Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Kassandra
Kassandra ![]() Kobold
Kobold ![]() Tabelle
Tabelle
Azure Cosmos DB ist eine schemaunabhängige Datenbank, die es Ihnen ermöglicht, Ihre Anwendung zu durchlaufen, ohne sich mit Schema- oder Indexverwaltung befassen zu müssen. Standardmäßig indiziert Azure Cosmos DB automatisch alle Eigenschaften für sämtliche Elemente in Ihrem Container, ohne dass ein Schema definiert oder Sekundärindizes konfiguriert werden müssen.
In diesem Artikel wird beschrieben, wie Azure Cosmos DB Daten indiziert und wie Indizes zur Verbesserung der Abfrageleistung verwendet werden. Sie sollten zunächst diesen Abschnitt lesen, bevor Sie sich mit dem Anpassen von Indizierungsrichtlinien beschäftigen.
Von Elementen zu Strukturen
Bei jedem Speichern eines Elements in einem Container wird dessen Inhalt als ein JSON-Dokument projiziert und anschließend in eine strukturierte Darstellung konvertiert. Diese Konvertierung bedeutet, dass jede Eigenschaft dieses Elements als Knoten in einer Struktur dargestellt wird. Als übergeordnetes Element für alle Eigenschaften auf oberster Ebene des Elements wird ein Pseudostammknoten erstellt. Die Blattknoten enthalten die eigentlichen Skalarwerte eines Elements.
Betrachten Sie z. B. dieses Element:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Diese Struktur stellt das JSON-Beispielelement dar:
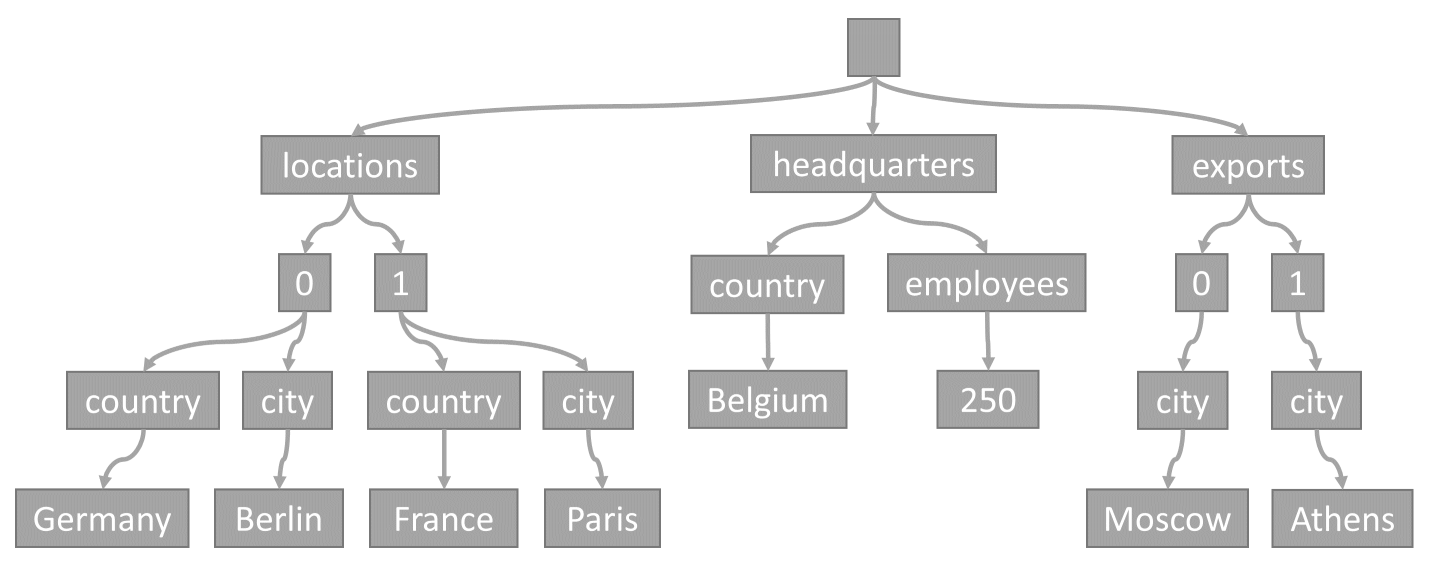
Beachten Sie, wie Arrays in der Struktur codiert werden: Jeder Eintrag in einem Array erhält direkt einen Zwischenknoten, der mit dem Index dieses Eintrags innerhalb des Arrays bezeichnet ist (0, 1 usw.).
Von Strukturen zu Eigenschaftenpfaden
Der Grund, warum Azure Cosmos DB Elemente in Strukturen transformiert, liegt darin, dass dies dem System ermöglicht, Eigenschaften anhand ihrer Pfade innerhalb dieser Strukturen zu referenzieren. Um den Pfad für eine Eigenschaft abzurufen, können Sie die Struktur vom Stammknoten aus bis zu dieser Eigenschaft durchlaufen. Verketten Sie dabei die Bezeichnungen aller durchlaufenen Knoten.
Dies sind die Pfade für jede Eigenschaft aus dem zuvor beschriebenen Beispielelement:
/locations/0/country: „Deutschland“/locations/0/city: „Berlin“/locations/1/country: „Frankreich“/locations/1/city: „Paris“/headquarters/country: „Belgien“/headquarters/employees: 250/exports/0/city: „Moskau“/exports/1/city: „Athen“
Azure Cosmos DB indiziert effektiv den Pfad jeder Eigenschaft und ihren entsprechenden Wert, wenn ein Element geschrieben wird.
Indextypen
Azure Cosmos DB unterstützt derzeit drei Typen von Indizes. Sie können diese Indextypen beim Definieren der Indizierungsrichtlinie konfigurieren.
Bereichsindex
Die Bereichsindizes basieren auf einer geordneten baumähnlichen Struktur. Dieser Indextyp wird für Folgendes verwendet:
Gleichheitsabfragen:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Gleichheitsübereinstimmung für ein Arrayelement
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Bereichsabfragen:
SELECT * FROM container c WHERE c.property > 'value'Hinweis
(funktioniert für
>,<,>=,<=,!=)Überprüfen, ob eine Eigenschaft vorhanden ist:
SELECT * FROM c WHERE IS_DEFINED(c.property)Zeichenfolgensystemfunktionen:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYfragt Folgendes ab:SELECT * FROM container c ORDER BY c.propertyJOINfragt Folgendes ab:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Range-Indizes können für Skalarwerte (Zeichenfolge oder Zahl) verwendet werden. Die standardmäßige Indizierungsrichtlinie für neu erstellte Container erzwingt Bereichsindizes für jede Zeichenfolge oder Zahl. Weitere Informationen zum Konfigurieren von Bereichsindizes finden Sie unter den Beispielrichtlinien für Bereichsindizes.
Hinweis
Eine ORDER BY-Klausel, die anhand einer einzelnen Eigenschaft geordnet wird, benötigt immer einen Range-Index. Falls der referenzierte Pfad diesen nicht aufweist, tritt ein Fehler auf. Ebenso benötigt eine ORDER BY-Abfrage, die nach mehreren Eigenschaften sortiert, immer einen zusammengesetzten Index.
Räumlicher Index
Räumliche Indizes ermöglichen effiziente Abfragen räumlicher Objekte wie Punkte, Linien, Polygone und Multipolygon. Diese Abfragen verwenden die Schlüsselwörter ST_DISTANCE, ST_WITHIN und ST_INTERSECTS. Im Folgenden finden Sie einige Beispiele für die Verwendung des räumlichen Indextyps:
Abfragen zum räumlichen Abstand:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Räumliche Abfragen:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Abfragen zur räumlichen Überschneidung:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Spatial-Indizes können für ordnungsgemäß formatierte GeoJSON-Objekte verwendet werden. Derzeit werden Point, LineString, Polygon und MultiPolygon unterstützt. Weitere Informationen zum Konfigurieren von räumlichen Indizes finden Sie in den Beispielrichtlinien für räumliche Indizes.
Zusammengesetzte Indizes
Zusammengesetzte Indizes erhöhen die Effizienz, wenn Sie Vorgänge für mehrere Felder durchführen. Dieser Indextyp wird für Folgendes verwendet:
ORDER BYfragt mehrere Eigenschaften ab:SELECT * FROM container c ORDER BY c.property1, c.property2Abfragen mit einem Filter und
ORDER BY. Diese Abfragen können einen zusammengesetzten Index verwenden, wenn die Filter-Eigenschaft derORDER BY-Klausel hinzugefügt wird.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Abfragen mit einem Filter für zwei oder mehr Eigenschaften, bei denen mindestens eine Eigenschaft ein Gleichheitsfilter ist
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Solange ein einziges Filterprädikat einen der Indextypen verwendet, wertet die Abfrage-Engine dieses zuerst aus, bevor der Rest überprüft wird. Wenn Sie z.B. eine SQL-Abfrage haben wie SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Bei der oben gezeigten Abfrage wird zuerst mithilfe des Index nach Einträgen gefiltert, bei denen „firstName“ den Wert „Andrew“ hat. Anschließend werden alle Einträge mit „firstName“ = „Andrew“ über eine nachfolgende Pipeline übergeben, um das Filterprädikat CONTAINS auszuwerten.
Sie können Abfragen beschleunigen und vollständige Containerscans vermeiden, wenn Sie Funktionen verwenden, die eine vollständige Überprüfung wie CONTAINS durchführen. Sie können weitere Filterprädikate hinzufügen, die den Index verwenden, um diese Abfragen zu beschleunigen. Die Reihenfolge der Filterklauseln ist nicht von Bedeutung. Die Abfrage-Engine ermittelt, welche Prädikate selektiver sind, und führt die Abfrage entsprechend aus.
Weitere Informationen zum Konfigurieren von zusammengesetzten Indizes finden Sie in den Beispielrichtlinien für zusammengesetzte Indizes.
Vektorindizes
Vektorindizes erhöhen die Effizienz beim Ausführen von Vektorsuchen mithilfe der VectorDistance-Systemfunktion. Vektorsuchvorgänge haben bei der Nutzung eines Vektorindizes eine deutlich geringere Wartezeit, einen höheren Durchsatz und einen geringeren RU-Verbrauch. Azure Cosmos DB für NoSQL unterstützt alle Vektoreinbettungen (Text, Bild, multimodal usw.) unter 4096 Dimensionen.
Informationen zum Konfigurieren von Vektorindizes finden Sie unter Beispiele für Vektorindizierungsrichtlinien.
ORDER BY-Vektorsuchabfragen:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Projektion der Ähnlichkeitsbewertung in Vektorsuchabfragen:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Bereichsfilter für die Ähnlichkeitsbewertung
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Wichtig
Derzeit sind Vektorrichtlinien und Vektorindizes nach der Erstellung unveränderlich. Um Änderungen vorzunehmen, erstellen Sie eine neue Sammlung.
Indexnutzung
Es gibt fünf Möglichkeiten, wie die Abfrage-Engine Abfragefilter auswerten kann. Diese sind hier in absteigender Reihenfolge von der effizientesten zu der am wenigsten effizienten aufgelistet:
- Indexsuche
- Genauer Indexscan
- Erweiterter Indexscan
- Vollständiger Indexscan
- Vollständige Überprüfung
Wenn Sie Eigenschaftenpfade indizieren, verwendet die Abfrage-Engine den Index automatisch so effizient wie möglich. Abgesehen von der Indizierung neuer Eigenschaftenpfade müssen Sie keine Konfigurationen durchführen, um die Verwendung des Index durch Abfragen zu optimieren. Die RU-Gebühr einer Abfrage setzt sich aus der RU-Gebühr für die Indexnutzung und der RU-Gebühr für das Laden von Elementen zusammen.
In der folgenden Tabelle werden die verschiedenen Verwendungsmöglichkeiten von Indizes in Azure Cosmos DB zusammengefasst:
| Indexsuchtyp | BESCHREIBUNG | Typische Beispiele | RU-Gebühr für die Indexnutzung | RU-Gebühr für das Laden von Elementen aus dem Transaktionsdatenspeicher |
|---|---|---|---|---|
| Indexsuche | Lesen nur erforderlicher indizierter Werte und Laden nur übereinstimmender Elemente aus dem Transaktionsdatenspeicher | Gleichheitsfilter, IN | Konstant pro Gleichheitsfilter | Erhöht sich basierend auf der Anzahl von Elementen in Abfrageergebnissen |
| Genauer Indexscan | Binärsuche indizierter Werte und Laden nur übereinstimmender Elemente aus dem Transaktionsdatenspeicher | Bereichsvergleiche (>, <, <=, oder >=), StartsWith | Vergleichbar mit Indexsuche, erhöht sich leicht basierend auf der Kardinalität indizierter Eigenschaften | Erhöht sich basierend auf der Anzahl von Elementen in Abfrageergebnissen |
| Erweiterter Indexscan | Optimierte Suche (jedoch weniger effizient als Binärsuche) indizierter Werte und Laden nur übereinstimmender Elemente aus dem Transaktionsdatenspeicher | StartsWith (ohne Berücksichtigung der Groß-/Kleinschreibung), StringEquals (ohne Berücksichtigung der Groß-/Kleinschreibung) | Erhöht sich leicht basierend auf der Kardinalität indizierter Eigenschaften | Erhöht sich basierend auf der Anzahl von Elementen in Abfrageergebnissen |
| Vollständiger Indexscan | Lesen eines eindeutigen Satzes indizierter Werte und Laden nur übereinstimmender Elemente aus dem Transaktionsdatenspeicher | Contains, EndsWith, RegexMatch, LIKE | Erhöht sich linear basierend auf der Kardinalität indizierter Eigenschaften | Erhöht sich basierend auf der Anzahl von Elementen in Abfrageergebnissen |
| Vollständige Überprüfung | Laden aller Elemente aus dem Transaktionsdatenspeicher | Oben, unten | – | Erhöht sich basierend auf der Anzahl von Elementen im Container |
Beim Schreiben von Abfragen sollten Sie Filterprädikate verwenden, die den Index so effizient wie möglich nutzen. Wenn z. B. StartsWith oder Contains für Ihren Anwendungsfall geeignet ist, sollten Sie StartsWith auswählen, da hiermit statt eines vollständigen Indexscans ein präziser Indexscan durchgeführt wird.
Details zur Indexnutzung
Dieser Abschnitt enthält weitere Details dazu, wie Indizes von Abfragen genutzt werden. Dieser Detailgrad ist zwar für die ersten Schritte mit Azure Cosmos DB nicht erforderlich, wird hier aber für interessierte Benutzer ausführlich dokumentiert. Dazu das bereits zuvor in diesem Dokument verwendete Beispielelement genutzt:
Beispielelemente:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB verwendet einen invertierten Index. Der Index ordnet jeden JSON-Pfad dem Satz von Elementen zu, die diesen Wert enthalten. Die Element-ID-Zuordnung wird auf vielen verschiedenen Indexseiten für den Container dargestellt. Hier sehen Sie eine Beispielabbildung eines invertierten Index für einen Container, der die beiden Beispielelemente enthält:
| Pfad | Wert | Liste der Element-IDs |
|---|---|---|
| /locations/0/country | Deutschland | 1 |
| /locations/0/country | Irland | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Frankreich | 1 |
| /locations/1/city | Paris | 1 |
| /hauptsitz/land | Belgien | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
Der invertierte Index verfügt über zwei wichtige Attribute:
- Werte werden für einen bestimmten Pfad in aufsteigender Reihenfolge sortiert. Daher kann die Abfrage-Engine
ORDER BYproblemlos über den Index bedienen. - Die Abfrage-Engine kann für einen bestimmten Pfad den eindeutigen Satz möglicher Werte durchsuchen, um die Indexseiten zu ermitteln, die Ergebnisse enthalten.
Die Abfrage-Engine kann den invertierten Index auf vier verschiedene Arten nutzen:
Indexsuche
Betrachten Sie die folgende Abfrage:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Das Abfrageprädikat (nach Elementen filtern, die an beliebiger Stelle „France“ als Land oder Region enthalten) würde dem hervorgehobenen Pfad in dieser Abbildung entsprechen:
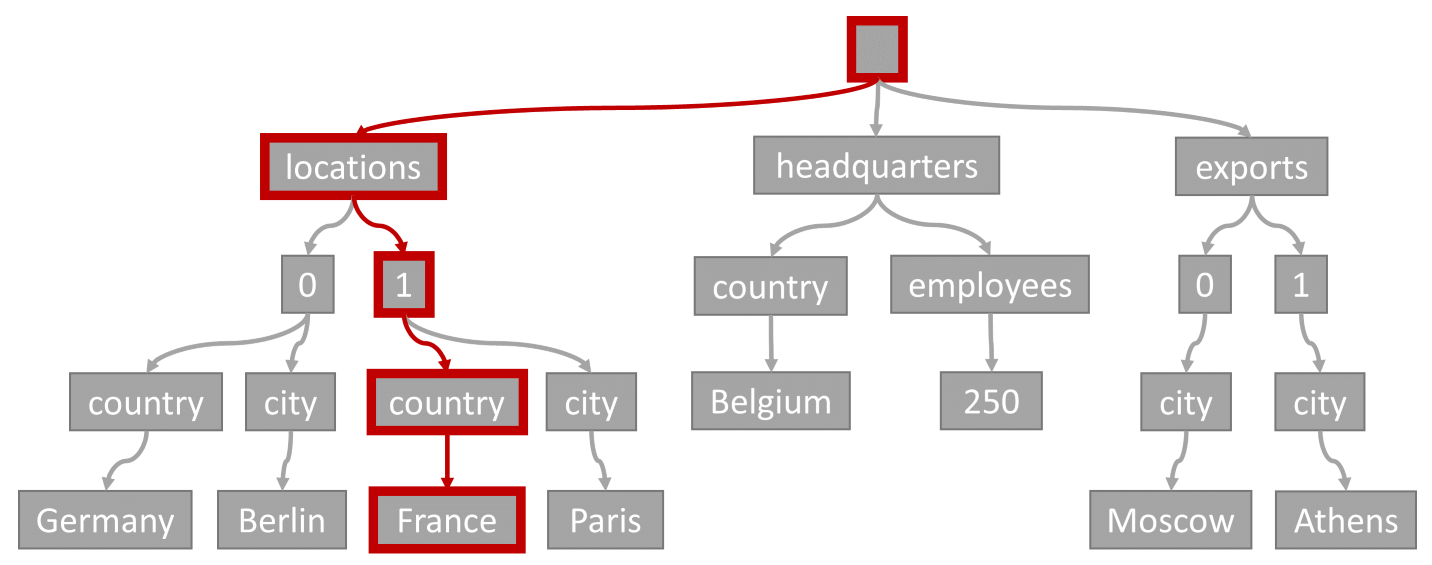
Da diese Abfrage einen Gleichheitsfilter aufweist, können nach dem Durchlaufen dieser Struktur die Indexseiten, die die Abfrageergebnisse enthalten, schnell ermittelt werden. In diesem Fall liest die Abfrage-Engine Indexseiten, die Element 1 enthalten. Eine Indexsuche ist die effizienteste Möglichkeit zur Verwendung des Indexes. Bei einer Indexsuche werden nur die erforderlichen Indexseiten gelesen und nur die Elemente in den Abfrageergebnissen geladen. Daher sind der Zeitaufwand und die RU-Gebühr für die Indexsuche äußerst niedrig und zwar unabhängig vom Gesamtdatenvolumen.
Genauer Indexscan
Betrachten Sie die folgende Abfrage:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Das Abfrageprädikat (Filtern nach Elementen mit mehr als 200 Mitarbeitern) kann mit einem präzisen Indexscan des Pfads headquarters/employees ausgewertet werden. Bei einem präzisen Indexscan führt die Abfrage-Engine zuerst eine Binärsuche nach dem eindeutigen Satz möglicher Werte durch, um den Speicherort des Werts 200 für den Pfad headquarters/employees zu finden. Da die Werte für jeden Pfad in aufsteigender Reihenfolge sortiert sind, kann die Abfrage-Engine ganz einfach eine Binärsuche durchführen. Nachdem die Abfrage-Engine den Wert 200 gefunden hat, beginnt sie mit dem Lesen aller verbleibenden Indexseiten (in aufsteigender Reihenfolge).
Da die Abfrage-Engine eine Binärsuche durchführen kann, um das Überprüfen unnötiger Indexseiten zu vermeiden, weisen präzise Indexscans in der Regel eine vergleichbare Latenz und ähnliche RU-Gebühren wie Indexsuchvorgänge auf.
Erweiterter Indexscan
Betrachten Sie die folgende Abfrage:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Das Abfrageprädikat (Filtern nach Elementen mit Hauptsitz an einem Standort, der mit „United“ unter Beachtung der Groß-/Kleinschreibung beginnt) kann mit einem erweiterten Indexscan des Pfads headquarters/country ausgewertet werden. Vorgänge, die einen erweiterten Indexscan durchführen, verfügen über Optimierungen, mit denen vermieden werden kann, dass jede Indexseite überprüft werden muss, doch sind sie etwas teurer als die Binärsuche bei einem präzisen Indexscan.
Wenn z. B. StartsWith ohne Beachtung der Groß-/Kleinschreibung ausgewertet wird, überprüft die Abfrage-Engine den Index auf verschiedene mögliche Kombinationen aus Groß- und Kleinbuchstaben. Durch diese Optimierung kann die Abfrage-Engine das Lesen der meisten Indexseiten vermeiden. Verschiedene Systemfunktionen weisen unterschiedliche Optimierungen auf, mit denen das Lesen jeder Indexseite vermieden werden kann. Daher werden diese im Allgemeinen als erweiterter Indexscan kategorisiert.
Vollständiger Indexscan
Betrachten Sie die folgende Abfrage:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Das Abfrageprädikat (Filtern nach Elementen mit Hauptsitz an einem Standort, der „United“ enthält) kann mit einem Indexscan des Pfads headquarters/country ausgewertet werden. Im Gegensatz zu einem präzisen Indexscan wird bei einem vollständigen Indexscan immer der eindeutige Satz möglicher Werte überprüft, um die Indexseiten zu ermitteln, die Ergebnisse enthalten. In diesem Fall wird Contains für den Index ausgeführt. Der Zeitaufwand und die RU-Gebühr für Indexscans steigen mit zunehmender Kardinalität des Pfads. Anders ausgedrückt: Je mehr mögliche eindeutige Werte von der Abfrage-Engine überprüft werden müssen, desto höher sind Latenz und RU-Gebühr für einen vollständigen Indexscan.
Sehen Sie sich beispielsweise die beiden Eigenschaften town und country an. Die Kardinalität von „town“ ist 5.000, die Kardinalität von country ist 200. Hier sehen Sie zwei Beispielabfragen, die jeweils eine Systemfunktion Contains aufweisen, durch die ein Indexscan für die Eigenschaft town vollständig durchgeführt wird. Die erste Abfrage verbraucht mehr RUs als die zweite Abfrage, da die Kardinalität von „town“ höher als die von country ist.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Vollständige Überprüfung
In einigen Fällen ist die Abfrage-Engine möglicherweise nicht in der Lage, einen Abfragefilter mithilfe des Indexes auszuwerten. In diesem Fall muss die Abfrage-Engine alle Elemente aus dem Transaktionsspeicher laden, um den Abfragefilter auszuwerten. Vollständige Überprüfungen verwenden nicht den Index und weisen eine RU-Gebühr auf, die linear mit der Gesamtdatengröße zunimmt. Glücklicherweise kommen Vorgänge, die vollständige Überprüfungen erfordern, nur selten vor.
Vektorsuchabfragen ohne definierten Vektorindex
Wenn Sie keine Vektorindexrichtlinie definieren und die VectorDistance-Systemfunktion in einer ORDER BY-Klausel verwenden, führt dies zu einer vollständigen Überprüfung und hat eine höhere RU-Belastung, wie wenn Sie eine Vektorindexrichtlinie definiert haben. Wenn Sie VectorDistance mit dem booleschen Brute-Force-Wert verwenden, der auf true festgelegt ist, und keinen flat-Index für den Vektorpfad definiert haben, wird eine vollständige Überprüfung durchgeführt.
Abfragen mit komplexen Filterausdrücken
In den vorherigen Beispielen wurden nur Abfragen mit einfachen Filterausdrücken berücksichtigt (z. B. Abfragen mit nur einem Gleichheits- oder Bereichsfilter). In Wirklichkeit weisen die meisten Abfragen wesentlich komplexere Filterausdrücke auf.
Betrachten Sie die folgende Abfrage:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Zum Ausführen dieser Abfrage muss die Abfrage-Engine eine genaue Indexsuche für headquarters/employees und einen vollständigen Indexscan für headquarters/country ausführen. Die Abfrage-Engine weist eine interne Heuristik auf, die für eine möglichst effiziente Auswertung des Abfragefilterausdrucks genutzt wird. In diesem Fall würde die Abfrage-Engine das Lesen unnötiger Indexseiten vermeiden, indem zuerst eine Indexsuche ausgeführt wird. Wenn beispielsweise nur 50 Elemente dem Gleichheitsfilter entsprechen, muss die Abfrage-Engine nur Contains auf den Indexseiten auswerten, die diese 50 Elemente enthalten. Ein vollständiger Indexscan des gesamten Containers wäre nicht erforderlich.
Indexnutzung für skalare Aggregatfunktionen
Abfragen mit Aggregatfunktionen müssen ausschließlich auf dem Index basieren, um diesen zu verwenden.
In einigen Fällen kann der Index falsch positive Ergebnisse zurückgeben. Wenn z. B. Contains für den Index ausgewertet wird, kann die Anzahl der Übereinstimmungen im Index die Anzahl der Abfrageergebnisse übersteigen. Die Abfrage-Engine lädt dann alle Indexergebnisse, wertet den Filter für die geladenen Elemente aus und gibt nur die richtigen Ergebnisse zurück.
Bei den meisten Abfragen hat das Laden falsch positiver Indexergebnisse keine spürbaren Auswirkungen auf die Indexauslastung.
Betrachten Sie beispielsweise die folgende Abfrage:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Die Systemfunktion Contains gibt möglicherweise einige falsch positive Übereinstimmungen zurück, sodass die Abfrage-Engine überprüfen muss, ob jedes geladene Element dem Filterausdruck entspricht. In diesem Beispiel muss die Abfrage-Engine möglicherweise nur einige zusätzliche Elemente laden, sodass die Auswirkungen auf die Indexauslastung und die RU-Gebühr minimal sind.
Abfragen mit Aggregatfunktionen müssen jedoch ausschließlich auf dem Index basieren, um diesen zu verwenden. Betrachten Sie beispielsweise die folgende Abfrage mit einem Count-Aggregat:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Wie im ersten Beispiel gibt die Systemfunktion Contains möglicherweise einige falsch positive Übereinstimmungen zurück. Im Gegensatz zur SELECT *-Abfrage kann die Count-Abfrage jedoch nicht den Filterausdruck für die geladenen Elemente auswerten, um alle Indexergebnisse zu überprüfen. Die Count-Abfrage muss ausschließlich auf dem Index basieren. Wenn also die Möglichkeit besteht, dass ein Filterausdruck falsch positive Übereinstimmungen zurückgibt, greift die Abfrage-Engine auf eine vollständige Überprüfung zurück.
Abfragen mit den folgenden Aggregatfunktionen müssen ausschließlich auf dem Index basieren, sodass die Auswertung einiger Systemfunktionen eine vollständige Überprüfung erfordert.
Nächste Schritte
Weitere Informationen zur Indizierung erhalten Sie in den folgenden Artikeln: