Problembehandlung für die Autoskalierung in Azure Monitor
Mit der automatischen Skalierung von Azure Monitor können Sie jeweils die richtige Menge an Ressourcen ausführen, um die Lasten für Ihre Anwendung zu bewältigen. Sie können Ressourcen hinzufügen, um auf einen Anstieg der Last zu reagieren, und Kosten sparen, indem Sie ungenutzte Ressourcen entfernen. Sie können eine Skalierung basierend auf einem Zeitplan, an einem festgelegten Datum/Uhrzeit oder anhand einer ausgewählten Ressourcenmetrik ausführen. Weitere Informationen finden Sie unter Übersicht über die automatische Skalierung.
Der Dienst für die Autoskalierung bietet Metriken und Protokolle, anhand derer Sie ein Verständnis der Skalierungsaktionen und der ausgewerteten ursächlichen Bedingungen für diese Aktionen gewinnen können. Es werden beispielsweise folgende Fragen beantwortet:
- Warum wurde der Dienst horizontal hoch- oder herunterskaliert?
- Warum wurde mein Dienst nicht skaliert?
- Warum ist eine Aktion der automatischen Skalierung fehlgeschlagen?
- Warum dauert eine Aktion der automatischen Skalierung eine Weile?
Flexible VM-Skalierungsgruppen
Autoskalierungsaktionen verzögern sich um bis zu mehrere Stunden, nachdem eine manuelle Skalierungsaktion auf eine Ressource vom Typ Flex Microsoft.Compute/virtualMachineScaleSets (VMSS) für eine bestimmte Gruppe von VM-Vorgängen angewendet wurde.
Beispiele wären etwa das Löschen virtueller Azure-Computer über die Befehlszeilenschnittstelle und das Löschen virtueller Azure-Computer per REST-API, wenn der Vorgang für einen einzelnen virtuellen Computer ausgeführt wird.
In diesen Fällen sind dem Autoskalierungsdienst die einzelnen VM-Vorgänge nicht bekannt.
Verwenden Sie zur Vermeidung dieses Szenarios den gleichen Vorgang, aber auf VM-Skalierungsgruppenebene. Beispiele: az vmss delete-instances (CLI) oder das Löschen von Instanzen von Azure-VM-Skalierungsgruppen per REST-API. Die Autoskalierung erkennt die Änderung der Instanzanzahl in der VM-Skalierungsgruppe und führt die entsprechenden Skalierungsaktionen aus.
Metriken der automatischen Skalierung
Die Autoskalierung bietet Ihnen vier Metriken, anhand derer Sie den Vorgang nachvollziehen können:
- Beobachteter Metrikwert: Der Wert der Metrik, für welche die Skalierungsaktion ausgeführt werden soll, entsprechend der Anzeige oder berechnet durch das Autoskalierungsmodul. Da eine einzelne Autoskalierungseinstellung über mehrere Regeln und damit mehrere Metrikquellen verfügen kann, können Sie nach der Dimension „Metrikquelle“ filtern.
- Metrikschwellenwert: Der Schwellenwert, den Sie für die Ausführung der Skalierungsaktion festgelegt haben. Da eine einzelne Autoskalierungseinstellung über mehrere Regeln und damit mehrere Metrikquellen verfügen kann, können Sie nach der Dimension „Metrikregel“ filtern.
- Beobachtete Kapazität: Die Anzahl aktiver Instanzen der Zielressource, die von der Autoskalierungs-Engine festgestellt wurden.
- Initiierte Skalierungsaktionen: Die Anzahl der vom Autoskalierungsmodul initiierten Aktionen zum horizontalen Hoch- und Herunterskalieren. Sie können nach Aktionen zum horizontalen Hoch- bzw. Herunterskalieren filtern.
Mit dem Metrik-Explorer können Sie die obigen Metriken an einem Ort grafisch darstellen. Im Diagramm sollte Folgendes angezeigt werden:
- Eigentliche Metrik
- Metrik entsprechend Anzeige/Berechnung durch das Autoskalierungsmodul
- Schwellenwert für eine Skalierungsaktion
- Änderung der Kapazität
Beispiel 1: Analysieren einer Regel für die Autoskalierung
Eine Autoskalierungseinstellung für eine VM-Skalierungsgruppe bewirkt Folgendes:
- Horizontales Hochskalieren, wenn der durchschnittliche CPU-Prozentsatz einer Gruppe 10 Minuten lang über 70 % liegt
- Horizontales Herunterskalieren, wenn der CPU-Prozentsatz der Gruppe länger als 10 Minuten unter 5 % liegt
Betrachten wir nun die Metriken aus dem Autoskalierungsdienst.
Das folgende Diagramm zeigt eine Metrik CPU in Prozent für eine VM-Skalierungsgruppe.

Das nächste Diagramm zeigt die Metrik Beobachteter Metrikwert für eine Autoskalierungseinstellung.

Das letzte Diagramm zeigt die Metriken Metrikschwellenwert und Beobachtete Kapazität. Die obere Metrik Metrikschwellenwert liegt für die Regel zum horizontalen Hochskalieren bei 70. Die untere Metrik Beobachtete Kapazität zeigt die Anzahl aktiver Instanzen. Derzeit sind drei Instanzen aktiv.

Hinweis
Sie können den Metrikschwellenwert anhand der Regel für das horizontale Hochskalieren (Aufskalieren) der Metriktriggerregel-Dimension filtern, um den Schwellenwert für horizontales Hochskalieren anzuzeigen, sowie anhand der Regel für das horizontale Herunterskalieren (Abskalieren).
Beispiel 2: Erweiterte Autoskalierung für eine VM-Skalierungsgruppe
Eine Autoskalierungseinstellung ermöglicht das horizontale Hochskalieren der Ressource einer VM-Skalierungsgruppe anhand ihrer eigenen Metrik Ausgehende Datenflüsse. Die Option Metrikteilung nach Instanzenanzahl aktivieren ist für den Metrikschwellenwert aktiviert.
Wenn der Wert von Ausgehender Datenfluss pro Instanz größer als 10 ist, skaliert der Autoskalierungsdienst gemäß Skalierungsaktionsregel um 1 Instanz hoch.
In diesem Fall wird der beobachtete Metrikwert der Autoskalierungs-Engine berechnet, indem der tatsächliche Metrikwert durch die Anzahl der Instanzen dividiert wird. Wenn der beobachtete Metrikwert kleiner als der Schwellenwert ist, wird keine Aktion zum horizontalen Hochskalieren initiiert.
Die folgenden Screenshots zeigen zwei Metrikdiagramme.
Das Diagramm Durchschnittliche ausgehende Datenflüsse zeigt den Wert der Metrik Ausgehende Datenflüsse an. Der tatsächliche Wert ist 6.

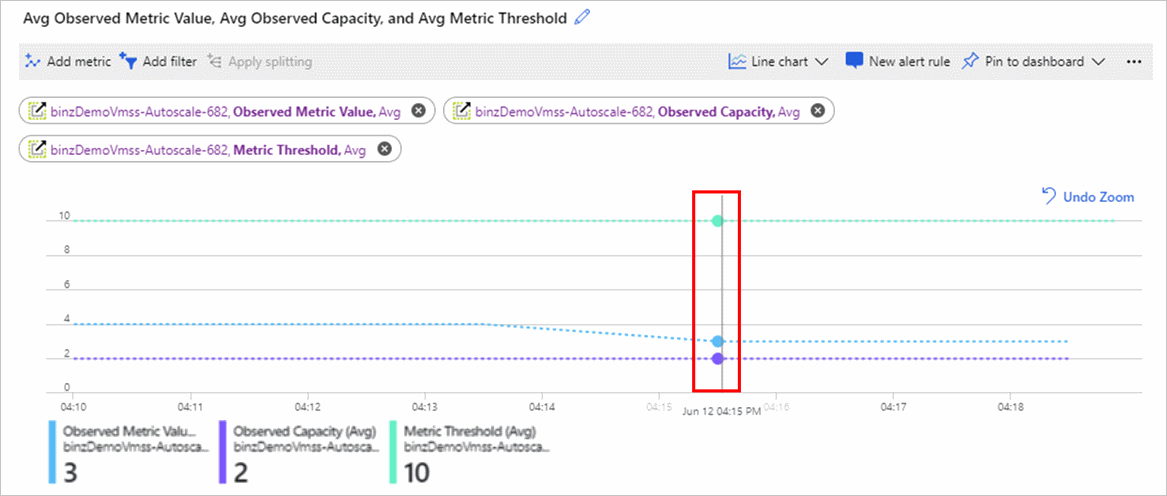
Das folgende Diagramm zeigt einige Werte:
- Die mittlere Metrik Beobachteter Metrikwert ist 3, da 2 aktive Instanzen vorhanden sind und 6 geteilt durch 2 3 ergibt.
- Die untere Metrik Beobachtete Kapazität zeigt die Instanzanzahl an, die von einer Autoskalierungs-Engine angezeigt wird.
- Die obere Metrik Metrikschwellenwert ist auf 10 festgelegt.

Wenn mehrere Regeln für Skalierungsaktionen vorhanden sind, können Sie die Teilungsoption oder die Option Filter hinzufügen im Diagramm des Metrik-Explorers verwenden, um Metriken nach einer bestimmten Quelle oder Regel anzuzeigen. Weitere Informationen zum Teilen eines Metrikdiagramms finden Sie unter Erweiterte Funktionen von Azure Metrik-Explorer – Teilen.
Beispiel 3: Verstehen von Autoskalierungsereignissen
Wechseln Sie im Bildschirm für Autoskalierungseinstellungen zur Registerkarte Ausführungsverlauf, um die aktuellen Skalierungsaktionen zu überprüfen. Auf der Registerkarte wird auch die Änderung des Werts von Beobachtete Kapazität im Lauf der Zeit angezeigt. Weitere Informationen zu allen Autoskalierungsaktionen, einschließlich Vorgängen wie Aktualisieren/Löschen von Autoskalierungseinstellungen, finden Sie im Aktivitätsprotokoll. Filtern Sie dort nach Autoskalierungsvorgängen.

Ressourcenprotokolle für die Autoskalierung
Der Dienst für die Autoskalierung stellt Ressourcenprotokolle bereit. Es gibt zwei Kategorien von Protokollen:
- Bewertungen der Autoskalierung: Die Autoskalierungs-Engine zeichnet bei jeder Überprüfung Protokolleinträge für die einzelnen Bedingungsauswertungen auf. Der Eintrag enthält Details zu den beobachteten Werten der Metriken, zu den ausgewerteten Regeln sowie Angaben dazu, ob die Bewertung zu einer Skalierungsaktion geführt hat.
- Skalierungsaktionen der Autoskalierung: Die Engine zeichnet vom Autoskalierungsdienst initiierte Ereignisse von Skalierungsaktionen sowie die Ergebnisse dieser Skalierungsaktionen (Erfolg, Fehler und vom Autoskalierungsdienst beobachteter Umfang der Skalierung) auf.
Wie bei jedem von Azure Monitor unterstützten Dienst können Sie diese Protokolle über Diagnoseeinstellungen an folgende Stellen weiterleiten:
- an Ihren Log Analytics-Arbeitsbereich zur ausführlichen Analyse
- an Azure Event Hubs und dann an Nicht-Azure-Tools
- Ihr Azure Storage-Konto zur Archivierung

Der obige Screenshot zeigt den Bereich Diagnoseeinstellungen für die Autoskalierung im Azure-Portal. Dort können Sie die Registerkarte Diagnose-/Ressourcenprotokolle auswählen und die Protokollaufzeichnung und -weiterleitung aktivieren. Sie können dieselbe Aktion für Diagnoseeinstellungen auch über die REST-API, die Azure CLI, PowerShell und Azure Resource Manager-Vorlagen ausführen, indem Sie als Ressourcentyp Microsoft.Insights/AutoscaleSettings auswählen.
Problembehandlung mithilfe von Autoskalierungsprotokollen
Für eine optimale Problembehandlung empfiehlt es sich, die Protokolle über einen Arbeitsbereich an Azure Monitor-Protokolle (Log Analytics) weiterzuleiten, wenn Sie die Autoskalierungseinstellung erstellen. Diese Vorgehensweise wird in dem Screenshot im vorherigen Abschnitt veranschaulicht. Sie können die Auswertungen und Skalierungsaktionen besser mithilfe von Log Analytics überprüfen.
Nachdem Sie das Senden Ihrer Autoskalierungsprotokolle an den Log Analytics-Arbeitsbereich konfiguriert haben, können Sie die Protokolle durch Ausführen der folgenden Abfragen überprüfen.
Führen Sie zuerst diese Abfrage aus, um die aktuellen Protokolle zur Autoskalierungsauswertung aufzurufen:
AutoscaleEvaluationsLog
| limit 50
Sie können auch die folgende Abfrage ausführen, um die Protokolle für aktuelle Skalierungsaktionen aufzurufen:
AutoscaleScaleActionsLog
| limit 50
In den folgenden Abschnitten finden Sie Antworten auf diese Fragen.
Es ist eine unerwartete Skalierungsaktion aufgetreten
Führen Sie zuerst die Abfrage für eine Skalierungsaktion aus, um die gewünschte Skalierungsaktion zu ermitteln. Wenn es sich um die letzte Skalierungsaktion handelt, verwenden Sie die folgende Abfrage:
AutoscaleScaleActionsLog
| take 1
Wählen Sie im Protokoll der Skalierungsaktionen das Feld CorrelationId aus. Suchen Sie anhand der CorrelationId nach dem betreffenden Auswertungsprotokoll. Beim Ausführen der folgenden Abfrage werden alle Regeln und Bedingungen angezeigt, die ausgewertet wurden und zu dieser Skalierungsaktion geführt haben.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId>"
Welches Profil hat eine Skalierungsaktion verursacht?
Es ist eine Skalierungsaktion aufgetreten. Sie verfügen jedoch über einander überschneidende Regeln und Profile und müssen feststellen, welche die Aktion verursacht hat.
Suchen Sie die CorrelationId der Skalierungsaktion, wie in Beispiel 1 erläutert. Führen Sie dann die Abfrage für Auswertungsprotokolle aus, um mehr über das Profil zu erfahren.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId_Guid>"
| where ProfileSelected == true
| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult
Mithilfe der folgenden Abfrage können Sie ein besseres Verständnis für die gesamte Profilauswertung erlangen:
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName contains == "profileEvaluation"
| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult
Es ist keine Skalierungsaktion aufgetreten
Sie haben eine Skalierungsaktion erwartet, die jedoch nicht stattgefunden hat. Möglicherweise sind keine Ereignisse oder Protokolle für Skalierungsaktionen vorhanden.
Überprüfen Sie die Metriken der Autoskalierung, wenn Sie eine metrikbasierte Skalierungsregel verwenden. Möglicherweise entspricht der Wert Beobachtete Metrik oder Beobachtete Kapazität nicht Ihren Erwartungen, und daher wurde die Skalierungsregel nicht ausgelöst. Sie sehen weiterhin Auswertungen, jedoch keine Regel für die horizontale Skalierung. Möglicherweise wurde die Skalierungsaktion auch durch die Abkühldauer verhindert.
Überprüfen Sie die Autoskalierungsprotokolle für den Zeitraum, in dem Sie die Skalierungsaktion erwartet haben. Überprüfen Sie alle vorgenommenen Auswertungen, und untersuchen Sie, warum keine Skalierungsaktion ausgelöst wurde.
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation"
| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult
Die Skalierungsaktion ist fehlgeschlagen.
In einigen Fällen hat der Autoskalierungsdienst die Skalierungsaktion möglicherweise initiiert, das System hat sich jedoch gegen die Skalierung entschieden oder konnte die Skalierungsaktion nicht abschließen. Führen Sie diese Abfrage aus, um die fehlgeschlagenen Skalierungsaktionen zu finden:
AutoscaleScaleActionsLog
| where ResultType == "Failed"
| project ResultDescription
Erstellen Sie Warnungsregeln, um über Autoskalierungsaktionen und auftretende Fehler benachrichtigt zu werden. Sie können auch Warnungsregeln erstellen, um Benachrichtigungen über Autoskalierungsereignisse zu erhalten.
Schema der Ressourcenprotokolle für die Autoskalierung
Weitere Informationen finden Sie unter Ressourcenprotokolle für die Autoskalierung.
Nächste Schritte
Informieren Sie sich über bewährte Methoden der Autoskalierung.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für