf einem durch Leerzeichen getrennten Array (TESTS_(IN)DIRECT). Diese Ausführungen erfolgen in einem neuensonobuoy-Namespace unter Verwendung einesarc-sb-plugin-Pods, der die Pytest-Validierungstests enthält.Der Sonobuoy-Aggregator sammelt die
junit-Testergebnisse und Protokolle für jedenarc-sb-plugin-Testlauf und exportiert sie in den Startprogrammpod.Rückgabe des Exitcodes der Tests und Generierung eines weiteren Satzes von Debugprotokollen – Azure CLI und
sonobuoy–, die lokal gespeichert und alstest-completegekennzeichnet werden.Durchführen einer CRD-Metadatenüberprüfung (ähnlich wie in Schritt 3) zum Ermitteln vorhandener benutzerdefinierter Ressourcen von Arc und Arc-Datendiensten Anschließende Zerstörung aller Arc-Ressourcen und Arc-Datenressourcen in umgekehrter Reihenfolge ihrer Bereitstellung sowie der benutzerdefinierten Ressourcendefinitionen, Rollen/Clusterrollen, PV/PVCs usw.
Versuch, mit dem bereitgestellten SAS-Token
LOGS_STORAGE_ACCOUNT_SASeinen neuen Speicherkontocontainer mit dem NamenLOGS_STORAGE_CONTAINERim bereits vorhandenen SpeicherkontoLOGS_STORAGE_ACCOUNTzu erstellen. Wenn der Speicherkontocontainer bereits vorhanden ist, wird er verwendet. Hochladen aller lokalen Testergebnisse und Protokolle in diesen Speichercontainer als Tarball (siehe unten).Beenden
Pro Testsammlung durchgeführte Tests
Es stehen ungefähr 375 eindeutige Integrationstests in 27 Testsammlungen zur Verfügung, von denen jede eine separate Funktionalität testet.
| Sammlungs-Nr. | Name der Testsammlung | Beschreibung des Tests |
|---|---|---|
| 1 | ad-connector |
Testet die Bereitstellung und Aktualisierung einer Active Directory Connector-Instanz (AD Connector). |
| 2 | billing |
Tests verschiedener unternehmenskritischer Lizenztypen spiegeln sich in der Ressourcentabelle im Controller wider, die für den Abrechnungsupload verwendet wird. |
| 3 | ci-billing |
Ähnlich wie billing, aber mit mehr CPU-/Arbeitsspeicherpermutationen. |
| 4 | ci-sqlinstance |
Zeitintensive Tests zur Erstellung mehrerer Replikate, Updates, Aktualisierung von GP auf BC, Sicherungsvalidierung und SQL Server-Agent. |
| 5 | controldb |
Testet die Steuerungsdatenbank: SA-Geheimnisüberprüfung, Überprüfung der Systemanmeldung, Überwachungserstellung und Integritätsüberprüfungen für SQL-Buildversion. |
| 6 | dc-export |
Abrechnung und Nutzungsupload im indirekten Modus. |
| 7 | direct-crud |
Erstellt eine SQL-Instanz unter Verwendung von ARM-Aufrufen, Validierung sowohl in Kubernetes als auch in ARM. |
| 8 | direct-fog |
Erzeugt mehrere SQL-Instanzen und erstellt mithilfe von ARM-Aufrufen eine Failovergruppe zwischen diesen. |
| 9 | direct-hydration |
Erstellt eine SQL-Instanz mit der Kubernetes-API, überprüft das Vorhandensein in ARM. |
| 10 | direct-upload |
Überprüft den Abrechnungsupload im direkten Modus. |
| 11 | kube-rbac |
Stellt sicher, dass die Kubernetes Service-Kontoberechtigungen für Arc-Datendienste den Erwartungen an die geringsten Rechte entsprechen. |
| 12 | nonroot |
Stellt sicher, dass Container als Nicht-Root-Benutzer*innen ausgeführt werden. |
| 13 | postgres |
Führt verschiedene Tests zum Erstellen, Skalieren und Sichern/Wiederherstellen von Postgres durch. |
| 14 | release-sanitychecks |
Plausibilitätsprüfungen für monatliche Releases, wie z. B. SQL Server-Buildversionen. |
| 15 | sqlinstance |
Verkürzte Version von ci-sqlinstance für schnelle Validierungen. |
| 16 | sqlinstance-ad |
Testet die Erstellung von SQL-Instanzen mit Active Directory Connector. |
| 17 | sqlinstance-credentialrotation |
Testen Sie die automatische Rotation von Anmeldeinformationen sowohl für allgemeine Zwecke als auch für unternehmenskritische Aufgaben. |
| 18 | sqlinstance-ha |
Verschiedene Stresstests zur Hochverfügbarkeit, einschließlich Podneustarts, erzwungenem Failover und Aussetzungen. |
| 19 | sqlinstance-tde |
Verschiedene TDE-Tests (Transparent Data Encryption). |
| 20 | telemetry-elasticsearch |
Überprüft die Protokollerfassung in Elasticsearch. |
| 21 | telemetry-grafana |
Überprüft, ob Grafana erreichbar ist. |
| 22 | telemetry-influxdb |
Überprüft die Metrikerfassung in InfluxDB. |
| 23 | telemetry-kafka |
Verschiedene Tests für Kafka mit SSL, Einzel-/Multi-Broker-Setup. |
| 24 | telemetry-monitorstack |
Testet Überwachungskomponenten, z. B. die Funktionsfähigkeit von Fluentbit und Collectd. |
| 25 | telemetry-telemetryrouter |
Testet OpenTelemetry. |
| 26 | telemetry-webhook |
Testet Data Services-Webhooks mit gültigen und ungültigen Aufrufen. |
| 27 | upgrade-arcdata |
Aktualisiert eine vollständige Sammlung von SQL-Instanzen (GP, BC 2-Replikat, BC 3-Replikat, mit Active Directory) und führt ein Upgrade von der Version des letzten Monats auf den neuesten Build durch. |
Zum Beispiel werden für sqlinstance-ha die folgenden Tests durchgeführt:
test_critical_configmaps_present: Stellt sicher, dass ConfigMaps und relevante Felder für eine SQL-Instanz vorhanden sind.test_suspended_system_dbs_auto_heal_by_orchestrator: Überprüft, obmasterundmsdbin irgendeiner Weise angehalten wurden (in diesem Fall durch eine(n) Benutzer*in). Der Abstimmungsvorgang bei der Orchestratorwartung behebt dies automatisch.test_suspended_user_db_does_not_auto_heal_by_orchestrator: Stellt sicher, dass keine automatische Behebung durch den Abstimmungsvorgang bei der Orchestratorwartung erfolgt, wenn eine Benutzerdatenbank absichtlich durch eine(n) Benutzer*in angehalten wird.test_delete_active_orchestrator_twice_and_delete_primary_pod: Löscht den Orchestratorpod mehrmals, gefolgt vom primären Replikat, und überprüft, ob alle Replikate synchronisiert wurden. Die Erwartungen im Hinblick auf die Failoverzeit für 2 Replikate sind gelockert.test_delete_primary_pod: Löscht das primäre Replikat und überprüft, ob alle Replikate synchronisiert wurden. Die Erwartungen im Hinblick auf die Failoverzeit für 2 Replikate sind gelockert.test_delete_primary_and_orchestrator_pod: Löscht das primäre Replikat und den Orchestratorpod und überprüft, ob alle Replikate synchronisiert wurden.test_delete_primary_and_controller: Löscht das primäre Replikat und den Datencontrollerpod und überprüft, ob der primäre Endpunkt erreichbar ist und das neue primäre Replikat synchronisiert wurde. Die Erwartungen im Hinblick auf die Failoverzeit für 2 Replikate sind gelockert.test_delete_one_secondary_pod: Löscht das sekundäre Replikat und den Datencontrollerpod und überprüft, ob alle Replikate synchronisiert wurden.test_delete_two_secondaries_pods: Löscht sekundäre Replikate und den Datencontrollerpod und überprüft, ob alle Replikate synchronisiert wurden.test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: Erzwingt ein Failover der Verfügbarkeitsgruppe aus dem aktuellen primären Replikat und stellt sicher, dass das neue primäre Replikat nicht dem alten primären Replikat entspricht. Überprüft, ob alle Replikate synchronisiert wurden.test_update_while_rebooting_all_non_primary_replicas: Testet, ob controllergesteuerte Aktualisierungen trotz verschiedener ungünstiger Umstände mit Wiederholungsversuchen stabil funktionieren.
Hinweis
Für bestimmte Tests wird möglicherweise spezielle Hardware benötigt, z. B. privilegierter Zugriff auf Domänencontroller für ad-Tests zum Erstellen von Konten und DNS-Einträgen. Diese Hardware steht möglicherweise nicht in allen Umgebungen zur Verfügung, die arc-ci-launcher verwenden möchten.
Untersuchen der Testergebnisse
Ein Beispiel für einen Speichercontainer und eine Datei, die vom Startprogramm hochgeladen wurden:
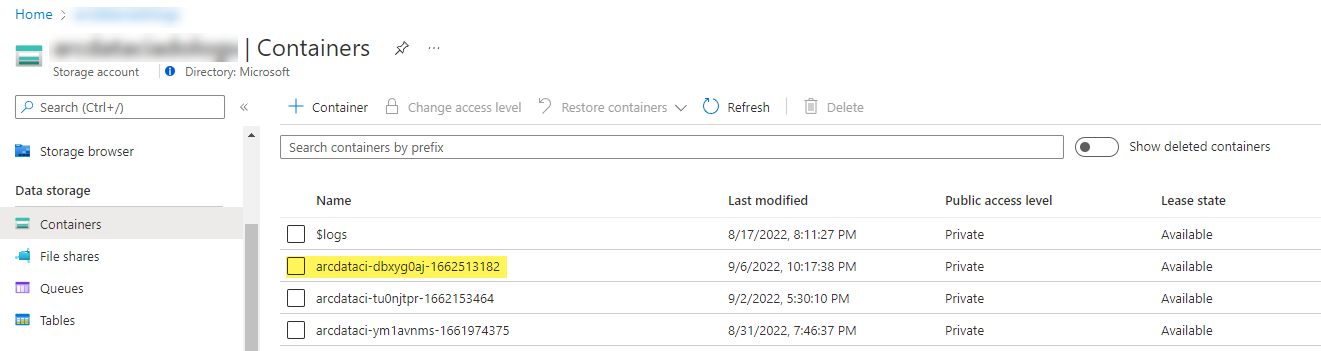
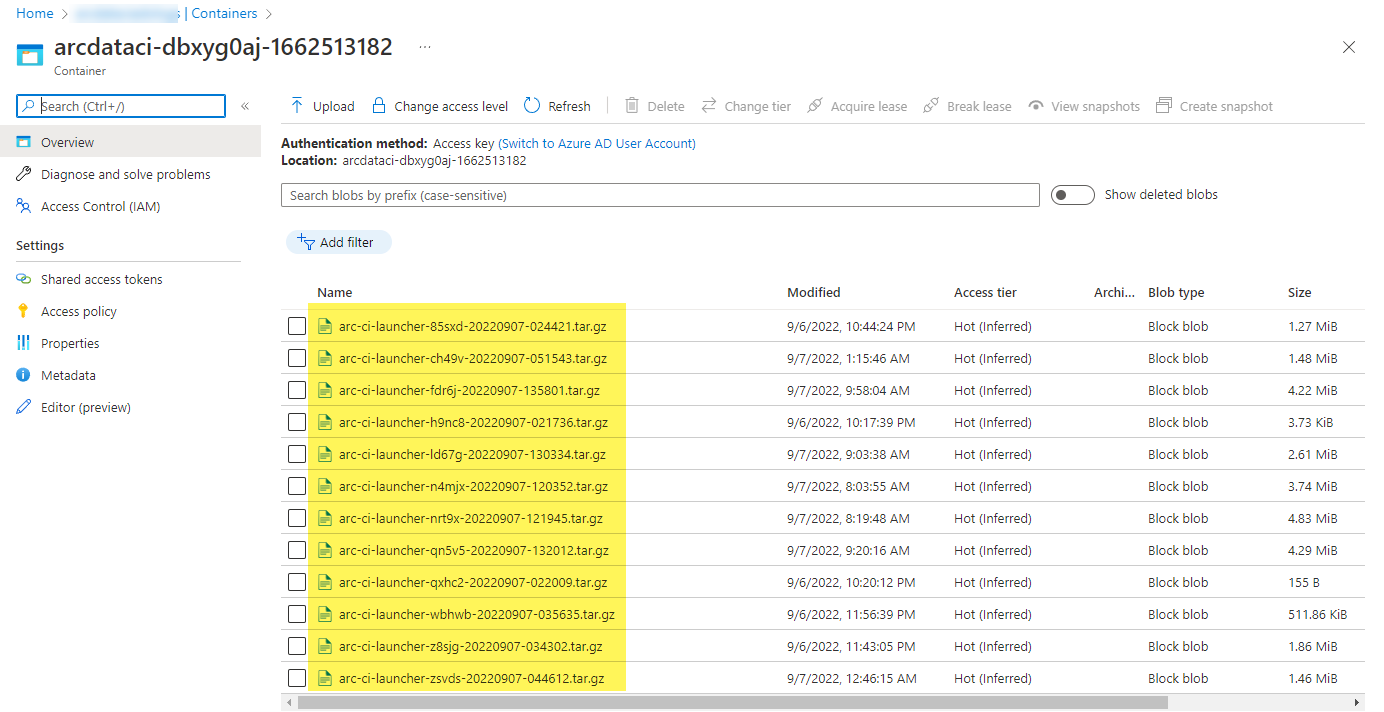
Und hier die Testergebnisse, die für die Ausführung generiert wurden:
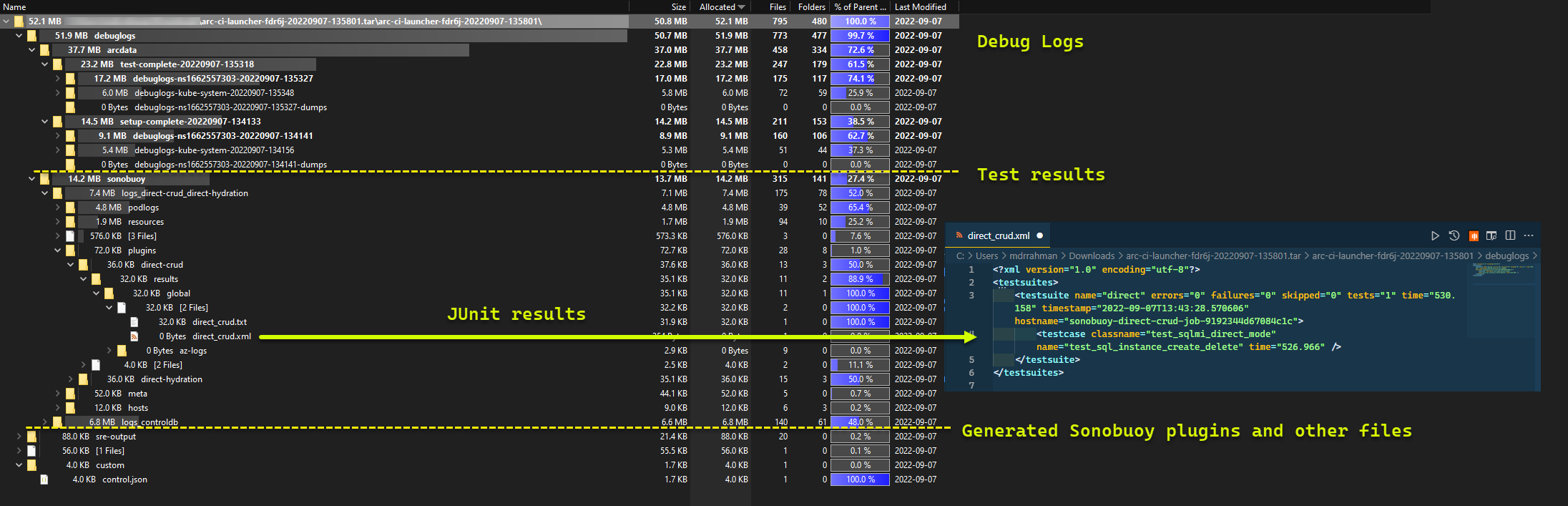
Bereinigen von Ressourcen
Führen Sie zum Löschen des Startprogramm den folgenden Befehl aus:
kubectl delete -k arc_data_services/test/launcher/overlays/aks
Hierdurch werden die Ressourcenmanifeste bereinigt, die als Bestandteil des Startprogramms bereitgestellt wurden.