Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Azure SQL Edge wird ab dem 30. September 2025 eingestellt. Weitere Informationen und Migrationsoptionen finden Sie im Einstellungshinweis.
Hinweis
Azure SQL Edge unterstützt die ARM64-Plattform nicht mehr.
In diesem Tutorial erfahren sie, wie Sie mit Azure Data Factory Daten aus einer Tabelle in einer Instanz von Azure SQL Edge inkrementell mit Azure Blob Storage synchronisieren.
Bevor Sie anfangen
Falls Sie in Ihrer Azure SQL Edge-Bereitstellung noch keine Datenbank oder Tabelle erstellt haben, verwenden Sie eine der folgenden Erstellungsmethoden:
Verwenden Sie SQL Server Management Studio oder Azure Data Studio zum Herstellen einer Verbindung mit SQL Edge. Führen Sie ein SQL-Skript zum Erstellen der Datenbank und der Tabelle aus.
Erstellen Sie eine Datenbank und Tabelle mithilfe von sqlcmd, indem Sie eine direkte Verbindung mit dem SQL Edge-Modul herstellen. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit der Datenbank-Engine mithilfe von „sqlcmd“.
Verwenden Sie „SQLPackage.exe“, um eine DAC-Paketdatei im SQL Edge-Container bereitzustellen. Sie können diesen Prozess automatisieren, indem Sie den URI der SqlPackage-Datei als Teil der gewünschten Konfiguration des Moduls angeben. Sie können auch direkt das Clienttool „SqlPackage.exe“ verwenden, um ein DAC-Paket in SQL Edge bereitzustellen.
Weitere Informationen zum Herunterladen von „SqlPackage.exe“ finden Sie unter Herunterladen und Installieren von „sqlpackage“. Im folgenden finden Sie einige Beispielbefehle für „SqlPackage.exe“. Weitere Informationen finden Sie in der Dokumentation zu „SqlPackage.exe“.
Erstellen eines DAC-Pakets
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Anwenden eines DAC-Pakets
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Erstellen einer SQL-Tabelle und einer Prozedur zum Speichern und Aktualisieren der Grenzwertstufen
Eine Grenzwerttabelle dient zum Speichern des letzten Zeitstempels, bis zu dem die Daten bereits mit Azure Storage synchronisiert wurden. Eine gespeicherte T-SQL-Prozedur (Transact-SQL) dient dazu, die Grenzwerttabelle nach jeder Synchronisierung zu aktualisieren.
Führen Sie für die SQL Edge-Instanz die folgenden Befehle aus:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Erstellen einer Data Factory-Pipeline
In diesem Abschnitt erstellen Sie eine Azure Data Factory-Pipeline, um Daten aus einer Tabelle in Azure SQL Edge mit Azure Blob Storage zu synchronisieren.
Erstellen einer Data Factory über die Data Factory-Benutzeroberfläche
Erstellen Sie eine Data Factory gemäß der Anleitung in diesem Tutorial.
Erstellen einer Data Factory-Pipeline
Wählen Sie auf der Seite Erste Schritte der Data Factory-Benutzeroberfläche die Kachel Pipeline erstellen aus.

Geben Sie im Fenster Eigenschaften der Pipeline auf der Seite Allgemein den Namen PeriodicSync ein.
Fügen Sie die Lookup-Aktivität hinzu, um den alten Grenzwert abzurufen. Erweitern Sie im Bereich Aktivitäten die Option Allgemein, und ziehen Sie die Lookup-Aktivität auf die Oberfläche des Pipeline-Designers. Ändern Sie den Namen der Aktivität in OldWatermark.
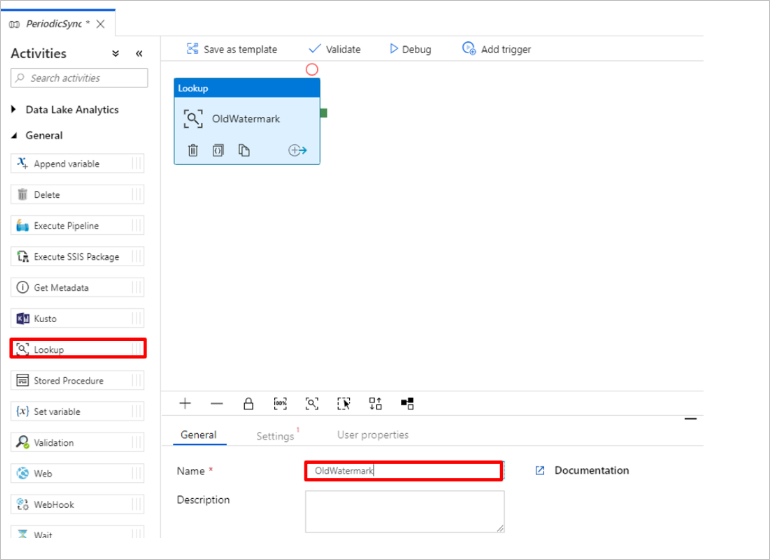
Wechseln Sie zur Registerkarte Einstellungen, und wählen Sie unter Source Dataset (Quelldataset) die Option Neu aus. Sie erstellen nun ein Dataset für Daten in der Grenzwerttabelle. Diese Tabelle enthält den alten Grenzwert, der für den vorherigen Kopiervorgang verwendet wurde.
Wählen Sie im Fenster Neues Dataset die Option Azure SQL Server und anschließend Weiter aus.
Geben Sie im Fenster Eigenschaften festlegen für das Dataset unter Name den Namen WatermarkDataset ein.
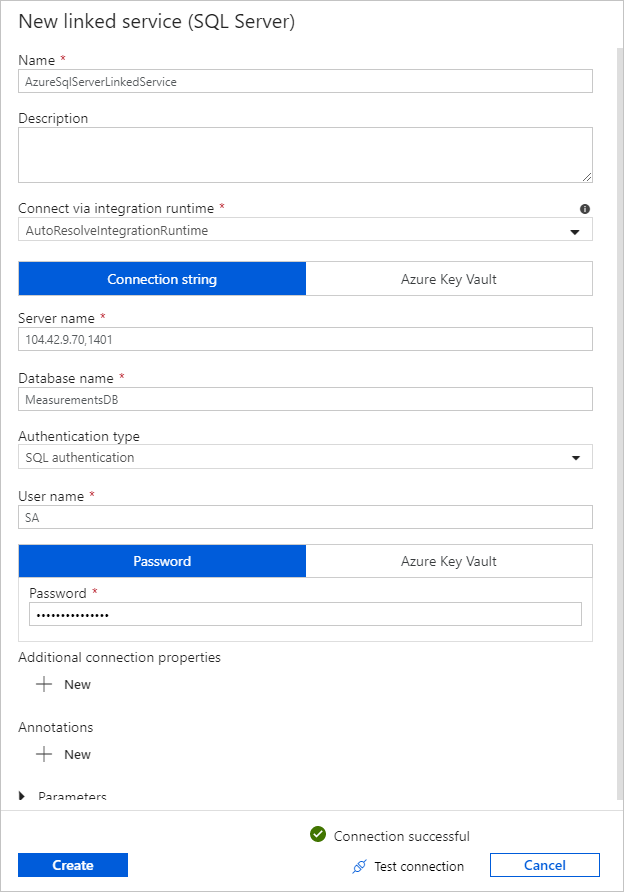
Wählen Sie unter Verknüpfter Dienst die Option Neu aus, und führen Sie dann die folgenden Schritte aus:
Geben Sie unter Name die Zeichenfolge SQLDBEdgeLinkedService ein.
Geben Sie unter Servername die Details Ihres SQL Edge-Servers ein.
Wählen Sie in der Liste Ihren Datenbanknamen aus.
Geben Sie unter Benutzername Ihren Benutzernamen und unter Kennwort Ihr Kennwort ein.
Wählen Sie Verbindung testen aus, um die Verbindung mit der SQL Edge-Instanz zu testen.
Wählen Sie "Erstellen" aus.
Wählen Sie OK aus.
Wählen Sie auf der Registerkarte Einstellungen die Option Bearbeiten aus.
Wählen Sie auf der Registerkarte Verbindung die Option
[dbo].[watermarktable]für Tabelle aus. Wählen Sie Datenvorschau aus, falls Sie eine Vorschau für die Daten in der Tabelle anzeigen möchten.Wechseln Sie zum Pipeline-Editor, indem Sie oben die Registerkarte „Pipeline“ oder in der Strukturansicht auf der linken Seite den Namen der Pipeline auswählen. Vergewissern Sie sich im Eigenschaftenfenster für die Lookup-Aktivität, dass in der Liste Source Dataset (Quelldataset) die Option WatermarkDataset ausgewählt ist.
Erweitern Sie im Bereich Aktivitäten die Option Allgemein, und ziehen Sie eine weitere Lookup-Aktivität auf die Oberfläche des Pipeline-Designers. Legen Sie im Eigenschaftenfenster auf der Registerkarte Allgemein als Namen NewWatermark fest. Mit dieser Lookup-Aktivität wird der neue Grenzwert aus der Tabelle mit den Quelldaten abgerufen, damit er in das Ziel kopiert werden kann.
Wechseln Sie im Eigenschaftenfenster für die zweite Lookup-Aktivität zur Registerkarte Einstellungen, und wählen Sie Neu aus, um ein Dataset zu erstellen, das auf die Quelltabelle mit dem neuen Grenzwert verweist.
Wählen Sie im Fenster Neues Dataset die SQL Edge-Instanz und anschließend Weiter aus.
Geben Sie im Fenster Eigenschaften festlegen unter Name den Namen SourceDataset ein. Wählen Sie unter Verknüpfter Dienst die Option SQLDBEdgeLinkedService aus.
Wählen Sie unter Tabelle die zu synchronisierende Tabelle aus. Sie können auch eine Abfrage für dieses Dataset angeben, wie weiter unten in diesem Tutorial beschrieben. Die Abfrage hat Vorrang vor der Tabelle, die Sie in diesem Schritt angeben.
Wählen Sie OK aus.
Wechseln Sie zum Pipeline-Editor, indem Sie oben die Registerkarte „Pipeline“ oder in der Strukturansicht auf der linken Seite den Namen der Pipeline auswählen. Vergewissern Sie sich im Eigenschaftenfenster für die Lookup-Aktivität, dass im Feld Source Dataset (Quelldataset) die Option SourceDataset ausgewählt ist.
Wählen Sie unter Abfrage verwenden die Option Abfrage aus. Aktualisieren Sie den Tabellennamen in der folgenden Abfrage, und geben Sie die Abfrage ein. Sie wählen nur den maximalen Wert von
timestampaus der Tabelle aus. Achten Sie darauf, First row only (Nur erste Zeile) auszuwählen.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];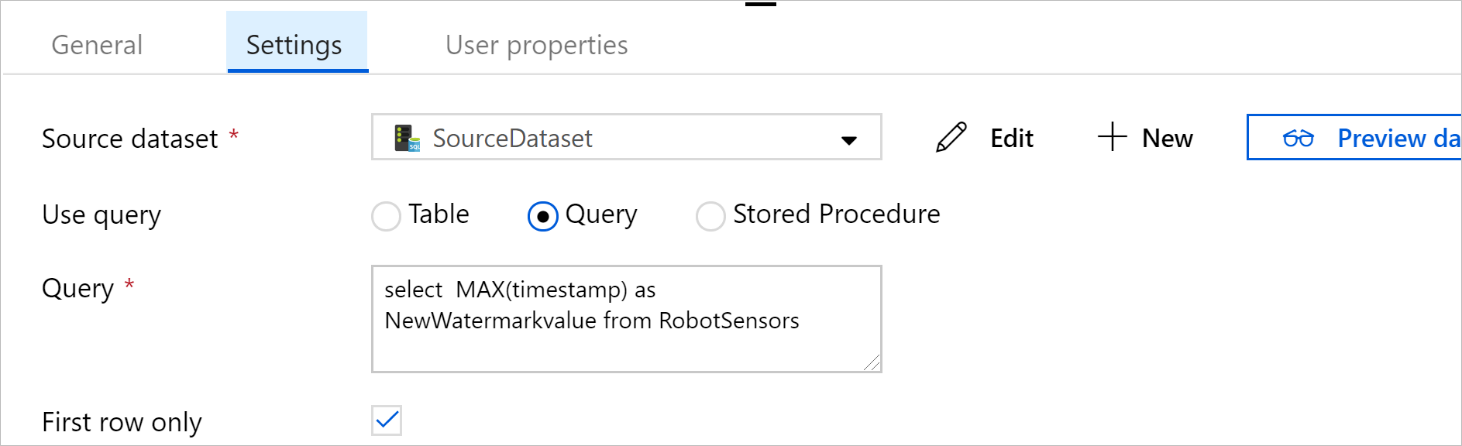
Erweitern Sie im Bereich Aktivitäten den Eintrag Move & Transform (Verschieben und transformieren), und ziehen Sie die Copy-Aktivität aus dem Bereich Aktivitäten auf die Designer-Oberfläche. Legen Sie als Namen der Aktivität IncrementalCopy fest.
Verbinden Sie beide Lookup-Aktivitäten mit der Copy-Aktivität, indem Sie die grüne Schaltfläche, die den Lookup-Aktivitäten zugeordnet ist, zur Copy-Aktivität ziehen. Lassen Sie die Maustaste los, wenn die Rahmenfarbe der Kopieraktivität blau wird.
Wählen Sie die Copy-Aktivität aus, und vergewissern Sie sich, dass die Eigenschaften für die Aktivität im Fenster Eigenschaften angezeigt werden.
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Quelle, und führen Sie die folgenden Schritte aus:
Wählen Sie im Feld Source Dataset (Quelldataset) die Option SourceDataset aus.
Wählen Sie unter Abfrage verwenden die Option Abfrage aus.
Geben Sie im Feld Abfrage die SQL-Abfrage ein. Dies ist eine Beispielabfrage:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';Wählen Sie auf der Registerkarte Senke unter Sink Dataset (Senkendataset) die Option Neu aus.
In diesem Tutorial ist der Senkendatenspeicher ein Azure Blob Storage-Datenspeicher. Wählen Sie Azure Blob Storage und anschließend im Fenster Neues Dataset die Option Weiter aus.
Wählen Sie im Fenster Format auswählen das Format Ihrer Daten und anschließend Weiter aus.
Geben Sie im Fenster Eigenschaften festlegen unter Name den Namen SinkDataset ein. Wählen Sie unter Verknüpfter Dienst die Option Neu aus. Sie erstellen nun eine Verbindung (einen verknüpften Dienst) mit Ihrer Azure Blob Storage-Instanz.
Führen Sie im Fenster New Linked Service (Azure Blob Storage) (Neuer verknüpfter Dienst (Azure Blob Storage)) die folgenden Schritte aus:
Geben Sie unter Name den Namen AzureStorageLinkedService ein.
Wählen Sie unter Speicherkontoname das Azure Storage-Konto für Ihr Azure-Abonnement aus.
Testen Sie die Verbindung, und wählen Sie Fertig stellen aus.
Vergewissern Sie sich, dass im Fenster Eigenschaften festlegen unter Verknüpfter Dienst die Option AzureStorageLinkedService ausgewählt ist. Wählen Sie Erstellen und OK aus.
Wählen Sie auf der Registerkarte Senke die Option Bearbeiten aus.
Navigieren Sie zur Registerkarte Verbindung von SinkDataset, und führen Sie die folgenden Schritte aus:
Geben Sie unter Dateipfad
asdedatasync/incrementalcopyein, wobeiasdedatasyncder Blobcontainername undincrementalcopyder Ordnername ist. Erstellen Sie den Container, wenn er noch nicht vorhanden ist, oder verwenden Sie den Namen eines bereits vorhandenen. Azure Data Factory erstellt den Ausgabeordnerincrementalcopyautomatisch, falls er nicht vorhanden ist. Sie können auch die Schaltfläche Durchsuchen für den Dateipfad verwenden, um zu einem Ordner in einem Blobcontainer zu navigieren.Wählen Sie für den Teil Datei des Felds Dateipfad die Option Dynamischen Inhalt hinzufügen [ALT+P] aus, und geben Sie dann
@CONCAT('Incremental-', pipeline().RunId, '.txt')in das Fenster ein, das geöffnet wird. Wählen Sie "Fertig stellen" aus. Der Dateiname wird mit dem Ausdruck dynamisch generiert. Jede Pipelineausführung verfügt über eine eindeutige ID. Die Copy-Aktivität nutzt die Ausführungs-ID zum Generieren des Dateinamens.
Wechseln Sie zum Pipeline-Editor, indem Sie oben die Registerkarte „Pipeline“ oder in der Strukturansicht auf der linken Seite den Namen der Pipeline auswählen.
Erweitern Sie im Bereich Aktivitäten die Option Allgemein, und ziehen Sie die Stored Procedure-Aktivität aus dem Bereich Aktivitäten auf die Oberfläche des Pipeline-Designers. Verbinden Sie die grüne Ausgabe (Erfolgreich) der Copy-Aktivität mit der Stored Procedure-Aktivität.
Wählen Sie im Pipeline-Designer die Option Aktivität „Gespeicherte Prozedur“ aus, und ändern Sie den Namen in
SPtoUpdateWatermarkActivity.Wechseln Sie zur Registerkarte SQL-Konto, und wählen Sie unter Verknüpfter Dienst die Option SQLDBEdgeLinkedService aus.
Wechseln Sie zur Registerkarte Gespeicherte Prozedur, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Name der gespeicherten Prozedur den Namen
[dbo].[usp_write_watermark]aus.Wählen Sie zum Angeben von Werten für die Parameter der gespeicherten Prozedur die Option Import parameter (Importparameter) aus, und geben Sie für die Parameter die folgenden Werte ein:
Name Typ Wert LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Wählen Sie zum Überprüfen der Pipelineeinstellungen auf der Symbolleiste die Option Überprüfen aus. Vergewissern Sie sich, dass keine Validierungsfehler vorliegen. Klicken Sie auf , um das Fenster >> (Pipelineüberprüfungsbericht) zu schließen.
Veröffentlichen Sie die Entitäten (verknüpfte Dienste, Datasets und Pipelines) im Azure Data Factory-Dienst, indem Sie die Schaltfläche Alle veröffentlichen auswählen. Warten Sie, bis eine Erfolgsmeldung für den Veröffentlichungsvorgang angezeigt wird.
Auslösen einer Pipeline nach einem Zeitplan
Wählen Sie auf der Symbolleiste für die Pipeline nacheinander Trigger hinzufügen, Neu/Bearbeiten und dann Neu aus.
Benennen Sie den Trigger mit HourlySync. Wählen Sie unter Typ die Option Zeitplan aus. Legen Sie die Wiederholung auf „1 Stunde“ fest.
Wählen Sie OK aus.
Wählen Sie Alle veröffentlichen.
Wählen Sie Trigger Now (Jetzt auslösen) aus.
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. Sie können den Status der Pipelineausführung anzeigen, die vom manuellen Trigger ausgelöst wird. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren.
## Verwandte Inhalte
- Die Azure Data Factory-Pipeline in diesem Tutorial kopiert einmal pro Stunde Daten aus einer Tabelle in der SQL Edge-Instanz an einen Speicherort in Azure Blob Storage. Informationen zu weiteren Data Factory-Verwendungsszenarien finden Sie in diesen Tutorials.