Optimieren der Leistung von Anwendungen und Datenbanken in Azure SQL Managed Instance
Gilt für:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Wenn Sie ein Leistungsproblem mit Azure SQL Managed Instance festgestellt haben, soll Sie dieser Artikel bei folgenden Aktionen unterstützen:
- Optimieren Sie Ihre Anwendung, und wenden Sie einige Best Practices zur Verbesserung der Leistung an.
- Optimieren Sie die Datenbank durch die Änderung von Indizes und Abfragen, um ein effizienteres Arbeiten mit Daten sicherzustellen.
In diesem Artikel wird davon ausgegangen, dass Sie die Übersicht über die Überwachung und Optimierung und Überwachung der Leistung mithilfe der Abfragespeicher gelesen haben. Darüber hinaus wird angenommen, dass kein Leistungsproblem in Zusammenhang mit der Auslastung von CPU-Ressourcen vorliegt, das sich lösen ließe, indem durch Erhöhen der Computegröße oder der Dienstebene Ihrer SQL Managed Instance mehr Ressourcen zur Verfügung gestellt werden.
Hinweis
Einen ähnliche Hilfestellung in Azure SQL-Datenbank finden Sie unter Optimieren der Leistung von Anwendungen und Datenbanken in Azure SQL-Datenbank.
Optimieren der Anwendung
Beim herkömmlichen lokalen Einsatz von SQL Server ist die anfängliche Kapazitätsplanung häufig von der Ausführung einer Anwendung in der Produktion getrennt. Zuerst werden die Hardware und die Produktlizenzen gekauft, und anschließend wird die Leistungsoptimierung durchgeführt. Bei Verwendung von Azure SQL ist es ratsam, den Prozess zur Ausführung und Optimierung einer Anwendung einzubinden. Beim Modell mit der Bezahlung für bedarfsabhängige Kapazität können Sie Ihre Anwendung so optimieren, dass die jeweils benötigten minimalen Ressourcen genutzt werden, anstatt eine Überbereitstellung von Hardware basierend auf dem geschätzten zukünftigen Wachstum einer Anwendung durchzuführen. Diese Schätzungen stimmen häufig nicht.
Einige Kunden entscheiden sich dennoch gegen die Optimierung einer Anwendung und stattdessen für die Überbereitstellung von Hardwareressourcen. Dieser Ansatz kann vorteilhaft sein, wenn Sie für eine wichtige Anwendung während eines Zeitraums mit hoher Auslastung keine Änderungen durchführen möchten. Durch das Optimieren einer Anwendung können aber Ressourcenanforderungen minimiert und monatliche Rechnungen reduziert werden.
Bewährte Methoden und Antipattern im Anwendungsentwurf für Azure SQL Managed Instance
Azure SQL Managed Instance-Dienstebenen sind zwar für die Verbesserung der Leistungsstabilität und Vorhersagbarkeit für eine Anwendung ausgelegt, allerdings es gibt einige bewährte Methoden, mit denen Sie Ihre Anwendung so optimieren können, dass die Ressourcen einer Computegröße besser genutzt werden. Bei vielen Anwendungen können Sie zwar erhebliche Leistungsgewinne erzielen, indem Sie einfach auf eine höhere Computegröße oder einen höheren Diensttarif umstellen. Für einige Anwendungen ist jedoch eine weitere Optimierung erforderlich, um von einer höheren Dienstebene zu profitieren.
Sie können zur Steigerung der Leistung eine zusätzliche Optimierung von Anwendungen erwägen, die über die folgenden Merkmale verfügen:
Anwendungen mit langsamer Leistung aufgrund von vielen Einzelaufrufen
Sie müssen diese Arten von Anwendungen ggf. ändern, um die Anzahl der Datenzugriffe auf die Datenbank zu reduzieren. Beispielsweise können Sie die Anwendungsleistung verbessern, indem Sie Verfahren wie das Zusammenfassen von Ad-hoc-Abfragen in Batches oder das Verschieben der Abfragen in gespeicherte Prozeduren verwenden. Weitere Informationen finden Sie unter Batch-Abfragen.
Datenbanken mit einer intensiven Workload, die nicht von einem gesamten einzelnen Computer unterstützt werden können
Datenbanken, welche die Ressourcen der höchsten Premium-Computegröße überschreiten, können vom horizontalen Hochskalieren der Workload profitieren. Weitere Informationen finden Sie unter Datenbankübergreifendes Sharding und Funktionale Partitionierung.
Anwendungen mit suboptimalen Abfragen
Anwendungen mit unzureichend optimierten Abfragen profitieren möglicherweise nicht von einer höheren Computegröße. Dies umfasst auch Abfragen, die keine WHERE-Klausel aufweisen, bei denen Indizes fehlen oder die über veraltete Statistiken verfügen. Diese Anwendungen profitieren von Standardverfahren zur Optimierung der Abfrageleistung. Weitere Informationen finden Sie unter Fehlende Indizes und Abfrageoptimierung/Abfragehinweise.
Anwendungen mit suboptimalem Datenzugriffsdesign
Anwendungen, die über inhärente Parallelitätsprobleme in Bezug auf den Datenzugriff verfügen (z.B. „Deadlocking“) profitieren ggf. nicht von einer höheren Computegröße. Erwägen Sie die Reduzierung von Roundtrips für die Datenbank, indem Daten auf Clientseite mit dem Azure-Cachedienst oder einer anderen Cachingtechnologie zwischengespeichert werden. Weitere Informationen finden Sie unter Zwischenspeicherung auf Anwendungsebene.
Informationen zur Vorbeugung von Deadlocks in Azure SQL Managed Instance finden Sie im Leitfaden zu Deadlocks unter Deadlock-Tools.
Optimieren der Datenbank
In diesem Abschnitt werden einige Verfahren beschrieben, mit denen Sie die Datenbank so optimieren können, dass Sie für Ihre Anwendung die beste Leistung erzielen und für die Ausführung die kleinstmögliche Computegröße wählen können. Einige dieser Verfahren sind mit herkömmlichen bewährten Methoden zum Optimieren von SQL Server identisch, während sich andere speziell auf Azure SQL Managed Instance beziehen. In einigen Fällen können Sie die verbrauchten Ressourcen für eine Datenbank untersuchen, um Bereiche zu ermitteln, die weiter optimiert werden können, und herkömmliche SQL Server-Verfahren so zu erweitern, dass sie auch für Azure SQL Managed Instance geeignet sind.
Bestimmen und Hinzufügen fehlender Indizes
Ein häufiges Problem in Bezug auf die OLTP-Datenbankleistung ist der physische Datenbankentwurf. Datenbankschemas werden häufig entworfen und bereitgestellt, ohne dass Skalierungstests durchgeführt werden (entweder in Bezug auf die Auslastung oder das Datenvolumen). Leider kann es passieren, dass die Leistung eines Abfrageplans auf niedriger Ebene akzeptabel ist, dann jedoch erheblich nachlässt, wenn Datenvolumina auf Produktionsebene verarbeitet werden müssen. Die häufigste Ursache dieses Problems ist das Fehlen geeigneter Indizes für Filter oder andere Einschränkungen in einer Abfrage. Das Fehlen von Indizes manifestiert sich häufig als Tabellenscan, wenn eine Indexsuche ausreichend wäre.
In diesem Beispiel wird für den ausgewählten Abfrageplan ein Scan genutzt, obwohl eine Suche ausreichen würde:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
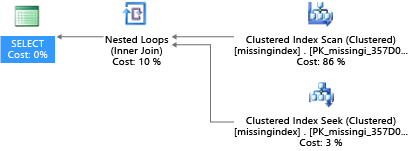
Mit seit 2005 in SQL Server integrierten DMVs wird die Abfragenkompilierung daraufhin untersucht, ob ein Index die geschätzten Kosten zum Ausführen einer Abfrage erheblich reduzieren würde. Während der Abfrageausführung wird mit der Datenbank-Engine nachverfolgt, wie häufig jeder Abfrageplan ausgeführt wird. Außerdem wird die geschätzte Differenz zwischen dem ausgeführten Abfrageplan und dem imaginären Abfrageplan mit dem Index nachverfolgt. Sie können diese DMVs verwenden, um schnell abzuschätzen, welche Änderungen am physischen Datenbankdesign zu einer Verbesserung der Workload-Gesamtkosten für eine Datenbank und der tatsächlichen Workload führen können.
Sie können die folgende Abfrage verwenden, um eventuell fehlende Indizes zu ermitteln:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
In diesem Beispiel hat die Abfrage zu folgender Empfehlung geführt:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Nach der Erstellung wählt dieselbe SELECT-Anweisung einen anderen Plan, bei der anstelle eines Scans eine Suche verwendet und der Plan dann effizienter ausgeführt wird:
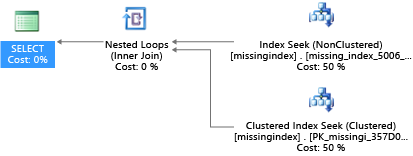
Die wichtigste Erkenntnis besteht darin, dass die E/A-Kapazität eines freigegebenen Warensystems mit mehr Einschränkungen als ein dedizierter Servercomputer versehen ist. Es ist wichtig, unnötige E/A-Vorgänge in den Ressourcen der einzelnen Computegrößen der Dienstebenen zu minimieren, um das System bestmöglich zu nutzen. Die Wahl des richtigen Designs der physischen Datenbank kann die Latenz für einzelne Abfragen und den Durchsatz gleichzeitiger Anforderungen pro Skalierungseinheit erheblich verbessern und die erforderlichen Kosten zur Erfüllung der Abfrage reduzieren.
Weitere Informationen zum Optimieren von Indizes mithilfe fehlender Indexanforderungen finden Sie unter Optimieren nicht gruppierter Indizes mit fehlenden Indexvorschlägen.
Abfrageoptimierung/Abfragehinweise
Der Abfrageoptimierer in Azure SQL Managed Instance ähnelt dem herkömmlichen Abfrageoptimierer von SQL Server. Die meisten bewährten Methoden zum Optimieren von Abfragen und Verstehen der Einschränkungen des Argumentationsmodells für den Abfrageoptimierer gelten auch für Azure SQL Managed Instance. Wenn Sie in Azure SQL Managed Instance Abfragen optimieren, profitieren Sie u. U. zusätzlich davon, dass sich die Ressourcenanforderungen insgesamt verringern. Ihre Anwendung kann unter Umständen zu geringeren Kosten als eine nicht optimierte gleichwertige Anwendung ausgeführt werden, weil Sie eine niedrigere Computegröße auswählen können.
Ein häufiges Beispiel für SQL Server, das auch für Azure SQL Managed Instance gilt, ist das Ermitteln (Englisch: Sniffing) von Parametern durch den Abfrageoptimierer. Während der Kompilierung wertet der Abfrageoptimierer den aktuellen Wert eines Parameters aus, um zu bestimmen, ob ein besserer Abfrageplan generiert werden kann. Diese Strategie kann zwar häufig zu einem Abfrageplan führen, der deutlich schneller als ein ohne bekannte Parameterwerte kompilierter Plan ist, aber derzeit funktioniert dies in Azure SQL Managed Instance nicht fehlerfrei. (Ein neues Feature für intelligente Abfrageleistung, das mit SQL Server 2022 mit dem Namen „Parameterabhängige Planoptimierung“ eingeführt wurde und das Szenario behebt, in dem ein einzelner zwischengespeicherter Plan für eine parametrisierte Abfrage für alle möglichen eingehenden Parameterwerte nicht optimal ist. Die Parameterabhängige Planoptimierung ist derzeit in Azure SQL Managed Instance nicht verfügbar.)
Es kann vorkommen, dass der Parameter nicht ermittelt wird oder dass er zwar ermittelt wird, der generierte Plan für den vollständigen Satz mit Parameterwerten in einer Workload aber nicht optimal ist. Microsoft bindet Abfragehinweise (Direktiven) ein, damit Sie Ihre Absichten besser angeben und das Standardverhalten der Parameterermittlung außer Kraft setzen können. Sie können Hinweise verwenden, wenn das Standardverhalten für eine bestimmte Kundenarbeitsauslastung unvollkommen ist.
Im nächsten Beispiel wird veranschaulicht, wie der Abfrageprozessor einen Plan generieren kann, der sowohl für Leistungs- als auch für Ressourcenanforderungen suboptimal ist. Dieses Beispiel verdeutlicht auch Folgendes: Wenn Sie einen Abfragehinweis verwenden, können Sie die Abfragelaufzeit und die Ressourcenanforderungen für Ihre Datenbank reduzieren:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Der Setupcode erstellt eine Tabelle mit unregelmäßig verteilten Daten in der t1-Tabelle. Der optimale Abfrageplan variiert in Abhängigkeit davon, welcher Parameter ausgewählt wird. Leider führt das Cachingverhalten des Plans nicht immer zu einer Neukompilierung der Abfrage, die auf dem häufigsten Parameterwert basiert. Es ist also möglich, dass ein suboptimaler Plan auch dann zwischengespeichert und für viele Werte verwendet wird, wenn ein anderer Plan generell eine bessere Wahl wäre. Anschließend erstellt der Abfrageplan zwei gespeicherte Prozeduren, die identisch sind, aber mit der Ausnahme, dass eine Prozedur einen speziellen Abfragehinweis aufweist.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Es ist ratsam, mindestens zehn Minuten zu warten, bevor Sie mit Teil 2 des Beispiels beginnen, damit die Ergebnisse in den resultierenden Telemetriedaten unterschiedlich sind.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
In jedem Teil dieses Beispiels wird versucht, eine parametrisierte Einfügeanweisung 1.000-mal auszuführen (zum Generieren einer ausreichenden Last für einen Testdatensatz). Beim Ausführen von gespeicherten Prozeduren untersucht der Abfrageprozessor den Parameterwert, der während der ersten Kompilierung an die Prozedur übergeben wird („Parameterermittlung“). Der Prozessor speichert den sich ergebenden Plan auch dann zwischen und verwendet ihn für spätere Aufrufe, wenn der Parameterwert anders ist. Der optimale Plan wird unter Umständen nicht immer verwendet. In einigen Fällen müssen Sie den Optimierer zur Auswahl eines Plans leiten, der für den Durchschnittsfall besser geeignet ist, anstatt der spezielle Fall, für den die Abfrage kompiliert wurde. In diesem Beispiel wird vom anfänglichen Plan ein „Scanplan“ generiert. Dieser liest alle Zeilen, um die einzelnen Werte zu ermitteln, die mit dem Parameter übereinstimmen:

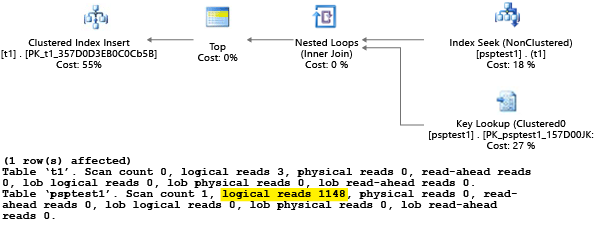
Da die Prozedur mit dem Wert 1 ausgeführt wurde, war der sich ergebende Plan für Wert 1 optimal, aber für alle anderen Werte der Tabelle suboptimal. Dies ist wahrscheinlich nicht das gewünschte Ergebnis, wenn Sie jeden Plan zufällig auswählen, da der Plan langsamer ist und mehr Ressourcen benötigt.
Wenn Sie den Test mit Festlegung von SET STATISTICS IO auf ON ausführen, werden die Schritte des logischen Scans in diesem Beispiel im Hintergrund ausgeführt. Sie sehen, dass vom Plan 1.148 Lesevorgänge ausgeführt werden (was nicht effizient ist, wenn im Normalfall nur eine Zeile zurückgegeben werden soll):

Im zweiten Teil des Beispiels wird ein Abfragehinweis verwendet, um den Optimierer anzuweisen, während des Kompilierungsprozesses einen bestimmten Wert zu verwenden. In diesem Fall wird erzwungen, dass der Abfrageprozessor den Wert ignoriert, der als Parameter übergeben wird, und stattdessen UNKNOWNannimmt. Bezieht sich auf einen Wert, der in der Tabelle für die durchschnittliche Häufigkeit angegeben ist (Datenschiefe wird ignoriert). Der sich ergebende Plan ist ein suchbasierter Plan, der im Durchschnitt schneller und ressourcenschonender als der Plan aus Teil 1 dieses Beispiels ist:
Sie können den Effekt in der sys.server_resource_stats Systemkatalogsicht sehen. Die Daten werden in Intervallen von 5 bis 10 Minuten gesammelt, aggregiert und aktualisiert. Für jede 15-Sekunden-Berichterstattung ist eine Zeile vorhanden. Beispiel:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Sie können sys.server_resource_stats überprüfen, um zu ermitteln, ob die Ressource für einen Test mehr oder weniger Ressourcen als für einen anderen Test verwendet. Beim Vergleichen von Daten sollten Sie Tests zeitlich ausreichend trennen, damit sie sich in der Ansicht sys.server_resource_stats nicht in demselben 5-Minuten-Fenster bewegen. Ziel dieser Übung ist die Minimierung der Gesamtmenge an verwendeten Ressourcen, und nicht die Minimierung der Ressourcen bei Spitzenlast. Im Allgemeinen führt eine Optimierung eines Codeabschnitts in Bezug auf die Latenz auch zu einem verringerten Ressourcenverbrauch. Stellen Sie sicher, dass die an einer Anwendung vorgenommenen Änderungen auch notwendig sind und dass die Änderungen keine negativen Auswirkungen auf die Benutzerfreundlichkeit haben, wenn Benutzer in der Anwendung Abfragehinweise verwenden.
Wenn eine Workload eine Gruppe von sich wiederholenden Abfragen enthält, ist es häufig sinnvoll, den Optimierungsgrad Ihrer Planentscheidungen zu erfassen und zu überprüfen. Dies hat nämlich Auswirkungen auf die Mindestgrößeneinheit für Ressourcen, die zum Hosten der Datenbank erforderlich ist. Untersuchen Sie die Pläne nach der ersten Überprüfung gelegentlich erneut, um sicherzustellen, dass sie nicht veraltet sind. Weitere Informationen finden Sie unter Abfragehinweise (Transact-SQL).
Bewährte Methoden für sehr große Datenbankarchitekturen in Azure SQL Managed Instance
In den folgenden beiden Abschnitten werden zwei Optionen für das Beheben von Problemen mit sehr großen Datenbanken in Azure SQL Managed Instance beschrieben.
Datenbankübergreifendes Sharding
Da Azure SQL Managed Instance auf handelsüblicher Hardware ausgeführt wird, gelten für eine Einzeldatenbank niedrigere Kapazitätsgrenzen als für eine herkömmliche lokale SQL Server-Installation. Einige Kunden verwenden Shardingverfahren, um Datenbankvorgänge auf mehrere Datenbanken zu verteilen, wenn diese die Limits für Einzeldatenbanken in Azure SQL Managed Instance überschreiten. Die meisten Kunden, die Shardingverfahren in Azure SQL Managed Instance verwenden, teilen ihre Daten in einer einzelnen Dimension auf mehrere Datenbanken auf. Bei diesem Ansatz muss verinnerlicht werden, dass von OLTP-Anwendungen häufig Transaktionen durchgeführt werden, die nur für eine Zeile oder eine kleine Gruppe von Zeilen im Schema gelten.
Wenn eine Datenbank beispielsweise Kundennamen, Bestellungen und Bestelldetails enthält (wie in der AdventureWorks-Datenbank), können Sie diese Daten auf mehrere Datenbanken aufteilen. Hierzu wird ein Kunde mit den zugehörigen Bestellinformationen und -details gruppiert. Sie können dafür sorgen, dass die Daten des Kunden in einer Einzeldatenbank verbleiben. Bei dieser Anwendung würden unterschiedliche Kunden auf verschiedene Datenbanken verteilt werden, um eine effektive Verteilung der Last auf mehrere Datenbanken zu erreichen. Beim Sharding können Kunden nicht nur verhindern, dass sie das Limit für die Datenbankgröße erreichen. Zusätzlich können Azure SQL Managed Instance auch die Verarbeitung von Workloads ermöglichen, die die Limits der unterschiedlichen Computegrößen deutlich überschreiten, solange jede einzelne Datenbank die Limits der Dienstebene nicht überschreitet.
Auch wenn beim Datenbanksharding die aggregierte Ressourcenkapazität für eine Lösung nicht reduziert wird, ist dieses Verfahren äußerst effektiv zur Unterstützung sehr großer Lösungen, die auf mehrere Datenbanken verteilt sind. Jede Datenbank kann mit einer anderen Computegröße ausgeführt werden, um sehr große, „effektive“ Datenbanken mit hohen Ressourcenanforderungen zu unterstützen.
Funktionale Partitionierung
Es kommt häufig vor, dass Benutzer viele Funktionen in einer Einzeldatenbank kombinieren. Wenn eine Anwendung beispielsweise Logik zum Verwalten des Bestands für einen Store enthält, kann die Datenbank Logik für die Bereiche Bestand, Nachverfolgung von Bestellungen, gespeicherte Prozeduren und indizierte/materialisierte Sichten zum Verwalten der Berichterstellung für den Monatsabschluss enthalten. Dieses Verfahren vereinfacht die Verwaltung der Datenbank für Vorgänge wie die Sicherung. Es erfordert aber auch, dass Sie die Größe der Hardware so bemessen, dass die Spitzenlast über alle Funktionen einer Anwendung hinweg bewältigt werden kann.
Wenn Sie eine Architektur mit horizontaler Skalierung in Azure SQL Managed Instance verwenden, ist es vorteilhaft, die Funktionen einer Anwendung auf unterschiedliche Datenbanken zu verteilen. Mit diesem Verfahren wird jede Anwendung unabhängig von anderen skaliert. Wenn die Auslastung einer Anwendung steigt (und somit auch die Auslastung der Datenbank), kann der Administrator unabhängige Computegrößen für jede Funktion in der Anwendung auswählen. Unter Berücksichtigung der Obergrenze kann eine Anwendung bei dieser Architektur eine Größe erreichen, die von einem einzelnen normalen Computer nicht mehr bewältigt werden kann, da die Last auf mehrere Computer verteilt wird.
Batch-Abfragen
Bei Anwendungen, die mit häufigen, hochvolumigen Ad-hoc-Abfragen auf Daten zugreifen, entfällt ein Großteil der Antwortzeit auf die Netzwerkkommunikation zwischen der Logikschicht und Datenbankebene. Auch wenn sich die Anwendung und die Datenbank im selben Rechenzentrum befinden, kann sich die Netzwerklatenz zwischen beiden Komponenten durch eine große Anzahl von Datenzugriffen erhöhen. Um die Netzwerkroundtrips für die Datenzugriffsvorgänge zu reduzieren, können Sie die Option zum Zusammenfassen von Ad-hoc-Abfragen in Batches oder zum Kompilieren als gespeicherte Prozeduren verwenden. Wenn Sie Ad-hoc-Abfragen in einem Batch verarbeiten, können Sie mehrere Abfragen in einem großen Batch an die Datenbank senden. Wenn Sie Ad-hoc-Abfragen in einer gespeicherten Prozedur kompilieren, können Sie das gleiche Ergebnis wie beim Zusammenfassen zu Batches erzielen. Durch die Verwendung einer gespeicherten Prozedur erhöht sich auch die Wahrscheinlichkeit, dass die Abfragepläne in der Datenbank zwischengespeichert werden, sodass Sie die gespeicherte Prozedur erneut verwenden können.
Einige Anwendungen sind mit vielen Schreibvorgängen verbunden. In einigen Fällen ist es auch möglich, die E/A-Gesamtlast einer Datenbank zu reduzieren, indem geprüft wird, wie Schreibvorgänge zu Batches zusammengefasst werden können. Dies ist häufig so einfach wie die Verwendung von expliziten Transaktionen anstelle von Transaktionen mit automatischem Commit innerhalb von gespeicherten Prozeduren und Ad-hoc-Batches. Eine Auswertung unterschiedlicher Verfahren, die verwendet werden können, finden Sie unter Stapelverarbeitungsverfahren für Datenbankanwendungen in Azure. Experimentieren Sie mit Ihrer eigenen Workload, um das richtige Modell für die Erstellung von Batches zu ermitteln. Achten Sie hierbei darauf, dass ein Modell ggf. etwas andere Konsistenzgarantien in Bezug auf Transaktionen aufweisen kann. Für die Ermittlung der richtigen Workload, bei der die Ressourcenverwendung reduziert wird, ist die richtige Kombination aus Konsistenz und Abstrichen bei der Leistung erforderlich.
Zwischenspeichern auf Anwendungsebene
Einige Datenbankanwendungen verfügen über Workloads mit einer hohen Zahl von Lesevorgängen. Cachingschichten können zu einer Reduzierung der Datenbanklast und ggf. auch der Computegröße beitragen, die zum Unterstützen einer Datenbank mit Azure SQL Managed Instance erforderlich ist. Mit Azure Cache for Redis können Sie die Daten leseintensiver Workloads einmalig (oder je nach der Konfiguration ggf. einmal pro Computer auf Anwendungsebene) lesen lassen und diese Daten dann außerhalb der Datenbank speichern. Dies stellt eine Möglichkeit zur Reduzierung der Datenbanklast (CPU- und Lesevorgangs-E/A) dar, die aber Auswirkungen auf die Transaktionskonsistenz hat, da die aus dem Cache gelesenen Daten ggf. nicht mehr mit den Daten in der Datenbank synchron sind. Es gibt zwar viele Anwendungen, bei denen ein gewisser Inkonsistenzgrad akzeptabel ist, aber dies gilt nicht für alle Workloads. Sie sollten sich daher vollständig mit den Anwendungsanforderungen vertraut machen, bevor Sie eine Cachingstrategie auf Anwendungsebene implementieren.
Zugehöriger Inhalt
- vCore-Kaufmodell: Azure SQL Managed Instance
- Konfigurieren von tempdb-Einstellungen für Azure SQL Managed Instance
- Überwachen der Leistung von Microsoft Azure SQL Managed Instance mithilfe von dynamischen Verwaltungssichten
- Optimieren nicht gruppierter Indizes mit Vorschlägen für fehlende Indizes
- Verwenden einer verwalteten Azure SQL-Instanz mit Azure Monitor
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für