Konfigurieren einer Failovergruppe – CLI
In diesem Artikel wird erläutert, wie Sie die Notfallwiederherstellung für von Azure Arc mit der CLI-aktivierten SQL Managed Instance konfigurieren. Bevor Sie fortfahren, überprüfen Sie die Informationen und Voraussetzungen in SQL Managed Instance, die von Azure Arc – Notfallwiederherstellung aktiviert sind.
Voraussetzungen
Die folgenden Voraussetzungen müssen erfüllt sein, bevor Sie Failover-Gruppen zwischen zwei Instanzen der von Azure Arc aktivierten SQL Managed Instance einrichten:
- Ein Azure Arc Datencontroller und eine Arc-fähige, verwaltete SQL-Instanz, die am primären Standort mit
--license-typeeiner vonBasePriceoderLicenseIncludedbereitgestellt werden. - Ein Azure Arc-Datenverantwortlicher und eine auf dem sekundären Standort bereitgestellte SQL-verwaltete Instanz mit identischer Konfiguration wie die primäre in Bezug auf:
- CPU
- Arbeitsspeicher
- Storage
- Dienstebene
- Sortierung
- Sonstige Instanzeinstellungen
- Die Instanz am sekundären Standort benötigt
--license-typealsDisasterRecovery. Diese Instanz muss neu sein, ohne dass Benutzerobjekte vorhanden sind.
Hinweis
- Es ist wichtig, den
--license-typewährend der Erstellung der verwalteten Instanz anzugeben. Dies ermöglicht der DR-Instanz, einen Seed von der primären Instanz im primären Rechenzentrum zu erhalten. Das Aktualisieren dieser Eigenschaft nach der Bereitstellung hat nicht die gleiche Auswirkung.
Bereitstellungsprozess
Führen Sie die folgenden Schritte aus, um eine Azure-Failover-Gruppe zwischen zwei Instanzen einzurichten:
- Erstellen einer benutzerdefinierten Ressource für eine verteilte Verfügbarkeitsgruppe am primären Standort
- Erstellen einer benutzerdefinierten Ressource für eine verteilte Verfügbarkeitsgruppe am sekundären Standort
- Kopieren der Binärdaten aus den Spiegelungszertifikaten
- Einrichten der verteilten Verfügbarkeitsgruppe zwischen dem primären und sekundären Standort, entweder im
sync-Modus oderasync-Modus
Die folgende Abbildung zeigt eine ordnungsgemäß konfigurierte verteilte Verfügbarkeitsgruppe:
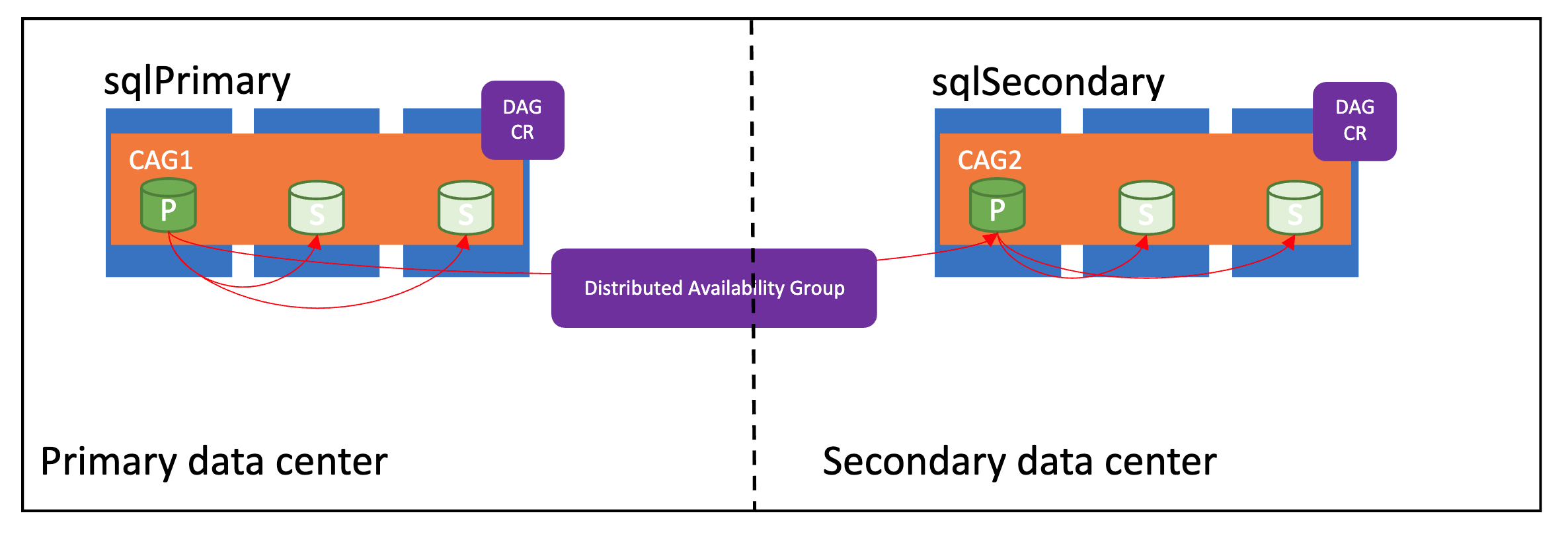
Synchronisierungsmodi
Failover-Gruppen in Azure Arc-Datendiensten unterstützen zwei Synchronisierungsmodi – sync und async. Der Synchronisierungsmodus wirkt sich direkt darauf aus, wie die Daten zwischen den Instanzen synchronisiert werden, und möglicherweise auf die Leistung auf der primären verwalteten Instanz.
Wenn sich primäre und sekundäre Standorte innerhalb weniger Meilen voneinander befinden, verwenden Sie den sync-Modus. Verwenden Sie andernfalls den async-Modus, um Leistungseinbußen auf den primären Standort zu vermeiden.
Konfigurieren der Azure-Failover-Gruppe – direkter Modus
Führen Sie die folgenden Schritte aus, wenn die Azure Arc-Datendienste im directly-verbundenen Modus bereitgestellt werden.
Nachdem die Voraussetzungen erfüllt sind, führen Sie den folgenden Befehl aus, um die Azure-Failover-Gruppe zwischen den beiden Instanzen einzurichten:
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Beispiel:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
Der obige Befehl führt Folgendes aus:
- Erstellt die erforderlichen benutzerdefinierten Ressourcen sowohl auf primären als auch auf sekundären Standorten
- Kopiert die Spiegelungszertifikate und konfiguriert die Failover-Gruppe zwischen den Instanzen
Konfigurieren der Azure-Failover-Gruppe – indirekter Modus
Führen Sie die folgenden Schritte aus, wenn Azure Arc-Datendienste im indirectly-verbundenen Modus bereitgestellt werden.
Stellen Sie die verwaltete Instanz am primären Standort bereit.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sWechseln Sie den Kontext zum sekundären Cluster, indem Sie
kubectl config use-context <secondarycluster>ausführen und die verwaltete Instanz am sekundären Standort bereitstellen, der die Notfallwiederherstellungsinstanz sein wird. An diesem Punkt sind die Systemdatenbanken nicht Teil der enthaltenen Verfügbarkeitsgruppe.Hinweis
Es ist wichtig,
--license-type DisasterRecoveryim Verlauf der verwalteten Instanz anzugeben. Dies ermöglicht der DR-Instanz, einen Seed von der primären Instanz im primären Rechenzentrum zu erhalten. Das Aktualisieren dieser Eigenschaft nach der Bereitstellung hat nicht die gleiche Auswirkung.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sSpiegelungszertifikate: Die Binärdaten innerhalb der „Mirroring Certificate“-Eigenschaft der verwalteten Instanz sind für die Erstellung der benutzerdefinierten Failovergruppenressource erforderlich.
Dafür stehen mehrere Methoden zur Verfügung:
(a) Wenn Sie
azCLI verwenden, generieren Sie zuerst die Spiegelungszertifikatdatei, und verweisen Sie dann beim Konfigurieren der Instanzfailovergruppe auf diese Datei, damit die Binärdaten aus der Datei gelesen und in die benutzerdefinierte Ressource kopiert werden. Die Zertifikatdateien werden nach der Failover-Gruppenerstellung nicht benötigt.(b) Wenn Sie
kubectlverwenden, kopieren Sie die Binärdaten direkt aus der benutzerdefinierten Ressource der verwalteten Instanz, und fügen Sie sie in die YAML-Datei ein, die zum Erstellen der Instanzfailovergruppe verwendet wird.Verwenden von (a) zuvor:
Erstellen der Spiegelungszertifikatdatei für die primäre Instanz:
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sBeispiel:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sErstellen einer Verbindung mit dem sekundären Cluster und Erstellen der Spiegelungszertifikatdatei für die sekundäre Instanz:
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sBeispiel:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sNachdem die Spiegelungszertifikatdateien erstellt wurden, kopieren Sie das Zertifikat aus der sekundären Instanz in einen freigegebenen/lokalen Pfad im primären Instanzcluster und umgekehrt.
Erstellen Sie die Failovergruppenressource an beiden Standorten.
Hinweis
Stellen Sie sicher, dass die SQL-Instanzen unterschiedliche Namen für primäre und sekundäre Standorte aufweisen; der Wert für
shared-namesollte bei beiden Standorten identisch sein.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sBeispiel:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sFühren Sie auf der sekundären Instanz den folgenden Befehl aus, um die benutzerdefinierte Failover-Gruppenressource einzurichten.
--partner-mirroring-cert-filesollte in diesem Fall auf einen Pfad verweisen, der die Spiegelungszertifikatdatei enthält, die von der primären Instanz generiert wurde, wie in 3(a) weiter oben beschrieben.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sBeispiel:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Abrufen des Integritätszustands der Azure-Failover-Gruppe
Informationen zur Failover-Gruppe, z. B. primäre Rolle, sekundäre Rolle und der aktuelle Integritätsstatus, können auf der benutzerdefinierten Ressource entweder am primären oder sekundären Standort angezeigt werden.
Führen Sie den folgenden Befehl auf dem primären und/oder sekundären Standort aus, um die benutzerdefinierte Ressource für Failover-Gruppen auflisten zu können:
kubectl get fog -n <namespace>
Beschreiben Sie die benutzerdefinierte Ressource zum Abrufen des Failover-Gruppenstatus wie folgt:
kubectl describe fog <failover group cr name> -n <namespace>
Failover Groups – Operations (Failovergruppen – Vorgänge)
Sobald die Failover-Gruppe zwischen den verwalteten Instanzen eingerichtet wurde, können abhängig von den Umständen unterschiedliche Failover-Vorgänge ausgeführt werden.
Mögliche Failover-Szenarien sind:
Die Instanzen an beiden Standorten befinden sich im fehlerfreien Zustand und ein Failover muss ausgeführt werden:
- Führen Sie ein manuelles Failover von primär auf sekundär ohne Datenverlust durch Festlegen des
role=secondaryam primären SQL MI aus.
- Führen Sie ein manuelles Failover von primär auf sekundär ohne Datenverlust durch Festlegen des
Der primäre Standort ist fehlerhaft/nicht erreichbar und ein Failover muss ausgeführt werden:
- die primäre verwaltete SQL-Instanz, die von Azure Arc aktiviert ist, ist ausgefallen/fehlerhaft/unerreichbar
- die sekundäre SQL Managed Instance, die von Azure Arc aktiviert wurde, muss zwangsweise zur primären Instanz befördert werden, was zu Datenverlusten führen kann
- Wenn die ursprüngliche primäre SQL Managed Instance, die von Azure Arc aktiviert wurde, wieder online geht, wird sie als
Primary-Rolle und ungesunder Zustand gemeldet und muss in einesecondary-Rolle gezwungen werden, damit sie der Failover-Gruppe beitreten kann und die Daten synchronisiert werden können.
Manuelles Failover (ohne Datenverlust)
Verwenden Sie die az sql instance-failover-group-arc update ...-Befehlsgruppe, um ein Failover von primär auf sekundär zu initiieren. Alle ausstehenden Transaktionen auf der geoprimären Instanz werden vor dem Failover auf der geosekundären Instanz repliziert.
Direkter Verbindungsmodus
Führen Sie den folgenden Befehl aus, um ein manuelles Failover mithilfe von ARM-APIs im direct-verbundenen Modus zu initiieren:
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Beispiel:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Indirekter Verbindungsmodus
Führen Sie den folgenden Befehl aus, um ein manuelles Failover mithilfe von Kubernetes-APIs im indirect-verbundenen Modus zu initiieren:
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Beispiel:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Erzwungenes Failover mit Datenverlust
Falls die geoprimäre Instanz nicht mehr verfügbar ist, können die folgenden Befehle zum Heraufstufen zur primären Instanz mit einem erzwungenen Failover mit potenziellem Datenverlust auf der geosekundären DR-Instanz ausgeführt werden.
Führen Sie auf der geosekundären DR-Instanz den folgenden Befehl aus, um sie mit Datenverlust zur primären Rolle heraufzustufen.
Hinweis
Wenn die --partner-sync-mode Konfiguration als sync erfolgt ist, muss sie auf zurückgesetzt async werden, an dem die sekundäre zur primären höhergestuft wird.
Direkter Verbindungsmodus
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Beispiel:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Indirekter Verbindungsmodus
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
Wenn die Instanz am primären geografischen Standort verfügbar ist, führen Sie den folgenden Befehl aus, um sie in die Failovergruppe zu übertragen und die Daten zu synchronisieren:
Direkter Verbindungsmodus
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Indirekter Verbindungsmodus
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
Optional kann --partner-sync-mode bei Bedarf wieder in den sync-Modus zurück konfiguriert werden.
Nach Failover-Vorgängen
Nachdem Sie ein Failover vom primären Standort zum sekundären Standort ausgeführt haben, entweder mit oder ohne Datenverlust, müssen Sie möglicherweise Folgendes tun:
- Aktualisieren Sie die Verbindungszeichenfolge für Ihre Anwendungen, um eine Verbindung mit der neuen primären, von Arc SQL verwalteten Instanz herzustellen
- Wenn Sie planen, den Produktions-Workload weiterhin am sekundären Standort auszuführen, aktualisieren Sie die
--license-typeauf entwederBasePriceoderLicenseIncluded, um die Abrechnung für die verbrauchten vCores einzuleiten.