Aufzeichnen von Sprachbeispielen für die Funktion „Benutzerdefinierte neuronale Stimme“
Dieser Artikel bietet Anweisungen zum Vorbereiten qualitativ hochwertiger Stimmbeispiele zum Erstellen eines professionellen Stimmmodells mithilfe des Projekts „Benutzerdefinierte neuronale Stimme – Pro“.
Das Erstellen einer qualitativ hochwertig produzierten benutzerdefinierten neuronalen Stimme von Grund auf ist kein einfaches Unterfangen. Die zentrale Komponente einer benutzerdefinierten neuronalen Stimme ist eine umfangreiche Sammlung von Audiobeispielen der menschlichen Sprache. Es ist wichtig, dass diese Audioaufzeichnungen eine hohe Qualität haben. Wählen Sie einen Sprecher aus, der über Erfahrung mit dieser Art von Aufzeichnungen verfügt, und lassen Sie die Aufzeichnung von einem Tontechniker mit professioneller Ausrüstung vornehmen.
Vor der Aufzeichnung benötigen Sie ein Skript: Die Wörter werden von Ihrem Sprecher vorgelesen, um die Audiobeispiele zu erstellen.
Das Erstellen einer professionellen Sprachaufzeichnung setzt sich aus vielen kleinen, jedoch wichtigen Details zusammen. Diese Anleitung ist eine Roadmap für einen Prozess, mit dem Sie gute, einheitliche Ergebnisse erzielen.
Tipps zum Vorbereiten von Daten für eine qualitativ hochwertige Stimme
Eine sehr natürliche benutzerdefinierte neuronale Stimme hängt von mehreren Faktoren ab, z. B. von der Qualität und dem Umfang Ihrer Trainingsdaten.
Die Qualität Ihrer Trainingsdaten ist ein entscheidender Faktor. Beispielsweise sind in demselben Trainingssatz konsistente Lautstärke, Sprechrate, Tonhöhe und Sprechstil unerlässlich, um eine qualitativ hochwertige benutzerdefinierte neuronale Stimme zu erstellen. Sie sollten auch Hintergrundgeräusche in der Aufzeichnung vermeiden und sicherstellen, dass das Skript und die Aufzeichnung übereinstimmen. Um die Qualität Ihrer Daten zu gewährleisten, müssen Sie die Kriterien für die Skriptauswahl und die Aufzeichnungsanforderungen befolgen.
Hinsichtlich dem Umfang der Trainingsdaten können Sie in den meisten Fällen eine vernünftige benutzerdefinierte neuronale Stimme mit 500 Äußerungen erstellen. Unsere Tests haben ergeben, dass das Hinzufügen von mehr Trainingsdaten in den meisten Sprachen nicht unbedingt die Natürlichkeit der Stimme selbst verbessert (getestet mit dem MOS-Score). Wenn mehr Trainingsdaten, die mehr Wortinstanzen abdecken, vorliegen, ist jedoch die Wahrscheinlichkeit höher, dass der Anteil der für die Stimme unbefriedigenden Teile der Sprache, z. B. Störungen, geringer wird. Um zu erfahren, wie sich unbefriedigende Teile der Sprache anhören, erkunden Sie die GitHub-Beispiele.
In einigen Fällen möchten Sie vielleicht eine Stimmpersona mit eindeutigen Merkmalen. Beispielsweise benötigt eine Zeichentrickpersona eine Stimme mit einem speziellen Sprechstil oder eine Stimme mit einer dynamischen Intonation. Für solche Fälle wird empfohlen, mindestens 1000 (vorzugsweise 2000) Äußerungen vorzubereiten und in einem professionellen Tonstudio aufzuzeichnen. Weitere Informationen zum Verbessern der Qualität Ihres Stimmmodells finden Sie unter Merkmale und Einschränkungen bei der Verwendung der benutzerdefinierten neuronalen Stimme.
Rollen bei der Stimmaufzeichnung
Es gibt vier grundlegende Rollen in einem Projekt zur Aufzeichnung einer benutzerdefinierten neuronalen Stimme:
| Rolle | Zweck |
|---|---|
| Sprecher | Die Stimme dieser Person bildet die Grundlage für die benutzerdefinierte neuronale Stimme. |
| Tontechniker | Überwacht die technischen Aspekte der Aufzeichnung und bedient die Aufzeichnungsgeräte. |
| Regisseur | Bereitet das Skript vor und weist den Sprecher ein. |
| Editor | Finalisiert die Audiodateien und bereitet sie für den Upload in Speech Studio vor. |
Eine Person kann unter Umständen mehrere Rollen übernehmen. In dieser Anleitung wird davon ausgegangen, dass Sie als Regisseur agieren und Sprecher*innen sowie Tontechniker*innen engagieren. Wenn Sie die Aufzeichnungen selbst vornehmen möchten, enthält dieser Artikel einige Informationen zur Rolle des Tontechnikers. Die Editor-Rolle wird erst nach der Aufzeichnungssitzung benötigt. In der Zwischenzeit kann der Regisseur bzw. die Regisseurin oder der Tontechniker bzw. die Tontechnikerin diese Rolle ausfüllen.
Auswählen des Sprechers
Schauspieler*innen, die Erfahrung mit Synchronisierung, Sprechrollen, Ansagen oder Nachrichtenarbeit haben, stellen gute Sprecher*innen für Stimmen dar. Wählen Sie einen Sprecher aus, dessen natürliche Stimme Ihnen gefällt. Es ist möglich, einzigartige Charakterstimmen zu erstellen. Für die meisten Sprecher*innen ist es jedoch schwieriger, diese konsistent beizubehalten, und die Anstrengung kann zu einer Stimmbelastung führen. Der wichtigste Faktor für die Auswahl des Sprechers ist Konsistenz. Ihr Aufzeichnungen für denselben Sprachstil sollten alle so klingen, als ob sie am selben Tag im selben Raum erstellt wurden. Sie können dieses Ideal über gute Aufzeichnungsverfahren und eine geeignete Technik erreichen.
Ihr Sprecher muss in der Lage sein, mit konsistenter Geschwindigkeit, Lautstärke, Tonhöhe und Ton mit klarer Aussprache zu sprechen. Sie müssen außerdem ihre Tonhöhenvariationen, ihre emotionale Wirkung und ihre Sprachmanierismen kontrollieren können. Die Aufzeichnung von Sprachbeispielen kann ermüdender sein als andere Arten von Spracharbeit, sodass die meisten Sprachtalente nur zwei oder drei Stunden pro Tag aufzeichnen können. Beschränken Sie die Sitzungen auf drei oder vier Tage pro Woche mit möglichst einem freien Tag dazwischen.
Arbeiten Sie mit Ihrem Sprecher zusammen, um eine Persona zu entwickeln, die den Gesamtton und die emotionale Tonlage der benutzerdefinierten neuronalen Stimme definiert, und achten Sie darauf, genau festzulegen, wie „neutral“ für diese Persona klingt. Sie definieren die „Sprechstile“ und bitten die Sprecher*innen, das Skript so zu lesen, dass es den gewünschten Stil widerspiegelt.
Beispielsweise würde eine Persona mit einer natürlich positiv gestimmten Persönlichkeit auch bei neutralem Sprechen eine Spur von Optimismus durchscheinen lassen. Dieses Persönlichkeitsmerkmal sollte allerdings subtil und konsistent sein. Hören Sie sich Aufzeichnungen von vorhandenen Stimmen an, um eine Vorstellung davon zu erhalten, was das Ziel sein könnte.
Tipp
In der Regel sollten Sie Besitzer der erstellten Sprachaufzeichnungen sein. Ihr Sprecher sollte offen für einen auf das Projekt beschränkten Vertrag sein.
Erstellen eines Skripts
Der Ausgangspunkt einer Sitzung für die Aufzeichnung einer benutzerdefinierten neuronalen Stimme ist das Skript, das die Äußerungen enthält, die von Ihrem Sprecher vorgetragen werden. Der Begriff „Äußerungen“ umfasst sowohl vollständige Sätze als auch kürzere Wendungen. Für die Erstellung einer benutzerdefinierten neuronalen Stimme werden mindestens 300 aufgezeichnete Äußerungen als Trainingsdaten benötigt.
Die Äußerungen in Ihrem Skript können beliebigen Ursprungs sein: Fiktion, Fakten, Redemanuskripte, Nachrichten und alles, was sonst noch in gedruckter Form zur Verfügung steht. Eine kurze Erläuterung möglicher rechtlicher Fragen finden Sie im Abschnitt Rechtsfragen. Sie können auch einen eigenen Text schreiben.
Ihre Äußerungen brauchen nicht aus derselben Quelle oder aus derselben Art von Quelle zu stammen oder überhaupt etwas miteinander zu tun haben. Wenn Sie allerdings feste Ausdrücke (z. B. „Sie haben sich erfolgreich angemeldet“) in Ihrer Sprachanwendung verwenden, achten Sie darauf, sie in Ihr Skript aufzunehmen. Damit erhöht sich die Wahrscheinlichkeit, dass diese Ausdrücke von Ihrer benutzerdefinierten neuronalen Stimme gut ausgesprochen werden.
Wir empfehlen, dass die Aufnahmeskripts sowohl allgemeine Sätze als auch fachgebietsspezifische Sätze enthalten. Wenn Sie z. B. 2.000 Sätze aufzeichnen möchten, könnten 1.000 davon allgemeine Sätze sein, weitere 1.000 könnten Sätze aus Ihrem Zielbereich oder dem Anwendungsfall Ihrer Anwendung sein.
Wir stellen Beispielskripts in den Bereichen „Allgemein“, „Chat“ und „Kundendienst“ für jede Sprache zur Verfügung, um Ihnen bei der Vorbereitung Ihrer Aufzeichnungsskripts zu helfen. Sie können diese von Microsoft freigegebenen Skripts direkt für Ihre Aufzeichnungen verwenden oder sie als Referenz für die Erstellung Ihrer eigenen Skripts nutzen.
Kriterien für die Skriptauswahl
Im Folgenden finden Sie einige allgemeine Richtlinien, die Sie befolgen können, um einen geeigneten Bestand (aufgezeichnete Audiobeispiele) für das Training der benutzerdefinierten neuronalen Stimme zu erstellen.
Stimmen Sie Ihr Skript so ab, dass es verschiedene Satzarten in Ihrem Bereich abdeckt, darunter Anweisungen, Fragen, Ausrufe, lange Sätze und kurze Sätze.
Jeder Satz sollte zwischen vier und 30 Wörtern umfassen, und Ihr Skript sollte keine doppelten Sätze enthalten.
Informationen zur Gewichtung der verschiedenen Satzarten finden Sie in der folgenden Tabelle:Satzarten Abdeckung Anweisungssätze Anweisungssätze sollten 70–80 % des Skripts ausmachen. Fragesätze Fragesätze sollten etwa 10 % bis 20 % Ihres fachspezifischen Skripts ausmachen, davon 5 % bis 10 % ansteigende und 5 % bis 10 % abfallende Töne. Ausrufungssätze Ausrufungssätze sollten ungefähr 10 % bis 20 % Ihrer Skripts ausmachen. Kurzes Wort/Ausdruck Skripts mit kurzen Wörtern oder Ausdrücken sollten etwa 10 % der gesamten Äußerungen ausmachen, mit fallweise 5 bis 7 Wörtern. Hinweis
Kurze Wörter/Ausdrücke sollten durch Kommas getrennt werden. Sie erinnern Ihre Sprecher daran, beim Lesen kurz innezuhalten.
Zu den bewährten Methoden gehören:
- Ausgewogene Abdeckung der Wortarten, wie Verben, Nomen, Adjektive usw.
- Ausgewogene Abdeckung für Aussprachen. Verwenden Sie alle Buchstaben von A bis Z, damit die Sprachsynthese-Engine lernt, wie jeder Buchstabe in Ihrem Stil ausgesprochen wird.
- Lesbare, verständliche, nachvollziehbare Skripts zum Lesen durch den Sprecher.
- Vermeiden zu vieler ähnlicher Muster für Wörter/Ausdrücke, wie „einfach“ und „einfacher“.
- Einbeziehen verschiedener Zahlenformate: Adresse, Einheit, Telefon, Menge, Datum usw. in allen Satzarten.
- Fügen Sie Rechtschreibsätze ein, wenn das etwas ist, das von Ihrer benutzerdefinierten neuronalen Stimme gelesen wird. Beispiel: „Die Schreibweise von Apfel ist A P F E L“.
Fügen Sie nicht mehrere Sätze in eine Zeile/eine Äußerung ein. Trennen Sie die Zeilen nach Äußerungen.
Achten Sie darauf, dass der Satz eindeutig ist. Generell sollten Sie nicht zu viele ungewöhnliche Wörter wie Zahlen oder Abkürzungen verwenden, da sie schwer zu lesen sind. Einige Anwendungen erfordern möglicherweise, dass viele Zahlen oder Akronyme gelesen werden. In diesen Fällen können Sie diese Wörter einbeziehen, Sie sollten sie aber in ihrer gesprochenen Form normalisieren.
Im Folgenden finden Sie einige Beispiele für bewährte Methoden:
- Bei Zeilen mit Abkürzungen schreiben Sie anstelle von „BTW“ entsprechend „by the way“ (übrigens).
- In Zeilen mit Ziffern schreiben Sie anstelle von „911“ „neun eins eins“.
- Bei Zeilen mit Akronymen schreiben Sie anstelle von „ABC“ vielmehr „A B C“.
Stellen Sie mit diesen Maßnahmen sicher, dass Ihr Sprecher diese Wörter wie erwartet ausspricht. Achten Sie darauf, dass Ihr Skript und Ihre Aufzeichnungen während des Trainingsprozesses stets übereinstimmen.
Das Skript sollte viele unterschiedliche Wörter und Sätze mit unterschiedlichen Satzlängen, Strukturen und Stimmungen enthalten.
Überprüfen Sie das Skript sorgfältig auf Fehler. Wenn möglich, bitten Sie eine andere Person, es ebenfalls zu überprüfen. Wenn Sie mit Ihren Sprecher*innen das Skript durchgehen, fallen Ihnen möglicherweise mehr Fehler auf.
Unterschied zwischen Sprecherskript und Trainingsskript
Das Trainingsskript kann sich vom Skript des Sprechers unterscheiden, insbesondere bei Skripts, die Ziffern, Symbole, Abkürzungen, Datum und Uhrzeit enthalten. Skripts, die für einen Sprecher vorbereitet sind, müssen den nativen Lesekonventionen folgen, z. B. 50 % und 45 USD. Die zum Training verwendeten Skripts müssen normalisiert werden, um der Audioaufzeichnung zu entsprechen, z. B. fünfzig Prozent und fünfundvierzig Dollar.
Hinweis
Wir stellen einige Beispielskripts für den Sprecher auf GitHub zur Verfügung. Um die Beispielskripts zum Training zu verwenden, müssen Sie sie entsprechend den Aufzeichnungen Ihres Sprechers normalisieren, bevor Sie die Datei hochladen.
Die folgende Tabelle zeigt den Unterschied zwischen Skripts für Sprecher und dem normalisierten Skript fürs Training.
| Category | Beispiel für Sprecherskripts | Beispiel für Trainingsskript (normalisiert) |
|---|---|---|
| Ziffern | 123 | einhundertdreiundzwanzig |
| Sonderzeichen | 50% | fünfzig Prozent |
| Abkürzung | ASAP (Baldmöglichst) | so bald wie möglich |
| Datum und Uhrzeit | 3. März um 17:00 Uhr | Dritter März um siebzehn Uhr |
Typische Fehler eines Skripts
Die schlechte Qualität des Skripts kann sich negativ auf die Trainingsergebnisse auswirken. Zum Erzielen qualitativ hochwertiger Trainingsergebnisse ist es entscheidend, Fehler zu vermeiden.
Skriptfehler lassen sich im Allgemeinen in die folgenden Kategorien einteilen:
| Category | Beispiel |
|---|---|
| Bedeutungslose Inhalte. | „Farblose grüne Ideen sind in der Wut des Schlafs gefangen." |
| Unvollständige Sätze. | - „Das war mein letzter Abend“ (kein Subjekt, keine bestimmte Bedeutung) – „Sie sind schon lustig (kein Anführungszeichen am Ende, es ist kein vollständiger Satz) |
| Tippfehler in den Sätzen. | - Kleinbuchstabe am Satzanfang - Keine abschließende Interpunktion, falls erforderlich - Falsche Schreibweise - Fehlende Interpunktion: kein Punkt am Ende (mit Ausnahme für Nachrichtentitel) - Endung mit Symbolen, mit Ausnahme von Komma, Fragezeichen, Ausrufezeichen - Falsches Format, z. B.: - 45$ (sollte $45 lauten) - Kein Leerzeichen oder überflüssiges Leerzeichen zwischen Wort/Interpunktion |
| Duplizierung in einem ähnlichen Format, eine pro Muster ist ausreichend. | - „Jetzt ist es 13 Uhr in New York“ - „Jetzt ist es 14 Uhr in New York“ - „Jetzt ist es 15 Uhr in New York“ - „Jetzt ist es 13 Uhr in Seattle“ - „Jetzt ist es 13 Uhr in Washington D.C.“ |
| Nicht gebräuchliche Fremdwörter: Nur gebräuchliche Fremdwörter sind in unserem Skript zulässig. | In Englisch kann man das französische Wort „faux“ in Umgangssprache verwenden, aber ein französischer Ausdruck wie „coincer la bulle“ wäre ungewöhnlich. |
| Emoji oder andere unübliche Symbole. |
Skriptformat
Das Skript ist für die Aufnahmesitzung bestimmt. Sie sind also frei, es so gestalten, dass Sie gut damit arbeiten können. Erstellen Sie die Textdatei, die für Speech Studio separat erforderlich ist.
Ein einfaches Skriptformat enthält drei Spalten:
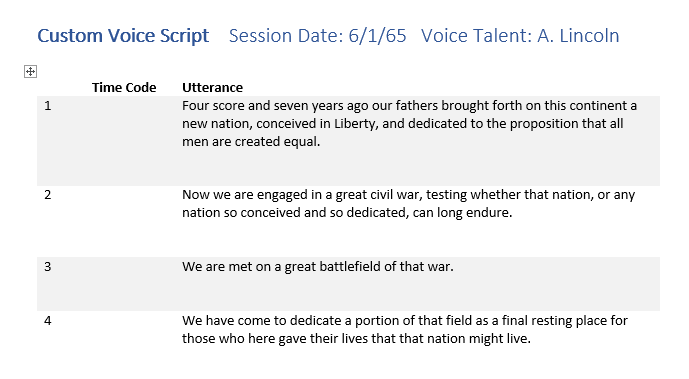
- Die Nummer der Äußerung, beginnend mit 1. Eine Nummerierung erleichtert allen im Studio die Bezugnahme auf eine bestimmte Äußerung („Wiederholen wir Nummer 356“). Sie können die Microsoft Word-Funktion für die Absatznummerierung verwenden, um die Zeilen der Tabelle automatisch zu nummerieren.
- Eine leere Spalte, in die Sie die Nummer der Aufnahmesitzung oder den Zeitcode für jede Äußerung eintragen, um die fertige Aufzeichnung schneller finden zu können.
- Der Text der Äußerung selbst.
Hinweis
Die meisten Studios zeichnen kurze Segmente auf, die als „Takes“ bezeichnet werden. Jeder Take enthält in der Regel 10 bis 24 Äußerungen. Das Notieren der Takenummer reicht aus, um eine Äußerung zu einem späteren Zeitpunkt zu finden. Wenn Sie die Aufzeichnung in einem Studio durchführen, in dem eher längere Aufzeichnungen gemacht werden, sollten Sie stattdessen den Zeitcode notieren. Im Studio sollte die Zeit gut sichtbar angezeigt werden.
Lassen Sie unter jeder Zeile ausreichend Platz für Notizen. Achten Sie darauf, dass keine Äußerungen durch Seitenumbrüche unterteilt werden. Nummerieren Sie die Seiten, und drucken Sie das Skript auf eine Seite des Papiers.
Drucken Sie drei Kopien des Skripts: eine für den Sprecher, eine für den Aufnahmetechniker und eine für den Regisseur (Sie). Verwenden Sie Büroklammern statt Heftklammern: Erfahrene Sprecher*innen trennen die Seiten, um Geräusche beim Blättern zu vermeiden.
Sprechererklärung
Um eine neuronale Stimme zu trainieren, müssen Sie ein Sprecherprofil mit einer Audiodatei erstellen, die vom Sprecher aufgezeichnet wurde, der der Verwendung seiner Sprachdaten zum Trainieren eines benutzerdefinierten Stimmmodells zugestimmt hat. Achten Sie beim Vorbereiten des Aufzeichnungsskripts darauf, den Anweisungssatz einzuschließen.
Rechtliches
Nach dem Urheberrechtsgesetz kann das Vorlesen von urheberrechtlich geschütztem Text durch einen Schauspieler eine Leistung sein, für die der Autor der Arbeit eine Vergütung erhalten muss. Diese Leistung ist im Endprodukt, in der benutzerdefinierten neuronalen Stimme, nicht erkennbar. Die Rechtmäßigkeit der Nutzung urheberrechtlich geschützter Arbeiten für diesen Zweck ist allerdings nicht ausreichend belegt. Microsoft kann keine rechtliche Beratung zu diesem Problem bieten. Wenden Sie sich an Ihren eigenen Rechtsberater.
Glücklicherweise ist es möglich, diese Probleme vollständig zu vermeiden. Es gibt viele Quellen für Texte, die Sie ohne Genehmigung oder Lizenz verwenden können.
| Textquelle | BESCHREIBUNG |
|---|---|
| CMU Arctic-Korpus | Etwa 1100 Sätze aus nicht urheberrechtlich geschützten Werken speziell für Sprachsyntheseprojekte. Ein ausgezeichneter Ausgangspunkt. |
| Nicht länger urheberrechtlich geschützte Werke |
In der Regel Werke, die vor 1923 veröffentlicht wurden. Für Englisch bietet das Project Gutenberg Zehntausende dieser Werke. Sie sollten sich auf neuere Werke konzentrieren, da die Sprache näher an der modernen Sprache ist. |
| Von der Regierung erstellte Werke | Werke, die von US-Behörden erstellt wurden, sind in den USA nicht urheberrechtlich geschützt. Die Behörden könnten jedoch in anderen Ländern/Regionen Urheberrechte geltend machen. |
| Öffentlicher Bereich | Werke, für die Urheberrechte explizit ausgeschlossen wurden oder die für die Öffentlichkeit frei zugänglich sein sollen. In einigen Jurisdiktionen ist es möglicherweise nicht möglich, vollständig auf das Urheberrecht zu verzichten. |
| Werke mit spezieller Lizenz | Werke, die mit einer Lizenz wie „Creative Commons“ oder „GNU Free Documentation License“ (GDFL) verteilt werden. Wikipedia verwendet GFDL. Einige Lizenzen können jedoch Leistungseinschränkungen für den lizenzierten Inhalt enthalten, die sich auf die Erstellung eines benutzerdefinierten neuronalen Sprachmodells auswirken können. Daher sollten Sie die Lizenz sorgfältig lesen. |
Aufzeichnen des Skripts
Zeichnen Sie Ihr Skript in einem professionellen Tonstudio auf, das auf Sprecharbeiten spezialisiert ist. Sie haben eine Aufnahmekabine, die richtige Ausrüstung und die richtigen Leute für deren Betrieb. Es wird empfohlen, bei der Aufzeichnung keine Abstriche zu machen.
Besprechen Sie das Projekt mit dem Tontechniker des Studios, und hören Sie sich dessen Ratschläge an. Die Aufzeichnung sollte mit wenig oder ohne dynamische Komprimierung (maximal 4:1) durchgeführt werden. Es ist wichtig, dass das Audio eine einheitliche Lautstärke und ein hohes Signal-Rausch-Verhältnis aufweist.
Aufzeichnungsanforderungen
Um qualitativ hochwertige Trainingsergebnisse zu erzielen, befolgen Sie während der Aufzeichnung oder Datenvorbereitung die folgenden Anforderungen:
Klar und gut ausgesprochen
Natürliche Geschwindigkeit: nicht zu langsam oder zu schnell zwischen einzelnen Audiodateien.
Angemessene Lautstärke, Prosodie und Pause: beständig innerhalb eines Satzes oder zwischen Sätzen, korrekte Pause für Interpunktion.
Keine Störgeräusche während der Aufzeichnung
Anpassung an den Personaentwurf
Kein falscher Akzent: Anpassung an den Zielentwurf
Keine falsche Aussprache
Eine bewährte Methode zur Vorbereitung auf die Audiobeispiele finden Sie in der unten angegebenen Spezifikation.
| Eigenschaft | Wert |
|---|---|
| Dateiformat | *.wav, Mono |
| Samplingrate | 24 kHz |
| Beispielformat | 16 Bit, PCM |
| Spitzenlautstärkepegel | -3 dB bis -6 dB |
| SNR | > 35 dB |
| Stille | - Am Anfang und am Ende sollte etwas Stille herrschen (empfohlen werden 100 ms), aber nicht länger als 200 ms - Stille zwischen Wörtern oder Ausdrücken < -30 dB - Stille in der Welle, nachdem das letzte Wort gesprochen wurde < -60 dB |
| Umgebungsgeräusche oder Echo | - Der Rauschpegel am Anfang der Welle vor dem Sprechen < -70 dB |
Hinweis
Sie können mit höherer Samplingrate und Bittiefe aufzeichnen, z. B. im Format 48 kHz 24-Bit-PCM. Während des benutzerdefinierten neuronalen Stimmtrainings erfolgt automatisch ein Downsampling der Stimme auf 24 kHz 16-Bit-PCM.
Ein höheres Signal-Rausch-Verhältnis (SNR) deutet auf ein geringeres Rauschen in den Audioaufnahmen hin. Wenn Ihre Aufnahmen in einem professionellen Tonstudio vorgenommen wurden, können Sie SNR-Werte größer als 35 erzielen. Ein SNR-Wert unter 20 kann dazu führen, dass in der generierten Stimme das Rauschen deutlich zu hören ist.
Bei einer niedrigen Aussprachebewertung oder einem geringen SNR-Wert sollten Sie die betroffenen Äußerungen erneut aufnehmen. Wenn die erneute Aufzeichnung nicht möglich ist, erwägen Sie den Ausschluss dieser Äußerungen aus Ihren Daten.
Typische Audiofehler
Für qualitativ hochwertige Trainingsergebnisse wird dringend empfohlen, Audiofehler zu vermeiden. Audiofehler treten in der Regel in den folgenden Kategorien auf:
Der Name der Audiodatei stimmt nicht mit der Skript-ID überein.
Die WAR-Datei weist ein ungültiges Format auf und kann nicht gelesen werden.
Die Audiosamplingrate ist niedriger als 16 KHz. Die Samplingrate der WAV-Datei sollte für eine hochwertige neuronale Stimme gleich oder höher als 24 kHz sein.
Die Lautstärkespitze liegt nicht im Bereich von -3 dB (70 % der maximalen Lautstärke) bis -6 dB (50 %).
Clipping: Die Wellenform ist an Ihrem Spitzenwert beschnitten und daher nicht vollständig.
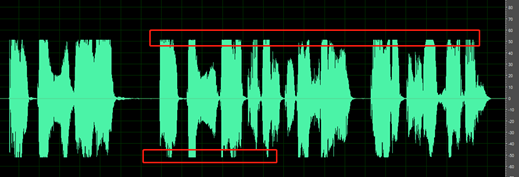
Die stillen Teile der Aufzeichnung sind nicht sauber; es sind Umgebungsgeräusche, Mundgeräusche und Echo hörbar.
Die folgenden Audiodaten enthalten z. B. die Umgebungsgeräusche zwischen den Reden.
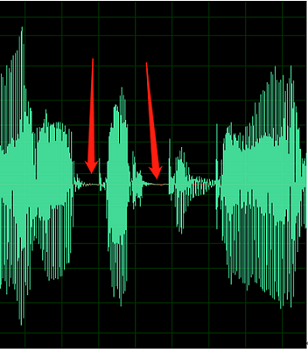
Das folgende Beispiel enthält Anzeichen für Gleichspannungsoffset oder Echo.
Die Gesamtlautstärke ist zu niedrig. Ihre Daten werden als problematisch gekennzeichnet, wenn die Lautstärke weniger als -18 dB (10 % der maximalen Lautstärke) beträgt. Achten Sie darauf, dass alle Audiodateien die gleiche Lautstärke aufweisen.
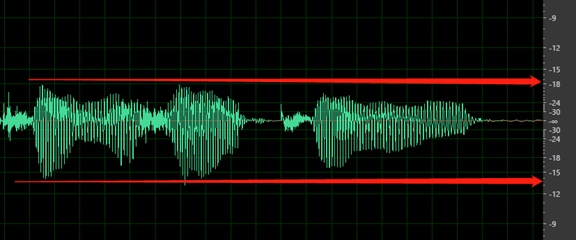
Keine Stille vor dem ersten Wort oder nach dem letzten Wort. Außerdem sollte die Anfangs- oder Endstille nicht länger als 200 ms oder kürzer als 100 ms sein.
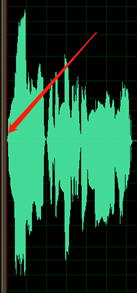
Aufzeichnung in Eigenregie
Wenn Sie die Aufzeichnung selbst vornehmen möchten, statt in einem Studio aufzuzeichnen, finden Sie hier eine kurze Einführung. Da immer häufiger Aufzeichnungen und Podcasts zu Hause erstellt werden, ist es einfacher als je zuvor, online gute Ratschläge und Ressourcen für Aufzeichnungen zu finden.
Ihre „Aufnahmekabine“ sollte ein kleiner Raum ohne nennenswertes Echo oder Eigengeräusche sein. Er sollte möglichst still und schalldicht sein. Mit Vorhängen an den Wänden kann das Echo verringert werden, und die Geräusche des Raums können gedämpft werden.
Verwenden Sie ein qualitativ hochwertiges Studio-Kondensatormikrofon zum Aufzeichnen der Stimme. Mit Sennheiser-, AKG- und sogar neuere Zoom-Mikrofonen können gute Ergebnisse erreicht werden. Sie können ein Mikrofon kaufen oder bei einem entsprechenden lokalen Anbieter ausleihen. Suchen Sie nach einem Mikrofon mit USB-Schnittstelle. Mit einem solchen Mikrofon können das Mikrofonelement, der Vorverstärker und der Analog-in-Digital-Wandler bequem in einem Paket kombiniert werden, um die Einrichtung zu vereinfachen.
Sie können auch ein analoges Mikrofon verwenden. Viele Verleihhäuser bieten „alte“ Mikrofone an, die der Stimme einen besonderen Charakter geben. Professionelle analoge Geräte sind mit XLR-Steckverbindern ausgestattet, nicht mit den 1/4-Zoll-Anschlüssen von Endverbrauchergeräten. Wenn Sie analog aufzeichnen, benötigen Sie auch einen Vorverstärker und eine Computeraudioschnittstelle für diese Steckverbinder.
Montieren Sie das Mikrofon auf einem Ständer oder Schwenkarm, und befestigen Sie einen Popschutz vor dem Mikrofon, um Störungen durch „plosive“ Konsonanten wie „p“ und „b“ zu vermeiden. Einige Mikrofone verfügen über eine Aufhängung, die sie vor Vibrationen im Ständer isoliert. Dies ist hilfreich.
Der Sprecher muss einen einheitlichen Abstand zum Mikrofon einhalten. Markieren Sie auf dem Boden mit Klebeband, wo er stehen sollte. Wenn der Sprecher lieber sitzen möchte, kontrollieren Sie den Abstand zum Mikrofon besonders sorgfältig, und vermeiden Sie Geräusche durch den Stuhl.
Verwenden Sie einen Ständer, um das Skript abzulegen. Der Ständer sollte nicht so stehen, dass er den Klang zum Mikrofon zurückwirft.
Die Person, die die Aufzeichnungsausrüstung bedient (der Techniker), sollte sich in einem anderen Raum als der Sprecher befinden und über eine Möglichkeit zur Kommunikation mit dem Sprecher in der Aufnahmekabine verfügen (eine Gegensprechanlage).
Die Aufzeichnung sollte möglichst wenig Rauschen enthalten. Das Ziel ist -80 dB.
Hören Sie sich eine Aufzeichnung der Stille Ihrer „Kabine“ genau an, um zu ermitteln, woher mögliches Rauschen stammt, und beseitigen Sie die Ursache. Häufige Quellen für Rauschen sind Lüftungen, Leuchtstofflampen, Verkehr auf Straßen in der Nähe und Lüfter von Geräten (sogar Notebooks können Lüfter enthalten). Mikrofone und Kabel können elektrischen Störungen durch Kabel in der Nähe aufnehmen, in der Regel ein Brummen oder Summen. Ein Summen kann auch durch eine Erdungsschleife verursacht werden, die dadurch verursacht wird, dass die Ausrüstung an mehrere Stromkreise angeschlossen ist.
Tipp
In einigen Fällen können Sie möglicherweise mit einem Equalizer- oder Rauschunterdrückungssoftware-Plug-In das Rauschen aus Ihren Aufzeichnungen entfernen. Es ist allerdings immer am besten, es an der Quelle zu beenden.
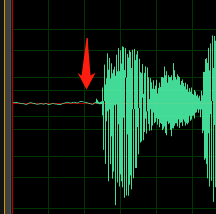
Legen Sie die Pegel so fest, dass der größte Teil des verfügbaren dynamischen Bereichs der digitalen Aufzeichnung ohne Übersteuern genutzt wird. Sie müssen also den Ton laut einstellen, aber nicht so laut, dass er verzerrt wird. Ein Beispiel für die Wellenform einer guten Aufzeichnung wird in der folgenden Abbildung dargestellt:
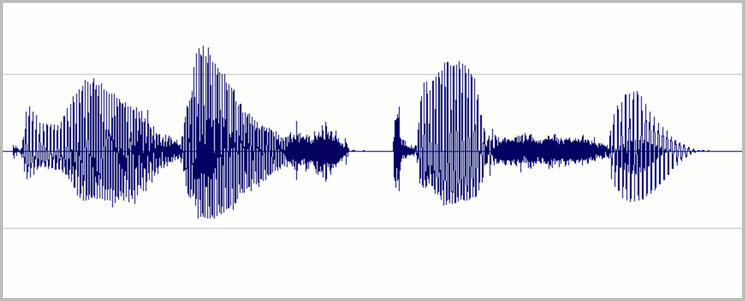
Hier wird der größte Teil des Bereichs (Höhe) verwendet, aber die höchsten Spitzen des Signals erreichen den oberen oder unteren Rand des Fensters nicht. Sie sehen auch, dass sich die Stille in der Aufzeichnung einer dünnen horizontalen Linie annähert. Dies ist ein Hinweis auf geringes Hintergrundrauschen. Diese Aufzeichnung hat einen akzeptablen dynamischen Bereich und ein akzeptables Signal-Rausch-Verhältnis.
Zeichnen Sie über eine qualitativ hochwertige Audioschnittstelle oder einen USB-Anschluss (abhängig vom verwendeten Mikrofon) direkt auf dem Computer auf. Halten Sie für analoge Aufzeichnungen die Audiokette einfach: Mikrofon, Vorverstärker, Audioschnittstelle, Computer. Avid Pro Tools und Adobe Audition können zu angemessenen Kosten monatlich lizenziert werden. Wenn Ihr Budget extrem knapp ist, testen Sie das kostenlose Tool Audacity.
Zeichnen Sie in Mono mit 44,1 kHz und 16 Bit (CD-Qualität) oder besser auf. Der aktuelle Stand der Technik sind 48 kHz und 24 Bit, wenn dies von Ihren Geräten unterstützt wird. Sie führen ein Downsampling Ihrer Audioaufzeichnungen auf 24 kHz und 16 Bit durch, bevor Sie sie an Speech Studio übermitteln. Es lohnt sich dennoch, eine qualitativ hochwertige Originalaufzeichnung zu haben, falls Änderungen erforderlich sind.
Im Idealfall werden die Rollen des Regisseurs, Technikers und Sprechers von verschiedenen Personen besetzt. Versuchen Sie nicht, alles selbst zu machen. Im Notfall können Regisseur und Techniker eine Person sein.
Vor der Sitzung
Um keine Studiozeit zu verschwenden, gehen Sie das Skript mit Ihrem Sprecher vor der Aufzeichnungssitzung durch. Während sich der Sprecher mit dem Text vertraut macht, kann er die Aussprache und unbekannte Wörter klären.
Hinweis
Die meisten Aufnahmestudios bieten eine elektronische Anzeige der Skripts in der Aufnahmekabine. Geben Sie in diesem Fall Ihre Notizen der Vorbesprechung direkt in das Skriptdokument ein. In einer Kopie auf Papier können Sie trotzdem während der Sitzung Notizen machen. Die meisten Techniker benötigen auch eine Kopie auf Papier. Und Sie benötigen weiterhin eine dritte Kopie als Absicherung für den Sprecher, falls der Computer ausfällt.
Ihr Sprecher könnte fragen, welches Wort in einer Äußerung betont werden soll (das „Schlüsselwort“). Antworten Sie, dass Sie einen natürlichen Vortrag ohne besondere Betonungen wünschen. Betonungen können hinzugefügt werden, wenn die Sprache synthetisiert wird. Sie sollten kein Teil der Originalaufzeichnung sein.
Bitten Sie den Sprecher, Wörter deutlich auszusprechen. Jedes Wort des Skripts sollte so gesprochen werden, wie es geschrieben ist. Silben sollten nicht weggelassen oder undeutlich gesprochen werden, wie es häufig in der Alltagssprache der Fall ist, es sein denn, sie wurden im Skript auf diese Weise geschrieben.
| Geschriebener Text | Unerwünschte saloppe Aussprache |
|---|---|
| Geben Sie niemals auf. | Geb’n Sie niemals auf. |
| Es gibt vier Leuchten. | ’s gibt vier Leuchten. |
| Wie ist das Wetter heute? | Wie’s das Wetter heute? |
| Grüßen Sie meinen kleinen Freund. | Grüß’n Sie meinen kleinen Freund. |
Die Sprecher*innen sollten keine deutlichen Pausen zwischen Wörtern einfügen. Der Satz sollte trotzdem natürlich fließen, auch wenn er ein wenig formal klingt. Es kann Übung erfordern, diesen feinen Unterschied richtig umzusetzen.
Die Aufzeichnungssitzung
Erstellen Sie am Beginn der Sitzung eine Referenzaufzeichnung oder Vergleichsdatei einer typischen Äußerung. Bitten Sie den Sprecher, diese Zeile beispielsweise nach jeder Seite zu wiederholen. Vergleichen Sie jedes Mal die neue Aufzeichnung mit der Referenz. Diese Verfahrensweise hilft dem Sprecher, bei Lautstärke, Geschwindigkeit, Tonhöhe und Intonation einheitlich zu bleiben. Der Techniker kann die Vergleichsdatei zudem als Referenz für Pegel und einen insgesamt konstanten Klang verwenden.
Die Vergleichsdatei ist besonders wichtig, wenn die Aufzeichnung nach einer Pause oder an einem anderen Tag fortgesetzt wird. Spielen Sie sie dem Sprecher mehrmals vor und fordern Sie ihn auf, sie jedes Mal zu wiederholen, bis eine Übereinstimmung erreicht ist.
Um einen Korpus mit einem bestimmten Stil aufzuzeichnen, wählen Sie sorgfältig Skripts aus, die den gewünschten Stil präsentieren. Stellen Sie während der Aufnahme sicher, dass das Stimmtalent in Lautstärke, Tempo, Tonhöhe und Ton konsistent bleibt, um Aufnahmen zu erzielen, die den beabsichtigten Stil verkörpern.
Fordern Sie den Sprecher auf, vor jeder Äußerung einmal tief durchzuatmen und kurz innezuhalten. Zeichnen Sie zwischen den Äußerungen ein paar Sekunden Stille auf. Wörter sollten bei jedem Auftreten unter Berücksichtigung des Kontexts auf die gleiche Weise ausgesprochen werden. Beispielsweise wird „record“ (aufzeichnen) als Verb anders ausgesprochen als „record“ (Datensatz) als Substantiv.
Zeichnen Sie vor der ersten Aufnahme ungefähr fünf Sekunden Stille auf, um den „Raumklang“ zu erfassen. Durch diese Vorgehensweise kann Speech Studio die Störungen in den Aufzeichnungen besser kompensieren.
Tipp
Sie müssen eigentlich nur den Sprecher aufzeichnen, daher ist eine monaurale (einkanalige) Aufzeichnung seiner Zeilen ausreichend. Wenn Sie jedoch in Stereo aufzeichnen, können Sie den zweiten Kanal zum Aufzeichnen der Gespräche im Kontrollraum verwenden, um Diskussionen zu bestimmten Texten oder Takes zu erfassen. Entfernen Sie diese Spur aus der Version, die in Speech Studio hochgeladen wird.
Hören Sie sich über Kopfhörer den Vortrag des Sprechers genau an. Achten Sie auf eine gute, aber natürliche Ausdrucksweise, die richtige Aussprache und darauf, dass wenige unerwünschte Töne vorhanden sind. Zögern Sie nicht, Ihren Sprecher zu bitten, eine Äußerung erneut aufzuzeichnen, die diese Standards nicht erfüllt.
Tipp
Wenn Sie eine große Zahl von Äußerungen verwenden, hat eine einzelne Äußerung unter Umständen keine spürbaren Auswirkungen auf die resultierende benutzerdefinierte neuronalen Stimme. Daher ist es möglicherweise zweckdienlicher, einfach alle Äußerungen mit Problemen zu notieren, sie aus Ihrem Dataset auszuschließen und herauszufinden, wie Ihre benutzerdefinierte neuronalen Stimme klingt. Sie können immer wieder ins Studio gehen und die fehlenden Beispiele später aufzeichnen.
Notieren Sie sich für jede Äußerung die Takenummer oder den Zeitcode im Skript. Bitten Sie den Techniker, jede Äußerung auch in den Metadaten der Aufzeichnung oder im Cuesheet zu markieren.
Machen Sie regelmäßige Pausen, und bieten Sie dem Sprecher ein Getränk an, damit die Stimme in Form bleibt.
Nach der Sitzung
Moderne Aufnahmestudios nutzen Computer. Am Ende der Sitzung erhalten Sie eine oder mehrere Audiodateien, kein Band. Diese Dateien liegen wahrscheinlich im WAV- oder AIFF-Format in CD-Qualität (44,1 kHz, 16 Bit) oder höherer Qualität vor. 24 kHz und 16 Bit sind gängig und wünschenswert. Die Standardsamplingrate für eine benutzerdefinierte neuronale Stimme beträgt 24 kHz. Es wird empfohlen, eine Abtastrate von 24 kHz für Ihre Trainingsdaten zu verwenden. Höhere Samplingraten, z. B. 96 kHz, sind für gewöhnlich nicht erforderlich.
Speech Studio erfordert, dass jede bereitgestellte Äußerung in einer eigenen Datei enthalten ist. Jede vom Studio gelieferte Audiodatei enthält mehrere Äußerungen. Die Hauptaufgabe nach der Produktion ist also, die Aufzeichnungen zu unterteilen und sie für die Übermittlung vorzubereiten. Der Tontechniker hat möglicherweise Marker in der Datei platziert (oder ein separates Cuesheet bereitgestellt), um anzugeben, wo die einzelnen Äußerungen beginnen.
Verwenden Sie Ihre Notizen, um die gewünschten Takes zu finden. Nutzen Sie dann ein Programm für die Tonbearbeitung wie z.B. Avid Pro Tools, Adobe Audition oder das kostenlose Audacity, um jede einzelne Äußerung in eine neue Datei zu kopieren.
Hören Sie sich jede Datei genau an. Sie können in dieser Phase kleine, unerwünschte Töne entfernen, die Sie während der Aufzeichnung überhört haben, z.B. ein leichtes Schmatzen vor einer Zeile. Achten Sie jedoch darauf, dass Sie nicht den eigentlichen Text entfernen. Wenn Sie eine Datei nicht korrigieren können, entfernen Sie sie aus dem Dataset, und machen Sie sich dazu eine entsprechende Notiz.
Konvertieren Sie vor dem Speichern jede Datei in 16 Bit und eine Samplingrate von 24 kHz. Falls Sie die Gespräche im Studio aufgezeichnet haben, entfernen Sie den zweiten Kanal. Speichern Sie jede Datei im WAV-Format, und benennen Sie die Dateien mit der Nummer der Äußerung aus Ihrem Skript.
Erstellen Sie abschließend das Transkript, mit dem die WAV-Datei mit einer Textversion der entsprechenden Äußerung verknüpft wird. Das Trainieren Ihres Stimmmodells beinhaltet Details zum erforderlichen Format. Sie können den Text direkt aus Ihrem Skript kopieren. Erstellen Sie eine ZIP-Datei der WAV-Dateien und des Texttranskripts.
Archivieren Sie die Originalaufzeichnungen an einem sicheren Ort, falls Sie sie später noch benötigen. Bewahren Sie auch Ihr Skript und die Notizen auf.
Nächste Schritte
Sie können nun Ihre Aufzeichnungen hochladen und Ihre benutzerdefinierte neuronale Stimme erstellen.