Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Migration von hoch leistungsfähigen Exadata-Datenbanken in die Cloud wird immer wichtiger für Microsoft-Kunden. Lieferketten-Softwaresuiten legen die Messlatte aufgrund der hohen Anforderungen an Speicher-E/A mit einer gemischten Lese- und Schreibarbeitsauslastung, die von einem einzelnen Serverknoten gesteuert wird, hoch. Azure-Infrastruktur in Kombination mit Azure NetApp Files ist in der Lage, die Anforderungen dieser sehr anspruchsvollen Workload zu erfüllen. In diesem Artikel wird gezeigt, wie diese Nachfrage für einen Kunden erfüllt wurde und wie Azure die Anforderungen Ihrer kritischen Oracle-Workloads erfüllen kann.
Oracle-Leistung im Unternehmensmaßstab
Wenn Sie die oberen Grenzwerte der Leistung untersuchen, ist es wichtig, alle Einschränkungen zu erkennen und zu reduzieren, welche die Ergebnisse verfälschen könnten. Wenn beispielsweise die Leistungsfähigkeit eines Speichersystems nachgewiesen werden soll, sollte der Client idealerweise so konfiguriert werden, dass die CPU nicht zu einem mildernden Faktor wird, bevor die Speicherleistungsgrenzwerte erreicht werden. Zu diesem Zweck wurden Tests mit dem E104ids_v5-Instanztyp gestartet, da diese VM nicht nur mit einer Netzwerkschnittstelle von 100 GBit/s ausgestattet ist, sondern mit einem ebenso großen Grenzwert für ausgehenden Datenverkehr (100 GBit/s).
Die Tests fanden in zwei Phasen statt:
- Die erste Phase konzentrierte sich auf Tests mit Kevin Clossons inzwischen branchenüblichen SLOB2-Tool (Silly Little Oracle Benchmark) – Version 2.5.4. Ziel ist es, so viel Oracle-E/A wie möglich von einem virtuellen Computer (VM) auf mehrere Azure NetApp Files-Volumes zu fahren und dann mit mehr Datenbanken zu skalieren, um die lineare Skalierung zu veranschaulichen.
- Nachdem wir die Skalierungsgrenzen getestet hatten, wechselten wir für eine Testphase mit einer echten Supply-Chain-Anwendung und realen Daten zum günstigeren, aber fast genauso leistungsfähigen E96ds_v5.
Vertikale SLOB2-Skalierungsleistung
In den folgenden Diagrammen wird das Leistungsprofil einer einzelnen E104ids_v5 Azure-VM erfasst, auf der eine einzelne Oracle 19c-Datenbank mit acht Azure NetApp Files-Volumes mit acht Speicherendpunkten ausgeführt wird. Die Volumes sind auf drei ASM-Datenträgergruppen verteilt: Daten, Protokoll und Archiv. Fünf Volumes wurden der Datendatenträgergruppe, zwei Volumes der Protokolldatenträgergruppe und ein Volume der Archivdatenträgergruppe zugeordnet. Alle in diesem Artikel erfassten Ergebnisse wurden mithilfe von Produktions-Azure-Regionen und aktiven Produktions-Azure-Diensten gesammelt.
Um Oracle auf virtuellen Azure-Computern mit mehreren Azure NetApp Files-Volumes auf mehreren Speicherendpunkten bereitzustellen, verwenden Sie Anwendungsvolumegruppe für Oracle.
Einzelhostarchitektur
Das folgende Diagramm zeigt die Architektur, für die Tests durchgeführt wurden. Beachten Sie, dass die Oracle-Datenbank über mehrere Azure NetApp Files-Volumes und -Endpunkte verteilt ist.

Einzelhostspeicher-E/A
Das folgende Diagramm zeigt eine zufällig ausgewählte Workload von 100 % mit einem Datenbankpuffertrefferverhältnis von ca. 8 %. SLOB2 konnte ungefähr 850.000 E/A-Anforderungen pro Sekunde steuern und gleichzeitig eine sequenzielle Leseereignislatenz der DB-Datei beibehalten. Mit einer Datenbankblockgröße von 8K, die ungefähr 6.800 MiB/s des Speicherdurchsatzes beträgt.

Einzelhostdurchsatz
Das folgende Diagramm zeigt, dass Azure NetApp Files für bandbreitenintensive sequenzielle E/A-Workloads wie vollständige Tabellenüberprüfungen oder RMAN-Aktivitäten die volle Bandbreitenfunktionen der E104ids_v5-VM selbst bereitstellen kann.

Hinweis
Da sich die Computeinstanz am theoretischen Maximum ihrer Bandbreite befindet, führt das Hinzufügen zusätzlicher Anwendungsparallelität nur zu einer erhöhten clientseitigen Latenz. Dies führt dazu, dass SLOB2-Workloads den zielbezogenen Abschlusszeitrahmen überschreiten, weshalb die Threadanzahl auf sechs begrenzt wurde.
Horizontale SLOB2-Skalierungsleistung
Die folgenden Diagramme erfassen das Leistungsprofil von drei E104ids_v5 Azure-VMs, die jeweils eine einzelne Oracle 19c-Datenbank ausführen, jede mit ihren eigenen Azure NetApp Files-Volumes und einem identischen ASM-Datenträgergruppenlayout, wie im Abschnitt „Skalierungsleistung“ beschrieben. Die Grafiken zeigen, dass die Leistung mit Azure NetApp Files multi-volume/multi-endpoint einfach, konsistent und vorhersagbar aufskaliert wird.
Multihostarchitektur
Das folgende Diagramm zeigt die Architektur, für die Tests durchgeführt wurden. Beachten Sie, dass die drei Oracle-Datenbanken über mehrere Azure NetApp Files-Volumes und -Endpunkte verteilt sind. Endpunkte können einem einzelnen Host zugeordnet werden, wie mit Oracle VM 1 gezeigt, oder unter Hosts freigegeben werden, wie mit Oracle VM2 und Oracle VM 3 gezeigt.

Multihostspeicher-E/A
Das folgende Diagramm zeigt eine zufällig ausgewählte Workload von 100 % mit einem Datenbankpuffertrefferverhältnis von ca. 8 %. SLOB2 konnte ca. 850.000 E/A-Anforderungen pro Sekunde auf allen drei Hosts einzeln steuern. SLOB2 war in der Lage, dies zu bewerkstelligen, während es parallel zu einer kollektiven Gesamtzahl von etwa 2.500.000 E/A-Anforderungen pro Sekunde ausgeführt wurde, wobei jeder Host immer noch eine Latenzzeit von weniger als einer Millisekunde für sequenzielle Leseereignisse von DB-Dateien aufwies. Bei einer Datenbankblockgröße von 8K beträgt dies ungefähr 20.000 MiB/s für die drei Hosts.

Multihostdurchsatz
Das folgende Diagramm zeigt, dass Azure NetApp Files für sequenzielle Workloads die volle Bandbreitenfunktionen der E104ids_v5-VM selbst bereitstellen kann, selbst beim horizontalen Skalieren. SLOB2 kann die E/A mit insgesamt über 30 000 MiB/s auf den drei Hosts steuern können, während sie parallel ausgeführt werden.

Leistung in der Realität
Nachdem Skalierungsgrenzwerte mit SLOB2 getestet wurden, wurden Tests mit einer echten Supply-Chain-Anwendungssuite mit Oracle auf Azure NetApp-Dateien durchgeführt und die Ergebnisse waren hervorragend. Die folgenden Daten aus dem Oracle Automatic Workload Repository-Bericht (AWR) geben einen Überblick über die Leistung eines bestimmten kritischen Auftrags.
Diese Datenbank hat neben der Anwendungsauslastung erhebliche zusätzliche E/A-Vorgänge, da Flashback aktiviert ist und eine Datenbankblockgröße von 16k aufweist. Aus dem E/A-Profilabschnitt des AWR-Berichts geht hervor, dass das Verhältnis zwischen Schreib- und Lesevorgängen sehr hoch ist.
| - | Lese- und Seitenschreibvorgänge pro Sekunde | Lesevorgänge pro Sekunde | Schreibvorgänge pro Sekunde |
|---|---|---|---|
| Gesamt (MB) | 4.988,1 | 1.395,2 | 3.592,9 |
Obwohl das sequenzielle Lesewarteereignis der DB-Datei mit 2,2 ms eine höhere Latenz als bei den SLOB2-Tests aufwies, konnte dieser Kunde eine fünfzehnminütige Reduzierung der Auftragsausführungszeit feststellen, wenn er von einer RAC-Datenbank auf Exadata zu einer Single-Instance-Datenbank in Azure wechselte.
Azure-Ressourceneinschränkungen
Alle Systeme stoßen irgendwann an Ressourcenbeschränkungen, die traditionell als Chokepoints bezeichnet werden. Datenbankworkloads, insbesondere anspruchsvolle, wie z. B. Supply-Chain-Anwendungssuiten, sind ressourcenintensive Entitäten. Diese Ressourcenbeschränkungen herauszufinden und zu überwinden ist entscheidend für eine erfolgreiche Bereitstellung. In diesem Abschnitt werden verschiedene Einschränkungen beleuchtet, die Sie in einer solchen Umgebung erwarten und wie sie überwunden werden können. In jedem Unterkapitel lernen Sie sowohl die bewährten Methoden als auch die dahinter stehenden Überlegungen kennen.
Virtuelle Computer
In diesem Abschnitt werden die Kriterien beschrieben, die bei der Auswahl von VMs für optimale Leistung berücksichtigt werden sollten, sowie die Gründe für ihre Auswahl für die Tests. Azure NetApp Files ist ein NAS-Dienst (Network Attached Storage), weshalb eine geeignete Größenanpassung der Netzwerkbandbreite für eine optimale Leistung von entscheidender Bedeutung ist.
Chipsätze
Das erste interessante Thema ist die Chipsatzauswahl. Stellen Sie aus Konsistenzgründen sicher, dass die von Ihnen ausgewählte VM-SKU auf einem einzelnen Chipsatz basiert. Die Intel-Variante von E_v5-VMs läuft auf einer Konfiguration des Intel Case Platinum 8370C der dritten Konfiguration (Ice Lake). Alle VMs in dieser Familie sind mit einer einzigen Netzwerkschnittstelle von 100 GBit/s ausgestattet. Im Gegensatz dazu basiert die E_v3-Serie, die als Beispiel erwähnt wird, auf vier separaten Chipsätzen mit verschiedenen physischen Netzwerkbandbreiten. Die vier Chipsätze, die in der E_v3-Familie (Broadwell, Skylake, Cascade Lake, Haswell) verwendet werden, weisen unterschiedliche Prozessorgeschwindigkeiten auf, die sich auf die Leistungsmerkmale des Computers auswirken.
Lesen Sie die Azure Compute-Dokumentation, insbesondere die Informationen zu den Chipsatzoptionen. Weitere Informationen finden Sie in Bewährte Methoden in Bezug auf Azure VM SKUs für Azure NetApp Files. Die Auswahl einer MV mit einem einzelnen Chipsatz ist für eine optimale Konsistenz vorzuziehen.
Verfügbare Netzwerkbandbreite
Es ist wichtig, den Unterschied zwischen der verfügbaren Bandbreite der VM-Netzwerkschnittstelle und der gemessenen Bandbreite zu verstehen, die für diese Schnittstelle gilt. Wenn in der Azure Compute-Dokumentation von Einschränkungen der Netzwerkbandbreite die Rede ist, gelten diese Einschränkungen nur für den Ausgang (Schreibzugriff). Eingehender Datenverkehr (Lesedatenverkehr) wird nicht getaktet und ist daher nur durch die physische Bandbreite der Netzwerkadapterkarte (Network Interface Card, NIC) selbst begrenzt. Die Netzwerkbandbreite der meisten virtuellen Computer überschreitet den Grenzwert, der für den Computer gilt.
Da Azure NetApp Files-Volumes an das Netzwerk angeschlossen sind, kann das Limit für ausgehenden Datenverkehr so verstanden werden, dass es sich speziell auf Schreibvorgänge bezieht, während das eingehende Limit für Lesevorgänge und leseähnliche Workloads definiert ist. Während das ausgehende Limit der meisten Computer größer ist als die Netzwerkbandbreite der NIC, gilt dies nicht für E104_v5, die für die Tests in diesem Artikel verwendet wurde. E104_v5 verfügt über eine NIC von 100 GBit/s, wobei auch das ausgehende Limit auf 100 GBit/s festgelegt ist. Im Vergleich dazu hat E96_v5 mit 100-Gbit/s-NIC ein eingehndes Limit von 35 Gbit/s, während der Eingang bei 100 Gbit/s nicht eingeschränkt ist. Wenn die Größe der VMs abnimmt, verringern sich die Grenzen für den ausgehenden Datenverkehr, aber der Eingang wird nicht durch logisch auferlegte Grenzen behindert.
Ausgehende Grenzwerte sind VM-weit und werden als solche auf alle netzwerkbasierten Workloads angewendet. Bei der Verwendung von Oracle Data Guard werden alle Schreibvorgänge in Archivprotokolle verdoppelt und müssen bei den Überlegungen zum ausgehenden Grenzwert berücksichtigt werden. Dies gilt auch für Archivprotokolle mit mehreren Zielorten und RMAN, falls verwendet. Machen Sie sich bei der Auswahl von VMs mit Befehlszeilentools wie ethtool vertraut, die die Konfiguration der NIC offenlegen, da Azure die Konfiguration der Netzwerkschnittstelle nicht dokumentiert.
Netzwerkparallelität
Azure-VMs und Azure NetApp Files-Volumes sind mit bestimmten Bandbreiten ausgestattet. Wie bereits gezeigt, kann eine VM theoretisch die ihr zur Verfügung gestellte Bandbreite verbrauchen, solange sie über genügend CPU-Kapazität verfügt, d. h. innerhalb der Grenzen der Netzwerkkarte und des angewandten ausgehenden Grenzwerts. In der Praxis hängt der erreichbare Durchsatz jedoch von der Gleichzeitigkeit der Workload im Netzwerk ab, d. h. von der Anzahl der Netzwerkflüsse und Netzwerkendpunkte.
Lesen Sie den Abschnitt Grenzwerte für Netzwerkflows in der Dokumentation zur VM-Netzwerkbandbreite, um mehr darüber zu erfahren. Das Fazit: Je mehr Netzwerkflows den Client mit dem Speicher verbinden, desto größer ist die potenzielle Leistung.
Oracle unterstützt zwei separate NFS-Clients, Kernel NFS und Direct NFS (dNFS). Kernel NFS unterstützte bis vor kurzem einen einzigen Netzwerkflow zwischen zwei Endpunkten (Rechner – Speicher). Direct NFS, das leistungsfähigere der beiden Systeme, unterstützt eine variable Anzahl von Netzwerkflows – Tests haben Hunderte von einzelnen Verbindungen pro Endpunkt ergeben –, die je nach Auslastung zunehmen oder abnehmen. Aufgrund der Skalierung der Netzwerkflows zwischen zwei Endpunkten ist Direct NFS gegenüber Kernel NFS bei weitem vorzuziehen und als solches die empfohlene Konfiguration. Die Azure NetApp Files-Produktgruppe empfiehlt die Verwendung von Kernel NFS mit Oracle-Workloads nicht. Weitere Informationen dazu finden Sie unter Vorteile der Verwendung von Azure NetApp Files mit Oracle Database.
Ausführungsparallelität
Die Verwendung von Direct NFS, einem einzigen Chipsatz für Konsistenz und die Kenntnis der Bandbreitenbeschränkungen im Netzwerk bringen Sie nur bedingt weiter. Am Ende steuert die Anwendung die Leistung. Proofs of Concept mit SLOB2 und Proofs of Concept mit einer realen Supply-Chain-Anwendungssuite gegen echte Kundendaten konnten nur deshalb signifikante Mengen an Durchsatz erzielen, weil die Anwendungen mit einem hohen Grad an Gleichzeitigkeit liefen; erstere mit einer erheblichen Anzahl von Threads pro Schema, letztere mit mehreren Verbindungen von mehreren Anwendungsservern. Kurz gesagt, Parallelität treibt die Workload an, geringe Parallelität gleich geringer Durchsatz, hohe Parallelität gleich hoher Durchsatz, solange die Infrastruktur vorhanden ist, um dies zu unterstützen.
Beschleunigte Netzwerke
Der beschleunigte Netzwerkbetrieb ermöglicht die E/A-Virtualisierung mit Einzelstamm (Single Root I/O Virtualization, SR-IOV) in einer VM und somit eine erhebliche Steigerung der Netzwerkleistung. Über diesen Hochleistungspfad wird der Host des Datenpfads umgangen, um Latenzen, Jitter und CPU-Auslastung zu verringern. So können mit unterstützten VM-Typen die anspruchsvollsten Netzwerkworkloads genutzt werden. Wenn Sie VMs über Konfigurationsverwaltungsprogramme wie Terraform oder die Befehlszeile bereitstellen, beachten Sie bitte, dass die Netzwerkbeschleunigung nicht standardmäßig aktiviert ist. Aktivieren Sie den beschleunigten Netzwerkbetrieb für optimale Leistung. Beachten Sie, dass die Netzwerkbeschleunigung für jede einzelne Netzwerkschnittstelle aktiviert oder deaktiviert wird. Das beschleunigte Netzwerkfeature kann dynamisch aktiviert oder deaktiviert werden.
Hinweis
Dieser Artikel enthält Verweise auf den Begriff SLAVE, einen Begriff, den Microsoft nicht mehr verwendet. Sobald der Begriff aus der Software entfernt wird, wird er auch aus diesem Artikel entfernt.
Eine maßgebliche Methode, um sicherzustellen, dass die Netzwerkbeschleunigung für eine Netzwerkkarte aktiviert ist, ist die Verwendung des Linux-Terminals. Wenn das beschleunigte Netzwerk für eine NIC aktiviert ist, ist eine zweite virtuelle NIC mit der ersten NIC verbunden. Diese zweite NIC wird vom System mit aktiviertem SLAVE-Flag konfiguriert. Wenn keine NIC mit dem SLAVE-Flag vorhanden ist, ist das beschleunigte Netzwerk für diese Schnittstelle nicht aktiviert.
In dem Szenario, in dem mehrere NICs konfiguriert sind, müssen Sie feststellen, welche SLAVE-Schnittstelle mit der NIC verbunden ist, die zum Mounten des NFS-Volumes verwendet wird. Das Hinzufügen von Netzwerkschnittstellenkarten zum virtuellen Computer hat keine Auswirkungen auf die Leistung.
Verwenden Sie den folgenden Prozess, um die Zuordnung zwischen konfigurierter Netzwerkschnittstelle und der zugehörigen virtuellen Schnittstelle zu identifizieren. Dieser Vorgang bestätigt, dass die Netzwerkbeschleunigung für eine bestimmte NIC auf Ihrem Linux-Rechner aktiviert ist und zeigt die physische Eingangsgeschwindigkeit an, die die NIC potenziell erreichen kann.
- Führen Sie den
ip a-Befehl aus: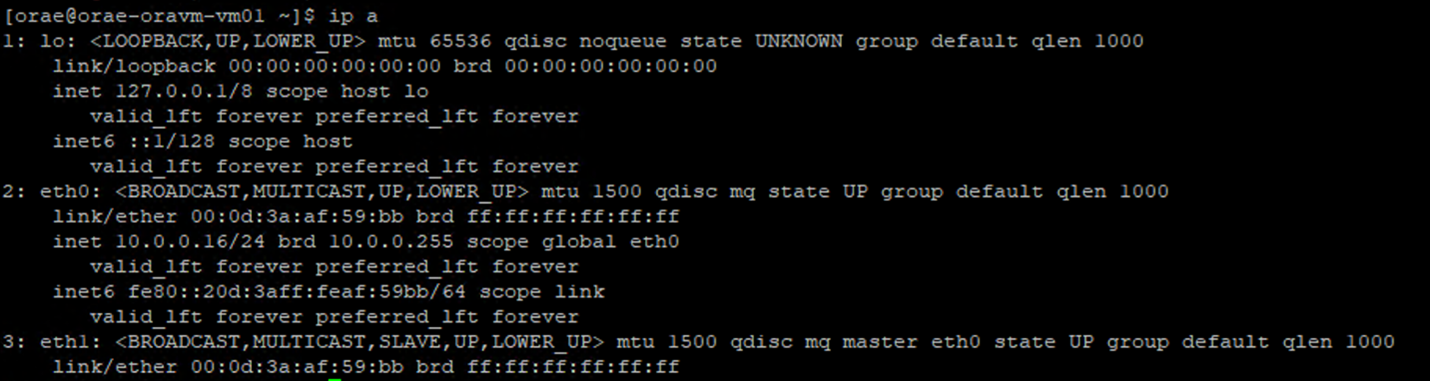
- Geben Sie das
/sys/class/net/-Verzeichnis der NIC-ID an, die Sie überprüfen (eth0im Beispiel), undgrepfür das Wort „lower“:ls /sys/class/net/eth0 | grep lower lower_eth1 - Führen Sie den
ethtool-Befehl für das Ethernet-Gerät aus, das im vorherigen Schritt als das untere Gerät identifiziert wurde.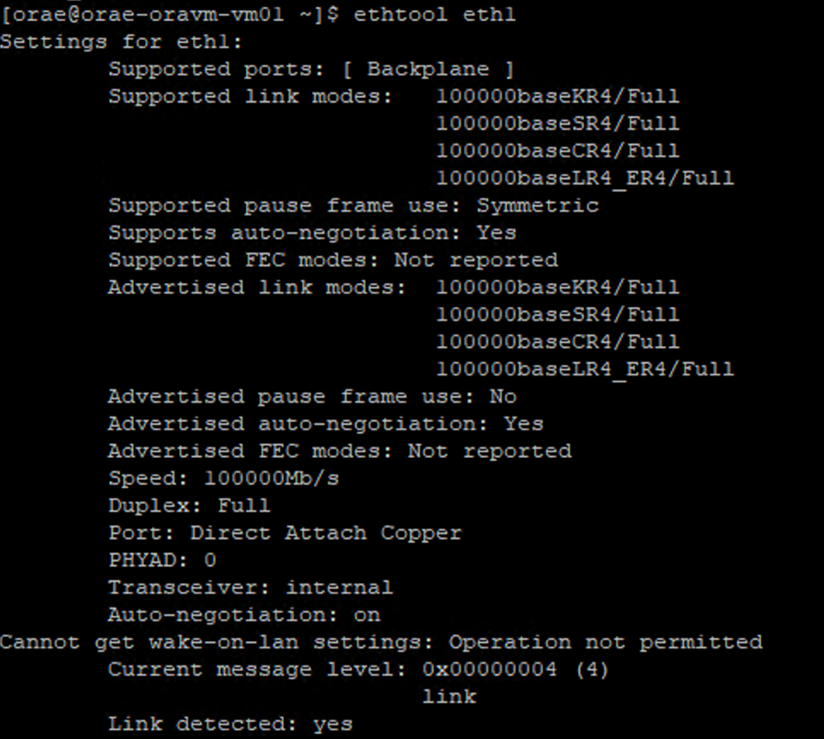
Azure VM: Netzwerk- und Datenträgerbandbreitenbeschränkungen
Beim Lesen der Dokumentation zu Azure VM-Leistungsbeschränkungen ist ein gewisses Fachwissen erforderlich. Unbedingt beachten:
- Temporärer Speicherdurchsatz und IOPS-Zahlen beziehen sich auf die Leistungsfunktionen des kurzlebigen On-Box-Speichers, der direkt an die VM angefügt ist.
- Nicht zwischengespeicherter Datenträgerdurchsatz und E/A-Zahlen beziehen sich speziell auf Azure Disk (Premium, Premium v2 und Ultra) und haben keine Auswirkungen auf netzwerkgebundenen Speicher wie Azure NetApp Files.
- Das Anfügen zusätzlicher NICs an den virtuellen Computer hat keine Auswirkungen auf die Leistungsbeschränkungen oder Leistungsfunktionen der VM (das wurde dokumentiert und getestet).
- Die maximale Netzwerkbandbreite bezieht sich auf Ausgangsgrenzwerte (d. h. Schreibvorgänge, wenn Azure NetApp Files beteiligt ist), die für die VM-Netzwerkbandbreite angewendet werden. Es werden keine Eingangsgrenzwerte (d. h. Lesevorgänge, wenn Azure NetApp Files beteiligt ist) angewendet. Bei ausreichender CPU, ausreichender Netzwerkparallelität und ausreichend vielen Endpunkten kann eine VM theoretisch den eingehenden Datenverkehr bis an die Grenzen der NIC treiben. Wie im Abschnitt Verfügbare Netzwerkbandbreite erwähnt, sollten Sie Tools wie
ethtoolverwenden, um die Bandbreite der NIC anzuzeigen.
Ein Beispieldiagramm soll als Referenz dienen:
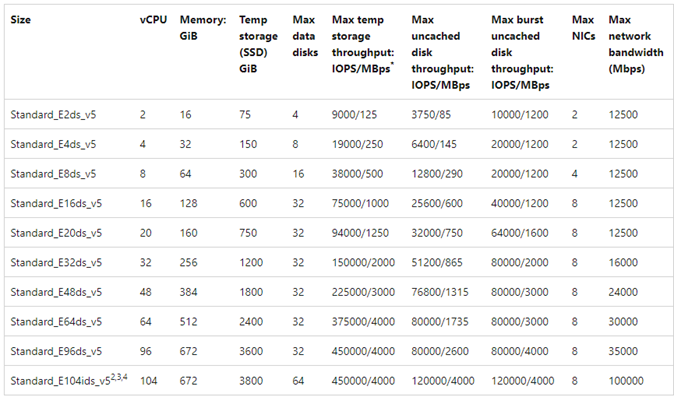
Azure NetApp-Dateien
Der Azure First-Party-Speicherdienst Azure NetApp Files bietet eine hochgradig verfügbare vollständig verwaltete Speicherlösung, die die zuvor eingeführten anspruchsvollen Oracle-Workloads unterstützen kann.
Da die Grenzen der Speicherleistung bei vertikaler Skalierung in einer Oracle-Datenbank gut bekannt sind, konzentriert sich dieser Artikel bewusst auf die Speicherleistung bei horizontaler Skalierung. Das horizontale Skalieren der Speicherleistung bedeutet, dass eine einzelne Oracle-Instanz Zugriff auf viele Azure NetApp Files-Volumes erhält, in denen diese Volumes über mehrere Speicherendpunkte verteilt werden.
Durch eine solche Skalierung einer Datenbankarbeitsauslastung über mehrere Volumes ist die Leistung der Datenbank unabhängig von den Obergrenzen der Volumes und Endpunkte. Da der Speicher keine Leistungsbeschränkungen mehr auferlegt, wird die VM-Architektur (CPU, NIC und VM-Ausgangsgrenzwerte) zum Engpass, den es zu überwinden gilt. Wie im VM-Abschnitt erwähnt, wurde bei der Auswahl der E104ids_v5- und E96ds_v5-Instanzen darauf geachtet.
Unabhängig davon, ob eine Datenbank auf einem einzigen Volume mit großer Kapazität oder auf mehrere kleinere Volumes verteilt ist, sind die finanziellen Gesamtkosten dieselben. Der Vorteil der Verteilung von E/A auf mehrere Volumes und Endpunkte im Gegensatz zu einem einzelnen Volume und Endpunkt ist die Vermeidung von Bandbreitenbeschränkungen – Sie nutzen nur das, wofür Sie bezahlen.
Wichtig
Wenn Sie Azure NetApp Dateien in einer multiple volume:multiple endpoint-Konfiguration einsetzen möchten, wenden Sie sich an Ihren Azure NetApp Files-Experten oder Cloud Solution Architect, um Unterstützung zu erhalten.
Datenbank
Die Datenbankversion 19c von Oracle ist die aktuelle Langzeitversion von Oracle und diejenige, die für die Erstellung aller in diesem Dokument besprochenen Testergebnisse verwendet wurde.
Um die beste Leistung zu erzielen, wurden alle Datenbank-Volumes über Direct NFS eingebunden. Kernel NFS wird aufgrund von Leistungseinschränkungen nicht empfohlen. Einen Leistungsvergleich zwischen den beiden Clients finden Sie unter Leistung von Oracle-Datenbanken auf einzelnen Azure NetApp Files-Volumes. Beachten Sie, dass alle relevanten dNFS-Patches (Oracle Support ID 1495104) angewendet wurden, ebenso wie die bewährten Methoden, die im Bericht Oracle-Datenbanken in Microsoft Azure mithilfe von Azure NetApp Files beschrieben wurden.
Oracle und Azure NetApp Files unterstützen zwar sowohl NFSv3 als auch NFSv4.1, aber da NFSv3 das ausgereiftere Protokoll ist, gilt es allgemein als die stabilere und zuverlässigere Option für Umgebungen, die sehr störanfällig sind. Die in diesem Artikel beschriebenen Tests wurden über NFSv3 abgeschlossen.
Wichtig
Einige der empfohlenen Patches, die Oracle in Support-ID 1495104 dokumentiert, sind für die Aufrechterhaltung der Datenintegrität bei Verwendung von dNFS wichtig. Die Anwendung dieser Patches wird für Produktionsumgebungen dringend empfohlen.
Die automatische Speicherverwaltung (Automatic Storage Management, ASM) wird für NFS-Volumes unterstützt. Obwohl ASM in der Regel mit blockbasiertem Speicher assoziiert wird, bei dem ASM sowohl die logische Datenträgerverwaltung (LVM) als auch das Dateisystem ersetzt, spielt ASM in NFS-Szenarien mit mehreren Volumes eine wertvolle Rolle und ist eine Überlegung wert. Ein solcher Vorteil von ASM, die dynamische Online-Erweiterung und der Ausgleich zwischen neu hinzugefügten NFS-Volumes und Endpunkten, vereinfacht die Verwaltung und ermöglicht eine beliebige Erweiterung von Leistung und Kapazität. Obwohl ASM an sich die Leistung einer Datenbank nicht erhöht, vermeidet seine Verwendung heiße Dateien und die Notwendigkeit, die Dateiverteilung manuell zu pflegen – ein Vorteil, der leicht zu erkennen ist.
Für alle in diesem Artikel besprochenen Testergebnisse wurde eine ASM-over-dNFS-Konfiguration verwendet. Das folgende Diagramm veranschaulicht das ASM-Dateilayout innerhalb der Azure NetApp Files-Volumes und die Dateizuordnung zu den ASM-Datenträgergruppen.

Es gibt einige Einschränkungen bei der Verwendung von ASM über bereitgestellte Azure NetApp Files NFS-Volumes, wenn es um Speichermomentaufnahmen geht, die mit bestimmten architektonischen Überlegungen überwunden werden können. Wenden Sie sich an Ihren Azure NetApp Files-Spezialisten oder Cloud-Lösungsarchitekten, um diese Überlegungen eingehend zu besprechen.
Synthetische Testwerkzeuge und abstimmbare Werte
In diesem Abschnitt werden die Testarchitektur, die abstimmbaren Werte und die Konfigurationsdetails detailliert beschrieben. Während sich der vorherige Abschnitt auf die Gründe konzentriert, warum Konfigurationsentscheidungen getroffen werden, konzentriert sich dieser Abschnitt speziell auf das „Was“ der Konfigurationsentscheidungen.
Automatisierte Bereitstellung
- Die Datenbank-VMs werden mithilfe von Bash-Skripts bereitgestellt, die auf GitHub verfügbar sind.
- Das Layout und die Zuordnung mehrerer Azure NetApp Files-Volumes und -Endpunkte werden manuell abgeschlossen. Arbeiten Sie mit Ihrem Azure NetApp Files-Spezialisten oder Cloud Solution Architect zusammen, um Unterstützung zu erhalten.
- Die Rasterinstallation, die ASM-Konfiguration, die Datenbankerstellung und -konfiguration sowie die SLOB2-Umgebung auf jedem Computer werden mit Ansible konfiguriert, um Konsistenz zu gewährleisten.
- Parallele SLOB2-Testausführungen auf mehreren Hosts werden aus Gründen der Konsistenz und für gleichzeitige Ausführung ebenfalls mit Ansible durchgeführt.
Konfiguration des virtuellen Computers
| Konfiguration | Wert |
|---|---|
| Azure-Region | Europa, Westen |
| VM-SKU | E104ids_v5 |
| NIC-Anzahl | 1 HINWEIS: Das Hinzufügen von vNICs hat keine Auswirkungen auf die Systemanzahl. |
| Max. ausgehende Netzwerkbandbreite (Mbps) | 100.000 |
| Temporärer Speicher (SSD): GiB | 3.800 |
Systemkonfiguration
Alle für Oracle erforderlichen Systemkonfigurationseinstellungen für Version 19c wurden gemäß der Oracle-Dokumentation implementiert.
Die folgenden Parameter wurden der /etc/sysctl.conf-Linux-Systemdatei hinzugefügt:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp-Dateien
Alle Azure NetApp Files-Volumes wurden mit den folgenden NFS-Bereitstellungsoptionen bereitgestellt.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Datenbankparameter
| Parameter | Wert |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3G |
pga_aggregate_limit |
3G |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
SLOB2-Konfiguration
Alle Workloads für die Tests wurden mit dem SLOB2-Tool Version 2.5.4 erzeugt.
Vierzehn SLOB2-Schemata wurden in einen Standard-Oracle-Tabellenbereich geladen und ausgeführt. In Kombination mit den aufgeführten Einstellungen der Slob-Konfigurationsdatei belief sich die SLOB2-Datenmenge auf 7 TiB. Die folgenden Einstellungen spiegeln eine zufällige Leseausführung für SLOB2 wider. Der Konfigurationsparameter SCAN_PCT=0 wurde während der sequenziellen Tests in SCAN_PCT=100 geändert.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
Für zufällige Lesetests wurden neun SLOB2-Ausführungen durchgeführt. Die Threadanzahl wurde um sechs erhöht, wobei jede Testiteration mit 1 beginnt.
Für sequenzielle Tests wurden sieben SLOB2-Ausführungen durchgeführt. Die Threadanzahl wurde um zwei erhöht, wobei jede Testiteration mit 1 beginnt. Die Threadanzahl wurde aufgrund der maximalen Grenzwerte für die Netzwerkbandbreite auf sechs begrenzt.
AWR-Metriken
Alle Leistungsmetriken wurden über das Oracle Automatic Workload Repository (AWR) gemeldet. Im Folgenden finden Sie die in den Ergebnissen dargestellten Metriken:
- Durchsatz: die Summe des durchschnittlichen Lesedurchsatzes und des Schreibdurchsatzes aus dem Abschnitt „AWR-Auslastungsprofil“
- Durchschnittliche Lese-E/A-Anforderungen aus dem Abschnitt „AWR-Auslastungsprofil“
- Durchschnittliche Wartezeit für das Warteereignis des sequenziellen Lesevorgangs der DB-Datei aus dem Abschnitt „Warteereignisse im AWR-Vordergrund“
Migrieren von speziell entwickelten Systemen in die Cloud
Oracle Exadata ist ein technisches System – eine Kombination aus Hardware und Software, die als am stärksten optimierte Lösung für die Ausführung von Oracle-Workloads gilt. Obwohl die Cloud im Gesamtbild der technischen Welt erhebliche Vorteile bietet, können diese spezialisierten Systeme für diejenigen, die die Optimierungen gelesen und gesehen haben, die Oracle für ihre spezielle(n) Workload(s) entwickelt hat, unglaublich attraktiv aussehen.
Wenn es um die Ausführung von Oracle auf Exadata geht, gibt es einige häufige Gründe, warum Exadata gewählt wird:
- 1-2 Workloads mit hohem E/A-Aufkommen, die von Natur aus für Exadata-Funktionen geeignet sind, und da diese Workloads erhebliche von Exadata entwickelte Funktionen erfordern, wurden die übrigen Datenbanken, die zusammen mit ihnen laufen, auf Exadata konsolidiert.
- Komplizierte oder schwierige OLTP-Workloads, die eine Skalierung mit RAC erfordern und ohne tiefgreifende Kenntnisse der Oracle-Optimierung nur schwer mit proprietärer Hardware architektonisch umgesetzt werden können oder bei denen es sich um technische Schulden handelt, die nicht optimiert werden können.
- Nicht ausgelastete vorhandene Exadata mit verschiedenen Workloads: Dies ist entweder auf frühere Migrationen, das Ende der Lebensdauer einer früheren Exadata oder auf den Wunsch zurückzuführen, eine Exadata intern auszuführen/zu testen.
Für jede Migration von einem Exadata-System ist es wichtig, die Workloads zu verstehen und zu wissen, wie einfach oder komplex die Migration sein kann. Eine zweites Notwendigkeit besteht darin, den Grund für den Kauf von Exadata aus einer Statusperspektive zu verstehen. Exadata- und RAC-Kenntnisse werden stärker nachgefragt und haben möglicherweise dazu geführt, dass die technischen Interessenvertreter den Kauf eines solchen Systems empfohlen haben.
Wichtig
Unabhängig vom Szenario sollte die allgemeine Erkenntnis lauten: Je mehr Exadata-eigene Funktionen verwendet werden, desto komplexer sind die Migration und die Planung für jede Datenbank-Workload, die von einer Exadata stammt. In Umgebungen, in denen die proprietären Funktionen von Exadata nicht in großem Umfang genutzt werden, kann der Migrations- und Planungsprozess vereinfacht werden.
Es gibt mehrere Tools, mit denen diese Workloadmöglichkeiten bewertet werden können:
- Das AWR (Automatic Workload Repository)
- Alle Exadata-Datenbanken sind für die Verwendung von AWR-Berichten und damit verbundenen Leistungs- und Diagnosefunktionen lizenziert.
- Ist immer aktiviert und sammelt Daten, die verwendet werden können, um historische Workloadinformationen anzuzeigen und die Nutzung zu bewerten. Höchstwerte können die hohe Nutzung des Systems bewerten.
- AWR-Berichte mit größeren Fenstern können die Gesamtauslastung bewerten und bieten wertvolle Einblicke in die Nutzung von Funktionen und in die effektive Migration der Auslastung auf Nicht-Exadata. AWR-Spitzenberichte eignen sich dagegen am besten für die Leistungsoptimierung und Fehlersuche.
- Der globale (RAC-Aware) AWR-Bericht für Exadata enthält auch einen Exadata-spezifischen Abschnitt, der die Nutzung spezifischer Exadata-Funktionen aufschlüsselt und wertvolle Informationen über die Nutzung von Flash-Cache, Flash-Protokollierung, E/A und anderen Funktionen nach Datenbank und Zellknoten liefert.
Entkoppeln von Exadata
Bei der Identifizierung von Oracle Exadata-Workloads, die in die Cloud migriert werden sollen, sollten Sie die folgenden Fragen und Datenpunkte berücksichtigen:
- Verbraucht die Workload mehrere Exadata-Funktionen, abgesehen von den Hardwarevorteilen?
- Intelligente Scans
- Speicherindizes
- Flash-Cache
- Flash-Protokollierung
- Hybride Spaltenkomprimierung
- Ist die Arbeitsauslastung mit Exadata-Offloading effizient? Wie hoch ist der Anteil (mehr als 10 % der DB-Zeit) der Workload bei den Vordergrundereignissen mit der höchsten Zeit:
- Intelligenter Tabellenscan der Zelle (optimal)
- Physisches Lesen von Multiblockzellen (weniger optimal)
- Physisches Lesen einzelner Zellenblocks (am wenigsten optimal)
- Hybride Spaltenkomprimierung (HCC/EHCC): Wie ist das Verhältnis zwischen komprimiert und unkomprimiert:
- Verbringt die Datenbank mehr als 10 % der Datenbankzeit mit dem Komprimieren und Dekomprimieren von Daten?
- Prüfen Sie den Leistungsgewinn für Prädikate, die die Komprimierung in Abfragen verwenden: Lohnt sich der Gewinn im Vergleich zu der Menge, die durch die Komprimierung eingespart wird?
- Physische Zell-E/A: Prüfen Sie die Einsparungen durch:
- die Menge, die an den DB-Knoten geleitet wird, um die CPU auszugleichen.
- Identifizieren der Anzahl der durch den intelligenten Scan zurückgegebenen Bytes. Diese Werte können in E/A für den prozentualen Anteil der physischen Lesevorgänge von Einzelblöcken subtrahiert werden, sobald diese von Exadata migriert werden.
- Beachten Sie die Anzahl der logischen Lesevorgänge aus dem Cache. Bestimmen Sie, ob Flash-Cache in einer Cloud-IaaS-Lösung für die Workload benötigt wird.
- Vergleichen Sie den physischen Lese- und Schreibzugriff mit der Gesamtmenge, die im Cache ausgeführt wurde. Kann der Arbeitsspeicher erhöht werden, um physische Leseanforderungen zu eliminieren? (Es ist üblich, die SGA zu verkleinern, um das Offloading für Exadata zu erzwingen.)
- Identifizieren Sie in Systemstatistik, welche Objekte von welcher Statistik betroffen sind. Wenn Sie SQL optimieren, können weitere Indizierung, Partitionierung oder andere physische Optimierungen die Workload erheblich verbessern.
- Überprüfen Sie die Initialisierungsparameter auf Unterstriche (_) oder veraltete Parameter, die aufgrund der Auswirkungen auf die Datenbankebene, die sie auf die Leistung haben können, gerechtfertigt sein sollten.
Exadata-Serverkonfiguration
In Oracle Version 12.2 und höher wird eine Exadata-spezifische Ergänzung in den globalen AWR-Bericht aufgenommen. Dieser Bericht enthält Abschnitte, die einen außergewöhnlichen Wert für eine Migration aus Exadata bieten.
Exadata-Version und Systemdetails
Details zu Zellenknotenbenachrichtigungen
Exadata-Nononline-Datenträger
Ausreißerdaten für alle Exadata-Betriebssystemstatistiken
Gelb/Rosa: Beunruhigend. Exadata wird nicht optimal ausgeführt.
Rot: Die Exadata-Leistung ist erheblich beeiträchtigt.
Exadata-Betriebssystem-CPU-Statistik: Top-Zellen
- Diese Statistiken werden vom Betriebssystem für die Zellen erfasst und sind nicht auf diese Datenbank oder Instanzen beschränkt.
- Ein
vund ein dunkelgelber Hintergrund geben einen Ausreißerwert unterhalb des niedrigen Bereichs an. - Ein
^und ein hellgelber Hintergrund geben einen Ausreißerwert über dem hohen Bereich an. - Es werden die obersten Zellen nach prozentualer CPU angezeigt und in absteigender Reihenfolge der CPU sortiert
- Durchschnitt: 39,34 % CPU, 28,57 % Benutzer, 10,77 % System
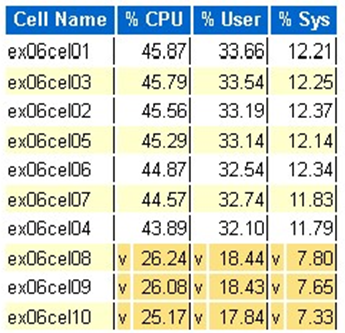
Lesevorgänge in einem physischen Block mit einer einzelnen Zelle
Flash-Cachenutzung
Temp E/A
Effizienz des Spaltencaches
Top-Datenbank nach E/A-Durchsatz
Obwohl Größenbewertungen durchgeführt werden können, gibt es einige Fragen zu den Durchschnittswerten und den simulierten Spitzenwerten, die in diese Werte für große Workloads integriert sind. Dieser Abschnitt, der am Ende eines AWR-Berichts zu finden ist, ist außergewöhnlich wertvoll, da er sowohl die durchschnittliche Flash- als auch die Datenträgernutzung der Top-10-Datenbanken auf Exadata zeigt. Obwohl viele davon ausgehen, dass sie Datenbanken für die Spitzenleistung in der Cloud dimensionieren wollen, ist dies für die meisten Implementierungen nicht sinnvoll (über 95 % liegen im durchschnittlichen Bereich; mit einem simulierten Spitzenwert berechnet, liegt der durchschnittliche Bereich bei über 98 %). Es ist wichtig, für das zu zahlen, was benötigt wird, selbst für die anspruchsvollsten Workloads von Oracle. Die Untersuchung der Top-Datenbanken nach IO-Durchsatz kann aufschlussreich sein, um den Ressourcenbedarf für die Datenbank zu verstehen.
Richtige Dimensionierung von Oracle mit AWR auf Exadata
Bei der Kapazitätsplanung für lokale Systeme ist es nur natürlich, dass ein erheblicher Overhead in die Hardware eingebaut wird. Die überdimensionierte Hardware muss die Oracle-Workload über mehrere Jahre hinweg bewältigen, unabhängig davon, ob die Workload aufgrund von Datenwachstum, Codeänderungen oder Upgrades zunimmt.
Einer der Vorteile der Cloud ist, dass die Ressourcen eines VM-Hosts und des Speichers skaliert werden können, wenn die Anforderungen steigen. Dies hilft, Cloud-Kosten und Lizenzkosten zu sparen, die an die Prozessornutzung gebunden sind (relevant bei Oracle).
Bei der richtigen Dimensionierung wird die Hardware aus der traditionellen Lift-and-Shift-Migration entfernt und die von Oracles Automatic Workload Repository (AWR) bereitgestellten Workload-Informationen verwendet, um die Workload auf Rechen- und Speichersysteme zu verlagern, die speziell für die Unterstützung der Workload in der Cloud der Wahl des Kunden ausgelegt sind. Der Prozess der richtigen Dimensionierung stellt sicher, dass die künftige Architektur die technischen Schulden der Infrastruktur und die Redundanz der Architektur beseitigt, die bei einer Duplizierung des lokalen Systems in die Cloud entstehen würde, und dass Cloud-Dienste implementiert werden, wann immer dies möglich ist.
Nach Schätzungen von Microsoft-Oracle-Experten sind mehr als 80 % der Oracle-Datenbanken überdimensioniert. Wenn Sie sich die Zeit nehmen, die Workload der Oracle-Datenbank vor der Migration in die Cloud richtig zu dimensionieren, können Sie entweder die gleichen Kosten erzielen oder sogar Einsparungen ermöglichen. Diese Bewertung erfordert von den Datenbankspezialisten im Team ein Umdenken in Bezug auf die Art und Weise, wie sie in der Vergangenheit die Kapazitätsplanung durchgeführt haben, aber es lohnt sich für die Beteiligten, in die Cloud und die Cloud-Strategie des Unternehmens zu investieren.
Nächste Schritte
- Ausführen Ihrer anspruchsvollsten Oracle-Workloads in Azure, ohne die Leistung oder Skalierbarkeit zu beeinträchtigen
- Lösungsarchitekturen mit Azure NetApp Files – Oracle
- Entwerfen und Implementieren einer Oracle-Datenbank in Azure
- Schätzungstool für die Dimensionierung von Oracle-Workloads auf Azure IaaS-VMs
- Referenzarchitekturen für Oracle Database Enterprise Edition in Azure
- Grundlegendes zu Azure NetApp Files-Anwendungsvolumegruppen für SAP HANA