Verfügbarkeit über lokale und Zonenredundanz – Azure SQL Managed Instance
Gilt für: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In diesem Artikel wird die Architektur von Azure SQL Managed Instance beschrieben, die die Verfügbarkeit durch lokale Redundanz und hohe Verfügbarkeit durch Zonenredundanz erreicht.
Wichtig
Zonenredundante Konfiguration befindet sich in der öffentlichen Vorschau für die Dienstebene „Universell“ und ist allgemein für die Dienstebene „Unternehmenskritisch“ verfügbar.
Übersicht
SQL Managed Instance wird in der neuesten stabilen Version der SQL Server-Datenbank-Engine unter dem Windows-Betriebssystem mit allen anwendbaren Patches ausgeführt. SQL Managed Instance verarbeitet automatisch wichtige Wartungsaufgaben, z. B. Patches, Sicherungen, Windows- und SQL-Datenbank-Engine-Upgrades, aber auch ungeplante Ereignisse wie Ausfälle der zugrunde liegenden Hardware oder Software oder Netzwerkfehler. Wenn eine Instanz gepatcht oder ein Failover dafür ausgeführt wird, hat die Downtime keine Auswirkungen, wenn Sie in Ihrer App Wiederholungslogik einsetzen. SQL Managed Instance ermöglicht auch unter den kritischsten Umständen eine schnelle Wiederherstellung und stellt sicher, dass Ihre Daten immer verfügbar sind. Die meisten Benutzer*innen bemerken nicht, dass kontinuierlich Upgrades durchgeführt werden.
Standardmäßig erreicht Azure SQL Managed Instance Verfügbarkeit durch lokale Redundanz, sodass Ihre Instanz während der folgenden Zeit verfügbar ist:
- Der Kunde initiierte Verwaltungsvorgänge, die zu einer kurzen Ausfallzeit führen
- Service-Wartungsvorgänge
- Probleme und Rechenzentrumsausfälle mit:
- Regal, in dem die Maschinen, die Ihren Dienst betreiben, ausgeführt werden.
- Physischer Computer, der die VM hostet, auf dem SQL-Datenbank-Engine ausgeführt wird.
- Virtuelle Maschine, die SQL-Datenbank-Engine ausführt
- Andere Probleme mit dem SQL-Datenbank-Engine
- Andere potenzielle ungeplante lokale Ausfälle
Die Standard-Verfügbarkeitslösung soll sicherstellen, dass Daten, für die ein Commit ausgeführt wurde, nie aufgrund von Fehlern verloren gehen, dass sich Wartungsvorgänge nicht auf Ihre Workload auswirken und dass die Instanz keinen Single Point of Failure in der Softwarearchitektur darstellt.
Um jedoch die Auswirkungen auf Ihre Daten im Falle eines Ausfalls auf eine gesamte Zone zu minimieren, können Sie eine hohe Verfügbarkeit erzielen, indem Sie Zonenredundanz aktivieren. Ohne Zonenredundanz erfolgen Failover lokal innerhalb desselben Rechenzentrums, was dazu führen kann, dass Ihre Instanz nicht verfügbar ist, bis der Ausfall aufgelöst wird. Die einzige Möglichkeit zum Wiederherstellen besteht aus einer Notfallwiederherstellungslösung, z. B. über eine Failovergruppe oder eine Geowiederherstellung einer georedundanten Sicherung. Weitere Informationen finden Sie unter Übersicht der Geschäftskontinuität.
Hohe Verfügbarkeit erhöht die Zuverlässigkeit Ihres Diensts, indem Sie vor Auswirkungen schützen auf:
- Verfügbarkeitszone, die das Rechenzentrum bildet
Es gibt zwei verschiedene Verfügbarkeits-Architekturmodelle, die auf der Dienstebene basieren:
- Das Remote-Storage-Modell basiert auf einer Trennung von Compute und Storage auf der Dienstebene Universell und Universell der nächsten Generation, die sich auf die Verfügbarkeit und Zuverlässigkeit des Remote-Storage und die Verfügbarkeit der von Azure Service Fabric verwalteten Compute-Cluster stützt. Dieses Verfügbarkeitsmodell zielt auf budgetorientierte Geschäftsanwendungen ab, die bei Wartungsarbeiten gewisse Leistungseinbußen tolerieren können.
- Das lokale Speichermodell basiert auf einem Cluster von Datenbank-Engine-Prozessen, die sich auf ein Quorum von verfügbaren Datenbank-Engine-Knoten auf der Dienstebene Unternehmenskritisch stützen, die über lokalen Speicher verfügen. Dieses lokale Speichermodell zielt auf unternehmenskritische Anwendungen ab, die eine hohe Transaktionsrate haben und eine hohe EA-Leistung erfordern. Die Hochverfügbarkeits-Architektur garantiert minimale Auswirkungen auf die Leistung Ihres Workloads während der Wartungsarbeiten.
Weitere Informationen zu bestimmten SLAs für verschiedene Dienstebenen finden Sie in der SLA für Azure SQL Managed Instance.
Verfügbarkeit durch lokale Redundanz
Lokal redundante Verfügbarkeit basiert auf der Speicherung Ihrer Serverknoten und Daten innerhalb eines einzelnen Rechenzentrums in der primären Region und dem Schutz Ihre Daten bei lokalen Ausfällen, z. B. bei einem kleinen Netzwerk oder einem Stromausfall. Bei einem Notfall von großem Ausmaß in einer Region (Feuer, Überschwemmung usw.) gehen jedoch eventuell alle Replikate in einem Speicherkonto oder Daten auf Serverkonten verloren oder könnten nicht mehr wiederhergestellt werden. Um Ihre Daten bei Verwendung der Option für lokal redundante Verfügbarkeit zusätzlich zu schützen, sollten Sie daher eine resilientere Speicheroption für Ihre Datenbanksicherungen verwenden.
Universelle Dienstebene
Für die Dienstebene „Universell“ wird die Architektur für Remotespeicherverfügbarkeit verwendet. In der folgenden Abbildung werden vier Knoten mit getrennter Compute- und Speicherebene veranschaulicht.
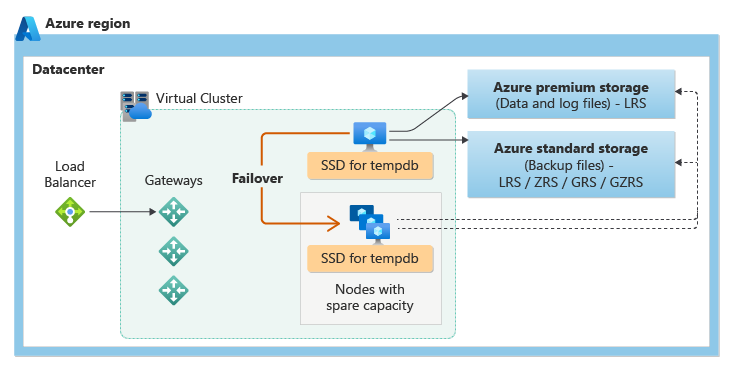
Das Modell für Remotespeicherverfügbarkeit umfasst zwei Ebenen:
- Eine zustandslose Computeebene, auf der der Datenbank-Engine-Prozess ausgeführt wird und die nur vorübergehende und zwischengespeicherte Daten enthält, z. B. die Datenbanken
tempdbundmodelauf der angefügten SSD, Plancache, Puffer- und Columnstore-Pool im Arbeitsspeicher. Dieser zustandslose Knoten wird vom Azure Service Fabric-Dienst gesteuert, der die Datenbank-Engine initialisiert, die Integrität des Knotens steuert und bei Bedarf ein Failover auf einen anderen Knoten durchführt. - Eine zustandsbehaftete Datenebene mit den Datenbankdateien (
.mdfand.ldf), die in Azure Blob Storage gespeichert sind. Azure Blob Storage verfügt über integrierte Datenverfügbarkeits- und Redundanzfunktionen. Lokal redundante Verfügbarkeit basiert auf der Speicherung Ihrer Daten in lokal redundantem Speicher (LRS), der Ihre Daten dreimal innerhalb eines einzelnen Rechenzentrums in der primären Region kopiert. Dadurch wird sichergestellt, dass jeder Datensatz in der Protokolldatei bzw. jede Seite in der Datendatei erhalten bleibt, auch wenn der Datenbank-Engine-Prozess abstürzt.
Bei jedem Upgrade der Datenbank-Engine oder des Betriebssystems sowie beim Erkennen eines Fehlers wird der zustandslose Datenbank-Engine-Prozess in Azure Service Fabric zu einem anderen zustandslosen Computeknoten mit ausreichender freier Kapazität verschoben. Daten in Azure Blob Storage sind vom Verschiebevorgang nicht betroffen, und die Daten- und Protokolldateien werden an den neu initialisierten Datenbank-Engine-Prozess angefügt. Dieser Prozess garantiert Hochverfügbarkeit, bei umfangreichen Workloads ist jedoch möglicherweise eine gewisse Leistungsbeeinträchtigung während des Übergangs festzustellen, da der neue Datenbank-Engine-Prozess mit einem kalten Cache gestartet wird.
Dienstebene Universell der nächsten Generation
Hinweis
Das Upgrade auf die Dienstebene Universell der nächsten Generation befindet sich derzeit in der Vorschau.
Universell der nächsten Generation ist ein Architekturupgrade der vorhandenen Dienstebene Universell mit einer aktualisierten Remotespeicherebene, die Instanzdaten und Protokolldateien auf verwalteten Datenträgern statt auf Seitenblobs speichert und lokal hält.
Dienstebene „Unternehmenskritisch“
Die Dienstebene „Unternehmenskritisch“ nutzt das Modell für die Verfügbarkeit von lokalem Speicher, das eine Integration von Computeressourcen (Datenbank-Engine-Prozess) und Speicher (lokal angefügte SSD) auf einem einzigen Knoten bietet. Hochverfügbarkeit wird durch Replizieren von Compute- und Speicherressourcen auf weiteren Knoten erreicht.
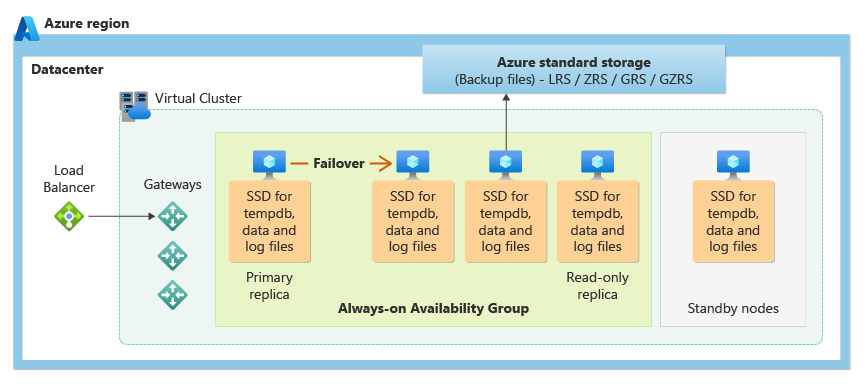
Die zugrunde liegenden Datenbankdateien (MDF- und LDF-Dateien) werden auf dem angefügten SSD-Speicher platziert, um eine E/A mit äußerst niedriger Latenz für Ihre Workload zu erzielen. Hochverfügbarkeit wird anhand einer ähnlichen Technologie wie AlwaysOn-Verfügbarkeitsgruppen in SQL Server implementiert. Der Cluster umfasst ein einzelnes primäres Replikat, der für Lese-/Schreib-Workloads der Kunden zugänglich ist, sowie bis zu drei sekundäre Replikate (Compute und Speicher) mit Kopien der Daten. Das primäre Replikat überträgt ständig Änderungen an die sekundären Replikate, um sicherzustellen, dass die Daten auf einer ausreichenden Anzahl sekundärer Replikate gespeichert sind, bevor jede Transaktion übertragen wird. Dieser Prozess garantiert, dass für den Fall, dass das primäre Replikat oder ein lesbares sekundäres Replikat aus irgendeinem Grund nicht mehr verfügbar ist, immer ein vollständig synchronisiertes Replikat zur Verfügung steht, auf dem das Failover ausgeführt werden kann. Das Failover wird von der Azure Service Fabric initiiert. Sobald ein sekundäres Replikat zum neuen primären Replikat wird, wird ein weiteres sekundäres Replikat erstellt, um sicherzustellen, dass der Cluster über eine ausreichende Anzahl von Replikaten verfügt, um ein Quorum beizubehalten. Sobald das Failover abgeschlossen ist, werden Azure SQL-Verbindungen automatisch an das neue primäre Replikat (oder das lesbare sekundäre Replikat basierend auf der Verbindungszeichenfolge) weitergeleitet.
Als weiteren Vorteil bietet das Modell für die Verfügbarkeit von lokalem Speicher die Möglichkeit, Azure SQL-Verbindungen mit Schreibschutz auf eines der sekundären Replikate umzuleiten. Dieses Feature wird als horizontale Leseskalierung bezeichnet. Es bietet 100 % zusätzliche Computekapazität ohne anfallende Zusatzkosten, sodass Schreibschutzvorgänge wie analytische Workloads vom primären Replikat ausgelagert werden können.
Hohe Verfügbarkeit durch Zonenredundanz
Die zonenredundante Verfügbarkeit basiert auf der Platzierung von Replikaten in drei Azure-Verfügbarkeitszonen in der primären Region. Jede Verfügbarkeitszone ist ein getrennter physischer Standort mit unabhängigen Stromversorgungs-, Kühlungs- und Netzwerkgeräten.
In der Standardeinstellung wird der Cluster von Knoten für das Modell für die Verfügbarkeit von lokalem Speicher im selben Rechenzentrum erstellt. Mit der Einführung von Azure-Verfügbarkeitszonen kann SQL Managed Instance verschiedene Replikate in unterschiedlichen Verfügbarkeitszonen in derselben Region platzieren. Um einen Single Point of Failure auszuschließen, wird der Steuerring zudem in mehreren Zonen kopiert. Der Steuerungsebene-Bereich wird dann an einen Lastenausgleich weitergeleitet, der auch über Verfügbarkeitszonen hinweg bereitgestellt wird. Das Datenverkehrsrouting von der Steuerungsebene zum Lastenausgleich wird von Azure Traffic Manager (ATM) gesteuert.
Durch die Verwendung einer zonenredundanten Konfiguration können Sie Ihre Instanzen der Dienstebene „Unternehmenskritisch“ oder „Universell“ für deutlich mehr Ausfallszenarien resistent machen (z. B. für schwerwiegende Ausfälle von Rechenzentren), ohne Änderungen an der Anwendungslogik vornehmen zu müssen. Sie können alle vorhandenen Instanzen der Dienstebene „Unternehmenskritisch“ oder „Universell“ in die zonenredundante Konfiguration konvertieren.
Da die zonenredundanten Instanzen über Replikate in verschiedenen Rechenzentren mit einiger Entfernung dazwischen verfügen, könnte sich durch die erhöhte Netzwerklatenz die Commitzeit für Transaktionen erhöhen und dadurch die Leistung einiger OLTP-Workloads beeinträchtigt werden. Sie können jederzeit zur Einzelzonenkonfiguration zurückkehren, indem Sie die zonenredundante Einstellung deaktivieren. Dieser Prozess ist ein Onlinevorgang und ähnelt dem regulären Upgrade des Dienstebenenziels. Am Ende des Prozesses wird die Instanz aus einem zonenredundanten Ring zum Ring einer einzelnen Zone migriert (oder umgekehrt).
Informationen zu den ersten Schritten mit Zonenredundanz für Ihre SQL Managed Instance finden Sie unter Konfigurieren der Zonenredundanz.
Universelle Dienstebene
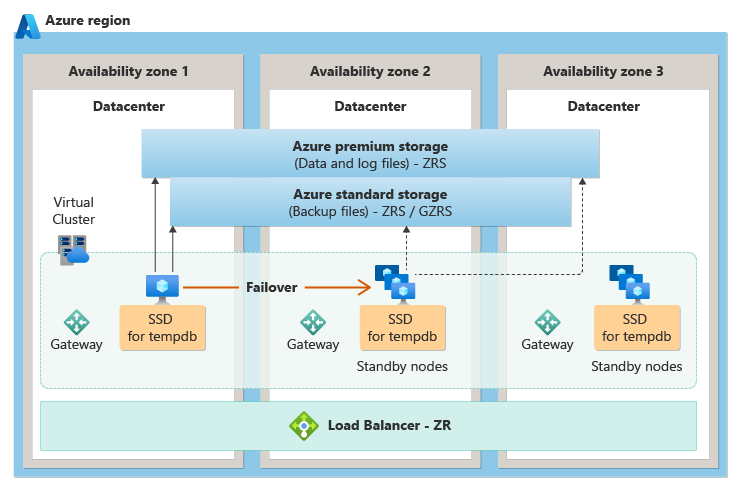
In der Dienstebene „Allgemein“ wird Zonenredundanz erreicht, indem zustandslose Serverknoten in verschiedenen Verfügbarkeitszonen platziert werden und dann auf einem zustandsbehafteten zonenredundanten Speicher (ZRS) basiert, der an den Knoten angefügt ist, der aktuell den aktiven SQL-Datenbank Engine-Prozess enthält. Im Falle eines Ausfalls wird der SQL-Datenbank Engine-Prozess auf einem der zustandslosen Knoten aktiv, der dann auf die Daten im zustandsbehafteten Speicher zugreift.
Das folgende Diagramm veranschaulicht die Zonenredundanz-Architektur für die Dienstebene „Universell“:
Hinweis
Zonenredundanz ist aktuell in Vorschau für die Dienstebene „Universell“.
Dienstebene „Unternehmenskritisch“
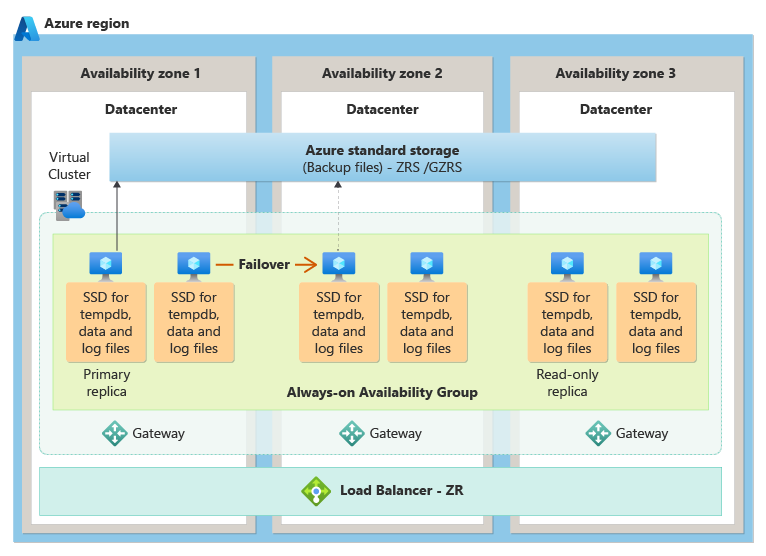
In der Dienstebene „Unternehmenskritisch“ wird Zonenredundanz erreicht, indem Compute- und Speicherreplikate in verschiedenen Verfügbarkeitszonen platziert und dann die zugrunde liegende Always On-Verfügbarkeitsgruppen-Technologie verwendet wird, um Datenänderungen von der primären Instanz in Standbyreplikate in anderen Verfügbarkeitszonen zu replizieren. Im Falle eines Ausfalls gibt es ein automatisches Failover, das nahtlos eines der Standbyreplikate übergibt, um primär zu sein.
Das folgende Diagramm veranschaulicht die Zonenredundanz-Architektur für die Dienstebene „Unternehmenskritisch“:
Testen der Resilienz von Anwendungsfehlern
Verfügbarkeit ist ein wesentlicher Bestandteil der SQL Managed Instance-Plattform und transparent für Ihre Datenbankanwendungen. Es ist uns jedoch bewusst, dass Sie möglicherweise testen möchten, wie sich die bei geplanten oder ungeplanten Ereignissen eingeleiteten automatischen Failover-Vorgänge ggf. auf eine Anwendung auswirken, ehe Sie sie in der Produktionsumgebung einsetzen. Sie können ein Failover manuell auslösen, indem Sie eine spezielle API zum Neustarten einer verwalteten Instanz aufrufen. Da Neustartvorgänge aufwendig sind und eine große Anzahl von ihnen die Plattform belasten könnte, ist für jede verwaltete Datenbank nur alle 15 Minuten ein Failoveraufruf erlaubt.
Während eines echten Failovers schlagen Verbindungen mit der Instanz fehl, während der SQL-Dienst primär auf einem anderen Knoten wird. Rufen Sie zum Simulieren eines Failovers den Befehl auf, der den SQL-Prozess neu startet, um das Starten des Diensts zu simulieren, als ob ein Failover aufgetreten wäre. Verbindungen können jedoch länger während eines echten Failovers im Vergleich zu einem simulierten Failover fehlschlagen, da der SQL-Prozess während eines echten Failovers auf einer anderen virtuellen Maschine innerhalb des Clusters (entweder lokal oder in einer anderen Zone, wenn Zonenredundanz aktiviert ist) und während eines simulierten Failovers der SQL-Prozess auf der vorhandenen virtuellen Maschine neu gestartet wird.
Der manuelle Failover-Befehl in diesem Abschnitt verhält sich üblicherweise in lokalen redundanten und zonenredundanten Konfigurationen auf die gleiche Weise: Er startet den SQL-Prozess nur lokal neu und initiiert kein Failover auf einen anderen Knoten. Es gelten jedoch ein paar Ausnahmen. Dieses lokale Failover unterscheidet sich von einem Failover, das für eine Failovergruppe auftritt.
Ein lokales Failover kann mithilfe von PowerShell, der REST-API oder Azure CLI initiiert werden:
| PowerShell | REST-API | Azure CLI |
|---|---|---|
| Invoke-AzSqlInstanceFailover | SQL Managed Instance: Failover | az sql mi failover kann für einen REST-API-Aufruf über die Azure-Befehlszeilenschnittstelle verwendet werden. |
Schlussbemerkung
Azure SQL Managed Instance verfügt über eine integrierte Hochverfügbarkeitslösung, die tief in die Azure-Plattform integriert ist. Der Dienst hängt von Service Fabric ab, um Ausfälle zu erkennen und wiederherzustellen, von Azure Blob Storage, um Daten zu schützen, und von Verfügbarkeitszonen für höhere Fehlertoleranz. Und für die unternehmenskritische Dienstebene verwendet SQL Managed Instance die SQL Server Always On-Verfügbarkeitsgruppen-Technologie für Datenbank-Replikation und Failover. Dank der Kombination dieser Technologien können Anwendungen die Vorteile eines gemischten Speichermodells voll ausschöpfen und sehr anspruchsvolle SLAs unterstützen.
Nächste Schritte
- Aktivieren Sie Zonenredundanz für Azure SQL Managed Instance.
- Weitere Informationen zu Azure-Verfügbarkeitszonen
- Weitere Informationen zu Service Fabric
- Weitere Informationen zu Azure Traffic Manager
- Erfahren Sie, wie Sie ein Vom Benutzer initiiertes manuelles Failover für SQL Managed Instance durchführen.
- Weitere Optionen für Hochverfügbarkeit und Notfallwiederherstellung finden Sie unter Geschäftskontinuität.