Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Wichtig
SQL-Datensynchronisierung wird am 30. September 2027 ausgemustert. Erwägen Sie die Migration zu alternativen Datenreplikations-/Synchronisierungslösungen.
Synchronisieren von Daten mit SQL Server-Datenbanken durch die Installation und Konfiguration des Datensynchronisierungs-Agents für die SQL-Datensynchronisierung in Azure. Weitere Informationen zur SQL-Datensynchronisierung finden Sie unter Was ist die SQL-Datensynchronisierung für Azure?
Azure SQL Managed Instance oder Azure Synapse Analytics werden nicht von SQL-Datensynchronisierung unterstützt.
Herunterladen und installieren
Achtung
Erwägen Sie die Migration zu alternativen Datenreplikations-/Synchronisierungslösungen.
Sie können den Datensynchronisierungs-Agent hier herunterladen. Um den Data Sync Agent zu aktualisieren, installieren Sie den Agent am selben Speicherort wie der alte Agent. Dadurch wird der ursprüngliche Agent überschrieben.
Unbeaufsichtigtes Installieren
Geben Sie für die unbeaufsichtigte Installation des Datensynchronisierungs-Agents an der Eingabeaufforderung einen Befehl wie im folgenden Beispiel ein. Überprüfen Sie den Dateinamen der heruntergeladenen MSI-Datei, und geben Sie Ihre eigenen Werte für die Argumente TARGETDIR und SERVICEACCOUNT an.
Wenn Sie für TARGETDIR keinen Wert angeben, lautet der Standardwert
C:\Program Files (x86)\Microsoft SQL Data Sync 2.0.Wenn Sie
LocalSystemals Wert für SERVICEACCOUNT angeben, sollten Sie beim Konfigurieren des Agents für die Verbindung mit der SQL Server-Instanz die SQL Server-Authentifizierung verwenden.Wenn Sie ein Domänenbenutzerkonto oder ein lokales Benutzerkonto als Wert für SERVICEACCOUNT angeben, müssen Sie auch das Kennwort mit dem Argument SERVICEPASSWORD angeben. Beispiel:
SERVICEACCOUNT="<domain>\<user>" SERVICEPASSWORD="<password>".
msiexec /i "SQLDataSyncAgent-2.0-x86-ENU.msi" TARGETDIR="C:\Program Files (x86)\Microsoft SQL Data Sync 2.0" SERVICEACCOUNT="LocalSystem" /qn
Synchronisieren von Daten mit einer SQL Server-Datenbank
Informationen zum Konfigurieren des Datensynchronisierungs-Agents zum Synchronisieren von Daten mit einer oder mehreren SQL Server-Datenbanken finden Sie unter Hinzufügen einer SQL Server-Datenbank.
Unterstützung für lokale SQL Server-Versionen
Nur die folgenden versionen von SQL Server lokal können Teil einer Synchronisierungsgruppe sein:
- SQL Server 2008
- SQL Server 2008 R2
- SQL Server 2012
- SQL Server 2016
- SQL Server 2017 unter Windows
- SQL Server 2019 unter Windows
- SQL Server 2022 unter Windows
Häufig gestellte Fragen zum Datensynchronisierungs-Agent
Wozu benötige ich einen Client-Agent?
Der Dienst der SQL-Datensynchronisierung kommuniziert über den Client-Agent mit SQL Server-Datenbanken. Diese Sicherheitsfunktion verhindert die direkte Kommunikation mit Datenbanken hinter einer Firewall. Bei der Kommunikation des Diensts der SQL-Datensynchronisierung mit dem Agent werden verschlüsselte Verbindungen und ein eindeutiges Token bzw. ein eindeutiger Agent-Schlüssel verwendet. Die SQL Server-Datenbanken authentifizieren den Agent mit der Verbindungszeichenfolge und dem Agent-Schlüssel. Diese Vorgehensweise bietet ein hohes Maß an Sicherheit für Ihre Daten.
Wie viele Instanzen der lokalen Agent-Benutzeroberfläche können ausgeführt werden?
Es kann nur eine Instanz der Benutzeroberfläche ausgeführt werden.
Wie kann ich mein Dienstkonto ändern?
Nach der Installation eines Client-Agents besteht die einzige Möglichkeit zum Ändern des Dienstkontos darin, ihn zu deinstallieren und einen neuen Client-Agent mit dem neuen Dienstkonto zu installieren.
Wie ändere ich meinen Agent-Schlüssel?
Ein Agent-Schlüssel kann nur einmal von einem Agent verwendet werden. Er kann nicht wiederverwendet werden, wenn Sie einen Agent entfernen und dann einen neuen Agent installieren, und er kann nicht von mehreren Agents verwendet werden. Wenn Sie einen neuen Schlüssel für einen vorhandenen Agent erstellen müssen, müssen Sie sicherstellen, dass derselbe Schlüssel beim Client-Agent und beim Dienst der SQL-Datensynchronisierung hinterlegt wird.
Wie stelle ich einen Client-Agenten außer Dienst?
Wenn Sie einen Agent umgehend für ungültig erklären oder außer Kraft setzen möchten, generieren Sie erneut seinen Schlüssel im Portal, übergeben ihn jedoch nicht an die Agent-Benutzeroberfläche. Durch das erneute Generieren eines Schlüssels wird der vorherige Schlüssel ungültig gemacht – unabhängig davon, ob der entsprechende Agent online oder offline ist.
Wie verschiebe ich einen Client-Agent auf einen anderen Computer?
Wenn Sie den lokalen Agent auf einem anderen Computer als dem ausführen möchten, auf dem er sich gerade befindet, und wieder denselben Agent verwenden möchten, gehen Sie wie folgt vor:
- Installieren Sie den Agent auf dem gewünschten Computer.
- Melden Sie sich beim Portal der SQL-Datensynchronisierung an, und generieren Sie erneut einen Agent-Schlüssel für den vorhandenen Agent.
- Übergeben Sie den Agent-Schlüssel über die Benutzeroberfläche des neuen Agents.
- Warten Sie, während der Client-Agent die Liste der zuvor registrierten lokalen Datenbanken herunterlädt.
- Geben Sie Datenbankanmeldeinformationen für alle Datenbanken ein, die als nicht erreichbar angezeigt werden. Diese Datenbanken müssen auf dem neuen Computer erreichbar sein, auf denen der Agent installiert ist.
Wie lösche ich die Synchronisierungsmetadaten-Datenbank, wenn der Synchronisierungs-Agent ihr noch zugeordnet ist?
Um eine Synchronisierungsmetadatendatenbank zu löschen, der ein Synchronisierungs-Agent zugeordnet ist, müssen Sie zuerst den Synchronisierungs-Agent löschen. Gehen Sie zum Löschen des Agents wie folgt vor:
- Wählen Sie die Datenbank "Sync" aus.
- Wechseln Sie zur Seite Mit anderen Datenbanken synchronisieren.
- Wählen Sie den Synchronisierungs-Agent und dann Löschen aus.
Beheben von Problemen mit dem Datensynchronisierungs-Agent
Der Client-Agent kann nicht installiert, deinstalliert oder repariert werden.
Der Client-Agent funktioniert nach dem Abbrechen der Deinstallation nicht mehr.
Der Clientagent kann nicht installiert, deinstalliert oder repariert werden
Ursache. Viele Szenarien können diesen Fehler verursachen. Um die genaue Ursache für diesen Fehler zu ermitteln, sehen Sie sich die Protokolle an.
Lösung. Generieren Sie die Windows Installer-Protokolle, und untersuchen Sie diese, um die genaue Fehlerursache zu finden. Sie können die Protokollierung über eine Eingabeaufforderung aktivieren. Wenn Sie beispielsweise
SQLDataSyncAgent-2.0-x86-ENU.msials Installationsdatei heruntergeladen haben, generieren und untersuchen Sie die Protokolldateien mithilfe der folgenden Befehlszeilen:Für Installationen:
msiexec.exe /i SQLDataSyncAgent-2.0-x86-ENU.msi /l*v LocalAgentSetup.LogFür Deinstallationen:
msiexec.exe /x SQLDataSyncAgent-2.0-x86-ENU.msi /l*v LocalAgentSetup.LogSie können die Protokollierung auch für alle mit Windows Installer durchgeführten Installationen aktivieren. Im Microsoft Knowledge Base-Artikel Aktivieren der Windows Installer-Protokollierung erfahren Sie, wie Sie die Protokollierung für Windows Installer mit nur einem Klick aktivieren. Dort finden Sie auch Informationen zum Speicherort der Protokolle.
Der Client-Agent funktioniert nach dem Abbrechen der Deinstallation nicht mehr.
Der Client-Agent funktioniert nicht mehr, auch nachdem Sie die Deinstallation abgebrochen haben.
Ursache. Dieses Problem tritt auf, weil der Client-Agent der SQL-Datensynchronisierung keine Anmeldeinformationen speichert.
Lösung. Sie können die folgenden beiden Lösungen ausprobieren:
- Verwenden Sie „services.msc“, um die Anmeldeinformationen für den Client-Agent erneut einzugeben.
- Deinstallieren Sie den Client-Agent, und installieren Sie einen neuen. Den neuesten Client-Agent können Sie aus dem Download Center herunterladen und installieren.
Meine Datenbank ist in der Agent-Liste nicht enthalten.
Wenn Sie versuchen, einer Synchronisierungsgruppe eine bereits vorhandene SQL Server-Datenbank hinzuzufügen, wird die Datenbank nicht in der Agent-Liste angezeigt.
Folgende Szenarien können diesen Fehler verursachen:
Ursache. Client-Agent und Synchronisierungsgruppe befinden sich in unterschiedlichen Rechenzentren.
Lösung. Der Client-Agent und die Synchronisierungsgruppe müssen sich im gleichen Rechenzentrum befinden. Hierfür stehen Ihnen zwei Möglichkeiten zur Verfügung:
- Erstellen Sie einen neuen Agent in dem Rechenzentrum, in dem sich die Synchronisierungsgruppe befindet. Registrieren Sie anschließend die Datenbank bei diesem Agent.
- Löschen Sie die aktuelle Synchronisierungsgruppe, Erstellen Sie die Synchronisierungsgruppe dann in dem Rechenzentrum neu, in dem sich der Agent befindet.
Ursache. Die Datenbankliste des Client-Agents ist nicht auf dem neuesten Stand.
Lösung. Beenden Sie den Client-Agent-Dienst, und starten Sie ihn neu.
Der lokale Agent lädt die Liste mit den zugeordneten Datenbanken nur bei der ersten Übermittlung des Agent-Schlüssels herunter. Es lädt die Liste der zugehörigen Datenbanken bei nachfolgenden Agentenschlüssel-Einsendungen nicht herunter. Daher werden Datenbanken, die während der Verschiebung eines Agents registriert wurden, in der ursprünglichen Agent-Instanz nicht angezeigt.
Der Client-Agent startet nicht. (Fehler 1069)
Sie stellen fest, dass der Agent auf einem Computer, der SQL Server hostet, nicht ausgeführt wird. Wenn Sie versuchen, den Agent manuell zu starten, wird ein Dialogfeld mit folgender Fehlermeldung angezeigt: „Fehler 1069: Der Dienst wurde aufgrund eines Anmeldefehlers nicht gestartet.“
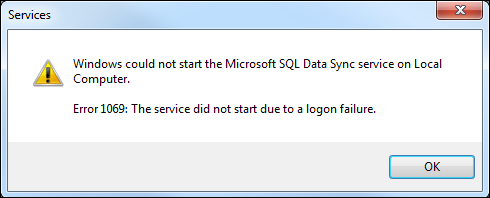
Ursache. Eine wahrscheinliche Ursache für diesen Fehler ist, dass sich das Kennwort auf dem lokalen Server geändert hat, seit Sie den Agent und das Agent-Kennwort erstellt haben.
Lösung. Legen Sie das Kennwort des Agents auf Ihr aktuelles Serverkennwort fest:
- Suchen Sie den Client-Agent-Dienst für die SQL-Datensynchronisierung.
a. Wählen Sie Starten aus.
b. Geben Sie services.msc in das Suchfeld ein.
c. Klicken Sie in den Suchergebnissen auf Dienste.
d. Scrollen Sie im Fenster Dienste zum Eintrag für den SQL-Datensynchronisierungs-Agent. - Klicken Sie mit der rechten Maustaste auf SQL-Datensynchronisierungs-Agent, und wählen Sie Beenden aus.
- Klicken Sie mit der rechten Maustaste auf SQL-Datensynchronisierungs-Agent, und wählen Sie Eigenschaften aus.
- Klicken Sie im Fenster Eigenschaften des SQL-Datensynchronisierungs-Agents auf die Registerkarte Anmelden.
- Geben Sie Ihr Kennwort in das Textfeld Kennwort ein.
- Geben Sie das Kennwort im Feld Kennwort bestätigen noch einmal ein.
- Klicken Sie auf Apply (Anwenden) und dann auf OK.
- Klicken Sie im Fenster Dienste mit der rechten Maustaste auf den Dienst SQL-Datensynchronisierungs-Agent, und wählen Sie dann Starten aus.
- Schließen Sie das Fenster Dienste.
- Suchen Sie den Client-Agent-Dienst für die SQL-Datensynchronisierung.
Ich kann den Agent-Schlüssel nicht übermitteln.
Nachdem Sie einen Schlüssel für einen Agenten erstellt oder neu erstellt haben, versuchen Sie, ihn mit der SqlAzureDataSyncAgent-Anwendung zu übermitteln. Die Übermittlung kann nicht abgeschlossen werden.
Voraussetzungen Bevor Sie fortfahren, überprüfen Sie die folgenden Voraussetzungen:
Der Windows-Dienst für SQL-Datensynchronisierung läuft.
Das Dienstkonto für den Windows-Dienst „SQL-Datensynchronisierung“ verfügt über Netzwerkzugriff.
Der ausgehende Port 1433 ist in Ihrer lokalen Firewallregel geöffnet.
Die lokale IP-Adresse wird der Firewallregel des Servers oder der Datenbank für die Datenbank für Synchronisierungsmetadaten hinzugefügt.
Ursache. Durch den Agent-Schlüssel wird jeder lokale Agent eindeutig identifiziert. Der Schlüssel muss zwei Bedingungen erfüllen:
- Der Client-Agent-Schlüssel auf dem Server für die SQL-Datensynchronisierung und dem lokalen Computer muss identisch sein.
- Der Client-Agent-Schlüssel kann nur einmal verwendet werden.
Lösung. Wenn Ihr Agent nicht funktioniert, liegt es daran, dass eine oder beide dieser Bedingungen nicht erfüllt sind. So beheben Sie das Problem mit dem Agent
- Generieren Sie einen neuen Schlüssel.
- Wenden Sie den neuen Schlüssel auf den Agent an.
So wenden Sie den neuen Schlüssel auf den Agent an:
- Wechseln Sie im Explorer zum Installationsverzeichnis Ihres Agents. Das Standardinstallationsverzeichnis lautet C:\Programme (x86)\Microsoft SQL Data Sync.
- Doppelklicken Sie auf das Unterverzeichnis „bin“.
- Öffnen Sie die SqlAzureDataSyncAgent-Anwendung.
- Klicken Sie auf Agent-Schlüssel übermitteln.
- Fügen Sie den Schlüssel aus der Zwischenablage in das dafür vorgesehene Feld ein.
- Klicken Sie auf OK.
- Schließen Sie das Programm.
Der Client-Agent kann nicht aus dem Portal gelöscht werden, wenn die zugeordnete lokale Datenbank nicht erreichbar ist.
Wenn ein lokaler, bei einem Client-Agent für die SQL-Datensynchronisierung registrierter Endpunkt (also eine Datenbank) nicht erreichbar ist, kann der Client-Agent nicht gelöscht werden.
Ursache. Der lokale Agent kann nicht gelöscht werden, da die nicht erreichbare Datenbank noch bei dem Agent registriert ist. Wenn Sie versuchen, den Agent zu löschen, versucht der Löschprozess erfolglos, die Datenbank zu erreichen.
Lösung. Verwenden Sie „force delete“, um die nicht erreichbare Datenbank zu löschen.
Hinweis
Wenn nach der Verwendung von „force delete“ Tabellen mit Synchronisierungsmetadaten zurückbleiben, verwenden Sie deprovisioningutil.exe, um diese zu bereinigen.
Die lokale Synchronisierungs-Agent-App kann keine Verbindung mit dem lokalen Synchronisierungsdienst herstellen.
Lösung. Probieren Sie die folgenden Schritte aus:
- Beenden Sie die App.
- Öffnen Sie den Bereich Komponentendienste.
a. Geben Sie services.msc in das Suchfeld der Taskleiste ein.
b. Doppelklicken Sie in den Suchergebnissen auf Dienste. - Beenden Sie den SQL-Datensynchronisierungsdienst.
- Starten Sie den SQL-Datensynchronisierungsdienst neu.
- Öffnen Sie die App erneut.
Führen Sie den Datensynchronisierungs-Agenten über die Eingabeaufforderung aus
Sie können die folgenden Befehle des Data Sync Agent an der Eingabeaufforderung ausführen:
Service anpingen
Verwendung
SqlDataSyncAgentCommand.exe -action pingsyncservice
Beispiel
SqlDataSyncAgentCommand.exe -action "pingsyncservice"
Anzeigen der registrierten Datenbanken
Verwendung
SqlDataSyncAgentCommand.exe -action displayregistereddatabases
Beispiel
SqlDataSyncAgentCommand.exe -action "displayregistereddatabases"
Übermitteln des Agent-Schlüssels
Verwendung
Usage: SqlDataSyncAgentCommand.exe -action submitagentkey -agentkey [agent key] -username [user name] -password [password]
Beispiel
SqlDataSyncAgentCommand.exe -action submitagentkey -agentkey [agent key generated from portal, PowerShell, or API] -username [user name to sync metadata database] -password [user name to sync metadata database]
Registrieren einer Datenbank
Verwendung
SqlDataSyncAgentCommand.exe -action registerdatabase -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name] -username [domain\\username] -password [password] -authentication [sql or windows] -encryption [true or false]
Beispiele
SqlDataSyncAgentCommand.exe -action "registerdatabase" -serverName localhost -databaseName testdb -authentication sql -username <user name> -password <password> -encryption true
SqlDataSyncAgentCommand.exe -action "registerdatabase" -serverName localhost -databaseName testdb -authentication windows -encryption true
Aufheben der Registrierung einer Datenbank
Wenn Sie diesen Befehl zum Aufheben der Registrierung einer Datenbank verwenden, wird die Bereitstellung der Datenbank vollständig aufgehoben. Wenn die Datenbank an anderen Synchronisierungsgruppen beteiligt ist, werden die anderen Synchronisierungsgruppen durch diesen Vorgang beschädigt.
Verwendung
SqlDataSyncAgentCommand.exe -action unregisterdatabase -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name]
Beispiel
SqlDataSyncAgentCommand.exe -action "unregisterdatabase" -serverName localhost -databaseName testdb
Anmeldeinformationen aktualisieren
Verwendung
SqlDataSyncAgentCommand.exe -action updatecredential -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name] -username [domain\\username] -password [password] -authentication [sql or windows] -encryption [true or false]
Beispiele
SqlDataSyncAgentCommand.exe -action "updatecredential" -serverName localhost -databaseName testdb -authentication sql -username <user name> -password <password> -encryption true
SqlDataSyncAgentCommand.exe -action "updatecredential" -serverName localhost -databaseName testdb -authentication windows -encryption true
Zugehöriger Inhalt
Weitere Informationen zur SQL-Datensynchronisierung finden Sie in den folgenden Artikeln:
- Übersicht: Synchronisieren von Daten über mehrere Cloud- und lokale Datenbanken mit SQL-Datensynchronisierung in Azure
- Einrichten der Datensynchronisierung
- Bewährte Methoden: Bewährte Methoden für die Azure SQL-Datensynchronisierung
- Überwachung: Überwachen der SQL-Datensynchronisierung mit Azure Monitor-Protokollen
- Problembehandlung: Behandeln von Problemen mit der Azure SQL-Datensynchronisierung