Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Durable Functions bietet mehrere Diagnosetools zur Fehlerbehebung bei Orchestrierungen. In diesem Artikel wird beschrieben, wie Sie Tracking und Protokollierung konfigurieren, replay-sicheren Code schreiben, verteilte Ablaufverfolgungen überprüfen und lokal debuggen.
In diesem Artikel erfahren Sie, wie Sie:
- Konfigurieren der Application Insights-Nachverfolgung für Lebenszyklusereignisse
- Abfrage von Orchestrierungsinstanzen mit Kusto
- Aktivieren Sie die Protokollierung des Durable Task Framework (DTFx) für tiefgehende Diagnosen.
- Distributed Tracing einrichten, um End-to-End-Orchestrierungsabläufe zu visualisieren
- Schreiben von replay-sicheren Protokollen in Orchestratorfunktionen
- Melden des benutzerdefinierten Orchestrierungsstatus an externe Clients
- Debuggen von Orchestrationen lokal mit Breakpoints
Konfigurieren der Nachverfolgung von Application Insights
Application Insights ist die empfohlene Möglichkeit, dauerhafte Funktionen zu überwachen. Die Durable-Erweiterung gibt Tracking-Ereignisse aus, mit denen die End-to-End-Ausführung einer Orchestrierung nachvollzogen werden kann. Sie können diese Nachverfolgungsereignisse mithilfe des Tools Application Insights Analytics im Azure-Portal suchen und abfragen.
Konfiguration auf Protokollebene
Konfigurieren Sie die Ausführlichkeit der an Application Insights ausgegebenen Nachverfolgungsdaten in Ihrer host.json Datei:
{
"logging": {
"logLevel": {
"Host.Triggers.DurableTask": "Information",
},
}
}
Standardmäßig werden alle ohne Wiedergabe definierten Nachverfolgungsereignisse ausgegeben. Sie können die Menge der Daten reduzieren, indem Sie Host.Triggers.DurableTask auf "Warning" oder "Error" festlegen, was bedeutet, dass Tracking-Ereignisse nur für außergewöhnliche Situationen ausgegeben werden. Wenn Sie die ausführlichen Wiedergabeereignisse für die Orchestrierung aktivieren möchten, legen logReplayEventstrue Sie diese in der konfigurationsdateihost.json fest.
Hinweis
Standardmäßig wird in der Azure Functions-Laufzeit die Application Insights-Telemetrie stichprobenartig verwendet, um zu verhindern, dass Daten zu häufig gesendet werden. Das Sampling kann dazu führen, dass Nachverfolgungsinformationen verloren gehen, wenn viele Lebenszyklusereignisse in kurzer Zeit auftreten. Im Artikel Azure Functions Monitoring wird erläutert, wie Sie dieses Verhalten konfigurieren.
Eingabe- und Ausgabeprotokollierung
Standardmäßig werden Orchestrator-, Aktivitäts- und Entitätsfunktionseingaben und -ausgaben nicht protokolliert. Dieser Ansatz wird empfohlen, da die Protokollierung von Eingaben und Ausgaben die Kosten für Application Insights erhöhen könnte. Eingabe- und Ausgabenutzdaten von Funktionen können außerdem vertrauliche Informationen enthalten. Stattdessen werden die Anzahl der Bytes für Funktionseingaben und -ausgaben protokolliert. Wenn die Durable Functions Erweiterung die vollständigen Eingabe- und Ausgabenutzlasten protokollieren soll, legen Sie die eigenschaft traceInputsAndOutputs auf true in der Konfigurationsdatei host.json fest.
Orchestrierungsinstanzen abfragen
Verwenden Sie die folgenden Kusto-Abfragen in Application Insights Analytics, um Orchestrierungsinstanzen zu prüfen.
Abfrage für einzelne Instanzen
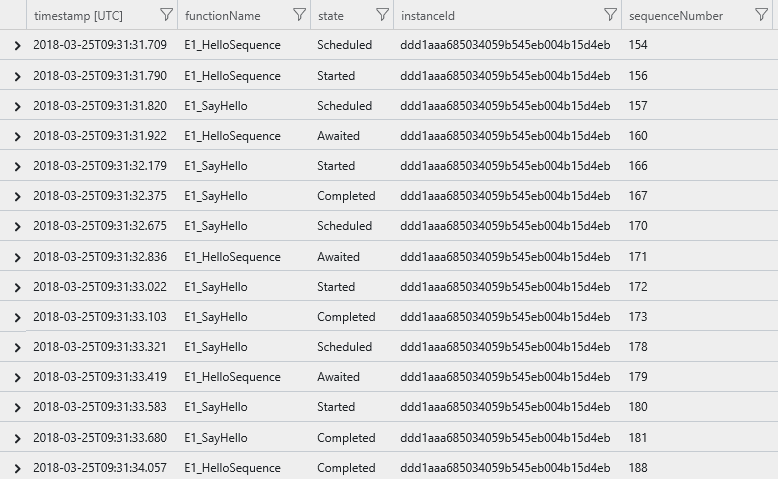
Mit der folgenden Abfrage werden Verlaufsdaten für die Nachverfolgung einer Einzelinstanz der Hello Sequence-Funktionsorchestrierung angezeigt. Die Wiedergabeausführung wird herausgefiltert, sodass nur der logische Ausführungspfad angezeigt wird. Sie können Ereignisse sortieren nach timestamp und sequenceNumber wie in der folgenden Abfrage gezeigt:
let targetInstanceId = "ddd1aaa685034059b545eb004b15d4eb";
let start = datetime(2018-03-25T09:20:00);
traces
| where timestamp > start and timestamp < start + 30m
| where customDimensions.Category == "Host.Triggers.DurableTask"
| extend functionName = customDimensions["prop__functionName"]
| extend instanceId = customDimensions["prop__instanceId"]
| extend state = customDimensions["prop__state"]
| extend isReplay = tobool(tolower(customDimensions["prop__isReplay"]))
| extend sequenceNumber = tolong(customDimensions["prop__sequenceNumber"])
| where isReplay != true
| where instanceId == targetInstanceId
| sort by timestamp asc, sequenceNumber asc
| project timestamp, functionName, state, instanceId, sequenceNumber, appName = cloud_RoleName
Das Ergebnis ist eine Liste mit Nachverfolgungsereignissen, die den Ausführungspfad der Orchestrierung anzeigt, z.B. alle Aktivitätsfunktionen, in aufsteigender Reihenfolge nach Ausführungszeit sortiert.
Instanz-Zusammenfassungsabfrage
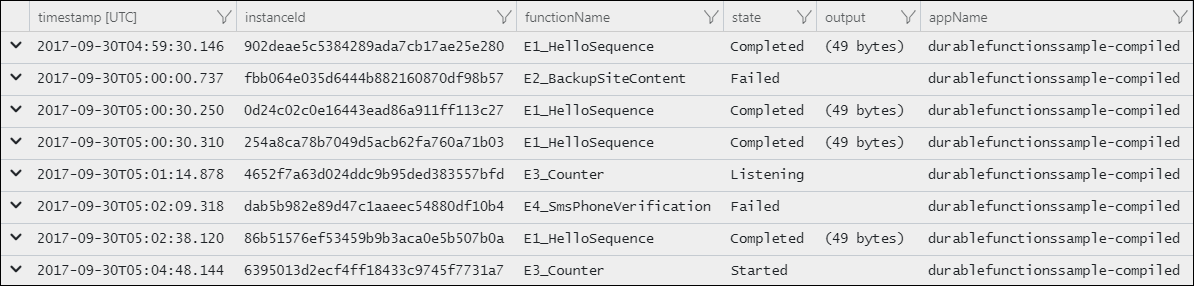
Mit der folgenden Abfrage wird der Status aller Orchestrierungsinstanzen angezeigt, die in einem angegebenen Zeitraum ausgeführt wurden.
let start = datetime(2017-09-30T04:30:00);
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "Host.Triggers.DurableTask"
| extend functionName = tostring(customDimensions["prop__functionName"])
| extend instanceId = tostring(customDimensions["prop__instanceId"])
| extend state = tostring(customDimensions["prop__state"])
| extend isReplay = tobool(tolower(customDimensions["prop__isReplay"]))
| extend output = tostring(customDimensions["prop__output"])
| where isReplay != true
| summarize arg_max(timestamp, *) by instanceId
| project timestamp, instanceId, functionName, state, output, appName = cloud_RoleName
| order by timestamp asc
Das Ergebnis ist eine Liste mit Instanz-IDs und dem aktuellen Laufzeitstatus.
Datenreferenz für die Nachverfolgung
Jede Orchestrierungsinstanz generiert im Verlauf ihres Lebenszyklus Nachverfolgungsereignisse. Jedes Lebenszyklusereignis enthält eine customDimensions-Nutzlast mit mehreren Feldern. Feldnamen wird immer prop__ vorangestellt.
| Feldname | Beschreibung |
|---|---|
hubName |
Der Name des Aufgabenhubs, in dem Ihre Orchestrierungen ausgeführt werden. |
appName |
Der Name der Funktions-App. Dieses Feld ist nützlich, wenn mehrere Funktions-Apps dieselbe Application Insights-Instanz gemeinsam nutzen. |
slotName |
Der Bereitstellungs-Slot, in dem die aktuelle Funktions-App ausgeführt wird. Dieses Feld ist nützlich, wenn Sie Bereitstellungsslots nutzen, um Ihre Orchestrierungen mit einer Version zu versehen. |
functionName |
Der Name der Orchestrator- oder Aktivitätsfunktion. |
functionType |
Der Typ der Funktion, z. B. Orchestrator oder Aktivität. |
instanceId |
Die eindeutige ID der Orchestrierungsinstanz. |
state |
Der Lebenszyklus-Ausführungsstatus der Instanz. |
state.Scheduled |
Die Funktion wurde für die Ausführung geplant, aber noch nicht ausgeführt. |
state.Started |
Die Funktion wurde gestartet, sie wurde aber noch nicht erwartet oder abgeschlossen. |
state.Awaited |
Der Orchestrator hat einige Aufgaben eingeplant und wartet darauf, dass sie abgeschlossen sind. |
state.Listening |
Der Orchestrator überwacht eine externe Ereignisbenachrichtigung. |
state.Completed |
Die Funktion wurde erfolgreich abgeschlossen. |
state.Failed |
Die Funktion ist mit einem Fehler fehlgeschlagen. |
reason |
Zusätzliche Daten, die dem Tracking-Ereignis zugeordnet sind. Wenn beispielsweise eine Instanz auf eine externe Ereignisbenachrichtigung wartet, gibt dieses Feld den Namen des Ereignisses an, auf das es wartet. Wenn eine Funktion fehlschlägt, enthält dieses Feld die Fehlerdetails. |
isReplay |
Boolescher Wert, der angibt, ob das Tracking-Ereignis für die wiederholte Ausführung bestimmt ist. |
extensionVersion |
Die Version der Durable Task-Erweiterung. Diese Versionsinformationen sind besonders wichtig, wenn mögliche Fehler der Erweiterung gemeldet werden. Bei Instanzen mit langer Laufzeit können mehrere Versionen gemeldet werden, wenn während der Ausführung der Instanz ein Update erfolgt. |
sequenceNumber |
Ausführungssequenznummer für ein Ereignis. In Kombination mit dem Zeitstempel hilft dies, die Ereignisse nach Ausführungszeit zu ordnen. Beachten Sie, dass diese Zahl auf Null zurückgesetzt wird, wenn der Host während der Ausführung der Instanz neu gestartet wird. Daher ist es wichtig, zuerst nach Zeitstempel zu sortieren und dann sequenceNumber. |
Dauerhafte Task Framework-Protokollierung (DTFx)
Die Durable-Erweiterungsprotokolle sind nützlich, um das Verhalten Ihrer Orchestrierungslogik zu verstehen. Diese Protokolle enthalten jedoch nicht immer genügend Informationen, um Probleme hinsichtlich Leistung und Zuverlässigkeit auf Frameworkebene zu debuggen. Ab v2.3.0 der Durable-Erweiterung stehen auch Protokolle, die vom zugrunde liegenden Durable Task Framework (DTFx) ausgegeben werden, zur Erfassung bereit.
Bei der Betrachtung von Protokollen, die von dtFx ausgegeben werden, ist es wichtig zu verstehen, dass das DTFx-Modul zwei Komponenten aufweist: das Core Dispatch Engine (DurableTask.Core) und eines von vielen unterstützten Speicheranbietern.
| Bestandteil | Beschreibung |
|---|---|
DurableTask.Core |
Kernorchestrierungsausführung und Low-Level-Scheduling-Protokolle und Telemetrie. |
DurableTask.DurableTaskScheduler |
Backend-Protokolle, die für den dauerhaften Aufgabenplaner spezifisch sind. |
DurableTask.AzureStorage |
Backend-Logdateien, die für den Azure Storage-Zustandsanbieter spezifisch sind. Diese Protokolle enthalten ausführliche Informationen mit den internen Warteschlangen, Blobs und Speichertabellen, die zum Speichern und Abrufen des internen Orchestrierungszustands verwendet wurden. |
DurableTask.Netherite |
Backend-Protokolle, die für den Netherite-Speicheranbieter spezifisch sind, falls aktiviert. |
DurableTask.SqlServer |
Backend-Protokolle, die für den Microsoft SQL (MSSQL)-Speicheranbieter spezifisch sind, falls aktiviert. |
Sie können diese Protokolle aktivieren, indem Sie den Abschnitt logging/logLevel in der Datei host.json Ihrer Funktions-App aktualisieren. Das folgende Beispiel zeigt, wie Warn- und Fehlerprotokolle sowohl von DurableTask.Core als auch von DurableTask.AzureStorage aktiviert werden können:
{
"version": "2.0",
"logging": {
"logLevel": {
"DurableTask.AzureStorage": "Warning",
"DurableTask.Core": "Warning"
}
}
}
Wenn Application Insights aktiviert ist, werden diese Protokolle automatisch der trace Sammlung hinzugefügt. Sie können sie auf die gleiche Weise durchsuchen, wie Sie mithilfe von Kusto-Abfragen nach anderen trace Protokollen suchen.
Hinweis
Für Produktionsanwendungen empfehlen wir, DurableTask.Core und die Protokolle des entsprechenden Speicheranbieters (z.B. DurableTask.AzureStorage) mithilfe des "Warning" Filters zu aktivieren. Filter mit höherer Ausführlichkeit, wie "Information", sind hilfreich beim Debuggen von Leistungsproblemen. Diese Protokollereignisse können jedoch ein hohes Volumen aufweisen und die Kosten für die Datenspeicherung von Application Insights erheblich erhöhen.
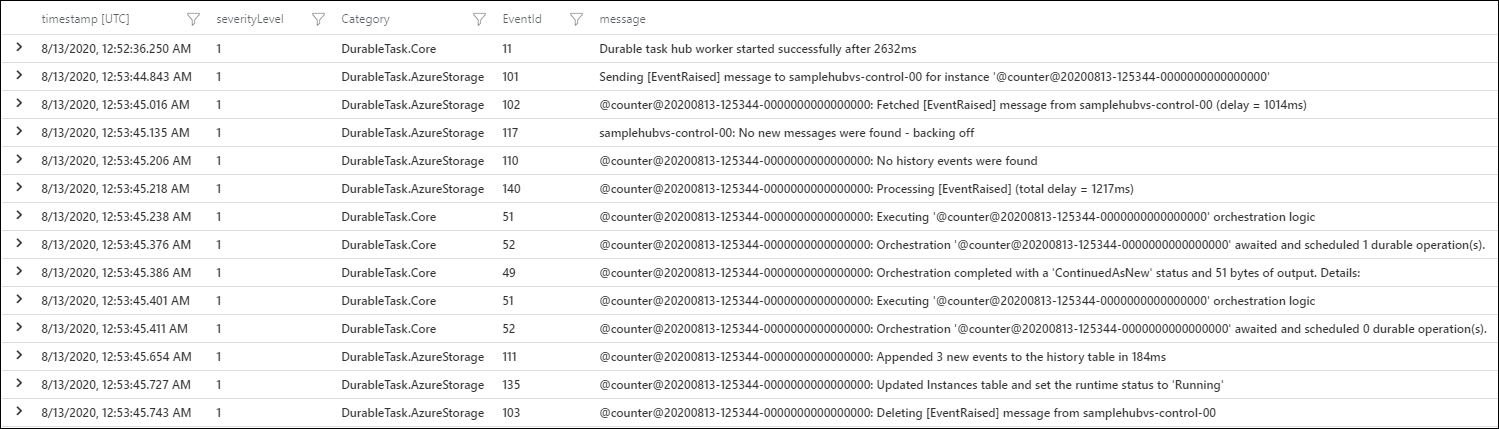
Die folgende Kusto-Abfrage zeigt, wie DTFx-Protokolle abgefragt werden. Der wichtigste Teil der Abfrage ist where customerDimensions.Category startswith "DurableTask", da er die Ergebnisse auf Protokolle in den Kategorien DurableTask.Core und DurableTask.AzureStorage filtert.
traces
| where customDimensions.Category startswith "DurableTask"
| project
timestamp,
severityLevel,
Category = customDimensions.Category,
EventId = customDimensions.EventId,
message,
customDimensions
| order by timestamp asc
Das Ergebnis ist eine Reihe von Protokollen, die von den Anbietern von Durable Task Framework-Protokollen geschrieben wurden.
Weitere Informationen dazu, welche Protokollereignisse verfügbar sind, finden Sie in der Dokumentation zur strukturierten Protokollierung des Durable Task Frameworks auf GitHub.
Verteiltes Tracing
Verteilte Ablaufverfolgung verfolgt Anforderungen und zeigt, wie verschiedene Dienste miteinander interagieren. In Durable Functions werden Orchestrierungen, Entitäten und Aktivitäten miteinander korreliert. Die verteilte Ablaufverfolgung zeigt die Ausführungszeit für jeden Orchestrierungsschritt relativ zur gesamten Orchestrierung an und identifiziert, wo Probleme oder Ausnahmen auftreten. Dieses Feature wird in Application Insights für alle Sprachen und Speicheranbieter unterstützt.
Voraussetzungen
Die verteilte Ablaufverfolgung erfordert bestimmte Mindesterweiterungsversionen:
- Für isolierte .NET-Apps Microsoft.Azure.Functions.Worker.Extensions.DurableTask>= v1.4.0.
- Für nicht-.NET-Apps folgen Sie diesen Anweisungen, um Microsoft.Azure.WebJobs.Extensions.DurableTask>= v3.2.0 manuell zu installieren. Verteilte Ablaufverfolgung ist in Erweiterungspaketen >v4.24.x verfügbar.
Einrichten der verteilten Ablaufverfolgung
Um das verteilte Tracing zu konfigurieren, aktualisieren Sie das host.json und richten Sie eine Application Insights Ressource ein.
host.json
{
"extensions": {
"durableTask": {
"tracing": {
"distributedTracingEnabled": true,
"version": "V2"
}
}
}
}
Anwendungsanalysen
Konfigurieren Sie Ihre Funktions-App mit einer Application Insights-Ressource.
Überprüfen der Ablaufverfolgungen
Navigieren Sie in Ihrer Application Insights-Ressource zur Transaktionssuche. Suchen Sie in den Ergebnissen nach Request und Dependency Ereignissen, die mit Durable-spezifischen Präfixen beginnen (zum Beispiel orchestration:, activity:, usw.). Wenn Sie eines dieser Ereignisse auswählen, wird ein Gantt-Diagramm geöffnet, das die verteilte End-to-End-Ablaufverfolgung anzeigt. Das Diagramm zeigt jeden Orchestrierungsschritt als horizontale Leiste an, wobei Aktivitäten und Unterorchestrierungen in die übergeordnete Orchestrierung eingebettet sind. Die Länge des Balkens stellt die Wanduhrdauer jedes Schritts dar, wodurch Engpässe oder unerwartet langsame Aktivitäten leicht zu erkennen sind.

Hinweis
Werden Ihre Traces in Application Insights nicht angezeigt? Warten Sie ungefähr fünf Minuten, nachdem Sie Ihre Anwendung ausgeführt haben, um sicherzustellen, dass alle Daten an die Application Insights-Ressource weitergegeben werden.
Wiedergabesichere Log-Erstellung in Orchestratorfunktionen
Orchestratorfunktionen werden jedes Mal wiedergegeben, wenn neue Eingaben empfangen werden, was bedeutet, dass jede Log-Anweisung in einem Orchestrator mehrmals für eine einzelne logische Ausführung ausgeführt wird. Beispielsweise erzeugt eine Funktion mit drei Aktivitätsaufrufen während der Wiedergabe eine Protokollausgabe wie die Folgende:
Calling F1.
Calling F1.
Calling F2.
Calling F1.
Calling F2.
Calling F3.
Calling F1.
Calling F2.
Calling F3.
Done!
Um doppelte Protokollzeilen zu verhindern, überprüfen Sie das Flag "wird wiedergegeben", sodass Protokolle nur für den ersten (nicht wiedergegebenen) Durchgang ausgeführt werden. Die folgenden Beispiele zeigen die wiedergabesichere Protokollierung in jeder Sprache.
Ab Durable Functions 2.0 können Sie CreateReplaySafeLogger verwenden, um Log-Anweisungen während der Wiedergabe automatisch herauszufiltern.
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
log = context.CreateReplaySafeLogger(log);
log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Bei wiederholungssicherem Logging lautet die Protokollausgabe:
Calling F1.
Calling F2.
Calling F3.
Done!
Benutzerdefinierter Orchestrierungsstatus
Verwenden Sie den benutzerdefinierten Orchestrierungsstatus, um den Workflowstatus an externe Clients zu melden. Allgemeine Muster umfassen Fertigstellungsprozentsätze, Schrittbeschreibungen und Fehlerzusammenfassungen. Externe Clients können den benutzerdefinierten Status über die HTTP-Statusabfrage-API oder sprachspezifische API-Aufrufe anzeigen.
Der folgende Code zeigt, wie ein benutzerdefinierter Statuswert in einer Orchestratorfunktion festgelegt wird:
[FunctionName("SetStatusTest")]
public static async Task SetStatusTest([OrchestrationTrigger] IDurableOrchestrationContext context)
{
// ...do work...
// update the status of the orchestration with some arbitrary data
var customStatus = new { completionPercentage = 90.0, status = "Updating database records" };
context.SetCustomStatus(customStatus);
// ...do more work...
}
Hinweis
Das vorherige C#-Beispiel ist für Durable Functions 2.x. Für Durable Functions 1.x müssen Sie DurableOrchestrationContext anstelle von IDurableOrchestrationContext verwenden. Weitere Informationen zu den Unterschieden zwischen den Versionen finden Sie im Artikel Durable Functions-Versionen.
Während der Ausführung der Orchestrierung können externe Clients diesen benutzerdefinierten Status abrufen:
GET /runtime/webhooks/durabletask/instances/instance123?code=XYZ
Clients erhalten die folgende Antwort:
{
"runtimeStatus": "Running",
"input": null,
"customStatus": { "completionPercentage": 90.0, "status": "Updating database records" },
"output": null,
"createdTime": "2017-10-06T18:30:24Z",
"lastUpdatedTime": "2017-10-06T19:40:30Z"
}
Warnung
Die benutzerdefinierte Statusnutzlast ist auf 16 KB UTF-16 JSON-Text beschränkt, da sie in eine Azure Table Storage Spalte passen muss. Sie können externen Speicher verwenden, wenn Sie eine größere Nutzlast benötigen.
Fehlersuche
Azure Functions unterstützt das direkte Debuggen von Funktionscode und die gleiche Unterstützung wird an Durable Functions weitergeleitet, unabhängig davon, ob sie in Azure oder lokal ausgeführt wird. Verwenden Sie den folgenden Workflow, um optimale Debugfunktionen zu erzielen:
Starten Sie eine neue Debugsitzung mit einem neuen Aufgabenhub , oder löschen Sie den Inhalt des Aufgabenhubs zwischen Sitzungen. Überbleibsel-Nachrichten aus vorherigen Läufen können zu einer unerwarteten erneuten Ausführung führen.
Legen Sie Haltepunkte in Ihren Orchestrator- oder Aktivitätsfunktionen fest. Verwenden Sie für Orchestratorfunktionen einen bedingten Haltepunkt, der nur ausgelöst wird, wenn der Wert "ist replaying"
falsebeträgt, um zu vermeiden, dass derselbe Haltepunkt während des Wiederholens mehrmals erreicht wird.Durchlaufen Sie Ihren Code wie gewohnt. Beachten Sie die folgenden Verhaltensweisen:
Wiedergabe:
Orchestrator-Funktionen werden regelmäßig erneut ausgeführt, wenn neue Eingaben empfangen werden. Eine einzelne logische Ausführung einer Orchestratorfunktion kann dazu führen, dass mehrmals derselbe Haltepunkt erreicht wird, insbesondere, wenn sie früh im Funktionscode festgelegt ist.Erwarten:
Immer wenn einawaitin einer Orchestratorfunktion auftritt, gibt sie die Kontrolle zurück an den Dispatcher des Durable Task Framework. Wenn eine bestimmteawaitzum ersten Mal auftritt, wird die zugehörige Aufgabe nie fortgesetzt. Da die Aufgabe nie fortgesetzt wird, ist das Übersteigen des "await" (F10 in Visual Studio) nicht möglich. Das Überspringen funktioniert nur, wenn eine Aufgabe wiedergegeben wird.Messaging-Timeouts:
Dauerhafte Funktionen verwenden intern Warteschlangennachrichten, um die Ausführung von Orchestrator-, Aktivitäts- und Entitätsfunktionen zu steuern. In einer Multi-VM-Umgebung könnten erweiterte Debugsitzungen dazu führen, dass eine andere VM die Nachricht verarbeitet, was zu doppelter Ausführung führt. Obwohl dieses Verhalten auch für normale Warteschlangentriggerfunktionen vorhanden ist, ist dieser Kontext wichtig hervorzuheben, da die Warteschlangen ein Implementierungsdetail sind.Beenden und Starten:
Nachrichten in dauerhaften Funktionen werden zwischen Debugsitzungen beibehalten. Wenn Sie das Debuggen beenden und den lokalen Hostprozess beenden, während eine dauerhafte Funktion ausgeführt wird, wird diese Funktion in einer zukünftigen Debugsitzung möglicherweise automatisch erneut ausgeführt.
Weitere Tools
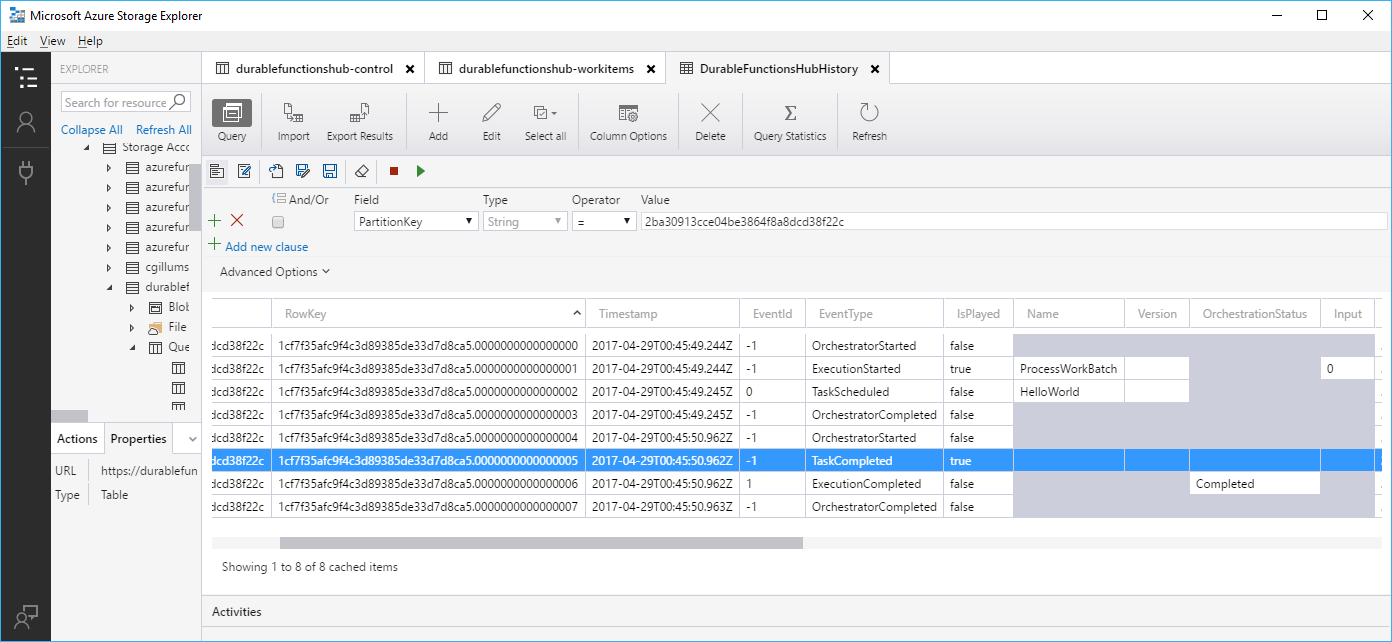
Überprüfen des Speicherzustands
Standardmäßig speichert Durable Functions den Zustand in Azure Storage. Sie können den Orchestrierungsstatus und Nachrichten mithilfe von Tools wie Microsoft Azure Storage Explorer überprüfen.
Warnung
Es ist zwar bequem, den Ausführungsverlauf im Tabellenspeicher angezeigt zu bekommen, aber Sie sollten es vermeiden, Abhängigkeiten von dieser Tabelle einzurichten. Es kann sich ändern, wenn sich die Durable Functions Erweiterung weiterentwickelt.
Hinweis
Sie können andere Speicheranbieter konfigurieren anstelle des Standardanbieters Azure Storage. Je nach dem für Ihre App konfigurierten Speicheranbieter müssen Sie möglicherweise verschiedene Tools verwenden, um den zugrunde liegenden Zustand zu überprüfen.
Überwachungsdienst für Durable Functions
Durable Functions Monitor ist ein grafisches Tool zum Überwachen, Verwalten und Debuggen von Orchestrierungs- und Entitätsinstanzen. Sie ist als Visual Studio Code-Erweiterung oder als eigenständige App verfügbar. Anweisungen zum Einrichten und eine Liste der Features finden Sie im Durable Functions Monitor-Wiki.
Diagnosefunktionen im Azure-Portal
Das Azure-Portal bietet integrierte Diagnosetools für Ihre Funktions-Apps.
Diagnostizieren und Lösen von Problemen: Azure Function App Diagnostics ist eine nützliche Ressource zum Überwachen und Diagnostizieren potenzieller Probleme in Ihrer Anwendung. Sie bietet außerdem Vorschläge, um Probleme basierend auf der Diagnose zu lösen. Weitere Informationen finden Sie unter Azure Function App Diagnostics.
Orchestrierungsablaufverfolgungen: Das Azure-Portal bietet Details zur Orchestrierungsablaufverfolgung, die Ihnen helfen, den Status jeder Orchestrierungsinstanz und die End-to-End-Ausführung zu verstehen. Wenn Sie sich die Liste der Funktionen in Ihrer Azure Functions-Anwendung anzeigen, sehen Sie eine Spalte namens Überwachung, die Links zu den Ablaufverfolgungen enthält. Sie müssen Application Insights für Ihre App aktiviert haben, um auf diese Informationen zuzugreifen.
Roslyn-Analysetool
Der Durable Functions Roslyn Analyzer ist ein Live-Codeanalysator, der C#-Entwickler leitet, Durable Functions spezifischen codeeinschränkungen zu befolgen. Anweisungen zum Aktivieren in Visual Studio und Visual Studio Code finden Sie unter Durable Functions Roslyn Analyzer.
Problembehandlung
Zur Behebung häufiger Probleme wie z. B. wenn Orchestrierungen hängen bleiben, nicht starten oder langsam laufen, siehe den Leitfaden zur Fehlerbehebung für Durable Functions.