Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() SQL-Datenbank in Fabric
SQL-Datenbank in Fabric
Datenbanken mit mehreren Modellen ermöglichen Ihnen das Speichern von und Arbeiten mit Daten in verschiedenen Formaten, darunter z. B. relationale Daten, Graphen, JSON- oder XML-Dokumente, räumliche Daten und Schlüssel-Wert-Paare.
Die Azure SQL-Produktfamilie verwendet ein relationales Modell, das für eine Vielzahl universeller Anwendungen die beste Leistung bietet. Azure SQL-Produkte wie Azure SQL-Datenbank und SQL Managed Instance sind jedoch nicht auf relationale Daten beschränkt. Sie ermöglichen die Nutzung einer Vielzahl von nicht relationalen Formaten, die eng in das relationale Modell integriert sind.
Ziehen Sie in folgenden Fällen die Verwendung der Azure SQL-Funktionen für mehrere Modelle in Betracht:
- Sie verfügen über einige Informationen oder Strukturen, die für NoSQL-Modelle besser geeignet sind, und möchten keine separate NoSQL-Datenbank verwenden.
- Ein Großteil Ihrer Daten eignet sich für ein relationales Modell, aber Sie müssen bestimmte Teile Ihrer Daten im NoSQL-Format modellieren.
- Sie möchten die Transact-SQL-Sprache zum Abfragen und Analysieren von relationalen und NoSQL-Daten nutzen und diese Daten anschließend in Tools und Anwendung integrieren, die die SQL-Sprache verwenden können.
- Sie möchten Datenbankfeatures wie z. B. In-Memory-Technologien anwenden, um die Leistung der Analyse oder Verarbeitung Ihrer NoSQL-Datenstrukturen zu verbessern. Sie können die Transaktionsreplikation oder Lesereplikate verwenden, um Kopien Ihrer Daten zu erstellen und einige Analyseworkloads aus der primären Datenbank auszulagern.
In den folgenden Abschnitten werden die wichtigsten Funktionen für mehrere Modelle von Azure SQL beschrieben.
Hinweis
Sie können JSONPath-Ausdrücke, XQuery/XPath-Ausdrücke, räumliche Funktionen und Ausdrücke zur Graphabfrage in ein und derselben Transact-SQL-Abfrage verwenden, um auf beliebige in der Datenbank gespeicherte Daten zuzugreifen. Darüber hinaus können alle Tools und Programmiersprachen, die Transact-SQL-Abfragen ausführen können, diese Abfrageschnittstelle für den Zugriff auf Daten in mehreren Modellen nutzen. Dies ist der wesentliche Unterschied zu Multi-Modell-Datenbanken wie z. B. Azure Cosmos DB, die spezialisierte APIs für Datenmodelle bereitstellen.
Diagrammfunktionen
Azure SQL-Produkte stellen Graphdatenbankfunktionen bereit, mit denen Sie m:n-Beziehungen in einer Datenbank modellieren können. Ein Graph ist eine Sammlung aus Knoten (oder Scheitelpunkten) und Kanten (oder Beziehungen). Ein Knoten repräsentiert eine Entität (z. B. eine Person oder eine Organisation). Ein Edge repräsentiert eine Beziehung zwischen den beiden Knoten, die es verbindet (z. B. Likes oder Freunde).
Folgende Features machen eine Graphdatenbank einmalig:
- Edges sind Entitäten erster Klasse in einer Graphdatenbank. Ihnen können Attribute oder Eigenschaften zugeordnet sein.
- Ein einzelner Edge kann flexibel mehrere Knoten in einer Graphdatenbank verbinden.
- Musterabgleiche und Navigationsabfragen über mehrere Hops lassen sich ganz einfach ausdrücken.
- Transitive Abschlüsse und polymorphe Abfragen lassen sich ebenfalls sehr einfach ausdrücken.
Graphbeziehungen und Graphabfragefunktionen sind in Transact-SQL integriert und profitieren von den Vorteilen der SQL Server-Datenbank-Engine als grundlegendes Datenbankverwaltungssystem. Graphfunktionen verwenden Transact-SQL-Standardabfragen, die um dem Graphoperator MATCH erweitert wurden, um die Graphdaten abzufragen.
Mit einer relationalen Datenbank können alle Aufgaben erfüllt werden, die mit einer Graphdatenbank möglich sind. Eine Graphdatenbank vereinfacht aber den Ausdruck bestimmter Abfragen. Bei Ihrer Entscheidung für einen dieser Ansätze sollten Sie die folgenden Aspekte berücksichtigen:
- Sie müssen hierarchische Daten modellieren, bei denen ein Knoten mehrere übergeordnete Knoten aufweisen kann, sodass Sie den hierarchyId-Datentyp nicht verwenden können.
- Ihre Anwendung umfasst komplexe n:n-Beziehungen. Wenn sich die Anwendung weiterentwickelt, werden neue Beziehungen hinzugefügt.
- Sie müssen miteinander verbundene Daten und Beziehungen analysieren.
- Sie möchten graphspezifische T-SQL-Suchbedingungen verwenden, z. B. SHORTEST_PATH.
JSON-Funktionen
In Azure SQL-Produkten können Sie Daten im JavaScript Object Notation-Format (JSON) analysieren und abfragen, und Sie können Ihre relationalen Daten als JSON-Text exportieren. JSON ist eine Kernfunktion der SQL Server-Datenbank-Engine.
JSON-Features ermöglichen es Ihnen, JSON-Dokumente in Tabellen zu platzieren, relationale Daten in JSON-Dokumente und JSON-Dokumente in relationale Daten zu transformieren. Sie können die Transact-SQL-Standardsprache verwenden, die mit JSON-Funktionen zum Analysieren von Dokumenten erweitert wurde. Sie können außerdem nicht gruppierte Indizes, Columnstore-Indizes oder speicheroptimierte Tabellen nutzen, um Ihre Abfragen zu optimieren.
JSON ist ein populäres Datenformat zum Austausch von Daten in modernen Web- und mobilen Anwendungen. JSON wird außerdem zum Speichern von teilstrukturierten Daten in Protokolldateien oder in NoSQL-Datenbanken. Viele REST-Webdienste geben Ergebnisse als JSON-Text formatiert zurück oder akzeptieren Daten, die im JSON-Format formatiert sind.
Die meisten Azure-Dienste verfügen über REST-Endpunkte, die Daten im JSON-Format zurückgeben oder verarbeiten. Zu diesen Diensten gehören Azure Cognitive Search, Azure Storage und Azure Cosmos DB.
Mithilfe der integrierten Funktionen JSON_VALUE, JSON_QUERY und ISJSON können Sie Daten aus einem JSON-Text extrahieren oder überprüfen, ob er ordnungsgemäß formatiert ist. Die weiteren Funktionen sind:
- JSON_MODIFY: Ermöglicht die Aktualisierung von Werten innerhalb von JSON-Text.
- OPENJSON: Ermöglicht die Transformation eines Arrays von JSON-Objekten in eine Reihe von Zeilen für eine erweiterte Abfrage und Analyse. Für das zurückgegebene Resultset kann eine beliebige SQL-Abfrage ausgeführt werden.
- FOR JSON: Ermöglicht die Formatierung von in relationalen Tabellen gespeicherten Daten als JSON-Text.
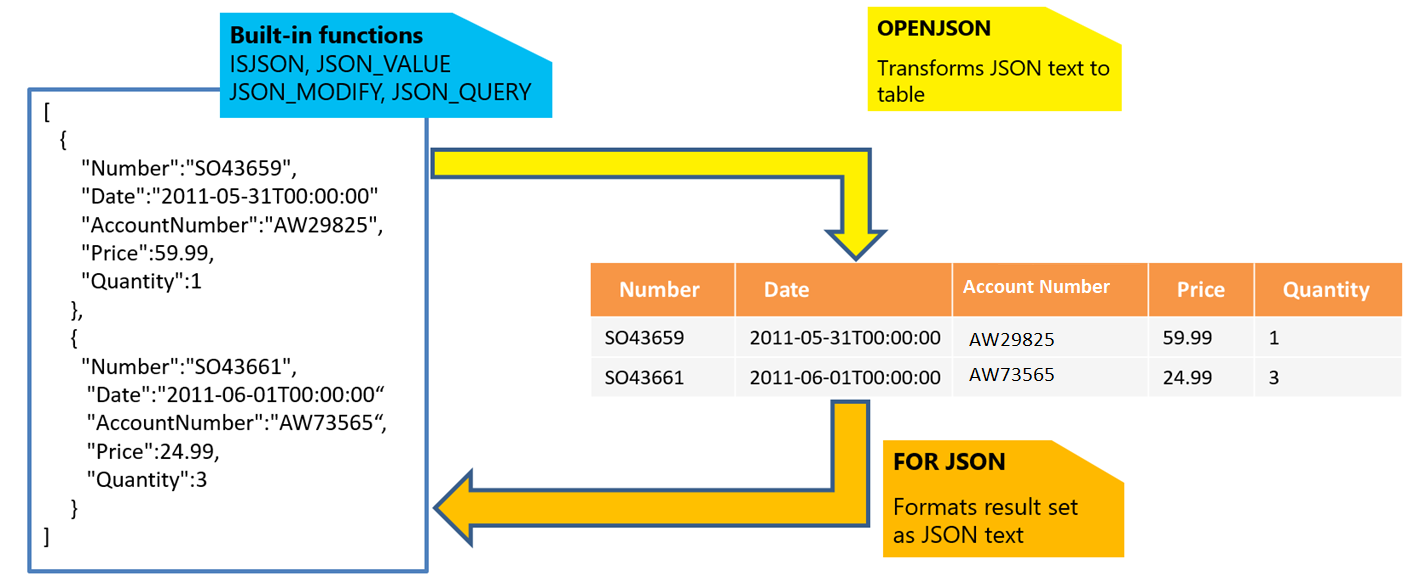
Weitere Informationen finden Sie unter Arbeiten mit JSON-Daten.
In einigen speziellen Szenarien können Sie anstelle von relationalen Modellen Dokumentmodelle verwenden:
- Ein hohes Maß an Normalisierung des Schemas bietet keine nennenswerten Vorteile, da Sie auf alle Felder der Objekte gleichzeitig zugreifen oder normalisierte Teile der Objekte nie aktualisieren. Das normalisierte Modell erhöht jedoch die Komplexität Ihrer Abfragen, weil Sie zum Abrufen der Daten eine große Anzahl von Tabellen verknüpfen müssen.
- Sie arbeiten mit Anwendungen, die für Kommunikation oder Datenmodelle nativ JSON-Dokumente verwenden, und Sie möchten keine weiteren Ebenen einführen, die relationale Daten in JSON und umgekehrt transformieren.
- Sie müssen Ihr Datenmodell vereinfachen, indem Sie untergeordnete Tabellen oder Entität-Objekt-Wert-Muster denormalisieren.
- Sie müssen im JSON-Format gespeicherte Daten laden oder exportieren, ohne ein zusätzliches Tool zum Analysieren der Daten zu verwenden.
XML-Funktionen
Mit XML-Funktionen können Sie XML-Daten in Ihrer Datenbank speichern und indizieren und native XQuery/XPath-Vorgänge für die Arbeit mit XML-Daten verwenden. Azure SQL-Produkte umfassen einen spezialisierten, integrierten XML-Datentyp und Abfragefunktionen zum Verarbeiten von XML-Daten.
Die SQL Server-Datenbank-Engine stellt eine leistungsstarke Plattform für die Entwicklung von Anwendungen zum Verwalten teilstrukturierter Daten bereit. Die XML-Unterstützung ist in alle Komponenten der Datenbank-Engine integriert und umfasst Folgendes:
- XML-Werte können nativ in einer XML-Datentypspalte gespeichert werden, die untypisiert gelassen oder gemäß einer Sammlung von XML-Schemas typisiert werden kann. Sie können die XML-Spalte indizieren.
- Es kann eine XQuery-Abfrage für in Spalten gespeicherte XML-Daten und Variablen des XML-Typs angegeben werden. XQuery-Funktionen können in jeder Transact-SQL-Abfrage verwendet werden, die auf ein in Ihrer Datenbank verwendetes Datenmodell zugreift.
- Automatische Indizierung aller Elemente in XML-Dokumenten mit dem primären XML-Index. Alternativ können Sie über den sekundären XML-Index die genauen Pfade angeben, die indiziert werden sollen.
OPENROWSETermöglicht das Massenladen von XML-Daten.- Relationale Daten können in das XML-Format transformiert werden.
In einigen speziellen Szenarien können Sie anstelle von relationalen Modellen Dokumentmodelle verwenden:
- Ein hohes Maß an Normalisierung des Schemas bietet keine nennenswerten Vorteile, da Sie auf alle Felder der Objekte gleichzeitig zugreifen oder normalisierte Teile der Objekte nie aktualisieren. Das normalisierte Modell erhöht jedoch die Komplexität Ihrer Abfragen, weil Sie zum Abrufen der Daten eine große Anzahl von Tabellen verknüpfen müssen.
- Sie arbeiten mit Anwendungen, die für Kommunikation oder Datenmodelle nativ XML-Dokumente verwenden, und Sie möchten keine weiteren Ebenen einführen, die relationale Daten in JSON und umgekehrt transformieren.
- Sie müssen Ihr Datenmodell vereinfachen, indem Sie untergeordnete Tabellen oder Entität-Objekt-Wert-Muster denormalisieren.
- Sie müssen im XML-Format gespeicherte Daten laden oder exportieren, ohne ein zusätzliches Tool zum Analysieren der Daten zu verwenden.
Räumliche Funktionen
Räumliche Daten repräsentieren Informationen zur physischen Position und Form von Objekten. Diese Objekte können Punktpositionen oder komplexere Objekte wie Länder/Regionen, Straßen oder Seen sein.
Azure SQL unterstützt zwei Arten von räumlichen Daten:
- Der geometrische Datentyp stellt Daten in einem euklidischen (flachen) Koordinatensystem dar.
- Der geografische Datentyp stellt Daten in einem Erdkugel-Koordinatensystem dar.
Räumliche Features in Azure SQL ermöglichen Ihnen das Speichern geometrischer und geografischer Daten. Sie können räumliche Objekte in Azure SQL nutzen, um im JSON-Format dargestellte Daten zu analysieren und abzufragen und Ihre relationalen Daten als JSON-Text zu exportieren. Zu den räumlichen Objekten gehören z. B. Point, LineString und Polygon. Azure SQL stellt außerdem spezielle räumliche Indizes bereit, mit denen Sie die Leistung Ihrer räumlichen Abfragen verbessern können.
Die räumliche Unterstützung ist eine Kernfunktion der SQL Server-Datenbank-Engine.
Schlüssel-Wert-Paare
Azure SQL-Produkte umfassen keine speziellen Typen oder Strukturen, die Schlüssel-Wert-Paar unterstützen, da Schlüssel-Wert-Strukturen nativ als relationale Standardtabellen dargestellt werden können:
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
Sie können diese Schlüssel-Wert-Struktur ohne jede Einschränkung an Ihre Anforderungen anpassen. Beispielsweise kann der Wert anstelle des Typs nvarchar(max) als XML-Dokument vorliegen. Wenn der Wert ein JSON-Dokument ist, können Sie mithilfe einer CHECK-Einschränkung die Gültigkeit des JSON-Inhalts überprüfen. Sie können eine beliebige Anzahl von Werten, die sich auf einen Schlüssel beziehen, in der zusätzlichen Spalten platzieren. Zum Beispiel:
- Fügen Sie berechnete Spalten und Indizes hinzu, um den Datenzugriff zu vereinfachen und zu optimieren.
- Definieren Sie die Tabelle als speicheroptimierte, schemabasierte Tabelle, um eine bessere Leistung zu erzielen.
Ein Beispiel dafür, wie ein relationales Modell effizient als Schlüssel-Wert-Paar-Lösung in der Praxis verwendet werden kann, finden Sie unter Wie bwin mit SQL Server 2016 In-Memory OLTP eine beispiellose Leistung und Skalierung erreicht. In dieser Fallstudie nutzt bwin ein relationales Modell für seine ASP.NET-Cachinglösung, um 1,2 Millionen Batches pro Sekunde zu erzielen.
Nächste Schritte
Die Funktionen für mehrere Modelle sind Kernfunktionen der SQL Server-Datenbank-Engine, die von Azure SQL-Produkten gemeinsam genutzt werden. Weitere Informationen zu diesen Features finden Sie in diesen Artikeln: