Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Azure Cosmos DB für PostgreSQL wird für neue Projekte nicht mehr unterstützt. Verwenden Sie diesen Dienst nicht für neue Projekte. Verwenden Sie stattdessen einen der folgenden beiden Dienste:
Verwenden Sie für hochskalige Szenarien eine verteilte Datenbanklösung mit Azure Cosmos DB für NoSQL, die ein 99,999%iges Verfügbarkeits-Service-Level-Agreement (SLA), eine sofortige Autoskalierung und ein automatisches regionenübergreifendes Failover bietet.
Verwenden Sie die Elastic Clusters-Funktion von Azure Database for PostgreSQL für geshartete PostgreSQL-Datenbanken mithilfe der Open-Source-Erweiterung Citus.
Zusammenstellen bedeutet, verwandte Informationen zusammen auf denselben Knoten zu speichern. Abfragen können schnell erfolgen, wenn alle erforderlichen Daten ohne Netzwerkdatenverkehr verfügbar sind. Durch das Zusammenstellen verwandter Daten auf unterschiedlichen Knoten können Abfragen effizient parallel auf den einzelnen Knoten ausgeführt werden.
Datenzusammenstellung für Tabellen mit Hashverteilung
In Azure Cosmos DB for PostgreSQL wird eine Zeile in einem Shard gespeichert, wenn der Hashwert des Werts in der Verteilungsspalte innerhalb des Hashbereichs des Shards liegt. Shards mit gleichem Hash-Bereich werden immer auf demselben Knoten platziert. Zeilen mit identischen Werten in der Verteilungsspalte werden tabellenübergreifend immer auf demselben Knoten platziert. Das Konzept der Tabellen mit Hashverteilung ist auch bekannt als zeilenbasiertes Sharding. Beim schemabasierten Sharding werden Tabellen innerhalb eines verteilten Schemas immer zusammengestellt.

Ein praktisches Beispiel für Colocation
Betrachten Sie die folgenden Tabellen, die ggf. Bestandteil einer mehrinstanzenfähigen SaaS für Webanalysen sind:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Jetzt wollen wir die Abfragen beantworten, die möglicherweise von einem vom Kunden genutzten Dashboard ausgegeben werden. Eine Beispielabfrage könnte wie folgt lauten: „Zurückgegeben werden soll die Anzahl der Besuche in der letzten Woche für alle Seiten, die bei Mandant 6 mit „/Blog“ beginnen.“
Würden sich die Daten auf einem einzelnen PostgreSQL-Server befinden, könnten wir die Abfrage ganz einfach mit dem umfassenden Satz relationaler Operationen, die von SQL angeboten werden, ausdrücken:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Solange der Arbeitssatz für diese Abfrage in den Arbeitsspeicher passt, ist eine Einzelservertabelle eine geeignete Lösung. Es gibt jedoch auch Möglichkeiten der Skalierung des Datenmodells mit Azure Cosmos DB for PostgreSQL.
Tabellen nach ID verteilen
Einzelserverabfragen werden mit zunehmender Anzahl von Mandanten und der für jeden Mandanten gespeicherten Datenmenge langsamer. Der Arbeitssatz hat keinen Platz mehr im Arbeitsspeicher, und die CPU wird zum Engpass.
In diesem Fall können wir die Daten mithilfe von Azure Cosmos DB for PostgreSQL über viele Knoten aufteilen (Sharding). Die erste und wichtigste Entscheidung, die wir beim Sharding treffen müssen, bezieht sich auf die Verteilungsspalte. Beginnen wir mit einer harmlosen Auswahl von event_id für die Ereignistabelle und page_id für die page-Tabelle:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Wenn Daten auf verschiedene Worker verteilt sind, können wir keine Verknüpfung wie auf einem einzelnen PostgreSQL-Knoten vornehmen. Stattdessen müssen wir zwei Abfragen ausgeben:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Anschließend müssen die Ergebnisse aus den beiden Schritten von der Anwendung kombiniert werden.
Beim Ausführen der Abfragen müssen die Daten in den über die Knoten verteilten Shards einbezogen werden.
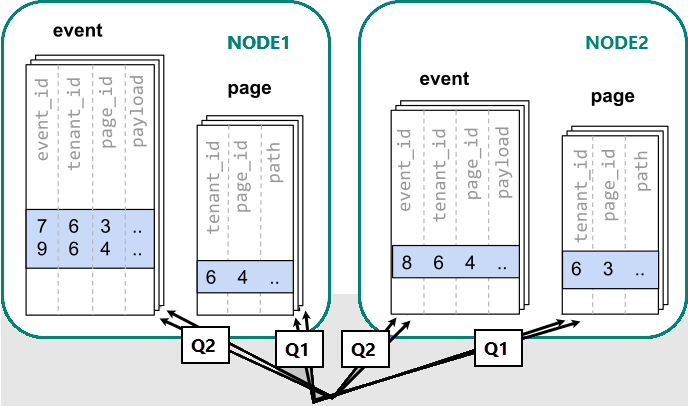
In diesem Fall führt die Verteilung der Daten zu erheblichen Nachteilen:
- Mehraufwand durch die Abfrage jedes Shards und das Ausführen mehrerer Abfragen.
- Mehraufwand bei der ersten Abfrage (Q1), die viele Zeilen an den Client zurückgibt.
- Q2 wird sehr groß.
- Die Notwendigkeit, Abfragen in mehreren Schritten zu schreiben, setzt Änderungen an der Anwendung voraus.
Die Daten sind verteilt, sodass Abfragen parallelisiert werden können. Dies ist nur von Nutzen, wenn der Arbeitsaufwand, den die Abfrage übernimmt, erheblich größer als der Mehraufwand durch die Abfrage vieler Shards ist.
Verteilen von Tabellen nach Mandant
In Azure Cosmos DB for PostgreSQL befinden sich Zeilen mit dem gleichen Wert in der Verteilungsspalte garantiert auf demselben Knoten. Wenn wir noch einmal von vorn beginnen, können wir unsere Tabellen mit tenant_id als Verteilungsspalte erstellen.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Jetzt kann Azure Cosmos DB for PostgreSQL die ursprüngliche Einzelserverabfrage ohne Änderung beantworten (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Aufgrund des Filters und der Verknüpfung durch „tenant_id“ weiß Azure Cosmos DB for PostgreSQL, dass die gesamte Abfrage mithilfe der Gruppe zusammengestellter Shards beantwortet werden kann, welche die Daten für diesen speziellen Mandanten enthalten. Ein einzelner PostgreSQL-Knoten kann die Abfrage in einem Schritt beantworten.
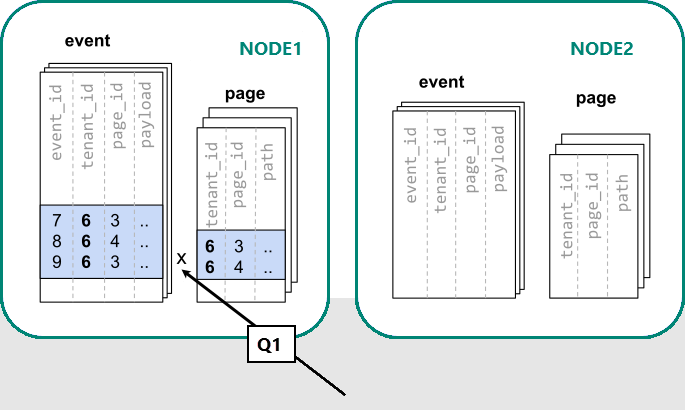
In einigen Fällen müssen Abfragen und Tabellenschemas geändert werden, um die Mandanten-ID in eindeutige Einschränkungen und Verknüpfungsbedingungen einzubeziehen. Diese Änderung ist in der Regel unkompliziert.
Nächste Schritte
- Informationen zum Zusammenstellen von Mandantendaten finden Sie im Tutorial zum Verwenden mehrerer Mandanten.