Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dieser Artikel bietet eine Übersicht über die Funktion der Failover-Gruppen und enthält bewährte Methoden sowie Empfehlungen für die Nutzung mit Azure SQL Managed Instance. Mit dem Feature "Failovergruppen" können Sie die Replikation und das Failover aller Benutzerdatenbanken in einer SQL-verwalteten Instanz in eine andere Azure-Region verwalten.
Informationen zu den ersten Schritten finden Sie unter Konfigurieren einer Failovergruppe für die verwaltete Azure SQL-Instanz.
Übersicht
Mit dem Feature "Failovergruppen" können Sie die Replikation und das Failover von Benutzerdatenbanken aus einer SQL-verwalteten Instanz in eine andere verwaltete SQL-Instanz in einer anderen Azure-Region verwalten. Failovergruppen wurden entwickelt, um die Bereitstellung und Verwaltung georeplizierter Datenbanken im großen Stil zu vereinfachen.
Weitere Informationen finden Sie unter Hochverfügbarkeit für Azure SQL Managed Instance. Informationen zu Geofailover-RPO und -RTO finden Sie unter Übersicht über die Geschäftskontinuität.
Endpunktumleitung
Failovergruppen stellen Listenerendpunkte mit Lese-/Schreibzugriff bereit sowie schreibgeschützte Listenerendpunkte, die während Geofailovers unverändert bleiben. Sie müssen die Verbindungszeichenfolge für Ihre Anwendung nach einem Geofailover nicht ändern, da die Verbindungen automatisch an das aktuelle primäre Replikat weitergeleitet werden. Sowohl bei manueller als auch automatischer Failover-Aktivierung schaltet das Geofailover alle sekundären Datenbanken in der Gruppe zur primären Rolle um. Nach Abschluss des Geofailovers wird der DNS-Eintrag automatisch aktualisiert, um die Endpunkte in die neue Region umzuleiten.
Auslagern schreibgeschützter Workloads
Um den Datenverkehr an Ihre primären Datenbanken zu verringern, können Sie zudem mithilfe der sekundären Datenbanken in einer Failovergruppe schreibgeschützte Workloads auslagern. Verwenden Sie den schreibgeschützten Listener, um schreibgeschützten Datenverkehr an eine lesbare sekundäre Datenbank weiterzuleiten.
Wiederherstellen einer Anwendung
Wenn Sie echte Geschäftskontinuität erreichen möchten, ist das Hinzufügen einer regionalen Datenbankredundanz nur ein Teil der Lösung. Für die komplette Wiederherstellung einer Anwendung bzw. eines Diensts nach einem schwerwiegenden Fehler ist das Wiederherstellen aller Komponenten erforderlich, aus denen sich der Dienst und alle abhängigen Dienste zusammensetzen. Beispiele dieser Komponenten sind die Clientsoftware (z. B. ein Browser mit benutzerdefiniertem JavaScript), Web-Front-Ends, Speicher und DNS. Es ist wichtig, dass alle Komponenten hinsichtlich derselben Fehler gegen Ausfälle geschützt und innerhalb des RTO (Recovery Time Objective) der Anwendung wieder verfügbar sind. Daher müssen Sie alle abhängigen Dienste bestimmen und mit dem Leistungsumfang und den Funktionen vertraut sein, die sie bieten. Dann müssen Sie entsprechende Maßnahmen ergreifen, um sicherzustellen, dass Ihr Dienst während des Failovers der Dienste funktioniert, von denen er abhängig ist.
Failover-Richtlinie
Failovergruppen unterstützen zwei Failover-Richtlinien:
-
Vom Kunden verwaltet (empfohlen) – Kunden können ein Failover einer Gruppe ausführen, wenn sie einen unerwarteten Ausfall bemerken, der sich auf eine oder mehrere Datenbanken in der Failover-Gruppe auswirkt. Bei Verwendung von Befehlszeilentools wie PowerShell, Azure CLI oder der Rest-API lautet der Wert der Failover-Richtlinie für den verwalteten Kunden
manual. -
Microsoft verwaltet – Im Falle eines weit verbreiteten Ausfalls, der sich auf eine primäre Region auswirkt, initiiert Microsoft ein Failover aller betroffenen Failovergruppen, für die ihre Failoverrichtlinie so konfiguriert ist, dass sie von Microsoft verwaltet wird. Von Microsoft verwaltetes Failover wird für einzelne Failovergruppen oder eine Teilmenge von Failovergruppen in einer Region nicht initiiert. Bei Verwendung von Befehlszeilentools wie PowerShell, Azure CLI oder der Rest-API lautet der Wert der Failoverrichtlinie für Microsoft-verwaltet
automatic.
Jede Failoverrichtlinie verfügt über einen eindeutigen Satz von Anwendungsfällen und entsprechenden Erwartungen an den Failoverumfang und Datenverlust, wie in der folgenden Tabelle zusammengefasst:
| Failover-Richtlinie | Failoverbereich | Anwendungsfall | Potenzieller Datenverlust |
|---|---|---|---|
| Vom Kunden verwaltet (Empfohlen) |
Failovergruppen | Eines oder mehrere Datenbanken in einer Failovergruppe sind von einem Ausfall betroffen und nicht verfügbar. Sie können auswählen, dass ein Fehler auftritt. | Ja |
| Von Microsoft verwaltet | Alle Failovergruppen in der Region | Ein weit verbreiteter Ausfall in einer Region führt zu einer Nichtverfügbarkeit von Datenbanken, und das Microsoft Azure SQL-Dienstteam entscheidet, ein erzwungenes Failover auszulösen. Verwenden Sie diese Option nur, wenn Sie die Verantwortung für die Notfallwiederherstellung an Microsoft delegieren möchten und die Anwendung auf RTO (Ausfallzeiten) von mindestens einer Stunde oder mehr tolerant ist. Das Failover, das von Microsoft verwaltet wird, wird möglicherweise nur unter extremen Umständen ausgeführt. Eine vom Kunden verwaltete Failoverrichtlinie wird dringend empfohlen. |
Ja |
Vom Kunden verwaltet
In seltenen Fällen reicht die integrierte Verfügbarkeit oder hohe Verfügbarkeit nicht aus, um einen Ausfall zu minimieren, und Ihre Datenbanken in einer Failovergruppe sind möglicherweise für eine Dauer nicht verfügbar, die für die Vereinbarung zum Servicelevel (Service Level Agreement, SLA) der Anwendungen, die die Datenbanken verwenden, nicht akzeptabel ist. Datenbanken können aufgrund eines lokalisierten Problems, das sich auf nur wenige Datenbanken auswirkt, nicht verfügbar sein, oder sie kann sich auf der Ebene des Rechenzentrums, der Verfügbarkeitszone oder der Region befinden. In jedem dieser Fälle können Sie zum Wiederherstellen der Geschäftskontinuität ein erzwungenes Failover initiieren.
Das Festlegen Ihrer Failoverrichtlinie auf vom Kunden verwaltete Kunden wird dringend empfohlen, da Sie die Kontrolle darüber behalten, wann sie ein Failover initiieren und die Geschäftskontinuität wiederherstellen möchten. Sie können ein Failover initiieren, wenn sie einen unerwarteten Ausfall bemerken, der sich auf eine oder mehrere Datenbanken in der Failovergruppe auswirkt.
Von Microsoft verwaltet
Mit einer von Microsoft verwalteten Failoverrichtlinie wird die Verantwortung für die Notfallwiederherstellung an den Azure SQL-Dienst delegiert. Damit der Azure SQL-Dienst ein erzwungenes Failover initiieren kann, müssen die folgenden Bedingungen erfüllt sein:
- Der Ausfall der Region aufgrund eines Naturkatastrophenereignisses, Konfigurationsänderungen, Softwarefehler oder Hardwarekomponentenfehler und viele Datenbanken in der Region sind betroffen.
- Die Karenzzeit ist abgelaufen. Da Maßnahmen ergriffen werden müssen, um das Ausmaß des Ausfalls zu überprüfen und festzustellen, wie schnell dieser minimiert werden kann, kann die Toleranzperiode nicht auf einen Wert unter einer Stunde festgelegt werden.
Wenn diese Bedingungen erfüllt sind, initiiert der Azure SQL-Dienst erzwungene Failovers für alle Failovergruppen in der Region, für die die Failoverrichtlinie auf Microsoft verwaltet wurde.
Wichtig
Verwenden Sie die vom Kunden verwaltete Failoverrichtlinie, um Ihren Notfallwiederherstellungsplan zu testen und zu implementieren. Verlassen Sie sich nicht auf das von Microsoft verwaltete Failover, da es von Microsoft nur in Extremsituationen vorgenommen wird. Ein von Microsoft verwaltetes Failover wird für alle Failovergruppen in der Region initiiert, für die ihre Failoverrichtlinie auf "Microsoft verwaltet" festgelegt ist. Es kann nicht für einzelne Failover-Gruppen gestartet werden. Wenn Sie Ihre Failovergruppe selektiv übertragen müssen, verwenden Sie die kundenspezifische Failoverrichtlinie.
Legen Sie die Failoverrichtlinie nur auf Microsoft fest, die verwaltet wird, wenn:
- Sie möchten die Verantwortung für die Notfallwiederherstellung an den Azure SQL-Dienst delegieren.
- Die Anwendung ist tolerant für Ihre Datenbank, die mindestens eine Stunde lang nicht verfügbar ist.
- Es ist akzeptabel, erzwungene Failover einige Zeit nach Ablauf der Nachfrist auszulösen, da die tatsächliche Zeit für das erzwungene Failover erheblich variieren kann.
- Es ist akzeptabel, dass alle Datenbanken innerhalb der Failovergruppe unabhängig vom Zonenredundanzkonfigurations- oder Verfügbarkeitsstatus fehlschlagen. Datenbanken, die für Zonenredundanz konfiguriert sind, sind zwar widerstandsfähig für Zonalfehler und sind möglicherweise nicht durch einen Ausfall betroffen, aber sie werden immer noch fehlgeschlagen, wenn sie Teil einer Failovergruppe mit einer von Microsoft verwalteten Failoverrichtlinie sind.
- Es ist akzeptabel, dass in der Failovergruppe Failovers von Datenbanken erzwungen werden, ohne die Abhängigkeit der Anwendung von anderen Azure-Diensten oder -Komponenten zu berücksichtigen, die von der Anwendung verwendet werden, was zu Leistungsbeeinträchtigungen oder Nichtverfügbarkeit der Anwendung führen kann.
- Es ist akzeptabel, eine unbekannte Menge an Datenverlust zu verursachen, da die genaue Zeit des erzwungenen Failovers nicht gesteuert werden kann, und ignoriert den Synchronisierungsstatus der sekundären Datenbanken.
- Die primären und sekundären Replikate in der Failovergruppe weisen die gleiche Dienstebene, Computeebene und Computegröße auf.
Wenn ein Failover von Microsoft ausgelöst wird, wird dem Azure Monitor-Aktivitätsprotokoll ein Eintrag für den Vorgangsnamen Failover Azure SQL-Failovergruppe hinzugefügt. Der Eintrag enthält den Namen der Failovergruppe unter "Ressource", und "Ereignis", das von einem einzelnen Bindestrich (-) initiiert wird, um anzugeben, dass das Failover von Microsoft initiiert wurde. Diese Informationen finden Sie auch auf der Seite "Aktivitätsprotokoll" des neuen primären Servers oder der neuen Instanz im Azure-Portal.
Terminologie und Funktionen
Failovergruppe
Eine Failovergruppe ermöglicht es allen Benutzerdatenbanken innerhalb einer SQL-verwalteten Instanz, einen Failover als Einheit für eine andere Azure-Region durchzuführen, falls die primäre verwaltete SQL-Instanz aufgrund eines Ausfalls einer primären Region nicht verfügbar ist. Da Failovergruppen für SQL Managed Instance alle Benutzerdatenbanken in der Instanz enthalten, kann nur eine Failovergruppe für eine Instanz konfiguriert werden.
Wichtig
Der Name der Failovergruppe muss innerhalb der
.database.windows.net-Domäne global eindeutig sein.Primärer Server/verwaltete Instanz
Die von SQL verwaltete Instanz, die die primären Datenbanken in der Failovergruppe hosten soll.
Sekundärer Server/verwaltete Instanz
Die von SQL verwaltete Instanz, die die sekundären Datenbanken in der Failovergruppe hosten soll. Das sekundäre Replikat kann sich nicht in derselben Azure-Region befinden wie das primäre Replikat.
Wichtig
Wenn eine Datenbank In-Memory-OLTP-Objekte enthält, müssen die primäre Datenbank und die sekundäre Georeplikat-Datenbank übereinstimmende Dienstebenen aufweisen, da sich In-Memory-OLTP-Objekte im Speicher befinden. Eine niedrigere Dienstebene auf der Geo-Replica-Instanz kann zu Problemen durch nicht genügend Arbeitsspeicher führen. Wenn dies der Fall ist, kann das Georeplikat die Datenbank nicht wiederherstellen, was dazu führt, dass die sekundäre Datenbank zusammen mit den In-Memory-OLTP-Objekten auf der sekundären Geodatenbank nicht verfügbar ist. Dies wiederum kann dazu führen, dass auch Failover nicht erfolgreich sind. Um dies zu vermeiden, stellen Sie sicher, dass die Dienstebene der sekundären Geodatenbank mit der der primären Datenbank übereinstimmt. Dienstebenenupgrades können Vorgänge zur Datengröße sein und können eine Weile dauern.
Failover (kein Datenverlust)
Beim geplanten Failover wird eine vollständige Datensynchronisierung zwischen primärer und sekundärer Datenbank ausgeführt, bevor die sekundäre Datenbank die Rolle der primären Datenbank übernimmt. Dadurch ist sichergestellt, dass keine Daten verloren gehen. Failover ist nur möglich, wenn auf die primäre Datei zugegriffen werden kann. Ein geplantes Failover wird in den folgenden Szenarien verwendet:
- Ausführen von DR-Drills (Notfallwiederherstellung) in der Produktion, wenn ein Datenverlust nicht akzeptabel ist
- Verschieben der Datenbanken in eine andere Region
- Rückkehr der Datenbanken in die primäre Region, nachdem der Ausfall behoben wurde (Failback)
Erzwungenes Failover (potenzieller Datenverlust)
Beim ungeplanten oder erzwungenen Failover übernimmt die sekundäre Datenbank sofort die Rolle der primären Datenbank, ohne dass auf die Weitergabe kürzlicher Änderungen von der primären Datenbank gewartet wird. Dieser Vorgang kann zu Datenverlust führen. Ein ungeplantes Failover wird als Wiederherstellungsmethode bei Ausfällen verwendet, wenn auf die primäre Datenbank nicht zugegriffen werden kann. Wenn der Ausfall behoben wird, stellt die alte primäre Datenbank automatisch wieder eine Verbindung her und wird zu einer neuen sekundären Datenbank. Ein geplantes Failover kann ausgeführt werden, um ein Failback durchzuführen und die Replikate an ihre ursprünglichen primären und sekundären Rollen zurückzugeben.
Toleranzperiode mit Datenverlust
Da Daten mithilfe der asynchronen Replikation auf die sekundäre Replikation repliziert werden, kann das erzwungene Failover von Gruppen mit von Microsoft verwalteten Failoverrichtlinien zu Datenverlust führen. Sie können die Richtlinie für automatisches Failover entsprechend der Toleranz Ihrer Anwendung gegenüber Datenverlust anpassen. Durch Konfiguration von
GracePeriodWithDataLossHourskönnen Sie steuern, wie lange das System wartet, bevor ein erzwungenes Failover initiiert wird, das zu Datenverlust führen kann.
DNS-Zone
Eine eindeutige ID, die automatisch generiert wird, wenn eine neue SQL Managed Instance erstellt wird. Ein Zertifikat mit mehreren Domänen (SAN) für diese Instanz wird bereitgestellt, um die Clientverbindungen mit einer beliebigen Instanz in der gleichen DNS-Zone zu authentifizieren. Die beiden SQL-verwalteten Instanzen in derselben Failovergruppe müssen die DNS-Zone gemeinsam nutzen.
Lese-/Schreib-Failovergruppenlistener
Ein DNS CNAME-Eintrag, der auf die aktuelle primäre Datenbank verweist. Er wird automatisch mit der Failovergruppe erstellt und ermöglicht der Lese-/Schreibworkload die transparente Verbindungswiederherstellung mit der primären verwalteten Instanz, wenn sich diese nach dem Failover ändert. Wenn die Failovergruppe auf einer SQL-verwalteten Instanz erstellt wird, wird der DNS-CNAME-Eintrag für die Listener-URL als
<fog-name>.<zone_id>.database.windows.net.Nur-Lese-Failovergruppenlistener
Ein DNS CNAME-Eintrag, der auf die aktuelle sekundäre Datenbank verweist. Er wird automatisch mit der Failovergruppe erstellt und ermöglicht der schreibgeschützten SQL-Workload das transparente Verbinden mit der sekundären verwalteten Instanz, wenn sich diese nach dem Failover ändert. Wenn die Failovergruppe auf einer SQL-verwalteten Instanz erstellt wird, wird der DNS-CNAME-Eintrag für die Listener-URL als
<fog-name>.secondary.<zone_id>.database.windows.net. Standardmäßig ist das Failover des schreibgeschützten Listeners deaktiviert, da sichergestellt wird, dass die Leistung der primären Datei nicht beeinträchtigt wird, wenn die sekundäre Offlineversion offline ist. Es bedeutet jedoch auch, dass die schreibgeschützten Sitzungen erst dann eine Verbindung herstellen können, nachdem die sekundäre Datenbank wiederhergestellt wurde. Wenn Sie keine Ausfallzeiten für die Nur-Lese-Sitzungen tolerieren können und den primären Rechner sowohl für den Nur-Lese- als auch für den Schreib-Lese-Verkehr verwenden können, ohne dass die Leistung des primären Rechners beeinträchtigt wird, können Sie Failover für den Nur-Lese-Listener aktivieren, indem Sie die EigenschaftAllowReadOnlyFailoverToPrimarykonfigurieren. In diesem Fall wird der schreibgeschützte Datenverkehr automatisch zur primären Datenbank umgeleitet, wenn die sekundäre Datenbank nicht verfügbar ist.Hinweis
Die Eigenschaft
AllowReadOnlyFailoverToPrimaryist nur wirksam, wenn die Richtlinie für automatisches Failover aktiviert ist und ein automatisches Failover ausgelöst wurde. Wenn in diesem Fall die Eigenschaft auf "True" gesetzt ist, dient die neue primäre Instanz sowohl für Lese-Schreib- als auch für Schreibgeschützt-Sessions.
Architektur einer Failovergruppe
Die Failovergruppe muss für die primäre Instanz konfiguriert und mit der sekundären Instanz in einer anderen Azure-Region verbunden werden. Alle Benutzerdatenbanken in der primären Instanz werden in die sekundäre Instanz repliziert. Systemdatenbanken wie master und msdb werden nicht repliziert.
Das folgende Diagramm veranschaulicht eine typische Konfiguration einer georedundanten Cloudanwendung mit einer verwalteten SQL-Instanz und Failovergruppe:
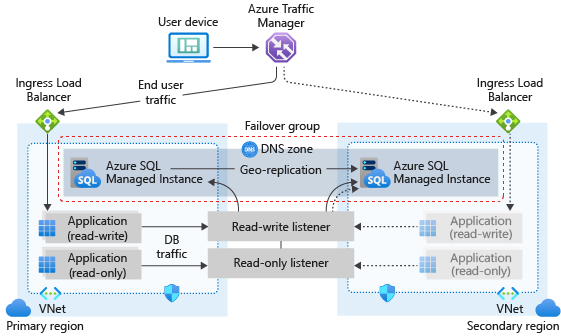
Wenn Ihre Anwendung SQL Managed Instance als Datenschicht verwendet, beachten Sie beim Entwerfen für Geschäftskontinuität die in diesem Artikel beschriebenen allgemeinen Richtlinien und Best Practices.
Erstellen der sekundären Geoinstanz
Um eine unterbrechungsfreie Verbindung mit der primären verwalteten SQL-Instanz nach dem Failover sicherzustellen, müssen sich sowohl die primären als auch die sekundären Instanzen in derselben DNS-Zone befinden. Es wird sichergestellt, dass das gleiche Zertifikat mit mehreren Domänen (SAN) zum Authentifizieren von Clientverbindungen mit einer der zwei Instanzen in der Failovergruppe verwendet werden kann. Wenn Ihre Anwendung für die Bereitstellung in der Produktionsumgebung bereit ist, erstellen Sie eine sekundäre SQL Managed Instance in einer anderen Region, und stellen Sie sicher, dass sie die gleiche DNS-Zone wie die primäre SQL Managed Instance verwendet. Dazu können Sie einen optionalen Parameter angeben, wenn Sie die Instanz erstellen. Wenn Sie PowerShell oder die REST-API verwenden, lautet der Name des optionalen Parameters DNSZonePartner. Der Name des entsprechenden optionalen Felds im Azure-Portal ist Primäre verwaltete Instanz.
Wichtig
Die erste im Subnetz erstellte verwaltete SQL-Instanz bestimmt die DNS-Zone für alle nachfolgenden Instanzen im selben Subnetz. Dies bedeutet, dass zwei Instanzen aus dem gleichen Subnetz nicht zu verschiedenen DNS-Zonen gehören können.
Weitere Informationen zum Erstellen der sekundären SQL Managed Instance in derselben DNS-Zone wie die primäre Instanz finden Sie unter Konfigurieren einer Failovergruppe für Azure SQL Managed Instance.
Verwenden von Regionspaaren
Stellen Sie beide von SQL verwalteten Instanzen aus Leistungsgründen in gekoppelten Regionen bereit. SQL Managed Instance-Failovergruppen in gekoppelten Regionen weisen im Vergleich zu nicht gekoppelten Regionen eine bessere Leistung auf.
Azure SQL Managed Instance folgt einer sicheren Bereitstellungsmethode, bei der gekoppelte Azure-Regionen generell nicht gleichzeitig bereitgestellt werden. Es ist jedoch nicht möglich, vorherzusagen, welche Region zuerst aktualisiert wird, sodass die Reihenfolge der Bereitstellung nicht garantiert ist. Manchmal wird zuerst ein Upgrade der primären Instanz durchgeführt, und manchmal wird zuerst ein Upgrade der sekundären Instanz durchgeführt.
In Situationen, in denen Azure SQL Managed Instance Teil einer Failovergruppe ist und sich die Instanzen in der Gruppe nicht in Azure-Regionspaaren befinden, wählen Sie unterschiedliche Wartungsfensterzeitpläne für Ihre primäre und sekundäre Datenbank aus. Wählen Sie beispielsweise das Wartungsfenster Werktag für Ihre sekundäre Geodatenbank und das Wartungsfenster Wochenende für Ihre primäre Geodatenbank aus.
Aktivieren und Optimieren des Datenverkehrsflows für die Georeplikation zwischen den Instanzen
Die Konnektivität zwischen den virtuellen Netzwerksubnetzen, die die primäre und sekundäre Instanz hosten, muss für unterbrechungsfreie Georeplikationsdatenverkehr eingerichtet und verwaltet werden. Es gibt mehrere Möglichkeiten, die Konnektivität zwischen den Instanzen bereitzustellen, aus denen Sie basierend auf Ihrer Netzwerktopologie und Richtlinien wählen können:
Das globale Peering virtueller Netzwerke (VNet-Peering) ist die empfohlene Methode zum Einrichten der Konnektivität zwischen zwei Instanzen in einer Failovergruppe. Es bietet eine private Verbindung mit geringer Latenz und hoher Bandbreite zwischen den virtuellen Netzwerken mit Peering mithilfe der Microsoft-Backbone-Infrastruktur. Für die Kommunikation zwischen virtuellen Netzwerken mit Peering werden kein öffentliches Internet, keine Gateways und keine zusätzliche Verschlüsselung benötigt.
Anfängliches Seeding
Beim Einrichten einer Failovergruppe zwischen verwalteten SQL-Instanzen gibt es eine anfängliche Seedingphase, bevor die Datenreplikation beginnt. Die Seedingphase zu Beginn ist der längste und teuerste Teil des Vorgangs. Nach Abschluss des anfänglichen Seeding-Prozesses werden die Daten synchronisiert, und nur nachfolgende Datenänderungen werden repliziert. Die Zeit für den Abschluss des anfänglichen Seedings hängt von der Größe der Daten, der Anzahl der replizierten Datenbanken, der Arbeitsauslastungsintensität für die primären Datenbanken und der Geschwindigkeit der Verbindung zwischen den virtuellen Netzwerken ab, die die primäre und sekundäre Instanz hosten, die hauptsächlich von der Art und Weise abhängig ist, wie die Konnektivität hergestellt wird. Unter normalen Umständen und wenn die Konnektivität mithilfe des empfohlenen globalen Peerings virtueller Netzwerke eingerichtet wird, beträgt die Seedinggeschwindigkeit für SQL Managed Instance bis zu 360 GB pro Stunde. Das Seeding wird für eine Reihe von Benutzerdatenbanken parallel, aber nicht notwendigerweise für alle Datenbanken gleichzeitig ausgeführt. Möglicherweise sind mehrere Batches erforderlich, wenn viele Datenbanken in der Instanz gehostet werden.
Wenn die Geschwindigkeit der Verbindung zwischen den beiden Instanzen langsamer als erforderlich ist, wirkt sich dies wahrscheinlich erheblich auf die Zeit für das Seeding aus. Sie können die angegebene Seedinggeschwindigkeit, die Anzahl der Datenbanken, die Gesamtgröße von Daten und die Verknüpfungsgeschwindigkeit verwenden, um zu schätzen, wie lange die anfängliche Seedingphase dauert, bevor die Datenreplikation beginnt. Beispielsweise würde für eine einzelne Datenbank mit 100 GB die anfängliche Seedingphase etwa 1,2 Stunden dauern, wenn die Verbindung eine Pushübertragung von 84 GB pro Stunde unterstützt und für keine anderen Datenbanken ein Seeding ausgeführt wird. Wenn über die Verbindung nur 10 GB pro Stunde übertragen werden können, dauert das Seeding einer 100-GB-Datenbank ungefähr 10 Stunden. Wenn mehrere Datenbanken repliziert werden sollen, wird das Seeding parallel ausgeführt. In Kombination mit einer langsamen Verbindungsgeschwindigkeit kann die anfängliche Seedingphase erheblich länger dauern, insbesondere, wenn das parallele Seeding von Daten aus allen Datenbanken die verfügbare Linkbandbreite überschreitet.
Wichtig
Die anfängliche Phase des Seedings kann bei extrem niedrigen Geschwindigkeiten oder stark beanspruchten Verbindungen Tage dauern. In diesem Fall kann das Erstellen der Failovergruppe ablaufen. Das Erstellen der Failovergruppe wird nach sechs Tagen automatisch abgebrochen.
Verwalten von Geofailovern auf eine sekundäre Geoinstanz
Die Failovergruppe verwaltet das Geofailover aller Datenbanken in der primären verwalteten SQL-Instanz. Wenn eine Gruppe erstellt wird, wird jede Datenbank auf der Instanz automatisch auf die geo-sekundäre Instanz repliziert. Sie können Failovergruppen nicht dazu verwenden, ein Teilfailover einer Untergruppe von Datenbanken zu initiieren.
Wichtig
Wenn eine Datenbank in der primären verwalteten SQL-Instanz abgelegt wird, wird sie auch automatisch in der geo-sekundären verwalteten SQL-Instanz abgelegt.
Verwenden des Lese-/Schreiblisteners (primäre verwaltete Instanz)
Verwenden Sie für Lese-/Schreibworkloads <fog-name>.zone_id.database.windows.net als Servernamen. Verbindungen werden automatisch an die primäre Datenbank weitergeleitet. Dieser Name wird nach dem Failover nicht geändert. Das Geo-Failover umfasst das Aktualisieren des DNS-Eintrags, sodass neue Clientverbindungen erst nach dem Aktualisieren des Client-DNS-Caches an den neuen primären Server weitergeleitet werden. Da die sekundäre Instanz die gleiche DNS-Zone wie die primäre Instanz verwendet, kann die Clientanwendung mit dem gleichen serverseitigen SAN-Zertifikat erneut eine Verbindung herstellen. Die vorhandenen Clientverbindungen müssen beendet und dann neu erstellt werden, um an die neue primäre Instanz weitergeleitet zu werden. Der Lese-/Schreib-Listener und der schreibgeschützte Listener können nicht über den öffentlichen Endpunkt für die verwaltete SQL-Instanz erreicht werden.
Verwenden des Lese-/Schreiblisteners (sekundäre verwaltete Instanz)
Wenn Sie über logisch isolierte schreibgeschützte Workloads verfügen, die datenlatenztolerant sind, können Sie sie auf der sekundären Geodatenbank ausführen. Verwenden Sie <fog-name>.secondary.<zone_id>.database.windows.net als Servernamen, um eine direkte Verbindung mit der sekundären Geodatenbank herzustellen.
Auf der Dienstebene „Unternehmenskritisch“ unterstützt SQL Managed Instance die Verwendung schreibgeschützter Replikate zur Auslagerung schreibgeschützter Abfrageworkloads unter Verwendung des Parameters ApplicationIntent=ReadOnly in der Verbindungszeichenfolge. Wenn Sie eine georeplizierte sekundäre Datenbank konfiguriert haben, können Sie mit dieser Funktion eine Verbindung entweder mit einem schreibgeschützten Replikat am primären Standort oder am geografisch replizierten Standort herstellen:
- Verwenden Sie
ApplicationIntent=ReadOnlyund<fog-name>.<zone_id>.database.windows.net, um eine Verbindung mit einem schreibgeschützten Replikat am primären Standort herzustellen. - Wenn Sie eine Verbindung mit einem schreibgeschützten Replikat am sekundären Standort herstellen möchten, verwenden Sie
ApplicationIntent=ReadOnlyund<fog-name>.secondary.<zone_id>.database.windows.net.
Der Lese-/Schreib-Listener und der schreibgeschützte Listener können nicht über den öffentlichen Endpunkt für die verwaltete SQL-Instanz erreicht werden.
Potenzielle Leistungsbeeinträchtigung nach einem Failover
Eine typische Azure-Anwendung nutzt mehrere Azure-Dienste und besteht aus mehreren Komponenten. Das automatisierte Geofailover der Failovergruppe wird ausschließlich anhand des Status der Azure SQL-Komponenten ausgelöst. Ein Ausfall wirkt sich möglicherweise nicht auf andere Azure-Dienste in der primären Region aus, und ihre Komponenten sind in dieser Region weiterhin verfügbar. Nachdem die primären Datenbanken auf die sekundäre Region umgestellt wurden, erhöht sich unter Umständen die Wartezeit zwischen den abhängigen Komponenten. Stellen Sie sicher, dass die Redundanz aller Komponenten der Anwendung in der sekundären Region gewährleistet ist und dass ein Failover der Anwendungskomponenten zusammen mit der Datenbank erfolgt, sodass eine höhere regionsübergreifende Latenz die Leistung der Anwendung nicht beeinträchtigt.
Potenzieller Datenverlust nach einem Geofailover
Wenn ein Ausfall in der primären Region auftritt, wurden die letzten Transaktionen möglicherweise nicht in die geo-sekundäre Region repliziert, und es kann Datenverlust geben, wenn ein erzwungenes Failover ausgeführt wird.
DNS-Update
Die DNS-Aktualisierung des Lese-/Schreib-Listeners erfolgt sofort nach dem Initiieren des Failovers. Bei diesem Vorgang gehen keine Daten verloren. Der Wechsel von Datenbankrollen kann jedoch unter normalen Bedingungen bis zu fünf Minuten dauern. Bis er abgeschlossen ist, sind einige Datenbanken in der neuen primären Instanz noch schreibgeschützt. Wenn ein Failover mithilfe von PowerShell initiiert wird, ist der Vorgang für den Wechsel der primären Replikatrolle synchron. Wird es über das Azure-Portal initiiert, wird auf der Benutzeroberfläche der Abschlussstatus angegeben. Verwenden Sie beim Initiieren über die REST-API den Standardabfragemechanismus von Azure Resource Manager, um den Abrufvorgang auf seinen Abschluss zu überwachen.
Wichtig
Verwenden Sie ein manuelles geplantes Failover, um die primäre Datenbank zurück an den ursprünglichen Speicherort zu verschieben, sobald der Ausfall, der das Geofailover verursacht hat, entschärft wurde.
Sparen von Kosten mit einem lizenzfreien DR-Replikat
Sie können die Kosten für SQL Server-Lizenzen sparen, indem Sie ihre sekundäre verwaltete SQL-Instanz so konfigurieren, dass sie nur für die Notfallwiederherstellung (DR) verwendet wird. Informationen zur Einrichtung finden Sie unter Konfigurieren eines lizenzfreien Standbyreplikats für Azure SQL Managed Instance.
Solange die sekundäre Instanz nicht für Leseworkloads verwendet wird, stellt Microsoft ihnen kostenlos eine Anzahl von virtuellen Kernen zur Verfügung, die mit der der primären Instance übereinstimmt. Ihnen werden trotzdem die Compute- und Speicherkosten in Rechnung gestellt, die von der sekundären Instanz verwendet werden. Failovergruppen unterstützen nur ein Replikat, und das Replikat muss entweder ein lesbares Replikat sein oder als nur DR-Replikat festgelegt werden.
Aktivieren von Szenarien in Abhängigkeit von Objekten in den Systemdatenbanken
Systemdatenbanken werden nicht in die sekundäre Instanz in einer Failovergruppe repliziert. Um Szenarien zu aktivieren, die von Objekten aus den Systemdatenbanken abhängen, müssen Sie die gleichen Objekte in der sekundären Instanz erstellen. Halten Sie sie mit der primären Instanz synchronisiert.
Wenn Sie beispielsweise beabsichtigen, die gleichen Anmeldungen für die sekundäre Instanz zu verwenden, stellen Sie sicher, dass Sie sie mit dem identischen SIDerstellen.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Weitere Informationen finden Sie unter Azure SQL Managed Instance – Sync Agent Jobs and Logins in Failover Groups (Azure SQL Managed Instance: Synchronisieren von Agent-Aufträgen und Anmeldungen bei Failovergruppen).
Synchronisieren von Instanzeigenschaften und Aufbewahrungsrichtlinien
Instanzen in einer Failovergruppe bleiben von Azure-Ressourcen getrennt, und Änderungen, die an der Konfiguration der primären Instanz vorgenommen werden, werden nicht automatisch in die sekundäre Instanz repliziert. Stellen Sie sicher, dass Alle relevanten Änderungen sowohl für die primäre als auch für die sekundäre Instanz ausgeführt werden. Wenn Sie z. B. die Redundanz des Sicherungsspeichers oder die langfristige Aufbewahrungsrichtlinie für Sicherungen bei der primären Instanz ändern, müssen Sie sie auch bei der sekundären Instanz ändern.
Skalieren von Instanzen
Die Konfiguration Ihrer primären und sekundären Instanz sollte identisch sein. Dazu gehören die Computegröße, die Speichergröße und die Dienstebene. Wenn Sie die Konfiguration Ihrer Failovergruppe ändern müssen, können Sie dies tun, indem Sie jede Instanz entsprechend auf dieselbe Konfiguration skalieren. Weitere Informationen finden Sie unter Skalierungsinstanzen in einer Failovergruppe.
Verhinderung des Verlusts kritischer Daten
Aufgrund der hohen Latenzzeit von WANs verwendet die Georeplikation einen asynchronen Replikationsmechanismus. Bei der asynchronen Replikation ist die Möglichkeit eines Datenverlusts unvermeidbar, wenn die primäre Datenbank ausfällt. Wenn Sie erfahren möchten, wie Sie Ihre Daten schützen können, lesen Sie " Datenverlust verhindern".
Failovergruppenstatus
Die Failovergruppe berichtet über ihren aktuellen Status und beschreibt dabei den Zustand der Datenreplikation.
- Seeding: Das anfängliche Seeding erfolgt nach der Erstellung der Failovergruppe, bis alle Benutzerdatenbanken in der sekundären Instanz initialisiert werden. Failover kann nicht initiiert werden, während sich die Failovergruppe im Seeding-Zustand befindet, da Benutzerdatenbanken noch nicht in die sekundäre Instanz kopiert werden.
- Synchronisieren: Der übliche Status der Failover-Gruppe. Dies bedeutet, dass Datenänderungen in der primären Instanz asynchron auf die sekundäre Instanz repliziert werden. Dieser Status garantiert nicht, dass die Daten zu jedem Zeitpunkt vollständig synchronisiert werden. Aufgrund der asynchronen Natur des Replikationsprozesses zwischen Instanzen in einer Failover-Gruppe können Datenänderungen auf der primären Instanz vorliegen, die noch auf die sekundäre Instanz repliziert werden müssen. Sowohl automatische als auch manuelle Failover können initiiert werden, während sich die Failovergruppe im Synchronisierungszustand befindet.
- Failover wird ausgeführt: Dieser Status gibt an, dass entweder automatisch oder manuell initiiertes Failover ausgeführt wird. Es können keine Änderungen an der Failovergruppe oder zusätzliche Failovers initiiert werden, während sich die Failovergruppe in diesem Zustand befindet.
Failback
Wenn Failovergruppen mit einer von Microsoft verwalteten Failoverrichtlinie konfiguriert sind, wird das erzwungene Failover auf den geo-sekundären Server während eines Notfallszenarios gemäß der definierten Nachfrist initiiert. Das Failback auf den alten primären Server muss manuell initiiert werden.
Featureinteroperabilität
Sicherungen
In den folgenden Szenarien wird eine vollständige Sicherung durchgeführt:
- Bevor die anfängliche Ermittlung der Setzliste anfängt, wenn Sie eine Failovergruppe erstellen.
- Nach einem Failover.
Eine vollständige Sicherung ist ein datenintensiver Vorgang, der nicht übersprungen oder verzögert werden kann und einige Zeit in Anspruch nehmen kann. Die Zeit, die zum Abschluss benötigt wird, hängt von der Größe der Daten, der Anzahl der Datenbanken und der Workloadintensität auf den primären Datenbanken ab. Eine vollständige Sicherung kann die anfängliche Ermittlung der Setzliste spürbar verzögern und eine Failoveroperation in einer neuen Instanz kurz nach einem Failover verzögern oder verhindern.
Beachten Sie Folgendes:
- Datenbanken, die in der sekundären Instanz einer Failovergruppe gehostet werden, werden erst gesichert, wenn diese Instanz nach einem Failover zur primären Instanz wird oder die Failovergruppe gelöscht wird.
- Nachdem eine Datenbank nach einem Failover in die primäre Rolle geändert wurde oder nach dem Löschen einer Failovergruppe eigenständig wird, wird automatisch eine vollständige Datenbanksicherung initiiert, um Point-in-Time-Wiederherstellungen zu erleichtern.
- Eine Datenbank kann nicht von einer Instanz zu einem Zeitpunkt wiederhergestellt werden, zu dem diese Instanz ein sekundäres Replikat in einer Failovergruppe war. Um eine Zeitangabe wiederherzustellen, müssen Sie die Datenbank aus der Instanz wiederherstellen, die zu diesem Zeitpunkt primär war.
- Um eine verworfene Failovergruppe für dasselbe Paar von SQL-verwalteten Instanzen neu zu erstellen, müssen alle Benutzerdatenbanken nach dem Ablegen der Failovergruppe aus der beabsichtigten sekundären Entfernt werden. Eine Datenbank wird erst vollständig entfernt, nachdem alle ausstehenden Sicherungsvorgänge abgeschlossen wurden, einschließlich einer vollständigen Sicherung, wenn eine nicht ausgeführt wurde (die Größe des Datenvorgangs ist). Lassen Sie Zeit, die sekundäre Instanz nach dem Entfernen einer Failovergruppe mit sehr großen Datenbanken zu bereinigen, da für jede Datenbank ein noch ausstehender vollständiger Sicherungsvorgang in Arbeit sein kann.
Eine vollständige Sicherung ist ein Datensicherungsvorgang, der weder übersprungen noch verzögert werden kann und einige Zeit in Anspruch nehmen kann. Die Zeit, die zum Abschluss benötigt wird, hängt von der Größe der Daten, der Anzahl der Datenbanken und der Workloadintensität auf den primären Datenbanken ab. Eine vollständige Sicherung kann das anfängliche Seeding spürbar verzögern und einen Failovervorgang in einer neuen Instanz kurz nach einem Failover verzögern oder verhindern.
Protokollwiedergabedienst
Datenbanken, die mithilfe des Protokollwiedergabedienstes (LRS) zu Azure SQL Managed Instance migriert wurden, können erst dann zu einer Failovergruppe hinzugefügt werden, wenn der Cutover-Schritt ausgeführt ist. Eine mit LRS migrierte Datenbank befindet sich in einem Wiederherstellungszustand bis das Cutover erfolgt, und Datenbanken in einem Wiederherstellungszustand können einer Failovergruppe nicht hinzugefügt werden. Der Versuch, eine Failovergruppe mit einer Datenbank in einem Wiederherstellungszustand zu erstellen, verzögert die Erstellung der Failovergruppe bis die Datenbankwiederherstellung abgeschlossen ist.
Transaktionsreplikation
Die Verwendung der Transaktionsreplikation mit Instanzen, die sich in einer Failovergruppe befinden, wird unterstützt. Wenn Sie jedoch die Replikation konfigurieren, bevor Sie Ihre verwaltete SQL-Instanz zu einer Failovergruppe hinzufügen, wird die Replikation angehalten, wenn Sie mit der Erstellung der Failovergruppe beginnen. Der Replikationsmonitor zeigt einen Status von Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Die Replikation wird fortgesetzt, sobald die Failovergruppe erfolgreich erstellt wurde.
Wenn eine als Herausgeber oder Verteiler fungierende Instanz von SQL Managed Instance Teil einer Failovergruppe ist, müssen die SQL Managed Instance-Administrator*innen alle Veröffentlichungen für die alte primäre Instanz bereinigen und nach einem Failover für die neue primäre Instanz erneut konfigurieren. Den in diesem Szenario erforderlichen Schritt der Aktivitäten können Sie der Anleitung zur Transaktionsreplikation entnehmen.
Erforderliche Berechtigungen und Einschränkungen
Überprüfen Sie eine Liste an Berechtigungen und Einschränkungen bevor Sie eine Failovergruppe konfigurieren.
Programmgesteuertes Verwalten von Failovergruppen
Gruppen für automatisches Failover können auch programmgesteuert mit Azure PowerShell, Azure CLI und der REST-API verwaltet werden. Lesen Sie " Failovergruppe konfigurieren ", um mehr zu erfahren.
Übungen zur Notfallwiederherstellung
Die empfohlene Methode zum Ausführen eines DR-Drilldowns ist die Verwendung des manuellen geplanten Failovers gemäß dem folgenden Lernprogramm: Testen des Failovers.
Das Ausführen eines Drill-Tests mit erzwungenem Failover wird nicht empfohlen, da dieser Vorgang keine Schutzmaßnahmen gegen Datenverlust bietet. Dennoch ist es möglich, einen datenverlustlosen erzwungenen Failover zu erreichen, indem sichergestellt wird, dass die folgenden Bedingungen erfüllt sind, bevor das erzwungene Failover initiiert wird:
- Die Workload wird in der primären verwalteten SQL-Instanz beendet.
- Alle Transaktionen mit langer Ausführung sind abgeschlossen.
- Alle Clientverbindungen mit der primären verwalteten SQL-Instanz wurden getrennt.
- Der Failovergruppenstatus lautet „Synchronisieren“.
Stellen Sie sicher, dass die beiden von SQL verwalteten Instanzen über gewechselte Rollen verfügen. Darüber hinaus hat sich der Status der Failover-Gruppe von "Failover in Bearbeitung" auf "Synchronisieren" geändert, bevor optional Verbindungen mit der neuen primären verwalteten SQL-Instanz eingerichtet und die Lese-/Schreibarbeitslast gestartet werden.
Um einen datenverlustlosen Failback in die ursprünglichen rollen der verwalteten SQL-Instanz durchzuführen, wird dringend empfohlen, das manuelle geplante Failover anstelle des erzwungenen Failovers zu verwenden. Wenn erzwungener Failback verwendet wird:
- Führen Sie die gleichen Schritte wie für das Failover ohne Datenverlust aus.
- Längere Failback-Ausführungszeiten sind zu erwarten, wenn der erzwungene Failback kurz nach dem Abschluss des initialen erzwungenen Failovers ausgeführt wird, da auf den Abschluss der ausstehenden automatischen Sicherungsoperationen auf der ehemaligen primären verwalteten SQL-Instanz gewartet werden muss.
- Alle ausstehenden automatischen Sicherungsvorgänge für eine Instanz, die von der primären zur sekundären Rolle übergehen, können sich auf die Datenbankverfügbarkeit für diese Instanz auswirken.
- Verwenden Sie den Failovergruppenstatus, um zu ermitteln, ob beide Instanzen ihre Rollen erfolgreich geändert haben und bereit sind, Clientverbindungen zu akzeptieren.
Zugehöriger Inhalt
- Konfigurieren einer Failovergruppe für verwaltete Azure SQL-Instanz
- Verwenden von PowerShell zum Hinzufügen einer sql-verwalteten Instanz zu einer Failovergruppe
- Konfigurieren eines lizenzfreien Standbyreplikats für Azure SQL Managed Instance
- Übersicht über die Geschäftskontinuität mit der Azure SQL Managed Instance
- Automatisierte Sicherungen in Azure SQL Managed Instance
- Wiederherstellen einer Datenbank aus einer Sicherung in Azure SQL Managed Instance