Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL Database
Azure SQL Database
Mit der Funktion „Failovergruppen“ können Sie die Replikation und das Failover einiger oder aller Datenbanken von einem logischen Server auf einen in einer anderen Region verwalten. Dieser Artikel enthält eine Übersicht über die Failover-Gruppenfunktion mit bewährten Methoden und Empfehlungen für die Verwendung mit Azure SQL-Datenbank.
Um mit der Verwendung des Features zu beginnen, überprüfen Sie Configure a failover group for Azure SQL Database.
Hinweis
In diesem Artikel werden Failovergruppen für Azure SQL Database behandelt. Informationen zu Azure SQL Managed Instance finden Sie unter Failover-Gruppen – Übersicht und bewährte Methoden – Azure SQL Managed Instance.
Weitere Informationen zu Azure SQL Database Notfallwiederherstellung finden Sie in diesem Video:
Übersicht
Mit dem Feature "Failovergruppen" können Sie die Replikation und das Failover von Datenbanken in eine andere Azure Region verwalten. Sie können alle oder einen Teil der Benutzerdatenbanken in einem logischen Server auswählen, um diese auf einen anderen logischen Server zu replizieren. Hierbei handelt es sich um eine deklarative Abstraktion, die auf dem Feature Aktive Georeplikation basiert und dazu dient, die Bereitstellung und Verwaltung georeplizierter Datenbanken zu vereinfachen.
Informationen zu Geofailover-RPO und -RTO finden Sie unter Übersicht über die Geschäftskontinuität.
Endpunktumleitung
Failovergruppen stellen Listenerendpunkte mit Lese-/Schreibzugriff bereit sowie schreibgeschützte Listenerendpunkte, die während Geofailovers unverändert bleiben. Sie müssen die Verbindungszeichenfolge für Ihre Anwendung nach einem Geofailover nicht ändern, da Verbindungen automatisch an den aktuellen Primärserver weitergeleitet werden. Das Geo-Failover schaltet alle sekundären Datenbanken in der Gruppe zur primären Rolle um. Nach Abschluss des Geofailovers wird der DNS-Eintrag automatisch aktualisiert, um die Endpunkte in die neue Region umzuleiten.
Auslagern schreibgeschützter Workloads
Um den Datenverkehr an Ihre primären Datenbanken zu verringern, können Sie zudem mithilfe der sekundären Datenbanken in einer Failovergruppe schreibgeschützte Workloads auslagern. Verwenden Sie den schreibgeschützten Listener, um schreibgeschützten Datenverkehr an eine lesbare sekundäre Datenbank zu leiten.
Wiederherstellen einer Anwendung
Wenn Sie echte Geschäftskontinuität erreichen möchten, ist das Hinzufügen einer regionalen Datenbankredundanz nur ein Teil der Lösung. Für die komplette Wiederherstellung einer Anwendung bzw. eines Diensts nach einem schwerwiegenden Fehler ist das Wiederherstellen aller Komponenten erforderlich, aus denen sich der Dienst und alle abhängigen Dienste zusammensetzen. Beispiele dieser Komponenten sind die Clientsoftware (z. B. ein Browser mit benutzerdefiniertem JavaScript), Web-Front-Ends, Speicher und DNS. Es ist entscheidend, dass alle Komponenten gegen die gleichen Ausfälle widerstandsfähig sind und innerhalb des Recovery Time Objective (RTO) Ihrer Anwendung wieder verfügbar werden. Daher müssen Sie alle abhängigen Dienste bestimmen und die Garantien und Fähigkeiten verstehen, die sie bieten. Dann müssen Sie entsprechende Maßnahmen ergreifen, um sicherzustellen, dass Ihr Dienst während des Failovers der Dienste funktioniert, von denen er abhängig ist.
Failover-Richtlinie
Failovergruppen unterstützen zwei Failover-Strategien:
-
Vom Kunden verwaltet (empfohlen) – Kunden können ein Failover einer Gruppe ausführen, wenn sie einen unerwarteten Ausfall bemerken, der sich auf eine oder mehrere Datenbanken in der Failover-Gruppe auswirkt. Wenn Sie Befehlszeilentools wie PowerShell, die Azure CLI oder die Rest-API verwenden, wird der Failoverrichtlinienwert für vom Kunden verwaltete Ressourcen auf
manualgesetzt. -
Microsoft verwaltet – Im Falle eines weit verbreiteten Ausfalls, der sich auf eine primäre Region auswirkt, initiiert Microsoft ein Failover aller betroffenen Failovergruppen, für die ihre Failoverrichtlinie so konfiguriert ist, dass sie von Microsoft verwaltet wird. Von Microsoft verwaltetes Failover wird für einzelne Failovergruppen oder eine Teilmenge von Failovergruppen in einer Region nicht initiiert. Bei Verwendung von Befehlszeilentools wie PowerShell, dem Azure CLI oder der Rest-API wird der Failoverrichtlinienwert für microsoft-managed
automatic.
Jede Failoverrichtlinie verfügt über einen eindeutigen Satz von Anwendungsfällen und entsprechenden Erwartungen an den Failoverumfang und Datenverlust, wie in der folgenden Tabelle zusammengefasst:
| Failover-Richtlinie | Failoverbereich | Anwendungsfall | Potenzieller Datenverlust |
|---|---|---|---|
| Vom Kunden verwaltet (Empfohlen) |
Failovergruppen | Eines oder mehrere Datenbanken in einer Failovergruppe sind von einem Ausfall betroffen und nicht verfügbar. Sie können ein Failover wählen. | Ja |
| Von Microsoft verwaltet | Alle Failovergruppen in der Region | Ein weit verbreiteter Ausfall in einer Region führt dazu, dass Datenbanken nicht verfügbar sind, und das Microsoft Azure SQL-Serviceteam entscheidet, ein erzwungenes Failover auszulösen. Verwenden Sie diese Option nur, wenn Sie die Verantwortung für die Notfallwiederherstellung an Microsoft delegieren möchten und die Anwendung auf RTO (Ausfallzeiten) von mindestens einer Stunde oder mehr tolerant ist. Ein von Microsoft verwalteter Failover könnte nur in extremen Umständen ausgeführt werden. Eine vom Kunden verwaltete Failoverrichtlinie wird dringend empfohlen. |
Ja |
Vom Kunden verwaltet
In seltenen Fällen reicht die integrierte Verfügbarkeit oder hohe Verfügbarkeit nicht aus, um einen Ausfall zu minimieren, und Ihre Datenbanken in einer Failovergruppe sind möglicherweise für eine Dauer nicht verfügbar, die für die Vereinbarung zum Servicelevel (Service Level Agreement, SLA) der Anwendungen, die die Datenbanken verwenden, nicht akzeptabel ist. Datenbanken können aufgrund eines lokalisierten Problems, das sich auf nur wenige Datenbanken auswirkt, nicht verfügbar sein, oder sie kann sich auf der Ebene des Rechenzentrums, der Verfügbarkeitszone oder der Region befinden. In jedem dieser Fälle können Sie zum Wiederherstellen der Geschäftskontinuität ein erzwungenes Failover initiieren.
Das Festlegen Ihrer Failover-Richtlinie auf kundengesteuert wird dringend empfohlen, da Sie die Kontrolle darüber behalten, wann Sie ein Failover initiieren und die Geschäftskontinuität wiederherstellen möchten. Sie können ein Failover initiieren, wenn sie einen unerwarteten Ausfall bemerken, der sich auf eine oder mehrere Datenbanken in der Failovergruppe auswirkt.
Von Microsoft verwaltet
Mit einer von Microsoft verwalteten Failoverrichtlinie wird die Verantwortung für die Notfallwiederherstellung an den Azure SQL Dienst delegiert. Damit der Azure SQL Dienst ein erzwungenes Failover initiieren kann, müssen die folgenden Bedingungen erfüllt sein:
- Der Ausfall der Region aufgrund eines Naturkatastrophenereignisses, Konfigurationsänderungen, Softwarefehler oder Hardwarekomponentenfehler und viele Datenbanken in der Region sind betroffen.
- Die Karenzzeit ist abgelaufen. Da das Überprüfen und Abmildern des Ausfalls von menschlichen Maßnahmen abhängt, kann die Aufschubfrist nicht auf unter eine Stunde gesetzt werden.
Wenn diese Bedingungen erfüllt sind, initiiert der Azure SQL Dienst erzwungene Failover für alle Failovergruppen in der Region, für die die Failoverrichtlinie von Microsoft verwaltet wird.
Wichtig
Verwenden Sie die vom Kunden verwaltete Failoverrichtlinie, um Ihren Notfallwiederherstellungsplan zu testen und zu implementieren. Verlassen Sie sich nicht auf das von Microsoft verwaltete Failover, da es von Microsoft nur in Extremsituationen vorgenommen wird. Ein von Microsoft verwaltetes Failover wird für alle Failovergruppen in der Region initiiert, für die ihre Failoverrichtlinie auf "Microsoft verwaltet" festgelegt ist. Es kann nicht für einzelne Failovergruppen initiiert werden. Wenn Sie Ihre Failovergruppe selektiv umschalten müssen, verwenden Sie die vom Kunden verwaltete Failoverrichtlinie.
Legen Sie die Failoverrichtlinie nur auf die von Microsoft verwaltete Option fest, wenn:
- Sie möchten die Verantwortung für die Notfallwiederherstellung an den Azure SQL Dienst delegieren.
- Die Anwendung ist tolerant für Ihre Datenbank, die mindestens eine Stunde lang nicht verfügbar ist.
- Es ist akzeptabel, erzwungene Failover einige Zeit nach Ablauf der Nachfrist auszulösen, da die tatsächliche Zeit für das erzwungene Failover erheblich variieren kann.
- Es ist akzeptabel, dass alle Datenbanken innerhalb der Failovergruppe unabhängig vom Zonenredundanzkonfigurations- oder Verfügbarkeitsstatus fehlschlagen. Datenbanken, die für Zonenredundanz konfiguriert sind, sind zwar widerstandsfähig für Zonalfehler und sind möglicherweise nicht durch einen Ausfall betroffen, aber sie werden immer noch fehlgeschlagen, wenn sie Teil einer Failovergruppe mit einer von Microsoft verwalteten Failoverrichtlinie sind.
- Es ist akzeptabel, dass in der Failovergruppe Failovers von Datenbanken erzwungen werden, ohne die Abhängigkeit der Anwendung von anderen Azure Diensten oder Komponenten, die von der Anwendung verwendet werden, zu berücksichtigen, was zu Leistungsbeeinträchtigungen oder Nichtverfügbarkeit der Anwendung führen kann.
- Es ist akzeptabel, eine unbekannte Menge an Datenverlust zu verursachen, da die genaue Zeit des erzwungenen Failovers nicht gesteuert werden kann, und ignoriert den Synchronisierungsstatus der sekundären Datenbanken.
- Die primären und sekundären Replikate in der Failovergruppe haben die gleiche Servicestufe, Rechenebene und Rechengröße.
Wenn ein Failover von Microsoft ausgelöst wird, wird ein Eintrag für den Vorgangsnamen Failover Azure SQL Failovergruppe zum Azure Monitor Aktivitätsprotokoll hinzugefügt. Der Eintrag enthält den Namen der Failovergruppe unter Ressource, und bei Vom Ereignis initiiert wird ein einfacher Bindestrich (-) angezeigt, um zu kennzeichnen, dass das Failover von Microsoft initiiert wurde. Diese Informationen finden Sie auch auf der Seite Activity des neuen primären Servers oder der neuen Instanz im Azure Portal.
Terminologie und Funktionen
Failovergruppe (FOG)
Eine Failovergruppe ist eine benannte Gruppe von Datenbanken, die von einem einzelnen logischen Server in Azure verwaltet wird. Diese kann im Falle eines Ausfalls in der primären Region als Einheit in eine andere Azure-Region überwechseln, wenn alle oder einige der primären Datenbanken aufgrund eines Ausfalls in der primären Region nicht verfügbar sind.
Wichtig
Der Name der Failovergruppe muss innerhalb der
.database.windows.net-Domäne global eindeutig sein.Server
Einige oder alle Benutzerdatenbanken auf einem logischen Server können in einer Failovergruppe platziert werden. Außerdem unterstützt ein Server mehrere Failovergruppen auf einem einzelnen Server.
Primär
Der logische Server, auf dem die primären Datenbanken in der Failovergruppe gehostet werden.
Sekundär
Der logische Server, auf dem die sekundären Datenbanken in der Failovergruppe gehostet werden. Die sekundäre kann nicht in der gleichen Azure Region wie die primäre Region sein.
Failover (kein Datenverlust)
Beim Failover wird eine vollständige Datensynchronisierung zwischen der primären und der sekundären Datenbank ausgeführt, bevor die sekundäre Datenbank die Rolle der primären Datenbank übernimmt. Dadurch ist sichergestellt, dass keine Daten verloren gehen. Failover ist nur möglich, wenn auf die primäre Datei zugegriffen werden kann. Failover wird in den folgenden Szenarien verwendet:
- Durchführen von Notfallwiederherstellungen (DR-Drills) in der Produktion, wenn ein Datenverlust nicht akzeptabel ist
- Verschieben Sie die Arbeitslast in eine andere Region
- Die Arbeitslast in die primäre Region zurückverlagern, nachdem der Ausfall behoben wurde (Failback)
Erzwungenes Failover (potenzieller Datenverlust)
Beim ungeplanten oder erzwungenen Failover übernimmt die sekundäre Datenbank sofort die Rolle der primären Datenbank, ohne dass auf die Weitergabe kürzlicher Änderungen von der primären Datenbank gewartet wird. Dieser Vorgang kann zu Datenverlust führen. Ein erzwungenes Failover wird als Wiederherstellungsmethode bei Ausfällen verwendet, wenn auf die primäre Instanz nicht zugegriffen werden kann. Wenn der Ausfall behoben wird, stellt die alte primäre Datenbank automatisch wieder eine Verbindung her und wird zu einer neuen sekundären Datenbank. Ein Failover kann ausgeführt werden, um ein Failback durchzuführen und die Replikate an ihre ursprünglichen primären und sekundären Rollen zurückzugeben.
Toleranzperiode mit Datenverlust
Da Daten mithilfe der asynchronen Replikation auf die sekundäre Instanz repliziert werden, kann ein erzwungenes Failover von Gruppen mit Failoverrichtlinien, die von Microsoft verwaltet werden, zu Datenverlust führen. Sie können die Failover-Richtlinie im Hinblick auf die Toleranz Ihrer Anwendung gegenüber Datenverlust anpassen. Durch konfigurieren
GracePeriodWithDataLossHourskönnen Sie steuern, wie lange der Azure SQL Dienst wartet, bevor ein erzwungenes Failover initiiert wird, was zu Datenverlust führen kann.
Hinzufügen einzelner Datenbanken zu Failovergruppe
Sie können mehrere einzelne Datenbanken auf demselben logischen Server in dieselbe Failovergruppe einfügen. Wenn Sie eine einzelne Datenbank zur Failovergruppe hinzufügen, wird auf dem von Ihnen bei der Erstellung der Failovergruppe angegebenen sekundären Server automatisch eine sekundäre Datenbank mit derselben Edition und Bereitstellungsgröße erstellt. Wenn Sie eine Datenbank hinzufügen, die bereits auf dem sekundären Server eine sekundäre Datenbank hat, erbt die Gruppe diese Verknüpfung für die Georeplikation. Wenn Sie eine Datenbank hinzufügen, die bereits eine sekundäre Datenbank auf einem Server hat, der nicht Teil der Failovergruppe ist, wird eine neue sekundäre Datenbank auf dem sekundären Server erstellt.
Wichtig
- Stellen Sie sicher, dass der sekundäre logische Server keine Datenbank mit demselben Namen aufweist, es sei denn, es handelt sich um eine vorhandene sekundäre Datenbank.
- Wenn eine Datenbank In-Memory-OLTP-Objekte enthält, müssen die primäre Datenbank und die sekundäre Georeplikat-Datenbank übereinstimmende Dienstebenen aufweisen, da sich In-Memory-OLTP-Objekte im Speicher befinden. Eine niedrigere Dienstebene in der Geo-Replica-Datenbank könnte zu Problemen durch nicht genügend Arbeitsspeicher führen. Wenn dies der Fall ist, kann das Georeplikat die Datenbank nicht wiederherstellen, was dazu führt, dass die sekundäre Datenbank zusammen mit den In-Memory-OLTP-Objekten auf der sekundären Geodatenbank nicht verfügbar ist. Dies wiederum kann dazu führen, dass auch Failover nicht erfolgreich sind. Um dies zu vermeiden, stellen Sie sicher, dass die Dienstebene der sekundären Geodatenbank mit der der primären Datenbank übereinstimmt. Dienstebenenupgrades können Datenmengenoperationen sein und eine Weile dauern.
Hinzufügen von Datenbanken im elastischen Pool zur Failovergruppe
Sie können mehrere oder alle Datenbanken in einem Pool für elastische Datenbanken in dieselbe Failovergruppe einfügen. Wenn sich die primäre Datenbank in einem Pool für elastische Datenbanken befindet, wird die sekundäre Datenbank automatisch im Pool für elastische Datenbanken desselben Namens (sekundärer Pool) erstellt. Sie müssen sicherstellen, dass der sekundäre Server einen Pool für elastische Datenbanken mit genau demselben Namen und ausreichend freier Kapazität zum Hosten der sekundären Datenbanken enthält, die von der Failovergruppe erstellt werden. Wenn Sie im Pool eine Datenbank hinzufügen, die bereits im sekundären Pool eine sekundäre Datenbank hat, erbt die Gruppe diese Verknüpfung für die Georeplikation. Wenn Sie eine Datenbank hinzufügen, die bereits eine sekundäre Datenbank auf einem Server hat, der nicht Teil der Failovergruppe ist, wird eine neue sekundäre Datenbank im sekundären Pool erstellt.
Listener für Lese-/Schreibvorgänge in Failovergruppen
Ein DNS CNAME-Eintrag, der auf die aktuelle primäre Datenbank verweist. Er wird automatisch mit der Failover-Gruppe erstellt und ermöglicht der Lese-/Schreiblast, sich transparent wieder mit der primären Instanz zu verbinden, wenn sich diese nach dem Failover ändert. Wenn die Failovergruppe auf einem Server erstellt wird, hat der DNS CNAME-Eintrag für die Listener-URL die Form
<fog-name>.database.windows.net. Nach dem Failover wird der DNS-Eintrag automatisch aktualisiert, um den Hörer auf den neuen primären Server umzuleiten.Schreibgeschützter Failovergruppen-Listener
Ein DNS CNAME-Eintrag, der auf die aktuelle sekundäre Datenbank verweist. Er wird automatisch mit der Failovergruppe erstellt und ermöglicht es der schreibgeschützten SQL-Workload, sich transparent mit der sekundären Instanz zu verbinden, wenn sich diese nach dem Failover ändert. Wenn die Failovergruppe auf einem Server erstellt wird, hat der DNS CNAME-Eintrag für die Listener-URL die Form
<fog-name>.secondary.database.windows.net. Standardmäßig ist das Failover des schreibgeschützten Listeners deaktiviert, um sicherzustellen, dass die Leistung der Primärinstanz nicht beeinträchtigt wird, wenn die Sekundärinstanz offline ist. Es bedeutet jedoch auch, dass die schreibgeschützten Sitzungen erst dann eine Verbindung herstellen können, nachdem die sekundäre Datenbank wiederhergestellt wurde.Mehrere Failovergruppen
Sie können mehrere Failovergruppen für das gleiche Serverpaar konfigurieren, um den Umfang von Geofailovern zu steuern. Jede Gruppe führt ein unabhängiges Failover durch. Wenn Ihre Mandant-pro-Datenbank-Anwendung in mehreren Regionen bereitgestellt wird und Pools für elastische Datenbanken verwendet, können Sie diese Funktion verwenden, um primäre und sekundäre Datenbanken in jedem Pool zu kombinieren. Auf diese Weise können Sie möglicherweise die Auswirkungen eines Ausfalls auf einige Mandantendatenbanken reduzieren.
Architektur einer Failovergruppe
Eine Failovergruppe in Azure SQL Database kann eine oder mehrere Datenbanken enthalten, die in der Regel von derselben Anwendung verwendet werden. Eine Failovergruppe muss auf dem primären Server konfiguriert werden, der sie mit dem sekundären Server in einer anderen Azure Region verbindet. Die Failover-Gruppe kann alle oder einige Datenbanken auf dem primären Server umfassen. Das folgende Diagramm zeigt eine typische Konfiguration einer georedundanten Cloudanwendung mit mehreren Datenbanken und einer Failovergruppe:
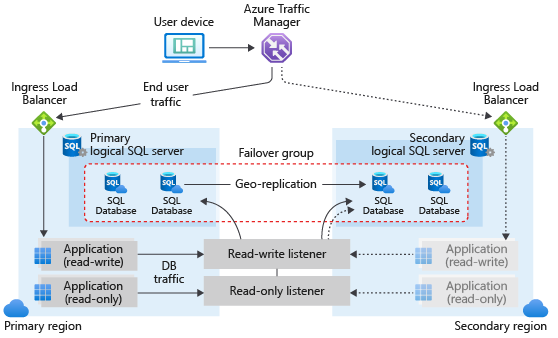
Wenn Sie einen Dienst entwerfen, der die Geschäftskontinuität aufrechterhalten soll, befolgen Sie die in diesem Artikel beschriebenen allgemeinen Richtlinien und Best Practices. Stellen Sie beim Konfigurieren einer Failovergruppe sicher, dass die Authentifizierung und der Netzwerkzugriff auf der sekundären Datenbank so eingerichtet sind, dass sie nach dem Geofailover ordnungsgemäß funktionieren, wenn die sekundäre Geodatenbank zur neuen primären Datenbank wird. Ausführliche Informationen finden Sie unter Konfigurieren und Verwalten der Sicherheit der Azure SQL-Datenbank für Geo-Wiederherstellung oder Failover. Weitere Informationen finden Sie unter Entwerfen von weltweit verfügbaren Diensten mit Azure SQL-Datenbank und Geo-restore für Azure SQL-Datenbank.
Verwenden Sie Regionspaare
Beim Erstellen Ihrer Failovergruppe zwischen dem primären und dem sekundären Server sollten Sie gekoppelte Regionen verwenden, da Failovergruppen in gekoppelten Regionen eine bessere Leistung im Vergleich zu nicht gekoppelten Regionen aufweisen.
Nach sicheren Bereitstellungspraktiken wird die Azure SQL-Datenbank im Allgemeinen nicht gleichzeitig in gekoppelten Regionen aktualisiert. Es ist jedoch nicht möglich vorherzusagen, für welche Region zuerst ein Upgrade ausgeführt wird, sodass die Reihenfolge der Bereitstellung nicht garantiert werden kann. Manchmal wird ihr primärer Server zuerst aktualisiert und manchmal wird es zweitens aktualisiert.
Wenn Sie geo-replication oder failover groups für Datenbanken konfiguriert haben, die nicht mit der Azure Region-Kopplung übereinstimmen, verwenden Sie unterschiedliche Wartungsfensterpläne für Ihre primären und sekundären Datenbanken. Sie können beispielsweise das Wartungsfenster Werktag für Ihre sekundäre Geodatenbank und das Wartungsfenster Wochenende für Ihre primäre Geodatenbank auswählen.
Anfängliche Aussaat
Beim Hinzufügen von Datenbanken oder elastischen Pools zu einer Failovergruppe gibt es eine anfängliche Initialisierungsphase, bevor die Replikation der Daten beginnt. Die anfängliche Seedingphase ist der längste und aufwendigste Vorgang. Sobald das anfängliche Seeding abgeschlossen ist, werden die Daten synchronisiert, und anschließend werden nur nachfolgende Datenänderungen repliziert. Die Zeit, die für das anfängliche Seeding benötigt wird, hängt von der Größe Ihrer Daten, der Anzahl der replizierten Datenbanken, der Last für primäre Datenbanken und der Geschwindigkeit der Verbindung zwischen der primären und der sekundären Datenbank ab. Unter normalen Umständen beträgt die mögliche Seedinggeschwindigkeit für SQL-Datenbank bis zu 500 GB pro Stunde. Das Seeding wird für alle Datenbanken parallel ausgeführt.
Anzahl der Datenbanken in einer Failovergruppe
Die Anzahl der Datenbanken in einer Failovergruppe wirkt sich unmittelbar auf die Dauer von Failover- und erzwungenen Failovervorgängen aus.
- Bei einem Failover (auch als geplantes Failover bezeichnet) wird sichergestellt, dass alle primären Datenbanken vollständig mit ihrem sekundären Datenbanken synchronisiert werden und einen bereiten Status erreichen. Um eine Überforderung der Steuerungsebene zu vermeiden, werden Datenbanken in Batches vorbereitet. Daher wird dringend empfohlen, die Anzahl der Datenbanken in einer Failovergruppe zu beschränken.
- Bei einem erzwungenen Failover ist die Vorbereitungsphase kürzer, da die Datensynchronisierung nicht initiiert wird. Um schnellere und vorhersagbare Failoverzeiten zu erzielen, kann es von Vorteil sein, die Anzahl der Datenbanken in der Failovergruppe zu verkleinern.
Verwenden mehrerer Failovergruppen für das Failover mehrerer Datenbanken
Eine oder mehrere Failovergruppen können zwischen zwei Servern in verschiedenen Regionen erstellt werden (primäre und sekundäre Server). Jede Gruppe kann eine oder mehrere Datenbanken enthalten, die als Einheit wiederhergestellt werden, falls alle oder einige primäre Datenbanken aufgrund eines Ausfalls in der primären Region nicht mehr verfügbar sind. Beim Erstellen einer Failovergruppe werden sekundäre Geodatenbanken mit dem gleichen Dienstziel wie bei der primären Datenbank erstellt. Wenn Sie einer Failovergruppe eine vorhandene Georeplikationsbeziehung hinzufügen, stellen Sie sicher, dass die sekundäre Geodatenbank mit der gleichen Dienstebene und Computegröße wie die primäre Datenbank konfiguriert ist.
Verwenden des Lese-/Schreiblisteners (primär)
Verwenden Sie für Workloads mit Lese-/Schreibzugriff <fog-name>.database.windows.net als Servernamen im connection string. Verbindungen werden automatisch zur primären Instanz weitergeleitet. Dieser Name wird nach dem Failover nicht geändert. Beachten Sie, dass das Failover die Aktualisierung von DNS-Einträgen einschließt, damit die Clientverbindungen erst dann an die neue primäre Datenbank weitergeleitet werden, wenn der Client-DNS-Cache aktualisiert wurde. Die Gültigkeitsdauer (TTL) des DNS-Eintrags für den primären und sekundären Listener beträgt 30 Sekunden.
Verwenden Sie den nur-Lese-Listener (sekundär)
Wenn Sie über logisch isolierte schreibgeschützte Workloads verfügen, die eine Toleranz gegenüber Datenlatenz aufweisen, können Sie sie auf einem geografischen sekundären System ausführen. Verwenden Sie für schreibgeschützte Sitzungen <fog-name>.secondary.database.windows.net als Servernamen im connection string. Verbindungen werden automatisch an das sekundäre geografische Rechenzentrum weitergeleitet. Es wird auch empfohlen, die Leseabsicht im connection string mithilfe von ApplicationIntent=ReadOnly anzugeben.
In den Dienstebenen Premium, Business Critical und Hyperscale unterstützt SQL-Datenbank die Verwendung von read-only-Replikaten zum Entladen schreibgeschützter Abfrageworkloads mithilfe des Parameters ApplicationIntent=ReadOnly im connection string. Wenn Sie einen geografischen Sekundärstandort konfiguriert haben, können Sie diese Möglichkeit nutzen, um entweder eine Verbindung zu einem schreibgeschützten Replikat am primären Standort oder am Sekundärstandort herzustellen:
Wenn Sie eine Verbindung mit einem schreibgeschützten Replikat am sekundären Standort herstellen möchten, verwenden Sie ApplicationIntent=ReadOnly und <fog-name>.secondary.database.windows.net.
Potenzielle Leistungsbeeinträchtigung nach einem Failover
Eine typische Azure Anwendung verwendet mehrere Azure Dienste und besteht aus mehreren Komponenten. Das Failover einer Gruppe wird basierend auf dem Status von Azure SQL Database ausgelöst. Andere Azure Dienste in der primären Region sind möglicherweise nicht von dem Ausfall betroffen, und ihre Komponenten sind in dieser Region weiterhin verfügbar. Nachdem die primären Datenbanken auf die sekundäre Region (DR-Region) umgestellt wurden, erhöht sich unter Umständen die Wartezeit zwischen den abhängigen Komponenten. Damit die Auswirkungen einer höheren Latenz auf die Leistung der Anwendung vermieden werden, stellen Sie die Redundanz aller Anwendungskomponenten in der DR-Region sicher, befolgen Sie diese Netzwerksicherheitsrichtlinien, und orchestrieren Sie das Geofailover relevanter Anwendungskomponenten zusammen mit der Datenbank.
Potentieller Datenverlust nach einem erzwungenen Failover
Wenn ein Ausfall in der primären Region auftritt, wurden die letzten Transaktionen möglicherweise nicht in die geo-sekundäre Region repliziert, und es kann Datenverlust geben, wenn ein erzwungenes Failover ausgeführt wird.
Wichtig
Bei elastischen Pools mit 800 oder weniger DTUs oder 8 oder weniger virtuellen Kernen und über 250 Datenbanken können Probleme wie geplante Geofailover, die länger dauern, und verminderte Leistung auftreten. Diese Probleme treten häufiger bei schreibintensiven Workloads auf, wenn Georeplikate geographisch weit auseinander liegen oder wenn mehrere sekundäre Georeplikate für jede Datenbank verwendet werden. Ein Symptom für diese Probleme ist eine im Laufe der Zeit zunehmende Verzögerung bei der Georeplikation, die möglicherweise bei einem Ausfall zu einem umfangreicheren Datenverlust führt. Diese Verzögerung können Sie mit sys.dm_geo_replication_link_status überwachen. Wenn diese Probleme auftreten, umfasst die Entschärfung das Hochskalieren des Pools, um mehr DTUs oder virtuelle Kerne zu erhalten, oder die Reduzierung der Anzahl georeplizierter Datenbanken im Pool. Detaillierte Anleitungen zur Problembehandlung bei Wiederholungsverzögerungen finden Sie unter Problembehandlung von Wiederholungsverzögerungen bei der Georeplikation.
Zurückschaltung
** Wenn Failover-Gruppen mit einer Microsoft-verwalteten Failoverrichtlinie konfiguriert sind, wird ein erzwungenes Failover auf den sekundären Geoserver während eines Notfallszenarios entsprechend der definierten Schonfrist initiiert. Das Failback auf den alten primären Server muss manuell initiiert werden.
Mehrere Sekundärsysteme
Wichtig
Mehrere Sekundärinstanzen für Failover-Gruppen sind eine Vorschaufunktion, die für Produktionsworkloads nicht empfohlen wird.
Jede Failovergruppe kann mehrere sekundäre Server in derselben oder unterschiedlichen Regionen unterstützen. Diese Konfiguration bietet zusätzliche Optionen für die Notfallwiederherstellung und ermöglicht die Verteilung schreibgeschützter Workloads über mehrere Regionen. Berücksichtigen Sie beim Konfigurieren mehrerer Secondärdateien Folgendes:
- Für jede Failovergruppe können bis zu vier sekundäre Server angegeben werden.
- Jeder sekundäre Server kann sich in derselben oder in einer anderen Region als der primäre Server sowie untereinander befinden.
- Jeder sekundäre Server verwaltet eine eigene Georeplikationsverknüpfung mit dem primären Server.
- Failover kann zu einem der sekundären Server durchgeführt werden.
- Der schreibgeschützte Listener kann nur für einen der sekundären Server konfiguriert werden und muss sich in einer anderen Region als Sekundärserver befinden, um schreibgeschützte Workloads ordnungsgemäß zu bedienen.
- Verkettung (Erstellen eines Georeplikats eines Georeplikats) wird mit dieser Konfiguration nicht unterstützt.
Erforderliche Berechtigungen und Einschränkungen
Überprüfen Sie das Handbuch für die Konfiguration von Failovergruppen für eine Liste der Berechtigungen und Einschränkungen.
Programmgesteuertes Verwalten von Failovergruppen
Failovergruppen können auch programmgesteuert mithilfe von Azure PowerShell, Azure CLI und REST-API verwaltet werden. Weitere Informationen hierzu erfahren Sie unter Configure a failover group for Azure SQL Database.
Aktivieren der hohen Verfügbarkeit (Zonenredundanz)
Verfügbarkeit durch Redundanz verbessert die Resilienz weiter, indem sie vor Ausfällen einer Verfügbarkeitszone innerhalb einer Region schützt.
Beim Erstellen einer Failovergruppe, die eine oder mehrere Datenbanken enthält, gibt es keine Option, hohe Verfügbarkeit für die sekundären Datenbanken zu aktivieren, unabhängig von den Einstellungen für hohe Verfügbarkeit der primären Datenbanken.
Zonenredundanz mit Nicht-Hyperscale-Datenbanken
Sekundäre Datenbanken, die über die Failovergruppe erstellt wurden, haben standardmäßig die Hochverfügbarkeit nicht aktiviert. Nachdem die Failovergruppe erstellt wurde, aktivieren Sie Hochverfügbarkeit für die Datenbanken, die in der Gruppe enthalten sind. Dieses Verhalten gilt auch, wenn Sie zuerst Active Geo-Replication erstellen und dann optional die Datenbanken zu einer Failovergruppe hinzufügen.
Zonenredundanz mit Hyperscale
Sekundäre Datenbanken, die über die Failovergruppe erstellt wurden, erben die Einstellungen für Hochverfügbarkeit ihrer jeweiligen primären Datenbanken. Wenn die Hochverfügbarkeit für die primäre Datenbank aktiviert hat, ist sie für die sekundäre Datenbank ebenfalls aktiviert. Wenn hingegen die Hochverfügbarkeit für die primäre Datenbank nicht aktiviert ist, ist sie für die sekundäre Datenbank ebenfalls nicht aktiviert.
Regionale Unterstützung für Verfügbarkeitszonen
In einem Szenario, in dem hohe Verfügbarkeit in der primären Datenbank aktiviert ist und sich die hinzugefügte sekundäre Datenbank in einer Region befindet, in der noch keine Verfügbarkeitszonen unterstützt werden, schlägt der Workflow mit einer Fehlermeldung mit Code 45122 fehl: "Erstellen oder Aktualisieren des Failovergruppenvorgangs erfolgreich abgeschlossen; Einige der Datenbanken konnten jedoch nicht zu Failovergruppen hinzugefügt oder daraus entfernt werden. Die Bereitstellung von zonenredundanten Datenbanken/Pools wird für Ihre aktuelle Anforderung nicht unterstützt. Um dieses Problem zu umgehen, verwenden Sie Aktive Georeplikation, wobei Sie beim Erstellen der sekundären Datenbank hohe Verfügbarkeit aktivieren oder deaktivieren. Sie können diese Datenbanken dann optional zu einer Failovergruppe hinzufügen.
Zugehöriger Inhalt
- Siehe Beispielskripts.
- Verwenden Sie PowerShell, um die aktive Geo-Replikation für Azure SQL-Datenbank zu konfigurieren
- Verwenden Sie PowerShell, um die aktive Georeplikation für eine gepoolte Datenbank in Azure SQL-Datenbank zu konfigurieren
- Verwenden Sie PowerShell, um eine Azure SQL-Datenbank zu einer Failover-Gruppe hinzuzufügen
- Eine Übersicht und verschiedene Szenarien zum Thema Geschäftskontinuität finden Sie unter Übersicht über die Geschäftskontinuität
- Weitere Informationen zu Azure SQL Database automatisierten Sicherungen finden Sie unter SQL Database automated backups.
- Informationen zum Verwenden automatisierter Sicherungen für die Wiederherstellung finden Sie unter Wiederherstellen einer Datenbank aus vom Dienst initiierten Sicherungen.
- Weitere Informationen zu Authentifizierungsanforderungen für einen neuen primären Server und die Datenbank finden Sie unter Verwalten der Sicherheit der Azure SQL-Datenbank nach der Notfallwiederherstellung.
- Informationen zur Fehlerbehebung bei Georeplikationsproblemen finden Sie unter Fehlerbehebung bei Georeplikations-Redo-Verzögerungen.