Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() SQL-Datenbank in Fabric
SQL-Datenbank in Fabric
Sie können dynamische Verwaltungsansichten (DYNAMIC Management Views, DMVs) über Transact-SQL (T-SQL) abfragen, um die Arbeitsauslastung zu überwachen und Leistungsprobleme zu diagnostizieren, die durch blockierte oder lange ausgeführte Abfragen, Ressourcenengpässe, suboptimale Abfragepläne und vieles mehr verursacht werden können.
Verwenden Sie für die grafische Überwachung von Abfrageressourcen den Abfragespeicher.
Trinkgeld
Erwägen Sie automatische Datenbankoptimierung, um die Abfrageleistung automatisch zu verbessern.
Überwachen der Ressourcennutzung
Sie können die Ressourcennutzung auf Datenbankebene mithilfe der folgenden DMVs überwachen.
sys.dm_db_resource_stats
Da diese Ansicht eine detaillierte Darstellung der Daten der Ressourcennutzung ist, sollten Sie für alle Analysen des aktuellen Zustands oder für die Problembehandlung zuerst sys.dm_db_resource_stats verwenden. Mit dieser Abfrage wird beispielsweise die durchschnittliche und maximale Ressourcennutzung für die aktuelle Datenbank in der letzten Stunde angezeigt:
SELECT DB_NAME() AS database_name,
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats;
In der sys.dm_db_resource_stats-Ansicht werden die zuletzt verwendeten Ressourcennutzungsdaten relativ zu den Grenzwerten der Computegröße angezeigt. Prozentsätze für CPU, Daten-E/A, Protokollschreibvorgänge, Arbeitsthreads und Speicherauslastung in Richtung des Grenzwerts werden für jedes 15-Sekunden-Intervall aufgezeichnet und werden ungefähr eine Stunde lang bewahrt.
Weitere Beispielabfragen finden Sie in den Beispielen in sys.dm_db_resource_stats.
sys.resource_stats
Die Sicht sys.resource_stats in der master-Datenbank umfasst zusätzliche Informationen, die beim Überwachen der Leistung Ihrer Datenbank innerhalb der jeweiligen Dienstebene und Computegröße nützlich sind. Die Daten werden alle fünf Minuten gesammelt und c.a. 14 Tage lang aufbewahrt. Diese Sicht ist für eine längere Verlaufsanalyse der Ressourcennutzung Ihrer Datenbank hilfreich.
Der folgende Graph zeigt die CPU-Ressourcennutzung für eine Premium-Datenbank mit der Computegröße P2 für jede Stunde einer Woche. Dieser Graph beginnt mit einem Montag und zeigt fünf Arbeitstage und dann das Wochenende, an dem die Anwendung deutlich weniger gefragt ist.
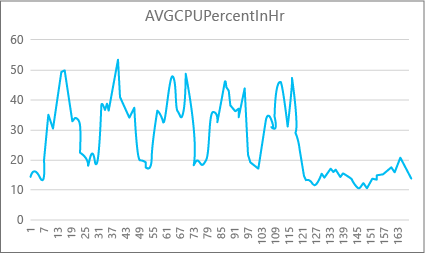
Die Daten verdeutlichen, dass diese Datenbank derzeit über eine CPU-Spitzenlast von etwas mehr als 50 Prozent CPU-Auslastung in Bezug zur Computegröße P2 verfügt (Dienstagmittag). Falls die CPU der entscheidende Faktor im Ressourcenprofil der Anwendung ist, entscheiden Sie sich ggf. für die Computegröße P2, um die Bewältigung der Workload stets sicherstellen zu können. Wenn eine Anwendung im Laufe der Zeit voraussichtlich größer wird, ist die Verwendung eines zusätzlichen Ressourcenpuffers ratsam, damit für die Anwendung nie der Grenzwert für die Leistungsebene erreicht wird. Wenn Sie die Computegröße erhöhen, können Sie für den Kunden sichtbare Fehler vermeiden. Diese können ggf. auftreten, wenn eine Datenbank nicht über genügend Leistung zum effektiven Verarbeiten von Anforderungen verfügt, vor allem in latenzsensiblen Umgebungen.
Bei anderen Anwendungstypen können Sie denselben Graphen unter Umständen anders interpretieren. Wenn eine Anwendung beispielsweise jeden Tag versucht, Gehaltsabrechnungsdaten zu verarbeiten, und dasselbe Diagramm gilt, wird diese Art von „Batchauftrag“-Modell bei der Computegröße P1 wahrscheinlich zufriedenstellend ausgeführt. Computegröße P1 verfügt über 100 DTUs im Vergleich zu 200 DTUs bei Computegröße P2. Computegröße P1 stellt gegenüber Computegröße P2 die halbe Leistungsfähigkeit bereit. Eine Nutzung von 50 Prozent CPU-Auslastung bei P2 entspricht also 100 Prozent CPU-Auslastung bei P1. Wenn die Anwendung keine Timeouts hat, spielt es möglicherweise keine Rolle, ob ein Auftrag 2 Stunden oder 2,5 Stunden dauert, bis er abgeschlossen ist, wenn er heute erledigt wird. Für eine Anwendung in dieser Kategorie reicht wahrscheinlich die Computegröße P1 aus. Sie können die Tatsache nutzen, dass es am Tag Zeiten gibt, in denen die Ressourcennutzung niedriger ist. Dies bedeutet, dass „Spitzen“ ggf. in einen der Zeiträume später am Tag verlagert werden können. Die Computegröße P1 ist für diese Art von Anwendung ggf. gut geeignet (und spart Kosten), solange die Aufträge jeden Tag pünktlich abgeschlossen werden können.
Die Datenbank-Engine macht die Informationen zum Ressourcenverbrauch für jede aktive Datenbank in der Sicht sys.resource_stats der master-Datenbank jedes logischen Servers verfügbar. Die Daten in der Ansicht werden in 5-Minuten-Intervallen zusammengefasst. Es kann einige Minuten dauern, bis sie in der Tabelle angezeigt werden. sys.resource_stats ist also besser für Verlaufsanalysen als für Analysen nahezu in Echtzeit geeignet. Fragen Sie die Sicht sys.resource_stats ab, um den kürzlichen Verlauf einer Datenbank anzuzeigen und zu überprüfen, ob die gewählte Computegröße zur gewünschten Leistung zur richtigen Zeit geführt hat.
Hinweis
Sie müssen eine Verbindung mit der master-Datenbank herstellen, um sys.resource_stats in den folgenden Beispielen abzufragen.
Dieses Beispiel zeigt Ihnen die Daten in sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
Das nächste Beispiel zeigt verschiedene Möglichkeiten zur Verwendung der sys.resource_stats-Katalogsicht, um Informationen zur Ressourcennutzung durch Ihre Datenbank abzurufen:
Um die Ressourcennutzung der vergangenen Woche für die Benutzerdatenbank
userdb1zu untersuchen, können Sie diese Abfrage ausführen, indem Sie Ihren eigenen Datenbanknamen ersetzen:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Um auszuwerten, wie gut Ihre Workload zur Computegröße passt, müssen Sie die einzelnen Aspekte der Ressourcenmetriken untersuchen: CPU, Daten, E/A, Protokoll schreiben, Anzahl von Workern und Anzahl von Sitzungen. Hier ist eine überarbeitete Abfrage mit
sys.resource_stats, um die Durchschnitts- und Höchstwerte dieser Ressourcenmetriken für jede Computegröße zu melden, für die die Datenbank bereitgestellt wurde:SELECT rs.database_name, rs.sku, MAX(rs.storage_in_megabytes) AS storage_mb, AVG(rs.avg_cpu_percent) AS 'Average CPU Utilization In %', MAX(rs.avg_cpu_percent) AS 'Maximum CPU Utilization In %', AVG(rs.avg_data_io_percent) AS 'Average Data IO In %', MAX(rs.avg_data_io_percent) AS 'Maximum Data IO In %', AVG(rs.avg_log_write_percent) AS 'Average Log Write Utilization In %', MAX(rs.avg_log_write_percent) AS 'Maximum Log Write Utilization In %', MAX(rs.max_worker_percent) AS 'Maximum Requests In %', MAX(rs.max_session_percent) AS 'Maximum Sessions In %' FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Mit diesen Informationen zu den Durchschnitts- und Höchstwerten der einzelnen Ressourcenmetriken können Sie bewerten, wie gut Ihre Workload zur ausgewählten Computegröße passt. Normalerweise erhalten Sie mit den Durchschnittswerten aus
sys.resource_statseine gute Grundlage gegenüber der Zielgröße.Für Datenbanken vom Typ DTU-Kaufmodell:
Beispielsweise können Sie die Standard-Dienstebene mit der Computegröße S2 verwenden. Die durchschnittlichen Nutzungsprozentsätze für CPU- und I/O-Lese- und -Schreibvorgänge liegen unter 40 Prozent, die durchschnittliche Anzahl von Workern unter 50 und die durchschnittliche Anzahl von Sitzungen unter 200. Für diese Workload ist unter Umständen die Computegröße S1 geeignet. Es ist leicht zu erkennen, ob Ihre Datenbank die Grenzen für Worker und Sitzungen einhält. Um zu ermitteln, ob sich für eine Datenbank eine niedrigere Computegröße eignet, dividieren Sie die DTU-Anzahl der niedrigeren Computegröße durch die DTU-Anzahl der aktuellen Computegröße, und multiplizieren Sie dann das Ergebnis mit 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Als Ergebnis erhalten Sie den relativen Leistungsunterschied zwischen den beiden Computegrößen in Prozent. Wenn die Ressourcennutzung diesen Prozentsatz nicht überschreitet, kann für Ihre Workload ggf. die niedrigere Computegröße geeignet sein. Sie sollten sich aber alle Bereiche der Ressourcennutzungswerte ansehen und anhand des Prozentsatzes ermitteln, wie oft für Ihre Datenbankworkload die niedrigere Computegröße geeignet wäre. Mit der folgenden Abfrage wird der Prozentsatz für die Eignung pro Ressourcendimension basierend auf dem in diesem Beispiel berechneten Schwellenwert von 40% ausgegeben:
SELECT database_name, 100 * ((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100 * ((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100 * ((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Auf Basis Ihrer Dienstebene für die Datenbank können Sie entscheiden, ob für Ihre Workload die niedrigere Computegröße geeignet ist. Wenn das Ziel für die Datenbankworkload 99,9 Prozent beträgt und die obige Abfrage höhere Werte als 99,9 Prozent für alle drei Ressourcendimensionen zurückgibt, ist die Wahrscheinlichkeit hoch, dass sich die niedrigere Computegröße für Ihre Workload eignet.
Wenn Sie sich den Prozentsatz für die Eignung ansehen, erhalten Sie auch Informationen dazu, ob Sie zur nächsthöheren Computegröße wechseln müssen, um das Ziel zu erreichen. Beispielsweise die CPU-Auslastung bei einer Beispieldatenbank in der vergangenen Woche:
Durchschnittlicher CPU-Prozentwert Maximaler CPU-Prozentwert 24,5 100,00 Der durchschnittliche CPU-Wert beträgt ca. ein Viertel der Obergrenze der Computegröße. Dies würde also gut zur Computegröße der Datenbank passen.
Für Datenbanken vom Typ DTU-Kaufmodell und vCore-Kaufmodell :
Der Höchstwert zeigt, dass die Datenbank die Obergrenze der Computegröße erreicht. Müssen Sie also zur nächsthöheren Computegröße wechseln? Prüfen Sie, wie häufig Ihre Workload 100 Prozent erreicht, und vergleichen Sie dies dann mit Ihrem Ziel für die Datenbankworkload.
SELECT database_name, 100 * ((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100 * ((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100 * ((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Diese Prozentsätze sind die Anzahl der Stichproben, die Ihre Workload bei der aktuellen Computegröße unterbringt. Wenn diese Abfrage einen Wert von weniger als 99,9 Prozent für eine der drei Ressourcendimensionen zurückgibt, überschreitet Ihre durchschnittliche Stichproben-Workload die Grenzwerte. Ziehen Sie entweder eine Umstellung auf die nächsthöhere Computegröße oder die Nutzung von Verfahren zur Anwendungsoptimierung in Betracht, um die Auslastung der Datenbank zu reduzieren.
sys.dm_elastic_pool_resource_stats
Gilt für: nur ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
So wie sys.dm_db_resource_stats stellt auch sys.dm_elastic_pool_resource_stats aktuelle und präzise Ressourcennutzungsdaten für einen Pool für elastische Azure SQL-Datenbank-Instanzen bereit. Die Ansicht kann in einer beliebigen Datenbank in einem Pool für elastische Datenbanken abgefragt werden, um Ressourcennutzungsdaten für einen gesamten Pool anstelle einer bestimmten Datenbank bereitzustellen. Die von diesem DMV gemeldeten Prozentwerte liegen in Richtung der Grenzwerte des Pools für elastische Datenbanken, die möglicherweise höher als die Grenzwerte für eine Datenbank im Pool sind.
Dieses Beispiel zeigt die zusammengefassten Ressourcennutzungsdaten für den aktuellen Pool für elastische Datenbanken in den letzten 15 Minuten:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Wenn Sie feststellen, dass sich die Ressourcennutzung über einen längeren Zeitraum hinweg 100 % nähert, sollten Sie die Ressourcennutzung der einzelnen Datenbanken im selben Pool für elastische Datenbanken überprüfen, um festzustellen, wie viel jede Datenbank zur Ressourcennutzung auf Poolebene beiträgt.
sys.elastic_pool_resource_stats
Gilt für: nur ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Ähnlich wie bei sys.resource_stats liefert sys.elastic_pool_resource_stats in der master-Datenbank historische Daten zum Ressourceneinsatz für alle Pools für elastische Datenbanken auf dem logischen Server. Sie können sys.elastic_pool_resource_stats für die Verlaufsüberwachung der letzten 14 Tagen verwenden, einschließlich der Nutzungstrendanalyse.
Dieses Beispiel zeigt die zusammengefassten Ressourcennutzungsdaten in den letzten sieben Tagen für alle Pools für elastische Datenbanken auf dem aktuellen logischen Server. Führen Sie die Abfrage in der master-Datenbank aus.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Gleichzeitige Anforderungen
Um die aktuelle Anzahl gleichzeitiger Anforderungen anzuzeigen, führen Sie diese Abfrage an Ihrer Benutzerdatenbank aus:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Dies ist nur eine Momentaufnahme zu einem bestimmten Zeitpunkt. Um ein besseres Verständnis Ihrer Workload und der Anforderungen an gleichzeitige Anforderungen zu entwickeln, müssten Sie im Laufe der Zeit viele Beispiele sammeln.
Durchschnittliche Anforderungsrate
Dieses Beispiel zeigt, wie Sie die durchschnittliche Anforderungsrate für eine Datenbank oder für Datenbanken in einem Pool für elastische Datenbanken über einen bestimmten Zeitraum ermitteln. In diesem Beispiel wird der Zeitraum auf 30 Sekunden festgelegt. Sie können sie anpassen, indem Sie die WAITFOR DELAY-Anweisung ändern. Führen Sie diese Abfrage in Ihrer Benutzerdatenbank aus. Wenn sich die Datenbank in einem Pool für elastische Datenbanken befindet und Sie über ausreichende Berechtigungen verfügen, umfassen die Ergebnisse auch andere Datenbanken im Pool für elastische Datenbanken.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Aktuelle Sitzungen
Um die Anzahl aktueller aktiver Sitzungen anzuzeigen, führen Sie diese Abfrage in Ihrer Datenbank aus:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Diese Abfrage liefert eine Zählung zu einem bestimmten Zeitpunkt. Wenn Sie im Laufe der Zeit mehrere Beispielwerte sammeln, können Sie sich am besten über Ihre Sitzungsnutzung informieren.
Aktueller Verlauf der Anforderungen, Sitzungen und Arbeiter
Dieses Beispiel gibt die aktuelle historische Nutzung von Anforderungen, Sitzungen und Arbeitsthreads für eine Datenbank oder für Datenbanken in einem Pool für elastische Datenbanken zurück. Jede Zeile stellt eine Momentaufnahme des Ressourceneinsatzes zu einem bestimmten Zeitpunkt für eine Datenbank dar. Die Spalte requests_per_second ist die durchschnittliche Anforderungsrate während des Zeitintervalls, das bei snapshot_time endet. Wenn sich die Datenbank in einem Pool für elastische Datenbanken befindet und Sie über ausreichende Berechtigungen verfügen, umfassen die Ergebnisse auch andere Datenbanken im Pool für elastische Datenbanken.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST (wg.delta_request_count AS DECIMAL) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Berechnen von Datenbank- und Objektgrößen
Die folgende Abfrage gibt die Datengröße in Ihrer Datenbank (in Megabyte) zurück:
-- Calculates the size of the database.
SELECT SUM(CAST (FILEPROPERTY(name, 'SpaceUsed') AS BIGINT) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Die folgende Abfrage gibt die Größe der einzelnen Objekte in Ihrer Datenbank in Megabyte zurück:
-- Calculates the size of individual database objects.
SELECT o.name,
SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Identifizieren von CPU-Leistungsproblemen
Dieser Abschnitt hilft Ihnen, einzelne Abfragen zu identifizieren, die besonders viel CPU verbrauchen.
Wenn der CPU-Verbrauch über einen längeren Zeitraum über 80 % liegt, berücksichtigen Sie die folgenden Schritte zur Problembehandlung, unabhängig davon, ob das CPU-Problem jetzt auftritt oder in der Vergangenheit aufgetreten ist. Sie können die Schritte in diesem Abschnitt außerdem ausführen, um die Abfragen mit dem höchsten CPU-Verbrauch proaktiv zu identifizieren und zu optimieren. In einigen Fällen können Sie durch die Reduzierung des CPU-Verbrauchs Ihre Datenbanken und Pools für elastische Datenbanken verkleinern und Kosten sparen.
Die Schritte zur Problembehandlung sind für eigenständige Datenbanken und Datenbanken in einem Pool für elastische Datenbanken identisch. Führen Sie alle Abfragen in der Benutzerdatenbank aus.
Das CPU-Problem tritt jetzt auf
Wenn das Problem aktuell auftritt, sind zwei Szenarien möglich:
Viele einzelne Abfragen, die zusammen zu einer hohen CPU-Auslastung führen
Verwenden Sie die folgende Abfrage, um die häufigsten Abfragen nach Abfragehash zu ermitteln:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() AS runtime,
*
FROM (SELECT query_stats.query_hash,
SUM(query_stats.cpu_time) AS 'Total_Request_Cpu_Time_Ms',
SUM(logical_reads) AS 'Total_Request_Logical_Reads',
MIN(start_time) AS 'Earliest_Request_start_Time',
COUNT(*) AS 'Number_Of_Requests',
SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*,
SUBSTRING(ST.text, (req.statement_start_offset / 2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset) / 2) + 1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Abfragen mit langer Ausführungszeit, die CPU-Ressourcen verbrauchen, werden noch ausgeführt
Verwenden Sie die folgende Abfrage, um diese Abfragen zu identifizieren:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
Das CPU-Problem ist in der Vergangenheit aufgetreten
Wenn das Problem in der Vergangenheit aufgetreten ist und Sie eine Ursachenanalyse durchführen möchten, verwenden Sie den Abfragespeicher. Benutzer mit Datenbankzugriff können T-SQL verwenden, um die Daten aus dem Abfragespeicher abzufragen. Standardmäßig erfasst der Abfragespeicher aggregierte Abfragestatistiken für einstündige Intervalle.
Verwenden Sie die folgende Abfrage, um die Aktivität für Abfragen mit hohem CPU-Verbrauch zu untersuchen. Diese Abfrage gibt die häufigsten 15 Abfragen mit CPU-Ressourcenverbrauch zurück. Denken Sie daran,
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()zu ändern, um einen anderen Zeitraum als die letzten zwei Stunden zu betrachten:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS (SELECT q.query_hash, SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms, SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms, MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms, MAX(max_logical_io_reads) AS max_logical_reads, COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans, COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids, SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count, SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count, SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count, SUM(count_executions) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular', 'Aborted', 'Exception') AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE()) GROUP BY q.query_hash), OrderedCPU AS (SELECT query_hash, total_cpu_ms, avg_cpu_ms, max_cpu_ms, max_logical_reads, number_of_distinct_plans, number_of_distinct_query_ids, total_executions, Aborted_Execution_Count, Regular_Execution_Count, Exception_Execution_Count, sampled_query_text, ROW_NUMBER() OVER (ORDER BY total_cpu_ms DESC, query_hash ASC) AS query_hash_row_number FROM AggregatedCPU) SELECT OD.query_hash, OD.total_cpu_ms, OD.avg_cpu_ms, OD.max_cpu_ms, OD.max_logical_reads, OD.number_of_distinct_plans, OD.number_of_distinct_query_ids, OD.total_executions, OD.Aborted_Execution_Count, OD.Regular_Execution_Count, OD.Exception_Execution_Count, OD.sampled_query_text, OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Sobald Sie die problematischen Abfragen identifiziert haben, sollten Sie diese optimieren, um die CPU-Auslastung zu reduzieren. Alternativ können Sie die Computegröße der Datenbank oder des Pools für elastische Datenbanken erhöhen, um das Problem zu umgehen.
Weitere Informationen zum Behandeln von CPU-Leistungsproblemen in der Azure SQL-Datenbank finden Sie unter Diagnose und Problembehandlung für hohe CPU in Azure SQL-Datenbank und SQL-Datenbank in Microsoft Fabric.
Identifizieren von Problemen mit der E/A-Leistung
Bei der Identifizierung von Problemen mit der Ein-/Ausgabeleistung (E/A) des Speichers sind die wichtigsten Wartetypen:
PAGEIOLATCH_*Für E/A-Probleme bei Datendateien (einschließlich
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Wenn der Name des Wartetyps die Buchstaben EA enthält, verweist er auf ein E/A-Problem. Wenn in der Seitensperre kein E/A vorhanden ist, weist dies auf ein anderes Problem hin, das sich nicht auf die Speicherleistung bezieht (z. B.tempdbContention).WRITE_LOGGilt für E/A-Probleme bei Transaktionsprotokollen.
Das E/A-Problem tritt jetzt auf
Verwenden Sie sys.dm_exec_requests oder sys.dm_os_waiting_tasks, um wait_type und wait_time anzuzeigen.
Identifizieren der Daten- und Protokoll-E/A-Nutzung
Verwenden Sie die folgende Abfrage, um die Daten- und Protokoll-E/A-Nutzung zu identifizieren.
SELECT DB_NAME() AS database_name,
end_time AS UTC_time,
rs.avg_data_io_percent AS 'Data IO In % of Limit',
rs.avg_log_write_percent AS 'Log Write Utilization In % of Limit'
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Weitere Beispiele für die Verwendung von sys.dm_db_resource_stats finden Sie weiter unten in diesem Artikel im Abschnitt Überwachen der Ressourcennutzung .
Wenn das E/A-Limit erreicht ist, haben Sie zwei Möglichkeiten:
- Upgrade der Computegröße oder Dienstebene
- Identifikation und Optimierung der Abfragen, die die meisten E/A-Ressourcen verbrauchen
Anzeigen von pufferbezogenen E/A-Vorgängen, die den Abfragespeicher verwenden
Um die wichtigsten Abfragen nach E/A-bezogenen Wartezeiten zu ermitteln, können Sie die folgende Abfrage im Abfragespeicher verwenden, um die letzten zwei Stunden der überwachten Aktivität anzuzeigen:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Sie können auch die Ansicht sys.query_store_runtime_stats verwenden und sich dabei auf die Abfragen mit großen Werten in den Spalten avg_physical_io_reads und avg_num_physical_io_reads konzentrieren.
Anzeigen sämtlicher E/A-Vorgänge für WRITELOG-Wartevorgänge
Wenn der Wartetyp WRITELOG ist, verwenden Sie die folgende Abfrage, um sämtliche Protokoll-E/A-Vorgänge nach Anweisung anzuzeigen:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identifizieren von tempdb-Leistungsproblemen
Die häufigsten Wartetypen in Zusammenhang mit tempdb-Problemen sind PAGELATCH_* (nicht PAGEIOLATCH_*). Waits bedeutet jedoch nicht immer, PAGELATCH_* dass Sie über einen Streit verfügen tempdb . Diese Wartezeit kann auch bedeuten, dass Sie aufgrund gleichzeitiger Anforderungen, die auf dieselbe Datenseite abzielen, einen Benutzerobjektdatenseitenkonflikt haben. Zur genaueren Ermittlung, ob es sich um einen tempdb-Konflikt handelt, verwenden Sie sys.dm_exec_requests, um zu bestätigen, dass der Wert von wait_resource mit 2:x:y beginnt, wobei „2“ die tempdb-Datenbank-ID, x die Datei-ID und y die Seiten-ID ist.
Bei tempdb-Konflikten besteht eine gängige Methode darin, den Anwendungscode, der tempdb benötigt, zu reduzieren oder neu zu schreiben. In folgenden Bereichen wird tempdb meist genutzt:
- Temporäre Tabellen
- Tabellenvariablen
- Tabellenwertparameter
- Abfragen mit Abfrageplänen, die Sortiervorgänge, Hashjoins und Spoolvorgänge verwenden
Weitere Informationen finden Sie unter tempdb in Azure SQL.
Alle Datenbanken in einem Pool für elastische Datenbanken teilen dieselbe tempdb-Datenbank. Eine hohe tempdb Speicherplatznutzung durch eine Datenbank kann sich auf andere Datenbanken im gleichen Pool für elastische Datenbanken auswirken.
Häufige Abfragen, die Tabellenvariablen und temporäre Tabellen verwenden
Verwenden Sie die folgende Abfrage, um die häufigsten Abfragen zu identifizieren, die Tabellenvariablen und temporäre Tabellen verwenden:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identifizieren von Transaktionen mit langer Ausführungszeit
Verwenden Sie die folgende Abfrage, um Transaktionen mit langer Ausführungszeit zu identifizieren. Transaktionen mit langer Ausführungszeit verhindern das Bereinigen von persistenten Versionsspeichern (PVS). Weitere Informationen finden Sie unter Problembehandlung der beschleunigten Datenbankwiederherstellung.
SELECT DB_NAME(dtr.database_id) AS 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT OUTER JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT OUTER JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT OUTER JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identifizieren von Leistungsproblemen bei Wartevorgängen für Speicherzuweisung
Wenn der häufigste Wartetyp lautet RESOURCE_SEMAPHORE, liegt möglicherweise ein Speichererteilungsproblem vor, bei dem Abfragen erst ausgeführt werden können, wenn sie eine ausreichend große Speichererteilung erhalten.
Ermitteln Sie, ob RESOURCE_SEMAPHORE ein häufiger Wartetyp ist.
Verwenden Sie die folgende Abfrage, um zu ermitteln, ob ein RESOURCE_SEMAPHORE-Wartevorgang ein häufiger Wartevorgang ist. Indikativ wäre auch ein steigender Wartezeitrang von RESOURCE_SEMAPHORE im aktuellen Verlauf. Weitere Informationen zur Behandlung von Problemen mit wartenden Speicherzuweisungen finden Sie unter Behandeln von Problemen mit geringer Leistung oder geringem Arbeitsspeicher aufgrund von Speicherzuweisungen in SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Ermitteln von Anweisungen mit hohem Arbeitsspeicherverbrauch
Wenn in Azure SQL-Datenbank Fehler auftreten, weil nicht genügend Arbeitsspeicher vorhanden ist, finden Sie hilfreiche Informationen unter sys.dm_os_out_of_memory_events. Weitere Informationen finden Sie unter Problembehandlung bei Speichermangel-Fehlern mit Azure SQL-Datenbank und Fabric SQL-Datenbank.
Ändern Sie zunächst das folgende Skript, um die relevanten Werte von start_time und end_time zu aktualisieren. Verwenden Sie anschließend die folgende Abfrage, um Anweisungen mit hohem Arbeitsspeicherverbrauch zu identifizieren:
SELECT IDENTITY (INT, 1, 1) AS rowId,
CAST (query_plan AS XML) AS query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c))
SELECT TOP 50 cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST (SerialDesiredMemory / 1024. AS DECIMAL (10, 2)) AS SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identifizieren der 10 häufigsten aktiven Speicherzuweisungen
Verwenden Sie die folgende Abfrage, um die 10 häufigsten aktiven Speicherzuweisungen zu identifizieren:
SELECT TOP 10 CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN 'Yes'
WHEN 0 THEN 'No'
ELSE 'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Überwachen von Verbindungen
Sie können die Ansicht sys.dm_exec_connections zum Abrufen von Informationen über die Verbindungen verwenden, die mit einer bestimmten Datenbank hergestellt wurden, sowie von Details zu den einzelnen Verbindungen. Wenn sich eine Datenbank in einem Pool für elastische Datenbanken befindet und Sie über ausreichende Berechtigungen verfügen, gibt die Ansicht die Menge der Verbindungen für alle Datenbanken im Pool für elastische Datenbanken zurück. Darüber hinaus ist die Sicht sys.dm_exec_sessions für das Abrufen von Informationen zu allen aktiven Benutzerverbindungen und internen Aufgaben nützlich.
Anzeigen aktueller Sitzungen
Die folgende Abfrage ruft Informationen für Ihre aktuelle Verbindung und Sitzung ab. Um alle Sitzungen und Verbindungen anzuzeigen, entfernen Sie die WHERE-Klausel.
Sie sehen alle ausgeführten Sitzungen in der Datenbank nur, wenn Sie beim Ausführen der VIEW DATABASE STATE- und sys.dm_exec_requests-Ansichten die Berechtigung für die sys.dm_exec_sessions-Datenbank haben. Andernfalls sehen Sie nur die aktuelle Sitzung.
SELECT c.session_id,
c.net_transport,
c.encrypt_option,
c.auth_scheme,
s.host_name,
s.program_name,
s.client_interface_name,
s.login_name,
s.nt_domain,
s.nt_user_name,
s.original_login_name,
c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Überwachen der Abfrageleistung
Langsame Abfragen oder Abfragen mit langen Ausführungszeiten können beträchtliche Systemressourcen beanspruchen. In diesem Abschnitt wird veranschaulicht, wie mit dynamischen Verwaltungssichten häufig auftretende Leistungsprobleme bei Abfragen mithilfe der dynamischen Verwaltungssicht sys.dm_exec_query_stats ermittelt werden können. Diese Sicht enthält eine Zeile pro Abfrageanweisung innerhalb des zwischengespeicherten Plans, und die Lebensdauer der Zeilen ist an den Plan selbst gebunden. Wenn ein Plan aus dem Cache entfernt wird, werden die entsprechenden Zeilen aus dieser Sicht entfernt. Wenn eine Abfrage keinen zwischengespeicherten Plan hat, zum Beispiel, weil OPTION (RECOMPILE) verwendet wird, ist sie in den Ergebnissen dieser Ansicht nicht enthalten.
Ermitteln der häufigsten Abfragen nach CPU-Zeit
Das folgende Beispiel gibt Informationen über die 15 häufigsten Abfragen gemessen an durchschnittlicher CPU-Zeit pro Ausführung zurück. In diesem Beispiel werden die Abfragen entsprechend ihrem Abfragenhash zusammengefasst, sodass logisch äquivalente Abfragen nach ihrem kumulativen Ressourcenverbrauch gruppiert werden.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM (SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset / 2) + 1, (
(CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset) / 2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Überwachen von Abfrageplänen auf kumulative CPU-Zeit
Ein ineffizienter Abfrageplan kann auch den CPU-Verbrauch erhöhen. Im folgenden Beispiel wird ermittelt, welche Abfrage die meiste kumulierte CPU-Auslastung im aktuellen Verlauf benötigt.
SELECT highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM (SELECT TOP 15 qs.plan_handle,
qs.total_worker_time
FROM sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time DESC) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Überwachen blockierter Abfragen
Langsame Abfragen oder Abfragen mit langer Laufzeit können zu einer übermäßigen Ressourcennutzung beitragen und auf blockierte Abfragen zurückzuführen sein. Ursache für das Blockieren kann ein mangelhafter Anwendungsentwurf, fehlerhafte Abfragepläne oder ein Mangel an nützlichen Indizes usw. sein.
Informationen zur aktuellen Sperraktivität in der Datenbank können mithilfe der sys.dm_tran_locks-Sicht abgerufen werden. Beispielcode finden Sie unter sys.dm_tran_locks. Weitere Informationen zur Problembehandlung beim Blockieren finden Sie unter Verstehen und Beheben von Blockierungsproblemen.
Überwachen von Deadlocks
In einigen Fällen können sich zwei oder mehr Abfragen blockieren, was zu einem Deadlock führt.
Sie können eine Ablaufverfolgung für erweiterte Ereignisse erstellen, um Deadlock-Ereignisse zu erfassen, und dann verwandte Abfragen und ihre Ausführungspläne im Abfragespeicher suchen. Weitere Informationen finden Sie unter Analysieren und Verhindern von Deadlocks in Azure SQL-Datenbank und SQL-Datenbank in Fabric. Erfahren Sie mehr über Deadlocks in der Deadlocks-Anleitung.
Berechtigungen
In Azure SQL-Datenbank erfordert die Abfrage eines DMV möglicherweise je nach Berechnungsgröße, Bereitstellungsoption und den Daten im DMV entweder VIEW DATABASE STATEoder VIEW SERVER PERFORMANCE STATEoder VIEW SERVER SECURITY STATE Berechtigung. Die letzten beiden Berechtigungen sind in der VIEW SERVER STATE-Berechtigung enthalten. Anzeigen der Serverstatus-Berechtigungen werden über die Mitgliedschaft in den entsprechenden Serverrollen gewährt. Informationen dazu, welche Berechtigungen zum Abfragen eines bestimmten DMV erforderlich sind, finden Sie in den dynamischen Systemverwaltungsansichten und finden Sie den Artikel zur Beschreibung des DMV.
Um einem Datenbankbenutzer die VIEW DATABASE STATE-Berechtigung zu erteilen, führen Sie die folgende Abfrage aus, wobei database_user mit dem Namen des Benutzerprinzipals in der Datenbank ersetzt wird:
GRANT VIEW DATABASE STATE TO [database_user];
Um der ##MS_ServerStateReader##-Serverrolle die Mitgliedschaft für eine Anmeldung namens login_name zum logischen Server zu gewähren, stellen Sie eine Verbindung zur master-Datenbank her und führen Sie anschließend z. B. die folgende Abfrage aus:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Es kann ein paar Minuten dauern, bis die erteilte Genehmigung wirksam wird. Weitere Informationen finden Sie unter Beschränkungen von Rollen auf Serverebene.
Zugehöriger Inhalt
- Diagnostizieren und Behandeln von Problemen mit hoher CPU in Azure SQL-Datenbank und SQL-Datenbank in Microsoft Fabric
- Optimieren der Leistung von Anwendungen und Datenbanken in Azure SQL-Datenbank
- Verstehen und Beheben von Blockierungsproblemen
- Analysieren und Verhindern von Deadlocks in Azure SQL-Datenbank und SQL-Datenbank in Fabric
- Abfrageleistungserblick für Azure SQL-Datenbank
- sys.dm_db_resource_stats
- sys.resource_stats
- sys.dm_elastic_pool_resource_stats
- sys.elastic_pool_resource_stats