Benutzerdefinierte Spracherkennungs-Container mit Docker
Der Container für die benutzerdefinierte Spracherkennung transkribiert Sprache in Echtzeit oder Batchaudioaufzeichnungen mit Zwischenergebnissen. Sie können ein benutzerdefiniertes Modell verwenden, das Sie im Custom Speech-Portal erstellt haben. In diesem Artikel erfahren Sie, wie Sie einen Container für die benutzerdefinierte Spracherkennung herunterladen, installieren und ausführen.
Weitere Informationen zu den Voraussetzungen, zum Überprüfen, ob ein Container ausgeführt wird, Ausführen mehrerer Container auf demselben Host und Ausführen nicht verbundener Container finden Sie unter Installieren und Ausführen von Docker-Containern für die APIs des Speech-Diensts.
Containerimages
Das Containerimage für die benutzerdefinierte Spracherkennung für alle unterstützten Versionen und Gebietsschemas finden Sie im Microsoft Container Registry (MCR)-Syndikat. Es befindet sich im Repository azure-cognitive-services/speechservices/ und trägt den Namen custom-speech-to-text.

Der vollqualifizierte Containerimagename lautet mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Fügen Sie entweder eine bestimmte Version oder zum Abrufen der aktuellen Version :latest an.
| Version | `Path` |
|---|---|
| Neueste Version | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Alle Tags, mit Ausnahme von latest, haben das folgende Format und beachten die Groß-/Kleinschreibung:
<major>.<minor>.<patch>-<platform>-<prerelease>
Hinweis
Die Werte locale und voice für benutzerdefinierte Spracherkennungs-Container werden durch das benutzerdefinierte Modell bestimmt, das vom Container erfasst wird.
Die Tags sind der Einfachheit halber auch im JSON-Format verfügbar. Der Text enthält den Containerpfad und eine Liste mit Tags. Die Tags sind nicht nach Version sortiert, "latest" ist jedoch wie im folgenden Codeschnipsel gezeigt immer am Ende der Liste enthalten:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
Abrufen des Containerimages mit dem Befehl „docker pull“
Sie müssen die Voraussetzungen erfüllen (einschließlich der Hardwareanforderungen). Sehen Sie sich auch die empfohlene Zuordnung von Ressourcen für die einzelnen Speech-Container an.
Verwenden Sie den Befehl docker pull, um ein Containerimage aus Microsoft Container Registry herunterzuladen:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Hinweis
Die Werte für locale und voice für benutzerdefinierte Speech-Container werden durch das benutzerdefinierte Modell bestimmt, das vom Container erfasst wird.
Abrufen der Modell-ID
Bevor Sie den Container ausführen können, müssen Sie die Modell-ID Ihres benutzerdefinierten Modells oder eine Basismodell-ID kennen. Wenn Sie den Container ausführen, geben Sie eine der Modell-IDs zum Herunterladen und Verwenden an.
Das benutzerdefinierte Modell muss mithilfe von Speech Studiotrainiert werden. Informationen zum Abrufen der Modell-ID finden Sie unter Lebenszyklus eines Custom Speech-Modells.
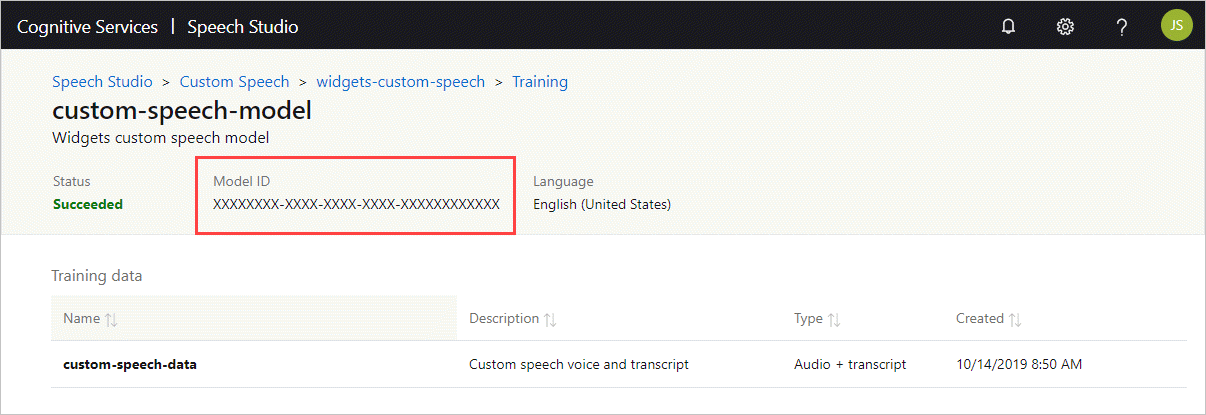
Rufen Sie die Modell-ID ab, um diese als Argument für den ModelId-Parameter des docker run-Befehls zu verwenden.
Herunterladen der Anzeigemodelle
Bevor Sie den Container ausführen, können Sie optional die Informationen zu den verfügbaren Anzeigemodellen abrufen und diese Modelle in Ihren Spracherkennungs-Container herunterladen. Dadurch erhalten Sie eine deutlich verbesserte endgültige Anzeigeausgabe. Der Download der Anzeigemodelle ist ab Version 3.1.0 des Containers für die benutzerdefinierte Spracherkennung verfügbar.
Hinweis
Obwohl Sie den Befehl docker run verwenden, wird der Container nicht für den Dienst gestartet.
Sie können die folgenden Anzeigemodelltypen abfragen oder herunterladen: Neubewertung (Rescore), Interpunktion (Punct), Neusegmentierung (Resegment) und wfstitn (Wfstitn). Andernfalls können Sie die Option FullDisplay (mit oder ohne die anderen Typen) verwenden, um alle Arten von Anzeigemodellen abzufragen oder herunterzuladen.
Legen Sie BaseModelLocale fest, um das neueste verfügbare Anzeigemodell für das Zielgebietsschema abzufragen. Wenn Sie mehrere Anzeigemodelltypen einbeziehen, gibt der Befehl die neuesten verfügbaren Anzeigemodelle für jeden Typ zurück. Beispiel:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Legen Sie DisplayLocale fest, um das neueste verfügbare Anzeigemodell für das Zielgebietsschema herunterzuladen. Wenn Sie DisplayLocale festlegen, müssen Sie auch FullDisplay oder eine durch Leerzeichen getrennte Teilmenge von Anzeigemodellen angeben. Der Befehl lädt das neueste verfügbare Anzeigemodell für jeden angegebenen Typ herunter. Beispiel:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Legen Sie einen Modell-ID-Parameter fest, um ein bestimmtes Anzeigemodell herunterzuladen: Neubewertung (RescoreId), Interpunktion (PunctId), Neusegmentierung (ResegmentId) oder wfstitn (WfstitnId). Dies ähnelt dem Herunterladen eines Basismodells über den Parameter ModelId. Zum Herunterladen eines Anzeigemodells für die Neubewertung können Sie beispielsweise den folgenden Befehl mit dem Parameter RescoreId verwenden:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Hinweis
Wenn Sie mehrere Abfrage- oder Downloadparameter festlegen, priorisiert der Befehl in dieser Reihenfolge: BaseModelLocale, Modell-ID und dann DisplayLocale (gilt nur für Anzeigemodelle).
Ausführen des Containers mit „docker run“
Verwenden Sie den Befehl docker run, um den Container auszuführen.
Die folgende Tabelle zeigt die verschiedenen docker run-Parameter und die entsprechenden Beschreibungen:
| Parameter | Beschreibung |
|---|---|
{VOLUME_MOUNT} |
Die Volumebereitstellung des Hostcomputers, die Docker zum dauerhaften Speichern des benutzerdefinierten Modells verwendet. Beispiel: c:\CustomSpeech, wobei sich das Laufwerk c:\ auf dem Hostcomputer befindet. |
{MODEL_ID} |
Die ID des benutzerdefinierten Sprachmodells oder Basismodells. Weitere Informationen finden Sie unter Abrufen der Modell-ID. |
{ENDPOINT_URI} |
Der Endpunkt ist zur Messung und Abrechnung erforderlich. Weitere Informationen finden Sie unter Abrechnungsargumente. |
{API_KEY} |
Der API-Schlüssel ist erforderlich. Weitere Informationen finden Sie unter Abrechnungsargumente. |
Wenn Sie den benutzerdefinierten Spracherkennungs-Container ausführen, konfigurieren Sie Port, Arbeitsspeicher und CPU gemäß den Anforderungen und Empfehlungen für benutzerdefinierte Spracherkennungs-Container.
Hier sehen Sie einen Beispielbefehl docker run mit Platzhalterwerten. Sie müssen die Werte VOLUME_MOUNT, MODEL_ID, ENDPOINT_URI und API_KEY angeben:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Dieser Befehl:
- Führt einen benutzerdefinierten Spracherkennungs-Container aus dem Containerimage aus.
- Ordnet 4 CPU-Kerne und 8 GB Arbeitsspeicher zu.
- Lädt das benutzerdefinierte Modell für die Spracherkennung aus der Volumebereitstellung für die Eingabe, z. B. C:\CustomSpeech.
- Macht den TCP-Port 5000 verfügbar und ordnet eine Pseudo-TTY-Verbindung für den Container zu.
- Lädt das Modell anhand der
ModelIdherunter (sofern diese in der Volumebereitstellung nicht gefunden wird). - Wenn das benutzerdefinierte Modell zuvor bereits heruntergeladen wurde, wird die
ModelIdignoriert. - Entfernt den Container automatisch, nachdem er beendet wurde. Das Containerimage ist auf dem Hostcomputer weiterhin verfügbar.
Weitere Informationen zur Verwendung von docker run mit Speech-Containern finden Sie unter Installieren und Ausführen von Docker-Containern für die APIs des Speech-Diensts.
Verwenden des Containers
Speech-Container bieten websocketbasierte Abfrageendpunkt-APIs, auf die über das Speech SDK und die Speech-Befehlszeilenschnittstelle (Command Line Interface, CLI) zugegriffen wird. Standardmäßig verwenden das Speech SDK und die Speech-CLI den öffentlichen Speech-Dienst. Um den Container verwenden zu können, müssen Sie die Initialisierungsmethode ändern.
Wichtig
Wenn Sie den Speech-Dienst mit Containern verwenden, müssen Sie die Hostauthentifizierung verwenden. Wenn Sie den Schlüssel und die Region konfigurieren, werden Anforderungen an den öffentlichen Speech-Dienst gesendet. Die Ergebnisse des Speech-Diensts sind möglicherweise nicht wie erwartet. Anforderungen von nicht verbundenen Containern schlagen fehl.
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
var config = SpeechConfig.FromSubscription(...);
Die folgende Konfiguration mit dem Container host:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
auto speechConfig = SpeechConfig::FromSubscription(...);
Die folgende Konfiguration mit dem Container host:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Die folgende Konfiguration mit dem Container host:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Die folgende Konfiguration mit dem Container host:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Die folgende Konfiguration mit dem Container host:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Die folgende Konfiguration mit dem Container host:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Die folgende Konfiguration mit dem Container host:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Verwenden Sie anstelle dieser Konfiguration für die Azure-Cloudinitialisierung:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Die folgende Konfiguration mit dem Container endpoint:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Wenn Sie die Speech CLI in einem Container verwenden, schließen Sie die Option --host ws://localhost:5000/ ein. Sie müssen auch --key none angeben, um sicherzustellen, dass die CLI nicht versucht, einen Speech-Schlüssel für die Authentifizierung zu verwenden. Informationen zum Konfigurieren der Speech-CLI finden Sie unter Erste Schritte mit der Azure KI Speech-CLI.
Testen Sie den Schnellstart zur Spracherkennung mithilfe der Hostauthentifizierung anstelle von Schlüssel und Region.
Nächste Schritte
- Lesen Sie die Übersicht über Speech-Container.
- Informieren Sie sich unter Konfigurieren von Containern über Konfigurationseinstellungen.
- Verwenden weiterer Azure KI-Container