Tutorial: Konfigurieren der aktiven Georeplikation und des Failovers (Azure SQL-Datenbank)
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Dieser Artikel zeigt Ihnen, wie Sie eine aktive Georeplikation konfigurieren und ein Failover für Azure SQL-Datenbank mithilfe des Azure-Portals, der PowerShell oder der Azure CLI initiieren.
Die aktive Georeplikation wird pro Datenbank konfiguriert. Wenn Sie einen automatischen Failover für eine Gruppe von Datenbanken wünschen oder wenn Ihre Anwendung einen stabilen Verbindungsendpunkt benötigt, sollten Sie stattdessen Failovergruppen in Betracht ziehen.
Voraussetzungen
Um dieses Lernprogramm abzuschließen, benötigen Sie eine einzelne Azure SQL-Datenbank. Informationen zum Erstellen einer Einzeldatenbank mit dem Azure-Portal, der Azure CLI oder PowerShell finden Sie unter Schnellstart: Erstellen einer Einzeldatenbank – Azure SQL-Datenbank.
Sie können die Azure-Portal verwenden, um die aktive Georeplikation über Abonnements hinweg einzurichten, solange sich beide Abonnements im selben Microsoft Entra ID-Mandanten befinden.
- Um ein geo-sekundäres Replikat in einem Abonnement zu erstellen, das sich vom Abonnement des primären in einem anderen Microsoft Entra ID-Mandanten unterscheidet, verwenden Sie das geo-sekundäre Replikat über Abonnements hinweg und das T-SQL-Lernprogramm des Microsoft Entra ID-Mandanten.
- Subscription-übergreifende Georeplikationsvorgänge, einschließlich Einrichtung und Geo-Failover, werden auch über die REST-API zum Erstellen oder Aktualisieren von Datenbanken unterstützt.
Hinzufügen einer sekundären Datenbank
Mit den folgenden Schritten wird eine neue sekundäre Datenbank in einer Partnerschaft für die Georeplikation erstellt.
Zum Hinzufügen einer sekundären Datenbank müssen Sie der Besitzer oder Mitbesitzer der Subscription sein.
Die sekundäre Datenbank hat den gleichen Namen wie die primäre Datenbank und standardmäßig auch die gleiche Dienstebene und Computegröße. Die sekundäre Datenbank kann eine Einzel- oder Pooldatenbank sein. Weitere Informationen finden Sie unter DTU-basierte Einkaufsmodellübersicht und vCore-basiertes Einkaufsmodell. Nachdem die sekundäre Datenbank erstellt und das Seeding ausgeführt wurde, beginnt die Replikation der Daten von der primären Datenbank in die neue sekundäre Datenbank.
Wenn Ihr sekundäres Replikat nur für notfallwiederherstellung (Dr) verwendet wird und keine Lese- oder Schreibworkloads enthält, können Sie die Lizenzierungskosten sparen, indem Sie die Datenbank für den Standbymodus entwerfen, wenn Sie eine neue aktive Georeplikationsbeziehung konfigurieren. Weitere Informationen finden Sie unter lizenzfreiem Standby-Replikat.
Hinweis
Wenn die Partnerdatenbank bereits vorhanden ist (z. B. aufgrund der Beendigung einer vorherigen Georeplikationsbeziehung), tritt für den Befehl ein Fehler auf.
Navigieren Sie im Azure-Portal zu der Datenbank, die Sie für die Georeplikation einrichten möchten.
Wählen Sie auf der Seite SQL-Datenbank Ihre Datenbank aus, scrollen Sie zu Datenverwaltung, wählen Sie Replikate und dann Replikat erstellen aus.
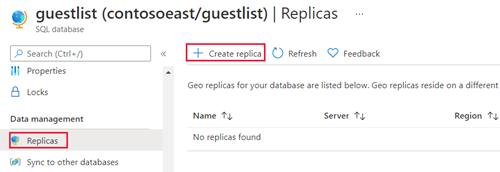
Wählen Sie Ihre geo-sekundäre Datenbank Abonnement und Ihre Ressourcengruppe aus.
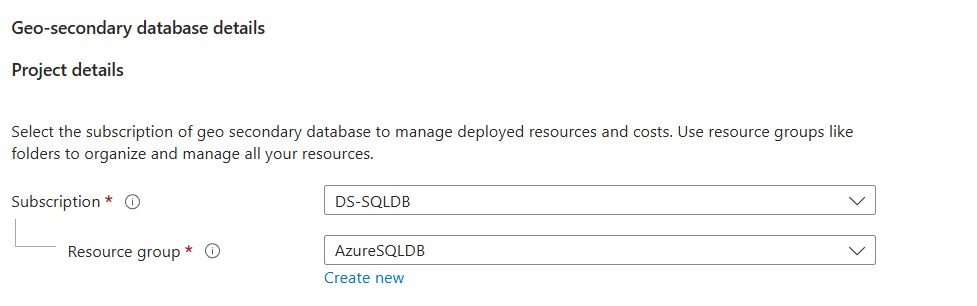
Wählen oder erstellen Sie den Server für die sekundäre Datenbank und konfigurieren Sie bei Bedarf die Compute und Speicher-Optionen. Sie können eine beliebige Region für Ihren sekundären Server auswählen, wir empfehlen jedoch das Regionspaar.
Optional können Sie einem Pool für elastische Datenbanken eine sekundäre Datenbank hinzufügen. Um die sekundäre Datenbank in einem Pool zu erstellen, wählen Sie Ja neben der Option Möchten Sie einen Pool für elastische SQL-Datenbanken verwenden? und dann einen Pool auf dem Zielserver aus. Ein Pool muss bereits auf dem Zielserver vorhanden sein. Dieser Workflow erstellt keinen Pool.
Überprüfen Sie die Informationen auf der Registerkarte Überprüfen und erstellen, und klicken Sie dann auf Erstellen.
Die sekundäre Datenbank wird erstellt und der Bereitstellungsprozess beginnt.
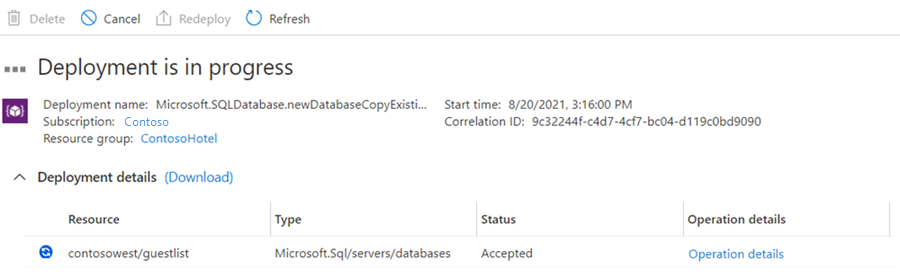
Nach Abschluss der Bereitstellung wird der Status für die sekundäre Datenbank angezeigt.
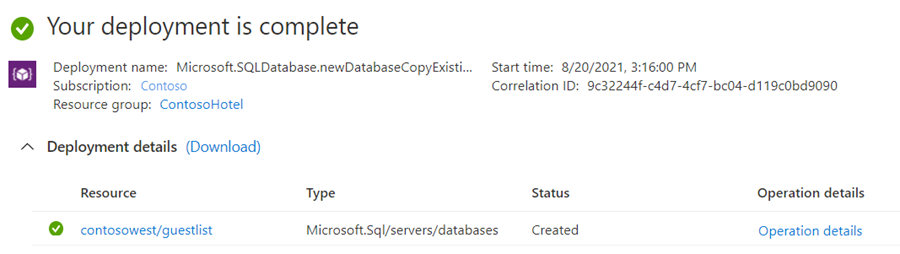
Kehren Sie zur Seite der primären Datenbank zurück, und wählen Sie Replikate aus. Ihre sekundäre Datenbank ist unter Georeplikate aufgeführt.
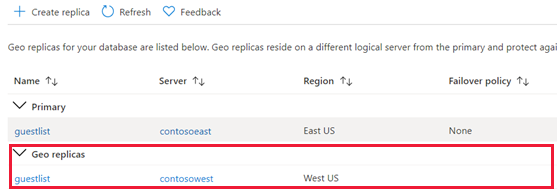



Initiieren eines Failovers
Für die sekundäre Datenbank kann ein Wechsel durchgeführt werden, bei dem sie zur primären Datenbank wird.
Navigieren Sie im Azure-Portal zur primären Datenbank in der Georeplikationspartnerschaft.
Scrollen Sie zu Datenverwaltung, und wählen Sie dann Replikate aus.
Wählen Sie in der Liste Georeplikate die Datenbank aus, die die neue primäre Datenbank werden soll. Wählen Sie dann die Auslassungspunkte und anschließend Erzwungenes Failover aus.
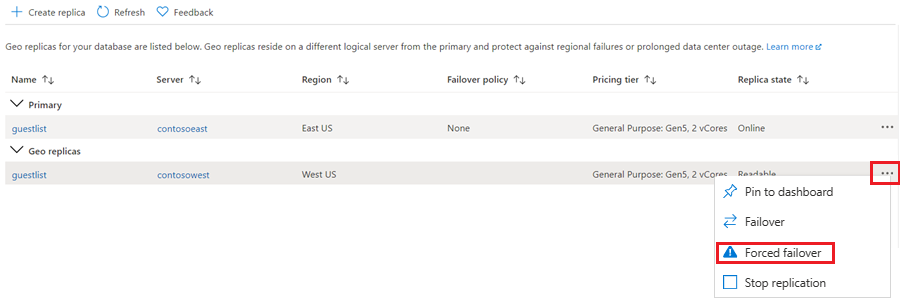
Wählen Sie Ja aus, um das Failover zu beginnen.

Durch den Befehl wird die sekundäre Datenbank sofort in die primäre Rolle geändert. Dieser Vorgang sollte normalerweise innerhalb von 30 Sekunden oder weniger abgeschlossen sein.
Beide Datenbanken sind für bis zu 25 Sekunden nicht verfügbar, während die Rollen gewechselt werden. Wenn die primäre Datenbank über mehrere sekundäre Datenbanken verfügt, werden die anderen sekundären Datenbanken durch den Befehl automatisch neu konfiguriert, sodass sie eine Verbindung mit der neuen primären Datenbank herstellen. Unter normalen Umständen dauert der gesamte Vorgang nicht länger als 1 Minute.
Entfernen einer sekundären Datenbank
Dieser Vorgang beendet die Replikation zur sekundären Datenbank dauerhaft und ändert die Rolle der sekundären Datenbank in eine normale Datenbank mit Lese-/Schreibzugriff. Wenn die Verbindung mit der sekundären Datenbank unterbrochen wird, ist der Befehl zwar erfolgreich, aber die sekundäre Datenbank wird erst mit Lese-/ Schreibzugriff versehen, nachdem die Verbindung wiederhergestellt wurde.
- Navigieren Sie im Azure-Portal zur primären Datenbank in der Georeplikationspartnerschaft.
- Wählen Sie Replikate aus.
- Wählen Sie in der Liste Georeplikate die Datenbank aus, die Sie aus der Georeplikationspartnerschaft entfernen möchten, klicken Sie auf die Auslassungspunkte und dann auf Replikation beenden.
- Ein Bestätigungsfenster wird geöffnet. Wählen Sie zum Entfernen der Datenbank aus der Georeplikationspartnerschaft Ja aus. (Legen Sie sie auf eine Lese-/Schreibdatenbank fest, die nicht Teil einer Replikation ist.)
Subscriptionübergreifende Georeplikation
- Um ein geo-sekundäres Replikat in einem anderen Abonnement als dem Abonnement des primären im selben Microsoft Entra-Mandanten zu erstellen, können Sie das Azure-Portal oder die Schritte in diesem Abschnitt verwenden.
- Um ein geo-sekundäres Replikat in einem Abonnement zu erstellen, das sich vom Abonnement des primären in einem anderen Microsoft Entra ID-Mandanten unterscheidet, müssen Sie die SQL-Authentifizierung und T-SQL mit den Schritten in diesem Abschnitt verwenden. Die Microsoft Entra-Authentifizierung für Azure SQL für die geoübergreifende Georeplikation wird nicht unterstützt, wenn sich ein logischer Server in einem anderen Azure-Mandanten befindet
Fügen Sie die IP-Adresse des Client-Rechners, der die T-SQL-Befehle in diesem Beispiel ausführt, zu den Server-Firewalls von beiden primären und sekundären Servern hinzu. Sie können diese IP-Adresse bestätigen, indem Sie die folgende Abfrage ausführen, während Sie von demselben Client-Rechner aus mit dem Primärserver verbunden sind.
SELECT client_net_address FROM sys.dm_exec_connections WHERE session_id = @@SPID;Weitere Informationen finden Sie unter IP-Firewallregeln für Azure SQL-Datenbank und Azure Synapse.
Erstellen Sie in der
master-Datenbank auf dem primären Server eine Anmeldung mit SQL-Authentifizierung für die Einrichtung der aktiven Georeplikation. Passen Sie den Anmeldenamen und das Passwort nach Bedarf an.CREATE LOGIN geodrsetup WITH PASSWORD = 'ComplexPassword01';Erstellen Sie in derselben Datenbank einen Benutzer für die Anmeldung, und fügen Sie ihn der Rolle
dbmanagerhinzu:CREATE USER geodrsetup FOR LOGIN geodrsetup; ALTER ROLE dbmanager ADD MEMBER geodrsetup;Notieren Sie sich den SID-Wert der neuen Anmeldung. Ermitteln Sie den SID-Wert mit der folgenden Abfrage.
SELECT sid FROM sys.sql_logins WHERE name = 'geodrsetup';Verbinden Sie sich mit der primären Datenbank (nicht mit der
master-Datenbank), und erstellen Sie einen Benutzer für dieselbe Anmeldung.CREATE USER geodrsetup FOR LOGIN geodrsetup;Fügen Sie in derselben Datenbank den Benutzer zur Rolle
db_ownerhinzu.ALTER ROLE db_owner ADD MEMBER geodrsetup;Erstellen Sie in der
master-Datenbank auf dem sekundären Server dieselbe Anmeldung wie auf dem primären Server, mit demselben Namen und Kennwort und derselben SID. Ersetzen Sie den hexadezimalen SID-Wert im nachfolgenden Beispielbefehl durch den in Schritt 4 erhaltenen Wert.CREATE LOGIN geodrsetup WITH PASSWORD = 'ComplexPassword01', SID = 0x010600000000006400000000000000001C98F52B95D9C84BBBA8578FACE37C3E;Erstellen Sie in derselben Datenbank einen Benutzer für die Anmeldung, und fügen Sie ihn der Rolle
dbmanagerhinzu.CREATE USER geodrsetup FOR LOGIN geodrsetup; ALTER ROLE dbmanager ADD MEMBER geodrsetup;Stellen Sie eine Verbindung mit der
master-Datenbank auf dem primären Server unter Verwendung der neuen Anmeldunggeodrsetupher, und initiieren Sie die geosekundäre Erstellung auf dem sekundären Server. Passen Sie den Datenbanknamen und den Namen des Sekundärservers nach Bedarf an. Nachdem der Befehl ausgeführt wurde, können Sie die geosekundäre Erstellung überwachen, indem Sie die Sicht sys.dm_geo_replication_link_status in der primären Datenbank und die Sicht sys.dm_operation_status in dermaster-Datenbank auf dem primären Server abfragen. Die für die Erstellung einer Geo-Sekundärdatenbank benötigte Zeit hängt von der Größe der Primärdatenbank ab.alter database [dbrep] add secondary on server [servername];Nachdem die Geo-Sekundärstation erfolgreich erstellt wurde, können die Benutzer, Anmeldungen und Firewall-Regeln, die mit diesem Verfahren erstellt wurden, entfernt werden.