Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Azure Cosmos DB für PostgreSQL wird für neue Projekte nicht mehr unterstützt. Verwenden Sie diesen Dienst nicht für neue Projekte. Verwenden Sie stattdessen einen der folgenden beiden Dienste:
Verwenden Sie für hochskalige Szenarien eine verteilte Datenbanklösung mit Azure Cosmos DB für NoSQL, die ein 99,999%iges Verfügbarkeits-Service-Level-Agreement (SLA), eine sofortige Autoskalierung und ein automatisches regionenübergreifendes Failover bietet.
Verwenden Sie die Elastic Clusters-Funktion von Azure Database for PostgreSQL für geshartete PostgreSQL-Datenbanken mithilfe der Open-Source-Erweiterung Citus.
Bevor wir die Schritte zum Erstellen einer neuen App untersuchen, ist es hilfreich, einen schnellen Überblick über die betreffenden Begriffe und Konzepte zu erhalten.
Übersicht über die Architektur
Azure Cosmos DB for PostgreSQL bietet Ihnen die Möglichkeit, Tabellen und/oder Schemas auf mehreren Computern in einem Cluster zu verteilen und diese transparent abzufragen, wie Sie auch einfaches PostgreSQL abfragen:
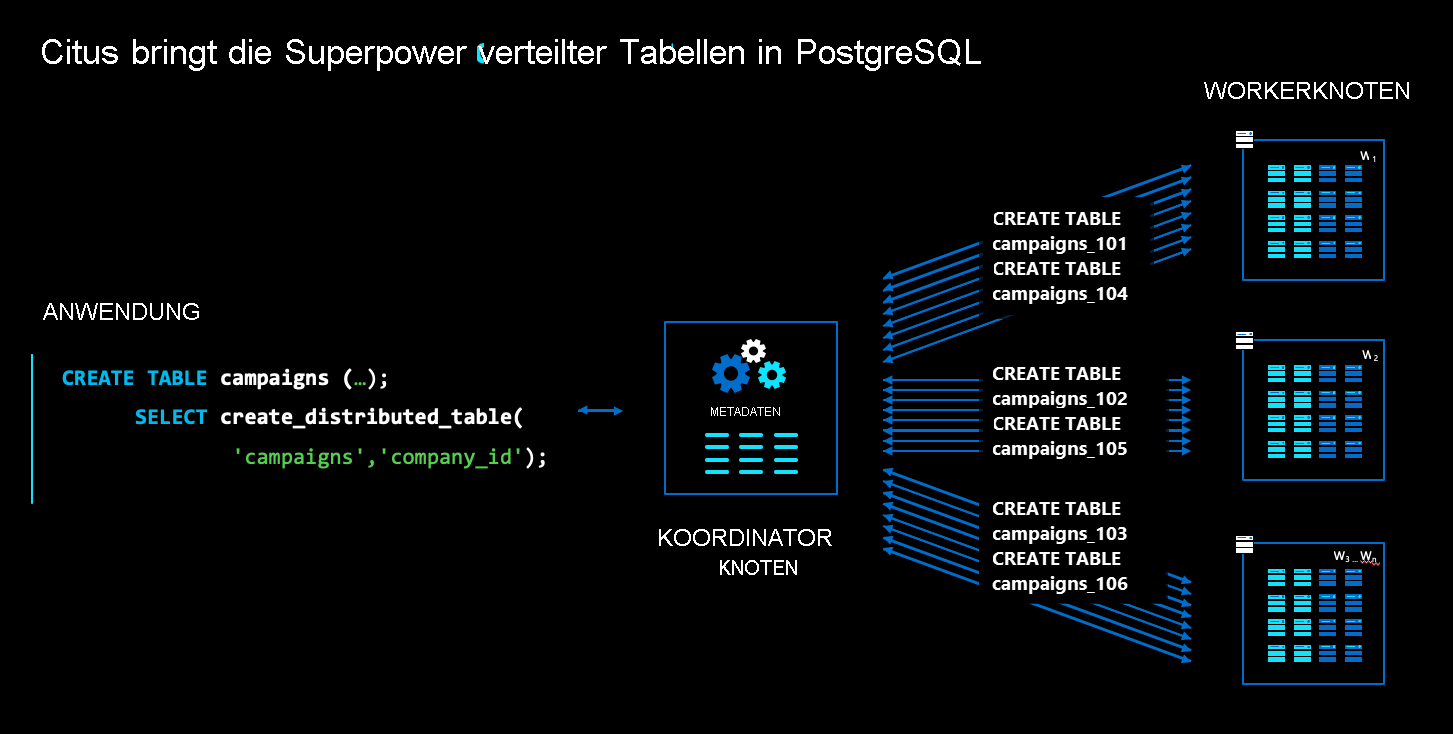
In der Azure Cosmos DB for PostgreSQL-Architektur gibt es mehrere Arten von Knoten:
- Der Koordinatorknoten speichert verteilte Tabellenmetadaten und ist für die verteilte Planung verantwortlich.
- Im Gegensatz dazu speichern die Workerknoten die tatsächlichen Daten und Metadaten und führen die Berechnung aus.
- Sowohl der Koordinator als auch die Worker sind einfache PostgreSQL-Datenbanken, wobei die
citus-Erweiterung geladen wurde.
Um eine normale PostgreSQL-Tabelle wie campaigns im obigen Diagramm zu verteilen, führen Sie einen Befehl aus, der create_distributed_table() genannt wird. Nachdem Sie diesen Befehl ausgeführt haben, erstellt Azure Cosmos DB for PostgreSQL transparent Shards für die Tabelle über Workerknoten hinweg. Im Diagramm werden Shards als blaue Felder dargestellt.
Führen Sie den Befehl citus_schema_distribute() aus, um ein normales PostgreSQL-Schema zu verteilen. Nachdem Sie diesen Befehl ausgeführt haben, wandelt Azure Cosmos DB for PostgreSQL Tabellen in solchen Schemas transparent in zusammengestellte Tabellen mit einem einzelnen Shard um, die als Einheit zwischen den Knoten des Clusters verschoben werden können.
Hinweis
In einem Cluster ohne Workerknoten befinden sich Shards von verteilten Tabellen auf dem Koordinatorknoten.
Shards sind einfache (aber speziell benannte) PostgreSQL-Tabellen, die Datensegmente enthalten. In unserem Beispiel, weil wir campaigns mit company_id verteilt haben, enthalten die Shards Kampagnen, wobei die Kampagnen verschiedener Unternehmen verschiedenen Shards zugewiesen werden.
Verteilungsspalte (auch als Shardschlüssel bezeichnet)
create_distributed_table() ist die Magic-Funktion, die Azure Cosmos DB for PostgreSQL bereitstellt, um Tabellen zu verteilen und Ressourcen auf mehreren Computern zu verwenden.
SELECT create_distributed_table(
'table_name',
'distribution_column');
Das zweite Argument oben wählt eine Spalte aus der Tabelle als Verteilungsspalte aus. Es kann sich um eine beliebige Spalte mit einem nativen PostgreSQL-Typ (wobei ganzzahlig und Text am geläufigsten sind) handeln. Der Wert der Verteilungsspalte bestimmt, welche Zeilen in welche Shards gehen, weshalb die Verteilungsspalte auch als Shardschlüssel bezeichnet wird.
Azure Cosmos DB for PostgreSQL entscheidet, wie Abfragen basierend auf ihrer Verwendung des Shardschlüssels ausgeführt werden:
| Abfrage umfasst | Bei dem es ausgeführt wird. |
|---|---|
| nur einen Shardschlüssel | auf dem Workerknoten, der seinen Shard enthält |
| mehrere Shardschlüssel | parallelisiert über mehrere Knoten |
Die Wahl des Shardschlüssels bestimmt die Leistung und Skalierbarkeit Ihrer Anwendungen.
- Ungleiche Datenverteilung pro Shardschlüssel (auch als Datenversatz bezeichnet) ist nicht optimal für die Leistung. Wählen Sie beispielsweise keine Spalte aus, für die ein einzelner Wert 50 % der Daten darstellt.
- Shardschlüssel mit niedriger Kardinalität können sich auf Skalierbarkeit auswirken. Sie können nur so viele Shards verwenden, wie es unterschiedliche Schlüsselwerte gibt. Wählen Sie einen Schlüssel mit Kardinalität in den Hunderten bis Tausenden aus.
- Das Verknüpfen von zwei großen Tabellen mit unterschiedlichen Shardschlüsseln kann langsam sein. Wählen Sie einen gemeinsamen Shardschlüssel in großen Tabellen aus. Weitere Informationen finden Sie in der Colocation.
Zusammenstellung
Ein weiteres Konzept, das eng mit Shardschlüssel verknüpft ist, ist Colocation. Tabellen, die von denselben Werten der Verteilungsspalten horizontal partitioniert werden, sind kolociert – Die Shards von kolocierten Tabellen werden zusammen auf denselben Workern gespeichert.
Nachfolgend finden Sie zwei Tabellen, die von demselben Schlüssel site_id horizontal partitioniert sind. Sie sind kolociert.
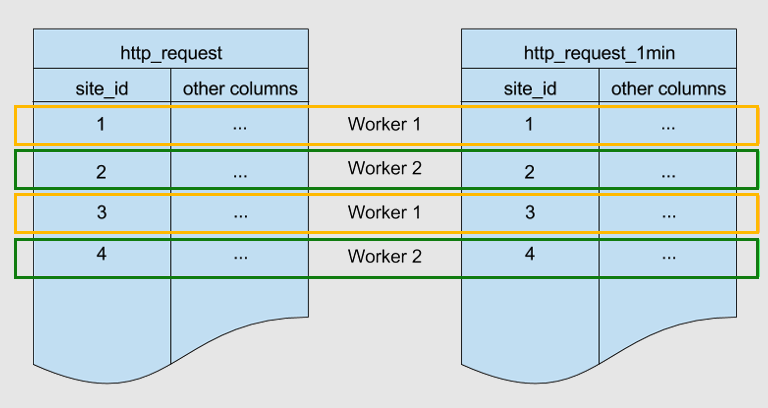
Azure Cosmos DB for PostgreSQL stellt sicher, dass Zeilen mit einem übereinstimmenden site_id-Wert in beiden Tabellen auf demselben Workerknoten gespeichert werden. Sie können sehen, dass für beide Tabellen Zeilen mit site_id=1 im Worker 1 gespeichert werden. Ähnlich für andere Site-IDs.
Colocation hilft, JOINs in diesen Tabellen zu optimieren. Wenn Sie die beiden Tabellen an site_id verknüpfen, kann Azure Cosmos DB for PostgreSQL die Verknüpfung lokal auf Workerknoten ausführen, ohne Daten zwischen Knoten zu schieben.
Tabellen innerhalb eines verteilten Schemas werden immer miteinander zusammengestellt.