Aktive Georeplikation
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Die aktive Georeplikation ist eine Funktion, mit der Sie eine kontinuierlich synchronisierte, lesbare sekundäre Datenbank für eine primäre Datenbank erstellen können. Die lesbare sekundäre Datenbank kann sich in derselben Azure-Region befinden wie die primäre, oder, was häufiger der Fall ist, in einer anderen Region. Diese Art von lesbaren sekundären Datenbanken wird auch als geo-sekundäre Datenbank oder Geo-Replikat bezeichnet.
Die aktive Georeplikation wird pro Datenbank konfiguriert und unterstützt nur manuelles Failover. Wenn Sie einen automatischen Failover für eine Gruppe von Datenbanken wünschen oder wenn Ihre Anwendung einen stabilen Verbindungsendpunkt benötigt, sollten Sie stattdessen Failovergruppen in Betracht ziehen.
Sie können SQL-Datenbankmit aktiver Georeplikation migrieren verwenden.
Überblick
Die aktive Georeplikation ist als Geschäftskontinuitätslösung konzipiert. Mit der aktiven Georeplikation können Sie im Falle einer regionalen Katastrophe oder eines großflächigen Ausfalls eine schnelle Wiederherstellung einzelner Datenbanken durchführen. Sobald die Geo-Replikation eingerichtet ist, können Sie einen Geo-Failover zu einer Geo-Sekundärstelle in einer anderen Azure-Region initiieren. Der Geo-Failover wird programmatisch durch die Anwendung oder manuell durch den Benutzer ausgelöst.
Das folgende Diagramm zeigt eine typische Konfiguration einer georedundanten Cloudanwendung mit aktiver Georeplikation.
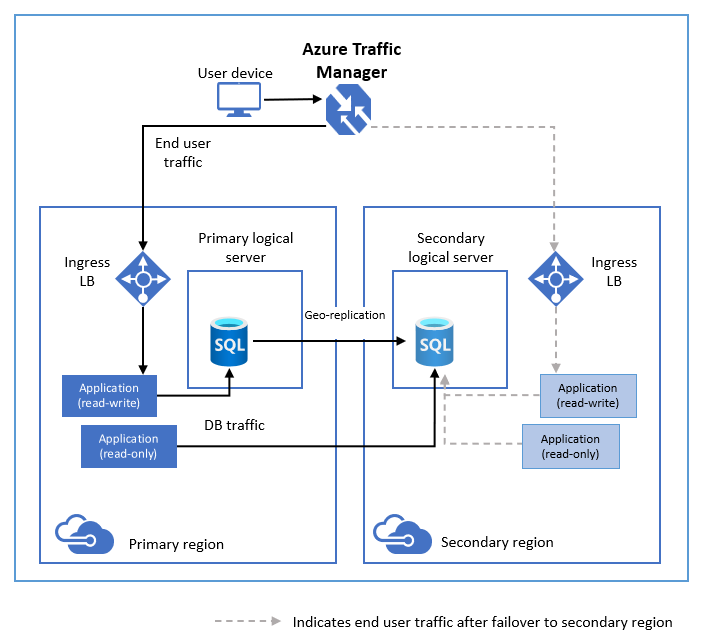
Wenn Ihre primäre Datenbank aus irgendeinem Grund ausfällt, können Sie einen Geo-Failover auf eine Ihrer sekundären Datenbanken veranlassen. Wenn ein Sekundärteilnehmer zum Primärteilnehmer befördert wird, werden alle anderen Sekundärteilnehmer automatisch mit dem neuen Primärteilnehmer verbunden.
Sie können die Georeplikation verwalten und einen Geo-Failover wie folgt initiieren:
- Das Azure-Portal
- PowerShell: Einzelne Datenbank
- PowerShell: Pool für elastische Datenbanken
- Transact-SQL: Einzelne Datenbank oder Pool für elastische Datenbanken
- REST-API: Einzelne Datenbank
Die aktive Georeplikation nutzt die Technologie der Allzeitverfügbarkeitsgruppe, um das auf dem primären Replikat erzeugte Transaktionsprotokoll asynchron auf alle Georeplikate zu replizieren. Auch wenn eine sekundäre Datenbank zu einem bestimmten Zeitpunkt etwas hinter der primären Datenbank zurückbleiben kann, ist die Konsistenz der Daten in einer sekundären Datenbank garantiert. Mit anderen Worten: Änderungen, die durch nicht bestätigte Transaktionen vorgenommen werden, sind nicht sichtbar.
Hinweis
Bei der aktiven Georeplikation werden Änderungen durch Streaming des Datenbanktransaktionsprotokolls vom primären Replikat auf sekundäre Replikate repliziert. Sie hat nichts mit der transaktionalen Replikation zu tun, die Änderungen durch die Ausführung von DML-Befehlen (INSERT, UPDATE, DELETE) auf Abonnenten repliziert.
Georeplikation bietet regionale Redundanz. Regionale Redundanz ermöglicht es Anwendungen, sich schnell von einem dauerhaften Verlust einer ganzen Azure-Region oder von Teilen einer Region zu erholen, der durch Naturkatastrophen, katastrophale menschliche Fehler oder bösartige Handlungen verursacht wurde. Geo-Replikations-RPO finden Sie in Übersicht über Business Continuity.
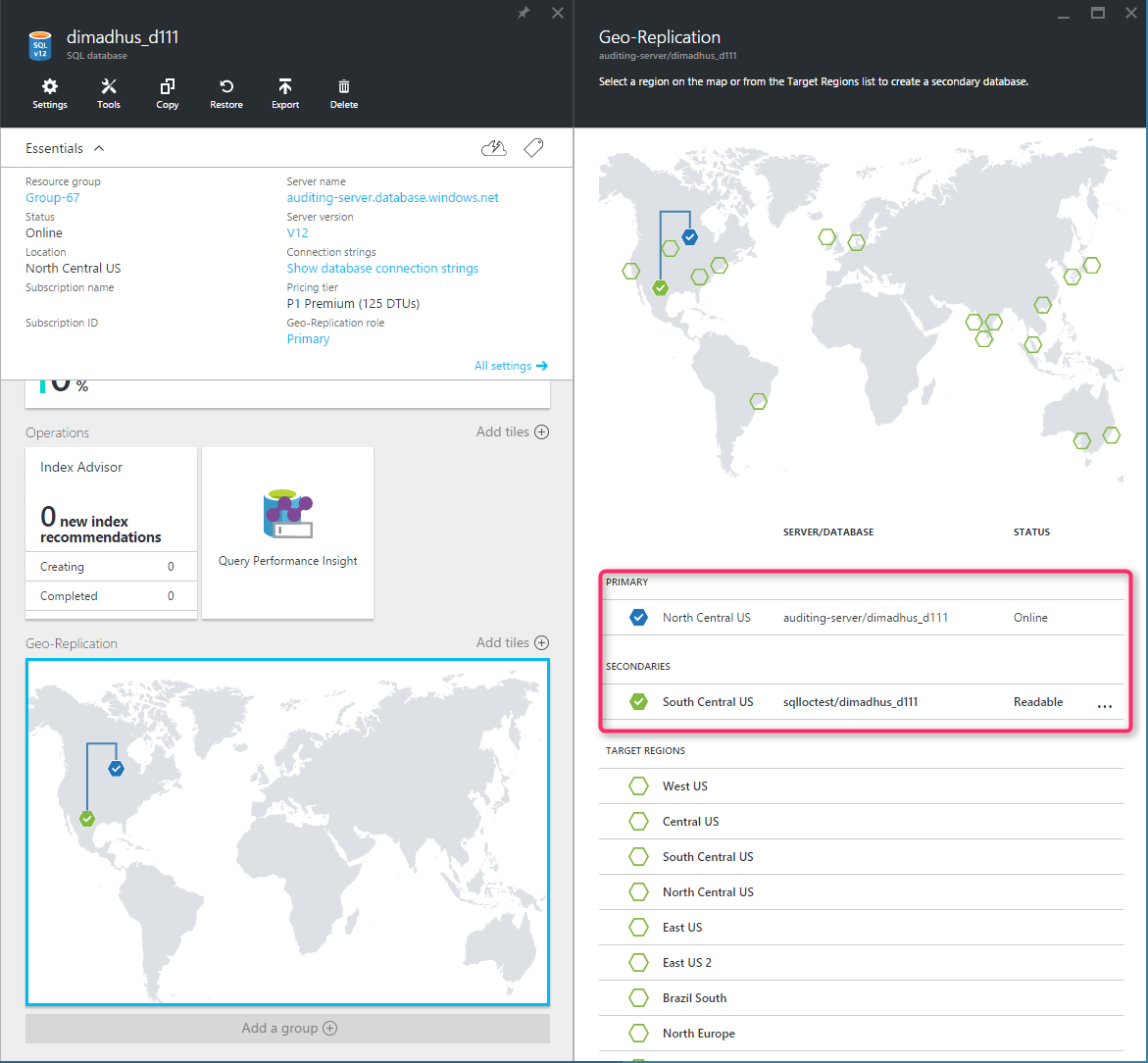
Die folgende Abbildung zeigt ein Beispiel für eine aktive Georeplikation mit einem primären Standort in der Region North Central US und einem sekundären Standort in der Region South Central US.
Neben der Notfallwiederherstellung kann die aktive Georeplikation in den folgenden Szenarien eingesetzt werden:
- Datenbankmigration: Sie können die aktive Georeplikation verwenden, um eine Datenbank mit minimaler Ausfallzeit von einem Server auf einen anderen zu migrieren.
- Anwendungsupgrades: Sie können bei Anwendungsupgrades eine zusätzliche sekundäre Datenbank als Failbackkopie erstellen.
Um eine vollständige Geschäftskontinuität zu erreichen, ist das Hinzufügen einer regionalen Datenbankredundanz nur ein Teil der Lösung. Für die komplette Wiederherstellung einer Anwendung bzw. eines Diensts nach einem schwerwiegenden Fehler ist das Wiederherstellen aller Komponenten erforderlich, aus denen sich der Dienst und alle abhängigen Dienste zusammensetzen. Beispiele dieser Komponenten sind die Clientsoftware (z. B. ein Browser mit benutzerdefiniertem JavaScript), Web-Front-Ends, Speicher und DNS. Es ist wichtig, dass alle Komponenten hinsichtlich derselben Fehler gegen Ausfälle geschützt und innerhalb des RTO (Recovery Time Objective) der Anwendung wieder verfügbar sind. Daher müssen Sie alle abhängigen Dienste bestimmen und mit dem Leistungsumfang und den Funktionen vertraut sein, die sie bieten. Dann müssen Sie entsprechende Maßnahmen ergreifen, um sicherzustellen, dass Ihr Dienst während des Failovers der Dienste funktioniert, von denen er abhängig ist. Weitere Informationen zum Entwerfen von Lösungen für die Notfallwiederherstellung finden Sie unter Entwerfen von Cloudlösungen für die Notfallwiederherstellung mithilfe der aktiven Georeplikation.
Aktive Georeplikation – Terminologie und Funktionen
Automatische asynchrone Replikation
Sie können eine Geo-Sekundärdatenbank nur für eine bestehende Datenbank erstellen. Die geo-sekundäre Datenbank kann auf einem beliebigen logischen Server erstellt werden, der nicht der Server mit der primären Datenbank ist. Nach der Erstellung wird die geo-sekundäre Replik mit den Daten der primären Datenbank befüllt. Dieser Prozess wird als Seeding bezeichnet. Nachdem eine Geo-Sekundärdatenbank erstellt und geimpft wurde, werden Aktualisierungen der primären Datenbank automatisch und asynchron auf die Geo-Sekundärdatenbank repliziert. Asynchrone Replikation bedeutet, dass die Transaktionen in der primären Datenbank bestätigt werden, bevor sie repliziert werden.
Lesbare geo-sekundäre Replikate
Eine Anwendung kann auf ein geo-sekundäres Replikat zugreifen, um schreibgeschützte Abfragen mit denselben oder anderen Sicherheitsprinzipien auszuführen, die für den Zugriff auf die primäre Datenbank verwendet werden. Weitere Informationen finden Sie unter Verwenden Sie schreibgeschützte Replikate, um schreibgeschützte Abfragen zu entlasten.
Wichtig
Mit der Georeplikation können Sie sekundäre Replikate in derselben Region wie das primäre erstellen. Sie können diese Secondaries verwenden, um Read-Scale-Out-Szenarien in derselben Region zu erfüllen. Ein sekundäres Replikat in derselben Region bietet jedoch keine zusätzliche Ausfallsicherheit bei katastrophalen Fehlern oder großflächigen Ausfällen und ist daher kein geeignetes Failover-Ziel für Disaster Recovery-Zwecke. Es garantiert auch keine Isolierung der Verfügbarkeitszonen. Verwenden Sie für die Isolierung von Verfügbarkeitszonen die Service-Tiers "Business Critical" oder "Premium" Zonenredundanzkonfiguration oder das Service-Tier "General Purpose" Zonenredundanzkonfiguration.
Failover (kein Datenverlust)
Failover tauscht die Rollen der primären und der geo-sekundären Datenbank nach Abschluss der vollständigen Datensynchronisation, so dass kein Datenverlust auftritt. Die Dauer des Failover hängt von der Größe des Transaktionsprotokolls auf dem primären System ab, das mit dem geo-sekundären System synchronisiert werden muss. Failover ist für die folgenden Szenarien vorgesehen:
- Führen Sie DR-Drills in der Produktion durch, wenn der Datenverlust nicht akzeptabel ist
- Verlegen Sie die Datenbank in eine andere Region
- Rückführung der Datenbank in die primäre Region nach Behebung des Ausfalls (sog. Failback).
Erzwungenes Failover (potenzieller Datenverlust)
Bei einem ungeplanten oder erzwungenen Geo-Failover wechselt der Geo-Sekundärserver sofort in die Primärrolle, ohne dass eine Synchronisierung mit dem Primärserver erfolgt. Alle Transaktionen, die auf dem primären System übertragen, aber noch nicht auf dem sekundären System repliziert wurden, gehen verloren. Dieser Vorgang ist als Wiederherstellungsmethode bei Ausfällen gedacht, wenn die Primärdatenbank nicht erreichbar ist, die Verfügbarkeit der Datenbank aber schnell wiederhergestellt werden muss. Wenn die ursprüngliche primäre Datenbank wieder online ist, wird sie automatisch wieder verbunden und mit den Daten der aktuellen primären Datenbank neu bestückt. So wird sie zu einer neuen geo-sekundären Datenbank.
Wichtig
Nach einem geplanten oder ungeplanten Geo-Failover ändert sich der Verbindungsendpunkt für den neuen Primärserver, da sich dieser nun auf einem anderen logischen Server befindet.
Mehrere lesbare Geo-Sekundärdaten
Für eine Primärseite können bis zu vier Geosekundärseiten erstellt werden. Wenn nur ein Sekundärspeicher vorhanden ist und dieser ausfällt, ist die Anwendung einem höheren Risiko ausgesetzt, bis ein neuer Sekundärspeicher erstellt wird. Wenn mehrere Sekundärsysteme vorhanden sind, bleibt die Anwendung auch dann geschützt, wenn eines der Sekundärsysteme ausfällt. Zusätzliche Secondaries können auch zur Skalierung von Nur-Lese-Workloads verwendet werden.
Tipp
Wenn Sie die aktive Georeplikation zum Aufbau einer global verteilten Anwendung verwenden und einen Nur-Lese-Zugriff auf Daten in mehr als vier Regionen benötigen, können Sie einen Sekundärteil eines Sekundärteils erstellen (ein Prozess, der als Verkettung bekannt ist), um zusätzliche Georeplikate zu erstellen. Die Replikationsverzögerung bei verketteten Geo-Replikaten könnte höher sein als bei Geo-Replikaten, die direkt mit dem Primärsystem verbunden sind. Das Einrichten von verketteten Georeplikations-Topologien wird nur programmatisch und nicht über das Azure-Portal unterstützt.
Georeplikation von Datenbanken in einem Pool für elastische Datenbanken
Jede Geosekundärdatenbank kann eine einzelne Datenbank oder eine Datenbank in einem elastischen Pool sein. Die Auswahl des elastischen Pools für jede geo-sekundäre Datenbank ist separat und hängt nicht von der Konfiguration eines anderen Replikats in der Topologie ab (weder primär noch sekundär). Jeder elastische Pool ist in einem einzigen logischen Server enthalten. Da die Namen der Datenbanken auf einem logischen Server eindeutig sein müssen, können sich niemals mehrere Geo-Sekundärdatenbanken desselben Primärservers einen elastischen Pool teilen.
Benutzergesteuertes Geo-Failover und Failback
Ein Geo-Sekundärdienst, der seine erste Aussaat abgeschlossen hat, kann jederzeit von der Anwendung oder dem Benutzer ausdrücklich in die primäre Rolle umgeschaltet werden (failed over). Während eines Ausfalls, bei dem auf das Primäre nicht zugegriffen werden kann, kann nur ein erzwungenes Failover verwendet werden, wodurch sofort eine geo-sekundäre als neue Primäre gefördert wird. Wenn der Ausfall behoben ist, macht das System die wiederhergestellte Primärdatenquelle automatisch zu einer Geo-Sekundärdatenquelle und bringt sie mit der neuen Primärdatenquelle auf den neuesten Stand. Aufgrund des asynchronen Charakters der Georeplikation könnten aktuelle Transaktionen bei ungeplanten Geo-Failovern verloren gehen, wenn die Primärseite ausfällt, bevor diese Transaktionen auf eine Geo-Sekundärseite repliziert werden. Fällt eine Primärdatei mit mehreren Geo-Sekundärdateien aus, konfiguriert das System automatisch die Replikationsbeziehungen neu und verbindet die verbleibenden Geo-Sekundärdateien mit der neuen Primärdatei, ohne dass ein Benutzereingriff erforderlich ist. Nachdem der Ausfall, der den Geo-Failover verursacht hat, entschärft wurde, könnte es wünschenswert sein, die Primäranlage in ihre ursprüngliche Region zurückzubringen. Führen Sie dazu ein manuelles Failover durch.
Standby-Replikat
Wenn Ihr sekundäres Replikat nur für Notfallwiederherstellung (DR) verwendet wird und keine Lese- oder Schreib-Workloads enthält, können Sie das Replikat als Standby festlegen, um Lizenzierungskosten zu sparen.
Vorbereitungen für Geo-Failover
Um sicherzustellen, dass Ihre Anwendung nach einem Geo-Failover sofort auf den neuen primären Server zugreifen kann, müssen Sie sicherstellen, dass die Authentifizierung und der Netzwerkzugriff für Ihren sekundären Server ordnungsgemäß konfiguriert sind. Weitere Informationen finden Sie unter Verwalten der Sicherheit der Azure SQL-Datenbank nach der Notfallwiederherstellung. Stellen Sie außerdem sicher, dass die Sicherungsaufbewahrungsrichtlinie der sekundären Datenbank mit der primären Datenbank übereinstimmt. Diese Einstellung ist nicht Teil der Datenbank und wird nicht von der Primärdatenbank repliziert. Standardmäßig ist die Geo-Sekundärdatei mit einer PITR-Aufbewahrungsfrist von sieben Tagen konfiguriert. Weitere Informationen finden Sie unter finden Sie unter Übersicht: Automatisierte SQL-Datenbanksicherungen.
Wichtig
Wenn Ihre Datenbank Mitglied einer Failovergruppe ist, können Sie das Failover nicht mit dem Befehl für ein Failover mit Georeplikation initiieren. Verwenden Sie den Failoverbefehl für die Gruppe. Wenn Sie ein Failover für eine einzelne Datenbank durchführen müssen, müssen Sie sie zuerst aus der Failovergruppe entfernen. Weitere Informationen finden Sie unter Failovergruppen.
Geo-sekundär konfigurieren
Sowohl die Primär- als auch die Geosekundärdienste müssen dieselbe Dienstebene haben. Es wird außerdem dringend empfohlen, die sekundäre Einheit für die Georeplikation mit der gleichen Sicherungspeicherredundanz und Computegröße (bereitgestellt oder serverlos) (DTUs oder vCores) zu konfigurieren wie die primäre Einheit. Wenn das primäre System eine hohe Schreiblast aufweist, könnte ein sekundäres System mit einer geringeren Rechenleistung möglicherweise nicht mithalten. Dies führt zu einer Verzögerung der Replikation auf der Geo-Sekundärstation und könnte schließlich zur Nichtverfügbarkeit der Geo-Sekundärstation führen. Um diese Risiken abzuschwächen, wird bei der aktiven Georeplikation die Transaktionsprotokollierungsrate des primären Systems bei Bedarf reduziert (gedrosselt), damit die sekundären Systeme aufholen können.
Eine weitere Folge einer unausgewogenen Geo-Sekundärkonfiguration ist, dass die Anwendungsleistung nach einem Failover aufgrund der unzureichenden Rechenkapazität des neuen Primärrechners leiden kann. In diesem Fall muss die Datenbank aufgestockt werden, um über ausreichende Ressourcen zu verfügen, was viel Zeit in Anspruch nehmen könnte und eine hochverfügbare Ausfallsicherung am Ende des Aufstockungsprozesses erfordert, was zu einer Unterbrechung der Anwendungsarbeitslasten führen könnte.
Wenn Sie sich dafür entscheiden, das Geo-Sekundärsystem mit einer anderen Konfiguration zu erstellen, sollten Sie die Protokoll-IO-Rate auf dem Primärsystem im Laufe der Zeit überwachen. So können Sie die minimale Rechengröße der Geo-Sekundärstation abschätzen, die erforderlich ist, um die Replikationslast aufrechtzuerhalten. Wenn Ihre primäre Datenbank beispielsweise P6 (1000 DTU) ist und ihr Log IO zu 50 % aufrechterhalten wird, muss die geo-sekundäre Datenbank mindestens P4 (500 DTU) sein. Verwenden Sie zum Abrufen von Protokoll-E/A-Verlaufsdaten die Sicht sys.resource_stats. Um aktuelle IO-Protokolldaten mit höherer Granularität abzurufen, die kurzfristige Spitzen besser widerspiegeln, verwenden Sie die Ansicht sys.dm_db_resource_stats.
Tipp
Die IO-Drosselung des Transaktionsprotokolls auf der primären Ebene aufgrund einer geringeren Rechenleistung auf einer geo-sekundären Ebene wird mit dem Wartentyp HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO gemeldet, der in den Datenbankansichten sys.dm_exec_requests und sys.dm_os_wait_stats sichtbar ist.
Die IO des Transaktionsprotokolls auf der Primärseite könnte aus Gründen gedrosselt werden, die nicht mit der geringeren Rechenleistung auf einer geo-sekundären Seite zusammenhängen. Diese Art der Drosselung könnte selbst dann auftreten, wenn die geo-sekundäre Stelle die gleiche oder eine höhere Rechenleistung hat als die primäre Stelle. Einzelheiten, einschließlich der Wartetypen für verschiedene Arten der Protokoll-IO-Drosselung, finden Sie unter Transaktionsprotokollratensteuerung.
Standardmäßig ist die Redundanz des Sicherungsspeichers für die geo-sekundäre Datenbank dieselbe wie für die primäre Datenbank. Sie können eine Geo-Sekundärdatei mit einer anderen Backup-Speicherredundanz konfigurieren. Sicherungen werden stets in der primären Datenbank erstellt. Wenn der Sekundärspeicher mit einer anderen Backup-Speicherredundanz konfiguriert ist, werden nach einem Geo-Failover, wenn der Geo-Sekundärspeicher zum Primärspeicher aufsteigt, neue Backups gespeichert und entsprechend der auf dem neuen Primärspeicher (vorheriger Sekundärspeicher) gewählten Speicherart (RA-GRS, ZRS, LRS) abgerechnet.
Kosten sparen mit dem Standby-Replikat
Wenn Ihr sekundäres Replikat nur für Notfallwiederherstellung (DR) verwendet wird und keine Lese- oder Schreib-Workloads enthält, können Sie Lizenzkosten sparen, indem Sie die Datenbank bei der Konfiguration einer neuen aktiven Geo-Replikationsbeziehung als Standby festlegen.
Weitere Informationen finden Sie unter Lizenzfreies Standby-Replikat.
Subscriptionübergreifende Georeplikation
Verwenden Sie Transact-SQL (T-SQL), um eine Geo-Sekundärdatei in einem Subscription zu erstellen, das sich von der Subscription der Primärdatei unterscheidet (unabhängig davon, ob es sich um denselben Mandanten von Microsoft Entra ID (früher Azure Active Directory) handelt oder nicht). Für weitere Informationen siehe Konfigurieren der aktiven Georeplikation.
Anmeldeinformationen und Firewall-Regeln auf dem neuesten Stand halten
Wenn Sie für die Verbindung zur Datenbank einen öffentlichen Netzwerkzugang verwenden, empfehlen wir für georeplizierte Datenbanken IP-Firewall-Regeln auf Datenbankebene zu verwenden. Diese Regeln werden mit der Datenbank repliziert, wodurch sichergestellt wird, dass alle Geo-Sekundärstellen dieselben IP-Firewall-Regeln haben wie die Primärstelle. Mit diesem Ansatz entfällt für die Kunden die Notwendigkeit, Firewall-Regeln auf den Servern, die die primären und sekundären Datenbanken hosten, manuell zu konfigurieren und zu pflegen. In ähnlicher Weise wird durch die Verwendung von Datenbankbenutzern mit für den Datenzugriff sichergestellt, dass sowohl die primäre als auch die sekundäre Datenbank immer über die gleichen Authentifizierungsdaten verfügen. Auf diese Weise kommt es nach einem Geo-Failover nicht zu Unterbrechungen aufgrund von nicht übereinstimmenden Anmeldeinformationen für die Authentifizierung. Wenn Sie mit Anmeldungen und Benutzern (nicht mit eigenständigen Benutzern) arbeiten, müssen Sie zusätzliche Schritte durchführen, um sicherzustellen, dass die gleichen Anmeldenamen in Ihrer sekundären Datenbank vorhanden sind. Konfigurationsdetails finden Sie unter Konfigurieren von Anmeldungen und Benutzern.
Skalieren der primären Datenbank
Sie können die primäre Datenbank auf eine andere Rechengröße vergrößern oder verkleinern (innerhalb derselben Dienstebene), ohne die Verbindung zu den sekundären Datenbanken zu unterbrechen. Bei der Skalierung wird empfohlen, zuerst die geo-sekundäre und dann die primäre Ebene zu vergrößern. Bei der Verkleinerung kehren Sie die Reihenfolge um: Verkleinern Sie zuerst die Primärseite und dann die Sekundärseite.
Hinweis
Wenn Sie eine geo-sekundäre Gruppe als Teil der Failover-Gruppenkonfiguration erstellt haben, ist es nicht empfehlenswert, diese zu verkleinern. Damit soll sichergestellt werden, dass Ihre Datenebene über genügend Kapazität verfügt, um die reguläre Arbeitslast nach einem Geo-Failover zu verarbeiten.
Wichtig
Die primäre Datenbank in einer Failover-Gruppe kann nur dann auf eine höhere Serviceebene (Edition) skaliert werden, wenn die sekundäre Datenbank zuerst auf die höhere Ebene skaliert wird. Wenn Sie z. B. den primären Bereich von "General Purpose" auf "Business Critical" skalieren wollen, müssen Sie zuerst den geo-sekundären Bereich auf "Business Critical" skalieren. Wenn Sie versuchen, die Primär- oder Geo-Sekundärdaten in einer Weise zu skalieren, die gegen diese Regel verstößt, erhalten Sie die folgende Fehlermeldung:
The source database 'Primaryserver.DBName' cannot have higher edition than the target database 'Secondaryserver.DBName'. Upgrade the edition on the target before upgrading the source.
Verhinderung des Verlusts kritischer Daten
Aufgrund der hohen Latenzzeit von WANs verwendet die Georeplikation einen asynchronen Replikationsmechanismus. Bei der asynchronen Replikation ist die Möglichkeit eines Datenverlusts unvermeidbar, wenn die primäre Datenbank ausfällt. Zum Schutz kritischer Transaktionen vor Datenverlust, kann ein Anwendungsentwickler die gespeicherte Prozedur sp_wait_for_database_copy_sync unmittelbar nach dem Commit der Transaktion aufrufen. Der Aufruf von sp_wait_for_database_copy_sync blockiert den aufrufenden Thread, bis die letzte committete Transaktion übertragen und im Transaktionsprotokoll der sekundären Datenbank gehärtet wurde. Er wartet jedoch nicht darauf, dass die übertragenen Transaktionen in der sekundären Datenbank wiedergegeben (wiederholt) werden. sp_wait_for_database_copy_sync ist auf eine bestimmte Georeplikationslink beschränkt. Jeder Benutzer mit den Rechten zum Herstellen der Verbindung mit der primären Datenbank kann diese Prozedur aufrufen.
Hinweis
sp_wait_for_database_copy_sync verhindert Datenverluste nach einem Geofailover für bestimmte Transaktionen, garantiert aber keine vollständige Synchronisierung für Lesezugriffe. Die durch einen sp_wait_for_database_copy_sync-Prozeduraufruf verursachte Verzögerung kann beträchtlich sein und hängt von der Größe des noch nicht übertragenen Transaktionsprotokolls auf der Primärseite zum Zeitpunkt des Aufrufs ab.
Verzögerung bei der Georeplikation überwachen
Verwenden Sie zum Überwachen der Verzögerung in Bezug auf RPO in der primären Datenbank die Spalte replication_lag_sec von sys.dm_geo_replication_link_status. Sie zeigt die Verzögerung in Sekunden zwischen den Transaktionen, die auf dem primären System durchgeführt wurden, und den gehärteten Transaktionen im Transaktionsprotokoll des sekundären Systems. Beträgt die Verzögerung beispielsweise eine Sekunde, bedeutet dies, dass Transaktionen, die in der letzten Sekunde durchgeführt wurden, verloren gehen, wenn die Primärseite in diesem Moment von einem Ausfall betroffen ist und ein Geo-Failover eingeleitet wird.
Um die Verzögerung bei Änderungen in der primären Datenbank zu messen, die in der geo-sekundären Datenbank gehärtet wurden, vergleichen Sie die last_commit-Zeit in der geo-sekundären Datenbank mit demselben Wert in der primären Datenbank.
Tipp
Wenn replication_lag_sec auf der Primärseite NULL ist, bedeutet dies, dass die Primärseite derzeit nicht weiß, wie weit eine Geosekundärseite zurückliegt. Dieser Fall tritt normalerweise ein, nachdem der Prozess neu gestartet wurde, und es sollte sich um einen vorübergehenden Zustand handeln. Erwägen Sie das Senden einer Warnung, wenn replication_lag_sec über einen längeren Zeitraum NULL zurückgibt. Es könnte darauf hinweisen, dass der Geo-Sekundärserver aufgrund eines Verbindungsfehlers nicht mit dem Primärserver kommunizieren kann.
Es gibt auch Bedingungen, die dazu führen können, dass der Unterschied zwischen der last_commit Zeit auf der Geosekundärseite und der Primärseite groß wird. Wenn z. B. nach einer langen Zeit ohne Änderungen ein Commit auf dem primären System durchgeführt wird, springt die Differenz auf einen großen Wert, bevor sie schnell wieder auf Null zurückgeht. Erwägen Sie, eine Warnmeldung zu senden, wenn die Differenz zwischen diesen beiden Werten über einen längeren Zeitraum groß bleibt.
Aktive Georeplikation programmatisch verwalten
Wie bereits erwähnt, kann die aktive Georeplikation auch programmatisch mit T-SQL, Azure PowerShell und REST API verwaltet werden. Die folgenden Tabellen beschreiben den verfügbaren Satz von Befehlen. Die aktive Georeplikation umfasst eine Reihe von Azure Resource Manager-APIs für die Verwaltung. Hierzu zählen unter anderem die Azure SQL-Datenbank-REST-API und Azure PowerShell-Cmdlets. Diese APIs unterstützen die rollenbasierte Zugriffskontrolle von Azure (Azure RBAC). Weitere Informationen zur Implementierung von Zugriffsrollen finden Sie unter Rollenbasierte Zugriffssteuerung in Azure (Azure RBAC).
T-SQL: Verwalten von Geo-Failover von einzelnen und gepoolten Datenbanken
Wichtig
Diese T-SQL-Befehle gelten nur für die aktive Georeplikation und nicht für Failover-Gruppen. Daher gelten sie auch nicht für SQL Managed Instance, das nur Failover-Gruppen unterstützt.
| Befehl | BESCHREIBUNG |
|---|---|
| ALTER DATABASE | Verwenden Sie das Argument ADD SECONDARY ON SERVER, um eine sekundäre Datenbank für eine bestehende Datenbank zu erstellen und die Datenreplikation zu starten |
| ALTER DATABASE | Verwenden Sie FAILOVER oder FORCE_FAILOVER_ALLOW_DATA_LOSS, um eine sekundäre Datenbank zur primären zu machen und ein Failover einzuleiten |
| ALTER DATABASE | Verwenden Sie REMOVE SECONDARY ON SERVER, um eine Datenreplikation zwischen einer SQL-Datenbank und der angegebenen sekundären Datenbank zu beenden. |
| sys.geo_replication_links | Gibt Informationen über alle vorhandenen Replikationsverknüpfungen für alle Datenbanken auf einem Server zurück. |
| sys.dm_geo_replication_link_status | Ruft den Zeitpunkt der letzten Replikation, die Verzögerung der letzten Replikation und andere Informationen über die Replikationsverknüpfung für eine angegebene Datenbank ab. |
| sys.dm_operation_status | Zeigt den Status aller Datenbankoperationen an, einschließlich Änderungen an Replikationsverbindungen. |
| sys.sp_wait_for_database_copy_sync | Bewirkt, dass die Anwendung wartet, bis alle bestätigten Transaktionen im Transaktionsprotokoll einer Geo-Sekundärdatei gehärtet sind. |
PowerShell: Verwalten von Geo-Failover von einzelnen und gepoolten Datenbanken
Hinweis
In diesem Artikel wird das Azure Az PowerShell-Modul verwendet. Dieses PowerShell-Modul wird für die Interaktion mit Azure empfohlen. Informationen zu den ersten Schritten mit dem Az PowerShell-Modul finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Wichtig
Das PowerShell Azure Resource Manager-Modul wird von Azure SQL-Datenbank weiterhin unterstützt, aber alle zukünftigen Entwicklungen erfolgen für das Az.Sql-Modul. Informationen zu diesen Cmdlets finden Sie unter AzureRM.Sql. Die Argumente für die Befehle im Az-Modul und den AzureRm-Modulen sind im Wesentlichen identisch.
| Cmdlet | BESCHREIBUNG |
|---|---|
| Get-AzSqlDatabase | Ruft mindestens eine Datenbank ab. |
| New-AzSqlDatabaseSecondary | Erstellt eine sekundäre Datenbank für eine vorhandene Datenbank und startet die Datenreplikation. |
| Set-AzSqlDatabaseSecondary | Erklärt die sekundäre Datenbank zur primären und wechselt zu ihr – dadurch wird das Failover gestartet. |
| Remove-AzSqlDatabaseSecondary | Beendet die Datenreplikation zwischen einer SQL-Datenbank und der angegebenen sekundären Datenbank. |
| Get-AzSqlDatabaseReplicationLink | Ruft die Geo-Replikationslinks für eine Datenbank ab. |
Tipp
Beispielskripts finden Sie unter Verwenden von PowerShell zum Konfigurieren der aktiven Georeplikation für eine einzelne Azure SQL-Datenbank und Verwenden von PowerShell zum Konfigurieren der aktiven Georeplikation für eine in einem Pool enthaltene Azure SQL-Datenbank.
REST-API: Verwalten von Geo-Failover von einzelnen und gepoolten Datenbanken
| API | BESCHREIBUNG |
|---|---|
| Create or Update Database (createMode=Restore) | Erstellt oder aktualisiert eine primäre oder sekundäre Datenbank oder stellt diese wieder her. |
| Get Create or Update Database Status | Ruft den Status während eines Erstellungsvorgangs ab. |
| Set Secondary Database as Primary (Planned Failover) | Legt fest, welche sekundäre Datenbank als primäre Datenbank verwendet wird, indem ein Failover von der aktuellen primären Datenbank durchgeführt wird. Diese Option wird für SQL Managed Instance nicht unterstützt. |
| Set Secondary Database as Primary (Unplanned Failover) | Legt fest, welche sekundäre Datenbank als primäre Datenbank verwendet wird, indem ein Failover von der aktuellen primären Datenbank durchgeführt wird. Bei diesem Vorgang können Daten verloren gehen. Diese Option wird für SQL Managed Instance nicht unterstützt. |
| Get Replication Link | Ruft eine spezifische Replikationsverknüpfung für eine angegebene Datenbank in einer Georeplikationspartnerschaft ab. Es werden die Informationen abgerufen, die in der Katalogsicht „sys.geo_replication_links“ sichtbar sind. Diese Option wird für SQL Managed Instance nicht unterstützt. |
| Replication Links – List By Database | Ruft alle Replikationsverknüpfungen für eine angegebene Datenbank in einer Georeplikationspartnerschaft ab. Es werden die Informationen abgerufen, die in der Katalogsicht „sys.geo_replication_links“ sichtbar sind. |
| Delete Replication Link | Löscht einen Datenbankreplikationslink. Kann nicht während eines Failovers verwendet werden. |
Nächste Schritte
- Beispielskripts, siehe:
- SQL-Datenbank unterstützt auch Failovergruppen. Weitere Informationen finden Sie unter Failovergruppen.
- Eine Übersicht und verschiedene Szenarien zum Thema Geschäftskontinuität finden Sie unter Übersicht über die Geschäftskontinuität.
- Sparen Sie Lizenzierungskosten, indem Sie Ihr sekundäres DR-Replikat als Standby festlegen.
- Weitere Informationen zu Azure SQL Database Hyperscale Georeplikaten finden Sie unter Hyperscale Georeplikat
- Informationen über automatisierte Sicherungen von Azure SQL-Datenbanken finden Sie unter Automatisierte SQL-Datenbanksicherungen.
- Informationen zum Verwenden automatisierter Sicherungen für die Wiederherstellung finden Sie unter Wiederherstellen einer Datenbank aus vom Dienst initiierten Sicherungen.
- Weitere Informationen zu Authentifizierungsanforderungen für einen neuen primären Server und die Datenbank finden Sie unter Verwalten der Sicherheit der Azure SQL-Datenbank nach der Notfallwiederherstellung.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für