Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel wird das Migrieren Ihrer Datenbank in Azure SQL-Datenbank vom DTU-basierten Kaufmodell (Database Transaction Unit, Datenbanktransaktionseinheit) zum vCore-basierten Kaufmodell (virtuellen Kern) beschrieben.
Migrieren einer Datenbank
Die Migration einer Datenbank vom DTU- zum vCore-basierten Kaufmodell ist vergleichbar mit der Skalierung zwischen Dienstzielen auf den Dienstebenen Basic, Standard und Premium mit ähnlicher Dauer und minimaler Ausfallzeit am Ende des Migrationsprozesses. Eine zum vCore-basierten Kaufmodell migrierte Datenbank kann jederzeit mit den gleichen Schritten zurück zum DTU-basierten Kaufmodell migriert werden. Eine Ausnahme gilt für Datenbanken, die zur Dienstebene Hyperscale migriert wurden.
Sie können Ihre Datenbank in ein anderes Kaufmodell migrieren, indem Sie die Azure-Portal, PowerShell, die Azure CLI und Transact-SQL verwenden.
Führen Sie die folgenden Schritte aus, um Ihre Datenbank mit dem Azure-Portal zu einem anderen Kaufmodell zu migrieren:
Rufen Sie Ihre SQL-Datenbank im Azure-Portal auf.
Wählen Sie Compute und Speicher unter Einstellungen.
Verwenden Sie die Dropdownliste unter Dienstebene, um ein neues Kaufmodell und eine neue Dienstebene auszuwählen:
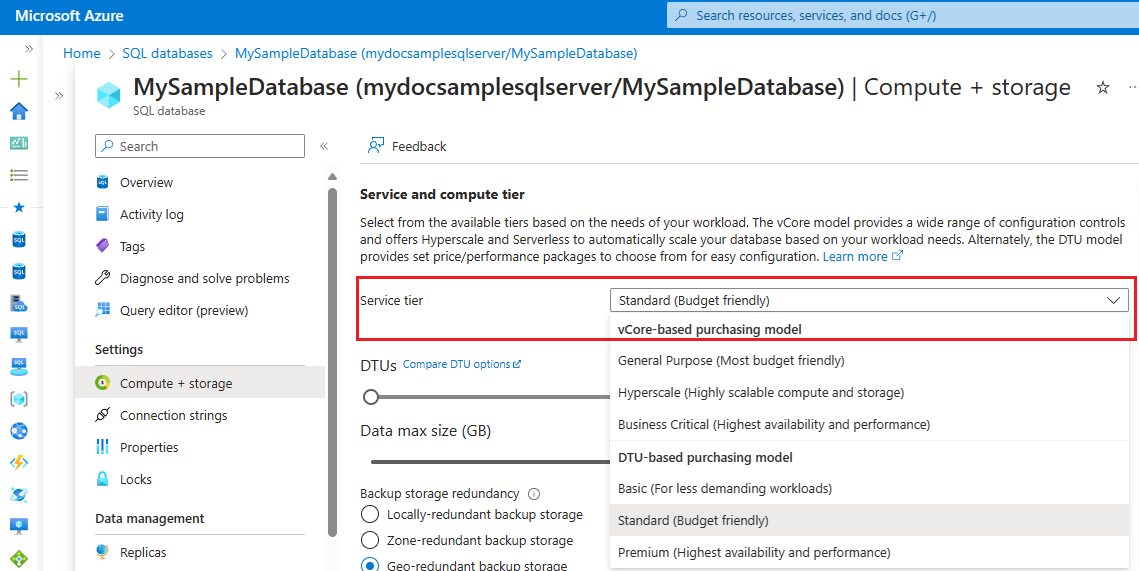

Wählen der vCore-Dienstebene und des Dienstziels
Bei den meisten Migrationsszenarien von DTU zu vCore werden Datenbanken und Pools für elastische Datenbanken auf den Dienstebenen Basic und Standard der Dienstebene Universell zugeordnet. Datenbanken und Pools für elastische Datenbanken auf der Dienstebene Premium werden der Dienstebene Unternehmenskritisch zugeordnet. Je nach Anwendungsszenario und Anforderungen kann die Dienstebene Hyperscale häufig als Migrationsziel für Datenbanken und Pools für elastische Datenbanken auf allen DTU-Dienstebenen genutzt werden.
Um das Dienstziel oder die Computegröße für die migrierte Datenbank im vCore-Modell zu wählen, können Sie eine grundlegende, aber ungefähre Faustregel befolgen: Alle 100 DTUs auf den Dienstebenen Basic oder Standard erfordern mindestens 1 virtuellen Kern, und alle 125 DTUs auf der Dienstebene Premium erfordern mindestens 1 virtuellen Kern.
Tipp
Diese Regel ist eine Näherung, da sie den für die DTU-Datenbank oder den Pool für elastische Datenbanken genutzten Hardwaretyp nicht berücksichtigt.
Im DTU-Modell kann jede verfügbare Hardwarekonfiguration für Ihre Datenbank oder Ihren Pool für elastische Datenbanken vom System ausgewählt werden. Darüber hinaus haben Sie beim DTU-Modell nur indirekte Kontrolle über die Anzahl der virtuellen Kerne (logischen CPUs), indem Sie höhere oder niedrigere DTU- oder eDTU-Werte auswählen.
Beim vCore-basierten Kaufmodell muss der Kunde eine explizite Auswahl sowohl der Hardwarekonfiguration als auch der Anzahl der virtuellen Kerne (logischen CPUs) treffen. Das DTU-basierte Kaufmodell bietet diese Wahlmöglichkeiten nicht. Der Hardwaretyp und Anzahl logischer CPUs, die für jede Datenbank und jeden Pool für elastische Datenbanken genutzt werden, werden über dynamische Verwaltungssichten verfügbar gemacht. Dies ermöglicht es, das passende vCore-Dienstziel genauer zu bestimmen.
Beim folgenden Ansatz werden diese Informationen zur Bestimmung eines vCore-Dienstziels mit einer ähnlichen Zuteilung von Ressourcen genutzt, um nach der Migration zum vCore-Modell ein ähnliches Leistungsniveau zu erreichen.
Zuordnung von DTU zu vCore
Die folgende T-SQL-Abfrage gibt bei der Ausführung im Kontext einer zu migrierenden DTU-Datenbank eine übereinstimmende Anzahl virtueller Kerne (möglicherweise als Bruchzahl) in jeder Hardwarekonfiguration im vCore-Modell zurück. Durch Runden dieser Zahl auf die nächstliegende Anzahl virtueller Kerne, die für Datenbanken und Pools für elastische Datenbanken in jeder Hardwarekonfiguration im vCore-Modell verfügbar sind, können Kund*innen das vCore-Dienstziel auswählen, das ihrer DTU-Datenbank oder ihrem Pool für elastische Datenbanken am ehesten entspricht.
Beispiele von Migrationsszenarien, die diesen Ansatz aufgreifen, sind im Abschnitt Beispiele beschrieben.
Führen Sie diese Abfrage im Kontext der zu migrierenden Datenbank und nicht in der master-Datenbank aus. Wenn Sie einen Pool für elastische Datenbanken migrieren, führen Sie die Abfrage im Kontext einer beliebigen Datenbank im Pool aus.
;WITH dtu_vcore_map
AS (
SELECT rg.slo_name,
CAST(DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS NVARCHAR(40)) COLLATE DATABASE_DEFAULT AS dtu_service_tier,
CASE
WHEN slo.slo_name LIKE '%SQLG4%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLGZ%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLG5%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG6%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG7%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%GPGEN8%' THEN 'standard_series'
END COLLATE DATABASE_DEFAULT AS dtu_hardware_gen,
s.scheduler_count * CAST(rg.instance_cap_cpu / 100. AS DECIMAL(3, 2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS DECIMAL(4, 2)) AS dtu_memory_per_core_gb
FROM sys.dm_user_db_resource_governance AS rg
CROSS JOIN (
SELECT COUNT(1) AS scheduler_count
FROM sys.dm_os_schedulers
WHERE status COLLATE DATABASE_DEFAULT = 'VISIBLE ONLINE'
) AS s
CROSS JOIN sys.dm_os_job_object AS jo
CROSS APPLY (SELECT UPPER(rg.slo_name) COLLATE DATABASE_DEFAULT AS slo_name) slo
WHERE rg.dtu_limit > 0
AND DB_NAME() COLLATE DATABASE_DEFAULT <> 'master'
AND rg.database_id = DB_ID()
)
SELECT dtu_logical_cpus,
dtu_memory_per_core_gb,
dtu_service_tier,
CASE
WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END AS vcore_service_tier,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus
END AS standard_series_vcores,
5.05 AS standard_series_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.8
END AS Fsv2_vcores,
1.89 AS Fsv2_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.9
END AS M_vcores,
29.4 AS M_memory_per_core_gb
FROM dtu_vcore_map;
Weitere Faktoren
Neben der Anzahl der virtuellen Kerne (logischen CPUs) und der Typ der Hardware können verschiedene andere Faktoren die Wahl des vCore-Dienstziels beeinflussen:
Die Transact-SQL-Zuordnungsabfrage entspricht den DTU- und vCore-Dienstzielen in Bezug auf ihre CPU-Kapazität. Daher sind die Ergebnisse bei CPU-gebundenen Workloads genauer.
Bei dem gleichen Hardwaretyp und der gleichen Anzahl virtueller Kerne sind die Ressourcengrenzwerte für IOPS- und Transaktionsprotokolldurchsatz bei vCore-Datenbanken oft höher als bei DTU-Datenbanken. Bei E/A-gebundenen Workloads ist es eventuell möglich, die Anzahl der virtuellen Kerne im vCore-Modell zu verringern, um dasselbe Leistungsniveau zu erreichen. Tatsächliche Ressourcengrenzwerte für DTU- und vCore-Datenbanken werden in der Sicht sys.dm_user_db_resource_governance verfügbar gemacht. Der Vergleich dieser Werte zwischen der zu migrierenden DTU-Datenbank oder dem Pool und einer vCore-Datenbank bzw. einem Pool unter Verwendung eines annähernd übereinstimmenden vCore-Dienstziels kann Ihnen helfen, das vCore-Dienstziel genauer auszuwählen.
Die Zuordnungsabfrage gibt auch die Arbeitsspeichergröße pro Kern für die zu migrierende DTU-Datenbank oder den zu migrierenden Pool für elastische Datenbanken und für jede Hardwarekonfiguration im vCore-Modell zurück. Die Gewährleistung eines ähnlichen oder größeren Gesamtarbeitsspeichers nach der Migration zu vCore ist wichtig für Workloads, die einen großen Datencache im Arbeitsspeicher benötigen, um eine ausreichende Leistung zu erzielen, oder für Workloads, die für die Abfrageverarbeitung große Speicherzuweisungen erfordern. Bei solchen Workloads kann es je nach tatsächlicher Leistung erforderlich sein, die Anzahl der virtuellen Kerne zu erhöhen, um genügend Gesamtarbeitsspeicher zu erhalten.
Bei Wahl des vCore-Dienstziels sollte die bisherige Ressourcennutzung der DTU-Datenbank berücksichtigt werden. DTU-Datenbanken mit durchweg nicht ausgelasteten CPU-Ressourcen benötigen möglicherweise weniger virtuellen Kerne als die von der Zuordnungsabfrage zurückgegebene Anzahl. Umgekehrt können DTU-Datenbanken, bei denen eine konstant hohe CPU-Auslastung eine unzureichende Leistung bei Workloads verursacht, mehr virtuellen Kerne erfordern, als von der Abfrage zurückgegeben werden.
Wenn Sie Datenbanken mit zeitweiligen oder unvorhersehbaren Nutzungsmustern migrieren, sollten Sie den Computetarif Serverlose Computeebene für Azure SQL-Datenbank erwägen. Die maximale Anzahl gleichzeitiger Worker beträgt beim Tarif „Serverlos“ 75 % des Limits für bereitgestelltes Computing bei gleicher Anzahl der maximal konfigurierten virtuellen Kerne. Außerdem ist bei „Serverlos“ der verfügbare maximale Arbeitsspeicher 3 GB mal der maximalen Anzahl konfigurierter virtueller Kerne und damit kleiner als der pro Kern verfügbare Arbeitsspeicher für bereitgestelltes Computing. Beispielsweise beträgt der maximale Arbeitsspeicher für Gen5 120 GB, wenn bei „Serverlos“ maximal 40 virtuelle Kerne konfiguriert sind, im Gegensatz dazu aber 204 GB bei bereitgestelltem Computing mit 40 virtuellen Kernen.
Beim vCore-Modell kann die unterstützte maximale Datenbankgröße je nach Hardware variieren. Überprüfen Sie für große Datenbanken die unterstützten Höchstgrößen im vCore-Modell für einzelne Datenbanken und Pools für elastische Datenbanken.
Bei Pools für elastische Datenbanken weisen die Modelle Ressourcengrenzwerte für Pools für elastische Datenbanken, die das DTU-Kaufmodell verwenden und vCore Unterschiede bei der maximal unterstützten Anzahl von Datenbanken pro Pool auf. Dies muss berücksichtigt werden, wenn Sie Pools für elastische Datenbanken mit vielen Datenbanken migrieren.
Einige Hardwarekonfigurationen sind möglicherweise nicht in allen Regionen verfügbar. Prüfen Sie die Verfügbarkeit unter Hardwarekonfiguration für SQL-Datenbank.
Bei den in diesem Abschnitt genannten Größenrichtlinien für die Migration von DTU zu vCore handelt es sich um Richtwerte, die eine erste Einschätzung des Dienstziels der Zieldatenbank ermöglichen sollen.
Die optimale Konfiguration der Zieldatenbank ist workloadabhängig. Um nach der Migration ein optimales Preis-Leistungs-Verhältnis zu erzielen, müssen Sie daher möglicherweise die Flexibilität des vCore-Modells nutzen, um die Anzahl der virtuellen Kerne, die Hardwarekonfiguration sowie die Dienst- und Computeebenen anzupassen. Möglicherweise müssen Sie auch Datenbankkonfigurationsparameter anpassen, z. B. den maximalen Grad an Parallelität, und/oder den Kompatibilitätsgrad der Datenbank ändern, um aktuelle Verbesserungen an der Datenbank-Engine anzuwenden.
Beispiele für die Migration von DTU zu vCore
Hinweis
Die Werte in den folgenden Beispielen dienen nur zur Veranschaulichung. Die in den beschriebenen Szenarien zurückgegebenen tatsächlichen Werte können unterschiedlich sein.
Migrieren einer Standard-S9-Datenbank
Die Zuordnungsabfrage gibt das folgende Ergebnis zurück (einige Spalten werden der Kürze halber nicht angezeigt):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 24,00 | 5,40 | 24,000 | 5,05 |
Sie können erkennen, dass die DTU-Standarddatenbank 24 logische CPUs (virtuelle Kerne) mit 5,4 GB Arbeitsspeicher pro virtuellem Kern hat. Die direkte Entsprechung dazu ist Hardware im Tarif „Universell“ mit zwei virtuellen Kernen auf Hardware der Standard-Serie (Gen5), d. h. das Dienstziel GP_Gen5_24 für virtuelle Kerne.
Migrieren einer Standard-S0-Datenbank
Die Zuordnungsabfrage gibt das folgende Ergebnis zurück (einige Spalten werden der Kürze halber nicht angezeigt):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 0,25 | 1.3 | 0,500 | 5,05 |
Sie können erkennen, dass die DTU-Datenbank die Entsprechung von 0,25 logischen CPUs (virtuellen Kernen) mit 1,3 GB Arbeitsspeicher pro virtuellem Kern hat. Die kleinsten vCore-Dienstziele in der Hardwarekonfiguration Standard-Serie (Gen5), GP_Gen5_2, bietet mehr Computeressourcen als die Standard-S0-Datenbank, sodass eine direkte Entsprechung nicht möglich ist. Empfohlen wird die Option GP_Gen5_2. Wenn außerdem die Workload für den Computetarif Serverlos gut geeignet ist, wäre GP_S_Gen5_1 eine bessere Entsprechung.
Migrieren einer Premium P15-Datenbank
Die Zuordnungsabfrage gibt das folgende Ergebnis zurück (einige Spalten werden der Kürze halber nicht angezeigt):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 42,00 | 4,86 | 42,000 | 5,05 |
Sie können erkennen, dass die DTU-Datenbank 42 logische CPUs (virtuelle Kerne) mit 4,86 GB Arbeitsspeicher pro virtuellem Kern hat. Es gibt zwar kein vCore-Dienstziel mit 42 Kernen, aber das Dienstziel BC_Gen5_40 ist sowohl in Bezug auf die CPU- als auch die Arbeitsspeicherkapazität nahezu identisch und eine gute Entsprechung.
Migrieren eines Pool für elastische Datenbanken mit 200 Basic-eDTUs
Die Zuordnungsabfrage gibt das folgende Ergebnis zurück (einige Spalten werden der Kürze halber nicht angezeigt):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 4.00 | 5,40 | 4,000 | 5,05 |
Sie können erkennen, dass der DTU-Pool für elastische Datenbanken 4 logische CPUs (virtuelle Kerne) mit 5,4 GB Arbeitsspeicher pro virtuellem Kern hat. Hardware der Standard-Serie erfordert 4 virtuelle Kerne. Dieses Serviceziel unterstützt jedoch maximal 200 Datenbanken pro Pool, während ein Pool für elastische Datenbanken mit 200 eDTU im Basic-Tarif bis zu 500 Datenbanken unterstützt. Wenn der zu migrierende Pool für elastische Datenbanken mehr als 200 Datenbanken umfasst, muss das entsprechende vCore-Dienstziel GP_Gen5_6 lauten, das bis zu 500 Datenbanken unterstützt.
Migrieren georeplizierter Datenbanken
Die Migration vom DTU-basierten zum V-Kern-basierten Modell ähnelt dem Up- oder Downgrade der Georeplikationsbeziehungen zwischen Datenbanken auf der Dienstebene „Standard“ und „Premium“. Sie müssen die Georeplikation für die Dienstebenen Universell und Unternehmenskritisch während der Migration nicht beenden, es müssen jedoch die folgenden Sequenzierungsregeln eingehalten werden:
- Bei einem Upgrade müssen Sie zuerst das Upgrade für die sekundäre Datenbank und anschließend das Upgrade für die primäre Datenbank durchführen.
- Drehen Sie bei einem Downgrade die Reihenfolge um: Führen Sie zuerst das Downgrade für die primäre und anschließend das Downgrade für die sekundäre Datenbank durch.
Um eine Datenbank in die Hyperscale-Dienstebene zu konvertieren, sollte die Georeplikation vorübergehend entfernt werden. Weitere Informationen finden Sie unter Konvertieren einer vorhandenen Datenbank in Hyperscale.
Bei Verwendung der Georeplikation zwischen zwei Pools für elastische Datenbanken empfiehlt es sich, einen Pool als primäres Element und den anderen als sekundäres Element festzulegen. In diesem Fall sollten Sie sich beim Migrieren von Pools für elastische Datenbanken an die gleiche Sequenzierungsanleitung halten. Falls Sie jedoch über Pools für elastische Datenbanken verfügen, die sowohl primäre als auch sekundäre Datenbanken enthalten, müssen Sie den Pool mit der höheren Auslastung als primäres Element behandeln und die Sequenzierungsregeln entsprechend befolgen.
Die folgende Tabelle enthält eine Anleitung für spezifische Migrationsszenarien:
| Aktuelle Dienstebene | Zieldienstebene | Migrationstyp | Benutzeraktionen |
|---|---|---|---|
| Standard | Universell | Seitwärts | Die Migration ist in einer beliebigen Reihenfolge möglich, aber Sie müssen, wie zuvor beschrieben, für eine geeignete Größe der virtuellen Kerne sorgen. |
| Premium | Unternehmenskritisch | Seitwärts | Die Migration ist in einer beliebigen Reihenfolge möglich, aber Sie müssen, wie zuvor beschrieben, für eine geeignete Größe der virtuellen Kerne sorgen. |
| Standard | Unternehmenskritisch | Aktualisieren | Sekundäre Einheit muss zuerst migriert werden |
| Unternehmenskritisch | Standard | Downgrade | Primäre Einheit muss zuerst migriert werden |
| Premium | Universell | Downgrade | Primäre Einheit muss zuerst migriert werden |
| Universell | Premium | Aktualisieren | Sekundäre Einheit muss zuerst migriert werden |
| Unternehmenskritisch | Universell | Downgrade | Primäre Einheit muss zuerst migriert werden |
| Universell | Unternehmenskritisch | Aktualisieren | Sekundäre Einheit muss zuerst migriert werden |
| Standard | Hyperscale | Seitwärts | Georeplikation vor der Migration zu Hyperscale zu deaktivieren |
| Premium | Hyperscale | Seitwärts | Georeplikation vor der Migration zu Hyperscale zu deaktivieren |
Migrieren von Failovergruppen
Für die Migration von Failovergruppen mit mehreren Datenbanken ist eine individuelle Migration der primären und sekundären Datenbank erforderlich. Während dieses Prozesses gelten die gleichen Aspekte und Sequenzierungsregeln. Nachdem die Datenbanken auf das V-Kern-basierte Kaufmodell umgestellt wurden, bleibt die Failovergruppe mit den gleichen Richtlinieneinstellungen wirksam.
Erstellen einer sekundären Datenbank für die Georeplikation
Eine sekundäre Datenbank für die Georeplikation (Geo-Sekundärdatenbank) kann nur mit der gleichen Dienstebene erstellt werden, die auch für die primäre Datenbank verwendet wurde. Bei Datenbanken mit hoher Protokollgenerierungsrate empfiehlt es sich, die Geo-Sekundärdatenbank mit der gleichen Computegröße zu erstellen wie die primäre Datenbank.
Wenn Sie eine Geo-Sekundärdatenbank im Pool für elastische Datenbanken für eine einzelne primäre Datenbank erstellen, muss die Einstellung maxVCore für den Pool der Computegröße der primären Datenbank entsprechen. Wenn Sie eine Geo-Sekundärdatenbank für eine primäre Datenbank in einem anderen Pool für elastische Datenbanken erstellen, sollte die Einstellung maxVCore der Pools gleich sein.
Verwenden von Datenbankkopien zum Migrieren von DTU zu vCore
Beim Kopieren einer Datenbank wird eine transaktional konsistente Momentaufnahme der Daten zu einem bestimmten Zeitpunkt nach dem Start des Kopiervorgangs erstellt. Nach diesem Zeitpunkt werden keine Daten zwischen der Quelle und dem Ziel mehr synchronisiert.
Sie können eine beliebige Datenbank mit einer DTU-basierten Computegröße in eine Datenbank mit einer V-Kern-basierten Computegröße durch Verwendung von PowerShell, Azure CLI, or Transact-SQL kopieren, ohne dass hierfür Einschränkungen oder spezielle Sequenzierungen gelten, solange die Zielcomputegröße die maximale Datenbankgröße der Quelldatenbank unterstützt. Das Kopieren einer Datenbank in eine andere Dienstebene wird im Azure-Portal nicht unterstützt.