Tutorial: Einrichten eines Datenproduktbatchs
In diesem Tutorial erfahren Sie, wie Sie bereits bereitgestellte Datenproduktdienste einrichten. Verwenden Sie Azure Data Factory, um Ihre Daten zu integrieren und zu orchestrieren, und Microsoft Purview, um Datenressourcen zu ermitteln, zu verwalten und zu steuern.
In diesem Artikel werden folgende Themen erläutert:
- Erstellen und Bereitstellen erforderlicher Ressourcen
- Zuweisen von Rollen und Zugriffsberechtigungen
- Verbinden von Ressourcen für Datenintegration
In diesem Tutorial können Sie sich mit den Diensten vertraut machen, die in der <DMLZ-prefix>-dev-dp001-Beispieldaten-Produktressourcengruppe bereitgestellt werden. Erfahren Sie, wie die Azure-Dienste miteinander verbunden sind und welche Sicherheitsmaßnahmen getroffen wurden.
Wenn Sie die neuen Komponenten bereitstellen, können Sie untersuchen, wie Purview Dienstgovernance verbindet, um eine ganzheitliche, aktuelle Karte Ihrer Datenlandschaft zu erstellen. Das Ergebnis ist automatisierte Datenermittlung, Klassifizierung vertraulicher Daten und End-to-End-Datenherkunft.
Voraussetzungen
Bevor Sie mit der Einrichtung Ihres Datenproduktbatchs beginnen, stellen Sie sicher, dass diese Voraussetzungen erfüllt sind:
Azure-Abonnement. Falls Sie über kein Azure-Abonnement verfügen, erstellen Sie jetzt ein kostenloses Azure-Konto.
Berechtigungen für das Azure-Abonnement. Um Purview und Azure Synapse Analytics für die Bereitstellung einzurichten, müssen Sie über die Rolle Benutzerzugriffsadministrator oder Besitzer im Azure-Abonnement verfügen. Sie legen weitere Rollenzuweisungen für Dienste und Dienstprinzipale im Tutorial fest.
Bereitgestellte Ressourcen. Um das Tutorial abzuschließen, müssen diese Ressourcen bereits in Ihrem Azure-Abonnement bereitgestellt worden sein:
- Zielzone für die Datenverwaltung. Weitere Informationen finden Sie im GitHub-Repository für die Zielzone für die Datenverwaltung.
- Zielzone für Daten. Weitere Informationen finden Sie im GitHub-Repository für die Zielzone für Daten.
- Datenproduktbatch. Weitere Informationen finden Sie im GitHub-Repository für den Datenproduktbatch.
Microsoft Purview-Konto. Das Konto wird als Teil Ihrer Bereitstellung der Zielzone für die Datenverwaltung erstellt.
Selbstgehostete Integration Runtime. Die Runtime wird als Teil Ihrer Bereitstellung der Zielzone für die Daten erstellt.
Hinweis
In diesem Tutorial verweisen Platzhalter auf erforderliche Ressourcen, die Sie bereitstellen, bevor Sie mit dem Tutorial beginnen:
<DMLZ-prefix>bezieht sich auf das Präfix, das Sie eingegeben haben, als Sie Ihre Bereitstellung für die Zielzone für die Datenverwaltung erstellt haben.<DLZ-prefix>bezieht sich auf das Präfix, das Sie eingegeben haben, als Sie Ihre Bereitstellung für die Zielzone für Daten erstellt haben.<DP-prefix>bezieht sich auf das Präfix, das Sie eingegeben haben, als Sie Ihre Bereitstellung für Ihren Datenproduktbatch erstellt haben.
Erstellen von Azure SQL-Datenbank-Instanzen
Um dieses Tutorial zu beginnen, erstellen Sie zwei SQL-Datenbank-Beispielinstanzen. Sie verwenden die Datenbanken, um CRM- und ERP-Datenquellen in späteren Abschnitten zu simulieren.
Wählen Sie im Azure-Portal in den globalen Steuerelementen des Portals das Symbol Cloud Shell aus, um ein Azure Cloud Shell-Terminal zu öffnen. Wählen Sie Bash als Terminaltyp aus.

Führen Sie in Cloud Shell das folgende Skript aus. Das Skript findet die
<DLZ-prefix>-dev-dp001-Ressourcengruppe und den Azure SQL Server<DP-prefix>-dev-sqlserver001, der sich in der Ressourcengruppe befindet. Anschließend erstellt das Skript die beiden SQL-Datenbank-Instanzen auf dem<DP-prefix>-dev-sqlserver001-Server. Die Datenbanken werden vorab mit AdventureWorks-Beispieldaten aufgefüllt. Die Daten umfassen die Tabellen, die Sie in diesem Tutorial verwenden.Stellen Sie sicher, dass Sie den
subscription-Parameterplatzhalterwert durch Ihre eigene Azure-Abonnement-ID ersetzen.# Azure SQL Database instances setup # Create the AdatumCRM and AdatumERP databases to simulate customer and sales data. # Use the ID for the Azure subscription you used to deployed the data product. az account set --subscription "<your-subscription-ID>" # Get the resource group for the data product. resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dp001')==\`true\`].name") # Get the existing Azure SQL Database server name. sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") # Create the first SQL Database instance, AdatumCRM, to create the customer's data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumCRM --service-objective Basic --sample-name AdventureWorksLT # Create the second SQL Database instance, AdatumERP, to create the sales data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumERP --service-objective Basic --sample-name AdventureWorksLT
Nachdem das Skript ausgeführt wird, sind in der Azure SQL Server-Instanz<DP-prefix>-dev-sqlserver001 zwei neue SQL-Datenbank-Instanzen vorhanden: AdatumCRM und AdatumERP. Beide Datenbanken befinden sich in der Computeebene „Basic“. Die Datenbanken befinden sich in derselben <DLZ-prefix>-dev-dp001-Ressourcengruppe, die Sie zum Bereitstellen des Datenproduktbatchs verwendet haben.
Einrichten von Purview zum Katalogisieren des Datenproduktbatchs
Führen Sie als dann die Schritte zum Einrichten von Purview zum Katalogisieren des Datenproduktbatchs aus. Sie beginnen mit dem Erstellen eines Dienstprinzipals. Anschließend richten Sie erforderliche Ressourcen ein und weisen Rollen und Zugriffsberechtigungen zu.
Erstellen eines Dienstprinzipals
Wählen Sie im Azure-Portal in den globalen Steuerelementen des Portals das Symbol Cloud Shell aus, um ein Azure Cloud Shell-Terminal zu öffnen. Wählen Sie Bash als Terminaltyp aus.
Erstellen Sie das folgende Skript:
- Ersetzen Sie den
subscriptionId-Parameterplatzhalterwert durch Ihre eigene Azure-Abonnement-ID. - Ersetzen Sie den
spname-Parameterplatzhalterwert durch den Namen, den Sie für den Dienstprinzipal verwenden möchten. Der Dienstprinzipalname muss im Abonnement eindeutig sein.
Nachdem Sie die Parameterwerte aktualisiert haben, führen Sie das Skript in Cloud Shell aus.
# Replace the parameter values with the name you want to use for your service principal name and your Azure subscription ID. spname="<your-service-principal-name>" subscriptionId="<your-subscription-id>" # Set the scope to the subscription. scope="/subscriptions/$subscriptionId" # Create the service principal. az ad sp create-for-rbac \ --name $spname \ --role "Contributor" \ --scope $scope- Ersetzen Sie den
Überprüfen Sie die JSON-Ausgabe für ein Ergebnis, das dem folgenden Beispiel ähnelt. Notieren Sie sich die Werte in der Ausgabe zur Verwendung in späteren Schritten, oder kopieren Sie sie.
{ "appId": "<your-app-id>", "displayName": "<service-principal-display-name>", "name": "<your-service-principal-name>", "password": "<your-service-principal-password>", "tenant": "<your-tenant>" }
Einrichten des Dienstprinzipalzugriffs und der -berechtigungen
Rufen Sie aus der im vorherigen Schritt generierten JSON-Ausgabe die folgenden zurückgegebenen Werte ab:
- Dienstprinzipal-ID (
appId) - Dienstprinzipalschlüssel (
password)
Der Dienstprinzipal muss über die folgenden Berechtigungen verfügen:
- Rolle „Speicherblob-Datenleser“ für die Speicherkonten.
- Datenleserberechtigungen für die SQL-Datenbank Instanzen.
Um den Dienstprinzipal mit den erforderlichen Rollen und Berechtigungen einzurichten, führen Sie die folgenden Schritte aus.
Azure Storage-Kontoberechtigungen
Wechseln Sie im Azure-Portal zum
<DLZ-prefix>devraw-Speicherkonto. Wählen Sie im Ressourcenmenü Zugriffssteuerung (IAM) aus.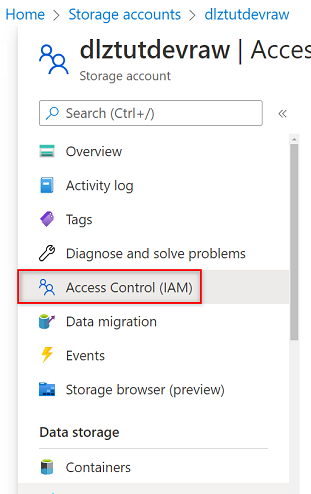
Wählen Sie Hinzufügen>Rollenzuweisung hinzufügen.
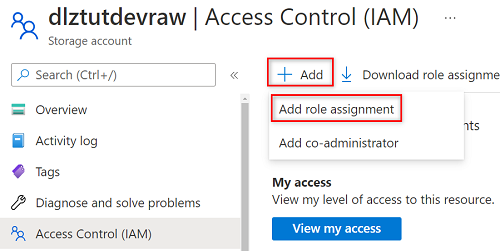
Suchen Sie unter Rollenzuweisung hinzufügen auf der Registerkarte Rolle nach Speicherblob-Datenleser, und wählen Sie diese Rolle aus. Wählen Sie anschließend Weiter aus.
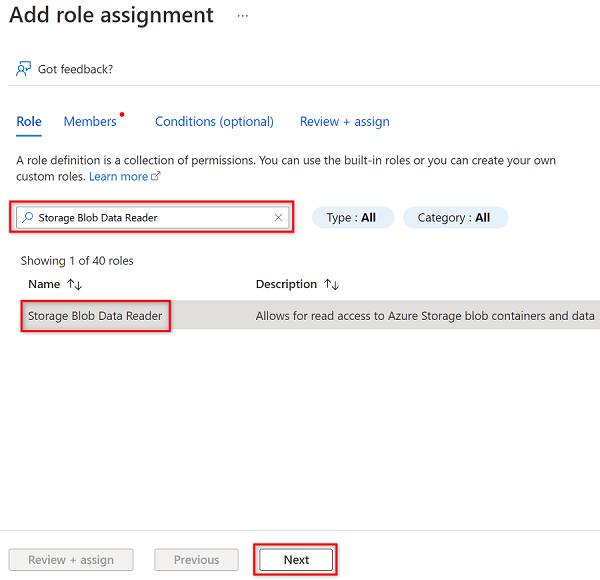
Wählen Sie unter Mitglieder die Option Mitglieder auswählen aus.
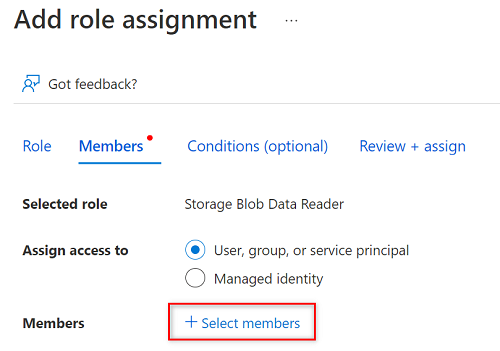
Suchen Sie in Mitglieder auswählen nach dem Namen des von Ihnen erstellten Dienstprinzipals.

Wählen Sie in den Suchergebnissen den Dienstprinzipal aus, und wählen Sie dann Auswählen aus.
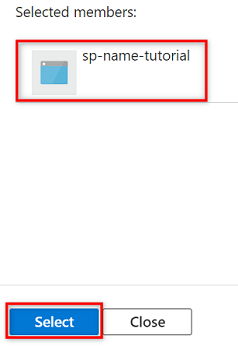
Um die Rollenzuweisung abzuschließen, wählen Sie zwei Mal Überprüfen und zuweisen aus.
Wiederholen Sie die in diesem Abschnitt beschriebenen Schritte für die verbleibenden Speicherkonten:
<DLZ-prefix>devencur<DLZ-prefix>devwork
SQL-Datenbank-Berechtigungen
Um SQL-Datenbank-Berechtigungen festzulegen, stellen Sie eine Verbindung mit der Azure SQL-VM mithilfe des Abfrage-Editors her. Da sich alle Ressourcen hinter einem privaten Endpunkt befinden, müssen Sie sich zunächst mit einer Azure Bastion-Host-VM am Azure-Portal anmelden.
Stellen Sie im Azure-Portal eine Verbindung mit der VM her, die in der <DMLZ-prefix>-dev-bastion-Ressourcengruppe bereitgestellt wird. Wenn Sie nicht sicher sind, wie Sie eine Verbindung mit der VM herstellen, indem Sie den Bastion-Hostdienst verwenden, lesen Sie unter Herstellen einer Verbindung mit einer VM.
Um den Dienstprinzipal als Benutzer in der Datenbank hinzuzufügen, müssen Sie sich möglicherweise zuerst als Microsoft Entra-Administrator hinzufügen. In den Schritten 1 und 2 fügen Sie sich selbst als Microsoft Entra-Administrator hinzu. In den Schritten 3 bis 5 erteilen Sie dem Dienstprinzipal Berechtigungen für eine Datenbank. Wenn Sie sich am Portal über die Bastion-Host-VM angemeldet haben, suchen Sie im Azure-Portal nach Azure SQL-VMs.
Navigieren Sie zur Azure SQL-VM
<DP-prefix>-dev-sqlserver001. Wählen Sie im Ressourcenmenü unter Einstellungen die Option Microsoft Entra ID aus.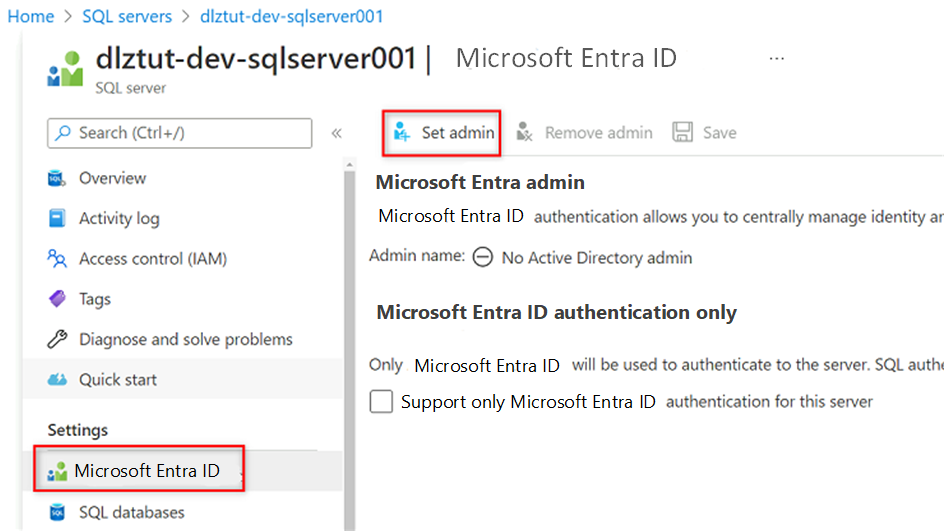
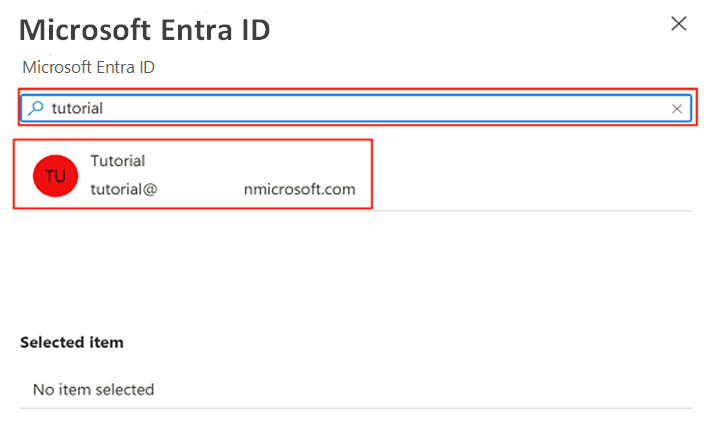
Wählen Sie in der Befehlsleiste Administrator festlegen aus. Suchen Sie nach Ihrem eigenen Konto, und wählen Sie es aus. Klicken Sie auf Auswählen.
Wählen Sie im Ressourcenmenü SQL-Datenbanken und dann die Datenbank
AdatumCRMaus.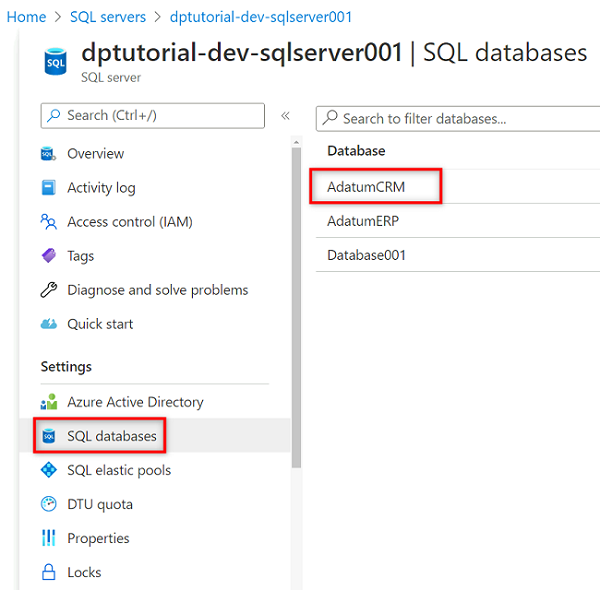
Wählen Sie im Ressourcenmenü AdatumCRM die Option Abfrage-Editor (Vorschau) aus. Wählen Sie unter Active Directory-Authentifizierung die Schaltfläche Fortfahren als aus, um sich anzumelden.
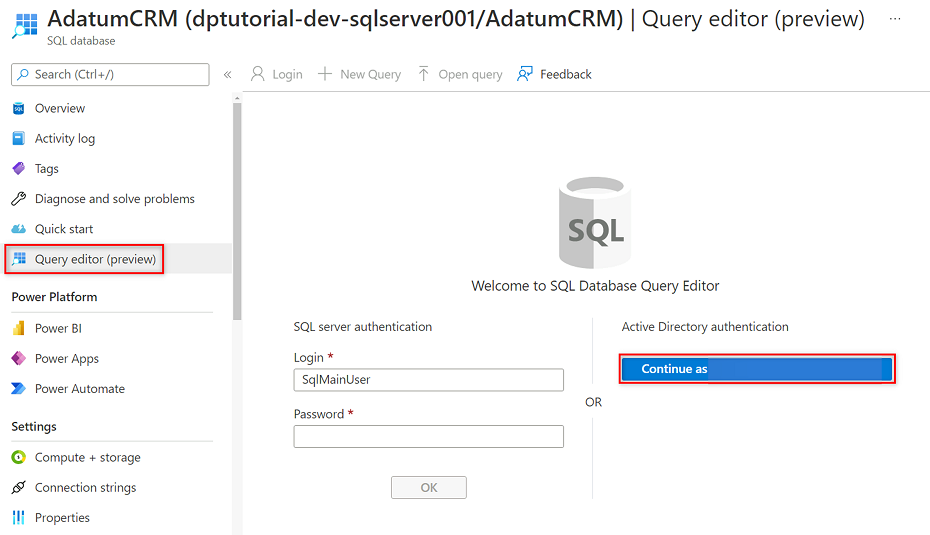
Überprüfen Sie im Abfrage-Editor die folgenden Anweisungen, um
<service principal name>durch den Namen des von Ihnen erstellten Dienstprinzipals zu ersetzen (z. B.purview-service-principal). Führen Sie dann die Anweisungen aus.CREATE USER [<service principal name>] FROM EXTERNAL PROVIDER GO EXEC sp_addrolemember 'db_datareader', [<service principal name>] GO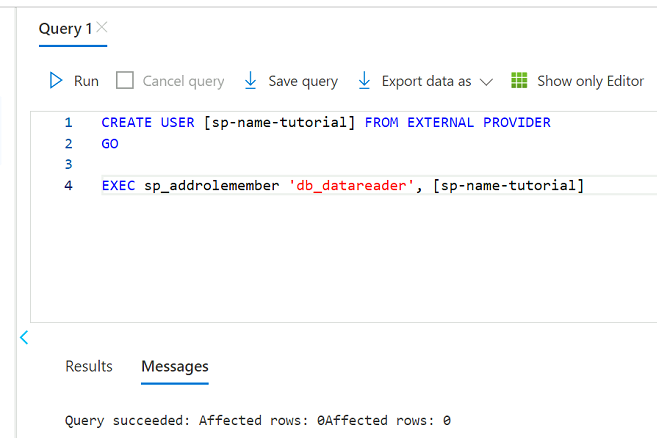
Wiederholen Sie die Schritte 3 bis 5 für die AdatumERP-Datenbank.
Einrichten des Schlüsseltresors
Purview liest den Dienstprinzipalschlüssel aus einer Instanz von Azure Key Vault. Der Schlüsseltresor wird in Ihrer Bereitstellung der Zielzone für die Datenverwaltung erstellt. Die folgenden Schritte sind erforderlich, um den Schlüsseltresor einzurichten:
Sie fügen den Dienstprinzipalschlüssel dem Schlüsseltresor als Geheimnis hinzu.
Weisen Sie Purview MSI Secrets Reader Berechtigungen im Schlüsseltresor zu.
Fügen Sie Purview den Schlüsseltresor als Schlüsseltresorverbindung hinzu.
Erstellen Sie Anmeldeinformationen in Purview, die auf das Geheimnis des Schlüsseltresors verweisen.
Hinzufügen von Berechtigungen zum Hinzufügen eines Geheimnisses zum Schlüsseltresor
Navigieren Sie im Azure-Portal zum Azure Key Vault-Dienst. Suchen Sie nach dem
<DMLZ-prefix>-dev-vault001-Schlüsseltresor.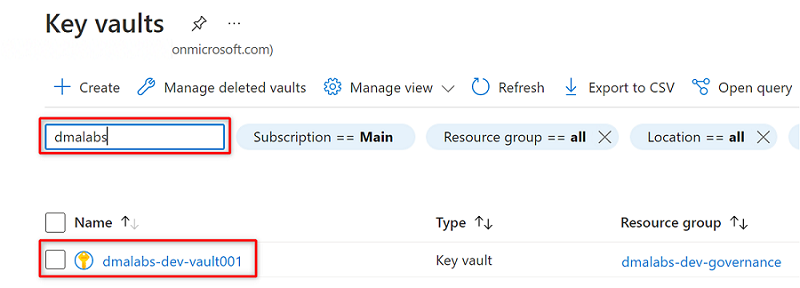
Wählen Sie im Ressourcenmenü Zugriffssteuerung (IAM) aus. Wählen Sie in der Befehlsleiste Hinzufügen und dann Rollenzuweisung hinzufügen aus.
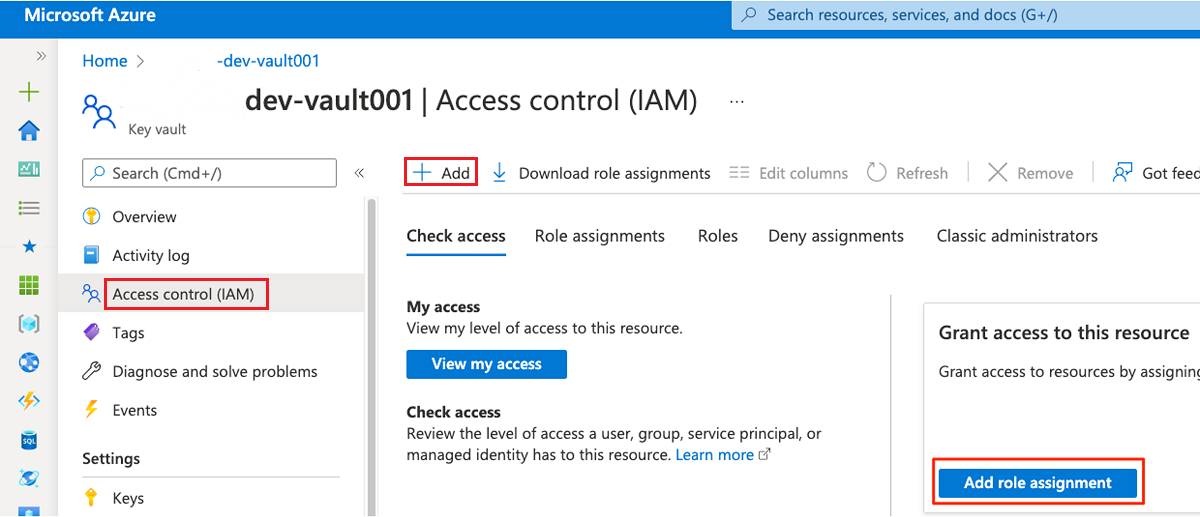
Suchen Sie auf der Registerkarte Rolle nach Key Vault-Administrator, und wählen Sie diese Option dann aus. Wählen Sie Weiter aus.
Wählen Sie unter Mitglieder die Option Mitglieder auswählen aus, um das Konto hinzuzufügen, das derzeit angemeldet ist.
Suchen Sie unter Mitglieder auswählen nach dem Konto, das derzeit angemeldet ist. Wählen Sie das Konto aus, und wählen Sie dann Auswählen aus.
Um den Rollenzuweisungsprozess abzuschließen, wählen Sie zwei Mal Überprüfen und zuweisen aus.
Hinzufügen eines Geheimnisses zum Schlüsseltresor
Führen Sie die folgenden Schritte aus, um sich am Azure-Portal von der Bastion-Host-VM anzumelden.
Wählen Sie im Ressourcenmenü des
<DMLZ-prefix>-dev-vault001-Schlüsseltresors die Option Geheimnisse aus. Wählen Sie in der Befehlsleiste Generieren/Importieren aus, um einen neuen Geheimen zu erstellen.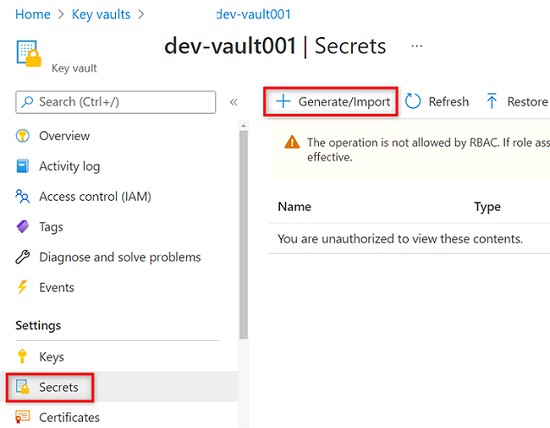
Wählen Sie im Bereich Geheimnis erstellen die folgenden Werte aus, oder geben Sie sie ein:
Einstellung Aktion Uploadoptionen Wählen Sie Manuell aus. Name Geben Sie service-principal-secret ein. Wert Geben Sie das von Ihnen zuvor erstellte Dienstprinzipalkennwort ein. 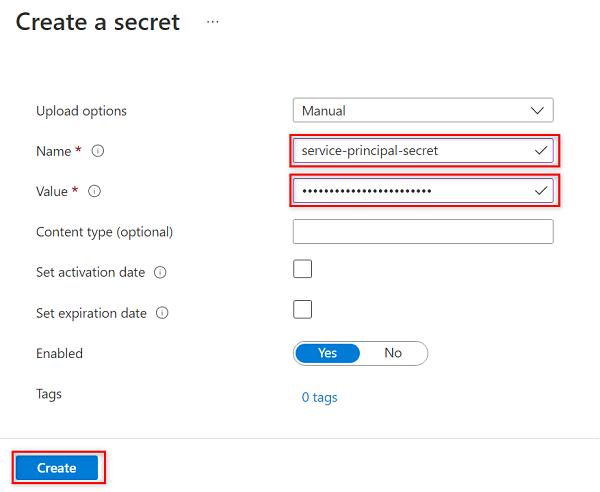
Hinweis
Dieser Schritt erstellt ein Geheimnis namens
service-principal-secretim Schlüsseltresor mithilfe des Dienstprinzipal-Kennwortschlüssels. Purview verwendet das Geheimnis, um eine Verbindung mit den Datenquellen herzustellen und diese zu scannen. Wenn Sie ein falsches Kennwort eingeben, können Sie die folgenden Abschnitte nicht abschließen.Klicken Sie auf Erstellen.
Einrichten von Purview-Berechtigungen im Schlüsseltresor
Damit die Purview-Instanz die Geheimnisse lesen kann, die im Schlüsseltresor gespeichert sind, müssen Sie Purview die relevanten Berechtigungen im Schlüsseltresor zuweisen. Um die Berechtigungen festzulegen, fügen Sie die verwaltete Purview-Identität der Rolle „Geheimnisleser“ des Schlüsseltresors hinzu.
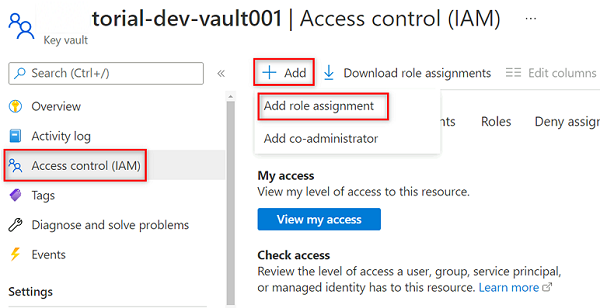
Wählen Sie im Ressourcenmenü des
<DMLZ-prefix>-dev-vault001-Schlüsseltresors die Option Zugriffssteuerung (IAM) aus.Wählen Sie in der Befehlsleiste Hinzufügen und dann Rollenzuweisung hinzufügen aus.
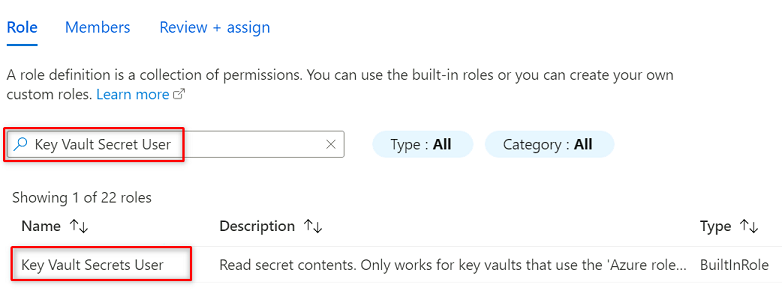
Suchen sie unter Rolle nach Key Vault-Geheimnisbenutzer. Wählen Sie Weiter aus.
Wählen Sie unter Mitglieder die Option Mitglieder auswählen aus.
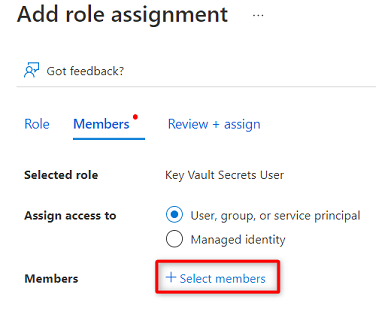
Suchen Sie nach der
<DMLZ-prefix>-dev-purview001-Purview-Instanz. Wählen Sie die Instanz aus, um das relevante Konto hinzuzufügen. Wählen Sie anschließend Auswählen aus.
Um den Rollenzuweisungsprozess abzuschließen, wählen Sie zwei Mal Überprüfen und zuweisen aus.
Einrichten einer Schlüsseltresorverbindung in Purview
Um eine Schlüsseltresorverbindung mit Purview einzurichten, müssen Sie sich mit einer Azure Bastion-Host-VM am Azure-Portal anmelden.
Navigieren Sie im Azure-Portal zum Purview-Konto
<DMLZ-prefix>-dev-purview001. Wählen Sie unter Erste Schritte im Open Microsoft Purview Governance-Portal die Option Öffnen aus.
Wählen Sie in Purview Studio Verwaltungs>Anmeldeinformationen aus. Wählen Sie in der Befehlsleiste Anmeldeinformationen die Option Key Vault-Verbindungen verwalten und dann Neu aus.
Wählen Sie unter Neue Schlüsseltresorverbindung die folgenden Informationen aus, oder geben Sie diese ein:
Einstellung Aktion Name Geben Sie <DMLZ-prefix>-dev-vault001 ein. Azure-Abonnement Wählen Sie das Abonnement aus, das den Schlüsseltresor hostet. Name des Schlüsseltresors Wählen Sie den Schlüsseltresor <DMLZ-prefix>-dev-vault001 aus. 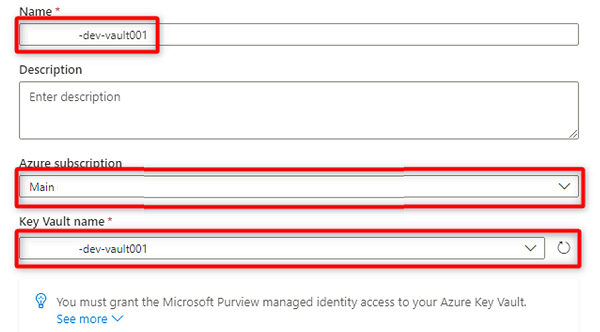
Klicken Sie auf Erstellen.
Wählen Sie unter Zuweisung des Zugriffs bestätigen die Option Bestätigen aus.
Erstellen von Anmeldeinformationen in Purview
Der letzte Schritt zum Einrichten des Schlüsseltresors besteht darin, Anmeldeinformationen in Purview zu erstellen, die auf das Geheimnis verweist, das Sie im Schlüsseltresor für den Dienstprinzipal erstellt haben.
Wählen Sie in Purview Studio Verwaltungs>Anmeldeinformationen aus. Wählen Sie in der Befehlsleiste Anmeldeinformationen die Option Neu aus.
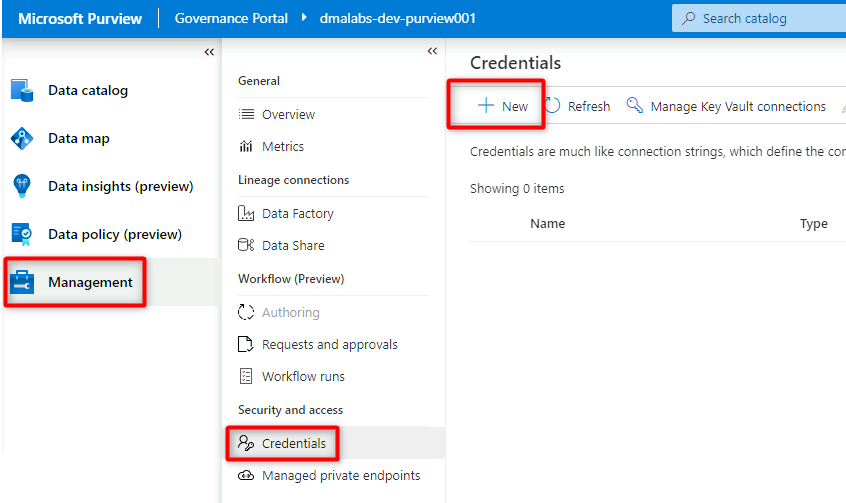
Wählen Sie unter Neue Anmeldeinformationen die folgenden Informationen aus, oder geben Sie sie ein:
Einstellung Aktion Name Geben Sie purviewServicePrincipal ein. Authentifizierungsmethode Wählen Sie Dienstprinzipal aus. Tenant ID Der Wert wird automatisch mit Daten aufgefüllt. Dienstprinzipal-ID Geben Sie die Anwendungs-ID oder Client-ID des Dienstprinzipals ein. Key Vault-Verbindung Wählen Sie die im vorherigen Abschnitt erstellte Schlüsseltresorverbindung aus. Geheimnisname Geben Sie den Namen des Geheimnisses im Schlüsseltresor (service-principal-secret) ein. 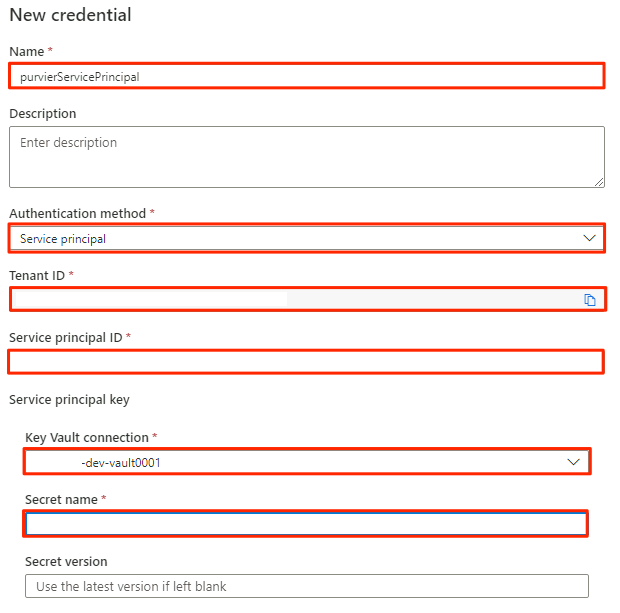
Klicken Sie auf Erstellen.
Registrieren von Datenquellen
An diesem Punkt kann Purview eine Verbindung mit dem Dienstprinzipal herstellen. Jetzt können Sie die Datenquellen registrieren und einrichten.
Registrieren von Azure Data Lake Storage Gen2-Konten
In den folgenden Schritten wird der Prozess zum Registrieren eines Azure Data Lake Storage Gen2-Speicherkontos beschrieben.
Wählen Sie in Purview Studio das Datenzuordnungssymbol aus, wählen Sie Quellen aus, und wählen Sie dann Registrieren aus.
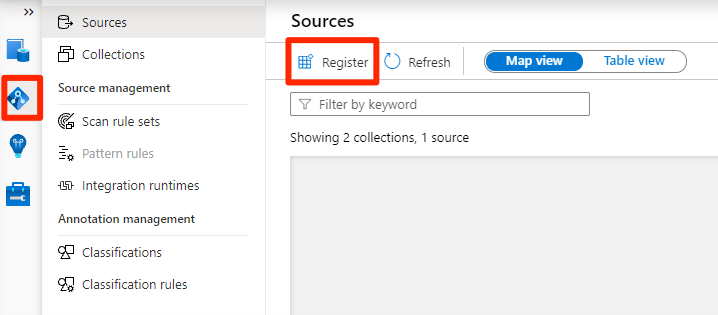
Wählen Sie unter Quellen registrieren die Quelle Azure Data Lake Storage Gen2 und dann Weiter aus.

Wählen Sie unter Quellen registrieren (Azure Data Lake Storage Gen2) die folgenden Informationen aus, oder geben Sie sie ein:
Einstellung Aktion Name Geben Sie <DLZ-prefix>dldevraw ein. Azure-Abonnement Wählen Sie das Abonnement aus, das das Speicherkonto hostet. Speicherkontoname Wählen Sie das relevante Speicherkonto aus. Endpunkt Der Wert wird auf der Grundlage des zuvor ausgewählten Speicherkontos automatisch mit Daten aufgefüllt. Auswählen einer Sammlung Wählen Sie die Stammsammlung aus. 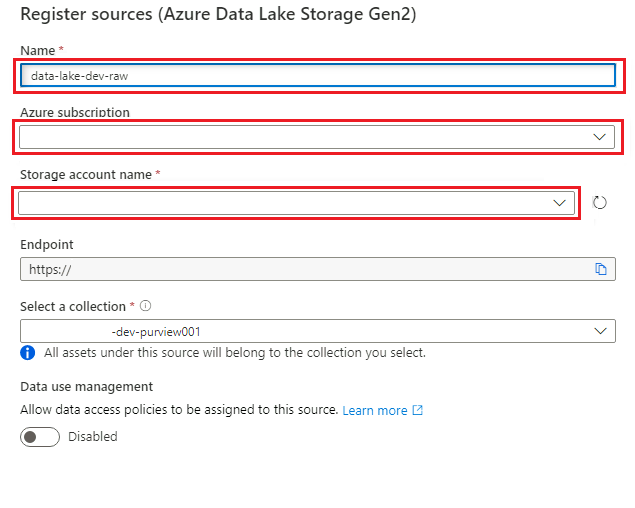
Wählen Sie Registrieren aus, um die Datenquelle zu erstellen.
Wiederholen Sie diese Schritte für die folgenden Speicherkonten:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Registrieren der SQL-Datenbank-Instanz als Datenquelle
Wählen Sie in Purview Studio das Datenzuordnungssymbol aus, wählen Sie Quellen aus, und wählen Sie dann Registrieren aus.
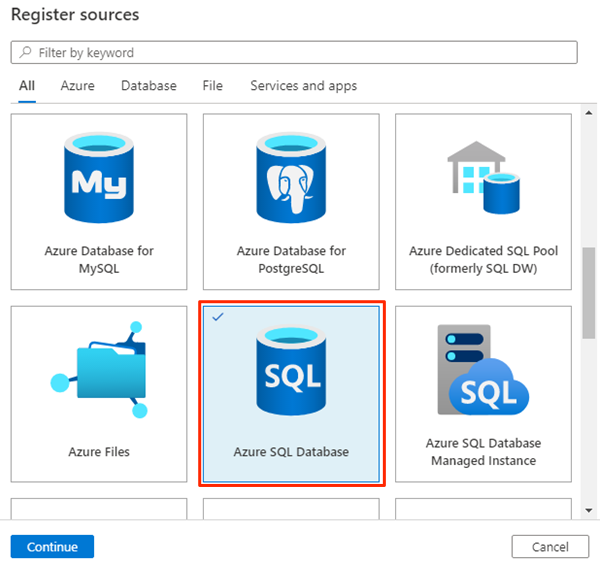
Wählen Sie unter Quellen registrieren die Quelle Azure SQL-Datenbank und dann Weiter aus.
Wählen Sie unter Quellen registrieren (Azure SQL-Datenbank) die folgenden Informationen aus, oder geben Sie diese ein:
Einstellung Aktion Name Geben Sie SQLDatabase ein (den Namen der Datenbank, die in Erstellen von Azure SQL-Datenbank-Instanzen erstellt wurde). Abonnement Wählen Sie das Abonnement aus, das die Datenbank hostet. Servername Geben Sie <DP-prefix>-dev-sqlserver001 ein. 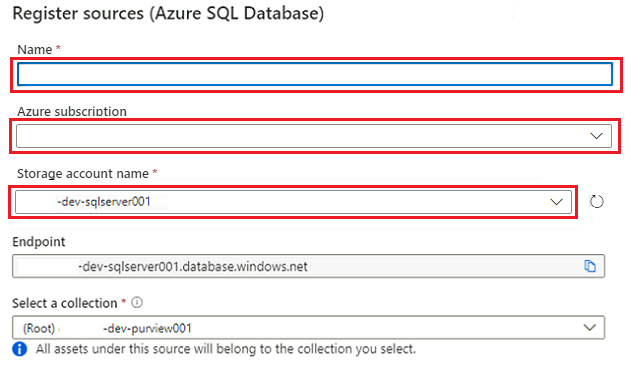
Wählen Sie Registrieren aus.
Einrichten von Scans
Richten Sie nun Scans für die Datenquellen ein.
Scannen der Azure Data Lake Storage Gen2-Datenquelle
Navigieren Sie in Purview Studio zur Datenzuordnung. Wählen Sie für die Datenquelle das Symbol Neuer Scan aus.
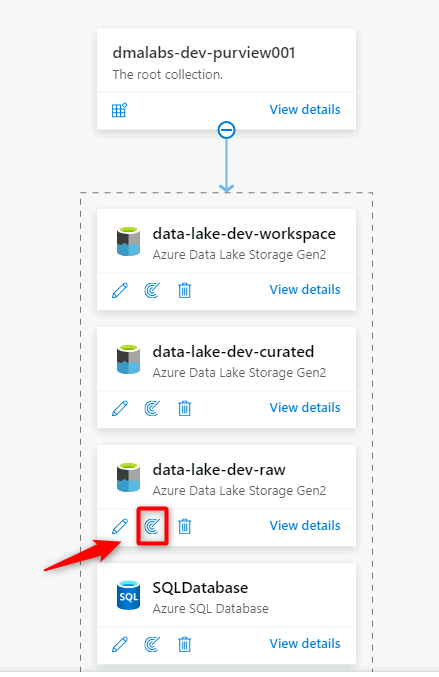
Wählen Sie im Bereich „Neuer Scan“ die folgenden Informationen aus, oder geben Sie diese ein:
Einstellung Aktion Name Geben Sie Scan_<DLZ-prefix>devraw ein. Herstellen einer Verbindung über Integration Runtime Wählen Sie die selbstgehostete Integration Runtime aus, die mit der Datenzielzone bereitgestellt wurde. Credential Wählen Sie den Dienstprinzipal aus, den Sie für Purview eingerichtet haben. 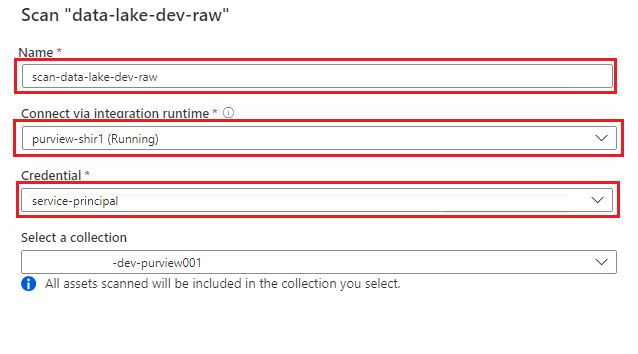
Wählen Sie Verbindung testen aus, um die Konnektivität zu überprüfen und sicherzustellen, dass Berechtigungen vorhanden sind. Wählen Sie Weiter.
Wählen Sie unter Umfang des Scans das gesamte Speicherkonto als Umfang für den Scan aus, und wählen Sie dann Weiter aus.
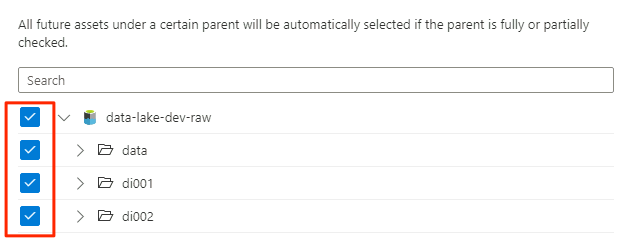
Wählen Sie unter Scanregelsatz auswählen die Option adlsGen2 aus, und wählen Sie dann Weiter aus.
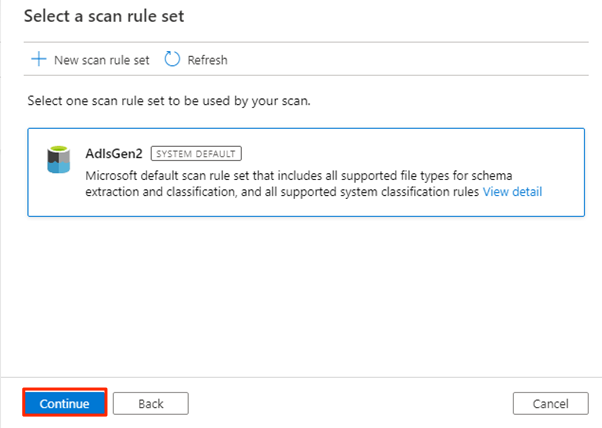
Wählen Sie unter Scantrigger festlegenEin Mal aus, und wählen Sie dann Weiter aus.
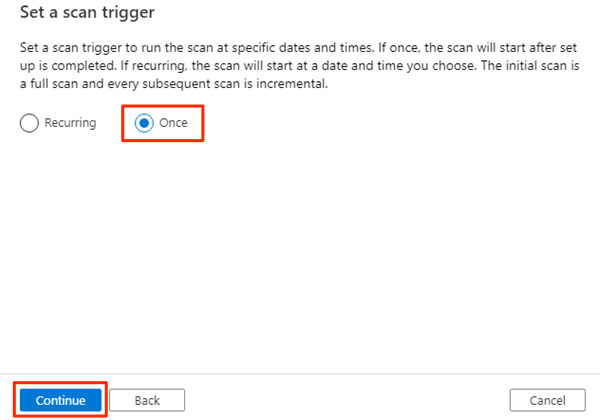
Überprüfen Sie unter Scan überprüfen die Scaneinstellungen. Wählen Sie Speichern und ausführen aus, um den Scan zu starten.
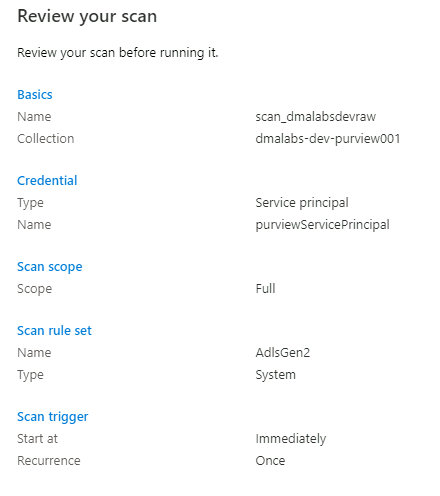
Wiederholen Sie diese Schritte für die folgenden Speicherkonten:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Scannen der Datenquelle der SQL-Datenbank
Wählen Sie in der Datenquelle der Azure SQL-Datenbank Neuer Scan aus.
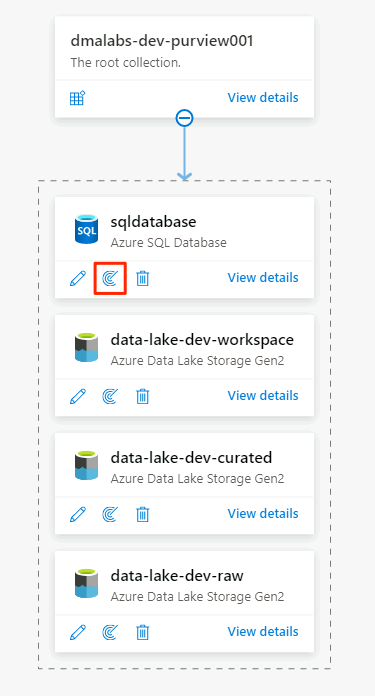
Wählen Sie im Bereich „Neuer Scan“ die folgenden Informationen aus, oder geben Sie diese ein:
Einstellung Aktion Name Geben Sie Scan_Database001 ein. Herstellen einer Verbindung über Integration Runtime Wählen Sie Purview-SHIR aus. Datenbankname Wählen Sie den Datenbanknamen aus. Credential Wählen Sie die Anmeldeinformationen des Schlüsseltresors aus, die Sie in Purview erstellt haben. Datenherkunftsextraktion (Vorschau) Wählen Sie Off (Aus) aus. 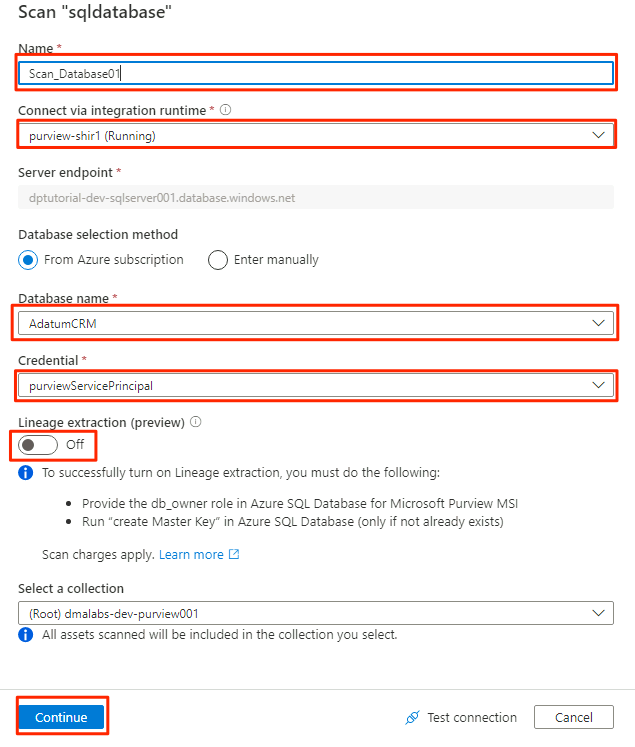
Wählen Sie Verbindung testen aus, um die Konnektivität zu überprüfen und sicherzustellen, dass Berechtigungen vorhanden sind. Wählen Sie Weiter.
Wählen Sie den Bereich für den Scan aus. Um die gesamte Datenbank zu scannen, verwenden Sie den Standardwert.
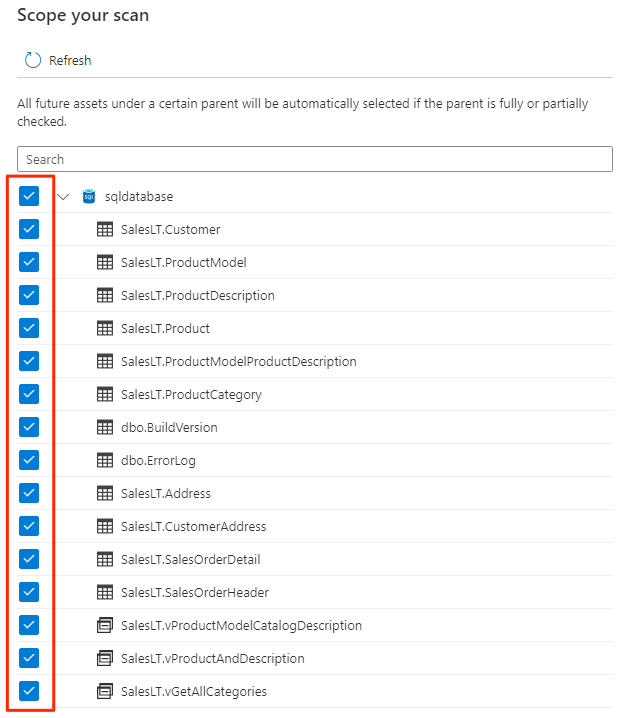
Wählen Sie unter Scanregelsatz auswählen die Option AzureSqlDatabase aus, und wählen Sie dann Weiter aus.
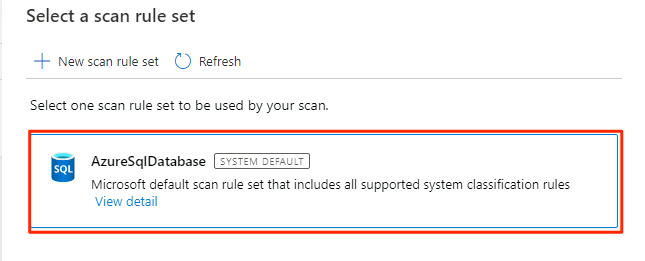
Wählen Sie unter Scantrigger festlegenEin Mal aus, und wählen Sie dann Weiter aus.
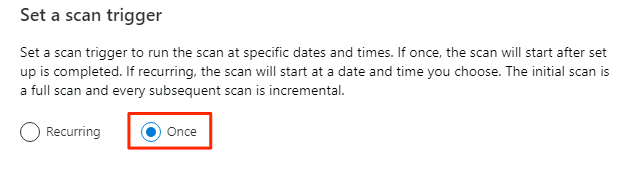
Überprüfen Sie unter Scan überprüfen die Scaneinstellungen. Wählen Sie Speichern und ausführen aus, um den Scan zu starten.
Wiederholen Sie diese Schritte für die AdatumERP-Datenbank.
Purview ist jetzt für Datengovernance für die registrierten Datenquellen eingerichtet.
Kopieren von SQL-Datenbank-Daten in Data Lake Storage Gen2
In den folgenden Schritten verwenden Sie das Tool „Daten kopieren“ in Data Factory, um eine Pipeline zu erstellen, um die Tabellen aus den SQL-Datenbank-Instanzen AdatumCRM und AdatumERP in CSV-Dateien im <DLZ-prefix>devraw-Data Lake Storage Gen2-Konto zu kopieren.
Die Umgebung ist für öffentlichen Zugriff gesperrt, daher müssen Sie zuerst private Endpunkte einrichten. Um die privaten Endpunkte zu verwenden, melden Sie sich am Azure-Portal in Ihrem lokalen Browser an, und stellen Sie dann eine Verbindung mit der Bastion-Host-VM her, um auf die erforderlichen Azure-Dienste zuzugreifen.
Erstellen privater Endpunkte
So richten Sie private Endpunkte für die erforderlichen Ressourcen ein:
Wählen Sie in der
<DMLZ-prefix>-dev-bastion-Ressourcengruppe<DMLZ-prefix>-dev-vm001aus.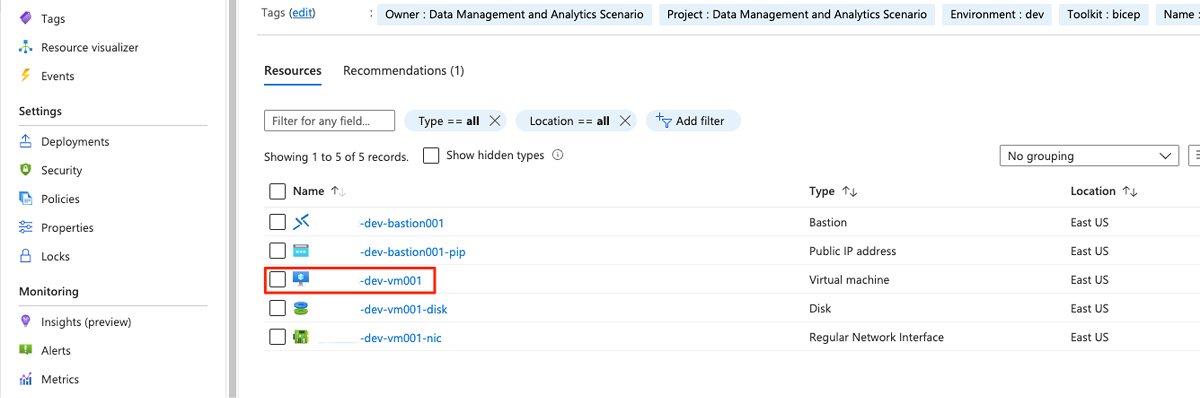
Wählen Sie auf der Befehlsleiste die Option Verbinden und dann Bastion aus.
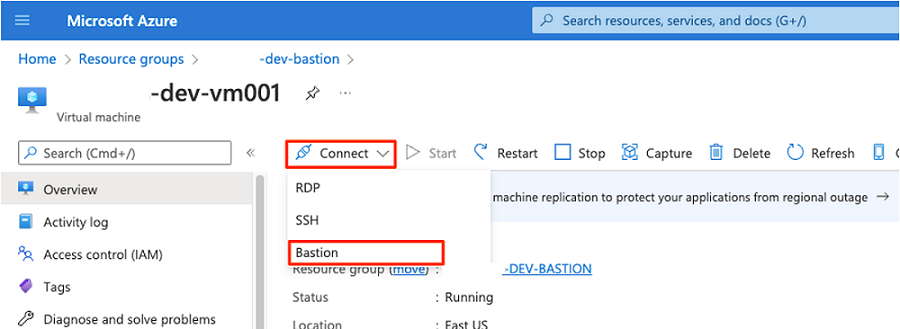
Geben Sie den Benutzernamen und das Kennwort für die VM ein, und wählen Sie dann Verbinden aus.
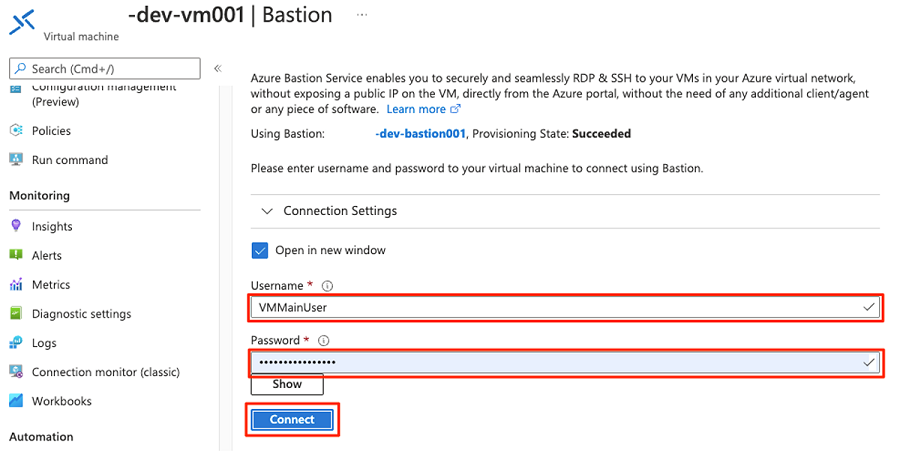
Navigieren Sie im Webbrowser der VM zum Azure-Portal. Navigieren Sie zur
<DLZ-prefix>-dev-shared-integration-Ressourcengruppe, und öffnen Sie die<DLZ-prefix>-dev-integration-datafactory001-Data Factory.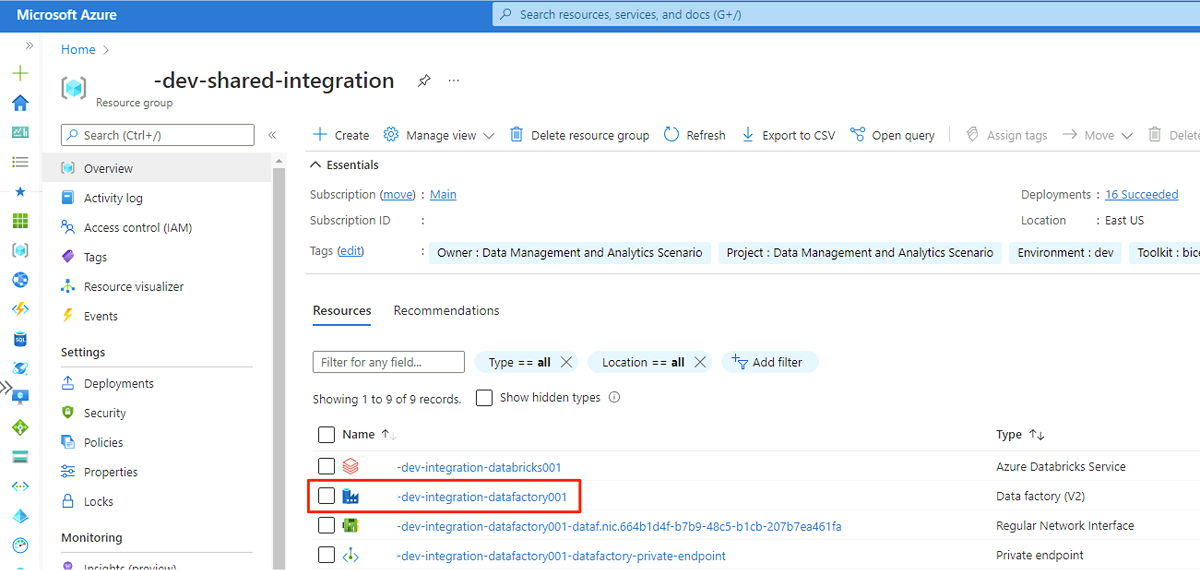
Wählen Sie unter Erste Schritte in Azure Data Factory Studio öffnen die Option Öffnen aus.
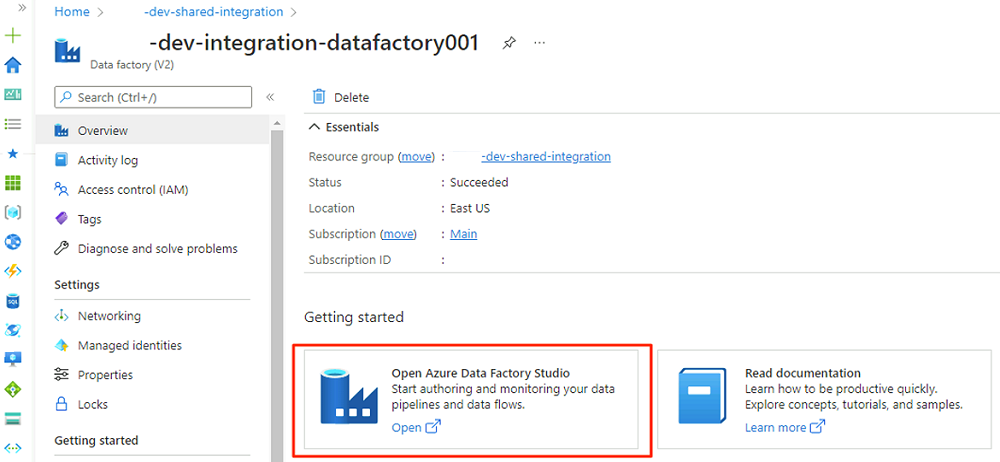
Wählen Sie im Menü „Data Factory Studio“ das Symbol Verwalten aus (das Symbol sieht aus wie ein quadratischer Werkzeugkasten mit einem Schraubenschlüssel). Wählen Sie im Ressourcenmenü Verwaltete private Endpunkte aus, um die privaten Endpunkte zu erstellen, die zum Verbinden von Data Factory mit anderen gesicherten Azure-Diensten erforderlich sind.
Die Genehmigung von Zugriffsanforderungen für die privaten Endpunkte wird in einem späteren Abschnitt behandelt. Nachdem Sie private Endpunktzugriffsanforderungen genehmigt haben, lautet ihr Genehmigungsstatus Genehmigt, wie im folgenden Beispiel für das
<DLZ-prefix>devencur-Speicherkonto gezeigt.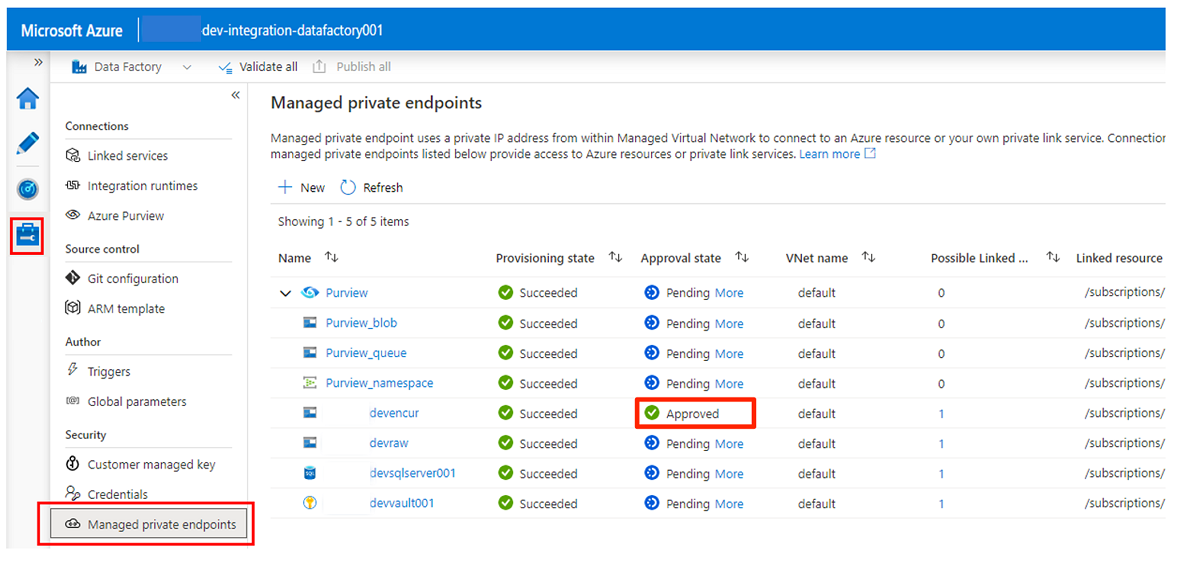
Bevor Sie die privaten Endpunktverbindungen genehmigen, wählen Sie Neu aus. Geben Sie Azure SQL ein, um den Azure SQL-Datenbankconnector zu finden, den Sie zum Erstellen eines neuen verwalteten privaten Endpunkts für die
<DP-prefix>-dev-sqlserver001-Azure SQL-VM verwenden. Die VM enthält die zuvor erstelltenAdatumCRM- undAdatumERP-Datenbanken.Geben Sie unter Neuer verwalteter privater Endpunkt (Azure SQL-Datenbank) als Namedata-product-dev-sqlserver001 ein. Geben Sie das Azure-Abonnement ein, das Sie zum Erstellen der Ressourcen verwendet haben. Wählen Sie als Servername
<DP-prefix>-dev-sqlserver001aus, damit Sie eine Verbindung mit ihm aus dieser Data Factory in den nächsten Abschnitten herstellen können.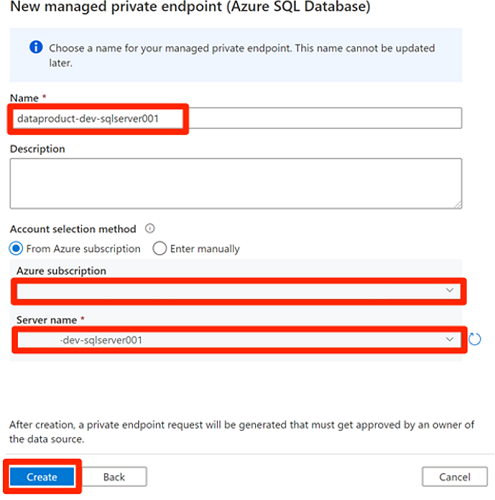



Genehmigen von privaten Endpunktzugriffsanforderungen
Um Daten Factory Zugriff auf die privaten Endpunkte für die erforderlichen Dienste zu gewähren, stehen Ihnen einige Optionen zur Verfügung:
Option 1: Navigieren Sie in jedem Dienst, auf den Sie Zugriff anfordern, im Azure-Portal zur Option für Netzwerk- oder private Endpunktverbindungen des Diensts, und genehmigen Sie die Zugriffsanforderungen auf den privaten Endpunkt.
Option 2: Führen Sie die folgenden Skripts in Azure Cloud Shell im Bash-Modus aus, um alle Anforderungen für den Zugriff auf die erforderlichen privaten Endpunkte auf gleichzeitig zu genehmigen.
# Storage managed private endpoint approval # devencur resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devencur')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # devraw resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devraw')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # SQL Database managed private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-dp001')==\`true\`].name") sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $sqlServerName --type Microsoft.Sql/servers -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $sqlServerName --type Microsoft.Sql/servers --description "Approved" # Key Vault private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-metadata')==\`true\`].name") keyVaultName=$(az keyvault list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'dev-vault001')==\`true\`].name") endPointConnectionID=$(az network private-endpoint-connection list -g $resourceGroupName -n $keyVaultName --type Microsoft.Keyvault/vaults -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].id") az network private-endpoint-connection approve -g $resourceGroupName --id $endPointConnectionID --resource-name $keyVaultName --type Microsoft.Keyvault/vaults --description "Approved" # Purview private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dev-governance')==\`true\`].name") purviewAcctName=$(az purview account list -g $resourceGroupName -o tsv --query "[?contains(@.name, '-dev-purview001')==\`true\`].name") for epn in $(az network private-endpoint-connection list -g $resourceGroupName -n $purviewAcctName --type Microsoft.Purview/accounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") do az network private-endpoint-connection approve -g $resourceGroupName -n $epn --resource-name $purviewAcctName --type Microsoft.Purview/accounts --description "Approved" done
Im folgenden Beispiel wird gezeigt, wie das <DLZ-prefix>devraw-Speicherkonto private Endpunktzugriffsanforderungen verwaltet. Wählen Sie im Ressourcenmenü für das Speicherkonto Netzwerk aus. Wählen Sie in der Befehlsleiste Private Endpunktverbindungen aus.

Für einige Azure-Ressourcen wählen Sie Private Endpunktverbindungen im Ressourcenmenü aus. Ein Beispiel für die Azure SQL Server-Instanz wird im folgenden Screenshot gezeigt.
Wenn Sie eine private Endpunktzugriffsanforderung genehmigen möchten, wählen Sie unterPrivate Endpunktverbindungen die ausstehende Zugriffsanforderung aus, und wählen Sie dann Genehmigen aus:

Nachdem Sie die Zugriffsanforderung in jedem erforderlichen Dienst genehmigt haben, kann es einige Minuten dauern, bis die Anforderung als Genehmigt in Verwaltete private Endpunkte in Data Factory Studio angezeigt wird. Auch wenn Sie in der Befehlsleiste Aktualisieren auswählen, kann der Genehmigungsstatus für einige Minuten unrichtig sein.
Wenn Sie die Genehmigung aller Zugriffsanforderungen für die erforderlichen Dienste abgeschlossen haben, lautet der Wert Genehmigungsstatus für alle Dienste in Verwaltete private EndpunkteGenehmigt:
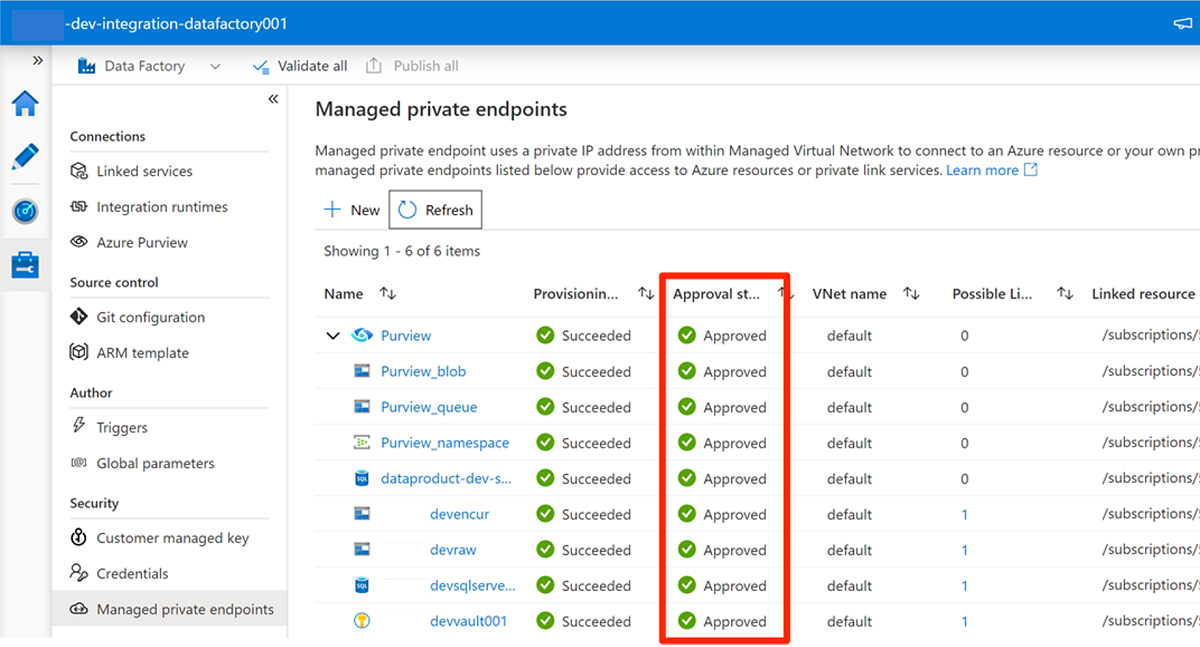
Rollenzuweisungen
Wenn Sie die Genehmigung der Zugriffsanforderungen für private Endpunkte abgeschlossen haben, fügen Sie die entsprechenden Rollenberechtigungen für Data Factory für den Zugriff auf diese Ressourcen hinzu:
- SQL-Datenbank-Instanzen
AdatumCRMundAdatumERPin der<DP-prefix>-dev-sqlserver001-Azure SQL Server-Instanz - Speicherkonten
<DLZ-prefix>devraw,<DLZ-prefix>devencurund<DLZ-prefix>devwork - Purview-Konto
<DMLZ-prefix>-dev-purview001
Azure SQL-VM
Um Rollenzuweisungen hinzuzufügen, beginnen Sie mit der Azure SQL-VM. Navigieren Sie in der
<DMLZ-prefix>-dev-dp001-Ressourcengruppe zu<DP-prefix>-dev-sqlserver001.Wählen Sie im Ressourcenmenü Zugriffssteuerung (IAM) aus. Wählen Sie in der Befehlsleiste Hinzufügen>Rollenzuweisung hinzufügen aus.
Wählen Sie auf der Registerkarte Rolle die Option Mitwirkender und dann Weiter aus.
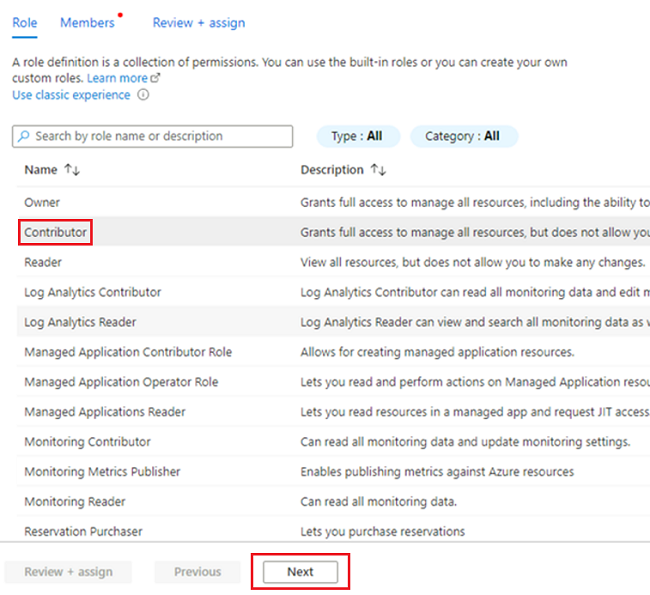
Wählen Sie unter Mitglieder für Zugriff zuweisen zu die Option Verwaltete Identität aus. Wählen Sie unter Mitglieder die Option Mitglieder auswählen aus.
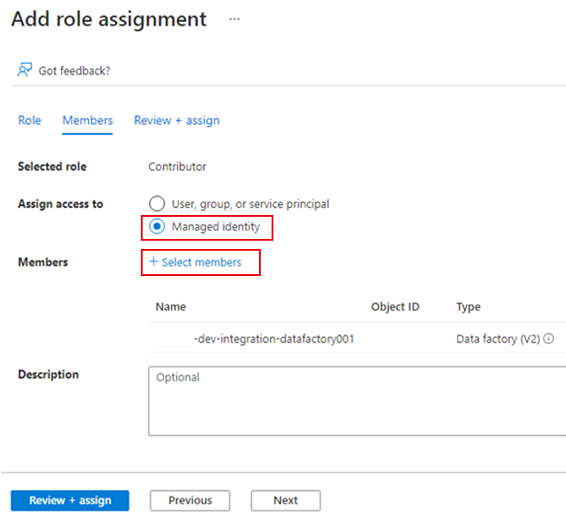
Wählen Sie unter Verwaltete Identitäten auswählen Ihr Azure-Abonnement aus. Wählen Sie als Verwaltete Identität die Option Data Factory (V2) aus, um verfügbare Data Factorys anzuzeigen. Wählen Sie in der Liste der Data Factorys Azure Data Factory <DLZ-prefix>-dev-integration-datafactory001 aus. Klicken Sie auf Auswählen.
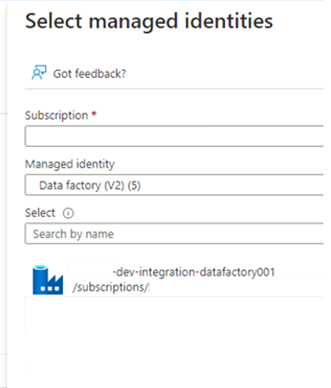
Wählen Sie Überprüfen und Zuweisen zwei Mal aus, um den Vorgang abzuschließen.
Speicherkonten
Weisen Sie nun die erforderlichen Rollen den <DLZ-prefix>devraw-, <DLZ-prefix>devencur- und <DLZ-prefix>devwork-Speicherkonten zu.
Um die Rollen zuzuweisen, führen Sie die gleichen Schritte aus, die Sie zum Erstellen der Azure SQL-Serverrollenzuweisung verwendet haben. Wählen Sie jedoch für die Rolle Speicherblob-Datenmitwirkender anstelle von Mitwirkenden aus.
Nachdem Sie Rollen für alle drei Speicherkonten zugewiesen haben, kann Data Factory eine Verbindung mit den Speicherkonten herstellen und darauf zugreifen.
Microsoft Purview
Der letzte Schritt zum Hinzufügen von Rollenzuweisungen besteht darin, die Rolle „Purview Data Curator“ in Microsoft Purview dem Konto der verwalteten Identität der <DLZ-prefix>-dev-integration-datafactory001-Data Factory hinzuzufügen. Führen Sie die folgenden Schritte aus, damit Data Factory Datenkatalog-Ressourceninformationen aus mehreren Datenquellen an das Purview-Konto senden kann.
Navigieren Sie in der Ressourcengruppe
<DMLZ-prefix>-dev-governancezum Purview-Konto<DMLZ-prefix>-dev-purview001.Wählen Sie in Purview Studio das Datenzuordnungssymbol aus, und wählen Sie dann Sammlungen aus.
Wählen Sie die Registerkarte Rollenzuweisungen für die Sammlung aus. Fügen Sie unter Datenkuratoren die verwaltete Identität für
<DLZ-prefix>-dev-integration-datafactory001hinzu: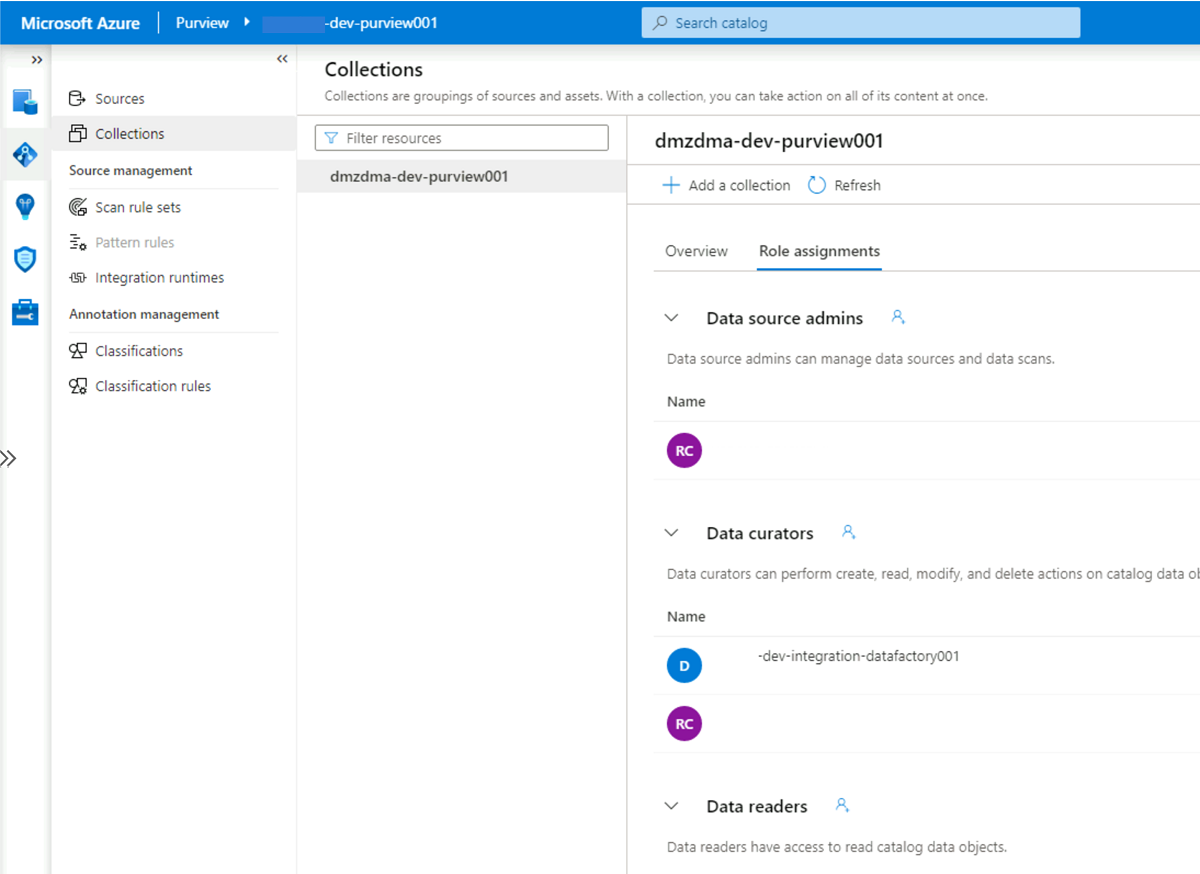
Verbinden von Data Factory mit Purview
Die Berechtigungen sind festgelegt, und Purview kann die Data Factory jetzt sehen. Der nächste Schritt besteht darin, dass <DMLZ-prefix>-dev-purview001 eine Verbindung mit <DLZ-prefix>-dev-integration-datafactory001 herstellt.
Wählen Sie in Purview Studio das Verwaltungssymbol aus, und wählen Sie dann Data Factory aus. Wählen Sie Neu aus, um eine Data Factory-Verbindung zu erstellen.
Geben Sie im Bereich Neue Data Factory-Verbindungen Ihr Azure-Abonnement ein, und wählen Sie die
<DLZ-prefix>-dev-integration-datafactory001-Data Factory aus. Klicken Sie auf OK.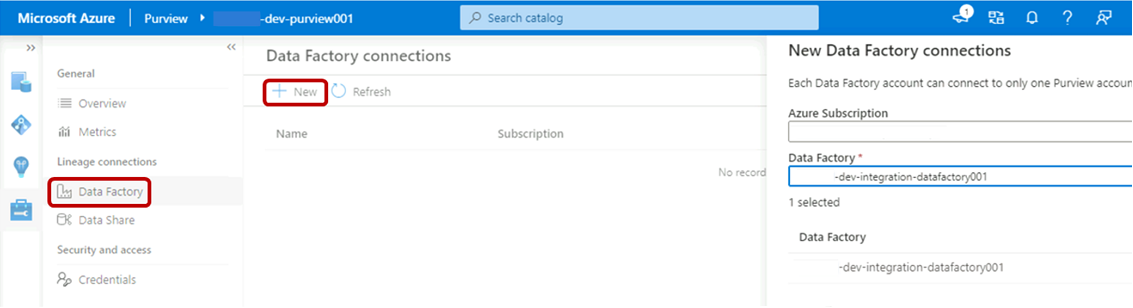
Aktualisieren Sie in der
<DLZ-prefix>-dev-integration-datafactory001-Data Factory Studio-Instanz unter Verwalten>Azure Purview die Angabe Azure Purview-Konto.Die
Data Lineage - Pipeline-Integration zeigt jetzt das grüne Symbol Verbunden an.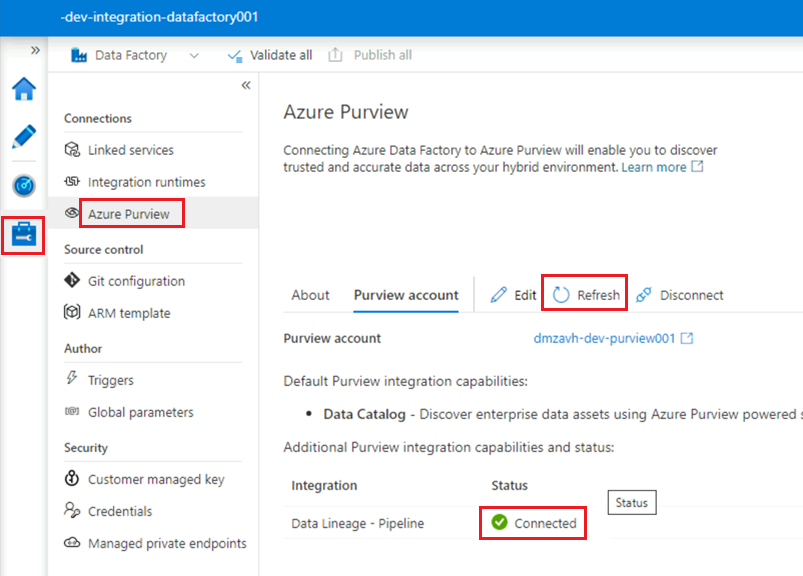

Erstellen einer ETL-Pipeline
Nachdem <DLZ-prefix>-dev-integration-datafactory001 nun über die erforderlichen Zugriffsberechtigungen verfügt, erstellen Sie eine Kopieraktivität in Data Factory, um Daten aus SQL-Datenbank-Instanzen in das <DLZ-prefix>devraw-Rohspeicherkonto zu verschieben.
Verwenden des Tools „Daten kopieren“ mit AdatumCRM
Dieser Prozess extrahiert Kundendaten aus der AdatumCRM-SQL-Datenbank-Instanz und kopiert sie in Data Lake Storage Gen2-Speicher.
Wählen Sie in Data Factory Studio das Symbol Autor aus, und wählen Sie dann Factoryressourcen aus. Wählen Sie das Pluszeichen (+) aus, und wählen Sie das Tool Daten kopieren aus.
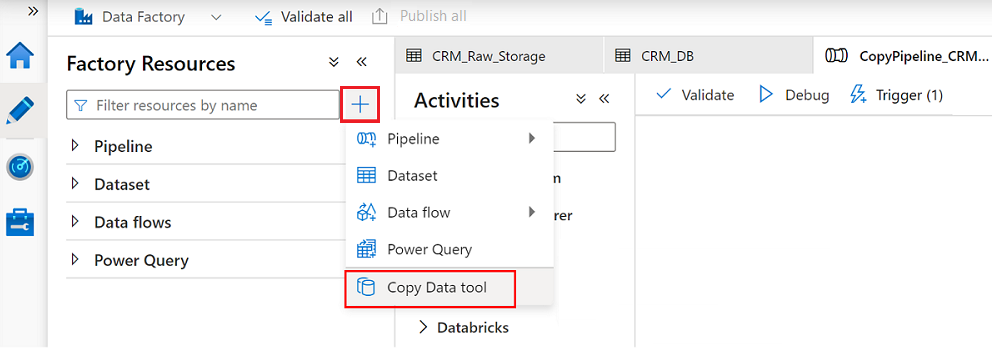
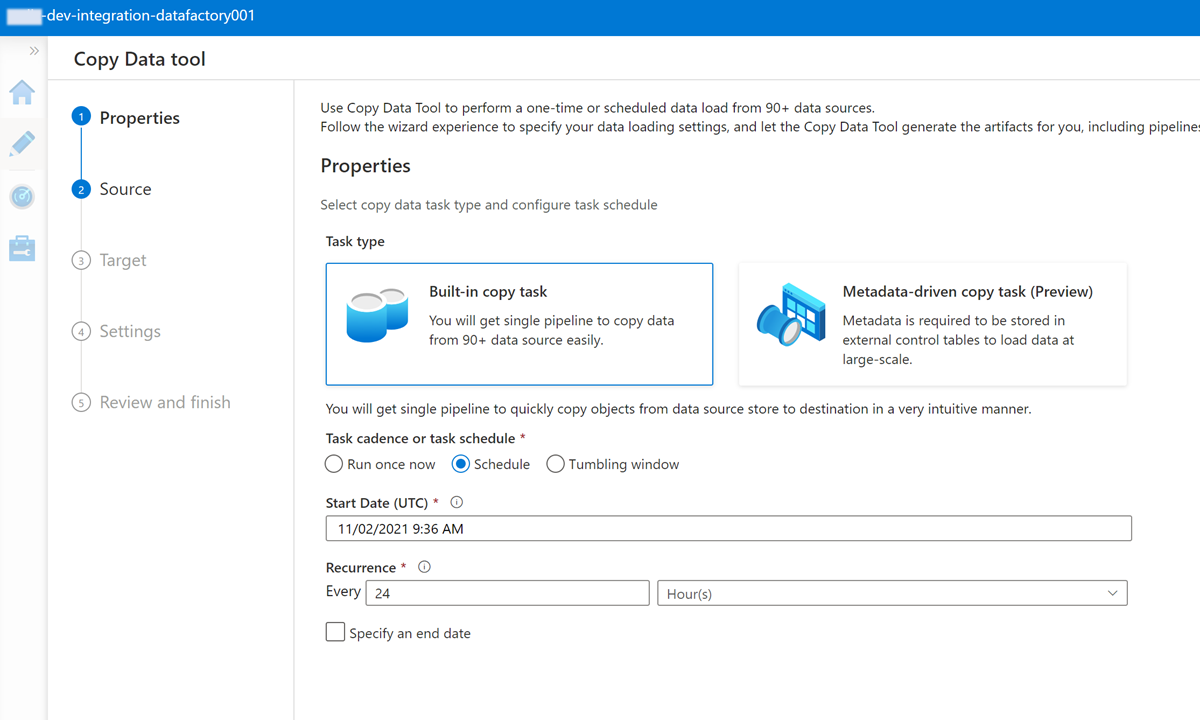
Führen Sie jeden Schritt im Assistenten des Tools zum Kopieren von Daten aus:
Wenn Sie einen Trigger erstellen möchten, um die Pipeline alle 24 Stunden auszuführen, wählen Sie Zeitplan aus.
Um einen verknüpften Dienst zu erstellen und diese Data Factory mit der
AdatumCRM-SQL-Datenbank-Instanz auf dem<DP-prefix>-dev-sqlserver001-Server (Quelle) zu verbinden, wählen Sie Neue Verbindung aus.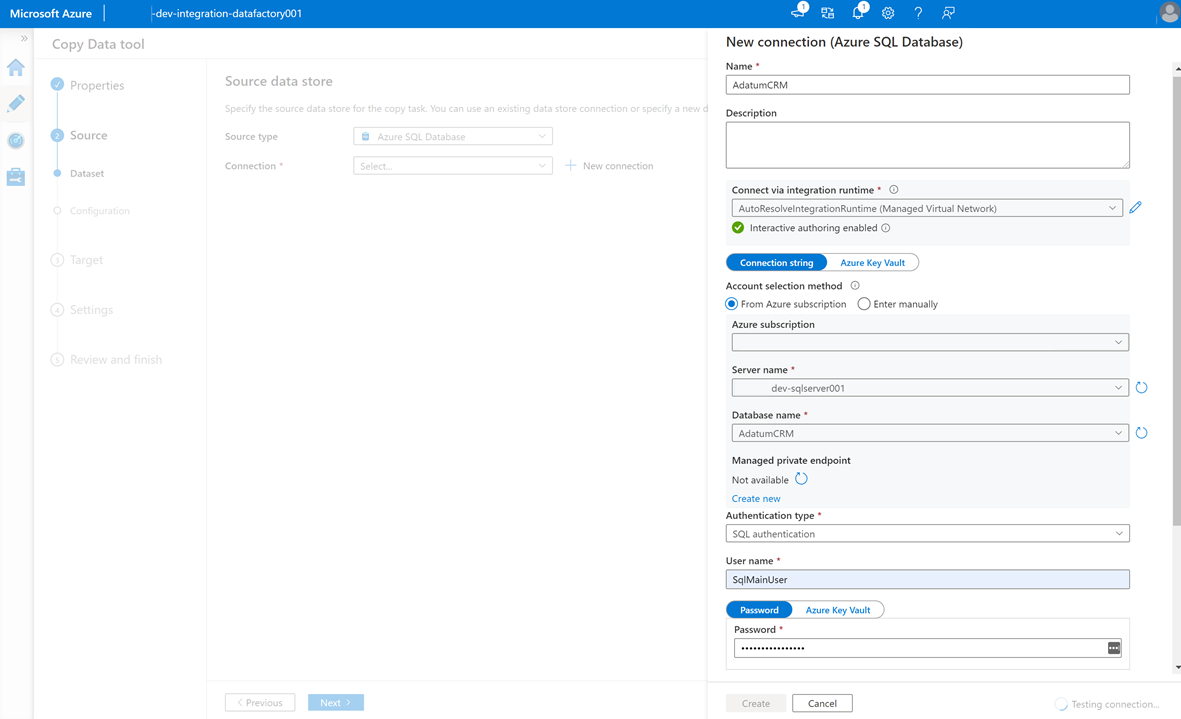
Hinweis
Wenn Fehler beim Verbinden mit den oder Zugreifen auf die Daten in den SQL-Datenbank-Instanzen oder Speicherkonten auftreten, überprüfen Sie Ihre Berechtigungen im Azure-Abonnement. Stellen Sie sicher, dass die Data Factory über die erforderlichen Anmeldeinformationen und Zugriffsberechtigungen für jede problematische Ressource verfügt.
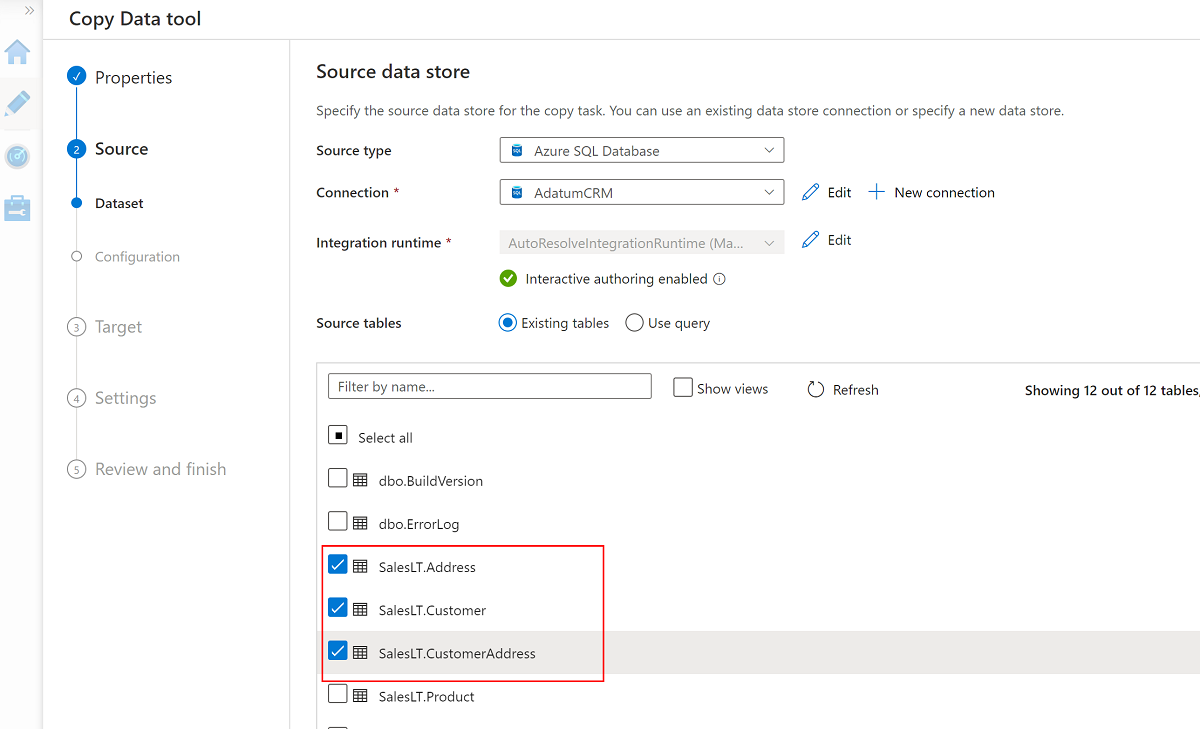
Wählen Sie diese drei Tabellen aus:
SalesLT.AddressSalesLT.CustomerSalesLT.CustomerAddress
Erstellen Sie einen neuen verknüpften Dienst, um auf den
<DLZ-prefix>devraw-Azure Data Lake Storage Gen2-Speicher (Ziel) zuzugreifen.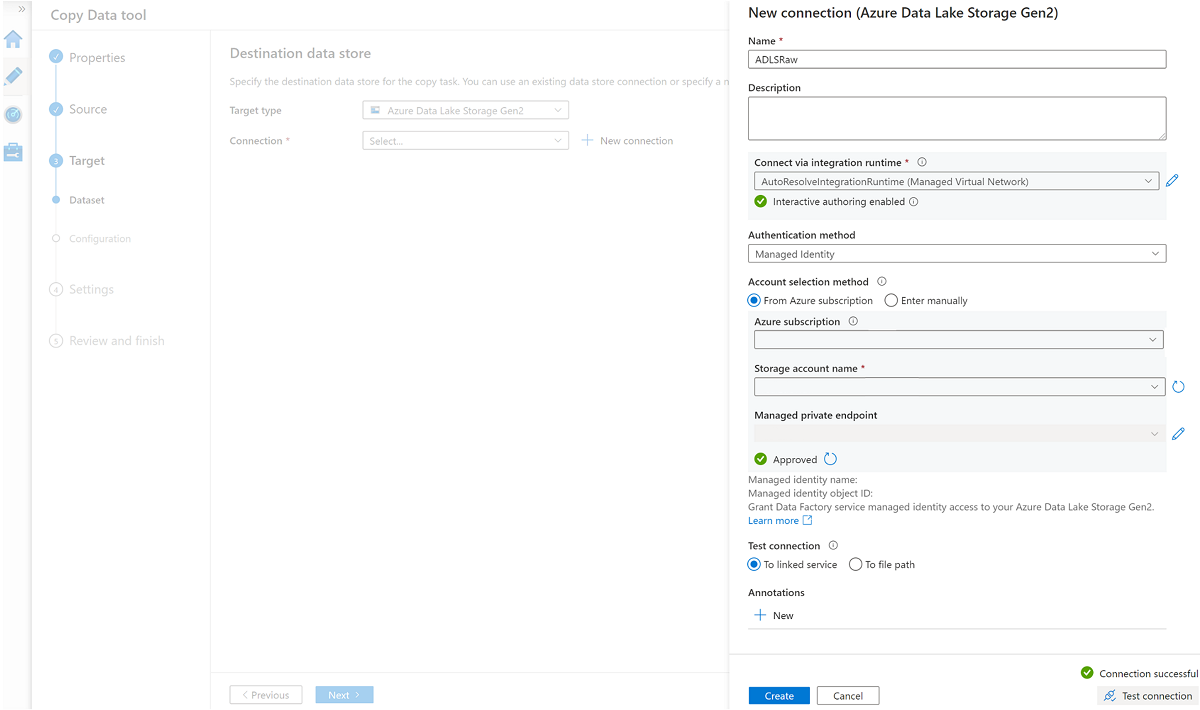
Durchsuchen Sie die Ordner im
<DLZ-prefix>devraw-Speicher, und wählen Sie Daten als Ziel aus.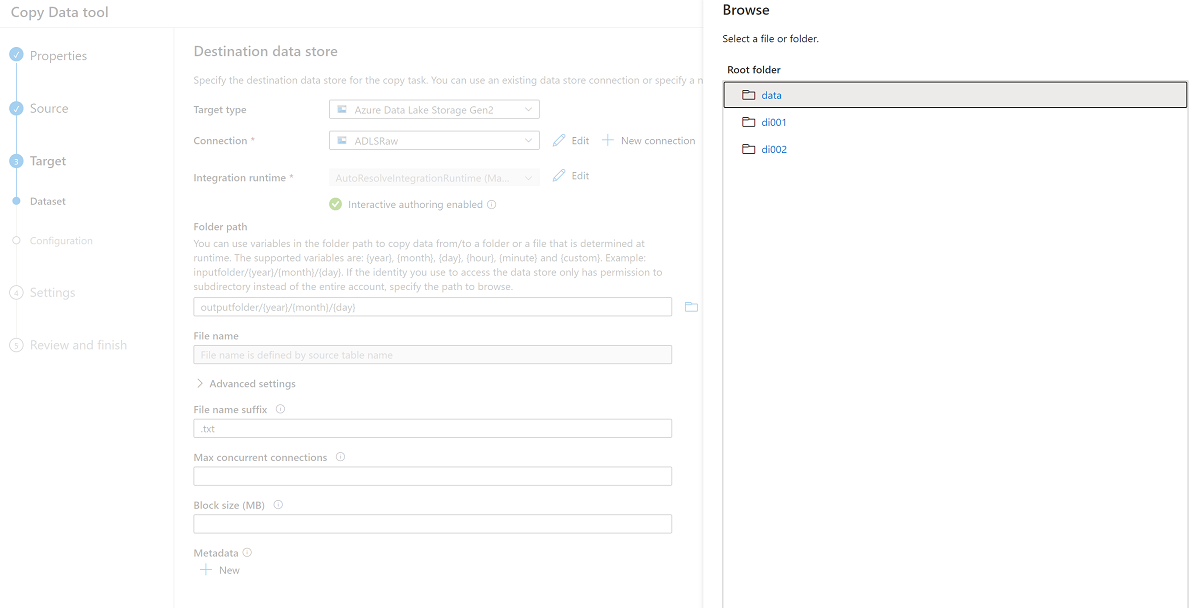
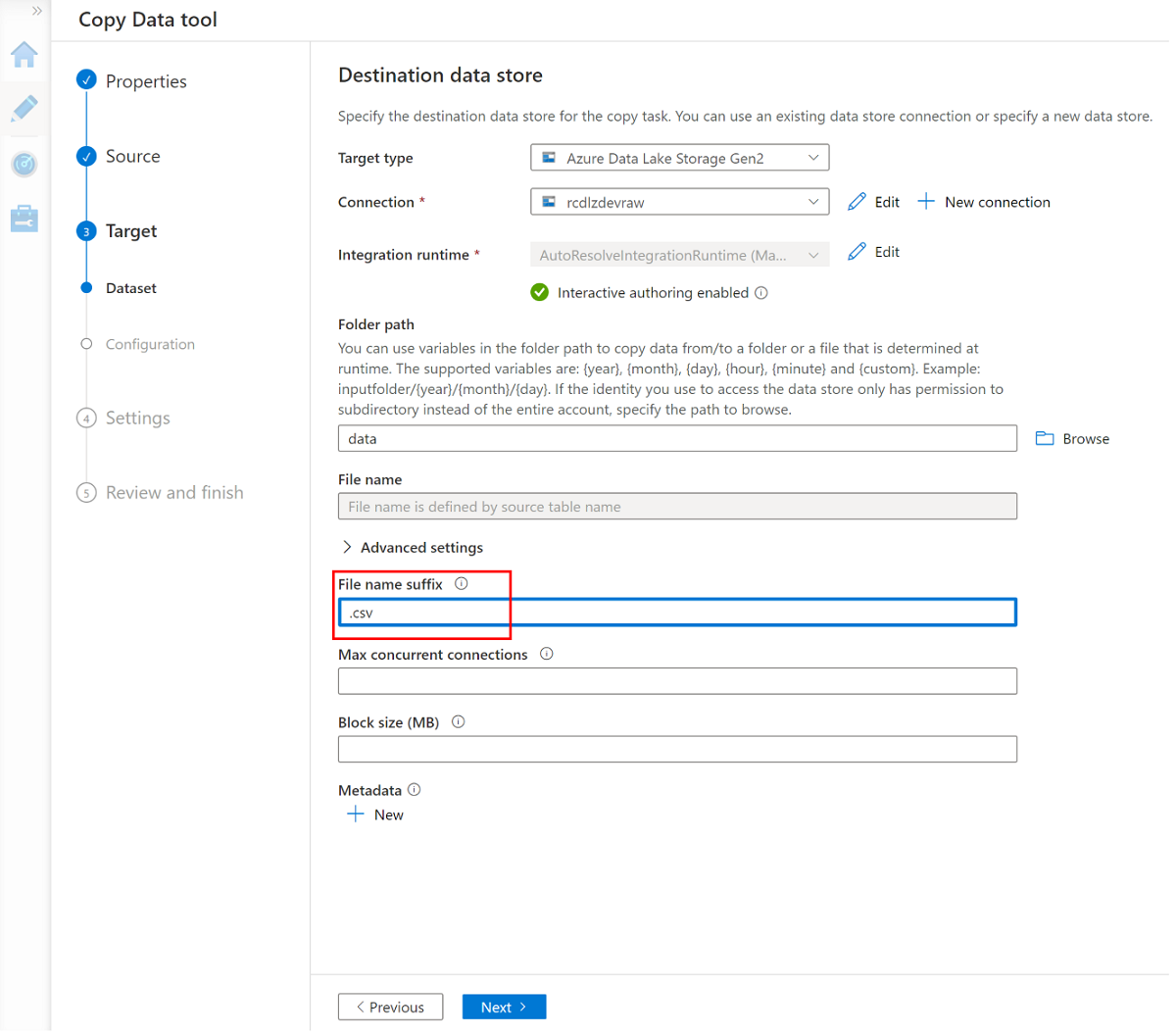
Ändern Sie das Dateinamensuffix in .csv, und verwenden Sie die anderen Standardoptionen.
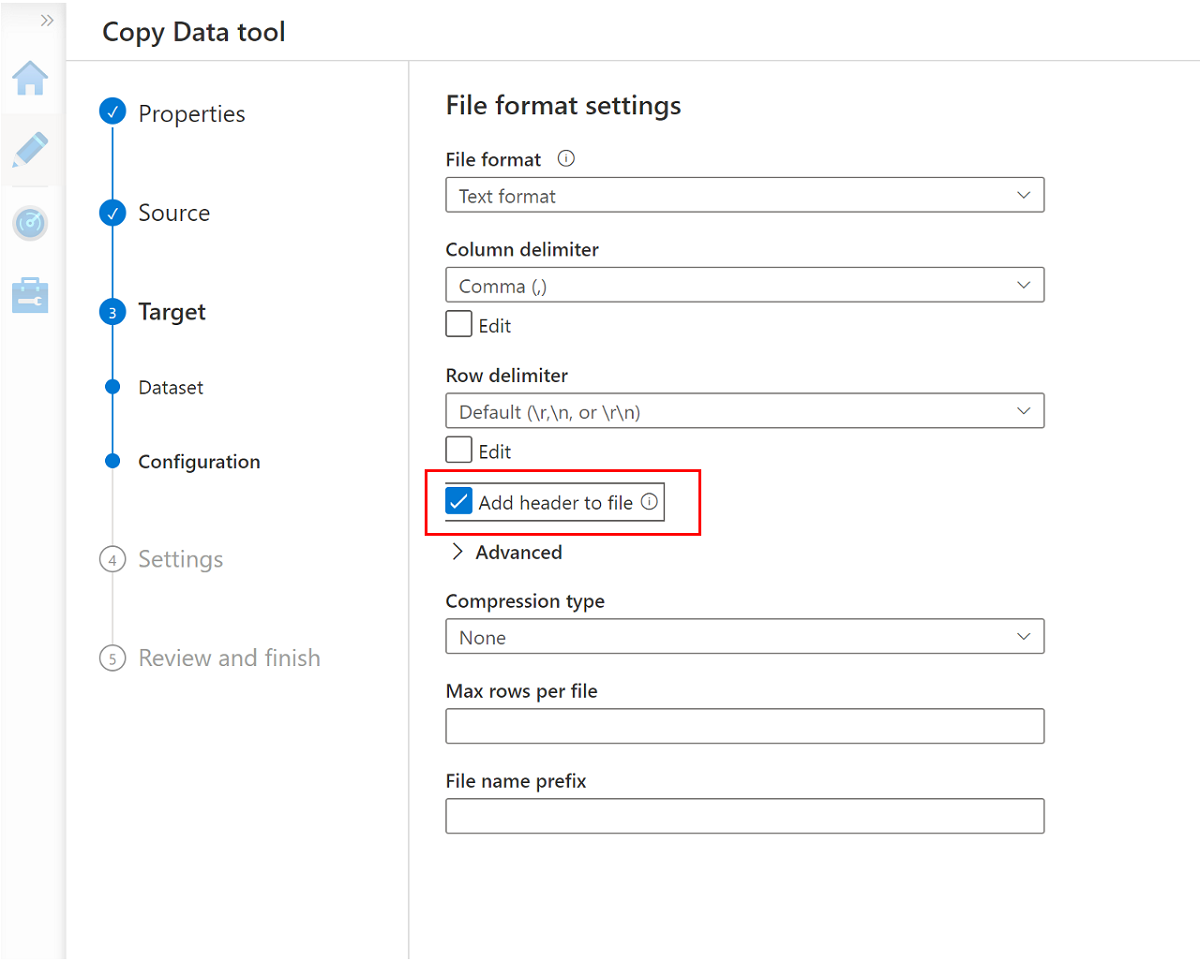
Navigieren Sie zum nächsten Bereich, und wählen Sie Datei Kopfzeile hinzufügen aus.
Wenn Sie den Assistenten fertig stellen, sieht der Bereich Bereitstellung abgeschlossen ähnlich wie dieses Beispiel aus:
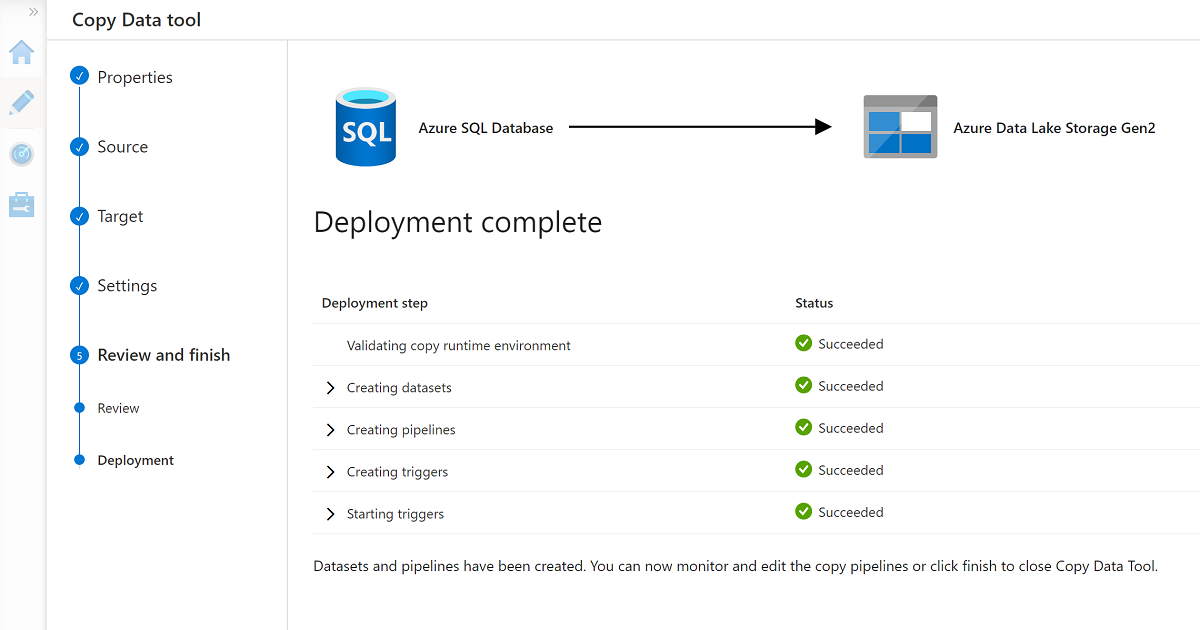




Die neue Pipeline wird unter Pipelines aufgeführt.
Führen Sie die Pipeline aus.
Dieser Prozess erstellt drei CSV-Dateien im Ordner Data\CRM: eine Datei für jede der ausgewählten Tabellen in der AdatumCRM-Datenbank.
Benennen Sie die Pipeline
CopyPipeline_CRM_to_Rawum.Benennen Sie die Datasets
CRM_Raw_StorageundCRM_DBum.Wählen Sie in der Befehlsleiste Factoryressourcen die Option Alle veröffentlichen aus.
Wählen Sie die
CopyPipeline_CRM_to_Raw-Pipeline und dann in der Pipelinebefehlsleiste Trigger aus, um die drei Tabellen aus SQL-Datenbank in Data Lake Storage Gen2 zu kopieren.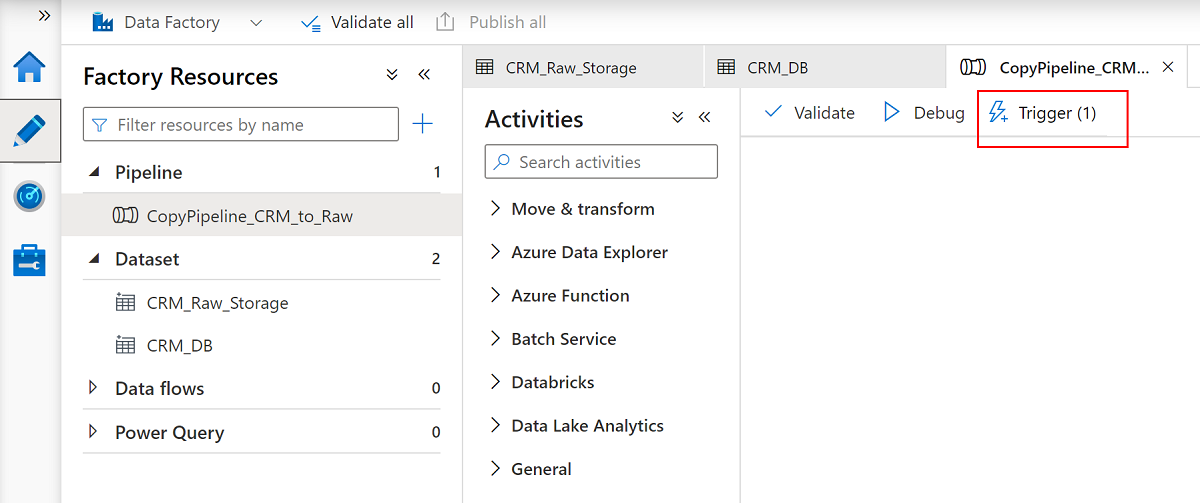
Verwenden des Tools „Daten kopieren“ mit AdatumERP
Extrahieren Sie nun die Daten aus der AdatumERP Datenbank. Die Daten stellen Umsatzdaten aus dem ERP-System dar.
Erstellen Sie in Data Factory Studio eine neue Pipeline mithilfe des Tools „Daten kopieren“. Dieses Mal senden Sie die Umsatzdaten aus
AdatumERPin den Datenordner des<DLZ-prefix>devraw-Speicherkontos, genau wie Sie bei den CRM-Daten verfahren sind. Führen Sie die gleichen Schritte aus, verwenden Sie jedoch dieAdatumERP-Datenbank als Quelle.Erstellen Sie den Zeitplan so, dass er jede Stunde ausgelöst wird.
Erstellen Sie einen verknüpften Dienst mit der
AdatumERP-SQL-Datenbank-Instanz.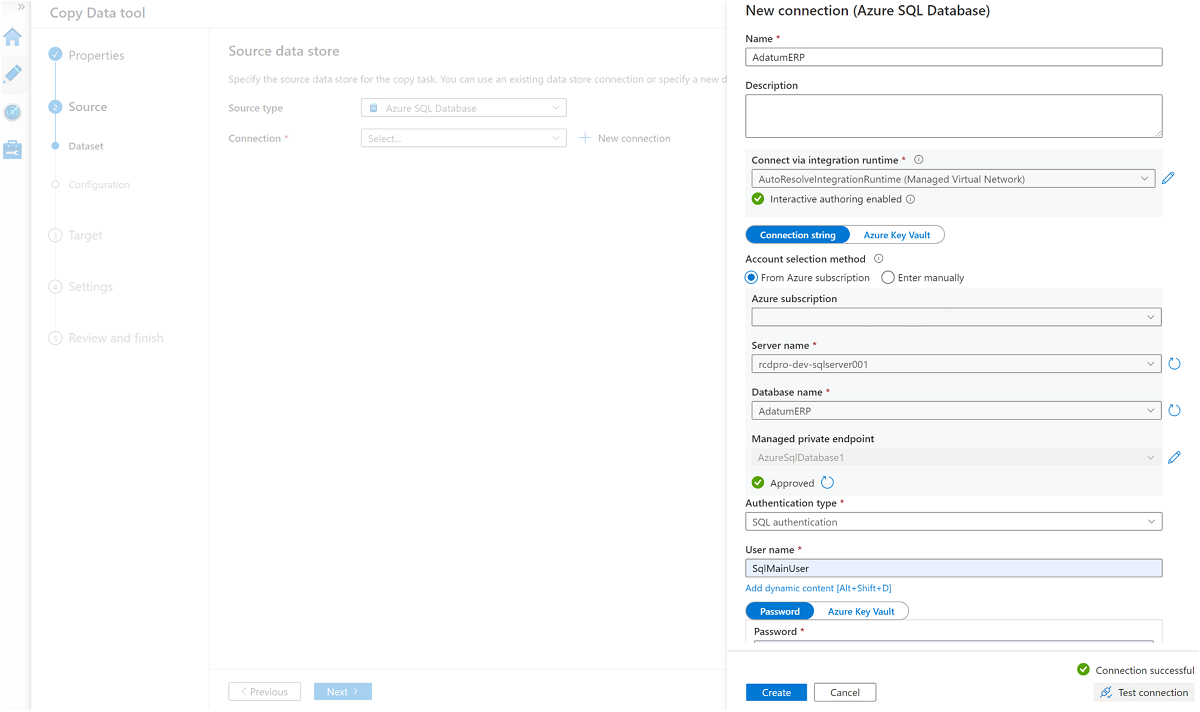
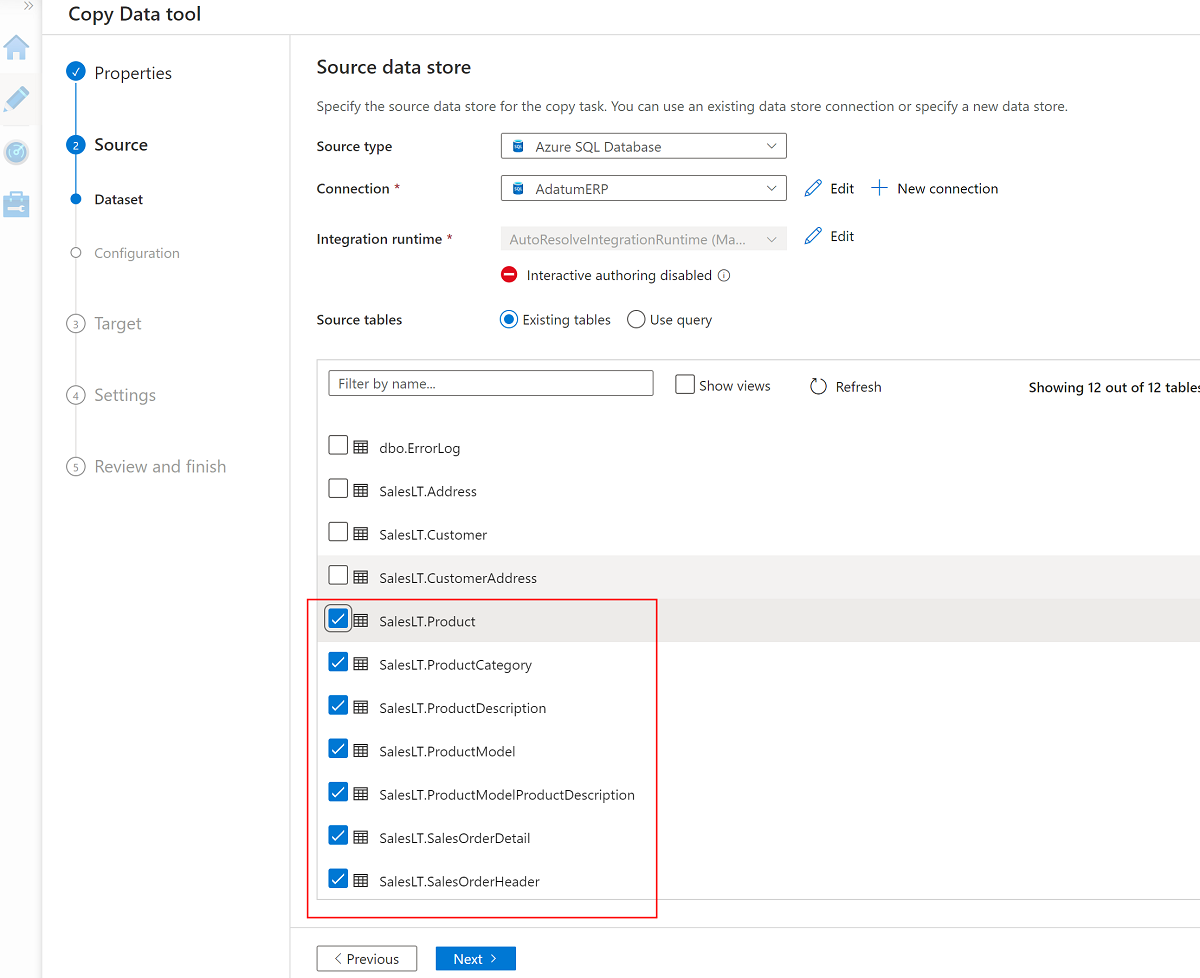
Wählen Sie die folgenden sieben Tabellen aus:
SalesLT.ProductSalesLT.ProductCategorySalesLT.ProductDescriptionSalesLT.ProductModelSalesLT.ProductModelProductDescriptionSalesLT.SalesOrderDetailSalesLT.SalesOrderHeader
Verwenden Sie den vorhandenen verknüpften Dienst zum
<DLZ-prefix>devraw-Speicherkonto, und legen Sie die Dateierweiterung auf .csv fest.
Wählen Sie Datei Kopfzeile hinzufügen aus.
Schließen Sie den Assistenten erneut ab, und benennen Sie die Pipeline
CopyPipeline_ERP_to_DevRawum. Wählen Sie dann in der Befehlsleiste Alle veröffentlichen aus. Führen Sie schließlich den Trigger für diese neu erstellten Pipeline aus, um die sieben ausgewählten Tabellen aus SQL-Datenbank in Data Lake Storage Gen2 zu kopieren.

Nachdem Sie diese Schritte abgeschlossen haben, befinden sich 10 CSV-Dateien im <DLZ-prefix>devraw-Data Lake Storage Gen2-Speicher. Im nächsten Abschnitt stellen Sie die Dateien im <DLZ-prefix>devencur-Data Lake Storage Gen2-Speicher zusammen.
Zusammenstellen von Daten in Data Lake Storage Gen2
Wenn Sie das Erstellen der 10 CSV-Dateien im <DLZ-prefix>devraw-Data Lake Storage Gen2-Rohspeicher abgeschlossen haben, transformieren Sie diese Dateien nach Bedarf, wenn Sie sie in den zusammengestellten <DLZ-prefix>devencur-Data Lake Storage Gen2-Speicher kopieren.
Verwenden Sie weiterhin Azure Data Factory, um diese neuen Pipelines zum Orchestrieren der Datenverschiebung zu erstellen.
Zusammenstellen von CRM zu Kundendaten
Erstellen Sie einen Datenfluss, der die CSV-Dateien im Ordner Data\CRM in <DLZ-prefix>devraw abruft. Transformieren Sie die Dateien, und kopieren Sie die transformierten Dateien im PARQUET-Dateiformat in den Ordner Data\Customer in <DLZ-prefix>devencur.
Navigieren Sie in Azure Data Factory zur Data Factory, und wählen Sie Orchestrieren aus.
Benennen Sie die Pipeline unterAllgemein
Pipeline_transform_CRM.Klappen Sie im Bereich Aktivitäten das Element Verschieben und transformieren auf. Ziehen Sie die Datenflussaktivität, und legen Sie sie auf der Pipelinecanvas ab.
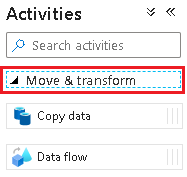
Wählen Sie unter Datenfluss hinzufügen die Option Neuen Datenfluss erstellen aus, und nennen Sie den Datenfluss
CRM_to_Customer. Wählen Sie Fertig stellen aus.Hinweis
Aktivieren Sie in der Befehlsleiste der Pipelinecanvas Datenfluss debuggen. Im Debugmodus können Sie die Transformationslogik interaktiv mit einem Apache Spark-Livecluster testen. Das Aufwärmen von Datenflussclustern dauert 5 bis 7 Minuten. Es wird empfohlen, das Debuggen zu aktivieren, bevor Sie mit der Datenflussentwicklung beginnen.

Wenn Sie mit der Auswahl der Optionen im
CRM_to_Customer-Datenfluss fertig sind, sieht diePipeline_transform_CRM-Pipeline ähnlich wie dieses Beispiel aus: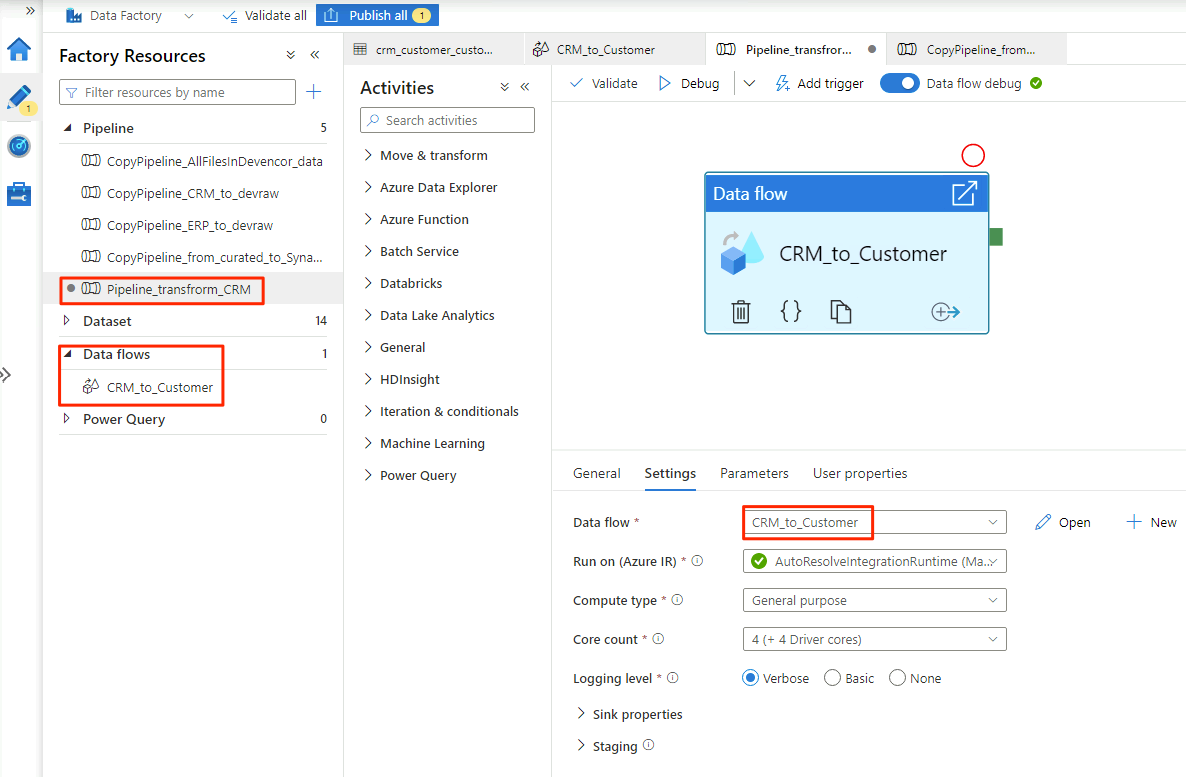
Der Datenfluss sieht wie dieses Beispiel aus:
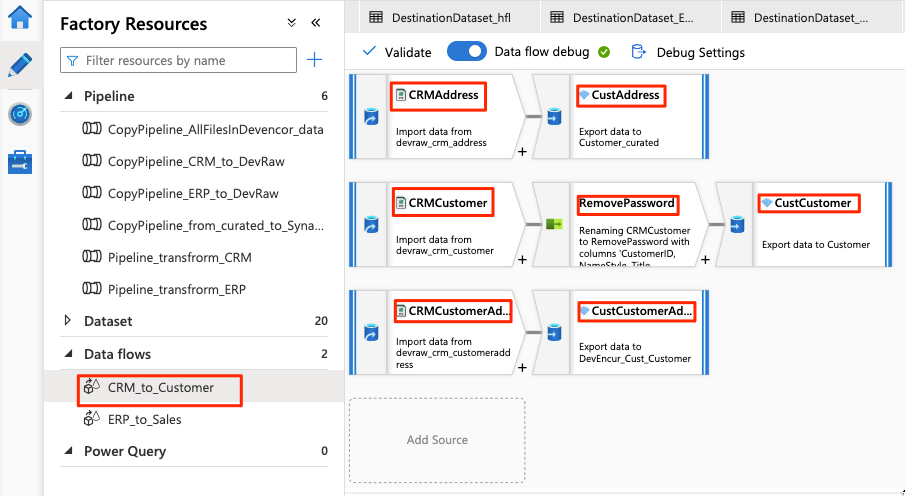
Ändern Sie nun die folgenden Einstellungen im Datenfluss für die
CRMAddress-Quelle:Erstellen Sie ein neues Dataset aus Data Lake Storage Gen2. Verwenden Sie das DelimitedText-Format. Benennen Sie das Dataset mit
DevRaw_CRM_Address.Verbinden Sie den verknüpften Dienst mit
<DLZ-prefix>devraw.Wählen Sie die Datei
Data\CRM\SalesLTAddress.csvals Quelle aus.
Ändern Sie die folgenden Einstellungen im Datenfluss für die gekoppelte
CustAddress-Senke:Erstellen Sie ein neues Dataset namens
DevEncur_Cust_Address.Wählen Sie den Ordner Data\Customer in
<DLZ-prefix>devencurals Senke aus.Konvertieren Sie unter Einstellungen\Ausgabe in einzelne Datei die Datei in Address.parquet.
Verwenden Sie für die restliche Datenflusskonfiguration die Informationen in den folgenden Tabellen für jede Komponente. Beachten Sie, dass es sich bei CRMAddressund CustAddress um die ersten beiden Zeilen handelt. Verwenden Sie sie als Beispiele für die anderen Objekte.
Ein Element, das sich in keiner der folgenden Tabellen befindet, ist der RemovePasswords-Schemamodifizierer. Der Screenshot oben zeigt, dass dieses Element zwischen CRMCustomer und CustCustomer eingefügt wird. Um diesen Schemamodifizierer hinzuzufügen, navigieren Sie zu Einstellungen auswählen und entfernen PasswordHash und PasswordSalt.
CRMCustomer gibt ein Schema mit 15 Spalten aus der CRV-Datei zurück. CustCustomer schreibt nur 13 Spalten, nachdem der Schemamodifizierer die beiden Kennwortspalten entfernt hat.
Die vollständige Tabelle
| Name | Objekttyp | Datasetname | Datenspeicher | Formattyp | Verknüpfter Dienst | Datei oder Ordner |
|---|---|---|---|---|---|---|
CRMAddress |
source | DevRaw_CRM_Address |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTAddress.csv |
CustAddress |
sink | DevEncur_Cust_Address |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Address.parquet |
CRMCustomer |
source | DevRaw_CRM_Customer |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTCustomer.csv |
CustCustomer |
sink | DevEncur_Cust_Customer |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Customer.parquet |
CRMCustomerAddress |
source | DevRaw_CRM_CustomerAddress |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTCustomerAddress.csv |
CustCustomerAddress |
sink | DevEncur_Cust_CustomerAddress |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\CustomerAddress.parquet |
Die ERP-to-Sales-Tabelle
Wiederholen Sie nun ähnliche Schritte, um eine Pipeline_transform_ERP-Pipeline zu erstellen, erstellen Sie einen ERP_to_Sales Datenfluss, um die CSV-Dateien im Ordner Data\ERP in <DLZ-prefix>devraw zu transformieren, und kopieren Sie die transformierten Dateien in den Ordner Data\Sales in <DLZ-prefix>devencur.
In der folgenden Tabelle finden Sie die Objekte, die im ERP_to_Sales-Datenfluss erstellt werden sollen, sowie die Einstellungen, die Sie für jedes Objekt ändern müssen. Jede CSV-Datei wird einer PARQUET-Senke zugeordnet.
| Name | Objekttyp | Datasetname | Datenspeicher | Formattyp | Verknüpfter Dienst | Datei oder Ordner |
|---|---|---|---|---|---|---|
ERPProduct |
source | DevRaw_ERP_Product |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProduct.csv |
SalesProduct |
sink | DevEncur_Sales_Product |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\Product.parquet |
ERPProductCategory |
source | DevRaw_ERP_ProductCategory |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductCategory.csv |
SalesProductCategory |
sink | DevEncur_Sales_ProductCategory |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductCategory.parquet |
ERPProductDescription |
source | DevRaw_ERP_ProductDescription |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductDescription.csv |
SalesProductDescription |
sink | DevEncur_Sales_ProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductDescription.parquet |
ERPProductModel |
source | DevRaw_ERP_ProductModel |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductModel.csv |
SalesProductModel |
sink | DevEncur_Sales_ProductModel |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModel.parquet |
ERPProductModelProductDescription |
source | DevRaw_ERP_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductModelProductDescription.csv |
SalesProductModelProductDescription |
sink | DevEncur_Sales_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModelProductDescription.parquet |
ERPProductSalesOrderDetail |
source | DevRaw_ERP_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductSalesOrderDetail.csv |
SalesProductSalesOrderDetail |
sink | DevEncur_Sales_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderDetail.parquet |
ERPProductSalesOrderHeader |
source | DevRaw_ERP_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductSalesOrderHeader.csv |
SalesProductSalesOrderHeader |
sink | DevEncur_Sales_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderHeader.parquet |