Abrufen der Gesichtsposition mit Mundbild
Hinweis
Informationen zu den für Mundbild-ID unterstützten Gebietsschemas und Mischformen finden Sie in der Liste aller unterstützten Gebietsschemas. Skalierbare Vektorgrafiken (SVG) werden nur für das en-US-Gebietsschema unterstützt.
Ein Visem ist die visuelle Beschreibung eines Phonems in der gesprochenen Sprache. Es bestimmt die Position des Gesichts und des Mundes, während eine Person spricht. Jedes Visem stellt die wichtigsten Gesichtsausdrücke für einen bestimmten Satz von Phonemen dar.
Sie können Visemes verwenden, um die Bewegung von 2D- und 3D-Avatar-Modellen zu steuern, sodass die Gesichtspositionen am besten an synthetischer Sprache ausgerichtet sind. Beispielsweise können Sie folgende Aktionen ausführen:
- Erstellen Sie einen animierten virtuellen Sprachassistenten für intelligente Kioske, um integrierte Mehrfachmodusdienste für Ihre Kunden zu entwickeln.
- Erstellen Sie immersive Nachrichtensendungen, und verbessern Sie das Zuschauererlebnis mit natürlichen Gesichts- und Mundbewegungen.
- Erstellen Sie interaktivere Gaming-Avatare und Cartoon-Figuren, die mit dynamischen Inhalten sprechen können.
- Erstellen Sie effektivere Sprachlernvideos, die Sprachlernenden helfen, das Verhalten des Munds bei einzelnen Wörtern und Phonemen zu verstehen.
- Hörgeschädigte können Töne auch visuell wahrnehmen und Sprachinhalte aus den Visemen in einem animierten Gesicht ableiten.
Weitere Informationen zu Visemen finden Sie in diesem Einführungsvideo.
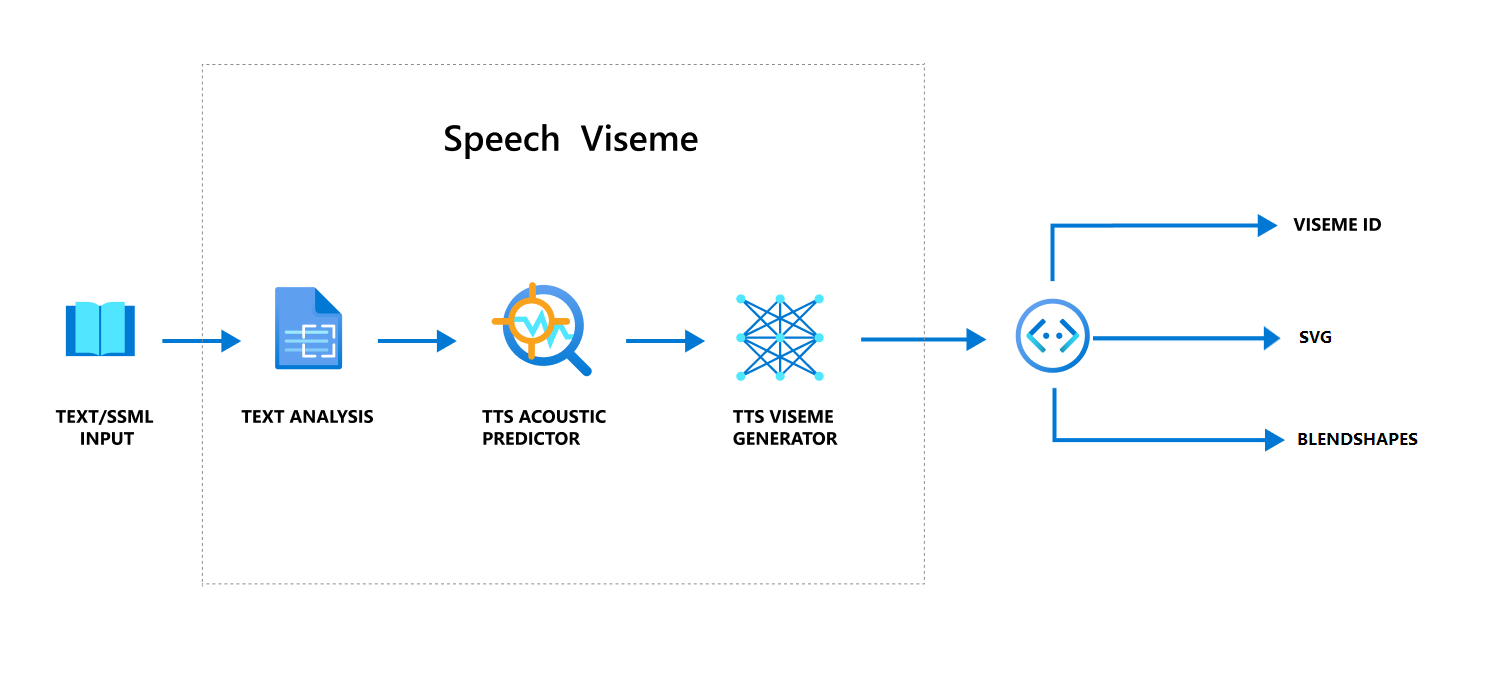
Gesamter Arbeitsablauf bei der Erstellung eines Visums mit Sprache
Neuronale Sprachsynthese (Neural Text-to-Speech, Neuronales TTS) wandelt eingegebenen Text oder SSML (Speech Synthesis Markup Language) in lebensechte synthetisierte Sprache um. Die Sprach-Audioausgabe kann von einer Viseme-ID, skalierbaren Vektorgrafiken (SVG) oder Mischformen begleitet werden. Mit einem 2D- oder 3D-Renderingmodul können Sie diese Mundbildereignisse nutzen, um Ihren Avatar zu animieren.
Der gesamte Workflow für Viseme ist im folgenden Flussdiagramm dargestellt.
VisemeId
Viseme ID bezieht sich auf eine ganzzahlige Zahl, die ein Visem spezifiziert. Wir bieten 22 verschiedene Viseme, die jeweils die Mundposition für eine bestimmte Gruppe von Phonemen darstellen. Es gibt keine Eins-zu-eins-Entsprechung zwischen Visemen und Phonemen. Häufig entspricht ein Mundbild mehreren Phonemen, da sie bei der Bildung auf dem Gesicht des Sprechenden gleich aussehen, z. B. s und z. Spezifischere Informationen finden Sie in der Tabelle zum Zuordnen von Phonemen zu Visem-IDs.
Die Sprach-Audioausgabe kann von Viseme-IDs und Audio offset begleitet werden. Das Audio offset gibt den Offset-Zeitstempel an, der die Startzeit jedes Visems in Ticks (100 Nanosekunden) darstellt.
Zuordnen von Phonemen zu Visemen
Viseme variieren je nach Sprache und Gebietsschema. Jedes Gebietsschema verfügt über einen Satz von Visemen, die den jeweiligen Phonemen entsprechen. Die Dokumentation der Phonetischen Alphabete von SSML ordnet Visem-IDs den entsprechenden IPA-Phonemen (International Phonetic Alphabet) zu. Die folgende Tabelle zeigt eine Zuordnungsbeziehung zwischen Mundbild-IDs und Mundpositionen und listet typische IPA-Phoneme für jede Mundbild-ID auf.
| VisemeId | IPA | Mundposition |
|---|---|---|
| 0 | Stille |  |
| 1 | æ, ə, ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, i, ɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, n, θ |
 |
| 20 | k, g, ŋ |
 |
| 21 | p, b, m |
 |
2D SVG-Animation
Für 2D-Figuren können Sie eine Figur entwerfen, die zu Ihrem Szenario passt, und Scalable Vector Graphics (SVG) für jede Mundbild-ID verwenden, um eine zeitbasierte Gesichtsposition zu erhalten.
Mit temporalen Tags, die in einem Mundbildereignis bereitgestellt werden, werden diese gut gestalteten SVGs mit Glättungsmodifikationen verarbeitet und bieten den Benutzer*innen stabile Animationen. Die folgende Abbildung zeigt z. B. eine Figur mit roten Lippen, die für das Sprachlernen konzipiert ist.

3D-Animation von Mischformen
Sie können Mischformen verwenden, um die Gesichtsbewegungen einer von Ihnen entworfenen 3D-Figur zu steuern.
Die JSON-String der Mischformen wird als zweidimensionale Matrix dargestellt. Jede Zeile repräsentiert einen Frame. Jeder Frame (in 60 FPS) enthält eine Reihe von 55 Gesichtspositionen.
Abrufen von Visemereignissen mit dem Speech SDK
Abonnieren Sie das VisemeReceived-Ereignis im Speech SDK, um Viseme zu Ihrer synthetisierten Sprache zu erhalten.
Hinweis
Um die Ausgabe von SVG- oder Mischformen anzufordern, sollten Sie das mstts:viseme-Element in SSML verwenden. Für weitere Details, sehen Sie Verwendung des Elements viseme in SSML.
Der folgende Codeausschnitt zeigt das Abonnieren des Visemereignisses.
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Hier ist ein Beispiel für die Viseme-Ausgabe.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Nachdem Sie die Mundbildausgabe erhalten haben, können Sie diese Ereignisse zur Steuerung der Figurenanimation verwenden. Sie können Ihre eigenen Figuren erstellen und diese automatisch animieren.