Konfigurieren einer Failovergruppe für Azure SQL-Datenbank
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel wird erläutert, wie Sie eine Failovergruppe für eine Einzel- oder Pooldatenbank in Azure SQL-Datenbank über das Azure-Portal und Azure PowerShell konfigurieren.
Informationen zu End-to-End-Skripts erfahren Sie, wie Sie einer Failovergruppe mit Azure PowerShell oder der Azure CLI eine einzelne Datenbank hinzufügen.
Voraussetzungen
Beachten Sie die folgenden Voraussetzungen für die Erstellung Ihrer Failovergruppe für eine Einzeldatenbank:
- Die Einstellungen für Serveranmeldung und Firewall für den sekundären Server müssen mit denen Ihres primären Servers übereinstimmen.
Erstellen einer Failovergruppe
Erstellen Sie Ihre Failovergruppe und fügen Sie Ihre Einzeldaten mithilfe des Azure-Portals zu dieser Gruppe hinzu.
Wählen Sie im linken Menü im Azure-Portal die Option Azure SQL aus. Wenn Azure SQL nicht in der Liste aufgeführt wird, wählen Sie Alle Dienste aus, und geben Sie dann im Suchfeld „Azure SQL“ ein. (Optional:) Wählen Sie den Stern neben Azure SQL aus, um die Option als Favorit zu markieren und als Element im linken Navigationsbereich hinzuzufügen.
Wählen Sie die Datenbank aus, die Sie der Failovergruppe hinzufügen möchten.
Wählen Sie unter Servername den Namen des Servers aus, um die Einstellungen für diesen Server zu öffnen.

Wählen Sie Failovergruppen im Bereich Einstellungen aus, und klicken Sie dann auf Gruppe hinzufügen, um eine neue Failovergruppe zu erstellen.
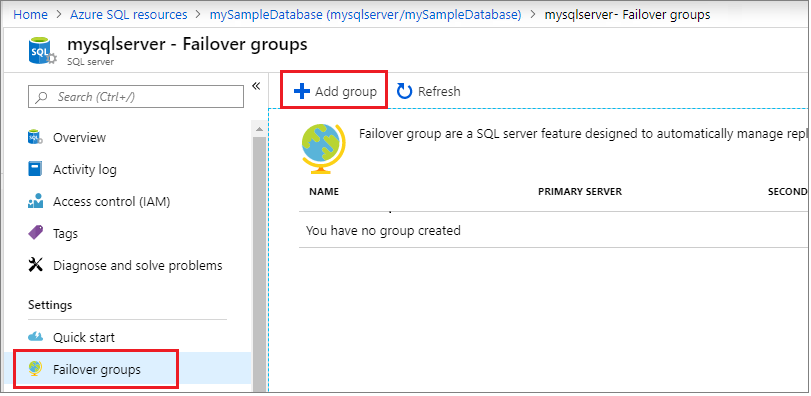
Wählen Sie auf der Seite Failovergruppe die erforderlichen Werte aus bzw. geben Sie sie ein, und wählen Sie dann Erstellen aus. Erstellen Sie entweder einen neuen sekundären Server, oder wählen Sie einen vorhandenen sekundären Server aus. Der sekundäre Server in der Failovergruppe muss sich in einer anderen Region befinden als der primäre Server.
- Datenbank innerhalb der Gruppe: Wählen Sie die Datenbank aus, die Sie Ihrer Failovergruppe hinzufügen möchten. Durch das Hinzufügen der Datenbank zur Failovergruppe wird automatisch der Georeplikationsprozess gestartet.
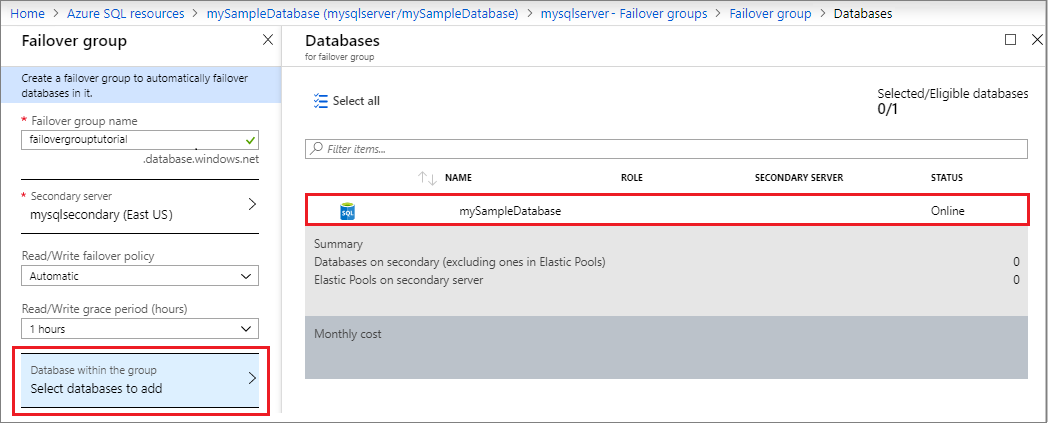
Testen des geplanten Failovers
Testen Sie das Failover Ihrer Failovergruppe mithilfe des Azure-Portals oder PowerShell.
Testen Sie das Failover Ihrer Failovergruppe mithilfe des Azure-Portals.
Wählen Sie im linken Menü im Azure-Portal die Option Azure SQL aus. Wenn Azure SQL nicht in der Liste aufgeführt wird, wählen Sie Alle Dienste aus, und geben Sie dann im Suchfeld „Azure SQL“ ein. (Optional:) Wählen Sie den Stern neben Azure SQL aus, um die Option als Favorit zu markieren und als Element im linken Navigationsbereich hinzuzufügen.
Wählen Sie die Datenbank aus, die Sie der Failovergruppe hinzufügen möchten.
Wählen Sie Failovergruppen im Bereich Einstellungen aus, und wählen Sie dann die soeben erstellte Failovergruppe aus.
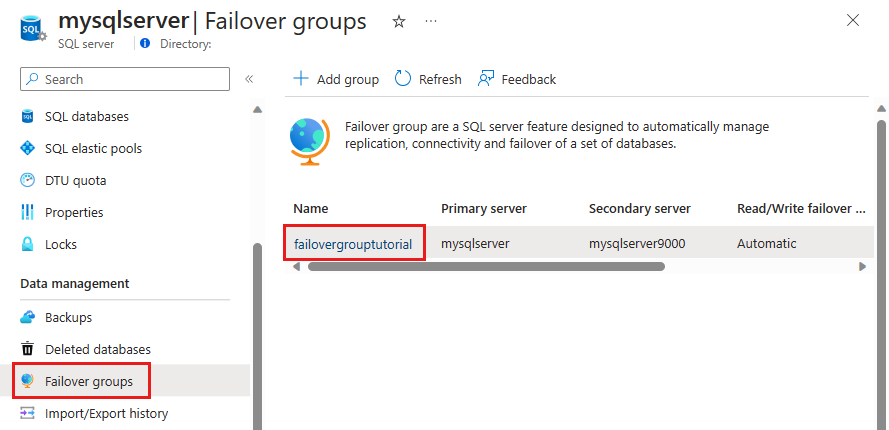
Überprüfen Sie, welcher Server der primäre und welcher der sekundäre ist.
Wählen Sie im Aufgabenbereich Failover aus, um ein Failover für die Failovergruppe mit Ihrer Datenbank durchzuführen.
Wählen Sie in der Meldung, dass die TDS-Sitzungen getrennt werden, Ja aus.
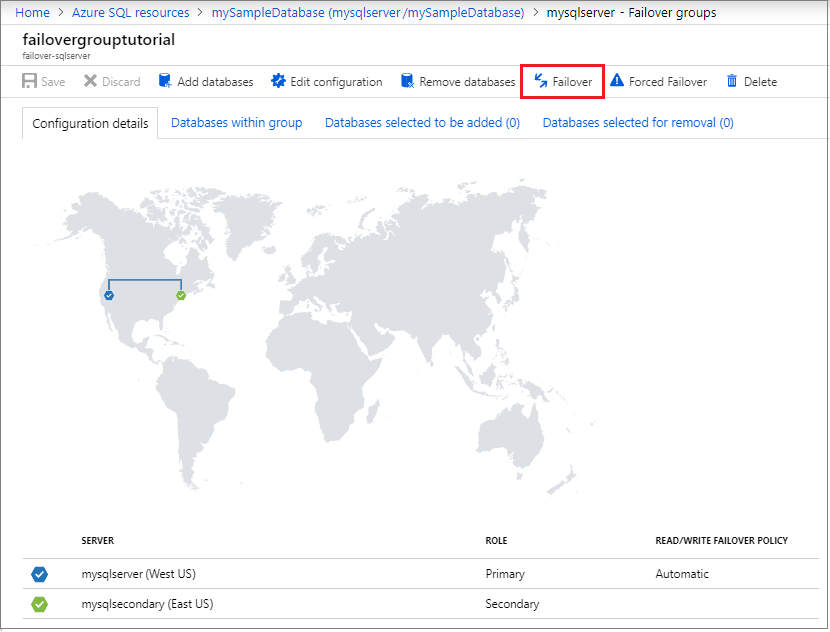
Überprüfen Sie, welcher Server jetzt der primäre und welcher der sekundäre ist. Wenn das Failover erfolgreich ausgeführt wurde, sollten die beiden Server die Rollen getauscht haben.
Wählen Sie erneut Failover aus, um die Server auf ihre ursprünglichen Rollen zurückzusetzen.
Wichtig
Wenn Sie die sekundäre Datenbank löschen müssen, entfernen Sie sie vor dem Löschen aus der Failovergruppe. Wenn eine sekundäre Datenbank vor dem Entfernen aus der Failovergruppe gelöscht wird, kann dies zu unvorhersehbarem Verhalten führen.
Informationen zu End-to-End-Skripts erfahren Sie, wie Sie einer Failovergruppe mit Azure PowerShell oder der Azure CLI einen elastischen Pool hinzufügen.
Voraussetzungen
Beachten Sie die folgenden Voraussetzungen für die Erstellung Ihrer Failovergruppe für eine Pooldatenbank:
- Die Einstellungen für Serveranmeldung und Firewall für den sekundären Server müssen mit denen Ihres primären Servers übereinstimmen.
Erstellen einer Failovergruppe
Erstellen Sie die Failovergruppe für Ihren Pool für elastische Datenbanken mithilfe des Azure-Portals oder PowerShell.
Erstellen Sie Ihre Failovergruppe, und fügen Sie ihr Ihren Pool für elastische Datenbanken mithilfe des Azure-Portals hinzu.
Wählen Sie im linken Menü im Azure-Portal die Option Azure SQL aus. Wenn Azure SQL nicht in der Liste aufgeführt wird, wählen Sie Alle Dienste aus, und geben Sie dann im Suchfeld „Azure SQL“ ein. (Optional:) Wählen Sie den Stern neben Azure SQL aus, um die Option als Favorit zu markieren und als Element im linken Navigationsbereich hinzuzufügen.
Wählen Sie den Pool für elastische Datenbanken aus, den Sie der Failovergruppe hinzufügen möchten.
Wählen Sie im Bereich Übersicht unter Servername den Namen des Servers aus, um die Einstellungen für den Server zu öffnen.
Wählen Sie Failovergruppen im Bereich Einstellungen aus, und klicken Sie dann auf Gruppe hinzufügen, um eine neue Failovergruppe zu erstellen.
Wählen Sie auf der Seite Failovergruppe die erforderlichen Werte aus bzw. geben Sie sie ein, und wählen Sie dann Erstellen aus. Erstellen Sie entweder einen neuen sekundären Server, oder wählen Sie einen vorhandenen sekundären Server aus.
Wählen Sie Datenbanken in der Gruppe und dann den Pool für elastische Datenbanken aus, den Sie der Failovergruppe hinzufügen möchten. Wenn auf dem sekundären Server noch kein Pool für elastische Datenbanken vorhanden ist, wird eine Warnung angezeigt, die Sie auffordert, einen Pool für elastische Datenbanken auf dem sekundären Server zu erstellen. Wählen Sie die Warnung aus, und klicken Sie dann auf OK, um den Pool für elastische Datenbanken auf dem sekundären Server zu erstellen.
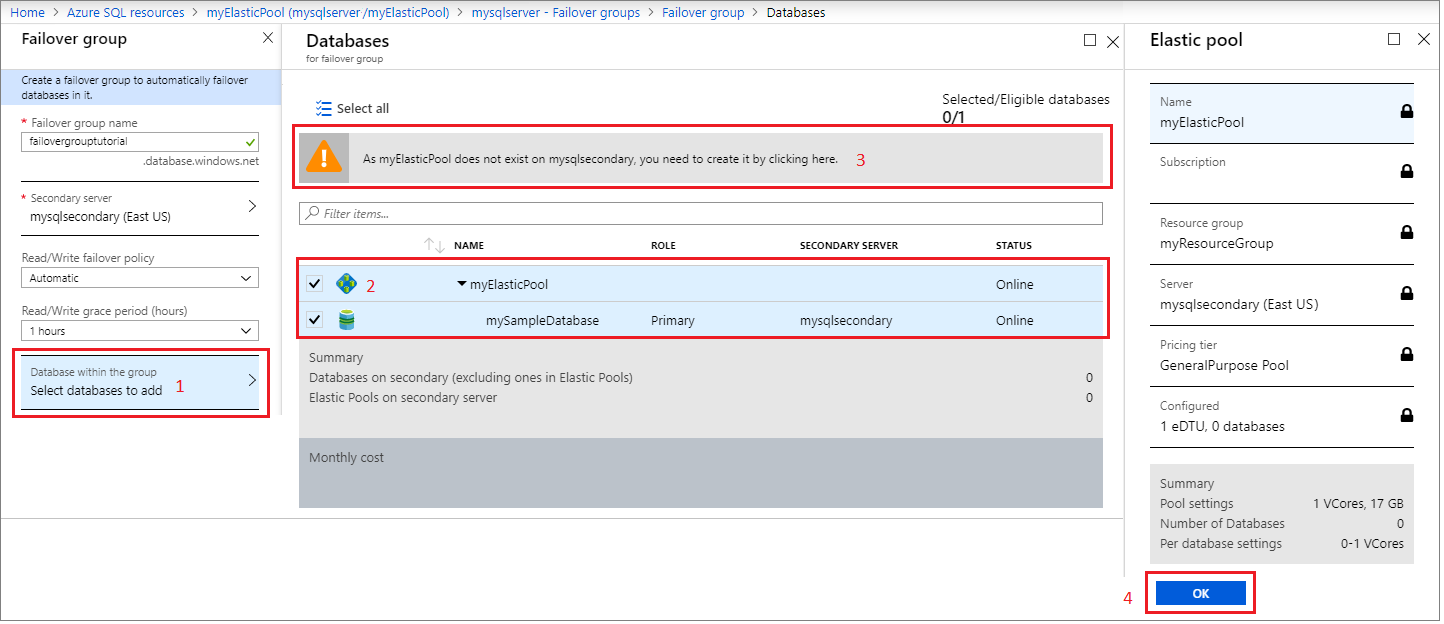
Wählen Sie Auswählen aus, um die Einstellungen für den Pool für elastische Datenbanken auf die Failovergruppe anzuwenden, und klicken Sie dann auf Erstellen, um Ihre Failovergruppe zu erstellen. Durch das Hinzufügen des Pool für elastische Datenbanken zur Failovergruppe wird automatisch der Georeplikationsprozess gestartet.
Testen des geplanten Failovers
Testen Sie das Failover Ihres Pool für elastische Datenbanken mithilfe des Azure-Portals oder PowerShell.
Führen Sie ein Failover für Ihre Failovergruppe auf den sekundären Server und anschließend ein Failback mit dem Azure-Portal aus.
Wählen Sie im linken Menü im Azure-Portal die Option Azure SQL aus. Wenn Azure SQL nicht in der Liste aufgeführt wird, wählen Sie Alle Dienste aus, und geben Sie dann im Suchfeld „Azure SQL“ ein. (Optional:) Wählen Sie den Stern neben Azure SQL aus, um die Option als Favorit zu markieren und als Element im linken Navigationsbereich hinzuzufügen.
Wählen Sie den Pool für elastische Datenbanken aus, den Sie der Failovergruppe hinzufügen möchten.
Wählen Sie im Bereich Übersicht unter Servername den Namen des Servers aus, um die Einstellungen für den Server zu öffnen.
Wählen Sie Failovergruppen im Bereich Einstellungen aus, und wählen Sie dann die soeben erstellte Failovergruppe aus.
Überprüfen Sie, welcher Server der primäre und welcher der sekundäre ist.
Wählen Sie im Aufgabenbereich Failover aus, um ein Failover für die Failovergruppe mit dem Pool für elastische Datenbanken durchzuführen.
Wählen Sie in der Meldung, dass die TDS-Sitzungen getrennt werden, Ja aus.
Überprüfen Sie, welcher Server der primäre und welcher der sekundäre ist. Wenn das Failover erfolgreich ausgeführt wurde, sollten die beiden Server die Rollen getauscht haben.
Wählen Sie erneut Failover aus, um die Failovergruppe wieder auf die ursprünglichen Einstellungen zurückzusetzen.
Wichtig
Wenn Sie die sekundäre Datenbank löschen müssen, entfernen Sie sie vor dem Löschen aus der Failovergruppe. Wenn eine sekundäre Datenbank vor dem Entfernen aus der Failovergruppe gelöscht wird, kann dies zu unvorhersehbarem Verhalten führen.
Verwenden von Private Link
Mithilfe einer privaten Verbindung können Sie einen logischen Server einer bestimmten privaten IP-Adresse innerhalb des virtuellen Netzwerks und Subnetzes zuordnen.
Gehen Sie folgendermaßen vor, um eine private Verbindung mit Ihrer Failovergruppe zu verwenden:
- Stellen Sie sicher, dass sich der primäre und der sekundäre Server in einem Regionspaar befinden.
- Erstellen Sie das virtuelle Netzwerk und das Subnetz in beiden Regionen, um private Endpunkte für den primären und den sekundären Server zu hosten, sodass sich die IP-Adressräume nicht überlappen. Der Adressbereich des primären virtuellen Netzwerks (10.0.0.0/16) und der des sekundären virtuellen Netzwerks (10.0.0.1/16) überschneiden sich beispielsweise. Weitere Informationen zu den Adressbereichen von virtuellen Netzwerken finden Sie im Blogartikel zum Entwerfen von virtuellen Azure-Netzwerken.
- Erstellen Sie einen privaten Endpunkt und eine private Azure-DNS-Zone für den primären Server.
- Erstellen Sie auch einen privaten Endpunkt für den sekundären Server. Verwenden Sie dafür jedoch die gleiche private DNS-Zone, die für den primären Server erstellt wurde.
- Nachdem die private Verbindung eingerichtet wurde, können Sie die Failovergruppe erstellen, indem Sie die zuvor in diesem Artikel beschriebenen Schritte ausführen.
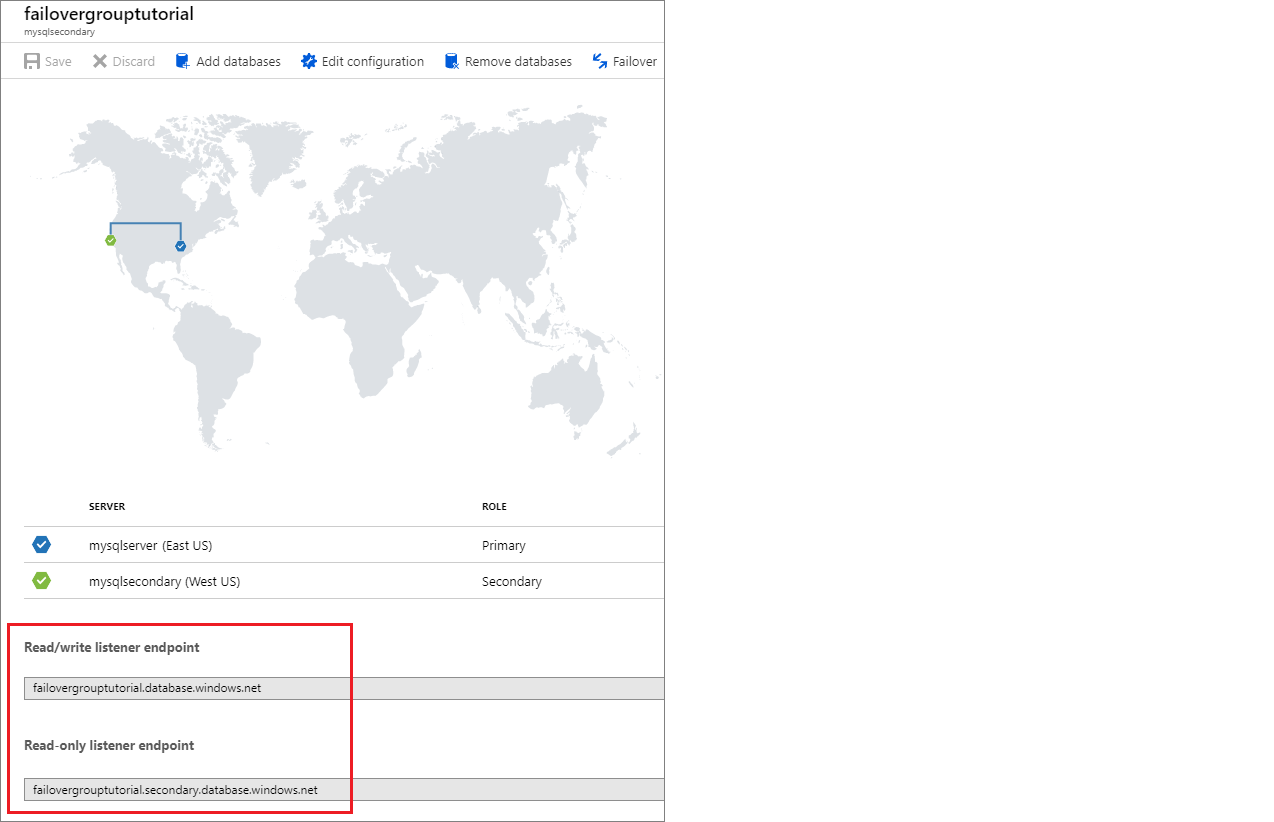
Listenerendpunkt suchen
Nachdem die Failovergruppe konfiguriert wurde, aktualisieren Sie die Verbindungszeichenfolge für die Anwendung auf den Listenerendpunkt. Dadurch bleibt Ihre Anwendung mit dem Listener der Failovergruppe verbunden und nicht mit der primären Datenbank oder dem Elastic Pool. Auf diesen Weise brauchen Sie die Verbindungszeichenfolge nicht bei jedem Failover Ihrer Datenbankentität manuell zu aktualisieren, und der Datenverkehr wird immer zu der Entität geroutet, die aktuell die primäre ist.
Der Listenerendpunkt hat die Form fog-name.database.windows.net und ist beim Anzeigen der Failovergruppe im Azure-Portal sichtbar:
Skalieren einer Datenbank in einer Failovergruppe
Sie können die primäre Datenbank auf eine andere Rechengröße vergrößern oder verkleinern (innerhalb derselben Dienstebene), ohne die Verbindung zu den sekundären Datenbanken zu unterbrechen. Bei der Skalierung wird empfohlen, zuerst die geo-sekundäre und dann die primäre Ebene zu vergrößern. Bei der Verkleinerung kehren Sie die Reihenfolge um: Verkleinern Sie zuerst die Primärseite und dann die Sekundärseite. Wenn Sie eine Datenbank auf eine andere Dienstebene skalieren, wird diese Empfehlung erzwungen.
Diese Reihenfolge ist besonders zur Vermeidung des Überladens der sekundären Datenbank auf einer niedrigeren SKU empfehlenswert, damit nicht während des Upgrade- oder Downgradevorgangs ein erneutes Seeding durchgeführt werden muss. Sie können dieses Problem auch vermeiden, indem Sie die primäre Datenbank mit Schreibschutz versehen. Das geht allerdings zu Lasten aller Lese-/Schreibworkloads für die primäre Datenbank.
Notiz
Wenn Sie im Rahmen der Konfiguration der Failovergruppe eine sekundäre Geodatenbank erstellt haben, wird davon abgeraten, die sekundäre Geodatenbank herunterzuskalieren. Damit soll sichergestellt werden, dass Ihre Datenebene über genügend Kapazität verfügt, um die reguläre Arbeitslast nach einem Geo-Failover zu verarbeiten. Sie können ein geosekundäres Datenbankreplikat nach einem erzwungenen Failover möglicherweise nicht skalieren, wenn das vormalige geoprimäre Datenbankreplikat aufgrund eines Ausfalls nicht verfügbar ist. Dies ist eine bekannte Einschränkung.
Verhinderung des Verlusts kritischer Daten
Aufgrund der hohen Latenzzeit von WANs verwendet die Georeplikation einen asynchronen Replikationsmechanismus. Bei der asynchronen Replikation ist die Möglichkeit eines Datenverlusts unvermeidbar, wenn die primäre Datenbank ausfällt. Zum Schutz kritischer Transaktionen vor Datenverlust, kann ein Anwendungsentwickler die gespeicherte Prozedur sp_wait_for_database_copy_sync unmittelbar nach dem Commit der Transaktion aufrufen. Der Aufruf von sp_wait_for_database_copy_sync blockiert den aufrufenden Thread, bis die letzte committete Transaktion übertragen und im Transaktionsprotokoll der sekundären Datenbank gehärtet wurde. Er wartet jedoch nicht darauf, dass die übertragenen Transaktionen in der sekundären Datenbank wiedergegeben (wiederholt) werden. sp_wait_for_database_copy_sync ist auf eine bestimmte Georeplikationslink beschränkt. Jeder Benutzer mit den Rechten zum Herstellen der Verbindung mit der primären Datenbank kann diese Prozedur aufrufen.
Notiz
sp_wait_for_database_copy_sync verhindert Datenverluste nach einem Geofailover für bestimmte Transaktionen, garantiert aber keine vollständige Synchronisierung für Lesezugriffe. Die durch einen sp_wait_for_database_copy_sync-Prozeduraufruf verursachte Verzögerung kann beträchtlich sein und hängt von der Größe des noch nicht übertragenen Transaktionsprotokolls auf der Primärseite zum Zeitpunkt des Aufrufs ab.
Ändern der sekundären Region
Zur Verdeutlichung der Änderungssequenz treffen wir die Annahme, dass Server A der primäre Server, Server B der vorhandene sekundäre Server und Server C der neue sekundäre Server in der dritten Region ist. Führen Sie diese Schritte aus, um die Umstellung durchzuführen:
- Erstellen Sie für jede Datenbank zusätzliche sekundäre Replikate von Server A auf Server C, indem Sie die aktive Georeplikation verwenden. Jede Datenbank auf Server A verfügt über zwei sekundäre Replikate: eins auf Server B und eins auf Server C. So wird garantiert, dass die primären Datenbanken während der Umstellung geschützt bleiben.
- Löschen Sie die Failovergruppe. An diesem Punkt treten bei Anmeldeversuchen, die Failovergruppenendpunkte verwenden, Fehler auf.
- Erstellen Sie die Failovergruppe mit dem gleichen Namen zwischen den Servern A und C neu.
- Fügen Sie alle primären Datenbanken von Server A der neuen Failovergruppe hinzu. An diesem Punkt schlagen die Anmeldeversuche nicht mehr fehl.
- Löschen Sie Server B. Alle Datenbanken auf Server B werden automatisch gelöscht.
Ändern der primären Region
Zur Verdeutlichung der Änderungssequenz nehmen wir an, dass Server A der primäre Server, Server B der vorhandene sekundäre Server und Server C der neue primäre Server in der dritten Region ist. Führen Sie diese Schritte aus, um die Umstellung durchzuführen:
- Führen Sie ein geplantes Geofailover durch, um den primären Server auf B umzustellen. Server A wird zum neuen sekundären Server. Beim Failover kann es zu einem Ausfall mit einer Dauer von mehreren Minuten kommen. Die tatsächliche Dauer hängt von der Größe der Failovergruppe ab.
- Erstellen Sie für jede Datenbank zusätzliche sekundäre Replikate von Server B auf Server C, indem Sie die aktive Georeplikation verwenden. Jede Datenbank auf Server B verfügt über zwei sekundäre Replikate: eins auf Server A und eins auf Server C. So wird garantiert, dass die primären Datenbanken während der Umstellung geschützt bleiben.
- Löschen Sie die Failovergruppe. An diesem Punkt treten bei Anmeldeversuchen, die Failovergruppenendpunkte verwenden, Fehler auf.
- Erstellen Sie die Failovergruppe mit dem gleichen Namen zwischen den Servern B und C neu.
- Fügen Sie alle primären Datenbanken von Server B der neuen Failovergruppe hinzu. An diesem Punkt schlagen die Loginversuche nicht mehr fehl.
- Führen Sie für die Failovergruppe ein geplantes Geofailover durch, um B und C umzustellen. Server C wird zum primären und Server B zum sekundären Server. Alle sekundären Datenbanken auf Server A werden automatisch mit den primären Replikaten auf C verknüpft. Wie in Schritt 1 auch, kann es beim Failover zu einem Ausfall von mehreren Minuten kommen.
- Löschen Sie Server A. Alle Datenbanken auf A werden automatisch gelöscht.
Wichtig
Wenn die Failovergruppe gelöscht wird, werden auch die DNS-Einträge für die Listenerendpunkte gelöscht. An diesem Punkt ist nicht völlig ausgeschlossen, dass eine andere Person eine Failovergruppe oder einen Server-DNS-Alias mit dem gleichen Namen erstellt. Da Failovergruppennamen und DNS-Aliase global eindeutig sein müssen, wird verhindert, dass Sie denselben Namen noch mal verwenden. Verwenden Sie keine generischen Namen für Failovergruppen um dieses Risiko zu minimieren.
Failovergruppen und Netzwerksicherheit
Für einige Anwendungen erfordern die Sicherheitsregeln, dass der Netzwerkzugriff auf die Datenebene auf eine bestimmte Komponente oder Komponenten wie eine VM, einen Webdienst usw. beschränkt ist. Diese Anforderung stellt einige Herausforderungen für den Entwurf der Geschäftskontinuität und die Verwendung von Failovergruppen dar. Berücksichtigen Sie bei der Implementierung eines solchen eingeschränkten Zugriffs die folgenden Optionen.
Verwenden von Failovergruppen und VNET-Dienstendpunkten
Wenn Sie Virtual Network-Dienstendpunkte und -Regeln verwenden, um den Zugriff auf Ihre SQL-Datenbank-Instanz einzuschränken, denken Sie daran, dass jeder Virtual Network-Dienstendpunkt nur für eine einzige Azure-Region gilt. Der Endpunkt ermöglicht anderen Regionen nicht das Akzeptieren von Nachrichten aus dem Subnetz. Aus diesem Grund können nur die Clientanwendungen, die in der gleichen Region bereitgestellt werden, eine Verbindung mit der primären Datenbank herstellen. Da ein Geofailover dazu führt, dass die SQL-Datenbank-Clientsitzungen zu dem Server in der anderen (sekundären) Region umgeleitet werden, treten bei diesen Sitzungen Fehler auf, wenn sie von Clients ausgehen, die sich außerhalb dieser Region befinden. Aus diesem Grund kann die Richtlinie für automatisches Failover nicht aktiviert werden, wenn die beteiligten Server in den VNET-Regeln enthalten sind. Gehen Sie folgendermaßen vor, um die manuelle Failover-Richtlinie zu unterstützen:
- Stellen Sie die redundanten Kopien der Front-End-Komponenten der Anwendung (Webdienst, VMs usw.) in der sekundären Region bereit.
- Konfigurieren Sie die VNET-Regeln einzeln für den primären und sekundären Server.
- Aktivieren Sie das Front-End-Failover durch eine Traffic Manager-Konfiguration.
- Initiieren Sie ein manuelles Geofailover, wenn der Ausfall erkannt wird. Diese Option ist für die Anwendungen optimiert, die konsistente Latenz zwischen Front-End und Datenebene erfordern, und unterstützt die Wiederherstellung, wenn Front-End, Datenebene oder beide vom Ausfall betroffen sind.
Notiz
Stellen Sie bei Verwendung des schreibgeschützten Listeners für den Lastenausgleich einer schreibgeschützten Workload sicher, dass diese Workload auf einem virtuellen Computer oder einer anderen Ressource in der sekundären Region ausgeführt wird, damit sie eine Verbindung mit der sekundären Datenbank herstellen kann.
Verwenden von Failovergruppen und Firewallregeln
Wenn Ihr Geschäftskontinuitätsplan das Durchführen eines Failovers mithilfe von Gruppen mit automatischem Failover erfordert, können Sie den Zugriff auf Ihre Datenbank in SQL-Datenbank mithilfe der öffentlichen IP-Firewallregeln einschränken. Die oben genannte Konfiguration sorgt dafür, dass ein automatisches Geofailover keine Verbindungen von den Front-End-Komponenten blockiert, und setzt voraus, dass die Anwendung die längeren Wartezeiten zwischen dem Front-End und der Datenebene tolerieren kann.
Gehen Sie folgendermaßen vor, um Failover-Gruppen-Failover zu unterstützen:
- Erstellen Sie eine öffentliche IP-Adresse.
- Erstellen Sie einen öffentlichen Lastenausgleich, und weisen Sie ihm die öffentliche IP-Adresse zu.
- Erstellen Sie ein virtuelles Netzwerk und die VMs für Ihre Front-End-Komponenten.
- Erstellen Sie eine Netzwerksicherheitsgruppe, und konfigurieren Sie eingehende Verbindungen.
- Stellen Sie mithilfe eines
Sql.<Region>Sql.<Region>sicher, dass die ausgehenden Verbindungen für Azure SQL-Datenbank in einer Region geöffnet sind. - Erstellen Sie eine SQL-Datenbank-Firewallregel, um eingehenden Datenverkehr von der öffentlichen IP-Adresse, die Sie in Schritt 1 erstellt haben, zuzulassen.
Weitere Informationen zur Konfiguration des ausgehenden Zugriffs und IP-Adresse, die in den Firewallregeln verwendet werden soll, finden Sie unter Ausgehende Verbindungen in Azure.
Wichtig
Damit die Geschäftskontinuität bei regionalen Ausfällen gewährleistet ist, müssen Sie die geografische Redundanz sowohl für die Front-End-Komponenten als auch die Datenbanken sicherstellen.
Berechtigungen
Berechtigungen für eine Failovergruppe werden über die rollenbasierte Zugriffssteuerung in Azure (Azure Role-Based Access Control, Azure RBAC) verwaltet.
Zum Erstellen und Verwalten von Failovergruppen wird Azure RBAC-Schreibzugriff benötigt. Die Rolle Mitwirkender von SQL Server verfügt über alle erforderlichen Berechtigungen zum Verwalten von Failovergruppen.
In der folgenden Tabelle werden spezifische Berechtigungsbereiche für Azure SQL-Datenbank aufgeführt:
| Aktion | Berechtigung | Umfang |
|---|---|---|
| Erstellen einer Failovergruppe | Azure RBAC-Schreibzugriff | Primärer Server Sekundärer Server Alle Datenbanken in der Failovergruppe |
| Aktualisieren einer Failovergruppe | Azure RBAC-Schreibzugriff | Failovergruppe Alle Datenbanken auf dem aktuellen primären Server |
| Failover einer Failovergruppe | Azure RBAC-Schreibzugriff | Failovergruppe auf dem neuen Server |
Einschränkungen
Bedenken Sie dabei folgende Einschränkungen:
- Failovergruppen können nicht zwischen zwei Servern in derselben Azure-Region erstellt werden.
- Failovergruppen unterstützen die Georeplikation aller Datenbanken in der Gruppe auf nur einen sekundären logischen Server in einer anderen Region.
- Failovergruppen können nicht umbenannt werden. Sie müssen die Gruppe löschen und unter einem anderen Namen neu erstellen.
- Die Datenbankumbenennung wird für Datenbanken in der Failovergruppe nicht unterstützt. Sie müssen die Failovergruppe vorübergehend löschen, um eine Datenbank umbenennen oder die Datenbank aus der Failovergruppe entfernen zu können.
- Wenn Sie eine Failovergruppe für eine einzelne oder eine Pooldatenbank entfernen, wird die Replikation nicht beendet und die replizierte Datenbank nicht gelöscht. Sie müssen die Georeplikation manuell beenden und die Datenbank vom sekundären Server löschen, wenn Sie eine einzelne Datenbank oder eine Pooldatenbank nach dem Löschen wieder einer Failovergruppe hinzufügen möchten. Wenn Sie keine der beiden Aktionen ausführen, kann ein Fehler ähnlich wie
The operation cannot be performed due to multiple errorsangezeigt werden, wenn Sie versuchen, der Failovergruppe die Datenbank hinzuzufügen. - Der Name der automatischen Failovergruppe unterliegt Benennungseinschränkungen.
Programmgesteuertes Verwalten von Failovergruppen
Gruppen für automatisches Failover können auch programmgesteuert mit Azure PowerShell, Azure CLI und der REST-API verwaltet werden. Die folgenden Tabellen beschreiben den verfügbaren Satz von Befehlen. Die aktive Georeplikation umfasst eine Reihe von Azure Resource Manager-APIs für die Verwaltung. Hierzu zählen unter anderem die Azure SQL-Datenbank-REST-API und Azure PowerShell-Cmdlets. Diese APIs erfordern die Verwendung von Ressourcengruppen und unterstützen die rollenbasierte Zugriffssteuerung (Azure RBAC) in Azure. Weitere Informationen zur Implementierung von Zugriffsrollen finden Sie unter Rollenbasierte Zugriffssteuerung in Azure (Azure RBAC).
| Cmdlet | Beschreibung |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Dieser Befehl erstellt eine Failovergruppe und registriert sie auf primären und sekundären Servern |
| Remove-AzSqlDatabaseFailoverGroup | Entfernt eine Failovergruppe vom Server |
| Get-AzSqlDatabaseFailoverGroup | Ruft die Konfiguration einer Failovergruppe ab |
| Set-AzSqlDatabaseFailoverGroup | Ändert die Konfiguration einer Failovergruppe |
| Switch-AzSqlDatabaseFailoverGroup | Löst das Failover einer Failovergruppe auf den sekundären Server aus |
| Add-AzSqlDatabaseToFailoverGroup | Fügt einer Failovergruppe eine oder mehrere Datenbanken hinzu |
Notiz
Es ist möglich, Ihre Failovergruppe subscriptionübergreifend bereitzustellen, indem Sie den -PartnerSubscriptionId-Parameter in Azure PowerShell ab Az.SQL 3.11.0 verwenden. Weitere Informationen finden Sie im folgenden Beispiel.
Nächste Schritte
Eine Übersicht der Optionen für Hochverfügbarkeit für Azure SQL-Datenbank finden Sie unter Georeplikation und Failovergruppen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für