Servicelevelziele für die Cloudüberwachung
Dieser Artikel ist Teil einer Reihe im Leitfaden zur Cloudüberwachung.
In den folgenden Abschnitten erfahren Sie mehr über die Grundprinzipien der Servicelevelziele und deren Implementierung und Anwendung.
Übersicht
Servicelevelziele (SLOs) sind messbare Ziele, die für wichtige kundenorientierte Servicelevelindikatoren (SLIs) festgelegt werden. Sie messen die Erfahrungen Ihrer Kunden mit einer Geschäfts- oder Infrastrukturworkload und ermitteln, ob der Dienstanbieter des Unternehmens die Versprechen einhält, die in einer formell ausgehandelten Vereinbarung zum Servicelevel (SLA) oder einer informellen Vereinbarung zwischen allen Parteien festgelegt wurden.
Als Service Broker verlassen Sie sich auf die Zusage von Microsoft hinsichtlich der Zuverlässigkeit der Dienste, wie sie in unseren Microsoft-Vereinbarungen zum Servicelevel für Azure-Dienste definiert ist. So können Sie sich auf Ihre Aufgaben in der Dienstleistungskette konzentrieren, z. B. synthetische Überwachung, Netzwerkkonnektivität, Sicherheit und Compliance.
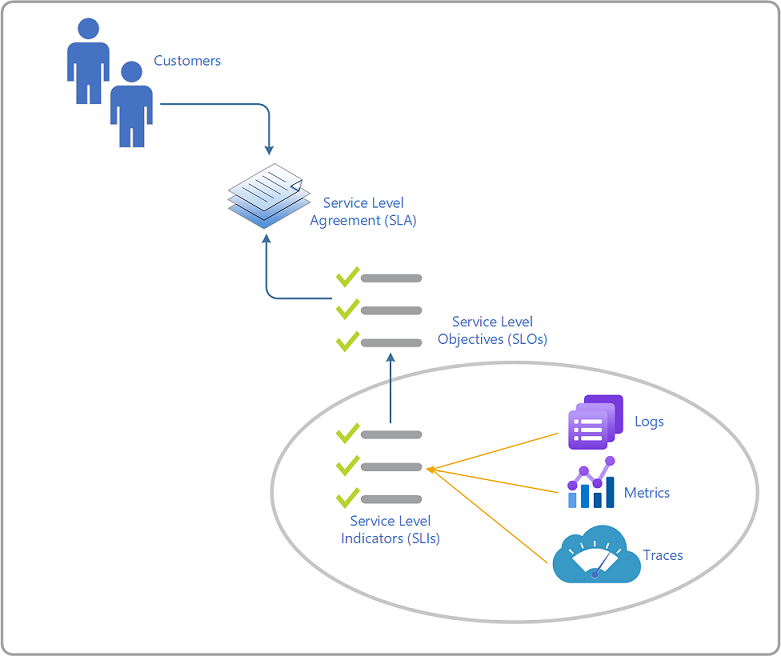
Begriff
Im Folgenden finden Sie die Definitionen für jeden dieser Begriffe sowie eine kurze Beschreibung. Diese Definitionen stammen aus dem SRE-Handbuch von Google.
| Begriff | Beschreibung |
|---|---|
| Vereinbarung zum Servicelevel (SLA) | In der Regel eine verbindliche Zusage zwischen einem Dienstleistungsanbieter und einem Kunden. Eine Vereinbarung umfasst in der Regel Konsequenzen, für den Fall, dass die SLO-Ziele verfehlt werden. Besondere Aspekte des Diensts sind Qualität, Verfügbarkeit und Zuständigkeiten, die zwischen dem Dienstanbieter und dem Dienstconsumer vereinbart werden. |
| Überwachung | Das Verfahren der Sammlung quantitativer Echtzeitdaten zu Diensten und Systemen. |
| Metriken | Messen das relevante Verhalten eines Diensts und können zu Servicelevelindikatoren (SLIs) aggregiert werden, die verarbeitet und aggregiert werden, um den aktuellen Betriebszustand eines Diensts zu messen und sein Verhalten zu quantifizieren. SLIs sind die wichtigsten Echtzeitindikatoren für die aktuelle Integrität eines Diensts. |
| Protokolle | Beginnen mit dem Code und melden Informationen zu einer einzelnen Ausführung eines Codepfads oder zu einem diskreten Ereignis. Verwenden diese Informationen zur Problembehandlung und zur Identifizierung von Problemen, die sich auf die Benutzerfreundlichkeit und die Zuverlässigkeit des Diensts auswirken, die durch SLIs/SLOs gemessen werden. |
| Servicelevelziel (SLO) | Ein Zielwert für den Servicelevel, der anhand von Servicelevelindikatoren (SLIs) gemessen wird und die Erwartung festlegt, wie gut ein Dienst funktioniert. Die SLOs verfolgen speziell die End-to-End-Benutzerfreundlichkeit nach. Um gute SLOs festzulegen, beginnen Sie in der Regel damit, gewünschte Erfahrung zu definieren. Dann instrumentieren Sie den Dienstcode, um diese Erfahrung zu messen (sammeln relevanter SLIs) und legen das Ziel fest, wie Sie die Erwartungen der Kunden erfüllen oder nicht. |
| Servicelevelindikatoren (SLIs) | Eine Metrik, die die Qualität oder Zuverlässigkeit des Diensts quantifiziert. Es gibt mindestens vier gängige SLIs, die zu bewerten sind: Verfügbarkeit, Wartezeit, Durchsatz und Fehlerrate. |
| Verfügbarkeit | Bezieht sich im Allgemeinen auf den messbaren oder beobachtbaren Prozentsatz der Zeit, in der ein System betriebsbereit und funktionsfähig ist. Sie messen die Verfügbarkeit als Zielvorgabe für die Kontinuität der Benutzerfreundlichkeit, die von einem oder mehreren Zuverlässigkeitsproblemen (und anderen Fehlerzuständen im Zusammenhang mit Konfigurationsänderungen, angewandten Updates und mehr) beeinflusst wird. |
| Fehlerbudget | Der Prozentsatz Ihres verbleibenden Puffers in Bezug auf Ihre SLO. Fehlerbudgets sind das Tool, das DevOps und die IT verwenden, um die Zuverlässigkeit des Diensts mit dem Innovationstempo in Einklang zu bringen. |
Der Zweck von SLOs
SLOs dienen vielen wichtigen Zwecken bei der Entwicklung und dem Betrieb von Cloudworkloads, darunter:
- Quasi-Echtzeit (Near real-time, NRT): Die Integrität eines Diensts aus Sicht eines Kunden in Quasi-Echtzeit anzeigen.
- Zeit bis zur Benachrichtigung (time-to-notify, TTN) verkürzen: Steuern Sie die automatisierte Benachrichtigung von Kunden bei Problemen mit dem Dienst, wodurch die TTN erheblich verkürzt wird.
- Primäres Signal an Kunden: Fungieren Sie als primäres Signal für die Bereitstellung und sorgen Sie für einen automatischen Rollback, wenn Probleme auftreten, sodass weniger Kunden potenziellen Problemen ausgesetzt sind.
- Ändern der Überprüfung: Bestätigen Sie, dass die Änderungen die erwartete Verbesserung der Benutzerfreundlichkeit bewirkt haben.
- Festlegen von Prioritäten: Unterstützen Sie Teams dabei, zu verstehen, ob sie Features erstellen oder an der Zuverlässigkeit arbeiten sollen.
- Erkenntnisse zur Dienstintegrität: Ermöglichen Sie objektive, kundenorientierte Diskussionen über die Integrität des Diensts.
- Reduzieren der Analysezeit: Beschleunigen Sie die Risikominderung und Grundursachenanalyse (RCA) von Kundenproblemen, indem Sie den Fokus auf den zuständigen Dienst lenken.
- Architektonische Abhängigkeiten: Leisten Sie einen wichtigen Beitrag zu architektonischen Entscheidungen, wenn Dienste Abhängigkeiten eingehen.
- Aufbauen von Vertrauen: Sorgen Sie für ein gemeinsames Verständnis von Integritätsmaßnahmen, das Vertrauen zwischen den Teams schafft.
- Transparenz: Stellen Sie unseren Kunden dieselben SLIs zur Verfügung, die wir verwenden, um unser Geschäft zu betreiben, sodass sie ihr eigenes Geschäft betreiben können.
- Zentralisierte Benutzeroberfläche: Aktivieren Sie eine zentralisierte Benutzeroberfläche für die Dienste und ihre Abhängigkeiten und Aufschlüsselungssilos.
Mithilfe von SLOs zur Steuerung Ihres Entwicklungsprozesses können DevOps und die IT-Abteilung frühzeitig ein Verständnis für die Integrität der Anwendung oder des Infrastrukturdiensts erlangen, den sie in Azure erstellen oder migrieren. Dies kann dann verwendet werden, um sowohl die menschlichen als auch die automatisierten Entscheidungen hinsichtlich der Zuverlässigkeit dieser Dienste zu steuern. Dieser Wandel in den Entwicklungsverfahren wird in naher Zukunft die größten Auswirkungen auf die Zuverlässigkeit dieser Dienste haben.
Wie definiert man SLOs?
Das Ziel eines SLO ist es, klare Signale zu erhalten, die die Qualität aus Sicht des Kunden genau messen. Jedes Serviceteam erstellt eine kleine Reihe von Servicelevelzielen (SLOs), die den zulässigen Bereich für die wichtigsten messbaren Metriken des Diensts festlegen, so wie sie vom Dienstconsumer erlebt werden. Ein SLO ist ein definiertes numerisches Ziel für eine Metrik, die von einem Dienst ausgegeben wird. Die mit diesem Ziel verbundenen Metriken können überwacht werden, um festzustellen, ob der Dienst fehlerfrei ist.
Hier ist ein vereinfachtes Beispiel für eine SLO für eine interne webbasierte Anwendung zur Zeiterfassung – Die Anforderungen der letzten fünf Minuten werden in weniger als 1000 Millisekunden im 99. Perzentil bedient.
Bei den Metriken handelt es sich um Aggregationen von Zeitreihendaten, die als Servicelevelindikatoren (SLIs) bezeichnet werden. Es spielt eine große Rolle, wo die SLIs erfasst werden. Wenn der Kunde im obigen Beispiel mithilfe einer API mit dem Dienst interagiert, sind die Messung der Wartezeit des Systems und der Zeit für die Bearbeitung von Anforderungen genaue SLIs. Wenn der Kunde jedoch mit dem Dienst mithilfe eines Webportals interagiert, dann sollte die Gesamtzeit für die Bearbeitung der Anforderung auch die JavaScript-Leistung der Webseite einbeziehen.
Der Schwerpunkt für Dienstbesitzer besteht darin, Folgendes zu bestimmen:
- Welche Szenarien sind kritische Indikatoren für die Integrität des Diensts aus Sicht des Kunden?
- Wo sollen die SLIs gesammelt werden, sodass sie so nah wie möglich der Erfahrung des Kunden entsprechen?
- Was sollen die SLOs für diese SLIs sein?
SLOs können mit einem schrittweisen Ansatz definiert werden, um die Zielerreichung zu fördern, oder sie werden direkt vom Unternehmen vorgegeben. Sie verwenden die von einem Dienst definierten SLOs, um architekturbezogene Entscheidungen darüber zu treffen, wie Sie diese erstellen. Daher ist es wichtig, sorgfältig auszuwählen, welche Szenarien gemessen werden sollen und in welchem Zeitrahmen dies erfolgen soll. Zusammenfassend lässt sich sagen, dass ein SLO aus den folgenden Werten besteht:
- Ein SLI. Beispielsweise ist der Anteil der ausreichend schnellen Anforderungen, die vom Lastenausgleich gemessen werden, kleiner als 400 ms.
- Eine Dauer. Die Zeitspanne, in der eine Metrik gemessen wird.
- Ein Ziel. Beispielsweise ein angestrebter Prozentsatz schneller Anforderungen im Verhältnis zu den gesamten Anforderungen (z. B. 90 %), den Sie für eine bestimmte Dauer erreichen möchten.
Typen von SLOs
Wenn Sie sich in der Branche umsehen, gibt es zwei Arten von SLOs:
Dienstorientierte SLOs: Diese SLOs sind taktische Ziele, die Teams definieren, um die Qualität ihres Diensts im Laufe der Zeit zu verbessern. Sie sind als pragmatische Ziele konzipiert, die in einem technischen Meilenstein erreicht werden können. Wenn z. B. ein Dienst derzeit eine Verfügbarkeit von 99,7 % erreicht, könnte das Team das Ziel festlegen, im nächsten Quartal eine Verfügbarkeit von 99,9 % zu erreichen.
Kundenorientierte SLOs: Diese SLOs definieren den idealen Zustand oder das Ziel. An diesem Punkt wären weitere Investitionen in die Qualität unnötig, da Sie die Erwartungen der Kunden voll erfüllen.
Wenn Ihr Kunde z. B. erwartet, dass ein von Ihnen betriebener Geschäfts- oder Infrastrukturdienst eine Verfügbarkeit von 99,99 % bietet und der Dienst derzeit nur eine Verfügbarkeit von 99,8 % erreicht, ist das kundenorientierte SLO immer noch 99,99 %.
Die Definition geeigneter SLOs braucht Zeit. Der erste Schritt besteht darin, mit Ihren Kunden zu sprechen und zu verstehen, was Ihre Benutzer von dem Dienst erwarten, um daraus eine kleine Auswahl von Indikatoren abzuleiten und diese zu dokumentieren. Erfahren Sie mehr über die Szenarien und Toleranzen für die Verwendung Ihres Diensts und was Ihr Dienst leisten muss, um ihr Geschäft erfolgreich zu betreiben. Dies ist in der Regel eine iterative Erfahrung, bei der die Erwartungen der Kunden von Ich möchte unter allen Bedingungen eine 100%ige Verfügbarkeit ohne Auswirkungen auf unseren Umsatzstrom bis hin zum Umgang mit stark variierenden Erwartungen zwischen den Kundensegmenten reichen.
Überwachungsansätze, die sich nur auf die Dienstintegrität (oder die Dienstinstanz) beziehen, bergen das Sicherheitsrisiko, dass Probleme mit der Kundenerfahrung an beiden Enden des Spektrums übersehen werden. Die Dienstintegrität korreliert nicht immer mit der Qualität der Kundenerfahrung. Das liegt daran, dass es unterschiedliche Verhaltensmerkmale zwischen einem Azure PaaS- und einem SaaS-Dienst gibt, an der Konfiguration dieser Azure-Dienste, daran, wie und wo (d. h. in welcher Region) ihre Ressourcen bereitgestellt werden, und an der Einbeziehung Ihres benutzerdefinierten Codes/ihrer benutzerdefinierten Logik, was die Komplexität weiter erhöht.
Wenn Sie ein SLO definieren, ist es wichtig, daran zu denken, dass Ihre Cloudanbieter eine Abhängigkeit von Ihrer SLA darstellen. Beachten Sie die für jeden ihrer Dienste festgelegten Vereinbarungen zum Servicelevel. Informationen zu Azure finden Sie unter Vereinbarungen zum Servicelevel (SLAs) für Onlinedienste.
Wie definieren Sie SLIs?
Eine SLI-Spezifikation ist eine formale Erklärung der Erwartungen Ihrer Benutzer an eine bestimmte Zuverlässigkeitsdimension Ihres Diensts, wie Wartezeit oder Verfügbarkeit.
Beginnen Sie einfach, indem Sie die richtigen Metriken zum Messen und Erfassen auswählen, und machen Sie es nicht zu kompliziert, indem Sie zu viele Metriken erfassen, die nicht aussagekräftig sind. Stellen Sie sicher, dass die von Ihnen definierten SLIs einen direkten Bezug zur Benutzerfreundlichkeit haben. Deshalb ist es wichtig, die Perspektive der Benutzer zu verstehen, um mit nur wenigen Indikatoren zu beginnen.
Wenn Ihr Dienst in irgendeiner Weise hinsichtlich der Ressourcen eingeschränkt ist, z. B. bei Arbeitsspeicher oder CPU, dann kann seine Auslastung auch ein hervorragender SLI sein. Die Auslastung sollte jedoch nicht als SLO verwendet werden, da sie nicht direkt mit einer schlechten Benutzererfahrung korrespondiert (ein Dienst kann eine hohe Speicherauslastung aufweisen, aber die Benutzer sind davon nicht betroffen).
Wir empfehlen, dass Sie bis zu drei Indikatoren erstellen. Mehr als drei Indikatoren sind selten von großem Wert. Bei einer zu großen Anzahl von Indikatoren werden oft auch Symptome von primären Indikatoren einbezogen. Datenverkehr und Auslastung sollten zu diesen drei Hauptindikatoren hinzukommen, da diese die Dienstauslastung beschreiben und die Interpretation der anderen Dienstindikatoren unterstützen.
Wie implementieren Sie SLOs?
Die wichtigsten SLIs sind diejenigen, die aus Kundensicht am deutlichsten eine Auswirkung auf Ihren Dienst darstellen. Für viele Dienste gehören dazu Wartezeit, Durchsatz, Fehlerrate und Verfügbarkeit. Wenn Ihr Dienst besondere Aspekte aufweist, die sich auf die Benutzerfreundlichkeit auswirken, dann sollten die SLIs für diese Bereiche ebenfalls gemessen werden. Beispielsweise ist die End-to-End-Verarbeitungswartezeit bei einem Messagingdienst ein direkter Indikator für die Benutzerfreundlichkeit und sollte von einem SLI abgedeckt werden.
SLO-Beispiele
Die Personalabteilung ist daran interessiert, ihre interne webbasierte Anwendung zur Zeiterfassung zu modernisieren und sie mithilfe der Unternehmens-IT in der Azure-Cloud zu hosten. Sie möchten, dass der Dienst weiterhin alle Benutzer in der Organisation erreicht, sodass sie an Folgendem interessiert sind:
- Nutzungsberichte und die Anzahl der Benutzer, die den Dienst im Laufe der Zeit verwenden.
- Regelmäßige Systemüberwachung wie Verfügbarkeit, Leistung, Sicherheit und Compliance (Servicegarantie).
- Kosten, z. B. die monatlichen Kosten eines Diensts.
- Cybersicherheit im Sinne der Kontrolle des Zugriffs auf Ressourcen und Daten durch eine Zero Trust-Sicherheitsstrategie.
Wie wir an den obigen Beispielen sehen, müssen die SLO/SLI-Kategorien und -Beispiele bereits in einem frühen Stadium der Dienstentwicklung festgelegt werden. Das unterscheidet sich nicht im Geringsten von den lokalen Diensten, die Sie bisher erstellt haben.
SLO-Tabellen/SLI-Kategorien
Die folgenden Beispiele sind keineswegs eine vollständige Liste. Während die SLOs für Zuverlässigkeit und Wartbarkeit seit Jahrzehnten ein Markenzeichen von Systemen sind, können Sie SLOs definieren, die Maßnahmen für Cybersicherheit, Qualität und Benutzererfahrung sowie Kosten umfassen.
Dienste
Typische allgemeine Maßnahmen für einen Dienst oder ein System werden die in der Regel in Servicevereinbarungen codiert. Die meisten modernen Vereinbarungen messen die Verfügbarkeit als wichtigstes SLO und verwenden einfache Messungen der Downtime, die auf wichtigen Workloadelementen oder Produktionseinheiten basieren, z. B. Authentifizierungstoken, Postfächer oder Speicherkonten.
| Category | Beschreibung | Beispiel |
|---|---|---|
| Verfügbarkeit | Einfache Downtime oder mittlere Zeit zwischen Wartung oder operative Verfügbarkeit (MTBM/(MTBM+MDT)) | 99,99 % über einen monatlichen Zeitraum |
| Capacity | Sorgen Sie für eine angemessene, maximale oder optimale Geschäfts- und Serviceleistung, für Durchsatz, Speicher, Mitarbeiter, Bandbreite, Nachfrage, Ressourcen und Dienstfunktionen. Enthält Arbeits- und Zeitlimits, die als Auslöser dienen. | Auslastung in % (CPU, Speicher, Arbeitsspeicher, Wartezeit, Durchsatz, Skalierung) |
| Sicherheit | Aktive Bedrohungen und Sicherheitsrisiken (intern und extern), die dem Unternehmen, den Ressourcen und den Daten Schaden zufügen könnten oder bereits Schaden zufügen. | Erkennung von HAFNIUM-Bedrohung |
| Compliance | Updates, Wartungsebenen, Härtung der Compliance, gewünschte Konfigurationsabweichung | 99,5 % gewartete Updates für alle Ressourcen |
| Kontinuität | Die Fähigkeit, extreme Notfälle und externe Ereignisse zu überstehen und sich davon zu erholen. | Zeit (Rekonstitution) |
| Quality of Service (QoS, Dienstqualität) | Merkmale der tatsächlichen Erfahrungen der Benutzer im Laufe der Zeit. | Teams-Anrufqualität – empfangene Paketverluste < 2 % |
Zuverlässigkeit
Zuverlässigkeit, das klassische SLO, bezeichnet den Grad der Zuverlässigkeit, Langlebigkeit und Qualität von Systemen, Diensten, Ressourcen oder Komponenten im Hinblick auf Ausfälle und Failover, wobei das Management Anstrengungen unternimmt, um Ausfälle zu behandeln (z. B. durch Erhöhen der Redundanz oder Hinzufügen eines Content Delivery Networks), um die Betriebszeit oder Verfügbarkeit zu erhöhen. Es könnte auch die Genauigkeit, Treue, Integrität und Vertrauenswürdigkeit der Daten bedeuten, die auch zur Messung der SLOs verwendet werden. Es kann die klassische Wahrscheinlichkeit bedeuten, dass ein System unter bestimmten Bedingungen, z. B. Temperaturdruck, seine beabsichtigte Funktion erfüllen wird. Zur Resilienz gehören auch integrierte Entwurfsfaktoren oder Features, die für Anpassungsfähigkeit sorgen, z. B. Skalierung, Abkühlung, Lastenausgleich, Wiederherstellung, unvorhersehbare Nachfrage, verminderte Leistung bei starker Belastung sowie Entwurf für Kontinuität bei größeren Notfällen (normalerweise ein separates SLO).
| Category | Beschreibung | Beispiel |
|---|---|---|
| Fehlerrate | Anzahl der Fehler während der gesamten Betriebsstunden | 5 Fehler in 973 Stunden ergeben eine Rate von 0,00514 |
| MTBF (Mean Time Between Failure, mittlere Betriebsdauer zwischen Ausfällen) | MTBF ist der Kehrwert der Fehlerrate | 194,6 Stunden |
Wartbarkeit
Kombinieren Sie Support-SLOs für IT-Service-Management-Prozesse wie Incident-Management und Problemverwaltung mit Zuverlässigkeits-SLOs, sodass eine Verfügbarkeitsmessung erreicht werden kann.
| Category | Beschreibung | Beispiel |
|---|---|---|
| Leistung von Dienstvorfällen | Nach Kategorie oder Produkt oder Priorität. | Zeit- und Kostenmessungen für jede Phase des Lebenszyklus eines Vorfalls. |
| Leistung von Sicherheitsvorfällen | Nach Kategorie oder Produkt oder Priorität. | Zeit- und Kostenmessungen für jede Phase des Lebenszyklus eines Vorfalls. |
| MTTR für Komponente (Mean Time To Repair, mittlere Reparaturzeit) | Von der Erkennung von Ereignissen bis zur Wiederherstellung oder Behebung. | |
| Mittlere Zeit zwischen Wartung (Mean Time Between Maintenance, MTBM) | Mittlere oder durchschnittliche Zeit zwischen allen Wartungsmaßnahmen, einschließlich vorbeugender Maßnahmen, bei denen normale Produktionsarbeiten stattfinden. | Siehe „Wartungsverzögerungszeit“ (Maintenance Delay Time, MDT) |
| Wartungsverzögerungszeit (MDT) | Gesamtzeit von der Entdeckung bis zur Wiederherstellung, einschließlich logistischer und administrativer Verzögerungen. | Zeit für den Austausch der Hardware, einschließlich Bestellung, Versand und Installation. |
Benutzerfreundlichkeit
| Kategorie | Beschreibung | Beispiel |
|---|---|---|
| Throughput | Die Menge, Rate oder Geschwindigkeit der Workload oder der produktiven Last, die einem System im Laufe der Zeit auferlegt wird. | Transaktionen pro Zeiteinheit. |
| Fehlerrate | Die Anzahl der gesamten Fehler in Prozent. | Sicherheitsrelevante Ereignisse in Prozent |
| Latency | Ein Maß für die Zeit oder Verzögerung von der Eingabe bis zur Ausgabe, der Bewegung der Arbeitsleistung durch einen Prozess oder von der Anwendung bis zum Benutzer. | Durchschnittliche Anzahl der Sekunden. |
Andere
| Category | Beschreibung | Beispiel |
|---|---|---|
| Kosten | Messen Sie Ausgaben, Abrechnungen und Rechnungen nach Dienst, Komponente oder Zeit. | Kapital- oder Betriebskosten |
| Abdeckung | Verwalteten Komponenten, Systeme und Dienste in Prozent (Compliance) | Kompatibilität |
| Zuverlässigkeit des Feeds | Fehler bei Heartbeats, Connectors, Änderungen und mehr. | Nachverfolgen von Änderungen in unternehmenskritischen Unternehmensdaten. |
| Produktivität | Effektivität bei der produktiven Erledigung von Aufgaben | Arbeit, Zeit nach Mitarbeiter, Produktivität des Analysten. |
Überlegungen
Stellen Sie den Zugriff sicher. Stellen Sie sicher, dass Manager und andere Personen im Unternehmen Zugriff auf die Visualisierungen erhalten, die in Azure Monitor oder von anderen Azure Diensten verfügbar sind, insbesondere Azure-SaaS und -PaaS, um deren Duplizierung zu vermeiden.
Sorgen Sie für eine umfassende Überwachung oder Sichtbarkeit der gesamten Ressourcen. Stellen Sie sicher, dass Agents, ausgegebene Protokolle, Tabellen und Abfragen für alle Ressourcen, die verwaltet und geschützt werden müssen, vorhanden sind, und identifizieren Sie nicht erfasste Bereiche oder Lücken in der Abdeckung, um die Realitätsnähe der SLOs sicherzustellen.
Stellen Sie die richtigen Daten für die richtigen Consumer bereit. Stellen Sie sicher, dass die Consumer von SLOs und SLIs die zugrunde liegenden Daten interpretieren können, um Vertrauen zu schaffen und Entscheidungen mithilfe der aus den Daten gewonnenen Informationen zu treffen.
Machen Sie angemessene Zusagen. Wenn Sie SLOs als Ziele festlegen, insbesondere wenn die Kostenverwaltung wichtig ist, stellen Sie sicher, dass die tatsächliche Systemleistung weder zu hoch noch zu niedrig ist, oder passen Sie das Ziel an, um die Erwartungen der Kunden zu erfüllen.
Berücksichtigen Sie unvorhergesehene externe Ereignisse. Entwickeln Sie Kontinuitätspläne und Risikobewertungen, um Ereignisse zu berücksichtigen, auf die Sie keinen Einfluss haben, z. B. Wetter, Stromausfälle oder Katastrophen.
Berücksichtigen Sie Änderungen. Stellen Sie sicher, dass die SLOs Änderungen hinsichtlich des Diensts oder der technischen Zuverlässigkeit, des Durchsatzes, der Qualität und der Wartbarkeit berücksichtigen, z. B. den Abbau von Supportmitarbeitern.
Stellen Sie eine ausgewogene Anzahl von SLOs bereit. Sorgen Sie für eine Reihe von SLOs, die eine ausgewogene oder 360-Grad-Perspektive auf den Dienst oder das System sowie den Fokus auf Zuverlässigkeit bieten.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für