Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für::![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel wird beschrieben, wie die für Pools für elastische Datenbanken und Pooldatenbanken in Azure SQL-Datenbank verfügbaren Compute- und Speicherressourcen skaliert werden können.
Ändern der Computeressourcen (virtuelle Kerne oder DTUs)
Nach dem Auswählen der Anzahl von virtuellen Kernen oder eDTUs können Sie einen Pool für elastische Datenbanken dynamisch und bedarfsgerecht zentral hoch- oder herunterskalieren. Hierzu können Sie eine der folgenden Methoden verwenden:
Auswirkungen der Änderung der Dienstebene oder der Skalierung der Computegröße
Die Vorgehensweise zum Ändern der Dienstebene oder der Computegröße eines Pools für elastische Datenbanken ähnelt der Vorgehensweise für Einzeldatenbanken und umfasst im Wesentlichen folgende Schritte:
Erstellen einer neuen Computeinstanz für den Pool für elastische Datenbanken
Eine neue Computeinstanz für den Pool für elastische Datenbanken wird mit der angeforderten Dienstebene und Computegröße erstellt. Bei einigen Kombinationen von Dienstebenen- und Computegrößenänderungen muss in der neuen Compute-Instanz jeweils ein Replikat der einzelnen Datenbanken erstellt werden. Dies umfasst das Kopieren von Daten und kann sich stark auf die Gesamtwartezeit auswirken. Die Datenbanken bleiben unabhängig davon während dieses Schritts online, und Verbindungen werden weiterhin an die Datenbanken in der ursprünglichen Computeinstanz weitergeleitet.
Umleiten der Verbindungen zur neuen Computeinstanz
Vorhandene Verbindungen mit den Datenbanken in der ursprünglichen Computeinstanz werden verworfen. Alle neuen Verbindungen werden mit den Datenbanken in der neuen Computeinstanz hergestellt. Bei einigen Kombinationen von Dienstebenen- und Computegrößenänderungen werden Datenbankdateien während des Wechsels getrennt und neu angefügt. Die Umstellung kann zu einer kurzen Dienstunterbrechung führen, in der Datenbanken in der Regel für weniger als 30 Sekunden nicht verfügbar ist. Sollten zu dem Zeitpunkt, zu dem die Verbindungen getrennt werden, aktive zeitintensive Transaktionen ausgeführt werden, kann dieser Schritt länger dauern, weil abgebrochene Transaktionen wiederhergestellt werden müssen. Beschleunigte Datenbankwiederherstellung kann die Auswirkung beim Abbrechen lang andauernder Transaktionen verringern.
Wichtig
Während dieses Workflows gehen keine Daten verloren.
Wartezeit beim Ändern der Dienstebene oder beim Skalieren der Computegröße
Beim Ändern der Dienstebene, beim Skalieren der Computegröße einer Einzeldatenbank oder eines Pools für elastische Datenbanken, beim Verschieben einer Datenbank in einen/aus einem Pool für elastische Datenbanken oder beim Verschieben einer Datenbank zwischen Pools für elastische Datenbanken wird die geschätzte Wartezeit wie folgt parametrisiert:
| Wartezeit bei Skalierung des Pools für elastische Datenbanken | Zu Pool für elastische Datenbanken vom Typ „Basic“, „Standard“, „Universell“ | Zu Pool für elastische Datenbanken vom Typ „Premium“ oder „Unternehmenskritisch“ | Zu Pool für elastische Datenbanken vom Typ „Hyperscale“ |
|---|---|---|---|
| Von Pool für elastische Datenbanken vom Typ „Basic“, „Standard“, „Universell“ | Proportional zur Anzahl der Datenbanken | • Wartezeit proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz |
N/A – Datenbanken müssen einzeln zu Pools für elastische Hyperscale-Datenbanken hinzugefügt werden. Die Wartezeit bei Skalierung pro Datenbank ist in Skalieren von Einzeldatenbankressourcen dokumentiert. |
| Von Pool für elastische Datenbanken vom Typ „Premium“ oder „Unternehmenskritisch“ | • Wartezeit proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz |
• Wartezeit proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz |
N/A – Datenbanken müssen einzeln zu Pools für elastische Hyperscale-Datenbanken hinzugefügt werden. Die Wartezeit bei Skalierung pro Datenbank ist in Skalieren von Einzeldatenbankressourcen dokumentiert. |
| Von Pool für elastische Datenbanken vom Typ „Hyperscale“ | – | – | • Konstante Zeitlatenz unabhängig vom verwendeten Speicherplatz. • In der Regel weniger als 2 Minuten. |
Hinweis
- Beim Ändern der Dienstebene oder Skalieren der Computegröße für einen Pool für elastische Datenbanken eines anderen Typs als „Hyperscale“ muss der verwendete Speicherplatz aller Datenbanken im Pool addiert werden, um die Schätzung zu berechnen. Die Wartezeit bei Skalierung für Pools für elastische Hyperscale-Datenbanken ist unabhängig vom verwendeten Speicherplatz.
- Bei Pools für elastische Datenbanken vom Typ „Standard“ und „Universell“ verhält sich die Latenzzeit beim Verschieben einer Datenbank in einen/aus einem Pool für elastische Datenbanken oder zwischen Pools für elastische Datenbanken proportional zur Datenbankgröße, wenn für den Pool für elastische Datenbanken PFS-Speicher (Premium File Share, Premium-Dateifreigabe) verwendet wird. Um zu ermitteln, ob ein Pool PFS-Speicher verwendet, führen Sie die folgende Abfrage im Kontext einer beliebigen Datenbank im Pool aus. Wenn der Wert in der Spalte „AccountType“
PremiumFileStorageoderPremiumFileStorage-ZRSlautet, verwendet der Pool PFS-Speicher.
SELECT s.file_id,
s.type_desc,
s.name,
FILEPROPERTYEX(s.name, 'AccountType') AS AccountType
FROM sys.database_files AS s
WHERE s.type_desc IN ('ROWS', 'LOG');
Hinweis
- Die zonenredundante Eigenschaft bleibt bei der Skalierung eines Pools für elastische Datenbank vom Typ „Unternehmenskritisch“ zum Typ „Universell“ standardmäßig unverändert.
- Die Wartezeit für den Skalierungsvorgang beim Ändern der Zonenredundanz für einen Pool für elastische Datenbanken vom Typ „Universell“ ist proportional zur Datenbankgröße.
- Das Ändern eines vorhandenen Pools für elastische Datenbanken ohne Hyperscale in die Hyperscale-Edition wird nicht unterstützt. Weitere Informationen finden Sie unter Hyperscale-Pools für elastische Datenbanken. Stattdessen Datenbanken müssen einzeln zu Pools für elastische Hyperscale-Datenbanken hinzugefügt werden.
- Das Ändern der Edition eines Pools für elastische Hyperscale-Datenbanken in eine Nicht-Hyperscale-Edition wird nicht unterstützt. Weitere Informationen finden Sie unter Hyperscale-Pools für elastische Datenbanken.
Tipp
Weitere Informationen zum Überwachen aktuell ausgeführter Vorgänge finden Sie unter: Verwalten von Vorgängen mit der SQL-REST-API, Verwalten von Vorgängen mithilfe der CLI, Überwachen von Vorgängen mit T-SQL und unter diesen beiden PowerShell-Befehlen: Get-AzSqlElasticPoolActivity und Stop-AzSqlElasticPoolActivity.
Weitere Überlegungen zum Ändern der Dienstebene oder Skalieren der Computegröße
- Beim Reduzieren von virtuellen Kernen oder eDTUs für einen Pool für elastische Datenbanken muss die verwendete Poolspeichermenge kleiner als der Grenzwert für die maximale Datengröße der gewünschten Dienstebene und Poolcomputeressourcen sein.
- Wenn Sie die Anzahl von eDTUs für einen Pool für elastische Datenbanken erhöhen, können in folgenden Fällen zusätzliche Speicherkosten anfallen:
- Die maximale Datengröße des Pools wird vom Zielpool unterstützt.
- Die maximale Datengröße des Pools überschreitet die enthaltene Speichermenge des Zielpools.
- Wenn z. B. ein 100-eDTU-Standard-Pool mit einer maximalen Datengröße von 100 GB auf einen 50-eDTU-Standard-Pool herabgestuft wird, fallen zusätzliche Speicherkosten an, da der Zielpool eine maximale Datengröße von 100 GB unterstützt und die enthaltene Speichermenge nur 50 GB beträgt. Daher beträgt die zusätzliche Speichermenge 100 GB – 50 GB = 50 GB. Ausführliche Informationen zu den Preisen für zusätzlichen Speicherplatz siehe SQL-Datenbank – Preise. Wenn die tatsächlich verwendete Speichermenge kleiner als die enthaltene Speichermenge ist, können Sie diese zusätzlichen Kosten vermeiden, indem Sie die maximale Datengröße auf die enthaltene Menge reduzieren.
Abrechnung während der Skalierung
Die Abrechnung erfolgt für jede Stunde, in der eine Datenbank die höchste in dieser Stunde angewendete Dienstebene und Computegröße nutzt – unabhängig von der Verwendung der Datenbank und ob sie weniger als eine Stunde aktiv war. Wenn Sie beispielsweise eine Einzeldatenbank erstellen und diese fünf Minuten später löschen, wird Ihnen eine volle Datenbankstunde in Rechnung gestellt.
Ändern der Speichergröße in einem Pool für elastische Datenbanken
Die Speichergröße (maximale Datengröße) für den Pool für elastische Datenbanken kann mit dem Azure-Portal, PowerShell, der Azure CLI oder der REST-API angegeben werden. Wenn Sie die maximale Datengröße des elastischen Pools erhöhen, kann der angegebene Wert die maximale Datengrößengrenze des Dienstziels des Pools nicht überschreiten. Beim Verringern der maximalen Datengröße muss der angegebene neue Wert gleich dem gesamten oder größer als der gesamte Speicherplatz sein, der für alle Datenbanken im Pool zugewiesen ist.
Wichtig
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Speicherplatz für Datenbanken in Azure SQL-Datenbank.
vCore-basiertes Kaufmodell
- Die Speichergröße (maximale Datengröße) für Pools für elastische Datenbanken in den Ebenen „Universell“ oder „Unternehmenskritisch“ kann bis zu den maximalen Grenzwerten für die Datengröße angegeben werden, die unter Ressourcenlimits für Pools für elastische Datenbanken, die das V-Kern-Kaufmodell verwenden angegeben sind. Die maximale Datengröße für den Pool für elastische Datenbanken kann in Vielfachen von 1 GB erhöht oder verringert werden.
- Der Preis für den Speicher für einen Pool für elastische Datenbanken errechnet sich aus der angegebenen maximalen Datengröße multipliziert mit dem Speichereinheitenpreis für die Dienstebene. Ausführliche Informationen zu den Speicherpreisen finden Sie unter SQL-Datenbank – Preise.
Wichtig
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Speicherplatz für Datenbanken in Azure SQL-Datenbank.
DTU-basiertes Kaufmodell
- Der eDTU-Preis für einen elastischen Pool umfasst einen bestimmten Speicherplatz ohne zusätzliche Kosten. Zusätzlicher Datenspeicher, der über die enthaltene Menge hinausgeht, kann gegen einen Aufpreis bis zum Grenzwert der maximalen Datengröße bereitgestellt werden, der den bereitgestellten eDTUs entspricht. Informationen zu enthaltenen Speichermengen und Grenzwerten für die maximale Datengröße finden Sie unter Ressourcengrenzwerte für Pools für elastische Datenbanken, die das DTU-Kaufmodell verwenden.
- Der Preis für zusätzlichen Speicher für einen Pool für elastische Datenbanken errechnet sich aus der Menge an zusätzlich bereitgestelltem Speicher multipliziert mit dem Einheitenpreis für zusätzlichen Speicher für die Dienstebene. Ausführliche Informationen zu den Preisen für zusätzlichen Speicherplatz siehe SQL-Datenbank – Preise.
- Gültige Werte für die maximale Datengröße für einen elastischen Standard- oder Premium-Pool können einen der folgenden Werte aufweisen: 50 GB, 100 GB, 150 GB, 200 GB, 250 GB, 300 GB, 400 GB, 500 GB, 750 GB, 800 GB, 1.024 GB, 1.200 GB, 1.280 GB, 1.536 GB, 1.600 GB, 1.792 GB, 2.000 GB, 2.048 GB, 2.304 GB, 2.500 GB, 2.560 GB, 2.816 GB, 3.000 GB, 3.072 GB, 3.328 GB, 3.584 GB, 3.840 GB, 4.096 GB. Die angegebene maximale Datengröße darf die für die bereitgestellten eDTUs angegebene maximale Datengröße nicht überschreiten.
Wichtig
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Speicherplatz für Datenbanken in Azure SQL-Datenbank.
Überwachen oder Abbrechen von Skalierungsänderungen
Die Änderung einer Dienstebene oder der Vorgang zur Computeneuskalierung kann überwacht und abgebrochen werden.
Navigieren Sie auf der Übersichtsseite SQL-Pool für Pool für elastische Datenbanken zu Benachrichtigungen, und wählen Sie die Kachel mit dem Hinweis, dass derzeit ein Vorgang ausgeführt wird, aus:
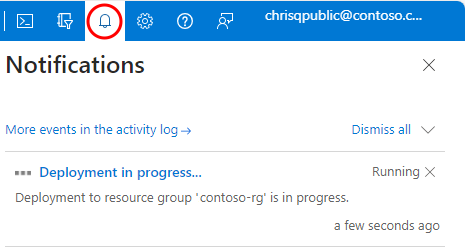
Wählen Sie auf der sich ergebenden Seite Bereitstellung wird ausgeführt die Option Abbrechen aus.
Berechtigungen
Um einen Pool für elastische Datenbanken über das Azure-Portal, PowerShell, die Azure CLI oder die REST-API zu skalieren, benötigen Sie Azure RBAC-Berechtigungen, insbesondere die Azure RBAC-Rollen „Mitwirkender“, „SQL DB-Mitwirkender“ oder „SQL Server-Mitwirkender“. Weitere Informationen finden Sie unter Integrierte Azure RBAC-Rollen.