Was ist der Azure Cosmos DB-Analysespeicher?
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Wichtig
Das Spiegeln von Azure Cosmos DB in Microsoft Fabric ist jetzt in der Vorschau für die NoSql-API verfügbar. Dieses Feature bietet alle Funktionen von Azure Synapse Link mit besserer Analyseleistung und der Möglichkeit, Ihren Datenbestand mit Fabric OneLake zu vereinheitlichen und den Zugriff auf die Daten im Delta-Parquet-Format zu öffnen. Wenn Sie Azure Synapse Link in Erwägung ziehen, wird empfohlen, die Spiegelung auszuprobieren, um die Eignung für Ihr Unternehmen insgesamt zu beurteilen. Erste Schritte mit der Spiegelung in Microsoft Fabric.
Um mit Azure Synapse Link zu beginnen, besuchen Sie bitte „Erste Schritte mit Azure Synapse Link“.
Der Azure Cosmos DB-Analysespeicher ist ein vollständig isolierter Spaltenspeicher, der umfangreiche Analysen für operative Daten in Ihrem Azure Cosmos DB ermöglicht, ohne dass dies Auswirkungen auf Ihre Transaktionsworkloads hat.
Der Azure Cosmos DB-Transaktionsspeicher ist schemaunabhängig und ermöglicht es Ihnen, Ihre Transaktionsanwendungen zu durchlaufen, ohne sich mit Schema- oder Indexverwaltung befassen zu müssen. Im Gegensatz dazu wird der Azure Cosmos DB-Analysespeicher schematisiert, um die Leistung von analytischen Abfragen zu optimieren. In diesem Artikel finden Sie ausführliche Informationen zum analytischen Speicher.
Herausforderungen bei umfangreichen Analysen operativer Daten
Die operativen Daten aus mehreren Modellen in einem Azure Cosmos DB-Container werden intern in einem indizierten zeilenbasierten „Transaktionsspeicher“ gespeichert. Das Zeilenspeicherformat ist so konzipiert, dass schnelle transaktionale Lese- und Schreibvorgänge mit Antwortzeiten im Millisekundenbereich sowie operative Abfragen möglich sind. Wenn das Dataset sehr umfangreich wird, können komplexe analytische Abfragen hinsichtlich des bereitgestellten Durchsatzes der in diesem Format gespeicherten Daten teuer sein. Ein hoher Verbrauch von bereitgestelltem Durchsatz wirkt sich wiederum auf die Leistung von transaktionalen Workloads aus, die von ihren Echtzeitanwendungen und -Diensten verwendet werden.
Zum Analysieren großer Datenmengen werden operative Daten in der Regel aus dem Transaktionsspeicher von Azure Cosmos DB extrahiert und in einer separaten Datenschicht gespeichert. Die Daten werden beispielsweise in einem Data Warehouse oder Data Lake in einem geeigneten Format gespeichert. Später werden diese Daten für umfangreiche Analysen verwendet und mithilfe von Compute-Engines (z. B. den Apache Spark-Clustern) analysiert. Die Trennung von analytischen und operativen Daten führt zu Verzögerungen für Analysten, die die neuesten Daten verwenden möchten.
Die ETL-Pipelines weisen zudem bei der Verarbeitung von Aktualisierungen der operativen Daten im Vergleich zur reinen Verarbeitung neu erfasster operativer Daten eine größere Komplexität auf.
Spaltenorientierter Analysespeicher
Der Azure Cosmos DB-Analysespeicher ist auf die Bewältigung der Herausforderungen hinsichtlich Komplexität und Latenz ausgelegt, die sich bei herkömmlichen ETL-Pipelines ergeben. Der Azure Cosmos DB-Analysespeicher kann Ihre operativen Daten automatisch in einen separaten Spaltenspeicher synchronisieren. Das Spaltenspeicherformat eignet sich für umfangreiche analytische Abfragen, die auf optimierte Weise ausgeführt werden können. Dies führt zu einer Verbesserung bei der Latenz solcher Abfragen.
Mithilfe von Azure Synapse Link können Sie jetzt HTAP-Lösungen ohne ETL erstellen, indem Sie eine direkte Verknüpfung von Azure Synapse Analytics mit dem Azure Cosmos DB-Analysespeicher herstellen. Damit können Sie umfangreiche Analysen Ihrer operativen Daten nahezu in Echtzeit ausführen.
Features des Analysespeichers
Wenn Sie den Analysespeicher für einen Azure Cosmos DB-Container aktivieren, wird basierend auf den operativen Daten in Ihrem Container ein neuer Spaltenspeicher intern erstellt. Dieser Spaltenspeicher wird getrennt vom zeilenorientierten Transaktionsspeicher für diesen Container in einem Speicherkonto, das vollständig von Azure Cosmos DB verwaltet wird, in einem internen Abonnement gespeichert. Kunden müssen keine Zeit für die Speicherverwaltung aufwenden. Die Einfüge-, Aktualisierungs- und Löschvorgänge für Ihre operativen Daten werden automatisch mit dem Analysespeicher synchronisiert. Änderungsfeed oder ETL sind nicht erforderlich, um die Daten zu synchronisieren.
Spaltenspeicher für Analyseworkloads operativer Daten
Analyseworkloads umfassen in der Regel Aggregationen und sequenzielle Scans ausgewählter Felder. Die analytisch gespeicherten Daten werden in einer spaltenweisen Reihenfolge gespeichert, so dass die Werte der einzelnen Felder ggf. zusammen serialisiert werden können. Dieses Format reduziert den IOPS-Aufwand zum Scannen oder Berechnen von Statistiken für bestimmte Felder. Dies führt beim Scannen großer Datasets zu einer wesentlichen Verbesserung der Antwortzeiten für Abfragen.
Wenn die operativen Tabellen beispielsweise das folgende Format haben:
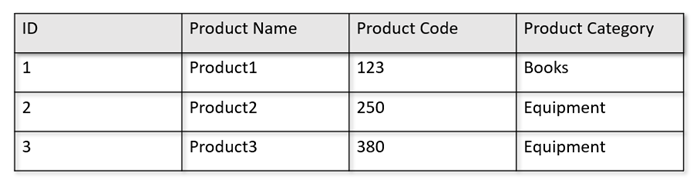
Im Zeilenspeicher werden die oben angegebenen Daten in einem serialisierten Format nach Zeile auf dem Datenträger gespeichert. Dieses Format ermöglicht schnellere transaktionale Lese- und Schreibvorgänge sowie operative Abfragen, wie z. B. „Rückgabe von Informationen über Produkt 1“. Wenn das Dataset jedoch immer größer wird und Sie komplexe analytische Abfragen für die Daten ausführen möchten, kann dies teuer werden. Wenn Sie z. B. die Umsatzentwicklung für ein Produkt in der Kategorie „Equipment“ für verschiedene Geschäftseinheiten und Monate abrufen möchten, müssen Sie eine komplexe Abfrage ausführen. Umfangreiche Scanvorgänge für dieses Dataset können in Hinsicht auf den bereitgestellten Durchsatz teuer werden und sich auch auf die Leistung der Transaktionsworkloads auswirken, die Ihre Echtzeitanwendungen und -dienste nutzen.
Der Analysespeicher, bei dem es sich um einen Spaltenspeicher handelt, ist für solche Abfragen besser geeignet, da er ähnliche Datenfelder gemeinsam serialisiert und die Datenträger-IOPS verringert.
In der folgenden Abbildung ist der Transaktions- bzw. Zeilenspeicher im Vergleich zum Analyse- bzw. Spaltenspeicher in Azure Cosmos DB dargestellt:
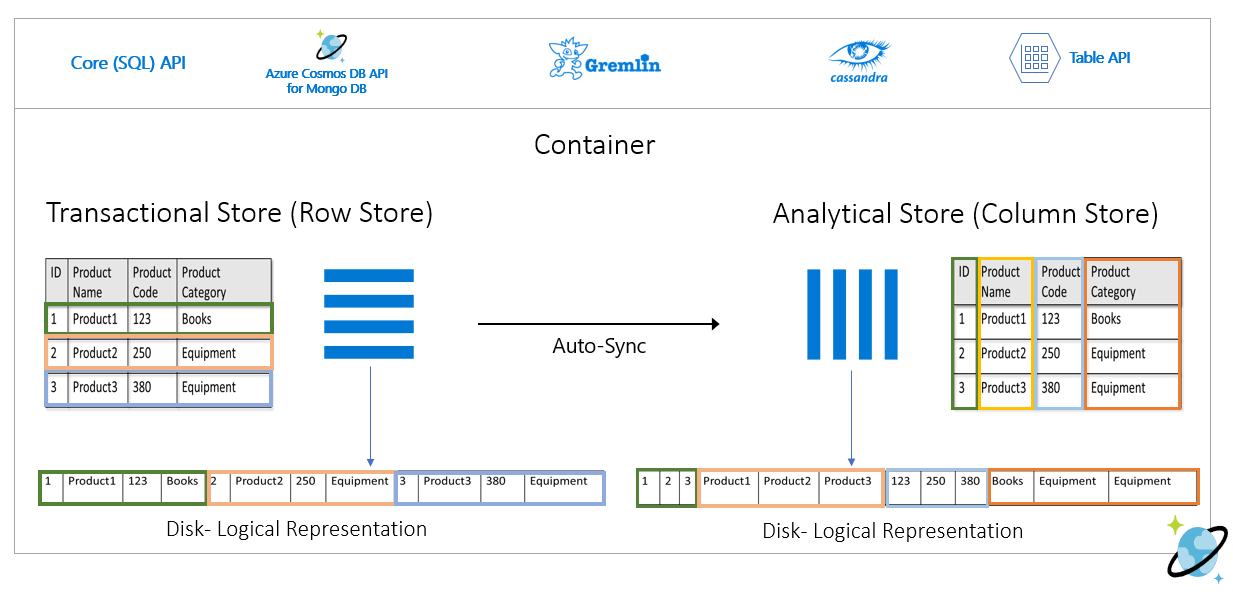
Entkoppelte Leistung für Analyseworkloads
Analytische Abfragen haben keine Auswirkung auf die Leistung der Transaktionsworkloads, da der Analysespeicher vom Transaktionsspeicher getrennt ist. Dem Analysespeicher müssen keine separaten Anforderungseinheiten (Request Units, RUs) zugewiesen werden.
Automatische Synchronisierung
Die automatische Synchronisierung bezieht sich auf die vollständig verwaltete Funktion von Azure Cosmos DB, bei der Einfüge-, Aktualisierungs- und Löschvorgänge für operative Daten automatisch nahezu in Echtzeit vom Transaktionsspeicher in den Analysespeicher synchronisiert werden. Die Wartezeit für die automatische Synchronisierung liegt normalerweise innerhalb von 2 Minuten. In Fällen, in denen eine Datenbank mit gemeinsam genutztem Durchsatz und einer großen Anzahl von Containern verwendet wird, kann die Wartezeit für die automatische Synchronisierung einzelner Containern länger sein und bis zu 5 Minuten betragen.
Am Ende jeder Ausführung des automatischen Synchronisierungsprozesses stehen Ihre Transaktionsdaten sofort für Azure Synapse Analytics-Laufzeiten zur Verfügung:
Spark-Pools in Azure Synapse Analytics können alle Daten, einschließlich der neuesten Updates, über Spark-Tabellen lesen, die automatisch aktualisiert werden, oder über den Befehl
spark.read, der immer den letzten Zustand der Daten liest.SQL Serverless-Pools in Azure Synapse Analytics können alle Daten, einschließlich der neuesten Updates, über Ansichten lesen, die automatisch aktualisiert werden, oder über
SELECTzusammen mit denOPENROWSET-Befehlen, die immer den letzten Status der Daten lesen.
Hinweis
Ihre Transaktionsdaten werden auch dann mit dem Analysespeicher synchronisiert, wenn Ihre Transaktionsgültigkeitsdauer (TTL) kürzer als zwei Minuten ist.
Hinweis
Beachten Sie, dass beim Löschen des Containers auch der Analysespeicher gelöscht wird.
Skalierbarkeit und Elastizität
Der Transaktionsspeicher Azure Cosmos DB nutzt die horizontale Partitionierung, um den Speicher und den Durchsatz elastisch und ohne Ausfallzeiten zu skalieren. Die horizontale Partitionierung im Transaktionsspeicher bietet Skalierbarkeit und Elastizität bei der automatischen Synchronisierung, um sicherzustellen, dass die Daten nahezu in Echtzeit in den Analysespeicher synchronisiert werden. Die Datensynchronisierung erfolgt unabhängig vom Durchsatz des transaktionalen Datenverkehrs, ganz gleich, ob es sich um 1000 Vorgänge/Sek. oder 1 Million Vorgänge/Sek. handelt. Zudem wirkt sie sich nicht auf den bereitgestellten Durchsatz im Transaktionsspeicher aus.
Automatische Handhabung von Schemaaktualisierungen
Der Azure Cosmos DB-Transaktionsspeicher ist schemaunabhängig und ermöglicht es Ihnen, Ihre Transaktionsanwendungen zu durchlaufen, ohne sich mit Schema- oder Indexverwaltung befassen zu müssen. Im Gegensatz dazu wird der Azure Cosmos DB-Analysespeicher schematisiert, um die Leistung von analytischen Abfragen zu optimieren. Mit der Funktion der automatischen Synchronisierung verwaltet Azure Cosmos DB den Schemarückschluss über die neuesten Aktualisierungen aus dem Transaktionsspeicher. Außerdem wird die Schemadarstellung im Analysespeicher standardmäßig verwaltet, einschließlich der Handhabung geschachtelter Datentypen.
Während Ihr Schema weiterentwickelt wird und im Laufe der Zeit neue Eigenschaften hinzugefügt werden, stellt der Analysespeicher ein zusammengefasstes Schema für alle verlaufsbezogenen Schemata im Transaktionsspeicher automatisch dar.
Hinweis
Im Kontext des Analysespeichers betrachten wir die folgenden Strukturen als Eigenschaft:
- JSON-„Elemente“ oder „Zeichenfolgen-Wert-Paare, die durch ein
:getrennt sind.“ - JSON-Objekte, getrennt durch
{und}. - JSON-Arrays, getrennt durch
[und].
Schemaeinschränkungen
Die folgenden Einschränkungen gelten für die operativen Daten in Azure Cosmos DB, wenn Sie den Analysespeicher aktivieren, damit das Schema automatisch abgeleitet und richtig dargestellt wird:
Sie können maximal 1000 Eigenschaften auf allen geschachtelten Ebenen im Dokumentschema und eine maximale Schachtelungstiefe von 127 festlegen.
- Nur die ersten 1000 Eigenschaften werden im Analysespeicher dargestellt.
- Nur die ersten 127 Eigenschaften werden im Analysespeicher dargestellt.
- Die erste Ebene eines JSON-Dokuments ist die Stammebene
/. - Eigenschaften in der ersten Ebene des Dokuments werden als Spalten dargestellt.
Beispielszenarien:
- Wenn die erste Ebene Ihres Dokuments über 2000 Eigenschaften verfügt, stellt der Synchronisierungsprozess die ersten 1000 Eigenschaften dar.
- Wenn Ihre Dokumente fünf Ebenen mit jeweils 200 Eigenschaften aufweisen, stellt der Synchronisierungsprozess alle Eigenschaften dar.
- Wenn Ihre Dokumente über 10 Ebenen mit jeweils 400 Eigenschaften verfügen, stellt der Synchronisierungsprozess die beiden ersten Ebenen vollständig und nur die Hälfte der dritten Ebene dar.
Das folgende hypothetische Dokument enthält vier Eigenschaften und drei Ebenen.
- Die Ebenen sind
root,myArrayund die geschachtelte Struktur innerhalb vonmyArray. - Die Eigenschaften sind
id,myArray,myArray.nested1undmyArray.nested2. - Die Darstellung des Analysespeichers enthält zwei Spalten,
idundmyArray. Sie können Spark- oder T-SQL-Funktionen verwenden, um die geschachtelten Strukturen auch als Spalten verfügbar zu machen.
- Die Ebenen sind
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Während JSON-Dokumente (und Azure Cosmos DB-Sammlungen/Container) im Hinblick auf die Eindeutigkeit zwischen Groß- und Kleinschreibung unterscheiden, ist dies beim Analysespeicher nicht der Fall.
- Im gleichen Dokument: Namen von Eigenschaften auf der gleichen Ebene sollten bei Nichtbeachtung der Groß-/Kleinschreibung eindeutig sein. Das folgende JSON-Dokument enthält z. B. „Name“ und „name“ auf der gleichen Ebene. Obwohl es sich um ein gültiges JSON-Dokument handelt, erfüllt es nicht die Bedingung der Eindeutigkeit und wird daher nicht vollständig im Analysespeicher dargestellt. In diesem Beispiel sind „Name“ und „name“ identisch, wenn sie ohne Berücksichtigung der Groß-/Kleinschreibung verglichen werden. Nur
"Name": "fred"wird im Analysespeicher dargestellt, da es das erste Vorkommen ist. Und"name": "john"wird überhaupt nicht dargestellt.
{"id": 1, "Name": "fred", "name": "john"}- In unterschiedlichen Dokumenten: Eigenschaften in der gleichen Ebene und mit dem gleichen Namen, aber in unterschiedlichen Fällen, werden innerhalb der gleichen Spalte dargestellt, wobei das Namensformat des ersten Vorkommens verwendet wird. Beispielsweise haben die folgenden JSON-Dokumente
"Name"und"name"auf derselben Ebene. Da das erste Dokumentformat"Name"ist, wird dies verwendet, um den Eigenschaftsnamen im Analysespeicher darzustellen. Anders ausgedrückt: der Spaltenname im Analysespeicher lautet"Name". Sowohl"fred"als auch werden"john"in der"Name"Spalte dargestellt.
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- Im gleichen Dokument: Namen von Eigenschaften auf der gleichen Ebene sollten bei Nichtbeachtung der Groß-/Kleinschreibung eindeutig sein. Das folgende JSON-Dokument enthält z. B. „Name“ und „name“ auf der gleichen Ebene. Obwohl es sich um ein gültiges JSON-Dokument handelt, erfüllt es nicht die Bedingung der Eindeutigkeit und wird daher nicht vollständig im Analysespeicher dargestellt. In diesem Beispiel sind „Name“ und „name“ identisch, wenn sie ohne Berücksichtigung der Groß-/Kleinschreibung verglichen werden. Nur
Das erste Dokument der Auflistung definiert das anfängliche Schema des Analysespeichers.
- Dokumente, die mehr Eigenschaften als das anfängliche Schema aufweisen, generieren neue Spalten im Analysespeicher.
- Spalten können nicht entfernt werden.
- Das Löschen aller Dokumente in einer Sammlung setzt das Schema des analytischen Speichers nicht zurück.
- Eine Versionierung des Schemas gibt es nicht. Die letzte Version, die aus dem Transaktionsspeicher abgeleitet wird, wird im Analysespeicher angezeigt.
Zurzeit kann Azure Synapse Spark keine Eigenschaften lesen, deren Namen einige der unten aufgeführten Sonderzeichen enthalten. Azure Synapse SQL (serverlos) ist nicht betroffen.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Hinweis
Leerzeichen werden auch in der Spark-Fehlermeldung aufgeführt, die zurückgegeben wird, wenn diese Einschränkung erreicht ist. Es wurden spezielle Verfahren für das Behandeln von Leerzeichen hinzugefügt. Weitere Details finden Sie in den folgenden Artikeln.
- Wenn Sie Eigenschaftennamen haben, die die oben aufgeführten Zeichen verwenden, sind die folgenden Alternativen verfügbar:
- Ändern Sie Ihr Datenmodell im Voraus, um diese Zeichen zu vermeiden.
- Da die Schemazurücksetzung derzeit nicht unterstützt wird, können Sie Ihre Anwendung ändern, um eine redundante Eigenschaft mit einem ähnlichen Namen hinzuzufügen und diese Zeichen zu vermeiden.
- Verwenden Sie den Änderungsfeed, um eine materialisierte Sicht Ihres Containers ohne diese Zeichen in Eigenschaftennamen zu erstellen.
- Verwenden Sie die Spark-Option
dropColumn, um die betroffenen Spalten zu ignorieren und alle Daten in einen DataFrame zu laden. Die Syntax ist:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark unterstützt jetzt Eigenschaften, deren Namen Leerzeichen enthalten. Dazu müssen Sie die Spark-Option
allowWhiteSpaceInFieldNamesverwenden, um die betroffenen Spalten in einen DataFrame zu laden und dabei den ursprünglichen Namen beizubehalten. Die Syntax ist:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Die folgenden BSON-Datentypen werden nicht unterstützt und nicht im Analysespeicher dargestellt:
- Decimal128
- Regular Expression
- DB-Zeiger
- JavaScript
- Symbol
- MinKey/MaxKey
Wenn Sie DateTime-Zeichenfolgen verwenden, die dem ISO 8601 UTC-Standard entsprechen, erwarten Sie das folgende Verhalten:
- Spark-Pools in Azure Synapse stellen diese Spalten als
stringdar. - SQL Serverless-Pools in Azure Synapse stellen diese Spalten als
varchar(8000)dar.
- Spark-Pools in Azure Synapse stellen diese Spalten als
Eigenschaften mit
UNIQUEIDENTIFIER (guid)-Typen werden wie im analytischen Speicher alsstringdargestellt und sollten zur richtigen Visualisierung in SQL inVARCHARoder in Spark instringumgewandelt werden.SQL serverlose Pools in Azure Synapse unterstützen Ergebnismengen mit bis zu 1.000 Spalten, und das Verfügbarmachen geschachtelter Spalten zählt auch für diesen Grenzwert. Es empfiehlt sich, diese Informationen in Ihrer Transaktionsdatenarchitektur und -modellierung zu berücksichtigen.
Wenn Sie eine Eigenschaft in einem oder vielen Dokumenten umbenennen, wird sie wie eine neue Spalte behandelt. Wenn Sie in allen Dokumenten der Sammlung dieselbe Umbenennung vornehmen, werden alle Daten zur neuen Spalte migriert, und die alte Spalte wird durch
NULL-Werte dargestellt.
Schemadarstellung
Es gibt zwei Methoden der Schemadarstellung im Analysespeicher, die für alle Container im Datenbankkonto gültig sind. Bei diesen Modi bestehen Kompromisse zwischen der Einfachheit der Abfrageerfahrung und der Benutzerfreundlichkeit einer umfassenderen spaltenförmigen Darstellung für polymorphe Schemata.
- Genau definierte Schemadarstellung, Standardoption für API für NoSQL- und Gremlin-Konten.
- Die Darstellung des Schemas mit vollständiger Genauigkeit ist die Standardoptionen für die API für MongoDB-Konten.
Genau definierte Schemadarstellung
Die genau definierte Schemadarstellung erstellt eine einfache tabellarische Darstellung der schemaunabhängigen Daten im Transaktionsspeicher. Bei der genau definierten Schemadarstellung gibt es die folgenden Überlegungen:
- Das erste Dokument definiert das Basisschema. Die Eigenschaften müssen in allen Dokumenten immer denselben Typ aufweisen. Es gelten nur die folgende Ausnahmen:
- Von
NULLin einen anderen Datentyp. Das erste Vorkommen ungleich null definiert den Spaltendatentyp. Alle Dokumente, die nicht dem ersten Datentyp ungleich null folgen, werden im Analysespeicher nicht dargestellt. - Von
floatininteger. Alle Dokumente werden im Analysespeicher dargestellt. - Von
integerinfloat. Alle Dokumente werden im Analysespeicher dargestellt. Um diese Daten jedoch mit Azure Synapse SQL serverlosen Pools zu lesen, müssen Sie eine WITH-Klausel verwenden, um die Spalte invarcharzu konvertieren. Und nach dieser anfänglichen Konvertierung ist es möglich, sie erneut in eine Zahl zu konvertieren. Schauen Sie sich das folgende Beispiel an, bei dem num der erste Wert eine Ganzzahl und der zweite ein Gleitkommazahl war.
- Von
SELECT CAST (num as float) as num
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = '<your-connection',
OBJECT = 'IntToFloat',
SERVER_CREDENTIAL = 'your-credential'
)
WITH (num varchar(100)) AS [IntToFloat]
Eigenschaften, die nicht dem Basisschemadatentyp folgen, werden im Analysespeicher nicht dargestellt. Betrachten Sie beispielsweise die folgenden Dokumente, von denen das erste das Basisschema des Analysespeichers definiert. Das zweite Dokument, bei dem
id"2"ist, hat kein genau definiertes Schema, da die"code"-Eigenschaft eine Zeichenfolge ist und das erste Dokument"code"als Zahl hat. In diesem Fall registriert der Analysespeicher den Datentyp von"code"alsintegerfür die Lebensdauer des Containers. Das zweite Dokument wird weiterhin im Analysespeicher enthalten sein, aber seine Eigenschaft"code"nicht.{"id": "1", "code":123}{"id": "2", "code": "123"}
Hinweis
Die obige Bedingung gilt nicht für die NULL-Eigenschaften. Beispielsweise ist {"a":123} and {"a":NULL} immer noch genau definiert.
Hinweis
Die obige Bedingung ändert sich nicht, wenn Sie "code" im Dokument "1" in eine Zeichenfolge in Ihrem Transaktionsspeicher ändern. Im Analysespeicher wird "code" als integer beibehalten, da die Schemazurücksetzung derzeit nicht unterstützt wird.
- Arraytypen müssen einen einzelnen wiederholten Typ enthalten.
{"a": ["str",12]}ist beispielsweise kein genau definiertes Schema, weil das Array eine Mischung aus ganzzahligen Typen und Zeichenfolgetypen enthält.
Hinweis
Wenn der Azure Cosmos DB-Analysespeicher der genau definierten Schemadarstellung folgt und die vorstehende Spezifikation durch bestimmte Elemente verletzt wird, werden diese Elemente in den Analysespeicher nicht einbezogen.
Gehen Sie von unterschiedlichem Verhalten in Bezug auf verschiedene Typen in einem genau definierten Schema aus:
- Spark-Pools in Azure Synapse stellen diese Werte als
undefineddar. - SQL Serverless-Pools in Azure Synapse stellen diese Werte als
NULLdar.
- Spark-Pools in Azure Synapse stellen diese Werte als
Erwarten Sie ein anderes Verhalten hinsichtlich expliziter
NULLWerte:- Spark-Pools in Azure Synapse lesen diese Werte als
0(NULL) und alsundefinedsobald die Spalte einen Ungleich-NULL-Wert aufweist. - SQL Serverless-Pools in Azure Synapse lesen diese Werte als
NULL.
- Spark-Pools in Azure Synapse lesen diese Werte als
Erwarten Sie ein anderes Verhalten hinsichtlich expliziter Werte:
- Spark-Pools in Azure Synapse stellen diese Spalten als
undefineddar. - SQL Serverless-Pools in Azure Synapse stellen diese Spalten als
NULLdar.
- Spark-Pools in Azure Synapse stellen diese Spalten als
Problemumgehungen bei Darstellungsherausforderungen
Möglicherweise wurde ein altes Dokument mit einem falschen Schema verwendet, um das Basisschema des Analysespeichers Ihres Containers zu erstellen. Basierend auf allen oben aufgeführten Regeln erhalten Sie möglicherweise NULL für bestimmte Eigenschaften, wenn Sie Ihren Analysespeicher mithilfe von Azure Synapse Link abfragen. Das Löschen oder Aktualisieren der problematischen Dokumente ist nicht hilfreich, da das Zurücksetzen des Basisschemas derzeit nicht unterstützt wird. Lösungsvorschläge:
- Um die Daten in einen neuen Container zu migrieren, stellen Sie sicher, dass alle Dokumente über das richtige Schema verfügen.
- Um die Eigenschaft mit dem falschen Schema aufzugeben, fügen Sie ein neues mit einem anderen Namen hinzu, das das richtige Schema in allen Dokumenten enthält. Beispiel: Im Container Orders befinden sich Milliarden von Dokumenten, bei denen die Eigenschaft status eine Zeichenfolge ist. Aber für das erste Dokument in diesem Container ist status als Ganzzahl definiert. So wird für ein Dokument status korrekt dargestellt, und alle anderen Dokumente haben
NULL. Sie können die Eigenschaft status2 allen Dokumenten hinzufügen und mit deren Verwendung anstelle der ursprünglichen Eigenschaft beginnen.
Schemadarstellung mit vollständiger Genauigkeit
Die Schemadarstellung mit vollständiger Genauigkeit ist so konzipiert, dass sie die gesamte Breite von polymorphen Schemata in den schemaunabhängigen operativen Daten verarbeitet. In dieser Schemadarstellung werden keine Elemente aus dem Analysespeicher gelöscht, selbst wenn die genau definierten Schemaeinschränkungen (d. h. keine Felder mit gemischtem Datentyp oder Arrays mit gemischtem Datentyp) verletzt werden.
Dies wird erreicht, indem die Blatteigenschaften der operativen Daten im Analysespeicher als key-value-Paare in JSON übersetzt werden, wobei der Datentyp key und der Eigenschaftsinhalt value ist. Diese JSON-Objektdarstellung ermöglicht Abfragen ohne Mehrdeutigkeit, und Sie können jeden Datentyp einzeln analysieren.
Anders ausgedrückt: In der vollständigen Schemadarstellung wird für jeden Datentyp jeder Eigenschaft jedes Dokuments ein key-value-Paar in einem JSON-Objekt für diese Eigenschaft generiert. Jede davon zählt als eine der maximal 1.000 Eigenschaften.
Sehen Sie sich beispielsweise das folgende Beispieldokument im Transaktionsspeicher an:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
Das geschachtelte address-Objekt ist eine Eigenschaft auf Stammebene des Dokuments, das als Spalte dargestellt wird. Jede Blatteigenschaft im address-Objekt wird als JSON-Objekt dargestellt: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Im Gegensatz zur klar definierten Schemadarstellung ermöglicht die Methode mit vollständiger Genauigkeit Variationen bei Datentypen. Wenn das nächste Dokument in dieser Auflistung im obigen Beispiel eine streetNo als Zeichenfolge enthält, wird sie im Analysespeicher als "streetNo":{"string":15850} dargestellt. Bei der Methode mit einem klar definierten Schema würde sie nicht dargestellt werden.
Datentypzuordnung für ein Schema mit vollständiger Genauigkeit
Im Folgenden finden Sie eine Zuordnung zwischen den MongoDB-Datentypen und ihrer Darstellung im analytischen Speicher in einer Schemadarstellung mit vollständiger Genauigkeit. Die nachstehende Zuordnung gilt nicht für NoSQL-API-Konten.
| Ursprünglicher Datentyp | Suffix | Beispiel |
|---|---|---|
| Double | ".float64" | 24,99 |
| Array | ".array" | ["a", "b"] |
| Binary | ".binary" | 0 |
| Boolean | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| Timestamp | ".timestamp" | Timestamp(0, 0) |
| ObjectID | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Dokument | ".object" | {"a": "a"} |
Erwarten Sie ein anderes Verhalten hinsichtlich expliziter
NULLWerte:- Spark-Pools in Azure Synapse lesen diese Werte als
0(null). - SQL Serverless-Pools in Azure Synapse lesen diese Werte als
NULL.
- Spark-Pools in Azure Synapse lesen diese Werte als
Erwarten Sie ein anderes Verhalten hinsichtlich expliziter Werte:
- Spark-Pools in Azure Synapse stellen diese Spalten als
undefineddar. - SQL Serverless-Pools in Azure Synapse stellen diese Spalten als
NULLdar.
- Spark-Pools in Azure Synapse stellen diese Spalten als
Erwarten Sie ein anderes Verhalten im Hinblick auf
timestamp-Werte:- Spark-Pools in Azure Synapse lesen diese Werte als
TimestampType,DateTypeoderFloat. Dies hängt vom Bereich und davon ab, wie der Zeitstempel generiert wurde. - SQL Serverless-Pools in Azure Synapse lesen diese Werte als
DATETIME2(im Bereich0001-01-01bis9999-12-31). Werte außerhalb dieses Bereichs werden nicht unterstützt und verursachen einen Ausführungsfehler für Ihre Abfragen. Ist dies bei Ihnen der Fall, können Sie folgende Schritte ausführen:- Entfernen Sie die Spalte aus der Abfrage. Um die Darstellung beizubehalten, können Sie eine neue Eigenschaft erstellen, die diese Spalte spiegelt, aber innerhalb des unterstützten Bereichs liegt. Verwenden Sie sie in Ihren Abfragen.
- Verwenden Sie Change Data Capture aus dem Analysespeicher ohne Kosten für RUs, um die Daten in ein neues Format innerhalb einer der unterstützten Senken zu transformieren und zu laden.
- Spark-Pools in Azure Synapse lesen diese Werte als
Verwenden des Schemas mit vollständiger Genauigkeit mit Spark
Spark verwaltet beim Laden in einen DataFrame jeden Datentyp als Spalte. Im Folgenden wird von einer Auflistung mit den folgenden Dokumenten ausgegangen.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Während das erste Dokument rating als Zahl und timestamp im UTC-Format aufweist, enthält das zweite Dokument rating und timestamp als Zeichenfolgen. Unter der Annahme, dass diese Auflistung ohne Datentransformation in DataFrame geladen wurde, lautet die Ausgabe von df.printSchema() wie folgt:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
In der klar definierten Schemadarstellung werden sowohl rating als auch timestamp des zweiten Dokuments nicht dargestellt. Im Schema mit vollständiger Genauigkeit können Sie die folgenden Beispiele verwenden, um einzeln auf jeden Wert jedes Datentyps zuzugreifen.
Im folgenden Beispiel können Sie PySpark verwenden, um eine Aggregation auszuführen:
df.groupBy(df.item.string).sum().show()
Im folgenden Beispiel können Sie PySQL verwenden, um eine weitere Aggregation auszuführen:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Verwenden des Schemas mit vollständiger Genauigkeit mit SQL
Sie können das folgende Syntaxbeispiel verwenden, mit den gleichen Dokumenten wie im obigen Spark-Beispiel:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Sie können Transformationen mithilfe von cast, convert oder jeder anderen T-SQL-Funktion implementieren, um Ihre Daten zu bearbeiten. Außerdem können Sie komplexe Datentypstrukturen auch mithilfe von Sichten ausblenden.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Arbeiten mit MongoDB-Feld _id
MongoDB-Feld _id ist grundlegend für jede Sammlung in MongoDB und hat ursprünglich eine hexadezimale Darstellung. Wie Sie in der obigen Tabelle sehen können, werden im Schema mit vollständiger Genauigkeit die Merkmale beibehalten. Dies stellt eine Herausforderung für die Visualisierung in Azure Synapse Analytics dar. Für die richtige Visualisierung müssen Sie den _id-Datentyp wie unten konvertieren:
Arbeiten mit dem MongoDB-Feld _id in Spark
Das folgende Beispiel funktioniert mit den Spark-Versionen 2.x und 3.x:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Arbeiten mit dem MongoDB-Feld _id in SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET('CosmosDB',
'Your-account;Database=your-database;Key=your-key',
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Arbeiten mit MongoDB-Feld id
Die id-Eigenschaft in MongoDB-Containern wird automatisch durch die Base64-Darstellung der Eigenschaft „_id“ im analytischen Speicher ersetzt. Das Feld „id“ ist für die interne Verwendung durch MongoDB-Anwendungen vorgesehen. Derzeit besteht die einzige Problemumgehung darin, die Eigenschaft „id“ in etwas anderes als „id“ umzubenennen.
Schema mit vollständiger Genauigkeit für die API für NoSQL- oder Gremlin-Konten
Es ist möglich, anstelle der Standardoption das Schema mit vollständiger Genauigkeit für API für NoSQL-Konten zu verwenden. Dazu legen Sie den Schematyp beim erstmaligen Aktivieren von Synapse Link für ein Azure Cosmos DB-Konto fest. Nachfolgend sind die Überlegungen zum Ändern des Standardtyps für die Schemadarstellung aufgeführt:
- Wenn Sie derzeit Synapse Link in Ihrem NoSQL-API-Konto über das Azure-Portal aktivieren, wird es als klar definiertes Schema aktiviert.
- Wenn Sie derzeit ein Schema mit vollständiger Genauigkeit mit NoSQL- oder Gremlin-API-Konten verwenden möchten, müssen Sie es auf Kontoebene in demselben CLI- oder PowerShell-Befehl festlegen, mit dem Synapse Link auf Kontoebene aktiviert wird.
- Derzeit ist Azure Cosmos DB for MongoDB mit dieser Möglichkeit zur Änderung der Schemadarstellung nicht kompatibel. Alle MongoDB-Konten weisen eine Schemadarstellung mit vollständiger Genauigkeit auf.
- Die oben erwähnte Datentypzuordnung mit einem Schema mit vollständiger Genauigkeit gilt nicht für NoSQL-API-Konten, die JSON-Datentypen verwenden. Beispielsweise werden die Werte
floatundintegerim Analysespeicher alsnumdargestellt. - Es ist nicht möglich, die Schemadarstellung von klar definiert auf vollständige Genauigkeit zurückzusetzen oder umgekehrt.
- Derzeit werden Containerschemata im Analysespeicher beim Erstellen des Containers definiert, auch wenn Synapse Link im Datenbankkonto nicht aktiviert wurde.
- Container oder Graphen, die erstellt wurden, bevor Synapse Link mit einem Schema mit vollständiger Genauigkeit auf Kontoebene aktiviert wurde, weisen ein klar definiertes Schema auf.
- Container oder Graphen, die erstellt wurden, nachdem Synapse Link mit einem Schema mit vollständiger Genauigkeit auf Kontoebene aktiviert wurde, weisen ein Schema mit vollständiger Genauigkeit auf.
Die Entscheidung über die Art der Schemadarstellung muss zeitgleich mit der Aktivierung von Synapse Link für das Konto mithilfe der Azure CLI oder mit PowerShell getroffen werden.
Mit der Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Hinweis
Ersetzen Sie im obigen Befehl create mit update für bestehende Konten.
Mit der PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Hinweis
Ersetzen Sie im obigen Befehl New-AzCosmosDBAccount mit Update-AzCosmosDBAccount für bestehende Konten.
Analytische Gültigkeitsdauer (TTL)
Die Gültigkeitsdauer von Analysedaten (ATTL) gibt an, wie lange Daten in Ihrem Analysespeicher für einen Container aufbewahrt werden sollen.
Der analytische Speicher ist aktiviert, wenn ATTL mit einem anderen Wert als NULL und 0 festgelegt wird. Wenn er aktiviert ist, werden Einfüge-, Aktualisierungs- und Löschvorgänge für operative Daten unabhängig von der Konfiguration der transaktionalen Gültigkeitsdauer (TTTL) automatisch aus dem Transaktionsspeicher in den Analysespeicher synchronisiert. Die Aufbewahrung dieser Transaktionsdaten im Analysespeicher kann auf Containerebene durch die Eigenschaft AnalyticalStoreTimeToLiveInSeconds gesteuert werden.
Mögliche ATTL-Konfigurationen sind:
Wenn der Wert auf
0festgelegt ist, wird der Analysespeicher deaktiviert, und es werden keine Daten aus dem Transaktionsspeicher in den Analysespeicher repliziert. Öffnen Sie einen Supportfall, um den analytischen Speicher in Ihren Containern zu deaktivieren.Wenn das Feld ausgeblendet ist, geschieht nichts, und der vorherige Wert wird beibehalten.
Wird der Wert auf
-1festgelegt, werden im Analysespeicher alle Verlaufsdaten aufbewahrt, unabhängig von der Aufbewahrung der Daten im Transaktionsspeicher. Diese Einstellung gibt an, dass Ihre operativen Daten im Analysespeicher unbegrenzt aufbewahrt werden.Wird der Wert auf eine beliebige positive Ganzzahl
nfestgelegt, läuft die Gültigkeit von Elementen im AnalysespeichernSekunden nach dem Zeitpunkt der letzten Änderung im Transaktionsspeicher ab. Diese Einstellung kann genutzt werden, wenn Sie die operativen Daten für einen begrenzten Zeitraum im Analysespeicher aufbewahren möchten, unabhängig von der Aufbewahrung der Daten im Transaktionsspeicher.
Zu berücksichtigende Punkte:
- Nachdem der Analysespeicher mit einem ATTL-Wert aktiviert wurde, kann er später auf einen anderen gültigen Wert aktualisiert werden.
- Während TTTL auf Container- oder Elementebene festgelegt werden kann, kann ATTL derzeit nur auf Containerebene festgelegt werden.
- Sie können eine längere Aufbewahrung Ihrer operativen Daten im Analysespeicher erzielen, indem Sie ATTL >= TTTL auf Containerebene festlegen.
- Der Analysespeicher kann auf die Spiegelung des Transaktionsspeichers festgelegt werden, indem ATTL = TTTL festgelegt wird.
- Wenn der ATTL-Wert höher als der TTTL-Wert ist, verfügen Sie irgendwann über Daten, die nur im Analysespeicher vorhanden sind. Die Daten sind schreibgeschützt.
- Derzeit löschen wir keine Daten aus dem Analysespeicher. Wenn Sie die ATTL auf eine positive ganze Zahl festlegen, werden die Daten nicht in Ihre Abfragen einbezogen, und es fallen dafür keine Kosten an. Wenn Sie den ATTL-Wert jedoch wieder in
-1ändern, werden alle Daten erneut angezeigt, und das gesamte Datenvolumen wird abgerechnet.
Sie können den Analysespeicher für einen Container auf folgende Weise aktivieren:
Über das Azure-Portal wird die ATTL-Option (sofern aktiviert) auf den Standardwert „-1“ festgelegt. Sie können diesen Wert in ‚n‘ Sekunden ändern, indem Sie unter „Daten-Explorer“ zu „Containereinstellungen“ navigieren.
Über das Azure Management SDK, Azure Cosmos DB-SDKs, PowerShell oder die CLI kann die ATTL-Option aktiviert werden, indem sie entweder auf „-1“ oder „n“ Sekunden festgelegt wird.
Weitere Informationen finden Sie unter Konfigurieren der analytischen Gültigkeitsdauer für einen Container.
Kosteneffiziente Analysen von Verlaufsdaten
Datentiering bezieht sich auf die Trennung von Daten zwischen Speicherinfrastrukturen, die für verschiedene Szenarien optimiert sind. Dadurch wird die Gesamtleistung und die Kosteneffizienz des End-to-End-Datenstapels verbessert. Mit dem Analysespeicher unterstützt Azure Cosmos DB jetzt das automatische Tiering von Daten aus dem Transaktionsspeicher in den Analysespeicher mit unterschiedlichen Datenlayouts. Mit dem Analysespeicher, der im Vergleich zum Transaktionsspeicher in Bezug auf die Speicherkosten optimiert ist, können Sie deutlich längere Horizonte operativer Daten für Verlaufsanalysen aufbewahren.
Nachdem der Analysespeicher aktiviert wurde, können Sie basierend auf den Anforderungen an die Datenaufbewahrung der Transaktionsworkloads die Eigenschaft transactional TTL so konfigurieren, dass Datensätze nach einem bestimmten Zeitraum automatisch aus dem Transaktionsspeicher gelöscht werden. Entsprechend können Sie mit analytical TTL den Lebenszyklus von Daten verwalten, die im Analysespeicher aufbewahrt werden, und zwar unabhängig vom Transaktionsspeicher. Das Aktivieren des Analysespeichers und Konfigurieren transaktions- und analysebezogener TTL-Eigenschaften ermöglicht Ihnen ein nahtloses Abstufen und Definieren des Datenaufbewahrungszeitraums für die beiden Speicher.
Hinweis
Wenn analytical TTL auf einen Wert festgelegt wird, der größer ist als der Wert transactional TTL, enthält Ihr Container Daten, die nur im Analysespeicher vorhanden sind. Diese Daten sind schreibgeschützt. Zudem unterstützen wir im Analysespeicher derzeit nicht die Dokumentebene TTL. Wenn Ihre Containerdaten in Zukunft möglicherweise aktualisiert oder gelöscht werden müssen, sollten Sie analytical TTL nicht größer als transactional TTL wählen. Diese Funktionalität wird für Daten empfohlen, die in Zukunft keine Updates benötigen oder gelöscht werden.
Hinweis
Wenn Ihr Szenario keine physischen Löschungen benötigt, können Sie einen logischen Lösch-/Updateansatz übernehmen. Fügen Sie in den Transaktionsspeicher eine andere Version desselben Dokuments ein, die nur im Analysespeicher vorhanden ist, aber eine logische Löschung bzw. Aktualisierung benötigt. Ggf. mit einem Flag, das angibt, dass es sich um eine Löschung oder Aktualisierung eines abgelaufenen Dokuments handelt. Beide Versionen desselben Dokuments sind gleichzeitig im Analysespeicher vorhanden, und Ihre Anwendung sollte nur die letzte berücksichtigen.
Resilienz
Der Analysespeicher nutzt Azure Storage und bietet folgenden Schutz vor physischen Ausfällen:
- Azure Cosmos DB-Datenbankkonten ordnen Analysespeicher in LRS-Konten (lokal redundanter Speicher) zu. LRS stellt eine Dauerhaftigkeit von mindestens 99,999999999 % (11 Neunen) für Objekte in einem bestimmten Jahr bereit.
- Wenn eine geografische Region des Datenbankkontos für Zonenredundanz konfiguriert ist, wird sie in ZRS-Konten (zonenredundanter Speicher) zugeordnet. Sie müssen Verfügbarkeitszonen für eine Region ihres Azure Cosmos DB-Datenbankkontos aktivieren, damit die Analysedaten dieser Region in einem zonenredundanten Speicher gespeichert werden können. Der ZRS bietet eine Dauerhaftigkeit für Speicherressourcen von mindestens 99,9999999999 % (12 mal die 9) über einen Zeitraum von einem Jahr.
Weitere Informationen zu Azure Storage-Dauerhaftigkeit finden Sie unter diesem Link.
Backup
Obwohl der Analysespeicher über einen integrierten Schutz vor physischen Ausfällen verfügt, kann eine Sicherung bei versehentlichen Lösch- oder Aktualisierungsvorgängen im Transaktionsspeicher erforderlich sein. In diesen Fällen können Sie einen Container wiederherstellen und den wiederhergestellten Container verwenden, um die Daten im ursprünglichen Container wieder aufzufüllen oder den Analysespeicher bei Bedarf vollständig neu zu erstellen.
Hinweis
Derzeit wird der analytische Speicher nicht gesichert, daher kann er nicht wiederhergestellt werden. Ihre Sicherungsrichtlinie kann nicht auf Grundlage dieses Speichers geplant werden.
Synapse Link und analytischer Speicher verfügt daher über unterschiedliche Kompatibilitätsstufen mit Azure Cosmos DB-Sicherungsmodi:
- Der Modus für regelmäßige Sicherungen ist vollständig kompatibel mit Synapse Link, und diese beiden Features können im selben Datenbankkonto verwendet werden.
- Synapse Link für Datenbankkonten mit fortlaufender Sicherung ist allgemein verfügbar.
- Der fortlaufende Sicherungsmodus für aktivierte Synapse-Link-Konten befindet sich in der öffentlichen Vorschau. Derzeit können Sie nicht auf fortlaufende Datensicherung umstellen, wenn Sie Synapse Link für eine Ihrer Sammlungen in einem Cosmos DB-Konto deaktiviert haben.
Sicherungsrichtlinien
Es gibt zwei mögliche Sicherungsrichtlinien, und zum Verständnis ihrer Verwendung sind die folgenden Details zu Azure Cosmos DB-Sicherungen sehr wichtig:
- Der ursprüngliche Container wird in beiden Sicherungsmodi ohne Analysespeicher wiederhergestellt.
- Azure Cosmos DB unterstützt keine Container, die von einer Wiederherstellung überschrieben werden.
Sehen wir uns nun an, wie Sie Sicherungen und Wiederherstellungen aus Sicht des Analysespeichers nutzen können.
Wiederherstellen eines Containers mit TTTL >= ATTL
Wenn transactional TTL größer oder gleich analytical TTL ist, sind alle Daten im Analysespeicher weiterhin im Transaktionsspeicher vorhanden. Bei einer Wiederherstellung gibt es zwei Möglichkeiten:
- Den wiederhergestellten Container als Ersatz für den ursprünglichen Container verwenden. Um den Analysespeicher neu zu erstellen, aktivieren Sie einfach Synapse Link auf Konto- und Containerebene.
- Den wiederhergestellten Container als Datenquelle verwenden, um die Daten im ursprünglichen Container wieder aufzufüllen oder zu aktualisieren. In diesem Fall spiegelt der Analysespeicher die Datenvorgänge automatisch wider.
Wiederherstellen eines Containers mit TTTL < ATTL
Wenn transactional TTL kleiner als analytical TTL ist, sind einige Daten nur im Analysespeicher vorhanden und befinden sich nicht im wiederhergestellten Container. Wiederum gibt es zwei Möglichkeiten:
- Den wiederhergestellten Container als Ersatz für den ursprünglichen Container verwenden. Wenn Sie in diesem Fall Synapse Link auf Containerebene aktivieren, werden nur die Daten, die sich im Transaktionsspeicher befanden, in den neuen Analysespeicher aufgenommen. Beachten Sie jedoch, dass der Analysespeicher des ursprünglichen Containers für Abfragen verfügbar bleibt, solange der ursprüngliche Container vorhanden ist. Möglicherweise sollten Sie Ihre Anwendung so ändern, dass beide abgefragt werden.
- Den wiederhergestellten Container als Datenquelle verwenden, um die Daten im ursprünglichen Container wieder aufzufüllen oder zu aktualisieren:
- Der Analysespeicher spiegelt automatisch die Datenvorgänge für die Daten wider, die sich im Transaktionsspeicher befinden.
- Wenn Sie Daten wieder einfügen, die zuvor aufgrund von
transactional TTLaus dem Transaktionsspeicher entfernt wurden, werden diese Daten im Analysespeicher dupliziert.
Beispiel:
- Für Container
OnlineOrdersist TTTL auf einen Monat und ATTL auf ein Jahr festgelegt. - Wenn Sie ihn als
OnlineOrdersNewwiederherstellen und den Analysespeicher für die Neuerstellung aktivieren, sind nur die Daten eines Monats im Transaktions- und Analysespeicher enthalten. - Der ursprüngliche Container
OnlineOrderswird nicht gelöscht, und sein Analysespeicher ist weiterhin verfügbar. - Neue Daten werden nur in
OnlineOrdersNewaufgenommen. - Analytische Abfragen führen einen UNION ALL-Vorgang aus Analysespeichern durch, wobei die ursprünglichen Daten weiterhin relevant sind.
Wenn Sie den ursprünglichen Container löschen, die enthaltenen Analysespeicherdaten aber nicht verlieren möchten, können Sie den Analysespeicher des ursprünglichen Containers in einem anderen Azure-Datendienst speichern. Synapse Analytics bietet die Möglichkeit, Verknüpfungen zwischen Daten an unterschiedlichen Speicherorten durchzuführen. Beispiel: Eine Synapse Analytics-Abfrage verknüpft Analysespeicherdaten mit externen Tabellen, die sich in Azure Blob Storage, Azure Data Lake Store usw. befinden.
Beachten Sie, dass die Daten im Analysespeicher ein anderes Schema als im Transaktionsspeicher aufweisen. Sie können zwar Momentaufnahmen Ihrer Analysespeicherdaten generieren und sie in einen beliebigen Azure-Datendienst exportieren, ohne dass Kosten für RUs entstehen, doch können wir nicht garantieren, dass anhand dieser Momentaufnahme eine Rückführung in den Transaktionsspeicher erfolgen kann. Dieser Vorgang wird nicht unterstützt.
Globale Verteilung
Wenn Sie über ein global verteiltes Azure Cosmos DB-Konto verfügen, ist es nach dem Aktivieren des Analysespeichers für einen Container in allen Regionen für dieses Konto verfügbar. Änderungen an operativen Daten werden in allen Regionen global repliziert. Sie können analytische Abfragen effektiv für die nächstgelegene regionale Kopie Ihrer Daten in Azure Cosmos DB ausführen.
Partitionierung
Die Partitionierung des Analysespeichers ist vollkommen unabhängig von der Partitionierung im Transaktionsspeicher. Daten im Analysespeicher sind standardmäßig nicht partitioniert. Wenn Ihre analytischen Abfragen häufig Filter verwenden, können Sie basierend auf diesen Feldern partitionieren, um die Abfrageleistung zu verbessern. Weitere Informationen finden Sie in der Einführung in die benutzerdefinierte Partitionierung und im Artikel zum Konfigurieren der benutzerdefinierten Partitionierung.
Sicherheit
Die Authentifizierung mit dem Analysespeicher erfolgt genauso, wie mit dem Transaktionsspeicher für eine bestimmte Datenbank. Sie können Primärschlüssel, sekundäre Schlüssel oder Schlüssel mit Leseberechtigung für die Authentifizierung verwenden. Sie können den verknüpften Dienst in Synapse Studio nutzen, um zu verhindern, dass die Azure Cosmos DB-Schlüssel in den Spark-Notebooks eingefügt werden. Für die serverlose Azure Synapse SQL können Sie die SQL Anmeldeinformationen verwenden, um auch das Einfügen der Azure Cosmos-Datenbankschlüssel in die SQL Notebooks zu verhindern. Der Zugriff auf diese verknüpften Dienste oder diese SQL-Anmeldeinformationen steht allen Personen zur Verfügung, die Zugriff auf den Arbeitsbereich haben. Beachten Sie, dass auch der schreibgeschützte Azure Cosmos DB-Schlüssel verwendet werden kann.
Netzwerkisolation mithilfe privater Endpunkte: Sie können den Netzwerkzugriff auf die Daten in den Transaktions- und Analysespeichern unabhängig voneinander steuern. Die Netzwerkisolation erfolgt über separate verwaltete private Endpunkte für jeden Speicher in verwalteten virtuellen Netzwerken in Azure Synapse-Arbeitsbereichen. Weitere Informationen finden Sie im Artikel Konfigurieren privater Endpunkte für den Analysespeicher.
Verschlüsselung ruhender Daten: Die Verschlüsselung Ihres analytischen Speichers ist standardmäßig aktiviert.
Datenverschlüsselung mit kundenseitig verwalteten Schlüsseln: Sie können Daten nahtlos im Transaktions- und Analysespeicher verschlüsseln und dabei die gleichen kundenseitig verwalteten Schlüssel automatisiert und transparent verwenden. Azure Synapse Link unterstützt nur das Konfigurieren von kundenseitig verwalteten Schlüsseln mithilfe der verwalteten Identität Ihres Azure Cosmos DB-Kontos. Sie müssen die verwaltete Identität Ihres Kontos in Ihrer Azure Key Vault-Zugriffsrichtlinie konfigurieren, bevor Sie den Azure Synapse Link für Ihr Konto aktivieren. Weitere Informationen finden Sie unter Konfigurieren von kundenseitig verwalteten Schlüsseln mithilfe verwalteter Identitäten eines Azure Cosmos DB-Kontos.
Hinweis
Wenn Sie Ihr Datenbankkonto von „Erstanbieter“ in „System- oder benutzerseitig zugewiesene Identität“ ändern und Azure Synapse Link in Ihrem Datenbankkonto aktivieren, können Sie nicht zur Erstanbieteridentität zurückkehren, da Sie Synapse Link über Ihr Datenbankkonto nicht deaktivieren können.
Unterstützung für mehrere Azure Synapse Analytics-Laufzeiten
Der Analysespeicher ist optimiert, um Skalierbarkeit, Elastizität und Leistung für Analyseworkloads ohne jegliche Abhängigkeit von den Computelaufzeiten bereitzustellen. Die Speichertechnologie ist selbst verwaltet, um Ihre Analyseworkloads ohne manuellen Aufwand zu optimieren.
Daten im Analysespeicher von Azure Cosmos DB könnten gleichzeitig aus den verschiedenen von Azure Synapse Analytics unterstützten Analyselaufzeiten abgefragt werden. Apache Spark und serverlose SQL-Pools mit Azure Cosmos DB-Analysespeicher werden von Azure Synapse Analytics unterstützt.
Hinweis
Sie können nur mithilfe der Azure Synapse Analytics-Laufzeiten aus dem Analysespeicher lesen. Umgekehrt können auch Azure Synapse Analytics-Laufzeiten nur aus dem Analysespeicher lesen. Nur der automatische Synchronisierungsprozess kann Daten im Analysespeicher ändern. Mithilfe des Spark-Pools in Azure Synapse Analytics können Sie Daten unter Verwendung des integrierten Azure Cosmos DB-OLTP-SDK in den Azure Cosmos DB-Transaktionsspeicher zurückschreiben.
Preise
Der Analysespeicher folgt einem nutzungsbasierten Preismodell, bei dem Folgendes in Rechnung gestellt wird:
Speicher: Die Menge an Daten, die im Analysespeicher pro Monat aufbewahrt werden, einschließlich Verlaufsdaten gemäß der analytischen Gültigkeitsdauer.
Analyseschreibvorgänge: Die vollständig verwaltete Synchronisierung von Aktualisierungen operativer Daten aus dem Transaktionsspeicher in den Analysespeicher (automatische Synchronisierung).
Analyselesevorgänge: Lesevorgänge, die für den Analysespeicher in Azure Synapse Analytics-Laufzeiten für Spark- und serverlose SQL-Pools ausgeführt werden.
Die Preise für den Analysespeicher sind vom Preismodell für den Transaktionsspeicher getrennt. Es gibt kein Konzept für bereitgestellte RUs im Analysespeicher. Ausführliche Informationen zum Preismodell für den Analysespeicher finden Sie auf der Azure Cosmos DB – Preisseite.
Auf Daten im Analysespeicher kann nur über Azure Synapse Link zugegriffen werden. Dies erfolgt in den Azure Synapse Analytics-Runtimes: Azure Synapse Apache Spark-Pools und Azure Synapse serverlose SQL-Pools. Ausführliche Informationen zum Preismodell für den Zugriff auf Daten im Analysespeicher finden Sie auf der Azure Synapse Analytics-Preisseite.
Wenn Sie eine allgemeine Kostenschätzung für das Aktivieren des Analysespeichers in einem Azure Cosmos DB-Container aus der Perspektive des Analysespeichers erhalten möchten, können Sie den Azure Cosmos DB Capacity Planner verwenden und so eine Schätzung der Kosten für den Analysespeicher und Analyseschreibvorgänge abrufen.
Schätzungen zu Lesevorgängen in Analysespeichern sind im Azure Cosmos DB-Kostenrechner nicht enthalten, da sie eine Funktion Ihrer analytischen Workload sind. Doch als grobe Schätzung führt das Scannen von 1 TB Daten im Analysespeicher in der Regel zu 130.000 Analyselesevorgängen und somit zu Kosten von 0,065 US-Dollar. Wenn Sie beispielsweise serverlose SQL-Pools in Azure Synapse für das Scannen von 1 TB nutzen, kostet dies gemäß der Azure Synapse Analytics-Preisseite 5,00 US-Dollar. Die endgültigen Gesamtkosten für diesen Scann von 1 TB betragen 5,065 US-Dollar.
Während die obige Schätzung für das Scannen von 1 TB Daten im Analysespeicher gilt, reduziert das Anwenden von Filtern die Menge gescannter Daten, und dies bestimmt die genaue Anzahl analytischer Lesevorgänge gemäß des nutzungsbasierten Preismodells. Ein Proof of Concept für die analytische Workload bietet einen exakteren Schätzwert der Anzahl analytischer Lesevorgänge. Diese Schätzung enthält nicht die Kosten für Azure Synapse Analytics.
Nächste Schritte
Weitere Informationen finden Sie in den folgenden Dokumenten:
Sehen Sie sich das Trainingsmodul zum Entwerfen der hybriden transaktionalen und analytischen Verarbeitung mithilfe von Azure Synapse Analytics an.
Häufig gestellte Fragen zu Azure Synapse Link für Azure Cosmos DB