Mandantenübergreifende Berichte mithilfe verteilter Abfragen
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Tutorial führen Sie verteilte Abfragen für die gesamte Gruppe von Mandantendatenbanken zur Berichterstellung aus. Diese Abfragen können Einblicke geben, die sonst in den tagtäglichen operativen Daten der Wingtip Tickets SaaS-Mandanten verborgen bleiben. Dazu stellen Sie eine zusätzliche Berichtsdatenbank auf dem Katalogserver bereit und führen mit einer elastischen Abfrage verteilte Abfragen durch.
In diesem Tutorial lernen Sie Folgendes kennen:
- Bereitstellen einer Berichtsdatenbank
- Ausführen verteilter Abfragen für alle Mandantendatenbanken
- Möglichkeit effizienter mandantenübergreifender Abfragen durch globale Ansichten in jeder Datenbank
Stellen Sie zum Durchführen dieses Tutorials sicher, dass die folgenden Voraussetzungen erfüllt sind:
- Die SaaS-App Wingtip Tickets mit einer Datenbank pro Mandant ist bereitgestellt. Unter Bereitstellen und Untersuchen der SaaS-App Wingtip Tickets mit einer Datenbank pro Mandant finden Sie Informationen dazu, wie Sie die App in weniger als fünf Minuten bereitstellen.
- Azure PowerShell wurde installiert. Weitere Informationen hierzu finden Sie unter Erste Schritte mit Azure PowerShell.
- SQL Server Management Studio (SSMS) muss installiert sein. Sie können SSMS unter Herunterladen von SQL Server Management Studio (SSMS) herunterladen und installieren.
Mandantenübergreifendes Berichterstellungsmuster
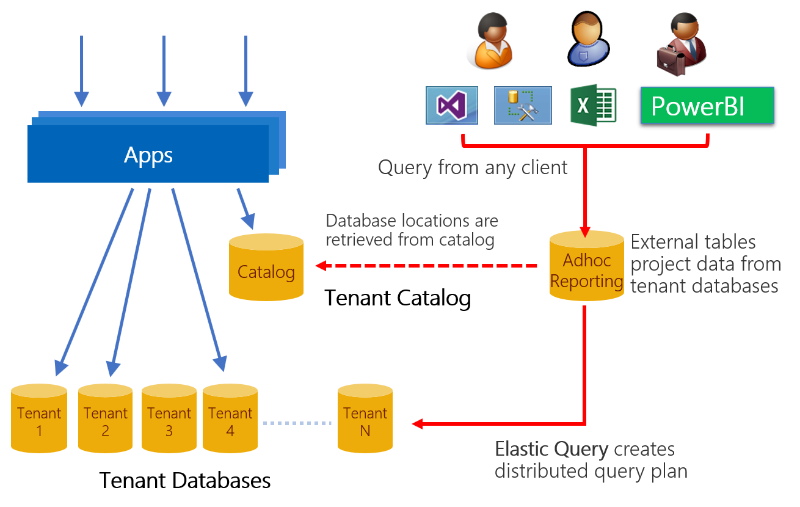
Ein Vorteil von SaaS-Anwendungen ist die Verwendung der riesigen Menge von in der Cloud gespeicherten Mandantendaten, um Einblick in den Betrieb und die Verwendung Ihrer Anwendung zu erhalten. An diesen gewonnenen Erkenntnissen können Sie sich bei der Entwicklung von Funktionen, Verbesserungen der Benutzerfreundlichkeit und anderen Investitionen in Ihre Apps und Dienste orientieren.
Es ist einfach, auf diese Daten in einer Datenbank mit mehreren Mandanten zuzugreifen, aber weniger einfach bei einer Verteilung über potentiell Tausende von Datenbanken. Ein Ansatz besteht in der Verwendung von Elastic Query, wodurch Abfragen für einen verteilten Satz von Datenbanken mit gemeinsamem Schema ermöglicht werden. Diese Datenbanken können auf verschiedene Ressourcengruppen und Abonnements verteilt werden, müssen jedoch dieselbe Anmeldung durchführen. Flexible Abfragen verwenden eine einzige Hauptdatenbank, in der externe Tabellen definiert werden, die Tabellen oder Sichten in den verteilten Datenbanken (Mandantendatenbanken) spiegeln. Abfragen, die an diese Hauptdatenbank übermittelt werden, werden kompiliert, um einen Plan der verteilten Abfrage zu erzeugen, bei dem Teile der Abfrage nach Bedarf per Push an die Mandantendatenbanken übertragen werden. Elastische Abfragen verwenden die Shardzuordnung in der Katalogdatenbank, um den Speicherort aller Mandantendatenbanken festzulegen. Für Setup und Abfragen der Hauptdatenbank wird einfach gewöhnlicher Transact-SQL-Code verwendet, und Abfragen von Tools wie Power BI und Excel werden unterstützt.
Durch das Verteilen von Abfragen über Mandantendatenbanken bietet Elastic Query schnellen Einblick in Liveproduktionsdaten. Dadurch, dass elastische Abfragen möglicherweise Daten aus vielen Datenbanken abrufen, kann die Abfragewartezeit länger sein als bei entsprechenden Abfragen, die an eine einzelne Datenbank mit mehreren Mandanten übermittelt werden. Entwerfen Sie Abfragen so, dass ein Minimum von Daten an die Hauptdatenbank zurückgegeben wird. Elastic Query ist häufig optimal für das Abfragen kleiner Mengen von Echtzeitdaten und weniger für das Erstellen von häufig verwendeten oder komplexen Analyseabfragen oder -berichten. Wenn Abfragen nicht optimal ausgeführt werden, schauen Sie sich den Ausführungsplan an, um zu sehen, welcher Teil der Abfrage per Push an die Remotedatenbank übertragen wird und wie viele Daten zurückgegeben werden. Abfragen, die eine komplexe Aggregation oder analytische Verarbeitung erfordern, können möglicherweise besser gehandhabt werden, indem Mandantendaten in eine Datenbank oder ein Data Warehouse extrahiert werden, die bzw. das für Analyseabfragen optimiert ist. Dieses Muster wird im Tutorial zu Mandantenanalysen erklärt.
Abrufen der Skripts zur SaaS-Anwendung Wingtip Tickets mit einer Datenbank pro Mandant
Die Skripts und der Anwendungsquellcode der mehrinstanzenfähigen Wingtip Tickets-SaaS-Datenbank stehen im GitHub-Repository WingtipTicketsSaaS-DbPerTenant zur Verfügung. Schritte zum Herunterladen und Entsperren der Wingtip Tickets-SaaS-Skripts finden Sie unter General guidance for working with Wingtip Tickets sample SaaS apps (Allgemeine Hinweise zur Verwendung von Wingtip Tickets-Beispiel-SaaS-Apps).
Erstellen von Ticketverkaufsdaten
Um Abfragen mit einem interessanteren Dataset auszuführen, erstellen Sie Ticketverkaufsdaten mit dem Ticketgenerator.
- Öffnen Sie in der PowerShell ISE das Skript „...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReporting.ps1“, und legen Sie den folgenden Wert fest:
- $DemoScenario = 1, Tickets für Events an allen Veranstaltungsorten kaufen.
- Drücken Sie F5, um das Skript auszuführen und Ticketverkaufsdaten zu generieren. Während das Skript ausgeführt wird, können Sie die nächsten Schritte des Tutorials ausführen. Sie können die Ticketdaten im Abschnitt Ausführen von verteilten Ad-hoc-Abfragen abfragen. Warten Sie zunächst, bis der Ticketgenerator abgeschlossen wurde.
Untersuchen der globalen Sichten
In der SaaS-Anwendung Wingtip Tickets mit einer Datenbank pro Mandant ist jedem Mandanten eine Datenbank zugeordnet. Die in den Datenbanktabellen enthaltenen Daten sind somit auf die Perspektive eines einzelnen Mandanten ausgerichtet. Wenn Sie alle Datenbanken abfragen, ist es wichtig, dass Elastic Query die Daten so behandeln kann, als seinen Sie Teil einer einzigen logischen Datenbank, die vom Mandanten freigegeben wurde.
Dieses Muster können Sie simulieren, indem Sie einen Satz von „globalen“ Ansichten der Mandantendatenbank hinzufügen, die eine Mandanten-ID in jede der global abgefragten Tabellen projizieren. Beispielsweise fügt die Ansicht VenueEvents eine berechnete VenueId in den Spalten ein, die von der Tabelle Events projiziert wurden. Auf ähnliche Weise fügen die Ansichten VenueTicketPurchases und VenueTickets eine berechnete VenueId-Spalte hinzu, die aus ihren jeweiligen Tabellen projiziert wird. Diese Ansichten werden von der elastischen Abfrage verwendet, um Abfragen zu parallelisieren und bei Vorhandensein einer VenueId-Spalte in die entsprechende Remotemandantendatenbank zu verschieben. Dadurch wird die Menge an zurückgegebenen Daten deutlich verringert und die Leistung von vielen Abfragen wesentlich gesteigert. Diese globalen Ansichten wurden in allen Mandantendatenbanken vorab erstellt.
Öffnen Sie SSMS, und stellen Sie eine Verbindung mit dem Server „tenants1-<BENUTZER>“ her.
Erweitern Sie die Option Datenbanken, klicken Sie mit der rechten Maustaste auf contosoconcerthall, und wählen Sie Neue Abfrage.
Führen Sie die folgenden Abfragen aus, um den Unterschied zwischen den Tabellen mit einem einzelnen Mandanten und den globalen Sichten zu untersuchen:
-- The base Venue table, that has no VenueId associated. SELECT * FROM Venue -- Notice the plural name 'Venues'. This view projects a VenueId column. SELECT * FROM Venues -- The base Events table, which has no VenueId column. SELECT * FROM Events -- This view projects the VenueId retrieved from the Venues table. SELECT * FROM VenueEvents
In diesen Ansichten wurde VenueId als Hash des Veranstaltungsorts berechnet. Für die Einführung eines eindeutigen Werts kann jedoch jeder Ansatz verwendet werden. Dieser Ansatz ähnelt der Berechnung des Mandantenschlüssels zur Verwendung im Katalog.
So können Sie die Definition der Ansicht Venues untersuchen:
Erweitern Sie im Objekt-Explorer die Option contosoconcerthall>Sichten:
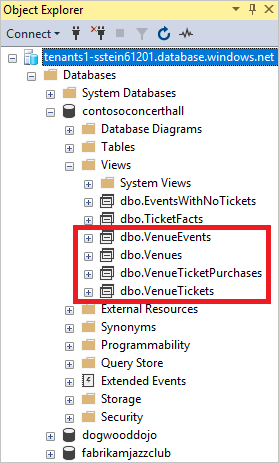
Klicken Sie mit der rechten Maustaste auf dbo.Venues.
Wählen Sie Skript für Sicht als>CREATE in>Neues Abfrage-Editor-Fenster.
Skripten Sie jede beliebige Venue-Ansicht, um zu sehen, wie die VenueId hinzugefügt wird.
Bereitstellen der für verteilte Abfragen verwendeten Datenbank
In dieser Übung wird die Datenbank adhocreporting bereitgestellt. Dies ist die Hauptdatenbank, die das Schema enthält, das zum Abfragen aller Mandantendatenbanken verwendet wird. Die Datenbank wird auf dem vorhandenen Katalogserver bereitgestellt. Dies ist der Server, der für alle verwaltungsbezogenen Datenbanken in der Beispielanwendung verwendet wird.
Öffnen Sie in der PowerShell ISE „...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReporting.ps1“.
Legen Sie $DemoScenario = 2, Ad-hoc-Berichtsdatenbank bereitstellen fest.
Drücken Sie F5, um das Skript auszuführen und die Datenbank adhocreporting zu erstellen.
Im nächsten Abschnitt fügen Sie das Schema in der Datenbank hinzu, damit es zum Ausführen von verteilten Abfragen verwendet werden kann.
Konfigurieren der Hauptdatenbank für verteilte Abfragen
In dieser Übung wird ein Schema (die externe Datenquelle und die externen Tabellendefinitionen) in die Datenbank adhocreporting eingefügt, um die Abfrage aller Mandantendatenbanken zu ermöglichen.
Öffnen Sie SQL Server Management Studio, und stellen Sie eine Verbindung mit der Ad-hoc-Berichtsdatenbank her, die Sie im vorherigen Schritt erstellt haben. Der Name der Datenbank lautet adhocreporting.
Öffnen Sie ...\Learning Modules\Operational Analytics\Adhoc Reporting\ Initialize-AdhocReportingDB.sql in SSMS.
Überprüfen Sie das SQL-Skript, und achten Sie auf Folgendes:
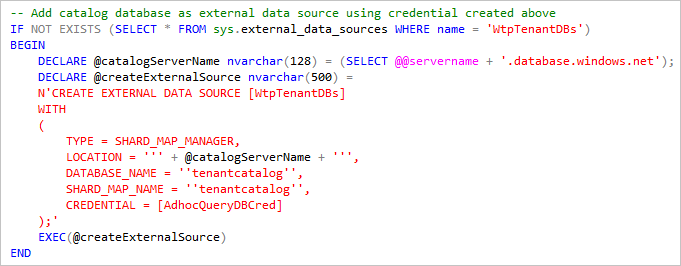
Für die elastische Abfrage werden datenbankbezogene Anmeldeinformationen verwendet, um auf die einzelnen Mandantendatenbanken zuzugreifen. Diese Anmeldeinformationen müssen in allen Datenbanken verfügbar sein, und im Normalfall sollten die Rechte gewährt werden, die zum Aktivieren dieser Abfragen mindestens erforderlich sind.

Mit der Katalogdatenbank als externer Datenquelle werden Abfragen auf alle Datenbanken verteilt, die bei Ausführung der Abfrage im Katalog registriert sind. Da sich Servernamen bei jeder Bereitstellung unterscheiden, ruft dieses Skript den Speicherort der Katalogdatenbank vom aktuellen Server (@@servername) ab, auf dem das Skript ausgeführt wird.
Die externen Tabellen, die auf die globalen Sichten aus dem vorherigen Abschnitt verweisen, und die mit DISTRIBUTION = SHARDED(VenueId) definiert werden. Da jeder VenueId-Wert auf eine einzelne Datenbank verweist, wird so die Leistung in vielen Szenarios verbessert, wie im nächsten Abschnitt gezeigt.
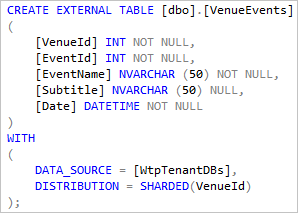
Die lokale Tabelle VenueTypes, die erstellt und mit Daten gefüllt wird. Diese Verweisdatentabelle kommt in allen Mandantendatenbanken vor. Daher kann sie hier als lokale Tabelle dargestellt werden, die mit den gemeinsamen Daten aufgefüllt ist. Bei einigen Abfragen kann durch eine Definition dieser Tabelle in der Hauptdatenbank die Datenmenge verringert werden, die in die Hauptdatenbank verschoben werden muss.
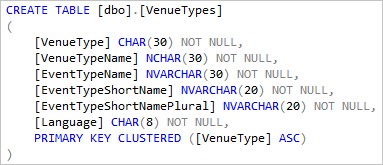
Wenn Sie so Verweistabellen einbeziehen, achten Sie darauf, dass Sie das Tabellenschema und die Tabellendaten aktualisieren, immer wenn Sie die Mandantendatenbank aktualisieren.
Drücken Sie F5, um das Skript auszuführen und die Datenbank adhocreporting zu initialisieren.
Jetzt können Sie verteilte Abfragen ausführen und Einblicke in alle Mandanten erhalten.
Ausführen von verteilten Abfragen
Jetzt wo die Datenbank adhocreporting eingerichtet ist, können Sie testweise einige verteilte Abfragen ausführen. Ziehen Sie den Ausführungsplan mit ein, um einen besseren Überblick zu haben, wo die Verarbeitung von Abfragen stattfindet.
Um ausführlichere Informationen zu erhalten, können Sie im Ausführungsplan auf die Plansymbole zeigen.
Beachten Sie, dass durch das Festlegen von DISTRIBUTION = SHARDED(VenueId) beim Definieren der externen Datenquelle die Leistung für viele Szenarios verbessert wird. Da jeder VenueId-Wert auf eine einzelne Datenbank verweist, können Sie leicht remote filtern und nur die benötigten Daten zurückgeben.
Öffnen Sie „...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReportingQueries.sql“ in SSMS.
Stellen Sie sicher, dass Sie mit der Datenbank adhocreporting verbunden sind.
Klicken Sie auf das Menü Abfrage und dann auf Include Actual Execution Plan (Tatsächlichen Ausführungsplan einschließen).
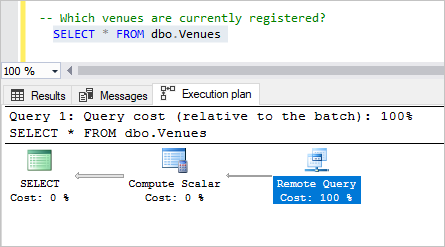
Markieren Sie die Abfrage Which venues are currently registered? (Welche Veranstaltungsorte sind aktuell registriert?), und drücken Sie F5.
Die Abfrage gibt die gesamte Liste an Veranstaltungsorten zurück. Dies zeigt, wie schnell und unkompliziert Sie alle Mandanten abfragen und Daten jedes Mandanten zurückgeben können.
Sehen Sie sich den Plan an, und beachten Sie, dass die Gesamtkosten in der Remoteabfrage enthalten sind. Jede Mandantendatenbank führt die Abfrage remote aus und gibt die jeweiligen Informationen zum Veranstaltungsort an die Hauptdatenbank zurück.
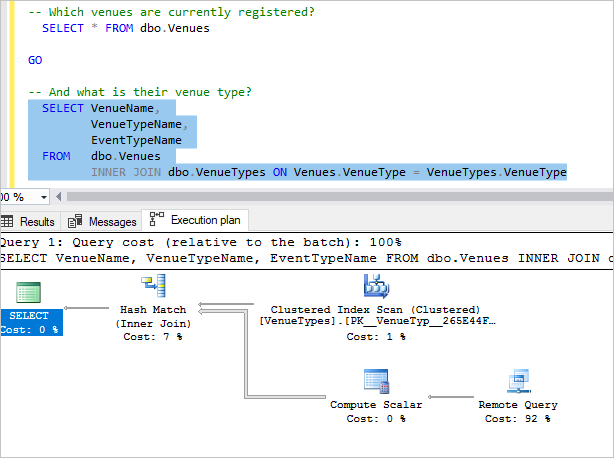
Wählen Sie die nächste Abfrage aus, und drücken Sie F5.
Diese Abfrage verknüpft Daten der Mandantendatenbank mit Daten der lokalen VenueTypes-Tabelle (lokal, da es sich dabei um eine Tabelle in der Datenbank adhocreporting handelt).
Sehen Sie sich den Plan an, und beachten Sie dass der Großteil der Kosten für die Remoteabfrage anfällt. Jede Mandantendatenbank gibt ihre Informationen zum Veranstaltungsort zurück und führt eine lokale Verknüpfung mit der lokalen VenueTypes-Tabelle durch, um den Anzeigenamen anzuzeigen.
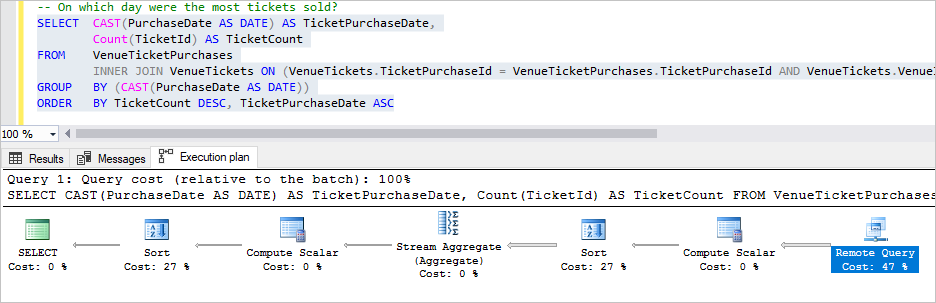
Wählen Sie nun die Abfrage On which day were the most tickets sold? (An welchem Tag wurden die meisten Tickets verkauft?) aus, und drücken Sie F5.
Diese Abfrage führt etwas komplexere Verknüpfungen und Aggregationen durch. Der Großteil der Verarbeitung erfolgt remote. Nur einzelne Zeilen mit den Ticketverkaufszahlen pro Tag für jeden Veranstaltungsort werden an die Hauptdatenbank zurückgegeben.
Nächste Schritte
In diesem Tutorial haben Sie Folgendes gelernt:
- Ausführen verteilter Abfragen für alle Mandantendatenbanken
- Bereitstellen einer Berichtsdatenbank und Definieren des Schemas, das zum Ausführen verteilter Abfragen erforderlich ist
Probieren Sie das Tutorial zu Mandantenanalysen aus, um sich mit dem Extrahieren von Daten in eine separate Analysedatenbank für komplexere Analyseverarbeitungen vertraut zu machen.